
基于深度学习的点云目标检测方法
2022-04-02 02:55熊风光
计算机技术与发展 2022年3期
高 焱,熊风光
(中北大学 大数据学院,山西 太原 030051)
0 引 言
在日常生活中视觉搜索几乎无处不在,人体在观察物体时通常不会第一时间观察全局,而是先观察全局中重要的和与重要的信息相关的部分。同样,在点云深度学习中如果将主要的计算数据集中在与检测的类别有关的点上,而与检测的类别无关的点不纳入处理范围,则可以在很大程度上减少计算量。因此,如何构建深度学习网络,并高效寻找与检测物体高度相关的点云就变得至关重要。
1 相关工作
近年来,深度学习方法与卷积神经网络在图像特征提取方面取得重大成就[1-7]。因而,紧跟计算机视觉的大趋势,深度学习逐渐取代手动输入特征表示点云的方法成为点云处理的主导方法。然而,与图像相比,三维点云无序,无结构,密度不均,因此如何用深度学习对其进行分析处理仍然是难题之一。Simon等人[8]提出了Complex-YOLO,Wu等人[9]提出了SqueezeSeg,Chen Xiaozhi等人[10]提出了一种自动驾驶的三维物体检测方法,三种方法的共同点是在二维中使用卷积,将卷积结果通过函数回归处理得到物体三维边界框预测,其中前两种的二维输入获取方式是三维数据在二维某方向上的投射,第三种的二维输入方式是二维图片。此种先将三维转换成为二维的方法的缺点在于高度信息的缺失和最终结果对数据误差非常敏感。针对二维图像的高度信息缺失问题,后来的方法中加入了无需将三维数据进行降维的点云数据处理方法,例如Martin等人[11]提出了一种快速高效利用卷积进行三维点云的物体检测方法,Daniel Maturana等人[12]提出了Voxnet。这两种方法的共同点是将点云转换成为立方体形式进行卷积计算,在上述三维物体检测方法的基础上很大程度解决了高度信息缺失问题,但缺点是计算量会随着数据量的增大而呈指数级增长。对此,Charles Qi博士等人[13]提出了PointNet深度学习框架,该框架无需转换点云格式,直接处理点云,且在物体分类和场景分割等任务上表现良好。
此外,在三维物体检测方面也进行了相关研究。Prawira等人[14]提出了基于立体图像的三维物体检测方法,Su-A Kim等人[15]提出了基于点特征直方图的三维物体检测算法,Ahmed Fawzy Elaraby等人[16]提出了基于Kinect的运用增强深度估计算法的三维物体检测方法,以上研究均从不同角度在三维物体检测方面取得了一定进展,然而将深度学习框架运用到点云大型场景中仍然难度很大。Minh等以二维图像作为输入,使用RNN(recurrent neural network,循环神经网络),在每次回溯迭代过程中重复使用同一块被剪裁区域的不同分辨率图像,达到图像内的物体检测随着每次的迭代更新趋于完全准确的效果[17-18]。