
运用模态融合的半监督广义零样本学习
2022-04-09 07:03:54王晓军
计算机工程与应用 2022年5期
林 爽,王晓军
1.南京邮电大学 计算机学院,南京 210023
2.南京邮电大学 物联网学院,南京 210003
传统分类任务通过使用大量数据训练模型实现高精度分类,但现实中的一些数据,譬如珍稀动植物样本,难以获得或者收集代价过大。若能利用已见过类的样本训练模型,使之能够识别未见过类的样本,便可以解决上述问题,于是有学者提出了零样本学习(zero-shot learning,ZSL)问题,ZSL的难点在于如何将未见过类信息与见过类信息联系起来。常见的解决方法是将语义
作为见过类和未见过类的桥梁,即为每个类提供额外的属性定义[1-2]、单词向量[3-4]和文本描述[5]等中间层语义表示[6],来辅助系统识别那些未见过类的样本。举个例子,您见过鸭子和海狸,但没有见过鸭嘴兽,如果告诉您鸭嘴兽的嘴和脚像鸭子,而身体和尾部像海狸,那么您在第一次见到真实的鸭嘴兽的时候,一定能认出它。Akata等人[7]和Lampert等人[1]提出利用视觉语义嵌入的方式解决ZSL问题。基于嵌入模型的方法是指将视觉和语义映射到同一空间中,再根据相似性度量进行分类[8],但同样的语义在不同物种上的表现并不相同,这些方法由于没有测试类样本可以进行训练,在映射测试类样例时便会产生偏差,这就是映射域漂移(projection domain shift)问题。解决映射域漂移问题的关键在于如何提高映射模型的泛化能力[9],于是Zhu等人[10]提出了基于生成模型的解决方案,通过未见过类生成样本,将ZSL问题转变为传统的分类问题。
ZSL设置的初衷在于通过学习见过类事物,继而识别未知事物,因此在训练阶段,其测试集不包含见过类样本。但这种设置没有考虑到现实中待分类样本种类混杂,不可能先通过人工筛选出其中的未见过类样本,再交付分类器进行分类。因此,有学者提出了广义零样本学习(generalized zero-shot learning,GZSL)问题,GZSL希望分类器能够同时识别见过类和未见过类样本。这样的设置更贴合实际,但同时也带来了新的问题:由于模型只学习了如何分辨见过类的事物,因此在判别一个未知事物时,总是更倾向于把它归为某个已见过类。这就是GZSL的偏见性预测问题(bias of prediction)[11]。Schonfeld等人[12]提出的交叉分布对齐变分自编码器模型(cross and distribution aligned VAE,CADA-VAE)在一定程度上对齐了VAE[13-14]模型抽取的视觉和语义潜层特征,然后利用潜层特征进行分类。CADA-VAE模型结合了生成模型和嵌入模型的优势,在一定程度上避免了映射域漂移和偏见性预测问题。
