
MDT-CNN-LSTM模型的股价预测研究
2022-04-09 07:06:30曹超凡罗泽南谢佳鑫
计算机工程与应用 2022年5期
曹超凡,罗泽南,谢佳鑫,李 路
上海工程技术大学 数理与统计学院,上海 201600
股票市场作为中国资本市场的重要组成部分,有市场主体竞争中性[1]、普惠[2]和分散投资风险[3]等基本特征,目前市场已经初步形成[4]基本制度与层次体系且规模位居世界前列,开放程度日益提高,积聚起一定的发展势能,正处于由大到强的关键转型阶段。因此,作为全球资本市场的重要组成[5-7],中国股票市场的价格预测分析对于完善市场定价机制、提高市场可持续融资功能、完善功能性监管框架、扩大资本市场高水平双向开放具有重要意义。
股票市场本质上是一个动态的、非平稳的、嘈杂和混乱的系统[8]。面对数据量大、非线性等复杂特征的股票数据,传统的统计学预测方法如回归分析、时间序列分析等无法取得较好的预测效果。随着人工智能与大数据时代的发展,逻辑回归、决策树和深度学习等机器学习技术广泛应用于金融数据的研究,其中深度学习因其具有更为强大特征学习能力脱颖而出,在股价预测效果中往往具有更强大的泛化性和预测精度。
深度学习最为基础的两个模型是CNN和RNN,而LSTM解决了由时间长度带来的梯度爆炸和梯度消失的问题,是RNN最为经典的变体之一,章静怡利用卷积神经网络学习金融数据特征,构建股价预测模型[9]。王悦霖用LSTM模型预测股价涨跌幅[10]。胡聿文用LASSO和PCA分别先对股票价格因子进行降维筛选,再输入LSTM模型进行预测[11]。Vidal等[12]提出CNN-LSTM组合模型,进行金价的波动率预测,预测结果优于单个CNN、LSTM模型。该模型充分提取时序特征,并利用了时间序列的自相关性进行高精度预测。但在股票市场中,股票因子之间相关性也是相当重要的考虑因素。本文在CNN-LSTM的模型基础上,引入了多向延迟嵌入的张量处理技术MDT(mutiway-delay-embedding),对股票因子进行重构,将每个时间点上的股票因子向量生成汉克尔因子矩阵,再将所有时间上的汉克尔因子矩阵并排成为汉克尔因子张量,作为CNN模型的输入,利用CNN卷积与池化操作提取因子的深层特征,再将其输入到LSTM模型,更好地处理股票因子之间的相关性。
本实验使用Keras作为深度学习平台,构建MDTCNN-LSTM模型,对48家主流上市公司2011—2021年的股票数据进行分析预测实验,对比预测结果与真实值,作出模型预测拟合图和模型训练误差图,并与CNNLSTM深度学习网络模型作对比,验证了加入MDT张量处理后模型预测的有效性和泛化性。