然而,由于是对图片进行裁剪操作,这种通过迭代更新检测结果的网络无法进行反向传播过程,进而无法对深度网络进行训练。为了更好地解决该问题,Jaderberg等人[19]提出了STN网络,在该网络中对输入图像进行空间仿射线性变换和对周围邻域像素的图像灰度值进行插值函数取样处理,从而得到输出的特征图像,而且该网络由于可微的灰度插值取样操作而可以进行反向传播训练。在上述文献的基础上,Sφren Kaae Sφnderby等人[20]将RNN与STN进行结合,用于二维图像的检测中。为了解决RNN的梯度爆炸和梯度急速下降与梯度消失问题,Bernardino等人[21]将设置有门控状态的长短期记忆网络LSTM(long short-term memory,LSTM,RNN的一种特殊形式)运用到了深度学习在二维图像的物体检测中,实现了LSTM的卷积网络形式,进一步提高了二维图像的物体检测精度。
该文提出基于PointNet的深度学习网络。该网络仅用于基于LIDAR数据的三维物体检测,旨在用相对较低的计算成本和网络规模较小的框架结构获得实时、良好的三维物体检测效果。为此,该文引入视觉注意力机制,对三维数据应用的重要分支—三维物体检测进行研究,旨在通过对与检测物体相关的点云的预测边界框进行连续更新获得良好的运行效果。主要工作如下:
(1)提出了基于PointNet的深度学习网络,该网络无需转换点云格式,直接对原始三维点云进行处理,对物体的整体形状进行学习,是端到端的可训练的网络框架结构。
(2)对三维物体检测进行研究,将人体视觉机制引入到用于三维多物体检测的点云深度学习框架中,引入该机制后的框架通过在给定复杂环境的条件下学习聚焦关键物体点云的能力,减少需要处理的点个数,从而减少计算成本。
(3)将基于PointNet的深度学习网络在自动驾驶数据集KITTI上运行,结果显示与已有的基于LIDAR数据的检测方法相比,提出的深度网络能够达到良好的运行效果。
2 网络框架介绍
改进之后的PointNet的总体框架如图1所示。该框图的最终效果为生成单个物体的三维预测边界框。该框图所表示的网络框架包括如下核心功能模块:环境网络、重复局部定位网络、分类器网络、三维转换与重采样网络、定位与识别网络。
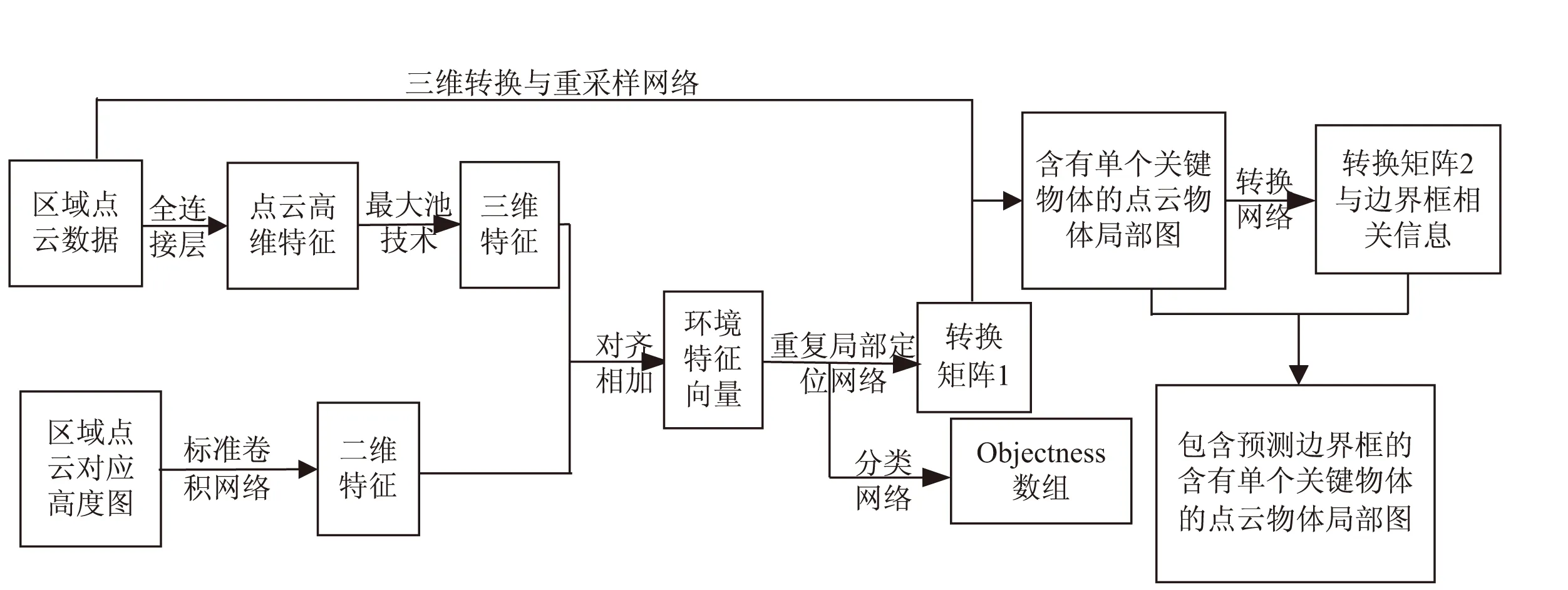
图1 网络总体框架
2.1 环境网络
该网络模块的主要功能为通过从输入的点云数据中提取环境特征从而得到与检测物体类别相关的物体的可能位置,为之后的与检测物体类别相关的局部点云的循环迭代更新做准备。在本次研究中,该模块的输入数据主要分为两个部分:经过剪裁处理后的大小为边长为12米的正方形区域内的三维点云与该区域内的点云对应的俯视图,其中后者的表现形式为以120*120像素的点云垂直投射的二维图像,数据类型为二维数组(x,y),x表示网格或点的索引信息,y表示该索引所表示的网格的对应高度信息。该模块的运行流程可表述如下:
(1)针对三维点云数据,该文使用简化版的PointNet对数据进行卷积计算(简化版如图2所示),通过MLP(multi-layer perceptron,多层感知器)将三维数据转换成为更高维度数据,通过最大池化技术将高维度数据转化成为特征向量,由于特征向量来源于三维数据,因此将该向量记作三维环境向量。
(2)针对二维俯视图,该文通过标准卷积计算与最大池化技术将二维俯视图转换成为特征向量,由于特征向量来源于二维数据,因此将该向量记作二维环境向量。
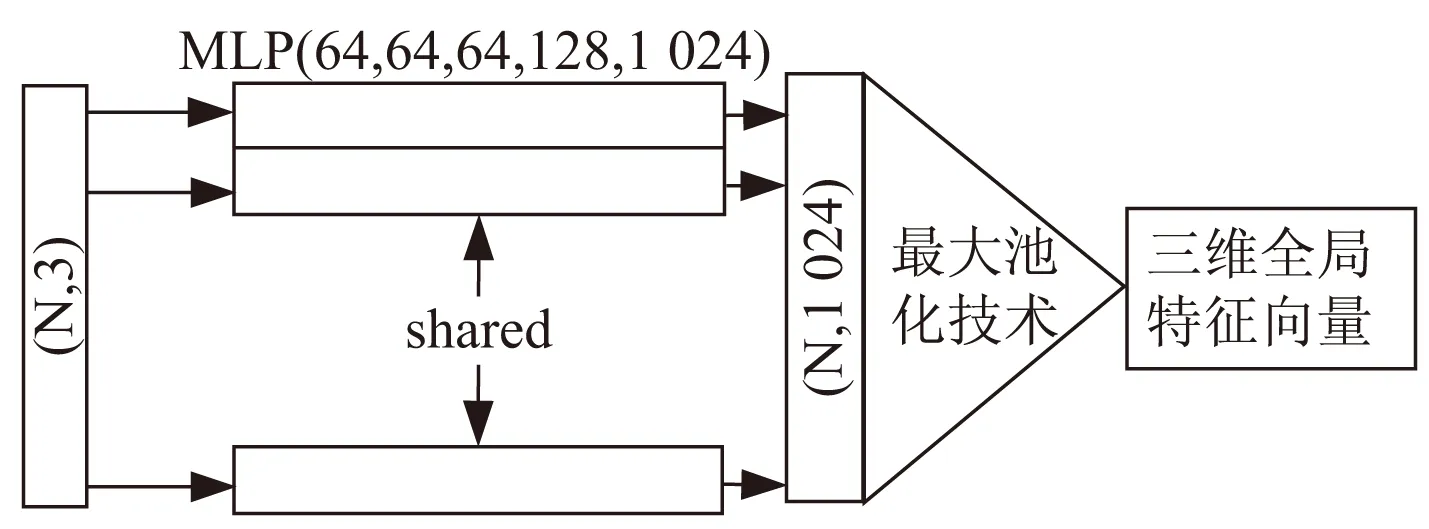
图2 简化版PointNet示意图
二维向量与三维向量分别具有不同的功能,在三维点云场景中,三维向量能够更好地提供物体的全面信息,二维向量能够更好地帮助理解复杂结构物体的信息,因此,该文将二维特征向量与三维特征向量进行结合。深度学习中向量结合的方式主要分为向量拼接和向量相加等操作。由于加法在网络容量相对较低的情况下能够达到与向量拼接相当的效果,因而选择向量相加操作,将二维环境向量与三维环境向量结合成为新环境向量。
环境网络模块的总体框架如图3所示。
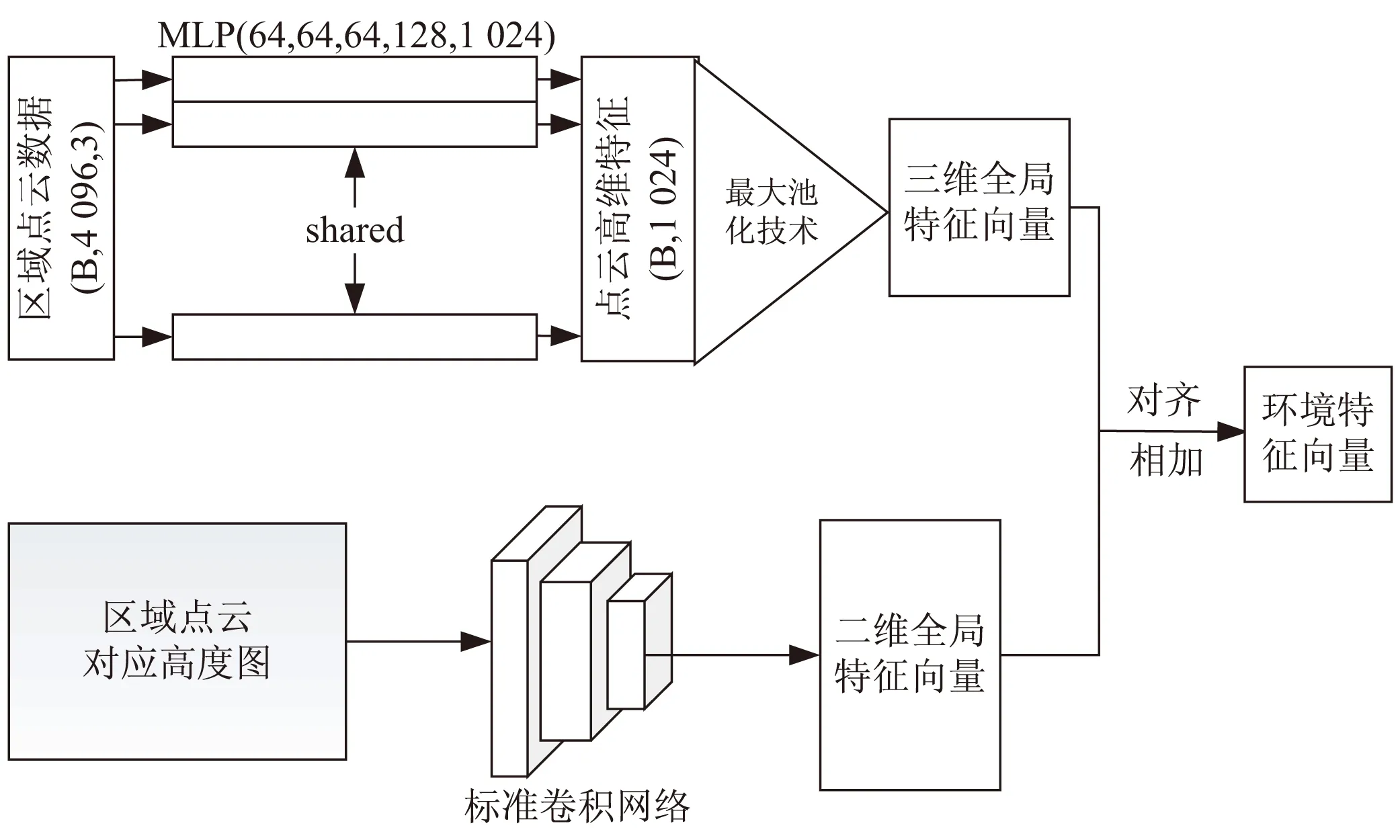
图3 特征网络框架
2.2 重复局部定位网络
作为该文提出网络的核心模块,重复局部定位网络模块的主要功能是在每次迭代计算的过程中对检测到的新物体进行检测位置更新。该模块主要分为两部分:
(1)重复迭代部分。二维图像深度学习中主要使用RNN(recurrent neural network,循环神经网络)深度神经网络实现重复迭代过程。作为RNN的一种特殊网络模块,该文使用GRU(gate recurrent unit,门控循环单元)深度网络实现重复迭代过程。本部分的输入为2.1节中的环境向量与上一次输出的隐藏状态向量,隐藏状态向量初始化为大小固定的零矩阵,输出为维度为512的向量与本次的隐藏状态向量。前者进入到局部定位模块进行处理,隐藏状态向量作为下次迭代过程的输入进行深度网络处理。
(2)局部定位部分。该模块的功能是通过3层的全连接层网络对转换矩阵的相关参数作回归处理。该网络模块的输入为维度为512的向量,输出为转换矩阵相关参数。由于本次研究中,物体的比例和大小不会随着物体与数据探测设备的距离而产生变化,因而仅研究固定的三维变换而对物体的大小予以忽略。为网络运行简便,该文仅探讨点云数据沿z轴的旋转。转换矩阵形式如式(1)所示。
(1)