但是训练数据的稀疏性会影响CADA-VAE模型对视觉特征和语义嵌入的共享潜层特征空间的学习。因此,当从语义潜层向量交叉重构视觉样本时,生成的视觉样本分布不能保持真实样本空间的簇结构。同时,潜层空间的类数据重叠分布也会影响分类性能。这需要研究在抽取核心特征以及交叉重构时,如何在适当范围内为数据编码及样本生成提供指导,在保持类内多样性的同时保留类间区分性信息。此外,在CADA-VAE模型的基础上如果能充分利用现实中的大量未标注数据以及未见过类语义进行辅助训练,则能在一定程度上提升模型的性能。于是本文针对上述两个问题,提出了对CADA-VAE模型的改进方案:(1)利用未标注样本特征及未见过类语义辅助模型进行模态内半监督自学习,提升模型的鲁棒性;(2)针对CADA-VAE交叉重构方案提出模态间互学习改进方案,通过使用本文提出的异类语义潜层向量指导视觉模态的特征编码过程,利用视觉质心对语义交叉重构进行约束,保证生成的样本具有类内多样性的同时保持类间区分度。
1 相关工作
ZSL要求训练数据和测试数据类别不存在交集,即利用已见过类数据训练模型,用模型对未见类样本的识别率评估其性能。故ZSL使用的训练数据为{(xi,yi)|xi∈Xs,yi∈Ys}及{(yi,ci)|yi∈Y,ci∈C},可以将这两者进行数据处理,整合成D={(xi,yi,ci)|xi∈Xs,yi∈Ys,ci∈Cs}⋃{(yi,ci)|yi∈Yu,ci∈Cu},并使用其训练模型,其中Xs、Ys、Cs分别为见过类样本特征集合、标签集合、语义集合,Yu、Cu和Y、C分别为未见过类和所有类的标签集合、语义集合;在训练完成后,利用模型识别未见过类的样本特征Xu[15]。而GZSL和ZSL设置唯一的区别在于测试集的设置,GZSL测试集中既包含见过类样本,也包含未见过类样本。
ZSL发展之初,为了解决映射域偏移问题提出的方案,诸如DeViSE[16]、SJE[17]、ALE[18]和EZSL[19],设法学习视觉和语义嵌入之间的线性兼容性函数(linear compatibility function),但是相似类的样本在经线性兼容性函数映射后会出现重叠,导致这类学习方法并不适合解决细粒度分类问题[20]。于是CMT[21]和LATEM[20]尝试使用非线性嵌入的方法应对ZSL挑战。上述几种传统嵌入模型试图在视觉和语义之间寻求关联,而基于相似度的方法另辟蹊径,它们试图从类与类的关联中寻找突破,譬如SYNC[22]利用“幻象”类(“Phantom”classes)将未知类与已知类相关联,从而完成对未知类样本的分类。实验表明,此类模型在ZSL设置上表现良好,但由于此类模型完全基于对已知类样本的分类,因此在面对GZSL问题时,很难通过类迁移函数分离混杂在已知类样本中的未知类样本。Xian等人[23]的实验结果表明,SYNC方法在GZSL问题上的表现相比传统嵌入模型要更差一些。
为了应对GZSL的偏见性预测挑战,近年来人们提出的方案主要分为两类,其中一类是诸如ReViSE[24]的新型嵌入模型方案。该方案先用自编码器分别抽取样本视觉和类语义的潜层特征。这种方案的优势在于,无论是见过类样本,还是未见过类样本,通过自编码器得到的中间层向量,保留了样本核心特征而不会存在偏见,同时,利用核心特征进行分类减少了视觉特征中的无效噪声带来的扰动。另一类是诸如CVAE[25]、SE[26]和f-CLSWGAN[27]等基于生成模型的方案,它们利用语义生成未知类的视觉特征,并将之作为分类模型的训练样本,从而将GZSL问题转变为传统的分类问题,缓解偏见性预测问题;同时,额外的生成数据的引入也使得模型的鲁棒性更强。在这之后提出的CADA-VAE模型结合了嵌入模型和生成模型的特点,通过交叉分布对齐视觉和语义的核心特征,进一步提升了模型在GZSL问题上的识别率。
