
机器学习模型在车险欺诈检测的研究进展
2022-04-09 07:02:00卢冰洁李炜卓那崇宁牛作尧
计算机工程与应用 2022年5期
卢冰洁,李炜卓,那崇宁,牛作尧,陈 奎
1.之江实验室,杭州 311121
2.南京邮电大学 现代邮政学院,南京 210003
3.东南大学 苏州联合研究生院,江苏 苏州 215123
4.南京大学 计算机软件新技术国家重点实验室,南京 210093
自改革开放以来,我国保险业取得了长足的发展。据2021年4月银保监会发布的保险业发展报告,发展至2020年,我国共计成立了235家保险公司,总资产达23万亿,保费收入4.53万亿元,同比增长6.12%,成为了全球第二大保险市场。车险作为财产险中的第一大险种高达69%,对保险行业的发展至关重要。然而,近年来车险欺诈案件的数量呈逐年上升趋势,使得保险公司的赔付成本不断上升。保守估计,我国车险欺诈渗漏占理赔金额的比例至少达20%[1]。2020年我国车险理赔支出合计约为4 725.50亿元,照此推算,保险公司在车险欺诈方面的渗漏损失高达900亿元以上[2]。车险欺诈增加了保险公司运营成本和经营风险,侵害了保险消费者的合法权益,破坏车险市场秩序,同时也对他人财产及整个社会构成危害。为此,银保监会于2018年2月专门印发了《反保险欺诈指引》以指导保险公司和保险行业进行反欺诈制度建设。如何有效地识别车险欺诈对促进车险市场良性健康发展具有重要意义。
在我国保险欺诈领域,车险欺诈相比于其他险种的欺诈,存在犯罪手段隐蔽、手法多样的特点,并逐渐呈现出团伙化的作案方式[2]。从近几年的数据可以发现,车险共同犯罪的比例存在明显的提升,且作案人员分工明确,这都给车险欺诈检测带来不小的挑战。近年来,受益于各个国家监管部门与保险公司对车险欺诈的广泛关注,车险欺诈检测技术的研究取得了很大的进展。由于机器学习模型对原始数据的预处理要求比较低、可以建模因子间存在的交互效应和非线性关系、具有预测能力较好等优点,目前已在车险损失预测中有了诸多应用研究[3]。
车险欺诈检测问题可以抽象为一个二分类或者多分类问题,国内外均有不少学者将机器学习模型应用在车险欺诈检测技术上,并取得了较好的研究成果。譬如,在国外,Viaene等人[4]、Hanafizadeh等人[5]、Kašćelan等人[6]、Li等人[7]分别探索了贝叶斯模型、聚类模型、数据挖掘、随机森林等技术在车险欺诈检测领域的效果;He等人[8]、Guo等人[9]、Wang等人[10]则进一步探索了深度学习模型在该任务上的应用价值;Subudhi等人[11]、Majhi等人[12]则从混合模型的角度进行切入,提供了一种有效的建模方法。相应的,国内学者庹国柱等人[13]、刘喜华等人[14]最早开始从车险的理论进行了探究;桂萍等人[15]收集了大量国内外车险道德风险文献,并在此基础上进行归纳梳理;赵桂芹等人[16]、汤俊等人[17]、王海巍等人[18]则根据国内的车险欺诈的实际情况,应用传统机器学习模型对其进行建模;近些年,闫春等人[19]、喻炜等人[1]、徐徐等人[20]开始从深度学习网络、混合模型的角度出发,在车险欺诈检测任务上取得了较大的进展。此外,车险欺诈领域具有其独特的挑战性。比如:车险欺诈数据的特征空间庞大,且特征之间有着复杂的依赖关系,而传统机器学习往往需要进行特征选择。针对这个问题,Panigrahi等人[21]采用了三种特征选择算法,提取车险欺诈数据中的重要特征,并利用机器学习算法进行检测,从而挑选出不同机器学习模型的最佳特征选择方法。另一方面,车险欺诈相对于信用卡欺诈等常见形式发生概率更低,因此类别不平衡现象更为明显[22]。为此,Hassan等人[23]、Padhi等人[24]分别使用了欠采样、过采样等策略来缓解车险欺诈任务所存在的挑战。
然而,尽管已有上述的诸多车险欺诈检测的研究工作,并且取得了较为显著的进展,但缺乏基于机器学习模型对车险欺诈检测进行系统深入的梳理与总结的工作,特别是近些年深度学习方法在车险欺诈检测研究上的进展。一方面,国内在车辆保险欺诈检测技术方相对滞后,模型实验所采用的车险欺诈数据较为陈旧,且部分采用国外早期开源的数据进行模拟。另一方面,国外的研究成果又较少对我国车险业务数据进行关注,无法适配目前国内车险行业拟定的规范,因此无法较好地进行建模。
为此,本文首次针对机器学习模型在车险欺诈检测领域的研究工作进行了文献调研。具体地说,本文首先给出车险欺诈检测流程的简介,分别对专家系统与智能理赔系统在车险欺诈检测的流程进行了简要的叙述。然后,对二十多年来的研究工作进行系统化的归纳与总结,依次从国外和国内的角度介绍了机器学习模型在车险欺诈检测的具体研究进展,将其归纳为基于传统机器学习方法、基于神经网络的方法以及基于混合模型的方法,并进行了宏观的对比。接着基于国内某车险公司近5年来高质量的车险数据选取最具代表性的机器学习模型进行建模,并进行了全面的测试与分析。最后,对全文进行总结并展望车险欺诈技术未来的研究方向。
1 车险欺诈检测流程简介
本章将分别从车险专家系统与智能理赔系统两个角度来介绍车险欺诈检测的流程。
车险专家系统(下称专家系统)是一种基于车险领域知识的推理系统,具体来说,它能够利用车险专家的经验知识进行决策,由此判定案件的性质以达到预警的目的[25]。专家系统的特点在于其基于规则和推理,这使得它具备了良好的可解释性。但相对的,一旦规则触发的条件不充足或者得不到满足时,专家系统就很难得出有用的结果。倘若欺诈方对规则有所了解,就可以在犯罪过程中绕过这些规则的触发条件来规避专家系统的检测。因此,专家系统在欺诈检测的精度和准确度上都存在局限。
尽管如此,专家系统在车险欺诈检测中依然有着广泛的应用。通常来说,当车险案件进入核价核损阶段时,案件数据将通过接口传输到专家系统中进行检测。如图1所示,数据进入专家系统后首先根据数据类型进行分类,随后根据数据类别采取相应的计算准则,计算得到案件触发的风险因子集合,接着,将该案件触发的风险因子集合与规则的触发条件进行一一匹配,最终得到案件的反欺诈判别结果和触发的欺诈规则集合,并提示该案件最终的欺诈风险等级。
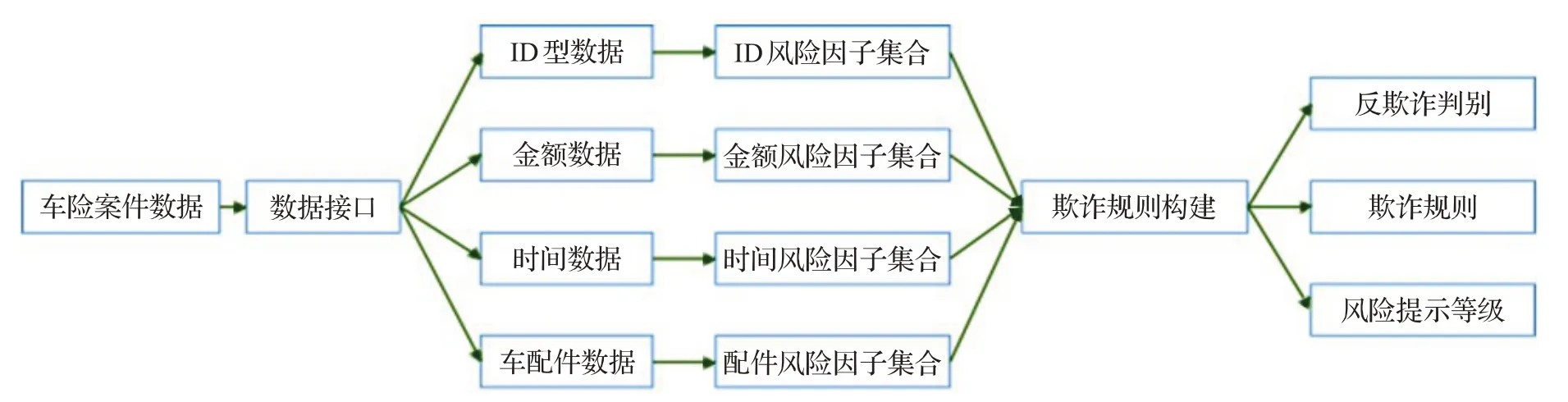
图1 专家系统车险欺诈检测流程图Fig.1 Diagram of expert system for auto insurance fraud detection
随着人工智能技术的发展,基于大数据的机器学习技术能够突破传统专家系统的局限,通过对被保险人、保险标的、出险情况等各方面数据进行收集和分析,为车险理赔提供了调查的方向。图2展示了构建智能理赔系统的5个步骤,包含数据需求、数据清洗、特征工程、超参数调优以及模型训练。