其中,θ表示点云数据沿z轴的旋转角,cosθ,sinθ,T(xi),T(yi),T(zi)表示转换矩阵的相关参数。i∈N+,i∈[0,n),n是重复迭代的次数。
与STN没有对数据转换进行监督学习不同,该文为预测得到物体位置通过点云数据与标签的一一对应对数据转换进行了监督。该部分总体如式(2)~式(4)所示。
C=fcontext(I)
(2)
hi=fRNN(C,hi-1)
(3)
T(Ωi)=floc(hi)
(4)
其中,式(2)表示作为输入的点云数据和对应的俯视图数据I通过2.1中的环境网络fcontext转化成为同时带有三维特征和二维特征的特征向量C;式(3)表示特征向量C和另外一个输入的隐藏的状态变量hi-1通过GRU转化成为新的隐藏状态变量hi;式(4)表示新的隐藏状态变量hi通过本地化网络floc转化成为旋转矩阵T(Ωi)。该模块的总体框架如图4所示。
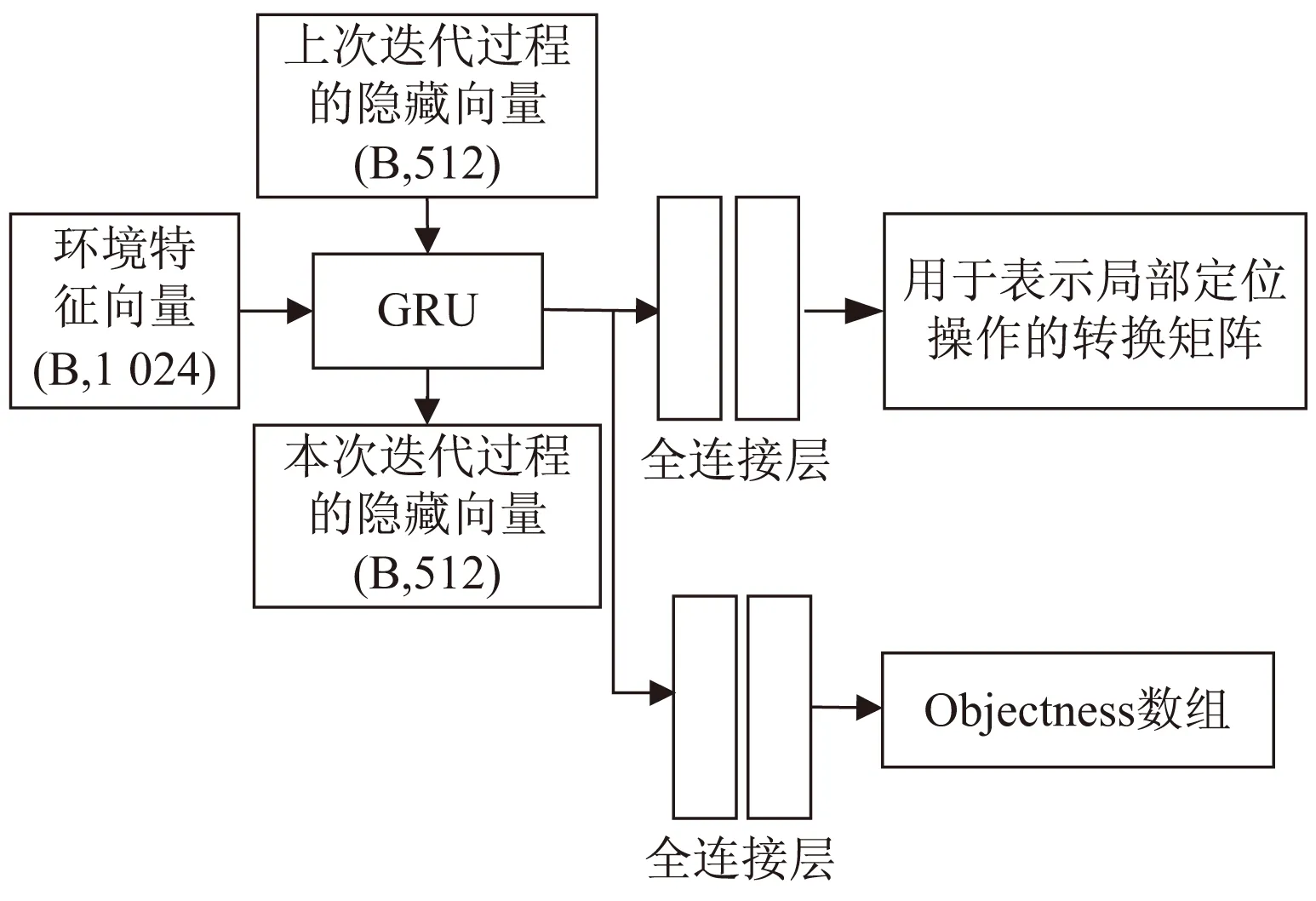
图4 循环局部化网络框架
2.3 分类器网络
根据图2与2.2节关于重复迭代模块的表述可知,重复迭代模块的输出为列数为512的张量与当前迭代过程的隐藏状态向量hi。其中列数为512的向量进入到循环局部化网络进行处理,此外该向量还会进入到分类器网络中。分类器网络主要是由两个与循环重复定位网络中的全连接层的参数不同的全连接层构成的。经过该部分最终输出的是objectness数组,并且为该数组内元素设定了阈值,如果数组内元素大于该阈值,则可以认为该元素对应的物体的位置和边界框的大小预测是准确的,将该元素对应的边界框的大小、物体的位置等信息加入到物体检测列表数组中。最终objectness数组的生成图如图4所示。
2.4 三维转换与重采样网络
在获得了旋转矩阵后,即在三维转换模块中对点云数据进行旋转变换。三维转换模块实现的功能是将输入的点云数据通过2.2节得到的转换矩阵转换成为新的点云数据,新的点云数据中与检测物体相关的点云能够落在更小的预测边界框内。为实现点云数据转换,数据矩阵等式如式(5)所示。
(5)
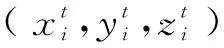
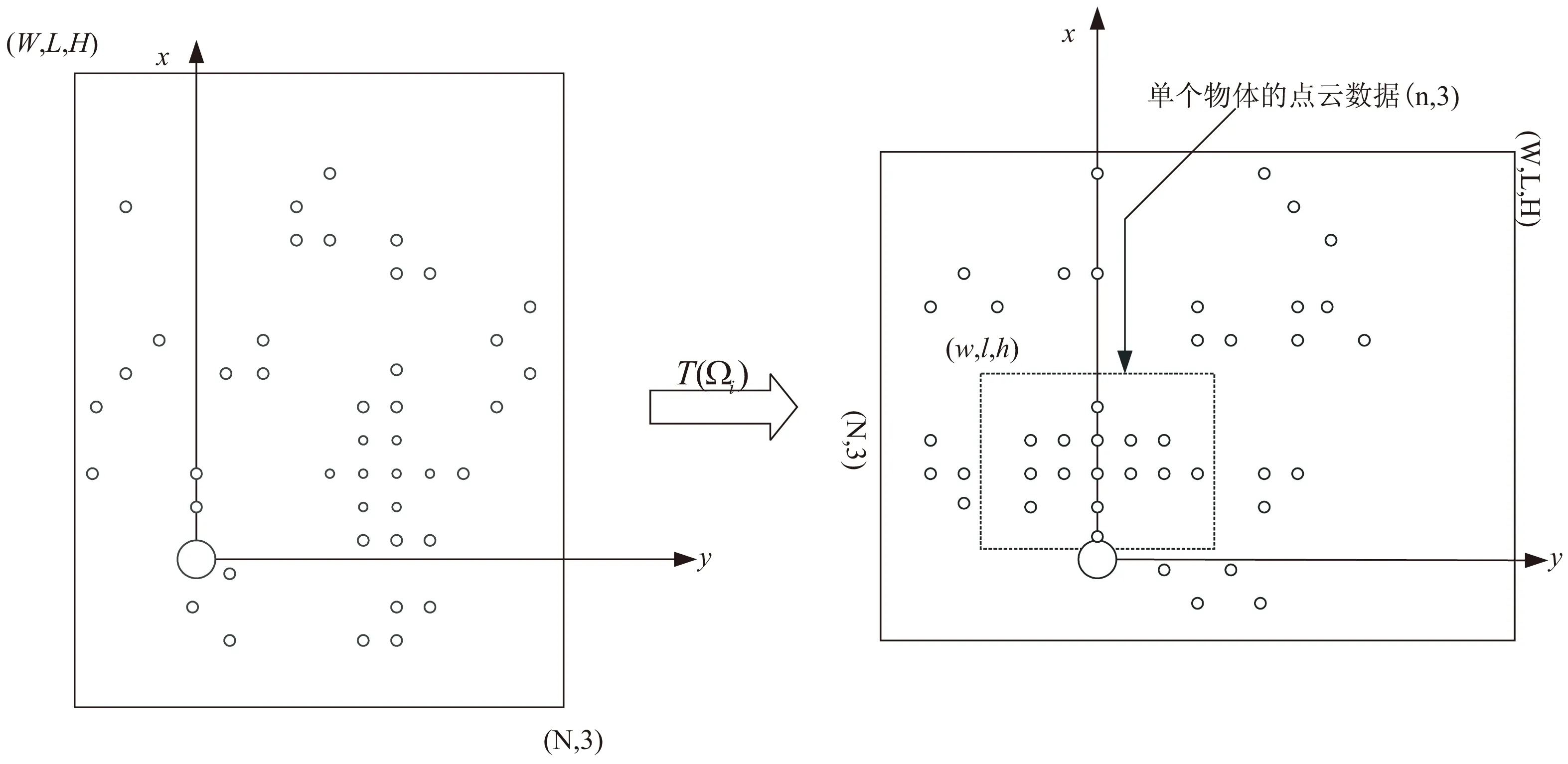
图5 循环局部化网络框架
为简易表示,本图将三维点云用二维形式呈现。图中所有点均落在以原点(0,0,0)为中心,三维数据分别为(W,L,H)的边界框内,此时通过转换矩阵T(Ωi),边界框与所有点均发生了旋转,此时在原先点云中的关键物体点云通过旋转落在了以原点为中心,三维数据分别为(w,l,h)的边界框内。此时对落在三维数据为(w,l,h)的框内点进行区域剪裁,并对点云进行取样,点个数下降成为512个。该模块的框架如图6所示。
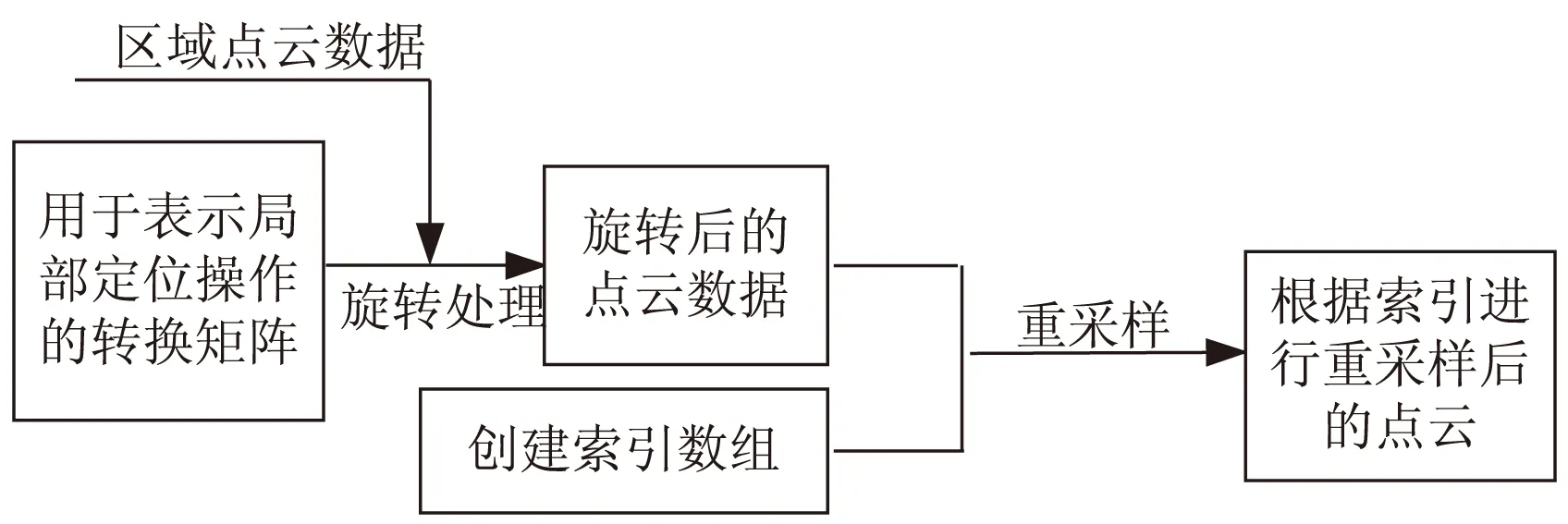