2 模型
2.1 交叉分布对齐的变分自编码器
CADA-VAE利用两组变分自编码器(VAE)分别学习两种数据模态(视觉特征和语义属性)组合的表示形式,并使用图1中分布对齐损失LDA和交叉重构损失LCA对模型进行约束。CADA-VAE模型的边缘似然为两种模态中各个数据点的边缘似然之和,见式(1)。其中的logpθ(xi)可展开为式(2),logpθ(ci)同理。


图1 交叉分布对齐的变分自编码器模型Fig.1 Cross and distribution aligned variational autoencoder model
不妨设式(2)中的先验概率p服从多元高斯分布(multivariate gaussian),编码器使用多层感知器(multilayer perceptron,MLP)找寻期望μ和方差Σ,使得后验分布q=N( )μ,Σ与分布p接近,继而生成潜层向量z[28],见式(3)。因为式(2)中的第一项为两个分布之间的KL散度,数值非负,所以logpθ(xi)的变分下界为L(θ,φ;xi),若 能 增 大 该 变 分 下 界,则 必 然 能 增 大logpθ(xi),L(θ,φ;xi)见式(4)。
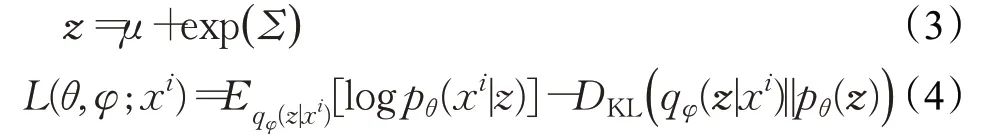
式(4)中,前者表示由xi生成的z再还原为xi的期望,本质上描述了解码器的性能,想要最大化该期望,等价于最小化样本特征在编解码前后的损失,即最小化VAE重构损失;而后者作为KL散度,恒大于0,因此想要增大L(θ,φ;xi),只需要最小化该KL散度即可。
对于式(4)中的VAE重构损失部分,为了最大程度地减少信息丢失,提高向量z的核心特征保留能力,必须通过视觉和语义模态对应的编解码器网络重建原始数据。实际上,第i个样本xi的模型重构损失LiR是样本特征损失和语义损失之和,见式(5),其中E1()、E2()、D1()、D2()分别表示数据经过Encoder1、Encoder2、Decoder1、Decoder2映射得到的结果,VAE模型损失见式(6)1),其中z1为视觉潜层,z2为语义潜层。
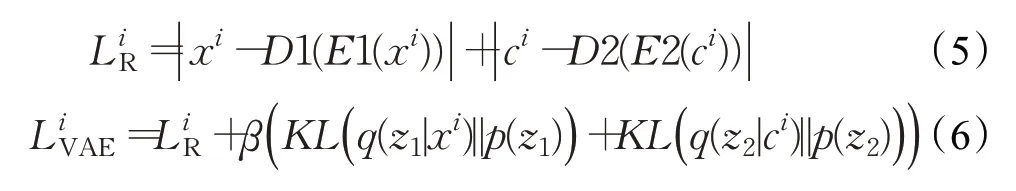
在特征和语义重构的基础上,CADA-VAE方案提出使用交叉重构(cross-alignment,CA)损失和分布对齐(distribution-alignment,DA)损失对模型进行约束。

在训练完CADA-VAE之后,利用模型对(Xs,Ys)和(C,Y)编码,分别得到它们的潜层特征和标签的组合(ZXs,Ys)和(ZC,Y)。然后,使用(ZXs,Ys)⋃(ZC,Y)训练分类器,可实现对任意一个由CADA-VAE编码得到的潜层向量的分类,从而解决GZSL问题。
2.2 半监督模态融合的VAE改进方案
在CADA-VAE模型(图1)基础上提出了半监督模态融合的VAE改进方案(semi-supervised modal fusion VAE model,SMF-VAE)。图2为改进后的模型图,其中的蓝色箭头表示改进方案中新增的数据流向,Imagesl中的五角星为对应类的视觉质心,坐标图表示计算异类语义潜层向量,视觉质心和异类语义潜层向量的定义见2.2.2节。
