
基于MD&A文本和深度学习模型的财务报告舞弊识别
2022-04-03 01:25赵纳晖张天洋
会计之友 2022年8期
赵纳晖 张天洋




【摘 要】 财务报告舞弊是企业舞弊的手段之一,不仅会导致会计信息失真,而且会危害经济的健康发展,因此,如何克服传统的人工检测和基于数值指标的浅层模型识别等方法的弊端,找到一种更为高效的智能化识别方法具有重要的现实意义。选取2015—2019年间存在舞弊行为的A股上市公司定期报告,以其中的管理层讨论与分析章节(Management Discussion and Analysis,MD&A)为样本,同时确定了规模相同的控制样本,通过实证研究对比了深度学习模型和以往常用的浅层模型在检测财务报告舞弊时的性能。结果表明,在规模对等的舞弊和非舞弊类财务报告组成的文本数据集上,深度学习模型表现出明显优于基准模型的分类性能。研究结果为利用MD&A文本数据和深度学习方法识别企业财务报告舞弊的有效性提供了直接的证据。
【关键词】 财务报告舞弊识别; 管理层讨论与分析; 文本数据; 深度学习; 卷积神经网络
【中图分类号】 F239.1 【文献标识码】 A 【文章编号】 1004-5937(2022)08-0140-10
一、引言
由于财务舞弊可能引发严重的经济和社会问题,有效识别舞弊成为会计和财务领域的研究热点。财务报告舞弊因其发生频率相对较低,且通常由行业内具有丰富知识和从业经验的人实施,企业很容易掩盖这类舞弊行为。
2021年《关于依法从严打击证券违法活动的意见》提出,要依法严厉查处证券违法犯罪案件,加强诚信约束惩戒,强化震慑效应。上市公司财务报告舞弊现象,严重削弱了财务报告本身的风险预警作用。相较于耗时且昂贵的人工检测方式,开展效率更高的自动化和智能化检测已成为财务报告舞弊识别研究的关键问题。早期关于财务报告舞弊智能化识别的研究大多利用各类会计和财务指标预测企业的舞弊行为,而现实的金融市场中充斥着各种复杂的模式,仅靠一些数值指标构建的识别模型,其预测性能是相对局限的。因此,之后的研究开始逐步重视文本信息对于识别财务舞弊的作用,相当数量的研究也已证实利用定期报告中的管理层讨论与分析章节(Management Discussion and Analysis,MD&A)能够发掘部分财务报告舞弊现象[1]。
在已有研究中,利用机器学习模型对文本数据进行分类预测的方法较为流行。但传统的机器学习模型,也称“浅层模型”,在处理文本信息时需要借助先验知识人工提取样本特征,这种方式对数据含义的表达能力较弱。为了充分利用文本数据的价值,对能够更高效地提取和利用文本信息算法的需求愈加强烈。深度学习模型作为机器学习的另一种范式,能够自动实现特征的多次提取和变换,以实现数据更高层次的抽象表示,从而弥补了浅层模型的不足[2]。
基于此,本文采用了一种字符级卷积神经网络[3]的深度学习算法,并结合上市公司定期报告中的MD&A文本,构建了识别财务报告舞弊的智能化模型。研究收集了2015—2019年的上市公司舞弊样本以及同样规模的控制样本,利用词嵌入层将MD&A中的文本转换为特征矩阵,以识别具有舞弊性质的财务报告。同时,为了比较不同模型的预测性能,研究还选取了部分统计学模型和浅层模型作为基准模型。结果表明,深度学习模型利用MD&A文本识别上市公司财务报告舞弊的性能明显优于基准模型。本文的贡献在于,不同于以往基于浅层模型的研究,本文引入了人工智能领域兴起的深度学习技术,以构建检测舞弊的智能化模型;此外,研究还证明了财务报告这种可得性和可靠性更强的文本数据同样具备识别企业舞弊行为的价值,可以为舞弊识别及相关研究提供新的数据支持。
二、文献综述
