
一种孤立中心损失方法及其在人脸表情识别中的应用
2022-04-02 03:11:50王军杰王泉蒋平刘音
西安交通大学学报 2022年4期
人脸表情是一种重要且自然的情绪表现形式,因而人脸表情自动识别也是人机和谐交互的重要基础。近三十年来,人脸表情识别(FER)研究一直是人工智能领域的一个热点
。近些年,随着深度学习技术发展,FER研究从实验室限制条件下的表情样本逐渐转移到了现实世界(自然)表情图像。自然表情图像复杂多变,如光照强度、头部姿态变化、有无遮挡物等,导致表情识别的难度增加
。
FER是一个典型的多分类任务,每一个样本必归属某一个类别,且只属于一个类别。Softmax Loss (SL)是一种交叉熵损失,经过Softmax变换,每一个样本最终输出对应多个类别的概率值(相对概率)。SL通过优化预测概率与目标概率之间的误差,会持续拉高正确类别的概率和降低错误分类的概率。在多分类问题上,SL直观、易理解,而且反向求导简洁,是FER领域应用最广泛的一种监督函数。
SL尽力把不同类别样本特征在角度空间分开,在SL监督下学习到的深度特征的区分度不够好
,因此研究者们对SL进行了改进
。针对SL的改进技术主要分两类:一类是改变SL本身(即SL的变体),例如人脸识别领域中的ArcFace
、Normface
和CosFace
等;另一类是增加约束项协同SL一起工作,如Center loss(CL)
和Island Loss(IL)
等。
分类任务有个共同原则,深度特征的区分度越高越好,即不同类别样本特征之间的距离(差异性)越大越好。现有技术主要通过减小类内距离和增大不同类之间的距离两个方面来提高特征区分度。
CL采用中心聚类思想,减小同类样本之间的欧式距离,有效降低类内变化。Luo等
认为同一种表情并非高度相似,同一种表情中也应该分成几个子类,从而提出了Subcenter Loss(SCL)。Li等
则减小每个样本与其相邻几个同类样本中心的距离,从而促使同类样本收敛在一起,这种方法兼具了CL、SCL的优点,但是计算复杂度高,且需要额外的内存开销。
IL在SL的基础上采用了CL,同时通过最小化不同类中心夹角的余弦值,期望不同类之间的夹角尽量大。IL需要约束每一类与其他类的夹角,难以处理类别数量多的任务,Zhao等
用于人脸识别的“排他正则化”本质上是IL的一种特例。Jiang等
证明了类间夹角相等且等于arccos(1/(1-
))(
为类别数量)是类间角度距离最大化的一种理想状态,基于此提出了一种改进Softmax损失(ASL)。
ASL能够有效最大化类间角度距离,CL能够有效地减小类内变化,但是ASL、CL单纯地协同工作,即ASL+CL并非更优秀,可能比ASL更差。针对此问题,本文提出了一种孤立中心聚类损失(ICL)方法,以ASL为基础融合中心聚类思想,即改进CL以符合ASL,再最大化类间欧式距离,使各类成为彻底的“孤岛”。实验结果表明,所提方法在识别精度和稳定性方面都有较好的提升。
1 相关工作
1.1 改进Softmax损失函数
无偏量的SL一般定义为
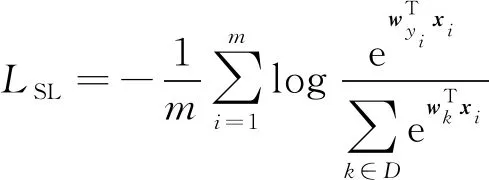
(1)
一个训练理想的模型,第
类特征的中心就在其对应权值向量
的方向上,即
可以代表第
类中心的方向。若用
表示第
和
类(中心)的夹角,则
的余弦值为