图6 三维转换与重采样模块框架
2.5 定位与识别网络
该模块的功能为在2.4节的基础上,即在关键物体点云确定后,通过对相关参数进行回归处理对物体的三维边界框进行预测。使用轻量级的PointNet[22]对三维转换矩阵的相关参数进行回归处理。该网络对三维转换矩阵的5个参数和边界框的3个参数(W,L,H)进行回归处理。最终的边界框的位置可以通过式(6)得到。
T(Φi)=T(Ωi)*T(Δi)
(6)
其中,T(Φi)表示最终单个物体边界框的位置信息的矩阵,T(Ωi)表示用于局部定位操作的转换矩阵,T(Δi)表示用于表示单个物体中心的矩阵,该矩阵主要包含5个参数:(cosδi,sinδi,txi,tyi,tzi),其中δi表示要实现对变换矩阵的回归需要旋转的角度,i∈[0,n),i∈N+。该模块的框架如图7所示。
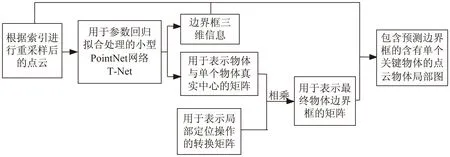
图7 定位与识别网络模块框架
3 实 验
为了对该文提出的网络进行训练和测试,实验使用KITTI自动驾驶数据集,该数据集包括7 481个训练图像或点云数据和7 518个测试图像或点云数据。本次实验中仅用该网络对汽车物体进行识别。
由于KITTI数据集不提供测试数据集合的真实有效值,因此该文采用的是和已有文献的点云3D网络中使用的评估方法[22]相似的评估方法。为了避免将来测试和训练的样本中同时含有相同的数据样本的情况出现,实验将数据集以70%和30%的比例分别作为训练集和测试集。
3.1 数据扩充
在KITTI数据集中,每一帧中所包含的点云数据大约有10万个,覆盖的范围大约有120米。本实验直接将点云用作网络的输入。然而将大约10万个点一次性作为输入会大幅增加计算的开销,而且对计算能力有着非常严格的要求,因此直接使用原始帧数据并不切实际。KITTI数据集仅在负责拍摄周围环境的摄像机的拍摄范围内通过数字标签的形式给出所包含的物体对象的所属类别,因此为了减少计算量,在实验时将落在摄像机的拍摄范围之外的点予以删除。
在对此次的网络模型进行训练时,该文对原有的数据集进行了一定的数据处理。
在进行实验时,首先将负责拍摄周围环境的摄像机的拍摄范围分成了若干个边长为12米的正方形区域,每个正方形之间有大约1米的边长的交叉部分。这样,每个分割成的正方形区域内的点的个数就有0~20 000个不等。如果对这些正方形区域内的点直接进行网络框架处理,仍然会增加内存的负担,所以实验将每个正方形区域内的点进行随机采样,使得每个正方形区域内的点为4 096个。
接下来,实验将每个边长为12米的正方形区域进行灰度图像的转化,生成场景所对应的大小为120*120像素的俯视高度图,将三维点云通过俯视角度投影并离散成为2D网格。