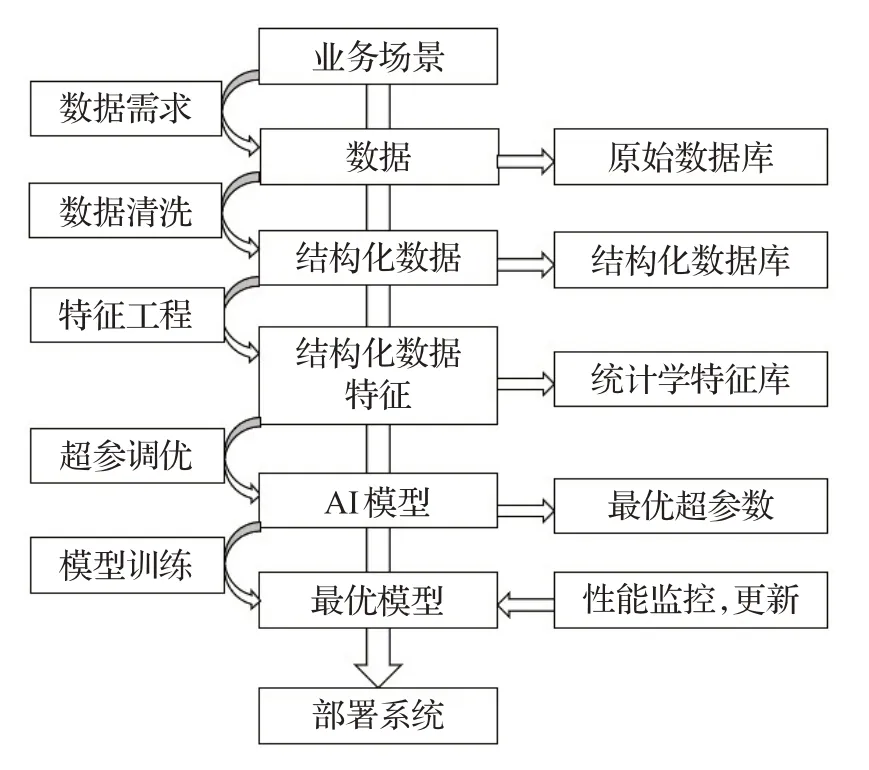
图2 智能理赔系统车险欺诈检测流程图Fig.2 Diagram of intelligent claim system for auto insurance fraud detection
(1)数据需求:根据车险业务场景提出数据需求,构建原始数据库。通常情况下,原始数据库中应包含报案、查勘、立案、定损、核价核损等多个重要环节数据。
(2)数据清洗:处理原始数据中可能存在的数据重复、数据格式不规范以及字段数据大量缺失等问题,并聚合清洗后的数据,将数据汇总至一张表中,形成结构化数据库。
(3)特征工程:采用手动/自动特征工程的方法处理结构化数据,包含时间类型数据处理、经纬度数据处理、离散型变量处理、特征交叉和选择等,最终生成统计学特征库。
(4)超参调优:基于标注好的训练数据,通过手动/自动超参优化方法优化机器学习模型参数,得到模型最优超参数设置。
(5)模型训练:采用最优超参训练模型,获得最优模型。需要注意的是,为了保证智能理赔系统的性能,在模型上线后,往往需要保持增量训练或定期更新模型。
2 机器学习模型在车险欺诈检测的研究进展及评述
2.1 国外研究进展
2.1.1 基于传统机器学习的方法
国外早期研究主要采用了一些传统的机器学习方法,目标是在车险欺诈检测数据中筛选出若干数据特征,从而根据这些特征构建车险欺诈检测的分类模型。基于贝叶斯模型的主要思路是利用贝叶斯分类的影响因子独立假设根据保险欺诈的因素构建分类器,最终推理得到保险欺诈的分类概率。基于该思想,Viaene等人[4]探索了具有自动确定相关性(automatic relevance determination,ARD)权重正则化项的神经网络分类器的显式能力,并将该网络应用于汽车保险索赔欺诈检测。该方案使用了一种基于贝叶斯学习的证据框架来实现ARD,从而确定每个输入的相对重要性,并剔除冗余特征。此外,作者通过和流行的Logistic和决策树算法得出的输入相对重要性进行比较,认为不同分类器具有互补的可能性,这符合现代贝叶斯学习在数据量有限时选择模型的方法。Bermúdez等人[26]将非对称链接函数的思想应用到保险欺诈领域,使用了一种有偏连接模型,假设模型参数服从某种先验分布进而通过贝叶斯估计和Gibbs采样来拟合。同时,作者在一个西班牙保险数据集上进行了实验,验证了该方法能显著提高保险欺诈检测的准确率。贝叶斯模型的局限性在于车险欺诈检测的特征通常具有复杂的关系,而无法满足相互独立的假设。此外,贝叶斯模型预测概率不够精确,通常只用于定性分析和特征选择。
基于聚类模型的主要思路是根据若干风险因素对车险案例进行划分,并得到可疑车险欺诈案例。基于该思想,Hanafizadeh等人[5]基于自组织映射和K-Means算法,提出了一种新颖的两阶段车险客户细分模型。在第一阶段,作者从文献综述中提取了人口统计学规范、汽车规范、政策规范和驾驶员记录4类18种不同的风险因素。在第二阶段,作者进一步利用专家意见来确定筛选过程。通过实证分析,作者发现保险公司的客户在很多方面都有所不同,而数据分析表明了基于历史数据和专家意见的最终选定因素对于区分客户的重要性。K-Means算法的性能取决于聚类簇的数量以及划分标准,在特征空间较大的情况下开销较大,因此在车险欺诈领域中应用依赖专家意见和人工筛选特征等过程。
基于数据挖掘的主要思路是从大量数据中找出隐藏的信息,主要通过统计学、模式识别等方法来进行有用信息的提炼。基于该思想,Bhowmik[27]分别提出了基于朴素贝叶斯、决策树以及产生式规则的欺诈检测方法,并借助可视化工具从实际车险数据中分析存在道德风险的可能性。同时,作者通过实证分析发现混淆矩阵具有很强的类倾斜性,是一个重要的欺诈检测领域的可靠性能指标。Kašćelan等人[6]基于数据挖掘技术找到现存风险和风险因子之间的功能依赖关系,继而帮助保险人评估风险和计算适当的保费。同时,作者通过实例分析验证了数据挖掘技术同样可以准确地预测索赔的规模和发生情况,从而为保费计算和风险分类提供了依据。在实例分析的过程,作者指出数据质量和合适的数据挖掘技术是该方法成功的前提条件。Yan等人[28]研究了数据挖掘技术在反车险欺诈中的应用。将基于规则剪枝的最近离群点检测方法应用于车险欺诈领域,建立了改进的车险欺诈识别模型,利用关联规则挖掘车险欺诈规律。实验结果表明,改进后的车险欺诈识别算法具有时间复杂度低、识别率高、准确率高、对聚类算法K值影响小等优点。Mihaela等人[29]通过对投保人年龄变量进行显著性分析,得出高欺诈风险人群特征。具体的,作者基于五个年龄区间构建了保费计算的负二项分布模型。在利用似然比对检验了泊松分布等假设后,实验结果表明负二项分布模型能更好地拟合数据,缓解保险组合中存在的过度分散现象。Nian等人[30]基于异常点检测的方法,提出了一种基于谱排序的异常保险样本检测方法,并发现谱优化问题可以解释为一个无监督支持向量机问题。作者通过利用拉普拉斯矩阵的非主特征向量来直接推导排序向量,从而找出异常的欺诈样本。同时,作者基于一个真实索赔数据集进行了实证分析。通过将该问题建模为无监督学习,基于海明距离及其核函数来生成该数据集的谱排序,并取得了良好的性能,此外,作者也表明为欺诈检测问题选择适当的相似度量的重要性。数据挖掘方法的特点是基于数据进行统计学分析,再利用机器学习模型实现车险欺诈检测的具体任务。因此,数据质量、统计建模以及模型选择等过程都会影响最终的预测结果。
基于K近邻算法的主要思路是给定车险欺诈数据的训练集,当新输入样本时分析该样本的最相似的K个实例,也就是K近邻的类别,把出现次数最多的类别作为新输入样本的类别。Badriyah等人[31]采用最近邻法和四分位数法检测车险数据中的欺诈行为。从实验结果来看,使用特征选择会提高检测欺诈的性能。具体的,作者采用基于距离的遗传算法进行特征选择,利用最近邻法进行欺诈检测。K近邻法应用于车险欺诈检测仍有较大的局限性,K比较小时对噪声数据非常敏感,容易过拟合;K比较大时,由于每个新输入数据作分类时都要遍历整个数据集,会造成巨大开销。
基于回归模型的主要思路是利用统计分析方法模拟风险因素的关系,继而得到保险欺诈因素之间的线性关系。Yan等人[32]提出了一种基于人工蜂群算法(artificial bee colony,ABC)的核岭回归算法(kernel ridge regression,KRR)——KRR-ABC,用于汽车保险欺诈检测。具体的,作者利用ABC算法的全局优化能力和良好的并行性对KRR的参数组合进行优化,提高了模型的泛化能力和计算速度。同时作者在8个基准数据集上对KRR-ABC模型的性能进行了测试,结果表明KRR-ABC模型具有更快的运行时间和更好的生成性能。将KRR-ABC模型应用于汽车保险欺诈检测,得到了欺诈规则。由于逻辑回归模型只能进行线性拟合,而且对变量相关性敏感,因此无法直接用于真实车险欺诈数据的检测,往往用来进行特征选择。