精准调控水分不但能提高作物产量和品质,还能有效地提高水分利用效率[11]。定量分析水分与作物生长发育之间的关系,对农田水分管理具有重要意义。研究表明[12-15],减少作物蒸腾作用而不影响光合作用,则植物的水分利用效率会明显增加,合理的农林间作群体有利于提高土壤贮水量,减少作物蒸腾,促进光合作用,提高水分利用效率。本试验中,轻度水分亏缺下棉花产量与正常灌水差异不显著,考虑到水分投入相对较少,在一定程度上大大提高了间作系统的水分利用效率,这与之前的研究结果一致[16-17]。
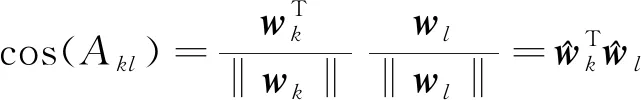
(2)
测试阶段采用10-crop方法,100×100×3的图像被剪裁成10幅90×90×3的图像块(左上、右上、左下、右下和中心部分共5张,以及它们水平翻转后的5幅),然后对这10幅子图的输出结果进行平均,再选择概率最高的类别作为识别结果。

(3)
式中:
为所有夹角的余弦值之和,
越小表示各类之间的夹角越大,区分度越好。
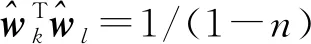
译文舍弃了原文的形式,采用了汉语常用的四字格,显得典雅,保存了原文的意境,原文边品咖啡边啧啧称赞的意境描绘得淋漓尽致,让消费者产生了最佳关联性期待,也按捺不住想尝尝,实乃译作精品。
UPS的配置应根据发信台设备的用电功率以结合其他因素做精确计算后进行配置,经统计,目前发信台正在运行的设备及所需功率如表2。
(4)
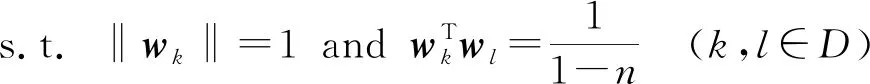
对比式(1)、式(4),ASL只是对SL的权值做了限制。ASL在初始化时,权值向量
由文献[20]的算法1生成
,在训练时固定不变。
ASL的优势有两点:ASL的权值向量等角度分布,可以缓解多样本类容易挤压少样本类角度空间的问题,在一定程度上可以解决样本不平衡的问题;ASL采用的权值是固定的,在训练过程中不需要更新,所以ASL的训练速度比SL快。
每年初夏,当闻到栀子花的香气时,我都会想起刚入职时的情景。那是一段关于栀子花的美丽记忆,每每想起,我都会不自觉地嘴角上扬……
内部审计的重担要求内部审计人员不仅需要通晓财务知识,还应当掌握经济、法律、金融、税收、计算机、企业管理等知识。但是,在现实生活中,由于有些中小型企业对内部审计工作的重要性认识不足,加之内部审计人员普遍存在着学历偏低、专业结构较为单一等问题,影响了内部审计作用的发挥和组织目标的实现。
1.2 中心聚类损失函数
针对SL只注重类间差异,忽略类内差异性过大的问题,文献[13]提出了一个减小类内离散度的约束函数,即著名的中心聚类损失函数(center loss,CL),其定义为

(5)
式中
表示第
类的中心。
CL是对SL的一种辅助,与SL一起监督学习,学习时总损失可以表示为
=
+
(6)
式中
是一个权值,决定了CL约束效果。
=0时,CL无效;
过大,则同类样本有可能被聚集在同一个点,这也不利于分类,因为同类样本特征不可能完全相同,同类样本之间也存在细微差别。
CL的核心思想是减小同类样本之间的(欧氏)空间距离,让同类样本尽量聚集在一起,从而增大不同类样本之间的距离,提升区分度。
2 孤立中心损失函数
增大类间差异、减小类内差异是监督学习提高区分度的基本原则。ASL本质上是类间角度距离最大化的结果,本文以ASL为基础,再在欧式空间减小类间离散度和增大类间距离,提出一种孤立中心损失方法(ICL)。
2.1 前向传播
ASL已经假定了第
类的中心在其对应的权值向量
方向上,因而可以设第