早期针对财务报告舞弊识别的研究集中在对舞弊影响因素和信号的识别上,并利用统计学模型发现违规披露行为[4],但这种方法取得的成果相当有限,可能和在选取与舞弊相关的财务指标时存在一定的主观性有关。之后,数据挖掘和机器学习等智能化模型的应用成为舞弊识别研究的一个新趋势。与统计学方法相比,智能化识别模型对数据的假设更少,且支持非线性决策,这些特征提高了模型的可塑性和分类性能,也使得此类模型很快得到了广泛的应用[5]。
起初的智能化模型普遍采用数值指标,其样本属性有限,且选取过程存在较强的主观性,严重限制了模型的预测性能。因此,研究人员开始更多地关注文本这类具有复杂性和隐藏性的非结构化数据,通过提取文本的特征以判断它们是否能够作为识别财务报告舞弊的信息来源[6]。由于财务报告的MD&A部分由企业的管理团队使用通用且正式的商业语言编辑而成,涵盖了对企业的财务状况、经营成果和前瞻性声明等内容的讨论,也被大多数研究用作识别财务报告舞弊的文本来源[7]。本章节之后的内容主要讨论基于数值和文本數据以及各类智能化模型识别财务报告舞弊的研究。
(一)基于数值数据的智能化财务报告舞弊识别
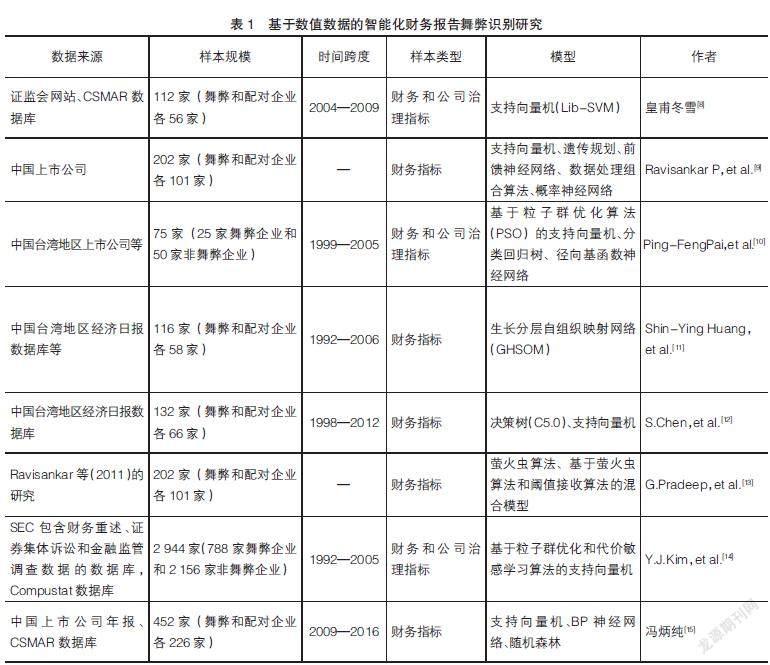
目前基于数值数据的智能化财务报告舞弊识别模型主要基于浅层模型和数据挖掘模型构建,包括神经网络、决策树、随机森林、进化算法、支持向量机和混合方法等。
神经网络主要涉及BP神经网络、概率神经网络、数据处理组合算法、径向基函数神经网络和生长分层自组织映射网络。决策树包括单个决策树和决策树的集合,如随机森林。尽管决策树和随机森林模型可以处理舞弊检测问题中的非线性特征,但训练过程中容易出现过拟合的问题,即识别模型的泛化性能普遍较差。进化算法(如遗传规划和萤火虫算法)也被用于辅助决策树模型的设计和训练。支持向量机能够通过线性分类的方式解决财务报告舞弊识别这一复杂的非线性问题,而不需要增加计算的复杂度。然而,在处理噪声较多的数据集时,支持向量机可能表现出性能不佳的问题。混合方法是利用多种模型的优势组合而成的新模型,在针对特定的问题域时能够表现出优于单个模型的分类性能。表1按照时间顺序总结了基于数值数据实现智能化财务报告舞弊识别的研究。
(二)基于文本数据的财务报告舞弊智能化识别
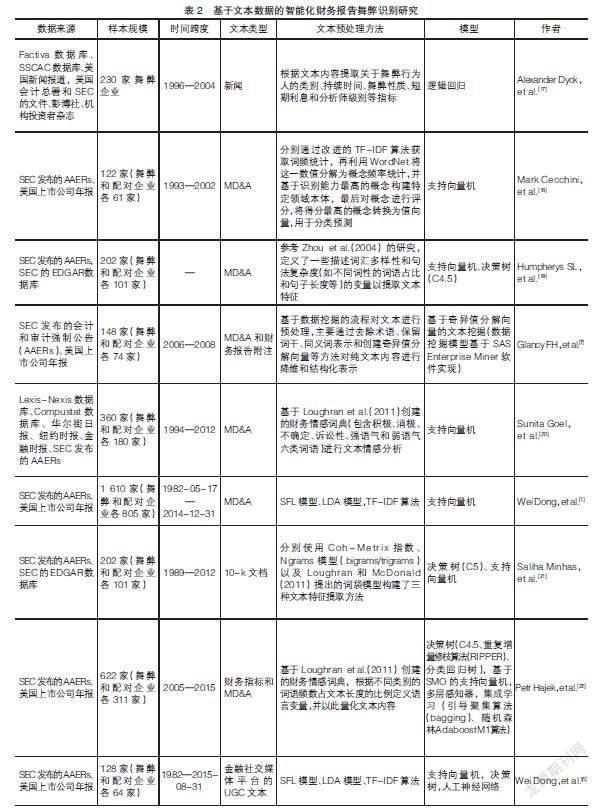
目前研究所采用的文本主要包括企业披露的定期报告、新闻、金融社交媒体平台的用户生成内容(User-Generated Content,UGC)以及各类利益相关者提出的关于企业经营情况以及公开披露信息的分析和讨论等。其中,新闻、社交媒体和各类利益相关者产生的数据包含较多噪音,而企业披露的定期报告则具有更易于处理的结构和更可靠的来源,且其中包含很多具有误导性陈述的语言变量可以作为识别企业舞弊的依据,因而被很多研究用作识别财务报告舞弊的直接证据[16]。
在利用文本识别舞弊性的财务报告时,需要对文本数据进行预处理。由于浅层模型不进行或只进行一次特征选择的局限,必须借助有效的文本表示方法单独提取文本特征,以保证下游模型的识别性能。目前研究中应用的文本表示方法大致可以分为两类:第一类是对某些关键词、关键词元组或词汇和句子特征等的统计描述。例如文本的情感分析,利用语言模型构建的文本分析框架和基于词汇多样性和句法复杂度等语言特征实现对文本数据的量化处理等。第二类是基于某类算法实现特定的文本格式。主要的算法类别有:(1)词袋模型,即一种预先定义的单词列表,能够表示财务报告的负面性、不确定性和诉讼性的单词列表通常与企业的舞弊行为之间存在关联;(2)主题模型,例如LDA(Latent Dirichlet Allocation)模型,在企业舞弊的研究中常被用来提取财务报告的语义主题;(3)TF-IDF(Term Frequency-Inverse Document Frequency)算法,该算法能够实现词语级的文本特征提取,并基于词语权重形成的词向量集合表示文本集合。表2按照时间顺序总结了基于文本数据实现智能化财务报告舞弊识别的研究。