基于随机森林模型的主要思路是利用集成学习泛化性能强的优势来进行分类器之间的组合,以此来提升保险欺诈的判别效果。基于该思想,Xu等人[33]提出了一种基于随机粗糙子空间的神经网络集成方法用于保险欺诈检测。该方法利用粗糙集划分的子集分别基于真实保险数据训练一个神经网络分类器,并利用集成策略将训练好的神经网络分类器进行组合。为了验证该方法的有效性,作者进行了实证分析。实验结果表明,作者提出的集成模型优于单个分类器和其他模型,能够快速准确地发现可疑的保险欺诈行为。Li等人[7]从潜在最近邻的角度分析了随机森林的分类机制,用基于潜在最近邻的投票机制取代了多数投票机制,避免了出袋(out of bag,OOB)样本造成的信息丢失。在此基础上,提出了主成分分析转换方法,将数据转换到主成分分析空间,提高分类器的多样性,从而提高随机森林算法的整体分类精度。虽然随机森林无须进行特征选择也可以获得较强的拟合能力,但是组合分类器给模型建立和预测增加了代价。此外,随机森林的参数较传统机器学习更多,不易调节。
基于XGBoost的方法同样属于集成学习,但它不同于随机森林的弱分类器之间相对独立的关系,XGBoost算法以提升树为原理,模型的预测结果受上一次预测结果的影响。因此,该类方法相比随机森林有较差的并行性。然而,XGBoost的整体效率高于使用多棵树进行预测的随机森林。此外,XGBoost可以用于对连续型欺诈数据进行回归分析,而随机森林模型只能用于分类任务。Dhieb等人[34]将XGBoost应用于车险欺诈检测的批量学习,该算法不仅具有优越的计算速度和模型性能,还能解决跨学科问题。此外作者利用快速决策树(VFDT)实现在线学习,该策略在新数据进入系统时动态地调整参数,而不需要重新训练整个模型。
基于传统机器学习方法均是先采用特征工程的方式来筛选对保险或者车险欺诈的敏感特征,随后以各类机器学习模型为基础进行有效的改进,从而达到更好的检测结果。然而,上述方法仍会存在数据转换适应性方面的问题。同时,传统方法不易挖掘出汽车保险数据中隐藏的特征及其关联。
2.1.2 基于神经网络的方法
基于神经网络的车险欺诈检测方法主要集中在浅层神经网络、图神经网络以及深度学习。目前,国外相关研究工作主要聚焦在图神经网络与深度学习这两种类型。
基于图神经网络的主要思路是利用图结构可以更好地表示车险欺诈中多方主体之间的关系,并发现潜在的组织行为。基于该思想,Liang等人[35]在索赔者之间引入了一个设备共享网络,然后开发了一个基于图学习算法的欺诈检测自动化解决方案,以将诈骗者从常规客户中分离出来,并发现有组织的诈骗者群体。作者介绍了三种类型的图,并展示了它们通过图神经网络区分欺诈和正常行为的优势。经过人类专家调查,与之前部署的基于规则的分类器相比,该解决方案的准确率超过80%,可疑账户覆盖率增加44%。此外该模型可以简单有效地推广到其他类型的保险。Liu等人[36]针对欺诈者产生的不一致问题,即上下文不一致、特征不一致和关系不一致,设计了一个新颖的图神经框架GraphConsis,并分别设计了三种模块来解决不同的不一致性问题。具体来说:(1)对于上下文不一致性,将上下文嵌入与节点特征相结合;(2)对于特征不一致性,设计了一致性评分来过滤不一致的邻域并产生相应的采样概率;(3)对于关系不一致性,学习与抽样节点相关的关系注意权值。实验分析表明,各种模块所针对的不一致性问题在欺诈检测任务中扮演着至关重要的角色。图神经网络适合构建元素之间具有复杂拓扑关系的模型,车险欺诈中往往涉及多方主体,因此引入该方法可以学习到多方主体之间的潜在关系,从而用于预测。然而,图神经网络目前还不能保证收敛点的质量和实际预测效果。
基于深度学习的主要思路是利用深度学习的网络深度优势与对深度框架的改良来提高汽车保险欺诈的推理效果。基于此思想,Qu等人[37]提出了一种基于点积的神经网络(PNN),该神经网络通过嵌入层来学习分类数据的分布式表示,然后通过点积层来捕获域间类别之间的交互模式,进一步利用全连接层来探索高阶特征交互。Cheng等人[38]提出了深浅层学习框架(wide&deep learning,WDL),通过联合训练浅层线性模型和深度神经网络,将其记忆和泛化功能结合起来用于推荐系统。他们在Google Play上制作并评估了这个系统。在线实验结果显示,应用WDL比单独的浅层和深度模型显著增加了APP应用的购买量。Xiao等人[39]通过区分不同特征交互的重要性来改进FM。他们提出了一种新的模型,称为注意力因子分解机(AFM),该模型通过神经网络从数据中学习每个特征交互的重要性。在两个真实数据集上的大量实验证明了AFM的有效性。Wang等人[40]提出了深度交叉网络(DCN)保留了深度神经网络(DNN)的优点,并引入了一种新颖的交叉网络,在学习某些有界度特征交互时更有效。特别地,DCN显式地在每一层应用特征交叉,不需要手动进行特征工程,并且增加的复杂度可以忽略不计。实验结果表明,在点击率预测数据集和密集分类数据集上,该算法在模型精度和内存使用方面均优于现有的算法。Guo等人[41]证明了可以推导出一个同时强调低阶和高阶特征交互的端到端学习模型DeepFM。在新的神经网络架构中,DeepFM结合了分解机制和深度学习的能力分别用于推荐和特征学习。与深度学习模型Wide&Deep相比,DeepFM有一个共享的输入分别传输到浅层和深层,可以直接利用原始特征不需要特征工程。同时作者在基准数据和商业数据上进行了综合实验,验证了DeepFM对点击率预测的有效性。尽管上述模型只是深度学习模型在推荐任务上的应用,但两者关联非常紧密,可以将上述模型根据车险欺诈检测任务进行适配,并得到较为理想的效果(见3.2节测试模型与结果分析)。