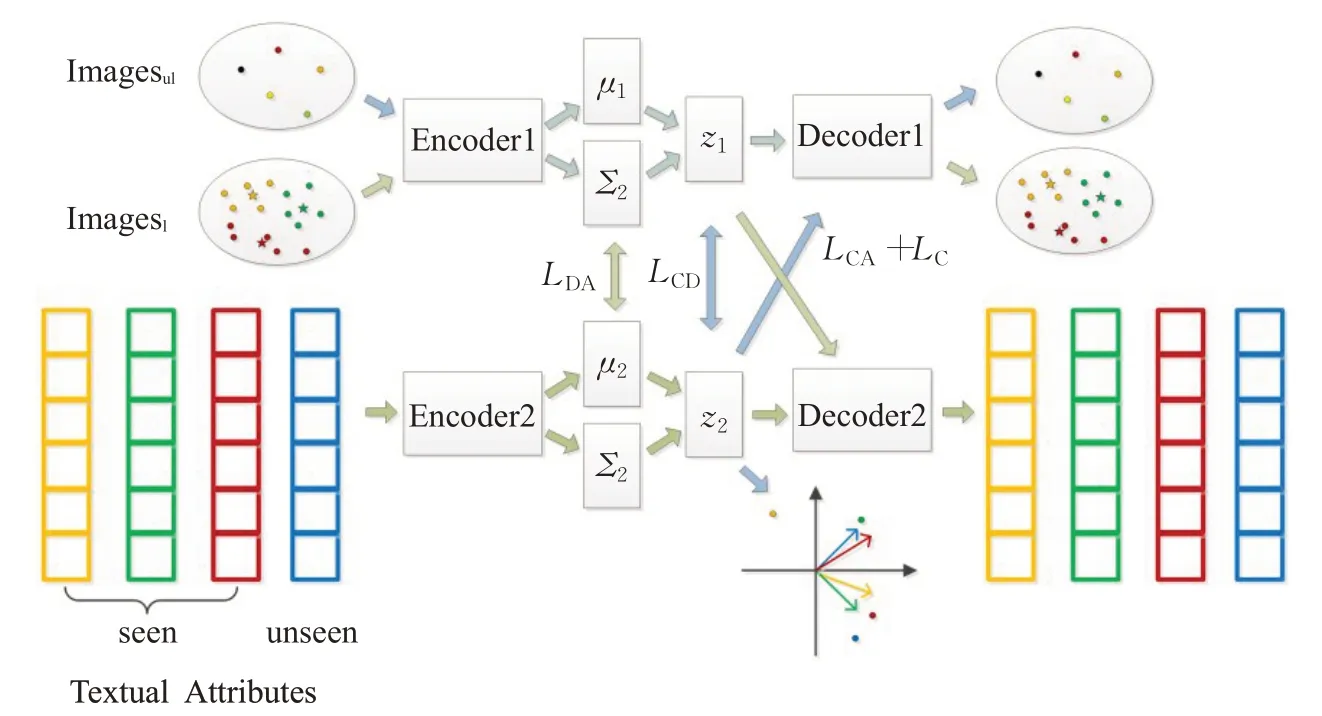
图2 基于模态融合的半监督广义零样本学习模型Fig.2 Semi-supervised generalized zero-shot learning model based on modal fusion
2.2.1 模态内半监督学习方案
大量标注数据训练后的CADA-VAE模型,抽取样本核心特征的能力较强,但在标注数据不足的情况下,模型较难提取样本核心特征,甚至解码潜层特征后无法还原为初始样本特征。现实中,由于人工标注样本代价较大,难以获得大量的有标注样本,若能使用未标注样本及未见过类的语义等辅助信息对模型进行训练,则在一定程度上能够减少训练阶段对标注样本的依赖。不难发现,模型中提取样本潜层特征的功能主要是通过VAE实现的,而VAE采用无监督学习方法,故提出半监督学习方案。该方法利用标注样本和未标注样本、见过
1)CADA-VAE论文中此公式β前的符号为“-”,但结合论文提供的源代码以及VAE论文,认为此处应该为“+”。类语义和未见过语义进行联合训练(joint training),即模型利用标注样本和所有类语义进行有监督的视觉和语义模态内自学习及模态间互学习;利用未标注数据和未见过类语义进行模态内无监督自学习。
为了使用未标注样本,将训练集(Xs,Ys)划分为标注样本集(Xl,Yl)和未标注样本集Xul。用于训练的每批数据中包含从Xs随机选取的标注样本以及未标注样本,其中有标注样本nl个,未标注样本nul个。通过最小化每批数据中的标注样本损失Ll和未标注样本损失Lul之和L,达到对模型进行约束的目的。Ll见式(10),Lul见式(11),L见式(12):
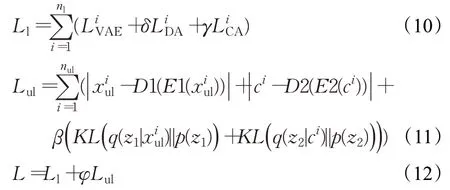
在使用未标注样本进行无监督模态内自学习时,也采用特征VAE和语义VAE联合训练的方法,但和有监督方法不同的是,这里的未标注样本xiul和语义ci∈C不再满足一一对应的关系。
图2中使用Imagesul和unseen的Textual Attribute进行额外的模态内自学习。
2.2.2 模态间互学习方案
CADA-VAE方案通过对齐视觉和语义潜层向量空间,融合了视觉模态和语义模态的共有信息。在跨模态数据互助方面,提出模态间互学习的改进方案,利用语义模态的异类语义潜层向量指导视觉模态的特征编码过程;利用视觉模态的视觉质心指导语义模态进行交叉重构。
(1)利用视觉质心指导语义交叉重构
CADA-VAE是使用(xi,yi,ci)联合训练特征VAE和语义VAE的,训练集中的每个见过类具有多个样本特征,每个类别对应一个语义向量。在训练阶段,对于两组类别相同的数据(xi,yi,ci)、(xj,yj,cj),其中ci=cj,yi=yj,ci和cj通过编码器Encoder2进行加噪编码后,会生成不同的语义潜层向量在交叉重构时将被解码成不同视觉特征的样本类似于现实中一个物种拥有无数个体,CADA-VAE将语义向量交叉重构后可生成多个不同的此类样本,保证了生成样本的类内多样性。但同类样本的视觉特征在高维空间分布的稀疏性会影响CADA-VAE模型在潜层学习到的条件概率分布。这个问题导致语义潜层向量通过交叉重构的视觉样本分散,丢失了用于类间区分的部分信息。为解决这个问题,需要考虑在交叉重构时,如何为模型提供提示,以保证生成的样本具有类内多样性的同时类间分布更具区分度。故本文提出在CADA-VAE方案的基础上,利用视觉模态的信息为语义模态的交叉重构提供指导,在语义交叉重构部分加入视觉质心设计,对于每一个(xi,yi,ci),使得由语义属性ci生成的视觉特征D1(E2(ci))和yi类所有标注样本的视觉质心对齐。