(三)文献评述
在对已有文献的综述中,有三点内容值得关注。首先,大多数研究运用的智能化识别方法对数据的假设更小,且允许非线性决策边界,这些特性提高了模型的灵活性和分类性能;其次,单纯使用数值指标构建智能化预测模型的局限性愈发突出,更多的学者开始关注文本这类来源广泛且数据量庞大,同时包含更多样本属性的非结构化数据;最后,对于财务报告舞弊的检测,浅层模型和数据挖掘算法只能利用数据集中存在的显式属性,却很难发掘同样存在的其他形式的隐藏属性。而文本数据恰恰包含较多隐藏的属性和模式,需要进一步探求更为有效的智能化识别方法。
对比浅层模型,深度学习模型的结构更为复杂,能更好地发掘数据集中存在的特征。而目前,基于文本数据识别财务报告舞弊的研究则是由浅层模型和数据挖掘模型占据主导地位,鲜有基于深度学习模型的探索。因此,本文的研究基于文本数据和深度学习算法构建识别财务报告舞弊的智能化模型,试图探究人工智能技术是否能更有效地挖掘和利用MD&A文本中预示企业舞弊行为的潜在信号,以识别财务报告舞弊,进而检验深度学习方法在财务报告舞弊识别研究中的应用价值。
三、数据选取和样本来源
我国上市公司各级监管机构的公开披露是判定上市公司是否存在舞弊行为最客观和有效的依据之一。一方面,研究依据中国证监会、上海证券交易所、深圳证券交易所和地方证监局对上市公司的处罚报告和收录这些披露文件的CSMAR数据库,并按照CSMAR数据库对处罚公告的分类,选取其中涉及虚构利润、虚列资产、虚假记载、重大遗漏、披露不实和一般会计处理不当六类定期报告舞弊行为的公告确定为舞弊样本。另一方面,由于2015年之前的部分定期报告将MD&A合并在董事会报告一节中未单独披露,研究将2015年作为选取舞弊样本的时间起点。据此,本文选取了2015—2019年存在上述舞弊行为的上市公司定期报告(包含具有MD&A章节的年度报告和半年度报告)共计454份。同时,为了保证控制样本与舞弊样本具有相同的规模,研究还依据中国社会科学院金融研究所等在2015—2018年发布的《中国上市公司质量评价报告》和报告中的上市公司价值管理能力排名,以及恒大研究院发布的《中国上市公司质量报告:2019》中的合规质量,选取每年排名前45的上市公司作为控制样本,得到半年度报告和年度报告共计450份。
图1总结了研究的分析过程,包括文本数据的选取、文本预处理、样本特征提取、模型构建和结果评估5个部分。
四、模型构建
文本分类是自然语言处理(Natural Language Processing,NLP)领域的一个经典问题,具体指按照事先定义好的主题类别来划分数据集中每个文本的类别。研究参考Zhang et al.[3]提出的字符级卷积神经网络,利用上市公司财务报告中的MD&A文本,构建了一种通过文本分类方式识别舞弊性财务报告的智能化模型,并选取了部分统计学模型和浅层模型作为基准模型,以对比不同模型的分类性能。
对于输入深度学习模型和基准模型的MD&A文本,研究采用了不同的文本預处理流程,尤其是根据浅层模型和深度学习模型各自的特点选取了不同的文本表示方法,以尽可能提升下游模型的分类性能。后面将详细阐述深度学习模型和基准模型各自的文本预处理方法,以及深度学习模型的具体架构和实现。对于基准模型,本文只进行简要的介绍。
(一)深度学习模型
深度学习模型的设计过程主要分为两个阶段:一是文本的预处理;二是模型的构建。
1.文本预处理
深度学习模型的文本预处理主要包括两个步骤:一是数据集类别的划分;二是文本字符的初步量化。