1 MDT张量处理技术
股票数据在输入到深度学习模型前,最常用的数据处理方式是滑动窗口法。滑动窗口法是将长度为n的时间序列沿着时间步长切分成多个长度为m(m<n)的连续子序列的方法[13]。在处理多维时间序列时,先设定时间步长,沿着时间方向滑动窗口处理二维时序矩阵切分出多个固定大小的子矩阵,切分出的子矩阵并排形成张量作为深度学习模型的输入,过程如图1所示。滑动窗口法考虑时间序列的自相关性,在处理单条时间序列时能起到较好效果,但在处理多维时间序列时未考虑到因子相关性,在股票市场中,股票因子之间存在强相关性。考虑到因子相关性,本文引入MDT张量处理技术[14]。
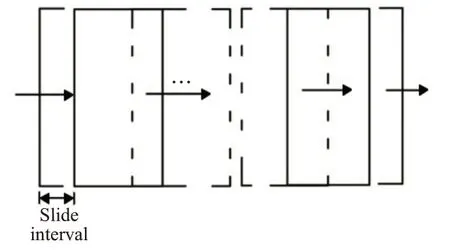
图1 滑动窗口处理过程Fig.1 Sliding window processing process
将股票数据集看成是拥有时间(以天为单位)和股票因子两个维度的矩阵。固定时间,矩阵的每一行便可看成当日的股票因子向量x,向量的各分量表示当日各股票因子的值。设当日股票因子向量x=(x1,x2,…,xn)T∈ℜn,利用MDT变换将其生成汉克尔矩阵Mτ(x),即:
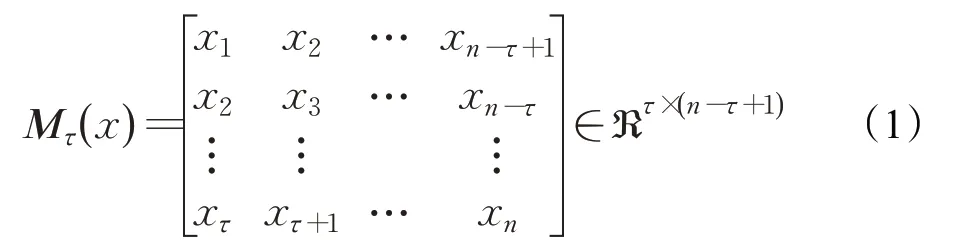
生成的汉克尔矩阵与原向量满足公式(2):

其中,vec为拉直算子,将汉克尔矩阵按列拉直成向量,C是复制矩阵,由多个τ×τ单位阵在对角线上错位排开组成,如图2所示。
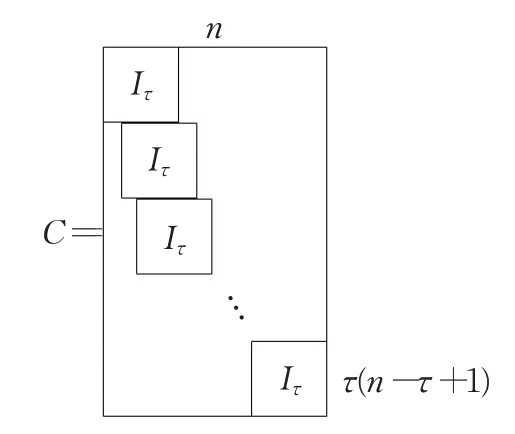
图2 复制矩阵示意图Fig.2 Schematic diagram of copy matrix
MDT运算可由公式(3)表示:

函数fold(n,τ):ℜτ(n-τ+1)→ℜτ×(n-τ+1)是一个折叠算子,可将向量转化为矩阵,设汉克尔矩阵Mτ()
x=(v1,v2,…,vn-τ+1),其中vi表示汉克矩阵的第i列向量:

将每日股票因子向量通过MDT变换生成汉克尔矩阵,再将每个时间点生成的汉克尔矩阵并排组成汉克尔张量,作为后续深度学习模型的输入数据。