近年来,由于深度学习模型无须进行繁琐的特征选择,并能够捕获文本中的特征之间隐藏的语义关系,不少学者开始将深度学习应用于车险欺诈检测,通过大量实证分析,深度学习模型往往优于传统机器学习模型。He等人[8]提出了一种用于稀疏预测的神经因子分解机(NFM)模型。NFM巧妙地结合了因子分解机(FM)在建模二阶特征交互中的线性和神经网络在建模高阶特征交互中的非线性。具体的说,作者通过添加隐藏层获得比FM更强的性能。相较于深度学习方法Wide&Deep和DeepCross而言,NFM使用了更浅的结构并保证了其性能,因此在实践中更容易训练和调整。Guo等人[9]提出了一种基于历史注意的交互式LSTM(HAInt-LSTM)循环神经网络来学习序列行为表示以进行欺诈检测。作者利用历史自注意模块解释了人类行为的周期性,并通过将源信息编码为一个交互模块,以增强行为序列的学习。通过结合历史自注意模块和交互模块,HAInt-LSTM在欺诈检测的序列行为表示学习、序列预测和序列分类等方面都取得了良好的性能。同时,作者在车险欺诈数据集上证明了该方法在欺诈检测任务上的优越性。Wang等人[10]提出了一种结合潜在狄利克雷分布(latent Dirichlet allocation,LDA)和深度学习的文本分析模型,并用于车险欺诈检测。该方法首先利用LDA提取事故索赔文本描述中隐藏的文本特征,利用深度神经网络训练文本特征和传统的数字特征。实验结果表明,深度神经网络的性能优于随机森林和支持向量机等广泛使用的机器学习模型。
基于神经网络方法更多是利用了神经网络较大的特征学习能力。不过,目前特征的选取仍是通过聚类、LDA无监督方式来进行训练筛选,并未涉及到端到端的模式。此外,基于深度学习的方法普遍依赖于大量训练数据,不利于小样本场景下的表示学习问题。特别是在车险欺诈领域,公开的有标签数据难以轻易获得,而标注任务也需要相当的专业知识。最近已经有学者将无监督深度学习用于保险欺诈检测,从而缓解数据对该任务的影响。Gomes等人[42]提出的方法结合无监督深度学习模型变分自编码器(VAE)和自编码器(AE)的能力,通过点击按钮进行周期性模型更新,持续学习用户行为的复杂变化。目前无监督深度学习方法分类精度有限,将更多应用于检测结果的质量评估、相似欺诈案例的推荐等场景。
2.1.3 基于混合模型的方法
目前基于混合模型的方法主要集中在将多个模型组合形成的系统框架,国外相关研究工作主要包括基于内在关联属性的方法以及其他的混合模型方法两种类型。
基于内在关联属性的主要思路是从实体因素之间的关系来进行建模,继而利用因素之间的网络关联来进行保险欺诈工作。基于该思想,Šubelj等人[25]提出了一种车险欺诈群体检测的专家系统,并对该系统进行了详细的描述和评估,同时考虑了检测欺诈的几个技术难点,以使其在实践中适用。与其他方法不同的是,该系统使用网络来表示数据,刻画和分析了实体之间的复杂关系。此外,作者还提出了一种新颖的迭代评估算法(iterative evaluation algorithm,IAA)来发现虚假实体。该算法除了研究实体的内在属性外,还研究了实体之间的关系,并根据真实世界数据进行了严格分析。结果表明,该系统在良好的数据表示的前提下,能够有效地检测出汽车保险欺诈行为。
其他混合模型算法的主要思路是将各个方法的优势进行融合。基于此思想,Subudhi等人[11]提出的车险欺诈检测系统为训练和欺诈检测两阶段。在训练阶段,结合遗传算法和模糊C聚类方法,在大多数类实例上生成具有最优集群中心的集群,从而识别出异常值和冗余数据点并删除,最终得到一个平衡的数据集,用于进一步的实验。在第二阶段对可疑样本进行验证,分别由四种不同的有监督学习方法DT、SVM、MLP和GMDH进行验证。作者在一个真实的汽车保险数据集上进行了实验,验证了该系统的有效性。Majhi等人[12]采用模糊C均值聚类方法进行聚类,并通过改进的鲸优化算法寻找给定数据集的全局最优解,进而提出了一个基于模糊聚类的保险欺诈检测系统。该方法首先采用模糊聚类方法去除离群点,对大部分样本数据集进行裁剪,然后使用CATBoost、决策树等先进的分类器对修改后的数据集进行分类。通过测量灵敏度、特异性和准确性等性能参数对分类器进行评价。
总的来说,国外对于保险欺诈检测领域的研究多采用组合分类器(如:随机森林),或较为前沿的深度学习模型(如:长短期记忆网络(LSTM)、图神经网络(GNN)。通过实证分析来进行模型的评价与改善,往往模型都能够达到较高的准确率与较强的泛化能力。从数据集的角度来看,这得益于国外的保险索赔数据具有更丰富的评价指标体系,从而为模型训练特征的选取提供了更多的保障。
2.2 国内研究进展
2.2.1 基于传统机器学习的方法
随着国内保险事业的兴趣,国内越来越多的学者也参与到保险欺诈与车险欺诈的研究中来。与国外类似,国内学者的车险欺诈研究早期仍以回归模型、聚类分析、数据挖掘等技术为主。
基于回归模型的主要思路是利用逻辑回归模型模拟风险因素的关系,继而得到保险欺诈与其他因素之间的关联关系。基于该思想,赵桂芹等人[16]为了探究车险市场中是否存在道德风险,作者首次采用动态续保数据进行实证研究。通过使用逻辑回归的参数方法和条件相关模型的非参数方法,从多个方面论证了道德风险存在的范围,并发现了道德风险在不同投保人群中具有不同显著性的现象。此外,作者再次验证了信息不对称的广泛性和显著性给道德风险带来的影响。张连增等人[43]基于国外保险索赔数据,通过逻辑回归模型分析了车险索赔的影响因素,并利用SAS软件对实验结果进行统计分析,得出汽车价值、地区、车型和驾驶员年龄都会影响车险索赔发生概率,并预测了概率数值。此外作者考虑到风险暴露对车险索赔造成的影响,通过引入风险暴露因子对模型进行了优化,从而扩展了逻辑模型在保险业的应用。
基于聚类模型的主要思路是根据若干风险因素对车险案例进行划分,并得到可疑欺诈案例。基于该思想,王海巍等人[18]利用一个保险运营的动态数据流,通过对投保、承保、理赔等关键环节的数据字段进行聚类分析,并建立数理模型观测、估计保险欺诈风险阈值,探索了保险实务中的道德风险识别问题。同时,作者基于实证分析提出了建立动态Hadoop模型进行风险因子聚类分析的必要性。
基于数据挖掘的主要思路是从大量数据中找出隐藏的信息,主要通过统计学、模式识别、大数据分析等方法对保险数据中特征关联进行提炼。基于该思想,汤俊等人[17]基于支持向量机和Apriori算法的数据挖掘技术,提出了一种新颖的车险欺诈检测规则挖掘方法。具体的说,作者利用Apriori算法挖掘到的规则构造了一个欺诈规律知识库,用于对支持向量机从历史数据库汇总挖掘出来的可疑案例进行再检验,从而提高车险欺诈检验的准确性。此外,作者建议周期性地对知识库中的规则进行维护更新以应对不断变化的车险欺诈行为。袁幕琴[44]基于我国保险欺诈的现状和主要表现形式,对保险欺诈的原因和危害进行了定性的分析研究工作,并结合大数据等现代信息技术提出了高效防范保险欺诈的对策建议,包括建设智能反欺诈模型、大数据分析优化承保、理赔规程等。卢文龙[45]基于保险欺诈案件的风险因子和大数据技术,提出了一个闭环式的保险欺诈循环处理系统,通过提炼出的风险因子建立数理识别模型,再将识别结果反馈来更新风险因子,从而构建出一个越来越完善的反欺诈模型。张澄等人[46]结合保险业个性化、定制化的发展趋势,使用大数据分析和“互联网+”技术实现风险管理的精细化和产品服务的定制化。具体的说,作者从位置大数据应用的角度出发,对手机定位的车辆位置信息在车险管理的应用问题进行探讨,并提出了一种新颖的地理区域网格化方法用于风险划分和计算。同时,作者针对生产应用中的承包端和理赔端分别给出模型实施路径和使用建议。