实验选择覆盖从地面以下2米到地面以上3米的高度区域,此举是为了基本上覆盖所有汽车类别的物体的高度。描述所有映射到俯视图的特定网格单元的点的集合如式(7)和式(8)所示。
H(Sj)=max(Pi→j.[0,0,1]T)
(7)
Pi→j={Pi=[x,y,z]T|Sj=fPS(Pi,r)}
(8)
其中,Pi→j表示将在原始点云数据中索引为i的点投射到高度图的网格单元对应的索引j中,[x,y,z]表示点云数据中点的三维坐标,Sj表示与点云数据对应的网格单元集合,Pi表示点云数据内的某一个点,r表示高度图的分辨率,即r=10 cm,H(Sj)表示网格单元集合Sj对应的高度。
针对是否有汽车对每个正方形区域进行标签设定。来自KITTI数据集的信息用于检查每个正方形区域内是否有汽车,并且对汽车位置、方向和大小进行观察和记录。经过对KITTI数据集的全方位分析之后,发现该数据集的所有区域中95%的区域最多仅有3辆汽车。因此对于每一个正方形区域,都会设有一个含有3个标签的序列。对应的矩阵变换参数则能够反映最终边界框的相关属性。如果某区域内汽车不足3辆,就会在该区域的范围之外的固定位置生成剩余数量的固定的大小的边界框,并显示为其余颜色,表示该区域内的汽车的数量不足3辆。
然而在实验过程中发现在非常多的正方形的被剪裁的区域内是没有一辆汽车的,而且没有汽车的正方形区域个数比有汽车的区域个数要多。为了能够让有汽车的被裁剪的区域和没有汽车的正方形区域的个数保持尽可能的一致,这里采用了数据增强方法,包含一系列对原始数据的操作(包括旋转、缩放、裁剪、移位、翻转等)。增强之后的所使用的KITTI一共包括约27 000个用于训练的被裁剪的正方形区域。
3.2 损失函数
上文提到该网络框架包含环境网络、重复定位网络、分类器网络、转换和重采样器网络、边界框预测等。不同部分会产生不同损失。总损失和各个部分损失的关系如式(9)~式(11)所示。
(9)
Lseq-i=α*Lcls+β*(LT1-reg+LT2-reg)+γ*Lsize-reg+λ*Lreg
(10)
Lreg=‖I-T(ψ)T(ψ)T‖2
(11)
其中,Lseq-i表示某一个序列的总计损失,Lcls表示由分类器网络产生的损失,LT1-reg表示用于重复局部定位的矩阵参数的损失,LT2-reg表示边界框预测模块产生的矩阵参数的损失,Lsize-reg表示边界框预测产生的损失,Lreg表示正则化损失,Lfinal表示总计的损失,I表示单位阵,T(ψ)表示回归操作的相关参数所对应的变换矩阵,α、β、γ、λ表示在计算总计损失时的加权系数。
在具体实现的过程中,各个部分损失具体采用的计算方法如下:
(1)对于分类部分损失的计算,采用二进制交叉熵的方法。
(2)对于转换矩阵回归处理产生的损失的计算,采用Huber的平滑L1方法。
(3)对于正则化损失的计算,采用均分损失函数的方法。