每个类的视觉质心定义为高维空间中该类样本视觉特征簇的质心,可以通过计算真实视觉特征在各维度的均值得到;也可以使用诸如密度聚类等其他类簇中心获取方法得到。为降低计算成本,采用前者得到视觉质心。yi类的视觉质心p(yi)见式(13),其中Xyi为yi类所有已见过样本的集合,|Xyi|为Xyi中样本数量。

质心约束损失LC为模型生成的样本和其所属类视觉质心的二阶矩,LC表达式见式(14)。将其作为正则项添加在模型损失中,保留了CADA-VAE模型交叉重构样本多样化的优势,同时使得生成的同类样本更加集中,类间区分度更大。

图2中,用不同颜色的圆点表示不同类别的样本,用五角星表示此类样本的视觉质心位置,在所有数据送入模型训练之前计算每一个类的视觉质心,希望通过LC的约束,能让Textual Attribute中的语义通过模型生成围绕此类样本视觉质心的特征。
(2)利用异类语义潜层向量优化视觉特征编码
因为CADA-VAE方案是基于编码视觉特征后得到的潜层向量进行分类的,所以视觉特征的潜层分布决定了分类的性能。CADA-VAE通过交叉重构,使用语义指导本类视觉特征编码固然有一定的效果,但相似类语义向量接近,导致它们的视觉特征在潜层的分布会出现重叠,这必然会降低分类性能。为了解决这个问题,提出异类语义潜层向量的概念。

算法1描述了利用标注样本和未标注样本对SMFVAE模型进行训练的详细步骤,其中n_epoch为训练纪元(epoch)的大小,n_dataset为数据集(dataset)的数据总量,n_batch为每一批(batch)的大小。使用Adam算法每次在一个批上优化模型参数(第23行)。
算法1 SMF-VAE Algorithm


算法1首先计算各类样本的视觉质心p(yi)(第5~7行),通过减少质心约束损失LC(第22、24行),使得由语义属性ci重构的视觉特征D1(E2(ci))具备此类样本的核心特征。然后,计算每个类的异类语义潜层向量zˉ~yi(第12~15行),通过最大化异类语义距离LCD(21、24行),使得模型能够沿异类语义潜层向量负方向进行视觉特征编码
3 实验
3.1 评价方法
Xian等人[23]通过评估现有的数据集分割方法,制定了统一的ZSL/GZSL评估基准。GZSL数据不平衡的问题,会鼓励分类器只在数据密集的类上表现出高性能,但实际应用中人们希望在数据稀少的类上也有很好的性能,因此,通常使用式(18)、(19)分别计算见过类和未见过类的平均识别率,使用式(20)作为最终的ZSL/GZSL性能评估标准,其中ns为见过类的类别总数,nu为未见过类的类别总数。使用此评估方法进行了以下GZSL的相关实验。

3.2 实验设置