2.2.2 基于神经网络的方法
相比于国外学者的研究集中在浅层神经网络、图神经网络以及深度学习领域,国内相关研究工作主要集中在浅层神经网络。
基于浅层神经网络的主要思路是利用前馈神经网络来学习各个欺诈因素的权重,以此来提高保险欺诈的推理效果。基于此思想,叶明华[47]以保险欺诈行为中的车险索赔为例,对基于反向传播神经网络(BP神经网络)用于保证欺诈识别的有效性进行验证。作者将欺诈识别分为统计回归混合人工智能两个阶段,利用逻辑回归分析选出显著性指标作为精炼变量来进行训练的BP神经网络模型。通过实验验证了BP神经网络和统计回归方法融合的效果。通过实验结果验证了经过融合后方法的识别准确率要高于单独使用BP神经网络识别的结果,从而证明了统计回归与BP神经网络具有互补性和相互纠错性的理论。因此,作者指出提高神经网络识别效果的前提是完善索赔指标体系。为了克服BP神经网络容易陷入局部最优、收敛速度慢而且依赖样本等局限性,闫春等人[48]利用改进的遗传算法来优化基于BP神经网络的车险欺诈识别模型。首先通过主成分分析将某保险公司的欺诈索赔数据进行指标的提炼,将提炼后的指标用于模型欺诈预测。改进的遗传算法通过自适应调节交叉概率与变异概率,进一步提高了遗传算法的寻优能力,防止算法陷入局部最优。作者在实证分析中发现,改进的遗传算法与经典遗传算法GA、IAGA算法相比,取得了收敛速度、精准度等评价指标的性能提升。
近年来,少数学者开始尝试利用深度学习技术构建车险欺诈检测模型,相比浅层神经网络方法在效果上有明显改善。徐徐等人[20]基于深度学习构建了一个车险欺诈识别模型。具体的说,作者基于采样思想来转换不平衡数据集,同时采用主成分分析算法对车险数据进行降维处理并消除变量之间的相关性。通过实证分析,作者验证了深度学习模型相比传统机器学习模型在欺诈识别领域取得更好的效果。
2.2.3 基于混合模型的方法
基于混合模型的方法目前主要集中在将多个模型组合形成的系统框架,国内相关研究工作体现在基于内在关联属性以及其他的混合模型两种类型。
基于内在关联属性的主要思路是从实体因素之间的关系来进行建模,继而利用因素之间的网络关联来进行保险欺诈工作。基于该思想,赵长利等人[49]基于变分不等式理论和变步长投影算法,探索了投保人、保险人和保险监管者三方主体在车险行为中的最优均衡模式。不同于常规模型在探究此类问题上的局限性,其构建的风险控制闭环模型能够以定量的方式分析各方主体的决策行为和利益关系。通过数据分析,作者发现了汽车网络利润不均衡的特点,进而提出给予各方参与者一定的利润空间以实现各方利润最大化和风险控制。喻炜等人[1]针对车险欺诈检测问题,首次在该领域引入了团伙微观建模的概念,利用矩阵运算识别出可疑的车险欺诈团伙行为。同时,将可疑欺诈团伙的碰撞网络矩阵映射为人的网络关系,从而识别出人为规避行为。相比传统方法,矩阵数值运算省略了样本预处理、模型训练等步骤,极大提高了计算效率。
其他混合模型算法的主要思路是将各个方法的优势进行融合。基于此思想,闫春等人[19]提出了一种基于蚁群算法和随机森林模型的组合分类器来提取出用于车险欺诈识别的一组特征。作者用平衡随机森林算法来改善车险索赔数据的不平衡性,然后将特征在随机森林中的重要性得分与数据的统计分数传递给蚁群算法实现信息素实时更新,从而准确地提取出车险欺诈特征。和传统算法相比,该方法提高了车险欺诈识别的准确性与鲁棒性。
总的来说,国内的车险欺诈检测方法更倾向于使用传统机器学习模型,如逻辑回归、BP神经网络,并利用数据挖掘等技术建立统计模型,在深度学习与集成学习方面的研究并不突出。这可能是因为国内的风险评价体系尚未健全,很多学者利用爬虫技术自行收集的数据量级比较小,且数据中含有大量的噪音,导致数据质量不高,因此在一定程度无法满足深度学习训练条件,这大大制约了国内保险欺诈识别的性能和应用场景。
2.3 模型评述
在这一节中,将对常用的机器学习模型及其特点总结,如表1所示,其中贝叶斯分类中的C表示类别,x表示样本特征。逻辑回归模型中的w表示样本权重,b表示偏置。决策树模型通过计算信息增益Info(D)依次选择分类效果最好的属性,其中的i表示类别,D表示样本集合,Pi表示D中任意一个样本属于i的概率。K近邻中的函数I()根据括号中的参数是否相等返回1或0。另外,公式中出现的sign(·)函数的作用是根据参数和阈值的大小关系返回相应类别,σ(·)函数称为激活函数,和sign(·)函数的作用类似,区别是sign(·)函数的取值是离散的,而激活函数σ(·)的取值是连续值。集成学习中的h(x)表示弱分类器预测结果,H(x)综合这些结果得到强分类器的结果。除此以外,公式表中相同的符号有着相同或相似的含义。

表1 车险欺诈检测中机器学习模型的总结Table 1 Summary of machine learning models for auto fraud detection
贝叶斯分类器是以贝叶斯定理为基础的分类算法的总称,是基于样本分布已知的假设来选择最有可能的类别。与其他方法相比,贝叶斯分类器支持增量训练并实时调整概率值。此外由于假设特征之间相互独立而无须考虑特征组合,大大提高了大规模训练集的计算效率。然而,贝叶斯分类器对特征组合较为受限。逻辑回归模型实际上是用于二分类问题的分类模型,选择与实际输出值误差最小的类别作为预测标签。这种方法实现简单,易于理解,并且能够方便地根据新的数据更新模型,因而得到了广泛的应用。然而,当数据量或特征空间比较大导致线性不可分时,该模型也会因为过于简单而无法对数据进行较好的学习,从而体现出欠拟合、异常值敏感等问题。支持向量机通过核函数可以较好地解决非线性问题,能够提高模型的泛化性能,解决高维度数据的问题,但是方法本质受限于算法的复杂度(特别是核方法)无法处理大规模数据。决策树也是一种易于理解的白盒模型,它甚至不限制使用非数值型数据。但是决策树完全依赖数据,存在过拟合的风险。集成学习的思想是利用多个弱分类器组合成强分类器,从而提高预测精度,并且一些集成学习方法如随机森林实现了数据的并行化处理,提高了效率,但是组合学习器相比单学习器势必会增加更多的计算成本。神经网络通过前向传播来拟合数据,通过反向传播来更新参数,是一种自主学习器,但是浅层的神经网络往往因为有限的样本数量和参数数量而无法拟合复杂函数。与之相比,深度学习通过增加网络的参数量和数据的需求量来实现更复杂的功能,但是这也使硬件成本和数据标注成本大大提升。无论是浅层神经网络还是深度学习方法都是一个完全的黑箱模型,因为人类无法得知模型输入特征多对应的相对权重,因此较难给出对输出的结果进行合理的解释。从本文收集的各种机器学习模型的文献数量和发表时间来看,传统机器学习模型应用较早,但是研究成果不多,这反映出传统机器学习可能在特征选择、模型拟合等环节存在较大局限性;而近年来基于神经网络,特别是基于深度学习的方法以强大的表示能力和数据拟合能力开始广泛应用于车险欺诈检测。