其中,式(12)主要是为了使得预测的变换矩阵尽可能接近于正交矩阵,以使得优化过程变得更加稳定和网络性能变得更好。
为了进行训练,这里将预测序列的长度预定义为n=3。为了能够使得损失的具体计算结果不受输入序列的数据的次序的影响,采用最大加权二分图匹配法。为了能够计算得到该方法所需要的权重,使用匈牙利算法进行计算,以得到最大匹配。
3.3 网络详细信息
环境网络由3个全连接层组成,每一层均是用1D卷积进行实现。该网络的最开始输入为三维点坐标,即(x,y,z)。每一层的输入和输出的特征的大小分别为(3,64),(64,128),(128,1 024)。除了第一层没有批次规范化处理之外,其余层均有ReLU激活函数批次规范化处理操作。
除了3D特征网络,本地化网络同样包含3个全连接层。该网络的每一层的输入和输出的大小分别为(512,256),(256,128),(128,5)。在该部分中,仅有第一层和第二层有ReLU激活函数,仅有第一层有Batch Normalization处理。
转换矩阵初始化为单位矩阵。
损失函数系数分别为:α=1,β=1.5,γ=0.5,λ=0.01。
在实验进行的过程中观察到,网络模型在训练迭代120次时趋于收敛。对此,本实验将训练过程中其余相关的参数设置如下:
动量:0.9,权重衰减:0.000 5,批次大小:初始化为32。
学习率:在前40次训练迭代过程中是0.01,之后为0.001。
在训练完整网络之前,还训练了此次的改进的网络的小型初始版本。在该版本中,删除了原始的点云数据输入和一开始的处理部分,以及最后的边界框预测部分,并且从定位网络直接回归边界框的大小尺寸。
4 实验结果分析
在点云检测任务中,最重要的数据即是检测的准确性,因此本次实验中对汽车类别的物体的检测进行了计算。在以上参数的调整下进行了实验,并且与已有文献的检测率进行了比较,结果如表1所示。
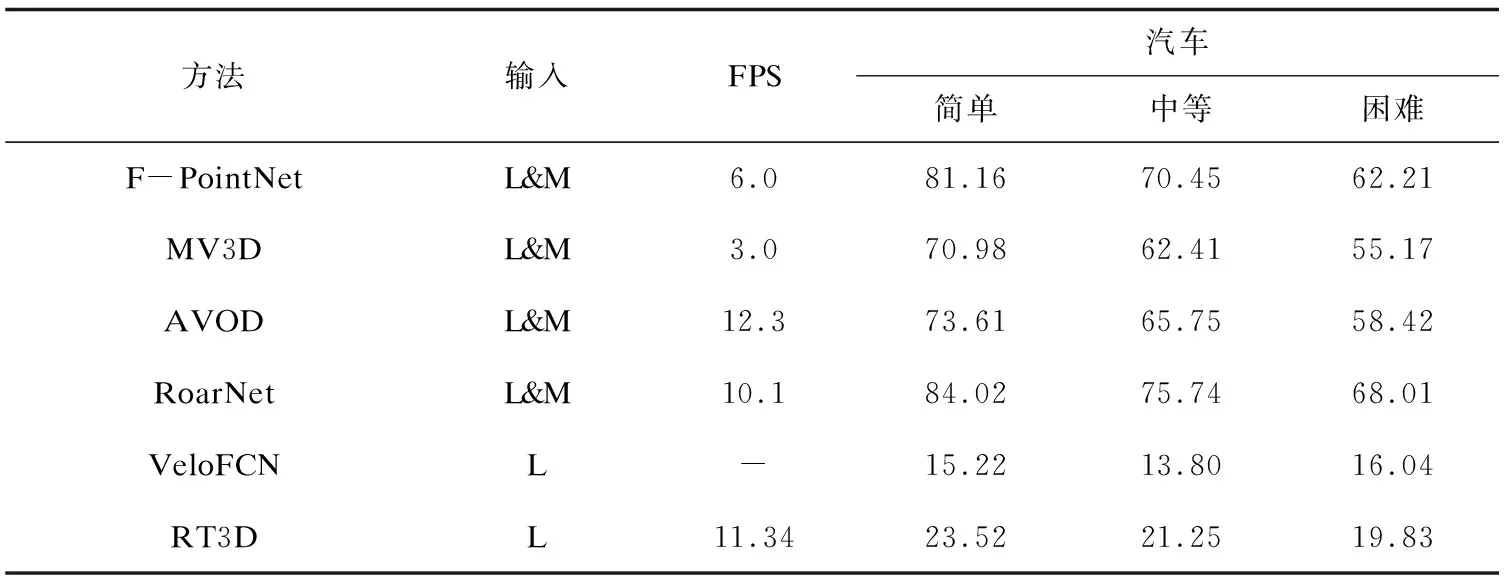
表1 网络框架在KITTI数据集下的运行结果
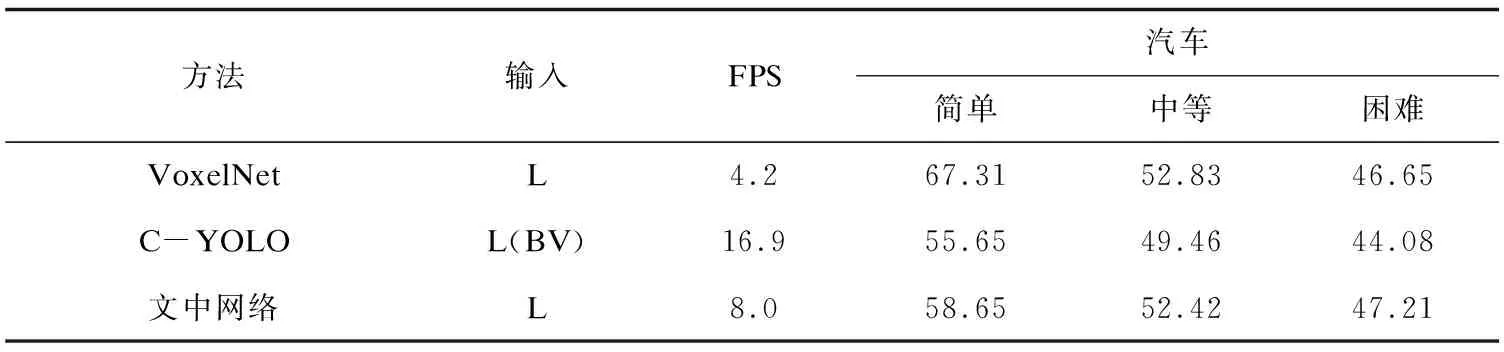
续表1
其中输入L&M为LIDAR+Mono,L为LIDAR。BV(Bird-eye View)表示俯视图,汽车类别的检测精度为百分比(%)。F-PointNet表示Frustum PointNet[22],C-YOLO表示Complex-YOLO[8]。