类的中心为
(
是一个可学习的值),则减小类内空间距离的损失函数可表示为
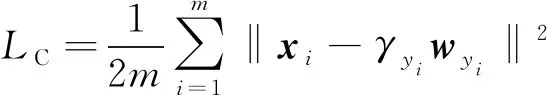
(7)
式中
代表深度特征
所对应的第
类的中心,
与其类中心
的距离越小,
的值越小。
ICL监督学习过程
Strategic marketing modes of cosmetic enterprises 3 54
神经网络参数
1:随机初始化网路参数
和
(
∈
),利用文献[20]的算法1生成权重
2:for
=1 to
do

RAF-DB数据集上的性能对比如表3所示,在识别准确度方面,SL+CL和ICL的识别率最高,达到88.26%,但是ICL的稳定度是0.180,要比SL+CL的稳定度0.288好得多。
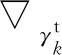
6: 更新
:
province ZHANG Ting FU Bi-chang ZHOU Zhi-guo et al.(12)

7: 更新网络参数
:
挖鞭笋要注意以下几点:沿山坡方向穿行的纵鞭不挖,横鞭则挖;“梅鞭”埋、“伏鞭”挖;干旱季不挖;竹林空隙处少挖,土层深厚处不挖;挖掘后笋穴及时覆土踩实。鞭笋型竹林经营一般以2年为间隔期比较合理。
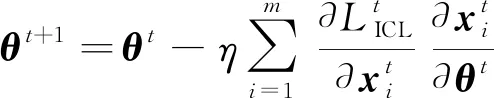
8:end for
创业型企业是指处于创业阶段,高成长性与高风险性并存的创新开拓型企业。随着国家鼓励民营经济的发展以及当前就业形势的日趋严峻,创业已成为促进区域经济发展和解决就业问题的一条重要途径。许多国家意识到,只有通过创新、创业,尤其是创建高新技术企业,它们才能参与新产品、新市场、新产业的发展,从而进入世界经济的高增长行列。
不同类中心的空间距离越远越好,可以考虑如下约束函数
受众理论的“使用—满足说”认为受众群体接受媒体的动机和得到的满足都是极其多样的[],研究生作为校园新媒体平台的受众,利用新媒体可以快速获取到学术讲座、招生就业、校园新闻、生活服务等方面的信息。作为新媒体的用户,研究生每天都会阅读和浏览大量的信息,而其中真正写的生动、吸引人的信息屈指可数。可见,新媒体运营模式是至关重要的。
采用SPSS 19.0统计学软件处理数据,计量资料采用(±s)表示,进行 t检验,计数资料采用[n(%)]表示,进行χ2检验,P<0.05为差异有统计学意义。
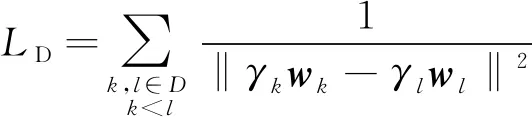
(8)
式中‖
-
‖为第
类中心
到第
类中心
的欧式距离,距离越大,其倒数越小,
越小。
ICL以ASL为基础,再用
损失减小类内空间距离,以
损失增加类间空间距离。ICL定义为
=
+
+
(9)
式中
、
为权值。
2.2 反向传播
实验采用3个经典的非限制性表情数据集:FER2013
、FERPlus
和RAF-DB
。
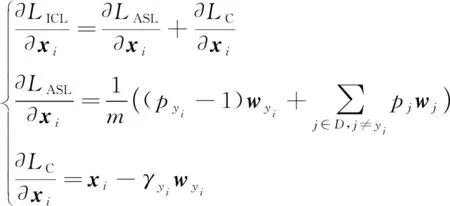
(10)
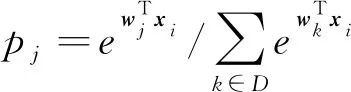
只有
和
中含有
,
的反向梯度为
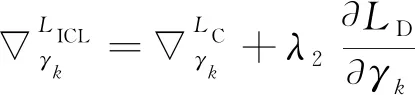
(11)
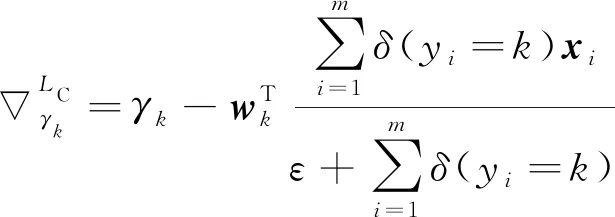
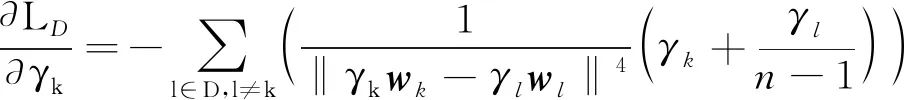