使用粗粒度标准数据集AWA1和细粒度标准数据集CUB、SUN来评估方案。AWA1数据集由50个动物类,共30 475幅图像组成,每个类提供85个数值属性值;CUB数据集包含200个鸟类,共11 788张图像;SUN数据集包含717场景类,共14 340张图片。为了便于同其他广义零样本学习方法进行比较,使用广义零样本学习最新基准[23]对数据集进行划分。
为了测试半监督学习方案性能,将训练集(Xs,Ys)分成了标注样本集(Xl,Yl)和未标注样本集Xul两个部分,即从(Xs,Ys)中的每一类数据中随机选取ratio比例的数据,组合成(Xl,Yl),将没有被选中的数据作为Xul,这样保证了每一个见过类都有数据参与训练,并且每个类的训练数据占比和原始数据一样,同其他方案对比得到的结果也更具可信力。
下述的实验均是基于python3.5和pytorch框架。

图4 CUB数据集上不同参数对SMF-VAE性能的影响Fig.4 Effects of different parameters on performance of SMF-VAE on CUB
3.3 核心参数寻找以及参数对模型的影响
为了和CADA-VAE模型进行比较,沿用了文献[12]实验中CADA-VAE模型的参数。为了找寻改进方案中核心参数α、φ、η的取值,从原训练集随机取90%的样本作为训练集,10%样本作为验证集。利用网格搜索方法寻找超参数α、φ、η,使得模型在使用训练集样本训练后,能够在验证集上表现性能最佳。实验中发现,参数α、φ、η不宜过大,否则会出现梯度爆炸现象。在AWA1、CUB、SUN三个数据集上进行不同参数的对比实验,实验结果如图3~5所示,其中横坐标的每组参数分别对应α、φ、η。当参数α∈(0.5,3.5),φ∈(0.3,0.5),η∈(0.25,1.75)时,模型在三个数据集上都能够获得不错的效果,当参数超出这个范围后,性能会有些下降。因此建议参数取值范围为α∈(0.5,3.5),φ∈(0.3,0.5),η∈(0.25,1.75),在AWA1数据集上的调参实验发现,η=0.5时效果更优,其他参数选择参数区间的中值更优,故在AWA1上使用参数α=2,φ=0.4,η=0.5,在CUN和SUN上使用参数α=2,φ=0.4,η=1进行了3.4和3.5节的实验,实验表明此组参数在不同训练数据量上都表现良好。
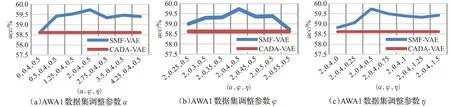
图3 AWA1数据集上不同参数对SMF-VAE性能的影响Fig.3 Effects of different parameters on performance of SMF-VAE on AWA1
3.4 SMF-VAE改进方案评估
将本文提出的方案应用于AWA1、CUB和SUN数据集,同当下主流的12个GZSL监督学习模型对比性能差异。为了同其他实验保持训练数据量的一致,此时的训练数据全部用于了监督学习,所以没有使用未标注数据进行训练,将在下一节同CADA-VAE方案进行对比时,再介绍使用模态内半监督自学习改进方案的提升。