从表1可看出,除去少量数据的上升,随着检测难度的增加,物体检测的精度总体上呈下降趋势。其中MV3D[23]、F-PointNet、AVOD[24]和RoarNet[25]均使用了LiDAR和数据形式与多传感器检测,其精度比未使用多传感器的方法高,其中RoarNet在各个检测难度上均比其余方法精度高;文中网络与VeloFCN[26]、RT3D[27]、VoxelNet[28]、Complex-YOLO方法均未使用多传感器方法,其中,由于Complex-YOLO方法仅使用了LiDAR数据形式的俯视图形式,因此尽管FPS在各种方法中最高,然而检测精度却未有大幅度提升。文中网络在未使用多传感器的条件下,在各个难度的汽车检测精度上仅次于VoxelNet。考虑到VoxelNet是将三维点云数据转化成为体素格形式,大幅增加了计算复杂度,对计算机硬件要求相对于其余未使用多传感器的方法要高。因此可以认为,文中网络在仅使用LIDAR数据,未使用多传感器,未将三维点云转换成为其余三维数据形式,以及较低计算复杂度的情况下,在汽车物体检测类别的精度上比其余方法的对应数据高,取得了良好的运行效果。
5 结束语
当前随着深度学习在计算机视觉研究中的不断深入,该研究方法在二维图像检测上得到了广泛的应用,之后,深度学习在三维数据上的研究工作亦进行开展。然而,大多数已有的关于深度学习在三维数据上的研究的文献使用的是手动输入特征值的方法或将非规则化三维体素格的数据形式转换成为规则化三维体素格的数据形式的方法,两种处理方式均会大幅提高计算成本,增加计算复杂度。为能够在未将三维点云数据转换成为其余数据形式的情况下用较低的计算成本对三维点云进行直接使用和处理,受到与人体视觉机理与RNN网络的启发,该文以深度学习神经网络PointNet为基础,提出用于三维物体检测的深度学习神经网络。该网络仅使用LIDAR的三维数据,高效获取数据几何特征,为减少计算成本与计算复杂度,该网络引入三维点云的人体视觉机制,引入三维局部定位网络。为对提出的网络进行实验,使用KITTI数据集,对数据集中的汽车进行检测,并对检测精度进行评估。结果显示,该网络在仅使用LIDAR数据,未使用多传感器,未将三维点云转换成为其余三维数据形式,以及较低计算复杂度的情况下,在汽车物体检测类别的精度上比其余方法的对应数据高,取得了良好的运行效果。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
黑龙江大学自然科学学报(2022年1期)2022-03-29
小资CHIC!ELEGANCE(2022年1期)2022-01-11
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
读与写·教育教学版(2017年10期)2017-11-10
高中生学习·高三版(2016年9期)2016-05-14
燕山大学学报(2015年4期)2015-12-25
新高考·高二数学(2015年11期)2015-12-23
南都周刊(2015年4期)2015-09-10
南都周刊(2015年3期)2015-09-10