式中:
(
)当条件
为真时取值1,为假则取值0;
是一个极小的常量,防止除数可能为零时出错,文中取值10
。
青菜、蔬菜、生菜是苏南地区的四季栽培蔬菜,在苏南气候条件下,夏季高温多雨对其构成了高温和高湿胁迫,所以青菜、菠 菜、生菜在夏季生产中往往表现生长缓慢,死苗率高,病虫害严重,叶片易变黄、腐烂等[1],因此夏季栽培中筛选耐高温高湿的品种成为青菜新品种选育的重要目标之一。鉴于此,笔者选取3个品系(生菜、菠菜、青菜)15份不同蔬菜材料,在不同温度和湿度下对其分别进行高温高湿处理,筛选适宜苏南夏季气候特征的蔬菜品种,旨在降低高温高湿胁迫对蔬菜产量的影响。
3 实验结果及分析
3.1 实验相关设置
实验采用Python开发平台和PyTorch库,运行平台为一台Dell服务器,其配置为CPU:Intel Xeon Silver 4114 @ 2.20 GHz,内存为64 GB,显卡为NVIDIA GeForce RTX 3090。
3.1.1 深度卷积网络结构
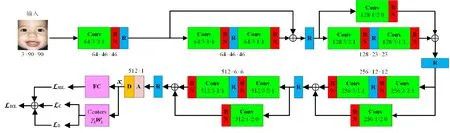
实验采用经典ResNet-18的变体,如图1所示,网络输入大小为90×90的三通道图像,输出为512×1特征向量。
从表1~表3可知,总体而言,ASL优于SL,SL+CL也很优秀,但是ASL+CL在FER2013数据库上的识别率和稳定性都比ASL差,在RAF-DB数据集上识别率也低于ASL,说明ASL+CL可能比单独的ASL更差,这也是本文提出ICL的出发点。ICL是以ASL为基础,融合了CL的思想,再加入了最大化类间空间距离的思想,ICL在3个数据库上都表现优异,表明了ICL的合理性和有效性。
在反向传播时,ASL的权值向量
固定不变,只需要更新深度特征
和第
类中心的
。
关于
的偏导数为
FER2013数据集有7类表情共35 886张图像,用于训练、验证和测试的图像分别是28 709、3 589和3 589张。训练表情样本包括愤怒3 995张、厌恶436张、恐惧4 097张、悲伤4 830张、开心7 215张、惊讶3 171张以及中性4 965张。
FER2013中含有一些标注错误的数据,因而FERPlus数据集则对FER2013中的图像重新进行了人工标注,在FER2013的7类基本表情上又增加了蔑视、未知和非人脸这3类。FERPlus每一张图像有10个分类标签,10个标签上的得分总和为10。本文只考虑7种基本表情,采用文献[22]提供的最大投票方式筛选后的训练图像有24 941张、验证图像3 186幅、测试图像3 137张。
RAF-DB有15 339表情图片,其中12 271和3 068分别用于训练和测试。训练图像含有的7类基本表情是愤怒705张、厌恶717张、恐惧281张、悲伤1 982张、开心4 772张、惊讶1 290张以及中性2 524张。
FER2013和FERPlus都含有验证集和测试集,本文只给出测试集的测试结果,结果如表1~4所示。
在图1中,实线箭头表示直接联系,即“乡愁”萌生于诗人(我)的心中,通过4个不同的意象载体,分别传达给4个不同的目标;而虚线箭头则表示间接联系,即“乡愁”在诗人心中所指向的实际目标。
3.1.3 图像预处理
FER2013和FERPlus的图片是48×48灰度图,先扩大成100×100图片,然后通过复制通道方式转换为100×100×3的图像。RAF-DB提供100×100 RGB彩色图像,无需转换。