华为诺亚方舟实验室[15]利用MDT等张量技术与传统ARIMA预测模型相结合,在指定数据集中取得不错效果。然而该文使用的数据集特征相关性弱于时序自相关性,所以只沿着时间方向应用MDT处理三阶原始张量。而股价波动隐藏着市场力量推动下因子间相关性,针对股票数据中有着更为复杂的因子相关性,本文选择沿着因子模式上应用MDT方法进行张量构建,并首次将其与深度学习模型相融合,使预测结果相较之下更具泛化性与时效性。
2 CNN-LSTM网络模型
2.1 卷积神经网络
卷积神经网络(CNN模型)是用于特征提取表达的深度学习模型,可实现从输入到输出的功能映射。如图3所示,CNN由输入层(Input)、卷积层(Convolution Layers)、池化层(Pooling)、扁平化全连接层(Flattening)和输出层(Output)组成。卷积层通过权值共享的卷积核与输入数据对应的感受野区域进行卷积计算,从而提取输入特征。卷积的计算公式为:
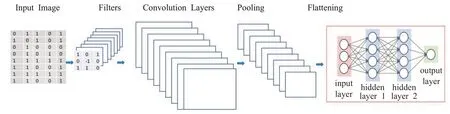
图3 卷积神经网络结构示意图Fig.3 Schematic diagram of convolutional neural network structure
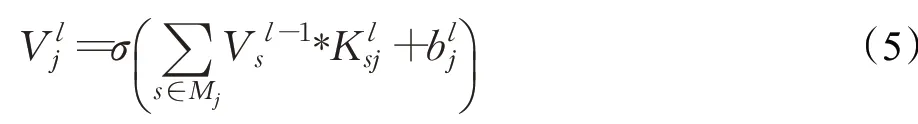
公式(1)中,规定输入层为第l-1层,用于表示输入层第s个特征,输出层为第l层,用于表示输出层第j个特征,用于表示卷积核的元素,为偏置项,σ为激活函数。
输入数据经过卷积层提取特征后,采取池化操作抽象卷积层输出特征的信息,从而能增大感受野,进一步提升模型的泛化能力。池化层通常出现在卷积层后。常见的池化方法是最大值池化与平均值池化。经过多次卷积层的特征提取与池化层信息抽象后,输入特征经Flattening扁平化处理张成一维向量,由全连接层的传统神经网络对其进行分类或预测。全连接层得到的输出与标签作对比,不断迭代更新权值,从而实现反向传播。本文选取CNN模型的卷积层和池化层,保留了模型特征提取和信息抽象的功能,将经由MDT变换生成的汉克尔张量作为该模型的输入数据,提取数据中含有因子间强相关性的特征,为后续的预测作准备。
2.2 长短时记忆网络(LSTM)
长短时记忆网络(LSTM)是循环神经网络(RNN)的变体[16]。为解决模型梯度消失的问题,增强模型泛化性,LSTM在RNN的基础上进行优化,有着类似的链式结构,同时引入了细胞状态ci用来存储序列的长期信息,并增加了三个门控单元:遗忘门、输入门与输出门来对长期信息和新输入的信息进行筛选与更新,如图4所示。
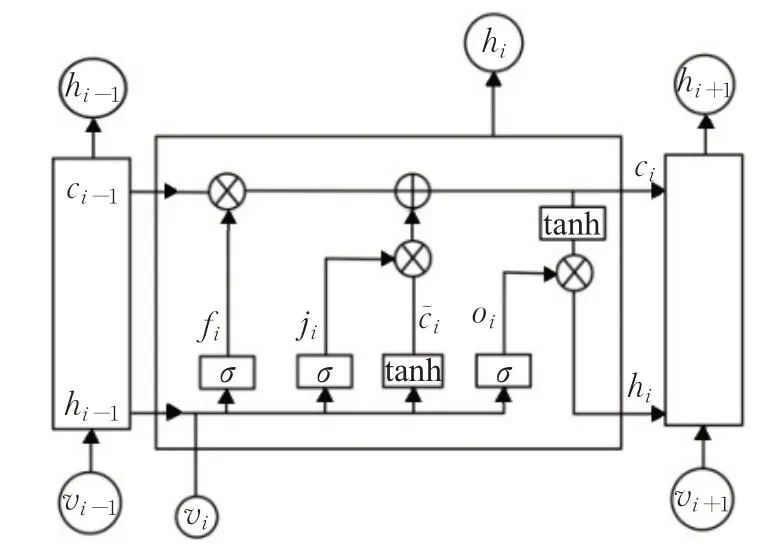