大多数基于智能化模型的财务预测研究采用了二分法的方式,即将数据集划分为训练集和测试集,其中训练集通常占80%,测试集占20%。为了尽可能避免训练阶段产生的模型出现过拟合的问题,研究增加了验证集的划分。同时,为了保持数据划分的一致性,避免因数据划分过程中存在额外偏差而影响最终的结果,参照机器学习研究对小样本集(样本总数通常小于10 000)的划分惯例,本文按照 的比例将MD&A文本集划分训练集、验证集和测试集,且每类数据集都保持舞弊类和非舞弊类的样本数量对等。
样本在划分为不同类别的数据集后还需要经过进一步的预处理:首先,去除了MD&A文本中的数字、字母、标点符号和一些特殊符号。这种对文本信息的过滤也是NLP中常用的方法,有助于降低下游分类模型的维数。其次,字符的编码过程需要为输入模型的文本构建一个固定规模为m的词汇表,并采用整数对表中的每个字符进行量化,每个整数表示一个字符的ID。词汇表通常需要覆盖文本所包含的95%的词汇,考虑到研究所采用的文本的字符数量,本文将m的大小设置为3 000,词汇表会优先量化高频字符,在达到固定规模3 000后其余的字符将被作为低频字符过滤掉。最后,利用词汇表将文本表示为字符的ID列表。此时,每篇MD&A文本序列的长度需要固定为l。这是因为用于训练卷积神经网络的张量(即表示为多维数组的数据,由词汇表量化的文本序列再经过词嵌入层的处理得到)必须由相同维数的矩阵组成,而每篇文本的长度不同,因此需要截断较长的文本,同时向较短的文本添加零,这种操作也被称为填充。研究将文本的固定长度l设置为5 000。此外,不在词汇表中的字符也将被量化为零。
2.基于词嵌入的文本表示
文本表示是NLP中的一个核心任务,现有的表示方法主要有离散形式的符号表示和分布式表示两种形式。词嵌入属于词语的一种分布式表示形式,能够将词语映射到一个数十或数百维度的实值向量中,并尽可能保留原始数据的属性。这种方法能更好地衡量词语之间的距离(即语义的相似性,距离上更接近的词语便被赋予类似的表示),以便在显著降低文本和下游模型维度的同时更好地理解文本的底层语义。
研究以截取自MD&A部分的语句为例,详细说明基于词嵌入的文本表示方法,具体过程可以分为4个步骤,结果如图2所示。第一,根据研究构建的词汇表,“强化公司内部管理”被转换为8个整数ID构成的句向量,n1至n8分别表示字符在词汇表中对应的整数。第二,整数ID构成的句向量被进一步转换为独热编码表示的8×m的矩阵。独热编码使用稀疏的高维向量表示每个字符(维度等于词汇表的规模m),该向量除第ni列(i=1,2,…,8)为1外,其余列均为0。第三,词嵌入层需要训练一个m×d的系数矩阵,d为语句最终嵌入的向量空间的维度。系数矩阵的参数aij(i=1,2,…,m;j=1,2,…,d)由随机初始化生成,通过神经网络模型和反向传播算法进行训练与更新。第四,独热编码表示的语句矩阵输入词嵌入层后,经过系数矩阵的变换(矩阵相乘),最终被映射到一个8×d的向量空间中,表示为一个8×d的文本特征矩阵。通过词嵌入的处理,8个字符都被表示成维度为d的向量,每个维度θij(i=1,2,…,8;j=1,2,…,d)则表示由-1到1之间的具体数值构成的特征值。
研究在卷积神经网络的前端构建了词嵌入层,每个由整数ID表示的字符构成且长度为l的文本向量在输入词嵌入层后被映射到一个l×d的向量空间中。向量空间的维度d属于模型的参数,经过多次训练和优化,本文将这一参数设置为64。词嵌入层通过自训练的方式实现,更利于针对特定数据和分类任务。
3.字符级的卷积神经网络
本文采用了一种基于字符层面建模的卷积神经网络来提取文本的高层抽象概念,具体架构如图3所示,包括词嵌入层、卷积层、池化层、全连接层以及输出层。卷积神经网络的核心思想是训练多个卷积核通过卷积操作来检测样本的局部特征。在本文的研究中,这些局部特征可能是识别财务报告舞弊的关键。