训练时,从100×100×3人脸图像中随机剪切出90×90×3图像块,再把每一个像素值除以255归一化。为了增强数据,在±10°范围内随机旋转,且以50%的概率随机水平翻转。
3.1.4 训练/测试策略
采用随机梯度下降法对模型进行端对端训练,每批128个表情样本,动量矩参数为0.9,采用的Heinitialization方法初始化卷积网络系数
,L2正则系数为3×10
,迭代次数为200,初始学习率为0.005,迭代80次后,每20代衰减率0.8。ICL的参数
和
分别为0.005和7。
基于类间角度距离(夹角)越大,区分度越高的原则,考虑如下损失函数
3.2 性能评价标准及实验结果
3.2.1 性能评价标准
本文采用文献[20]中的平均准确率和稳定度两个标准。对每种方法测试
(
=10)次,以
次结果的平均值作为最终准确率,定义为

(12)
式中Acc
为第
次实验的识别率。由于网络参数随机初始化和训练样本随机分批的原因,相同设置下每一次的识别结果有一定的误差,所以采用多次实验的平均值更加公平可靠。
稳定度是
次实验结果的均方差,定义为
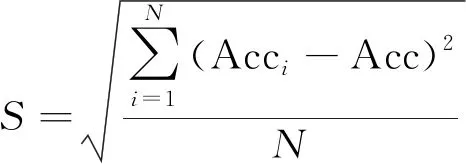
(13)
稳定度
体现了相同设置下实验结果的变化程度,
越小,表明模型性能越稳定。
3.2.2 表情识别性能对比
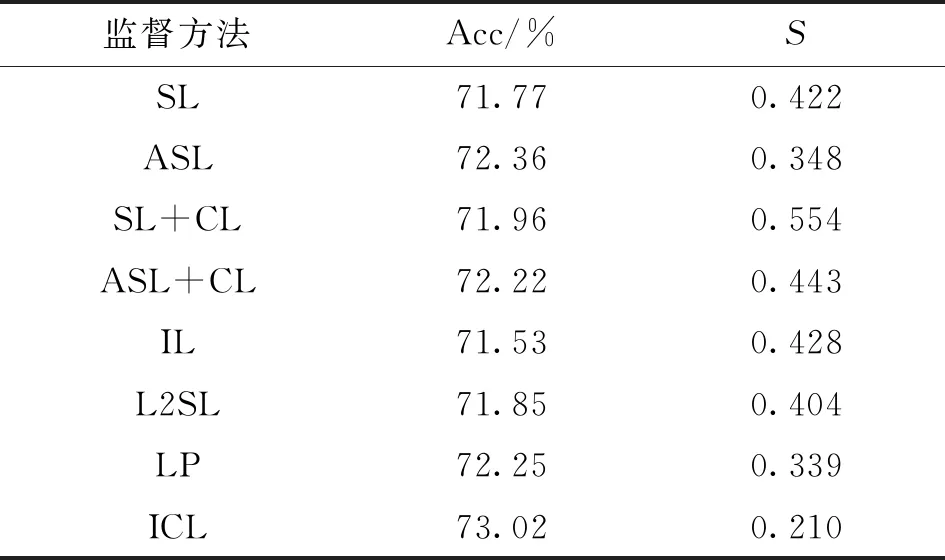
本文ICL是在SL基础上的改进,为了验证ICL的有效性,主要与SL及其改进技术进行对比,对比方法有:SL、ASL
、SL+CL
、ASL+CL、IL
、L2SL
和LP
。
本文在FER2013、FERPlus和RAF-DB数据集上进行了对比测试,为了公平对比,所有方法均采用图1中卷积网络,且采用相同的训练步骤和网络参数。ASL代码由原论文作者提供,其他方法则是按照文献所述原理另行编写程序。
ASL可定义为
在FER2013数据集上的性能对比结果如表1所示,ICL的平均识别率Acc最高,达到了73.02%,比SL和ASL分别提高了1.25%和0.66%。在稳定度
方面,ICL也取得了最佳成绩0.210,相比于SL的0.422,提升了一倍,稳定度性能提升是指
的数值下降。
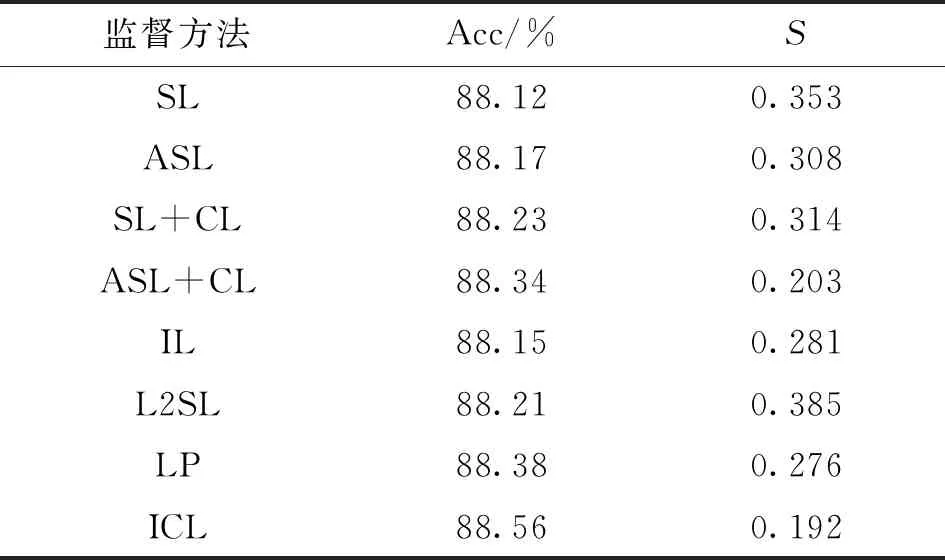
FERPlus数据库的测试结果如表2所示,在识别准确率和稳定度方面,ICL都取得了最好成绩,分别是88.56%和0.192。相比于SL和ASL,ICL的准确度提高了0.44%和0.39%,其性能提升程度没有FER2013上显著。


3.1.2 实验数据集
3.2.3 参数选择
ICL有两个人为设置的权值
、
,理论上应该采用网格计算最优权值。文献[13-15,17]表明,减小类内变化的约束权值在0.001~0.01区间比较合理,因而本文首先设置
为0
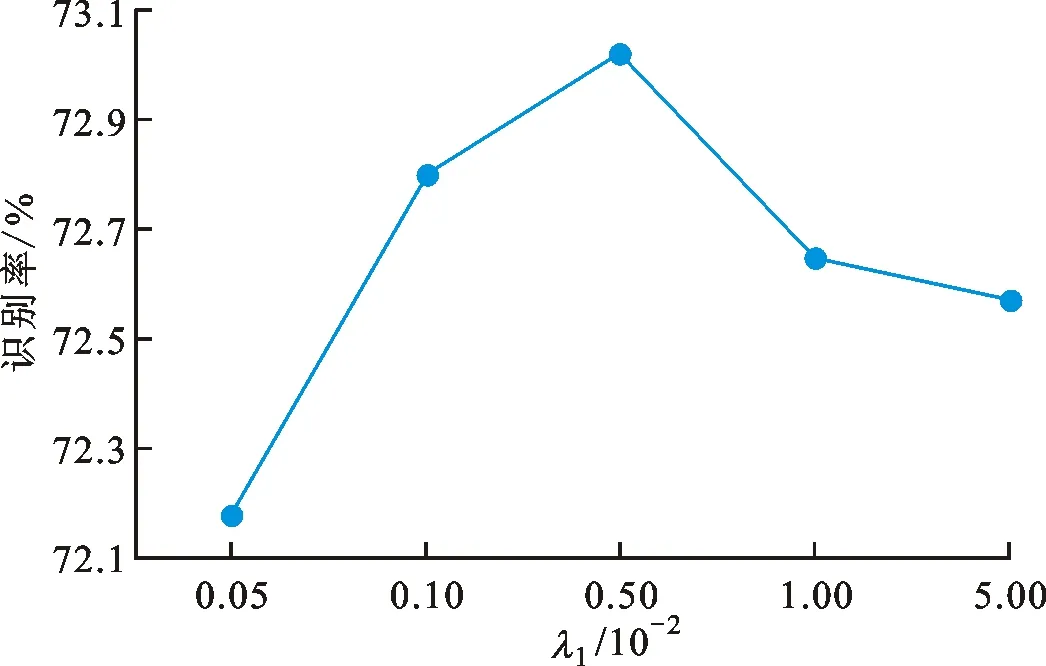
005,然后
取1到10共10个值,在FER2013数据集上的识别率如图2(b)所示,虽然不是严格的上凸曲线,整体而言,
=7时的识别率明显优于其他值。
设置为7,
分别取值0.000 5、0.001、0.005、0.01及0.05,在FER2013数据集上的识别结果如图2(a)所示,可知
=0.005时的识别率最高。
综上所述,本文选取
=0
005和
=7。
3.2.4 消融实验
ICL损失函数由ASL损失