图4 LSTM结构示意图Fig.4 Schematic diagram of LSTM structure
遗忘门定义要遗忘的信息,即确定应从上一个细胞状态中删除哪些信息。遗忘计算过程如下:
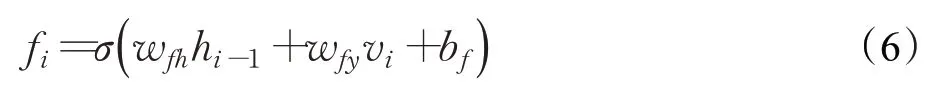
其中,fi是遗忘门的输出;σ是激活函数,通常是sigmoid函数,可以将所有激活值缩放至0到1之间,0表示“完全遗忘”,1表示“完全保留”;wfh、wfy是权重矩阵,hi-1是上一个存储单元的输出;vi是当前输入;bf是遗忘门的偏置项。
输入门定义应将哪些新生信息添加到细胞状态。数据经遗忘门筛选历史信息后,下一步是确定应更新哪些新生信息。更新过程分为两个部分[18],第一部分计算ji确定需要更新哪些新生信息至细胞状态,计算过程如公式(7):
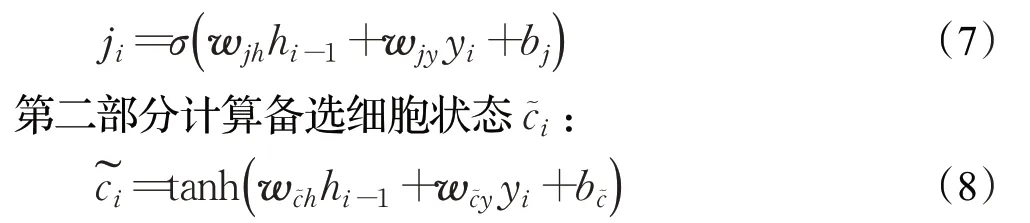
其中,tanh是正切函数;wjh、wjy、wc~h、wc~y是权重矩阵;bj和bc~是输入门偏置项。通过计算输入门输出ji与备选细胞状态~ci的乘积,确定了哪些新生信息将添加到细胞状态,同时计算遗忘门输出fi与原细胞状态ci-1的乘积,确定了原细胞状态中哪些历史信息得以保留。最后将二者相加,完成一轮新细胞状态的更新,计算过程如公式(9):

输出门定义应将哪些信息用作输出。经过遗忘门和输入门实现对细胞状态的更新后,下一步确定当前状态需要输出的信息,计算过程如下:
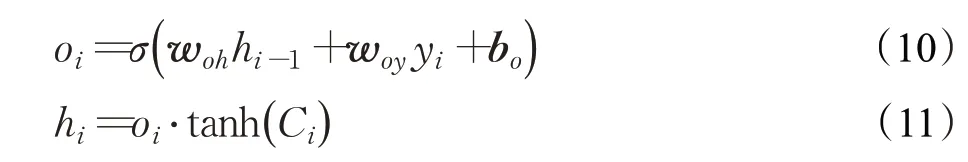
其中,oi是输出门的输出;woh、woy是权重矩阵;bo是偏差矢量;hi是当前记忆单元的输出。
LSTM通过隐藏层间的输入输出在处理关联数据时,能有效存储数据特性并解决梯度消失的问题。通常用于研究输入信息在时间维度上的相关性问题,在处理时间序列数据有着很大优势,如Sagheer和Kotb[17]使用长期短期记忆(LSTM)递归网络的深度架构对石油时间序列进行预测,结果好于RNN和ARIMA模型。而事实上,LSTM不光在时间序列数据上可以较好地预测效果,在有强关联性的特征数据上也有很强的预测能力。
2.3 CNN-LSTM网络模型结构