经过词嵌入层处理得到的文本特征矩阵T∈Rt×d首先被输入卷积层(l为文本的固定长度,d为向量空间的维度)。卷积核C∈Rh×d的行数h(即长度)为5,列数d与文本特征矩阵的维度同为64。每个卷积核都会从上到下依次与5行64列的文本矩阵块做卷积操作,卷积核每次下移的幅度为步长1。每次卷积操作得到的特征可以表示为:
其中,Ti:i+h-1表示由第i个到第i+h-1个字符向量组成的文本矩阵块,b为偏置项,f(x)为ReLU激活函数。每个卷积核通过卷积计算共能得到l-h+1个特征,由此组成的特征图可以表示为:
研究共构建了256个卷积核,因此能够得到256张特征图。
卷积层提取的特征图依然具有较高的维度,需要经过池化层的处理,以进一步提取特征和过滤文本信息。研究采用全局最大池化的方法,以每张特征图为单位,通过选取其中最大的特征值并舍弃其他特征值的方式再一次实现局部特征的提取。
池化层从每张特征图中提取的局部特征会输入全连接层进行非线性组合。研究对全连接层的神经元进行了随机失活(Dropout)处理,即在每轮迭代的过程中随机使一部分神经元失活(比例设置为0.5),从而减少特征的冗余,防止模型出现过拟合问题。此外,研究还采用ReLU(Rectified Linear Unit)激活函数对全连接层神经元输出的结果进行非线性变换。
最终,由softmax分类器构成的输出层会根据全连接层输入的结果生成每个样本的分类标签(舞弊和非舞弊),从而完成文本分类的过程。
4.模型的具体实现
研究基于TensorFlow的架构构建深度学习模型,模型的权重使用高斯分布进行初始化。由于CNN是一种典型的前馈神经网络,需要利用反向传播算法完成模型的训练,损失函数则选择了交叉熵损失函数。由于完整的训练集规模较大,耗用的计算资源较多,不利于模型的训练。因此,研究采用批尺寸为64,且经过Adam算法优化的随机梯度下降方法(Stochastic Gradient Descent,SGD)进行参数调优,学习率设置为0.0001(过低会导致参数更新速度缓慢,过高则可能跳过局部最小值点)。SGD也是对标准BP算法的一种优化。由于目标函数可以分解在不同的子集上进行计算求和,通过将训练集划分为多个较小的子样本集,可以使SGD算法一次只在一個批次上更新参数(包括词嵌入层和卷积层的权重矩阵)。样本的训练采用10轮迭代的方式,并在模型性能无法改善的情况下使用提前停止方法终止训练过程。
(二)其他基准模型
研究选取了一些统计学模型和浅层机器学习模型,并以此为基础对深度学习模型进行了基准测试。统计学模型包括逻辑回归和朴素贝叶斯模型,浅层模型则包含支持向量机、随机森林和两类梯度提升决策树的变体模型(XGBoost和LightGBM)。基准模型基于scikit-learn机器学习库提供的方法构建。
1.文本预处理
研究基于同样的MD&A文本集训练基准模型,并利用五折交叉验证方法实现模型的训练和测试。数据集在进行文本表征和特征提取前依然需要先移除文本中的数字、字母、标点符号和一些特殊符号,保留纯文本内容,再完成去除停用词和分词处理。研究参照哈尔滨工业大学开发的中文停用词表去除文本的停用词,并选用jieba中文分词工具实现分词处理。
文本的表示形式和特征提取过程基于卡方检验和TF-IDF算法。卡方检验的核心思想是通过观测实际值与理论值的偏差衡量假设是否正确。基于这一原理,在对MD&A文本进行特征选择时,本文将“特征词与财务报告舞弊不相关”作为原假设,以提取文本的特征词汇。具体的计算方法如下:
其中,N表示文本总数,A和B分别表示特征词在舞弊类和非舞弊类文本中出现的频率,C和D则分别表示特征词在舞弊类和非舞弊类文本中不出现的频率。根据上述的计算方法,研究提取了文本集中的前1 000个词作为特征词。