SL
、类内损失
和类间距离损失
这3部分构成,本次消融实验测试了
SL
(ASL)、
SL
+
和
SL
+
+
(ICL),其结果如表4所示,其中
SL
+
与对比实验中的ASL+CL是不同的方法。

在FER2013数据库上,
SL
的识别率和稳定度分别是72.36%和0.348。加入
损失(
SL
+
)后则分别是72.23%和0.188,识别率反而略微下降,但是稳定度性能大幅提升。再加入
(
SL
+
+
)后的成绩分别是73.02%和0.210,
SL
+
+
在识别率方面有了明显的提高;在稳定性方面,比
SL
+
的稳定度稍差一点,但仍然比
SL
优秀很多。
在FERPlus数据集中,
SL
、
SL
+
和
SL
+
+
3种方式的识别率分别是88.17%、88.47%和88.56%,依次略微提升。这3种方式的稳定度分别是0.308、0.167和0.192,
SL
+
的稳定度好,
SL
+
+
的稳定度反而比
SL
+
稍微差一点,但比
SL
仍然好很多。
在RAF-DB数据库上,
SL
、
SL
+
和
SL
+
+
的识别准确率分别是85.58%、85.89%和86.26%,依次增高。三者的稳定度分别是0.271、0.187和0.180,也是依次变好;
SL
+
和
SL
+
+
的稳定度非常接近,几乎差不多。
由此可见,大体上
SL
+
可以大幅增加稳定性,
SL
+
+
在保持稳定性优势的基础上可以提高一定的识别准确度。
3.2.5 时间复杂度
各种监督方法在FER2013数据集上训练一个Epoch所需的平均时间如表5所示,ASL速度最快,只需33.51 s。SL是33.92 s,ASL+CL与SL几乎差不多,需要33.97 s。ICL是以ASL为基础融合了CL思想,再增加了一部分约束,所以ICL比ASL+CL计算复杂度高,需要34.31 s,仍然比SL+CL略微快一点,比IL和L2SL快很多。

4 结 论
针对传统SL监督学习的深度特征区分度不足,本文提出了一种孤立中心损失方法(ICL),它主要包含了最大化类间角度距离、减小类内变化以及最大化类间(欧氏)空间距离3种约束,从而使各类成为彻底的“孤岛”,以提高各类之间的区分度。在FER2013、FERPlus和RAF-DB 3个数据集上的实验结果表明:ICL在识别准确率和稳定性两个方面都有明显的提升。ICL虽然由3部分组成,但是计算复杂度并未增加太多,运行速度只比传统SL略微慢一点,仍然比一些其他方法快。
ICL的基础是ASL,ASL中生成等角分布固定权值向量过程的计算量随着类别数量增大而呈几何形式增长,难以处理类别特别多的分类任务,ICL仍然存在这个问题,这是将来工作需要改进的一个方向。多损失函数融合模型在许多领域非常有效,未来工作将在这方面进行尝试。
:
[1] JIANG Ping,WAN Bo,WANG Quan,et al.Fast and efficient facial expression recognition using a Gabor convolutional network [J].IEEE Signal Processing Letters,2020,27:1954-1958.