本文将CNN与LSTM进行融合构建CNN-LSTM深度学习预测模型,如图5所示。先利用CNN模型的卷积层(Convolution Layer)、池化层(Pooling Layer)对输入数据提取特征、抽象信息得到特征数据,再经由Flattening层后输入到LSTM模型进行关联预测,最后接入全连接层(Full Connection Layer)得到模型的预测值。卷积和池化操作降低了输入数据的复杂性,可有效处理异常值数据,防止过拟合。接入LSTM层,利用LSTM的遗忘门与输入门可对关联数据信息进行有效的筛选与更新,更好地预测关联数据。
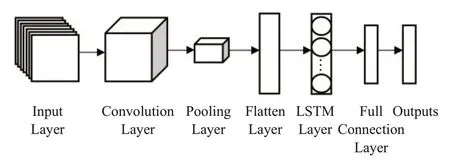
图5 CNN-LSTM网络结构Fig.5 CNN-LSTM network structure
3 MDT-CNN-LSTM预测框架
本文将MDT张量技术与CNN-LSTM模型相融合,构建的MDT-CNN-LSTM预测框架如图6所示。将归一化处理后的股票数据沿着因子方向作MDT变换,即将时序矩阵按时间进行切片,得到每日股票因子向量,股票因子向量重构生成充分含有因子强相关性信息的汉克尔矩阵,将多个汉克尔矩阵并排形成汉克尔张量,作为深度学习的输入样本。MDT变换通过公式(2)的复制矩阵将每日股票因子向量映射成汉克尔矩阵,汉克尔矩阵的每列相邻向量含有相似的因子信息,但相同的股票因子在每列向量所处的位置均不一样,且每列向量都会出现新的股票因子,完成了因子重构,这样极大程度地保留了不同股票因子间的因子相关性信息。将经MDT变换后的数据集分成训练集与测试集,将训练集数据输入CNN模型,利用卷积与池化操作充分对含有股票因子强相关性信息的输入数据进行特征提取与信息抽象,提取后的特征数据输入LSTM模型,进行拟合并训练模型参数,最后将测试集数据输入到训练好的模型进行股价关联预测。
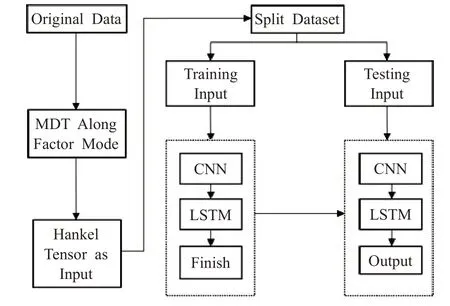
图6 MDT-CNN-LSTM预测流程图Fig.6 MDT-CNN-LSTM prediction flow chart
本文创新性地将经MDT变换并由CNN输出后包含股票因子间强关联性的特征数据输入至LSTM。利用MDT变换充分保留了股票因子相关性信息,CNN对含有因子相关性信息的输入数据充分提取特征,LSTM进行预测。完成了股票因子重构、因子相关性特征提取与因子关联预测的三个重要步骤,从而实现MDT张量技术与CNN-LSTM模型的有机结合。
4 实证分析
4.1 数据来源
本文选取A股市场中,2 000亿以上市值,涵盖22个行业的48支大盘股进行实证分析,如表1所示。从优矿获取该47支股票从2011年1月4日到2021年3月5日的历史数据,实验环境为python3.7。