考虑到这些特征词在文本分类中的重要性,利用词频-逆文本频率(Term Frequency-Inverse Document Frequency,TF-IDF)算法来赋予特征词不同的权重。基于TF-IDF算法,特征词的权重可以表示为:
其中,j表示文本,k和l表示文本类别,tfijk表示特征词i在k类j文本的词频,N表示文本总数,n表示包含特征词i的k类文本总数。由此,由卡方检验提取的特征词表示的MD&A文本被进一步转换为TF-IDF权重表示的文本向量。
2.统计学模型和浅层模型
逻辑回归是智能化舞弊识别研究中最常用的模型,它利用一系列输入向量、一个相关的响应变量以及自然对数来计算回归结果在特定类别内的概率。对于舞弊识别这种二元分类问题,响应变量可以表示为:
计算MD&A文本所属类别的公式为:
除了逻辑回归,本文还采用了另一种统计学中常用的数据分类模型,即朴素贝叶斯(Naive Bayesian,NB)模型。NB算法基于贝叶斯原理,假定MD&A文本的特征向量为,文本属于某一类别ci的概率为条件概率P(ci),模型的训练过程就是利用训练集统计先验概率P(ci)和特征dj(N为样本包含的特征数)在类别ci(i={0,1})中出现的概率。具体的计算方法可以表示为:
研究选取的浅层模型包括支持向量机、随机森林和决策树,这些模型都是财务预测的研究中最常用的智能化模型。支持向量机通过将样本空间映射到一个高维的特征空间中,使得很多复杂的非线性问题能够通过线性分类的方式解决。本文选择了RBF函数作为支持向量机模型的核函数;随机森林是一种包含多个决策树的分类模型,会随机选择特征集中的n个特征,每棵树都对样本集采用Bootstrap抽样的方法确定自身的训练集;此外,研究还构建了两种梯度提升决策树(Gradient Boosting Decision Tree,GBDT)的变体模型:XGBoost和LightGBM。GBDT是一种集成学习模型,能基于决策树实现分类和回归。模型的训练过程由多轮迭代完成,每轮迭代产生一个弱学习器,并基于上一轮迭代的残差进行训练,通过不断减小残差来提高分类精度,直至达到最优。
五、实证结果
(一)模型评估
构建一个具有较好的样本外预测能力的财务报告舞弊识别模型对本文的研究至关重要。对于深度学习模型和基准模型,研究都采用精确率(Precision)、召回率(Recall)和F1分数(F1-score)三类评价指标衡量模型在测试集上的分类性能。
精确率表示模型预测出的舞弊类样本中被正确预测的比例,召回率则表示所有的舞弊类样本中被正确预测的比例。精确率和召回率可以分别表示为:
其中,TP(即真阳性(True Positive,TP))表示被模型预测为舞弊样本且本身也为舞弊样本的MD&A文本;FP(即假阳性(False Positive,FP))表示被模型预测为舞弊样本而本身为非舞弊样本的MD&A文本;FN(即假阴性(False Negative)),表示被模型预测为非舞弊样本而本身为舞弊样本的MD&A文本。F1分数是统计学中常用来衡量模型二分类性能的一种指标,可以表示模型的精确率和召回率的一种调和平均值,具体表示为:
这三类指标的值均介于0和1之间,越接近1表示模型的分类性能越好。然而,以上三类指标的计算过程均假定舞弊类文本为正样本,而非舞弊类文本为负样本。为了综合考察模型在不同类别上的分类性能,研究还引入了宏平均(Macro-Average)的方法,即对舞弊类和非舞弊类样本分别作为正样本时得到的评价指标值求算术平均值。
(二)实证结果及分析
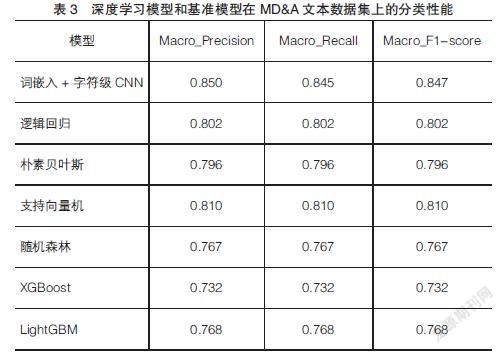