[2] RUAN Delian,YAN Yan,LAI Shenqi,et al.Feature decomposition and reconstruction learning for effective facial expression recognition [C]∥2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).Piscataway,NJ,USA:IEEE,2021:7656-7665.
[3] WANG Kai,PENG Xiaojiang,YANG Jianfei,et al.Suppressing uncertainties for Large-Scale facial expression recognition [C]∥2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).Piscataway,NJ,USA:IEEE,2020:6896-6905.
[4] YANG Huiyuan,CIFTCI U,YIN Lijun.Facial expression recognition by de-expression residue learning [C]∥2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition.Piscataway,NJ,USA:IEEE,2018:2168-2177.
[5] LI Danyang,WEN Guihua,HOU Zhi,et al.RTCRelief-F:an effective clustering and ordering-based ensemble pruning algorithm for facial expression recognition [J].Knowledge and Information Systems,2019,59(1):219-250.
[6] LI Shan,DENG Weihong.Deep facial expression recognition:a survey [J/OL].IEEE Transactions on Affective Computing [2021-08-30].https:∥ieeexplore.ieee.org/document/9039580.
[7] DENG Jiankang,GUO Jia,XUE Niannan,et al.ArcFace:additive angular margin loss for deep face recognition [C]∥2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).Piscataway,NJ,USA:IEEE,2019:4685-4694.
[8] 吴慧华,苏寒松,刘高华,等.基于余弦距离损失函数的人脸表情识别算法 [J].激光与光电子学进展,2019,56(24):188-194.
WU Huihua,SU Hansong,LIU Gaohua,et al.Facial expression recognition algorithm based on cosine distance loss function [J].Laser &Optoelectronics Progress,2019,56(24):188-194.
[9] 龙鑫,苏寒松,刘高华,等.一种基于角度距离损失函数和卷积神经网络的人脸识别算法 [J].激光与光电子学进展,2018,55(12):402-413.