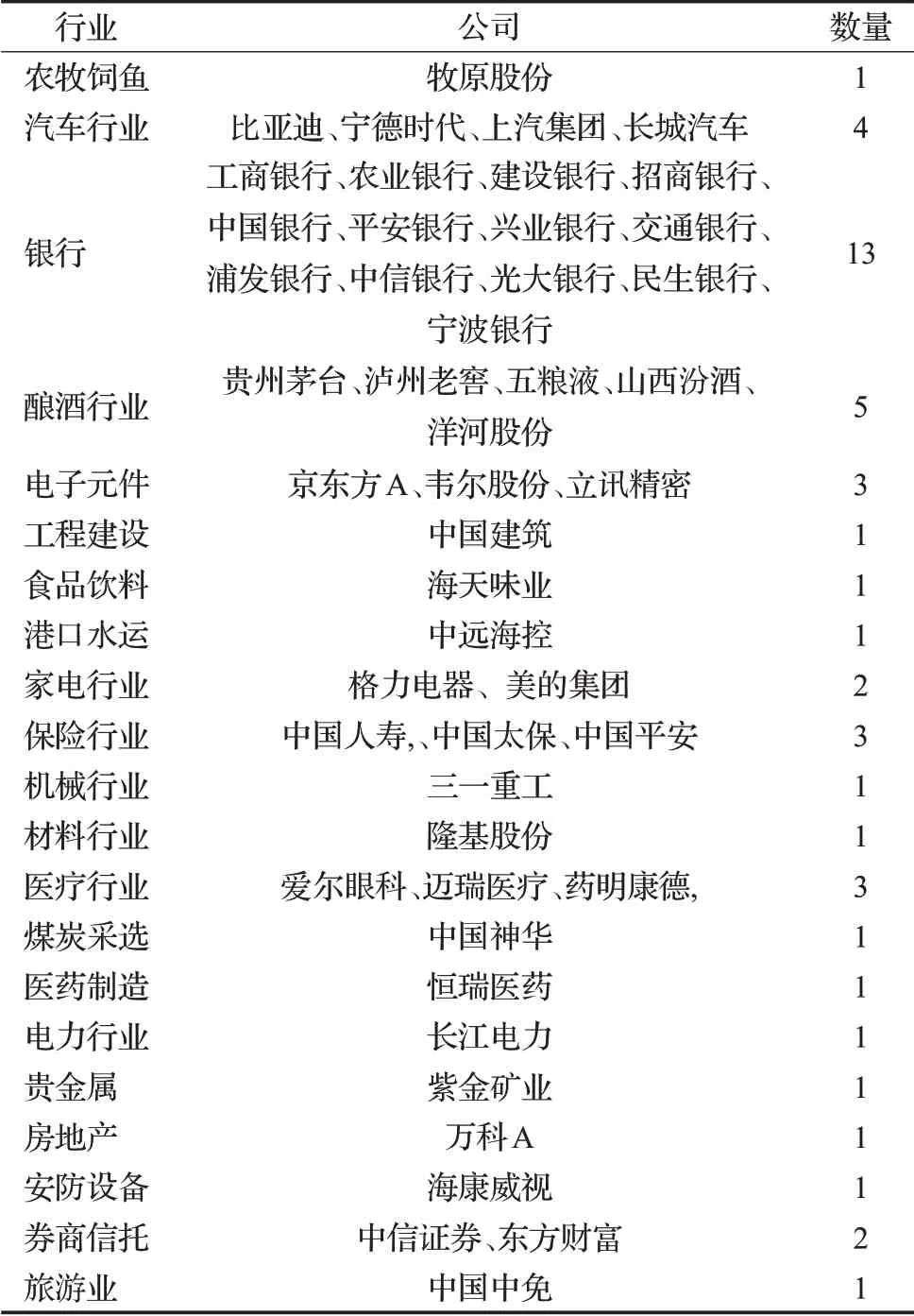
表1 股票名称、所在行业、数量Table 1 Stock name,industry,quantity
4.2 因子选取与参数设置
参考Yu等[18]利用因子分析的方法将9项指标简化为3项指标(资本配置、投融资水平和运营情况),并表明资本配置指标对股市发展起到关键作用。本文基于此成果,选取反映资本配置的市盈率、市净率,反映投融资水平的成交量、成交金额、成交笔数、流通市值、总市值,反映运营情况的日换手率、涨跌幅,再加上反映价格变动的当日开盘价、最高价、最低价总共12个股票因子,将第二天的收盘价作为预测标签,对48支股票股价进行预测。
优化器设定为Adam优化器,学习率设定为0.001.激活函数为RELU函数,设定均方误差(MSE)作为预测损失函数。训练集与测试集比例为4∶1。本文采用网格搜索,最终得出MDT的参数τ设定范围在[6,8]最为合适。其余参数如表2所示。
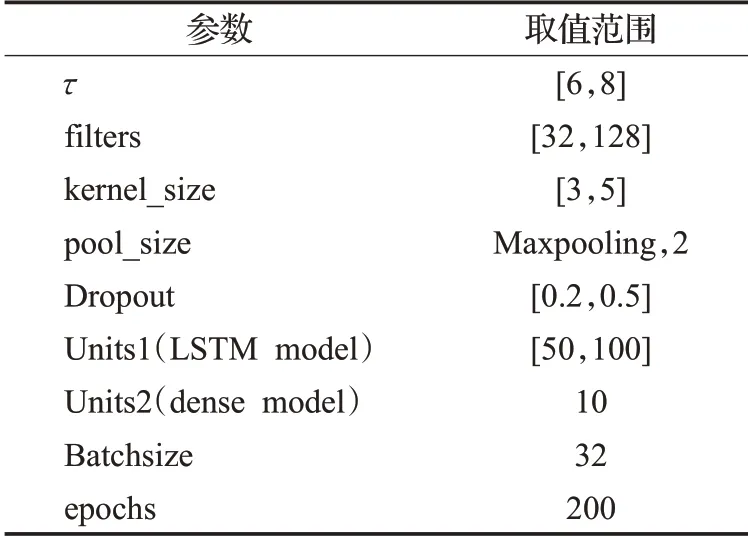
表2 MDT-CNN-LSTM参数设置Table 2 MDT-CNN-LSTM parameter settings
4.3 实证结果分析
本文将MDT-CNN-LSTM模型与CNN-LSTM、CNNLSTM模型作对照,分别根据48支股票的历史数据进行股价预测分析,并计算每支股票的平均绝对误差(MAE)、均方误差(MSE)、平均绝对百分比误差(MAPE)、均方根误差(RMSE)作为模型评价指标,最后取平均值,表现最好的指标结果以加粗字体显示,表3是计算股票预测误差的平均值,在四类评价指标中,CNN-LSTM拟合效果略好于LSTM,但差距不大。CNN的效果最差。MDT-CNN-LSTM的误差均达到最小值,充分说明模型预测的有效性。
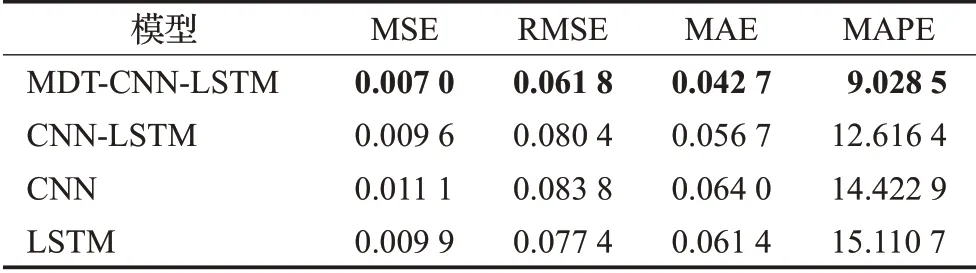
表3 模型预测评价指标的平均值Table 3 Average value of model prediction evaluation index
同时,为比较模型的时效性,本文同时将四种模型的运算时间作比较,表4为各模型预测所耗费的时间。

表4 模型预测时效性Table 4 Model prediction timeliness