表3和表4分别总结了利用上市公司定期报告中的MD&A文本训练的深度学习模型和基准模型在样本外数据集上的预测结果(评价指标采用宏平均后的数值),以及深度学习模型在不同类别上的预测性能。深度学习模型的架构基于词嵌入模型和一种字符级的卷积神经网络,基准模型则选取了两类统计学模型(逻辑回归和朴素贝叶斯模型)和三类浅层模型(支持向量机、随机森林和梯度提升决策树)。根据表3和表4列示的各项评价指标,研究的实证结果可以总结为以下四点:第一,研究所实现的模型,无论是深度学习模型还是其他基准模型,评价分类性能的指标值均大于0.7,表明模型能够有效利用MD&A中的文本信息进行财务报告舞弊识别;第二,深度学习的各项分类性能均显著高于其他基准模型,表明相较于传统智能化财务报告舞弊检测研究所采用的模型,本文构建的深度学习架构能更好地识别具有舞弊性质的财务报告;第三,逻辑回归、朴素贝叶斯和支持向量机模型的各项指标均在0.8左右,显著高于其他决策树类的模型,表明基于小样本(样本数小于1 000)的文本数据集进行财务报告舞弊识别时,逻辑回归、朴素贝叶斯和支持向量機模型具有更好的预测性能;第四,深度学习模型在两类MD&A文本集上的评价指标值均大于0.82,表明模型在不同类别的数据集上均表现出较好的舞弊识别能力。
六、结论与启示
财务报告作为公开披露的信息,直接反映了企业的运营状况,因此也成为了企业实施舞弊行为的重要媒介。有效识别财务报告舞弊成为规范金融市场运行秩序的重要手段之一。利用深度学习技术在NLP领域取得的各项突破,本文构建了用于识别上市公司财务报告舞弊的字符级卷积神经网络模型,该模型采用财务报告中的MD&A文本作为分析样本。结果表明,在浅层模型具有明显优势的小样本数据集上,不需要经过复杂的文本特征定向提取,字符级卷积神经网络模型依然能够表现出更优越的分类性能,这一结果也为利用深度学习技术改进现有的财务报告舞弊识别方法提供了直接的证据。此外,研究不仅证明了深度学习模型在识别财务报告舞弊上的优势,而且所构建的各类模型在MD&A文本上均表现出较好的预测性能,这体现了企业披露的公开文本所具有的效用和信息价值。同时,财务报告的文本披露作为一种可靠性强且易于获得的数据来源,可以为相关研究提供很好的数据支持。
本文涉及到的很多内容值得进一步探究。首先,深度学习模型和其他使用非结构化数据的人工智能系统类似,训练拟合出的卷积神经网络模型是一个黑箱。深入挖掘和分析模型训练过程中提取的文本局部特征,有利于揭示表明企业存在舞弊行为的财务报告文本的本质;其次,研究只采用了MD&A文本作为训练数据的唯一来源,而目前依然存在大量的非结构化数据源源不断地注入金融市场,利用更多不同来源的文本数据可能有助于提升深度学习模型在企业舞弊识别中的性能;最后,研究所涉及的词嵌入方法和字符级的CNN模型只是深度学习技术的冰山一角。仅就NLP而言,深度学习还存在大量的新兴技术值得深入研究,例如知识图谱、注意力机制、Transformer等文本表示方法,循环神经网络、自编码器、受限玻尔兹曼机、对抗生成网络和强化学习等深度学习的基础架构,以及基于这些架构及其变体模型组合而成的混合模型等。总之,本文发掘了基于文本数据的深度学习模型在财务和会计预测研究中的部分价值,更多的应用价值值得后续的研究进一步探索。
【参考文献】
[1] DONG W,LIAO S,LIANG L.Financial statement fraud detection using text mining:a systemic functional linguistics theory perspective[C].Proceedings of the Pacific Asia Conference on Information Systems (PACIS),2016.