表1总结了SMF-VAE方案和其他方法在三个数据集上的性能。表中识别率为见过类识别率S和未见过识别率U的调和平均数H,其中HAWA1、HCUB、HSUN分别为方案在AWA1、CUB、SUN数据集上的识别率。表中CADA-VAE以及SMF-VAE的识别率是通过五次实验求平均值得到的,由于CADA-VAE论文和本文的实验都是使用相同划分的基准数据集,故其余的对比实验结果均直接引用CADA-VAE论文中的识别率。SMF-VAE在粗粒度数据集AWA1上的表现明显优于所有现有的方法,比起原始方案CADA-VAE方案的识别率高出1.1个百分点;而细粒度数据集CUB和SUN上,相对于原始CADA-VAE方法提升为0.53和0.65个百分点。这主要是因为:AWA1是粗粒度数据集,其中包含了各种动物,动物之间的差异较大,所以不同类别样本的视觉质心距离较远,使用视觉质心指导语义交叉重构,令语义生成的样本分布在此类全体样本的视觉质心位置附近,使用此方案后,相当于减少了分布的方差,从而减少了分布边缘的样本被错误归为其他类别的可能。此外,使用异类语义潜层向量优化视觉编码,相当于将整类样本分布沿异类语义潜层向量的负方向靠拢,一定程度上可以增大样本分布的类间距离。而CUB、SUN为细粒度数据集,类间差异远不如AWA1数据集中的不同动物类之间大,故使用此方案后,在CUB和SUN数据集上的识别精度提升略低于在AWA1数据集上的提升。
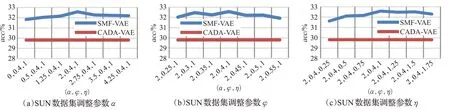
图5 SUN数据集上不同参数对SMF-VAE性能的影响Fig.5 Effects of different parameters on performance of SMF-VAE on SUN

表1 SMF-VAE与主流的广义零样本学习方案性能比较Table 1 Performance comparison between SMF-VAE and mainstream generalized zero-shot learning schemes
3.5 SMF-VAE在使用少量标注样本参与训练时的效果
比较了以下四种改进方法和CADA-VAE方案的性能差异:
(1)使用模态内半监督自学习改进方案;
(2)使用视觉质心指导语义交叉重构改进方案;
(3)使用异类语义潜层向量优化视觉特征编码改进方案;
(4)同时使用三种改进方法,即使用SMF-VAE方案。
图6描述了四种改进方法和原始的CADA-VAE方案在AWA1、CUB和SUN数据集上性能的对比,其中横坐标为用于训练的标注样本占总训练数据量的比例ratio,纵坐标为模型的平均识别率acc。实验结果和预期一样,随着用于训练的标注样本不断增多,三种改进方法和CADA-VAE的识别率都在稳步提升,且本文的所有改进都一直优于CADA-VAE方案。

图6 改进方法和CADA-VAE模型的性能对比Fig.6 Performance comparison of improved schemes and CADA-VAE
模态内半监督自学习改进在标注样本较少而未标注样本较多的情况下提升效果十分显著。并且由于细粒度数据集的样本类间距离较小,在使用少量标注样本训练时,编码器不能很好地把视觉特征映射到潜层,所以此时使用模态内半监督自学习方案改进效果更明显。在ratio比率为0.1时,AWA1、CUB和SUN数据集上识别率提升分别为1.01、1.85和1.89个百分点。随着用于无监督学习的数据量的减少,性能提升程度也在不断降低,最终用于无监督学习的数据量为0时,模态内半监督自学习方法和原始方案完全一致。