由表4可知CNN耗时最短,其次为MDT-CNNLSTM,预测时长与CNN-LSTM时间相接近,而LSTM耗时最长。因MDT-CNN-LSTM与CNN-LSTM模型均有卷积和池化操作,对输入数据进行特征提取,大大降低了输入数据的复杂性,故耗时相较直接输入LSTM模型要短。而CNN模型无后续操作,故耗时最短。但结合表3模型预测效果可以看出,CNN虽然耗时短但预测效果最差;CNN-LSTM与LSTM虽然在预测精度上差距不大,但CNN-LSTM相较LSTM模型时效性有较大提升,故综合对比优于LSTM。而MDT-CNN-LSTM在预测效果和时效性上都具有较大优势,证明本文提出的模型较好的实用性。
针对MDT-CNN-LSTM模型的拟合效果,本文截取了爱尔眼科、海天味业、中信银行、万科A4支股票的损失函数曲线图及股价预测图,分别如图7、图8所示。
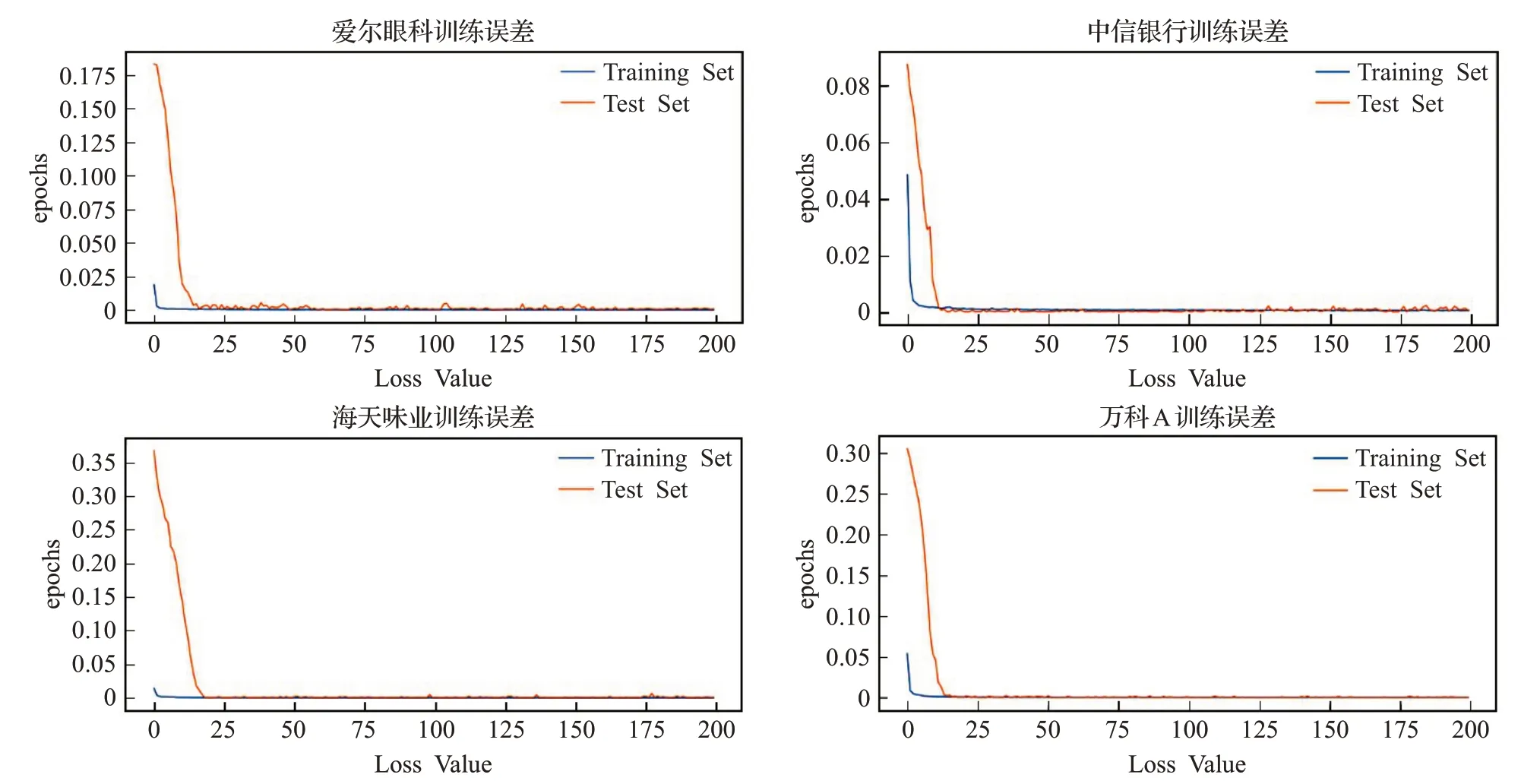
图7 损失函数曲线图Fig.7 Loss function graph
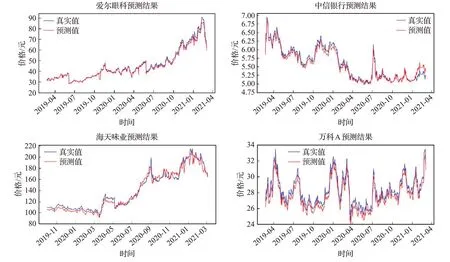
图8 股价预测曲线图Fig.8 Stock price forecast curve
从实际预测拟合的效果出发,发现MDT-CNNLSTM模型对四类股价走势具有较好的预测能力。
(1)股价低位盘整、缓步提升:股价在较长时间(如一年)低位盘整,在某个时间节点股价开始缓步爬升,如爱尔眼科在2019年4月至2020年10月股价有所波动,但是没有明显起色,在2020年10月后股价开始逐步爬升。
(2)股价底部震荡、迅速抬升:股价在较长时间(如一年)底部震荡,但在某个时间突然剧烈波动,股价抬升迅速,如海天味业在2019年11月至2020年7月股价均是在100~140元之间震荡,但是之后开始急速拉升至200元,呈现类似垂直的股价拉升。
(3)股价温和下跌后,急速拉升与下跌:在下跌通道的股票,先温和下跌,经历急速拉升与下跌后再次缓步下跌,如中信银行在2019年4月至2020年7月温和下跌,在2020年7月经历了一波急速拉升与下跌,又重新进入了温和下跌状态。
(4)股价区间震荡波动,且振幅明显:股价在很长时间(如两年)震荡波动,且振幅明显,股价变化迅速,如万科A在26~33元之间的股价区间震荡,还有京东方A在3.5~4.5元、3.5~5.5元这两个震荡区间的股价波动,建设银行在6~7.5元之间股价区间震荡等等。
4.4 股指预测效果分析