总之,没有一种机器学习技术能在所有数据集上所有任务中优于其他技术,它们都有各自的模型特点与局限性。为此,在车险欺诈研究的过程中,诸多学者提出了相应的改进思路。
3 模型结果分析
3.1 测试数据集与评估标准
数据集选取真实生产环境下某车险保险公司降采样数据(由于正常保险公司欺诈概率在1%左右,本文收集的标注数据欺诈概率在接近20%,实际上降低了正常数据的样本,因此称之为降采样)。共11 350条,采集时间为2014-03—2019-08,采集案件主要集中在2019年。其中,非欺诈数据8 792条占数据总量的77.46%,欺诈数据2 558条占数据总量的22.54%。经数据清洗后,可用字段合计900项,包含类别型字段31项、数值型字段868项以及欺诈标签字段1项。
由于车险数据是一种有偏的样本数据,因此在数据划分时需维持原样本的标签分布。在此模型测试过程中,训练集、测试集分别占数据总量的80%和20%。其中,训练集数据共9 080条,含非欺诈数据7 036条、欺诈数据2 044条;测试集数据共2 270条,含非欺诈数据1 756条、欺诈数据514条。需要注意的是,对于深度学习模型,将从训练集中额外划分出20%的数据作为验证集以用于调整模型的超参数。
对于二分类问题,根据样本真实类别和对应模型预测结果的组合分为真正例(true positive,TP)、真负例(true negative,TN)、假正例(false positive,FP)、假负例(false negative,FN),如表2所示。
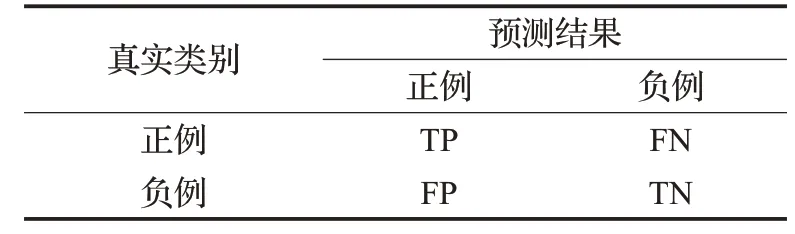
表2 分类样本混淆矩阵Table 2 Confusion matrix of classified sample
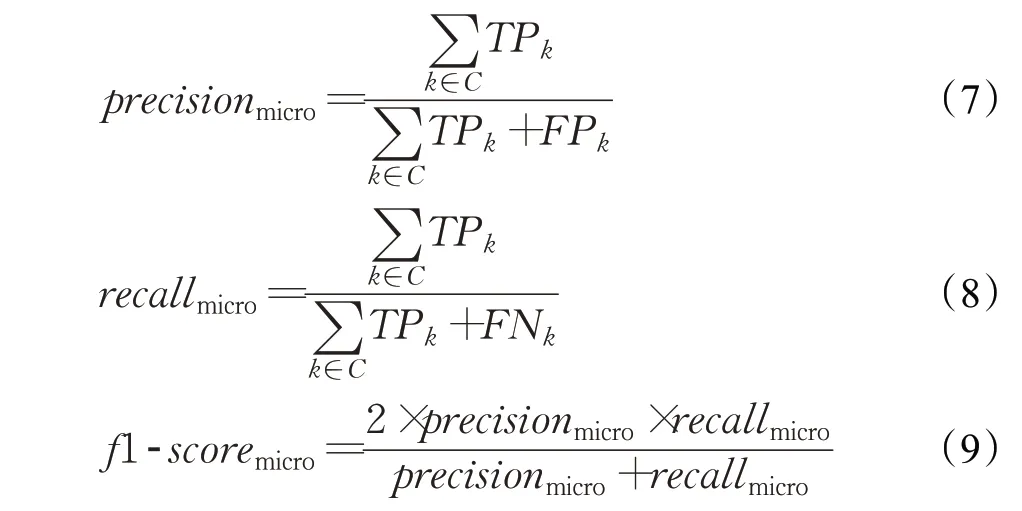
评估指标主要从精确率、召回率、F1-值、精度、AUC面积大小5种评估指标进行度量,以下分别对这5种指标进行描述。
Precision,又被称为精确率、查准率,是二分类任务中常用于评估模型预测结果是否精确的性能指标。精确率定义为真正例占所有预测结果为正例样本的比值,对应的公式为:

Recall,又被称为召回率、查全率,是二分类任务中常用于评估模型预测结果是否完备的性能指标。召回率定义为真正例占所有真实类别为正例样本的比值,对应的公式为:

F1-score,又被称为F1度量,它是在精确率和召回率的基础上取调和平均数得到,对应的公式为:

Accuracy,又被称为精度,定义为分类正确的样本占样本总数的比值,对应的公式为:

AUC(area under ROC curve),AUC是二分类任务中用于评估模型泛化性能的指标,它的定义是ROC(receiver operating characteristic)曲线下的区域面积。ROC曲线按照模型的预测结果逐个对样本进行排序,并分别以真正例率和假正例率为纵轴和横轴绘制在二维坐标系上形成一条曲线。其中真正例率(true positive rate,TPR)和假正例率(false positive rate,FPR)公式为:

通常使用曲线下区域面积AUC来进行比较,如图3所示。该性能指标可以在数据不平衡的数据集上进行客观的评估。
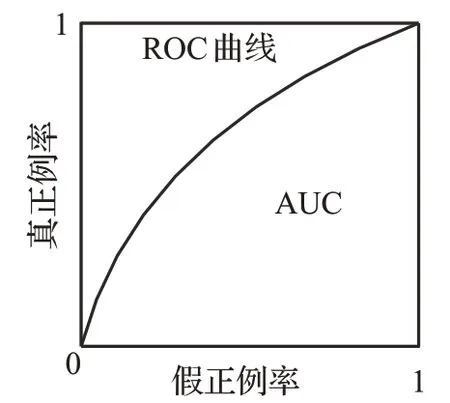
图3 AUC示意图Fig.3 Diagram of AUC
此外,为了分析欺诈模型在多分类上的效果,进一步将数据的标签细分为9个标签(为了保证多分类模型的训练效果,在欺诈标签类型细分时,会将少量原因不明欺诈数据视为正常数据处理),并保持实验的训练测试比例不变。具体的细分标签为:非欺诈标签(8 892),人工标记欺诈(1 302),倒签单(7),痕迹不符(928),酒驾(131),虚假报案(9),隐瞒事故真相(60),重复索赔(12),准驾异常(5)。
相应的,实验采用了多分类的评价指标,分别使用了Precision、Recall、F1-score对应的微平均(Micro)、宏平均(Macro)和带权平均(Weighted)的评估方式。
Micro形式的评价指标不关注样本类别,直接评估全体样本的分类效果。以precision为例,将所有类的TP加和,再除以所有类的TP和FN的加和。Micro形式下的precision、recall、accuracy相等。
Macro形式的评价指标首先分别求出每个类的对应值,再求算术平均。

Weighted形式是在Macro形式上的改进,对各类的结果值不再取算术平均,而是乘以该类在总样本数中的占比作为权重。
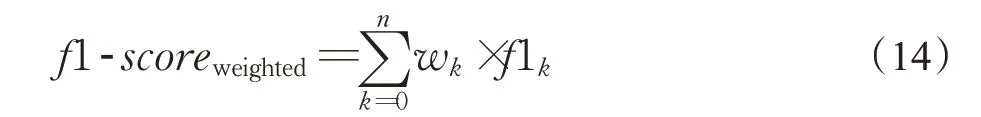
3.2 测试模型与结果分析
在Linux操作系统上(16核的Inter Xeon 2.99 GHz CPU,内存16 GB)进行了仿真实验,采用编程语言为Python 3.7,并基于sklearn库、xgboost库和deepCTRtorch库实例化测试模型。深度学习模型均选择自适应梯度算法(adaptive gradient algorithm)作为优化函数,设定学习率为0.01、批量采样的大小batch_size为32,周期epochs选择对应验证集梯度最小的参数值。需要注意的是,在未说明的情况下,输入数据中类别型数据默认采用标签编码(label encoding)的方式处理。
为了全面地评估现有机器学习模型的效果,一共选择了7类传统机器学习模型(含变种)以及6种深度学习模型进行测试和分析,具体列出如下:
贝叶斯网络,为经典的机器学习模型,基于特征间强独立假设和贝叶斯定理,车险数据特征大多离散分布,适用于二分类或者多分类任务建模,其中模型的先验平滑因子alpha=1.0。
逻辑回归,为经典的机器学习模型,基于概率论,通过极大似然模型求解参数以实现未知数据的欺诈检测,其中模型的惩罚参数penalty=l2,最大迭代次数