LONG Xin,SU Hansong,LIU Gaohua,et al.A face recognition algorithm based on angular distance loss function and convolutional neural network [J].Laser &Optoelectronics Progress,2018,55(12):402-413.
[10] 张文萍,贾凯,王宏玉,等.改进的Island损失函数在人脸表情识别上的应用 [J].计算机辅助设计与图形学学报,2020,32(12):1910-1917.
ZHANG Wenping,JIA Kai,WANG Hongyu,et al.Application of improved Island loss in facial expression recognition [J].Journal of Computer-Aided Design &Computer Graphics,2020,32(12):1910-1917.
[11] WANG Feng,XIANG Xiang,CHENG Jian,et al.NormFace:L
hypersphere embedding for face verification [C]∥Proceedings of the 25th ACM International Conference on Multimedia.New York,NY,USA:ACM,2017:1041-1049.
[12] WANG Hao,WANG Yitong,ZHOU Zheng,et al.CosFace:large margin cosine loss for deep face recognition [C]∥2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition.Piscataway,NJ,USA:IEEE,2018:5265-5274.
[13] WEN Yandong,ZHANG Kaipeng,LI Zhifeng,et al.A discriminative feature learning approach for deep face recognition [C]∥Computer Vision — ECCV 2016.Cham:Springer International Publishing,2016:499-515.
[14] WEN Yandong,ZHANG Kaipeng,LI Zhifeng,et al.A comprehensive study on center loss for deep face recognition [J].International Journal of Computer Vision,2019,127(6):668-683.
[15] CAI Jie,MENG Zibo,KHAN A S,et al.Island loss for learning discriminative features in facial expression recognition [C]∥2018 13th IEEE International Conference on Automatic Face &Gesture Recognition (FG 2018).Piscataway,NJ,USA:IEEE,2018:302-309.
[16] LUO Zimeng,HU Jiani,DENG Weihong.Local subclass constraint for facial expression recognition in the wild [C]∥2018 24th International Conference on Pattern Recognition (ICPR).Piscataway,NJ,USA:IEEE,2018:3132-3137.
[17] LI Shan,DENG Weihong,DU Junping.Reliable crowdsourcing and deep locality-preserving learning for expression recognition in the wild [C]∥2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR).Piscataway,NJ,USA:IEEE,2017:2584-2593.
[18] LI Shan,DENG Weihong.Reliable crowdsourcing and deep locality-preserving learning for unconstrained facial expression recognition [J].IEEE Transactions on Image Processing,2019,28(1):356-370.
[19] ZHAO Kai,XU Jingyi,CHENG Mingming.RegularFace:deep face recognition via exclusive regularization [C]∥2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).Piscataway,NJ,USA:IEEE,2019:1136-1144.
[20] JIANG Ping,LIU Gang,WANG Quan,et al.Accurate and reliable facial expression recognition using advanced softmax loss with fixed weights [J].IEEE Signal Processing Letters,2020,27:725-729.
[21] DHALL A,GOECKE R,JOSHI J,et al.Emotion recognition in the wild challenge 2013 [C]∥Proceedings of the 15th ACM on International Conference on Multimodal Interaction.New York,NY,USA:ACM,2013:509-516.
[22] BARSOUM E,ZHANG Cha,FERRER C C,et al.Training deep networks for facial expression recognition with crowd-sourced label distribution [C]∥Proceedings of the 18th ACM International Conference on Multimodal Interaction.New York,NY,USA:ACM,2016:279-283.
[23] HE Kaiming,ZHANG Xiangyu,REN Shaoqing,et al.Delving deep into rectifiers:surpassing human-level performance on ImageNet classification [C]∥2015 IEEE International Conference on Computer Vision (ICCV).Piscataway,NJ,USA:IEEE,2015:1026-1034.
猜你喜欢
宇航计测技术(2021年3期)2021-08-17 05:28:30
弹箭与制导学报(2020年2期)2020-09-01 02:08:56
计算机与生活(2019年8期)2019-08-12 02:11:34
中国校外教育(2019年12期)2019-04-15 11:14:34
传感器与微系统(2018年7期)2018-08-29 00:44:42
江淮论坛(2018年4期)2018-08-24 01:22:30
自动化学报(2017年4期)2017-06-15 20:28:55
福建中学数学(2016年5期)2016-11-29 02:45:52
电测与仪表(2016年12期)2016-04-11 12:27:22
心理学探新(2015年3期)2015-12-27 06:25:14