本文验证了MDT-CNN-LSTM在行业个股的有效性,而为探究该模型在股指预测中是否依然具有较好的预测效果,分别选取上证指数、沪深300指数、A股指数、深证综指四支股指,数据的时间维度为2011年1月4日至2021年3月5日,并选取昨日收盘价、开盘价、最高价、最低价、收盘价、成交量、成交金额、涨跌、涨跌幅九个股指因子,预测次日收盘价。
表5是计算股票预测误差的平均值,在四类评价指标中,MDT-CNN-LSTM误差依旧最低,拟合效果优于CNN-LSTM、CNN、LSTM,验证了该模型在股指预测中依旧取得较好效果。

表5 股指预测模型评价指标的平均值Table 5 Average value of evaluation index of stock index forecasting model
5 结语
本文通过在构建的CNN-LSTM模型中引用MDT张量技术对股票因子进行重构,生成汉克尔张量,重构后的数据含有因子相关性信息,使用CNN提取部分信息,得到包含因子相关性信息的特征矩阵,再输入到LSTM进行关联预测。本文将构建的MDT-CNN-LSTM预测方法用于48家主流上市公司进行股价预测,并与CNN-LSTM、CNN、LSTM三个模型进行对比,结果表面,预测准确率有了很大提升,且同时具有良好的时效性。根据预测结果,总结了MDT-CNN-LSTM对四种股价走势有着良好的预测能力。最后,本文将模型应用到沪深四类股指预测中,依然取得较优效果。本文首次将MDT张量技术与深度学习模型融合,考虑到验证MDT张量处理技术是否具有更强的应用,将会在未来尝试跟其他深度学习模型进行融合,希望探究其与深度学习有机结合的能力。
猜你喜欢
理财周刊(2023年11期)2023-11-08 00:37:19
数学物理学报(2021年1期)2021-03-29 03:13:38
五邑大学学报(自然科学版)(2020年4期)2020-12-09 06:28:48
股市动态分析(2019年42期)2019-11-13 01:55:04
股市动态分析(2016年23期)2016-12-27 19:01:58
股市动态分析(2016年22期)2016-12-27 10:39:02
山西大同大学学报(自然科学版)(2016年2期)2016-12-12 03:19:27
股市动态分析(2016年7期)2016-09-29 11:18:25
股市动态分析(2016年4期)2016-09-29 08:39:10
股市动态分析(2016年2期)2016-09-27 21:22:52