max_iter=100。
SVM(线性),为经典的机器学习模型,基于几何间隔最大化原理,以找出最大几何间隔的分类面为优化目标,其中模型的正则化参数penalty=l2,模型的损失函数为平方合页损失(squared_hinge)。
SVM(非线性),为SVM的核方法,适用于数据线性不可分的情况,通过核函数将数据映射到高维空间直到线性可分,其中模型选取的核为径向基函数(RBF)。
随机森林,属于机器学习中集成学习范畴,是一个由多个决策树构成的组合分类器,决策树之间无依赖关系,其中基评估器的数量为100个。
Xgboost,属于机器学习中集成学习范畴,是一个由多个分类回归树构成的组合分类器,分类回归树之间存在强依赖关系,其中目标函数分别采用binary:logistic(二分类)和multi:softprob(多分类)。
Xgboost(one-hot),为Xgboost的变种,主要是对输入数据中类别型数据采用one-hot encoding处理,其中目标函数同样采用binary:logistic(二分类)和multi:softprob(多分类)。
PNN,为基于点积的神经网络,属于深度学习模型。相较于传统的MLP模型,PNN通过嵌入层来学习分类数据的分布式表示,然后通过点积层来捕获域间类别之间的交互模式,进一步利用全连接层来探索高阶特征交互,其中隐藏层层数为2层,神经元数量均为128个,激活函数为relu,核的类型为mat。
WDL,为深浅层学习框架,属于深度学习模型。WDL通过结合线性模型和深度模型,保证了记忆与泛化的优点,同时采用联合训练(joint training)的方法进行优化。其中隐藏层层数为2层,神经元数量分别为256和128个,激活函数为relu。
DeepFM,为深度的因子分解机,属于深度学习模型。DeepFM结合了分解机制和深度学习的能力分别用于推荐和特征学习,它改进了WDL模型的Wide部分,将LR替换FM(因子分解机),以实现自动构造二阶特征,其中隐藏层层数为2层,神经元数量分别为256和128个,激活函数为relu。
DCN,为深度交叉网络,属于深度学习模型。它改进了WDL模型的Wide部分,DCN能够显式地在每一层应用特征交叉,自动构造有限高阶的交叉特征并学习对应权重,其中隐藏层层数为2层,神经元数量均为128个,激活函数为relu。
NFM,为神经因子分解机,属于深度学习模型。改进了WDL模型的Deep部分,NFM将FM的二阶交叉项作为Deep模型的输入,通过添加隐藏层获更强的性能,其中隐藏层层数为2层,神经元数量均为128个,激活函数为relu。
AFM,为注意力因子分解机,属于深度学习模型。改进了WDL模型的Deep部分,加入注意力机制区分不同交叉特征的重要性,其中激活函数为relu,attention network的隐藏层大小设置为8层。
表3列出了上述机器学习模型在车险欺诈中的整体实验结果。可以发现基于集成学习Xgboost及其变种Xgboost(one-hot)模型与基于深度学习的模型效果较好,特别在F1-score、Accuracy、AUC均超过传统的机器学习模型。Xgboost及其变种Xgboost(one-hot)在F1值与AUC上取得了最佳的效果,认为主要是受益于数据特征的提炼以及集成学习自身较强的泛化能力。相对的,在深度学习模型中,DCN的效果最佳,得益于它在改进部分深度学习模型(如:WDL)对于深度模块的建模方式。由于深度学习模型受限于现有数据规模,无法进一步从海量的特征中进行隐形特征的学习,因此效果较Xgboost略差。此外,发现贝叶斯网络和SVM-核方法分别在Recall和Precision取得了最佳效果。从侧面可以发现,这两类模型在车险欺诈检测任务中表现得较为极端。贝叶斯网络尽管可以发现更多的车险欺诈案例,但对应的也会误判部分正常的车险理赔案件,因为其正确率较低,这将会给公司校对人员带来更大的现场勘测成本。而SVM-核方法过于保守,尽管不会将正常的车险理赔案件误判,但也很难对真实的车险欺诈案件进行有效检测,因此难以达到实现车险欺诈检测的目的。
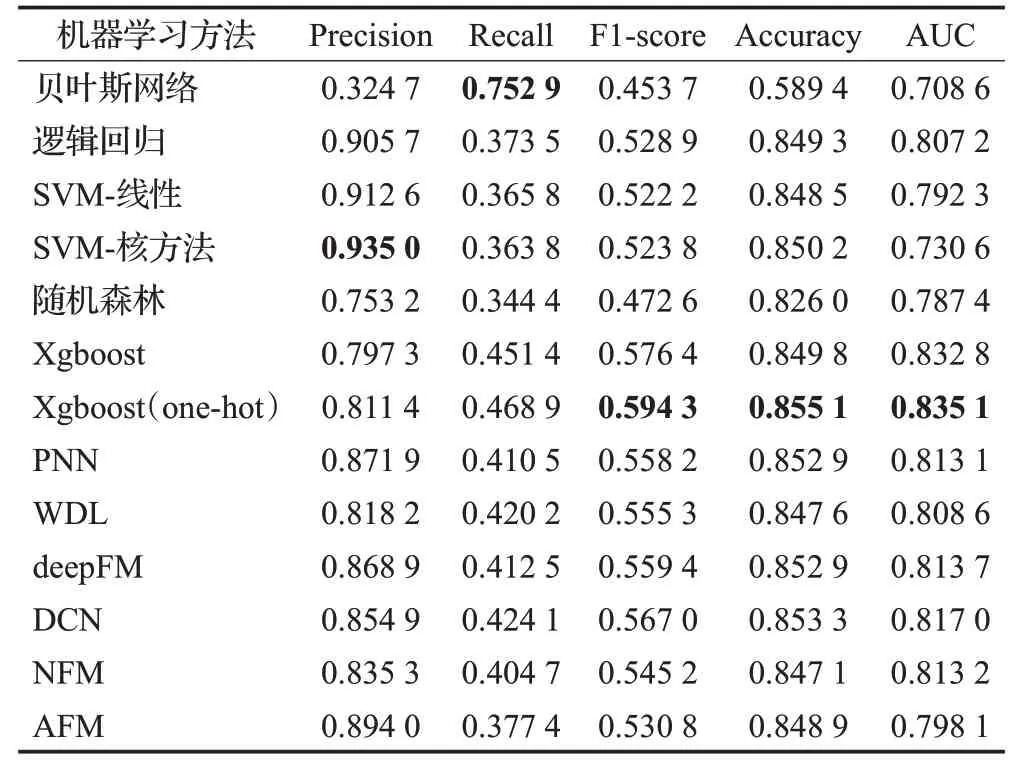
表3 车险欺诈检测整体的实验结果Table 3 Whole experiment result of auto fraud detection
考虑到车险欺诈数据在真实场景中存在客观的不均衡性,进一步检测了不同幅度下数据不均衡对各模型的影响。具体来说,将训练集中标注为“欺诈”的训练样例进行随机移除,同时保证正常的车险理赔案件数量不变,由此对训练数据集中的不均衡性进行调整。数据不均衡对各类机器学习模型的影响如表4所示。可以发现,大部分模型的性能都出现了不同程度的下降趋势。整体而言,Xgboost及其变种Xgboost(one-hot)依然能在各种数据不均衡的车险欺诈检测任务中获得最佳效果。受益于one-hot的建模效果Xgboost(one-hot)在比例减少时,性能上甚至存在着一定程度的反弹。分析认为,可能在于该批移除的车险欺诈的数据存在部分噪声,使得模型学习剩余数据的效果反而得到了提升。整体来说,随着数据不均衡的加剧,Xgboost(one-hot)仍会出现性能下降的趋势。此外,大部分深度学习模型在车险欺诈任务的性能上也会有不同程度的下降。尽管如此,在性能的损失方面,除了NFM与DCN之外,其他的深度模型下降的幅度只有1.5%左右,这在一定程度凸显出了这些模型能较好地学习到数据的隐性特征。
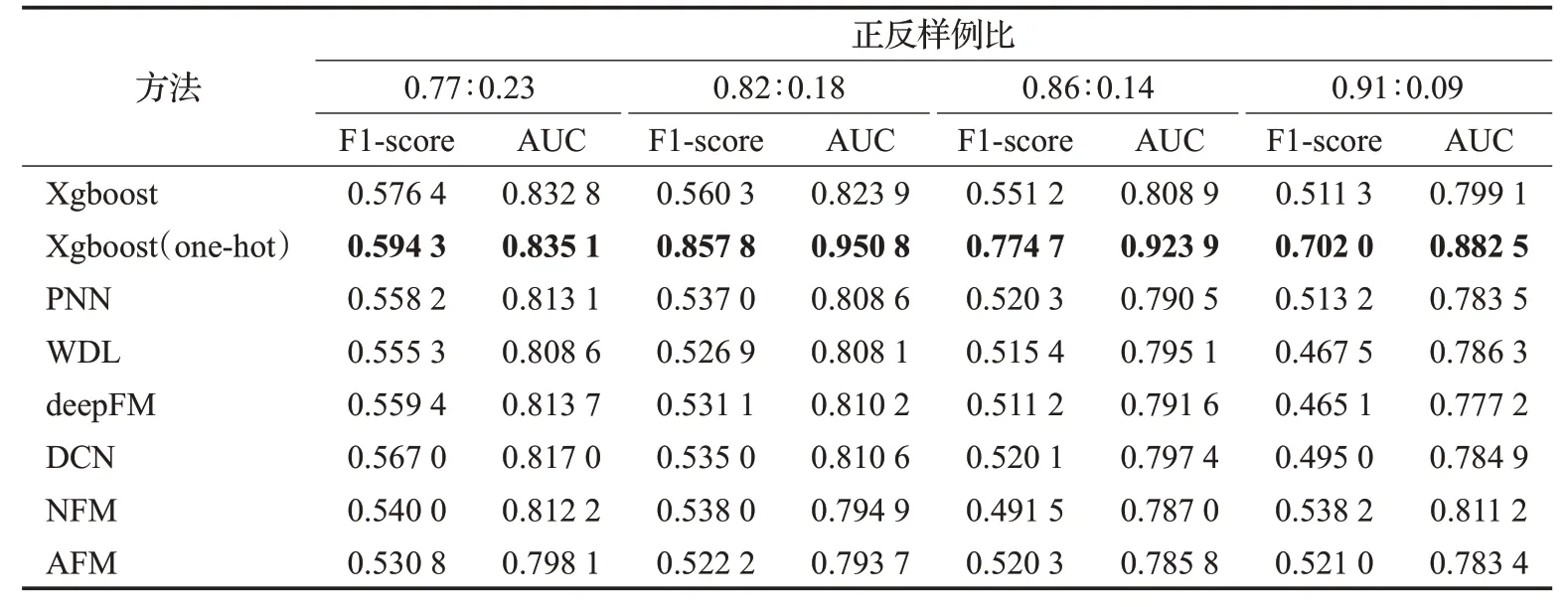
表4 数据不均衡对各模型的影响Table 4 Influence of data imbalance on each model
为了进一步验证训练数据规模对各模型的影响,对整体的训练集进行了等比例的缩放,并保证测试集不变。表5列出了不同百分比数据集对模型性能的影响。可以发现,即便在整体训练规模只有原训练集的50%时,Xgboost及其变种Xgboost(one-hot)依然能在车险欺诈检测任务上获得最佳的效果,综合F1-score和AUC的评分情况,可以发现Xgboost及其变种Xgboost(one-hot)在性能上均处于前2名。从图4中,可以观察到其在取值上整体高出了深度学习模型1.5%~2.0%。相对的,大部分深度学习模型在车险欺诈任务的性能都有不同程度的下降。此外,在性能损失方面,即便只有50%的训练数据,Xgboost及其变种Xgboost(one-hot)在F1-score与AUC的评分上只有2%左右的下降,在一定程度凸显出了它们的泛化能力。