[2] 胡越,罗东阳,花奎,等.关于深度学习的综述与讨论 [J].智能系统学报,2019,14(1):1-19.
[3] ZHANG X,ZHAO J,LECUN Y.Character-level convolutional networks for text classification[C].Proceedings of the Advances in Neural Information Processing Systems,2015.
[4] 张莉.基于国家治理的上市公司舞弊审计实证检验 [J].财会月刊,2018(6):20.
[5] MAI F,TIAN S,LEE C,et al.Deep learning models for bankruptcy prediction using textual disclosures[J].European Journal of Operational Research,2019,274(2):743-758.
[6] DONG W,LIAO S,ZHANG Z.Leveraging financial social media data for corporate fraud detection [J].Journal of Management Information Systems,2018,35(2):461-487.
[7] GLANCY F H,YADAV S B.A computational model for financial reporting fraud detection[J].Decision Support Systems,2011,50(3):595-601.
[8] 皇甫冬雪.基于Lib-SVM的損益调整类财务报告舞弊识别模型研究——来自中国证券市场的证据[J].会计之友,2011(25):75-79.
[9] RAVISANKAR P,RAVI V,RAO G R,et al.Detection of financial statement fraud and feature selection using data mining techniques[J].Decision Support Systems,2011,50(2):491-500.
[10] PAI P-F,HSU M-F,WANG M-C.A support vector machine-based model for detecting top management fraud[J].Knowledge-Based Systems,2011,24(2):314-321.
[11] HUANG S-Y,TSAIH R-H,YU F.Topological pattern discovery and feature extraction for fraudulent financial reporting[J].Expert Systems with Applications,2014,41(9):4360-4372.
[12] CHEN S,GOO YJ J,SHEN ZD.A hybrid approach of stepwise regression,logistic regression,support vector machine,and decision tree for forecasting fraudulent financial statements[J/OL].The Scientific World Journal,2014.
[13] PRADEEP G,RAVI V,NANDAN K,et al.Fraud detection in financial statements using evolutionary computation based rule miners[C].Proceedings of the International Conference on Swarm,Evolutionary,and Memetic Computing,2014.
[14] KIM Y J,BAIK B,CHO S.Detecting financial misstatements with fraud intention using multi-class cost-sensitive learning [J].Expert Systems with Applications,2016,62:32-43.
[15] 馮炳纯.基于数据挖掘技术的财务舞弊识别模型构建[J].财会通讯,2019,805(5):93-97.
[16] XING F Z,CAMBRIA E,WELSCH R E.Natural language based financial forecasting:a survey [J].Artificial Intelligence Review,2018,50(1):49-73.
[17] DYCK A,et al.The corporate governance role of the media[J].The Journal of Finance,2008,63(3):1093-1135.
[18] CECCHINI M,AYTUG H,KOEHLER G J,et al.Making words work:using financial text as a predictor of financial events[J].Decision Support Systems,2010,50(1):164-175.
[19] HUMPHERYS S L,MOFFITT K C,BURNS M B,et al.Identification of fraudulent financial statements using linguistic credibility analysis [J].Decision Support Systems,2011,50(3):585-594.
[20] GOEL S,UZUNER O.Do sentiments matter in fraud detection? Estimating semantic orientation of annual reports [J].Intelligent Systems in Accounting,Finance and Management,2016,23(3):215-239.
[21] MINHAS S,HUSSAIN A.From spin to swindle:identifying falsification in financial text [J].Cognitive computation,2016,8(4):729-745.
[22] HAJEK P,HENRIQUES R.Mining corporate annual reports for intelligent detection of financial statement fraud a comparative study of machine learning methods[J].Knowledge Based Systems,2017,128(6):139-152.
猜你喜欢
科技创新与应用(2016年35期)2017-02-21
计算机应用(2016年12期)2017-01-13
江苏教育·中学教学版(2016年11期)2016-12-21
现代情报(2016年10期)2016-12-15
新教育时代·教师版(2016年23期)2016-12-06
法制与社会(2016年32期)2016-12-01
软件导刊(2016年9期)2016-11-07
软件工程(2016年8期)2016-10-25
电脑知识与技术(2016年10期)2016-06-16