视觉质心指导语义交叉重构和异类语义潜层向量优化视觉特征编码改进带来的提升都比较稳定,在不同ratio比率的情况下,在AWA1、CUB和SUN数据集上视觉质心指导带来的提升分别为0.64、0.32和0.40个百分点左右,异类语义潜层向量带来的提升分别为0.52、0.32和0.42个百分点。
SMF-VAE改进方案继承了上述三种方法的优点,性能提升比较均衡,在标注样本较少的时候,模态内半监督自学习带来的提升占主导;在标注样本较多时,视觉质心指导和异类语义潜层向量方法带来的提升占主导。总体来看,合成方案性能更优。尤其在ratio比率为0.1时,即标注样本很少时,AWA1、CUB和SUN数据集上识别率提升分别为1.12、2.21和2.76个百分点。
图7中,S为见过类识别率,U为未见过类识别率,H为两者的调和平均数。正如图中显示的那样,在AWA1、CUB和SUN数据集上,当ratio比率为1时,本文的改进方案并不是通过大幅牺牲未见过类识别率或者已见过类识别率中的一者来提升另一者,而是提升总体的识别率。本文的方案在标注样本较少,而未标注样本较多时性能提升较大。当ratio=0.1时,如图8所示,本文的方案同样可以通过提升见过类和未见过识别率的其中一者或者两者来大幅提升综合识别率。

图7 SMF-VAE和CADA-VAE在ratio=1时识别率的对比Fig.7 Comparison of recognition rate of SMF-VAE and CADA-VAE at ratio=1

图8 SMF-VAE和CADA-VAE在ratio=0.1时识别率的对比Fig.8 Comparison of recognition rate of SMF-VAE and CADA-VAE at ratio=0.1
4 结束语
本文针对GZSL问题提出了一种基于模态融合的半监督学习改进方案SMF-VAE。半监督模态内自学习方案在使用标注样本以及见过类语义训练模型的基础上,通过使用大量未标注样本及未见过类语义训练模型的模态内编解码能力,模态间互学习方案使得模型由语义生成的样本更具代表性,模型编码未知类样本时能够更大程度保留其核心特征,提升了模型的鲁棒性。本文在3个基准数据集上将SMF-VAE和当下主流的GZSL方案进行性能对比,实验结果表明,本文所提出的方案性能优于当下主流方案,尤其在使用少量标注样本和大量未标注样本进行训练的情况下,性能提升更为明显。
猜你喜欢
开放教育研究(2020年2期)2020-03-31 01:54:14
计算机工程(2020年3期)2020-03-19 12:24:50
中国听力语言康复科学杂志(2019年3期)2019-06-24 09:51:20
中国交通信息化(2018年3期)2018-06-13 03:27:58
中国交通信息化(2016年2期)2016-06-06 07:28:02
现代语文(2016年21期)2016-05-25 13:13:44
湖北经济学院学报·人文社科版(2015年8期)2015-12-29 05:53:07
上海电机学院学报(2015年4期)2015-02-28 14:30:00
大连民族大学学报(2015年2期)2015-02-27 08:28:11
计算物理(2014年2期)2014-03-11 17:01:39