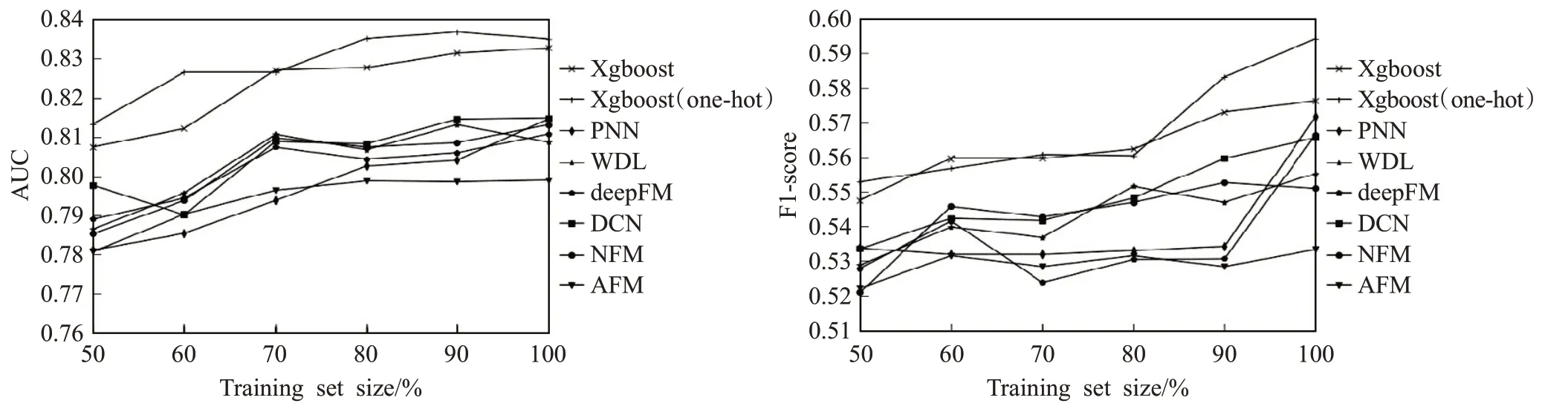
图4 不同训练百分比数据集中模型性能的趋势图Fig.4 Trend graph of model performance in data sets with different training percentage
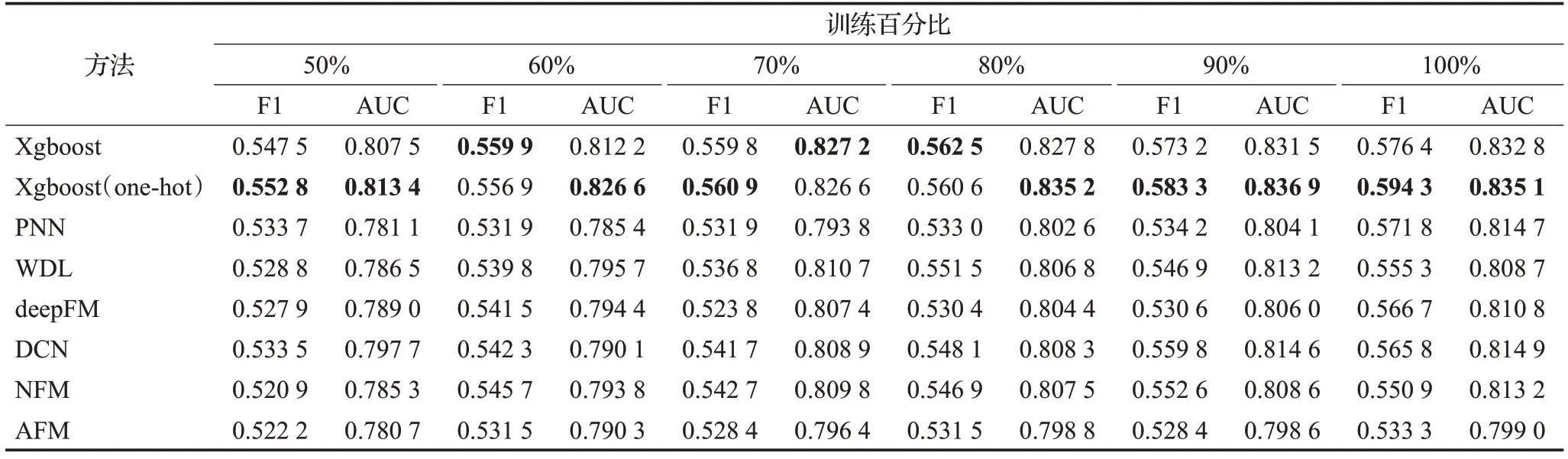
表5 训练百分比对各模型的影响Table 5 Influence of training percentage on each model
表6给出的是机器学习模型在多分类任务中评估的结果。整体上,可以看到在三项评估中,Xgboost(one-hot)依然在Micro形式与Weighted形式上较传统的机器学习方法与深度学习方法有着更加出色的效果。贝叶斯网络与Xgboost分别在Macro形式的Recall与Weighted形式的Precision上获得了最佳的效果。而深度学习模型整体表现非常一般,其效果甚至只能与逻辑回归模型的结果相当。经过对数据集的分析,发现深度学习模型主要还是受限于数据规模的影响。此外,在Macro评估方式中,可以发现所有的模型在Precision、Recall、F1-Score的表现都不如人意,特别是在虚假报案、隐瞒事故真相、重复索赔、准驾异常、倒签单这些样本不足100的分类标签上。通过表7中的实验结果,进一步证实了,绝大多数的模型是无法对一些稀疏样本的欺诈数据进行学习与区分的。因此,以算术平均为基础的Macro评估则会给出一个整体较差的结果。相对来说,传统的机器学习模型在这些少样本的分类任务上能取得的效果比深度学习模型的效果略好一些。
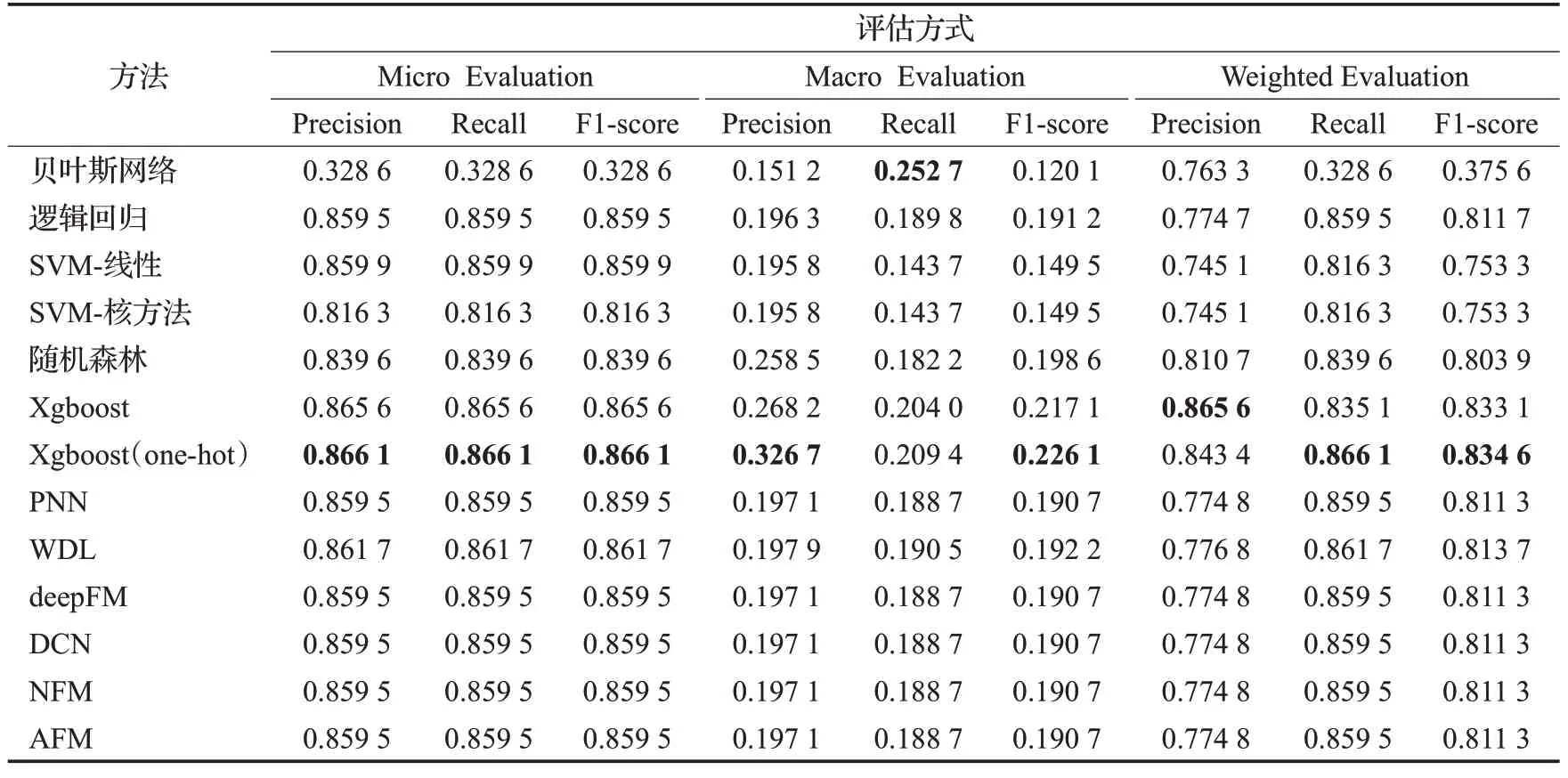
表6 机器学习模型在多分类任务中的评估结果Table 6 Evaluation results of ML models in multi-classification tasks
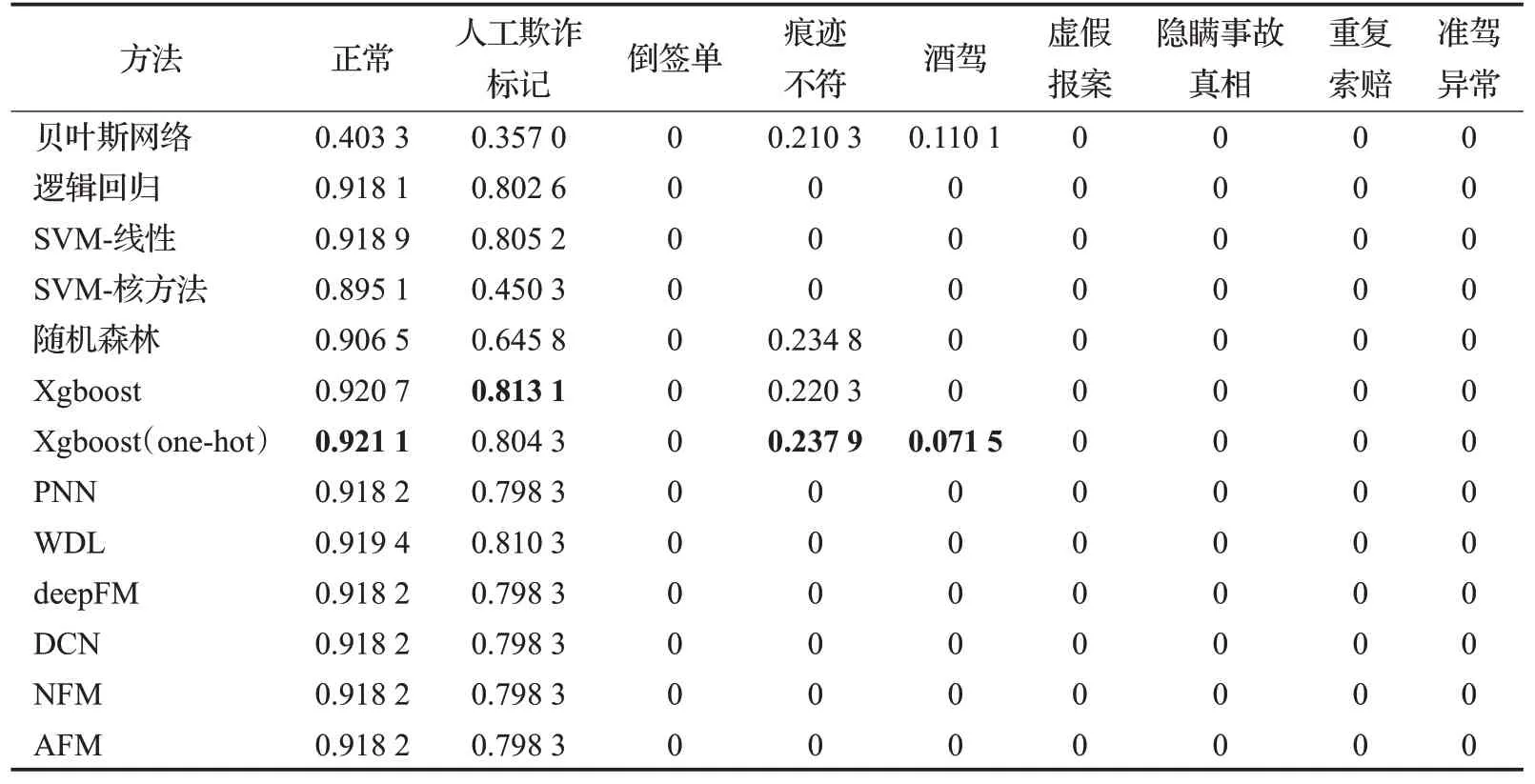
表7 机器学习在不同类别中F1的实验结果Table 7 Experimental results of F1 of ML models in different categories
根据目前车险公司提供的数据表明,在车险欺诈检测任务中,集成学习的效果与深度学习效果较传统机器学习模型效果更好。一方面,集成学习和传统的机器学习模型对硬件要求较低,而深度学习对硬件普遍具有较高的要求。另一方面,深度学习在保险欺诈检测任务中具备较好的效果,基于深度学习的思想可以学到潜在的特征表示,且标注数据规模越大越有效。相对的,传统的机器学习模型与集成学习模型对数据的特征提取存在较高的要求。
4 总结与展望
本文重点对机器学习模型在车险欺诈检测的研究进展进行全面细致的归纳与总结,基于车险公司真实的数据对各类机器学习模型进行全面测试与分析。实验结果表明,在车险欺诈的任务中,集成学习与深度学习模型较传统机器学习模型效果更好。相对的,集成学习需要对数据特征的提取存在较高的要求,而深度学习则对模型实现的硬件环境与数据集规模具有较大的需求。
经过对国内现有保险数据进行综合分析,认为将来车险欺诈检测的研究可以从以下五方面进行展开:
(1)基于小样本学习的欺诈检测技术。目前机器学习的模型在常规的二分类任务上表现较为满意。然而,对于多分类任务,可以发现当下的机器学习模型无法胜任这些欺诈类别中样本极度稀疏的分类工作。为此,可以将小样本学习(few-shot learning)[50-51]的前沿技术进行引入到车险欺诈的多分类任务中,以此来提高多种车险欺诈类型的检测性能。
(2)基于图谱的团伙检测技术。目前车险欺诈团伙犯罪的趋势较为明显,未来车险欺诈检测可以从团伙车险欺诈检测[52]入手,结合知识图谱[53]与事件图谱[54]等方法中实体关联,利用知识图谱或事件图谱表示学习中连续、稠密的向量表示来预测对案件因子之间内在的关联与案件之间的因果联系,从而将案件相关信息和相似案件信息进行深度结合,以此来提高欺诈检测的效果。
(3)基于表示学习的案因回溯检测技术。目前机器学习模型尽管表现效果较好,但仍存在解释匮乏的问题。而专家系统中的规则表达方式可以较好地弥补这一点。为此,可以对专家系统中的触发因子与机器学习和深度学习的向量表示进行关联,利用机器学习中各因子所在模型中所对应的权重以及深度学习所学习得到的向量表示来评估触发规则的概率,即便专家系统中的触发规则并未触发,但仍可以通过规则中相应的触发因子以及因子权重获得最可能的规则推送给专家,继而利用案因回溯的思想[55-56]给保险公司现场勘测人员提供有效的线索,提升勘测人员去现场确认的成功率。
(4)融合文本、图像的多模态检测技术。目前的机器学习模型更多地围绕车险欺诈拟定的指标体系从数据集库数据中抽取与提炼核心的特征,但对于文本(勘测记录的文字描述)以及图像数据(如:现场勘测拍摄的图片)的信息利用并不成熟。利用多模态技术[57-58]提高车险欺诈的检测精度将是未来的一个重要的研究方向。一方面,可以利用自然语言处理中的关系抽取技术、事件抽取技术从勘测记录中得到更多有用的结构化信息;另一方面,利用图像中的场景识别技术与匹配技术,可以有效地辨识案件中是否存在车险欺诈常用的场景,继而提高车险欺诈检测整体的效果。
(5)基于车险体系的联邦学习技术。由于目前车险欺诈领域高质量的标注数据存在不均衡现象,细粒度的欺诈标注数据集十分稀缺。为此,可以通过各保险公司协商,基于知识对齐技术[59]形成一套统一的车险规范体系[60],再进一步利用联邦学习技术[61-62]将保险公司中高质量的标注数据进行数据加密共享,最终,借助外部的高质量数据来提升模型学习的效果,继而提高车险欺诈检测的性能。
猜你喜欢
眼科新进展(2023年9期)2023-08-31 07:18:36
眼科新进展(2022年12期)2022-12-29 06:00:50
成都信息工程大学学报(2021年3期)2021-11-22 07:17:44
装备制造技术(2021年1期)2021-05-21 07:55:08
电子制作(2019年19期)2019-11-23 08:42:00
中国外汇(2019年10期)2019-08-27 01:58:04
公民与法治(2016年24期)2016-05-17 04:21:39
重型机械(2016年1期)2016-03-01 03:42:04
大连工业大学学报(2015年4期)2015-12-11 04:06:52
中国证券期货(2015年6期)2015-06-16 10:17:29
