
基于视差放大与超分辨率的三维光场腹腔镜标定
2022-04-01 05:16刘雪岩许聿达雷建昕周光泉张为中
光学精密工程 2022年5期
刘雪岩,许聿达,雷建昕,周光泉,张为中,周 平*
(1.东南大学 生物科学与医学工程学院,江苏 南京 210016;2.南京医科大学第一附属医院,江苏 南京 210029)
1 引 言
腹腔镜是腹部微创手术的重要成像工具,在临床中具有广泛的应用。目前使用的三维腹腔镜均基于双目立体视觉原理设计,需临床医生佩戴专用眼镜并自行在头脑中重建手术对象的三维信息。根据双目立体视觉的成像原理可知,这种三维腹腔镜受使用环境限制,“双目”间的基线很短,其三维成像精度较低,难以独立满足临床中三维测量的要求。具有独立三维测量功能的三维腹腔镜是当前研究的前沿问题。
2017年,Liu等提出了一种基于光场成像原理的三维腹腔镜[1],为三维腹腔镜的研究提供了一个新的思路。但是,Liu等提出的三维光场腹腔镜仅给出了实现可能,对成像模型、标定与成像算法等关键问题并未给出解决方案,且其成像分辨率仅为54×36,无法满足临床需求。标定算法与光场图像的分辨率是影响三维光场腹腔镜标定精度的重要因素。传统的光场成像系统标定均基于双平面模型,采用将成像参数一次标定或多次分步标定的策略进行。通常,一次标定的精度较高,如Dansereau等[2-3]提出的标定方法,缺点在于成像模型中的参数物理含义不清晰,不利于对成像过程的理解。对于多次分步标定而言,后标定的参数精度受前标定精度的影响,如Zhou[4]等提出的标定方法,优点在于参数物理意义清晰。但这些光场标定方法均应用于传统光场相机,并不适用于光场视差较小的光场腹腔镜。此外,成像分辨率是影响标定精度的重要原因,特别是对于光场成像,由于受到带宽积的限制,位置分辨率远低于传统成像分辨率。为解决分辨率低的问题,超分辨率算法是近年的研究热点[5-6]。自卷积神经网络在图像处理领域取得突破性进展后[7],Dong等在2014年提出了首个基于深度学习的图像超分辨方法[8],实现了远超传统方法的超分辨重建效果。随后,一系列基于神经网络结构的方法,如VDSR[9],SR DenseNet[10],SR GAN[11]等,基 于 上 采 样 的 方 法,如 转 置 卷积[12]、pixel-shuffle[13]等,以及基于损失函数的方法,如perceptual loss[14]、adversarial loss[11]等,进一步提升了深度学习超分辨方法的性能。
针对三维光场腹腔镜的标定问题,本文在前期两步标定法工作的基础上,在第二步标定中针对光场视差较小的问题提出了光场视差放大方法。针对光场三维腹腔镜的带宽积问题,提出了基于SRDenseNet的改进型超分辨率网络,分别对位置分辨率与角度分辨率进行超分辨率处理。
2 光场视差放大
基于以往研究成果与Dansereau的虚拟物平面理论,三维光场腹腔镜的标定模型可用如图1的双平面模型表示。基于光场的双平面理论,虚拟物平面代表方向平面(u,v),微透镜阵列(Micro Lens Array,MLA)平面代表位置平面(s,t),因此,将三维光场腹腔镜中的一条光线表示为L(u,v,s,t)。本文将其标定过程分解为光线成像于MLA平面与传感器平面两个步骤。首先,空间中的一个物点P(Xw,Yw,Zw)成像于MLA平面 点p(x,y),其成像过程如式(1)所示:
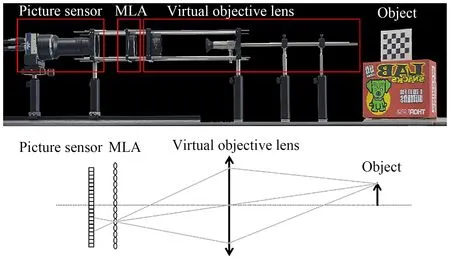
图1 三维光场腹腔镜的双平面模型Fig.1 Two-parallel-plane model of 3D light field endoscope
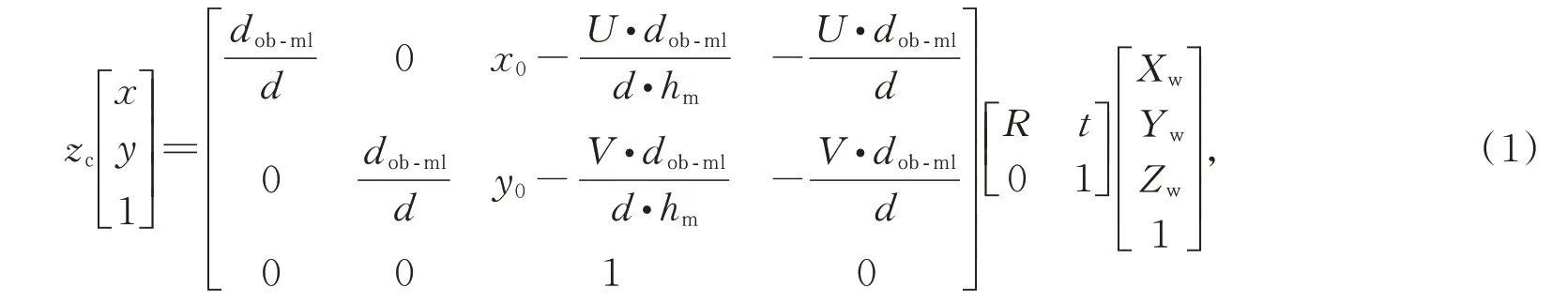
其中:以虚拟物平面中心建立坐标系,Zc为所得的空间物点坐标中的Z方向坐标值,dob-ml表示虚拟物平面与MLA平面间的距离,MLA平面与传感器平面间的距离采用dml-im表示,hm为物方焦平面到虚拟物平面间的距离,d为微透镜直径。此外,(U,V)为光线落于方向平面的坐标,但不是标定中必须求取的参数。根据光场理论,当以中心子孔径图像为研究对象时,(U,V)=(0,0),将式(1)描述的过程进行简化,便于完成第一步标定。除式(1)所示参数外,光场腹腔镜的标定需计算微透镜阵列与传感器平面间的距离dml-im,在传统标定中使用单个特征点的光场视差实现。因光场腹腔镜中的光场视差较小,标定精度较低,本文提出光场视差放大的方法加以解决。光场视差放大方法通过分析两个特征点在不同光场特征图像中的投影距离与dml-im间的关系,克服了单个特征点光场视差小对三维光场腹腔镜标定的影响,其原理如图2所示。
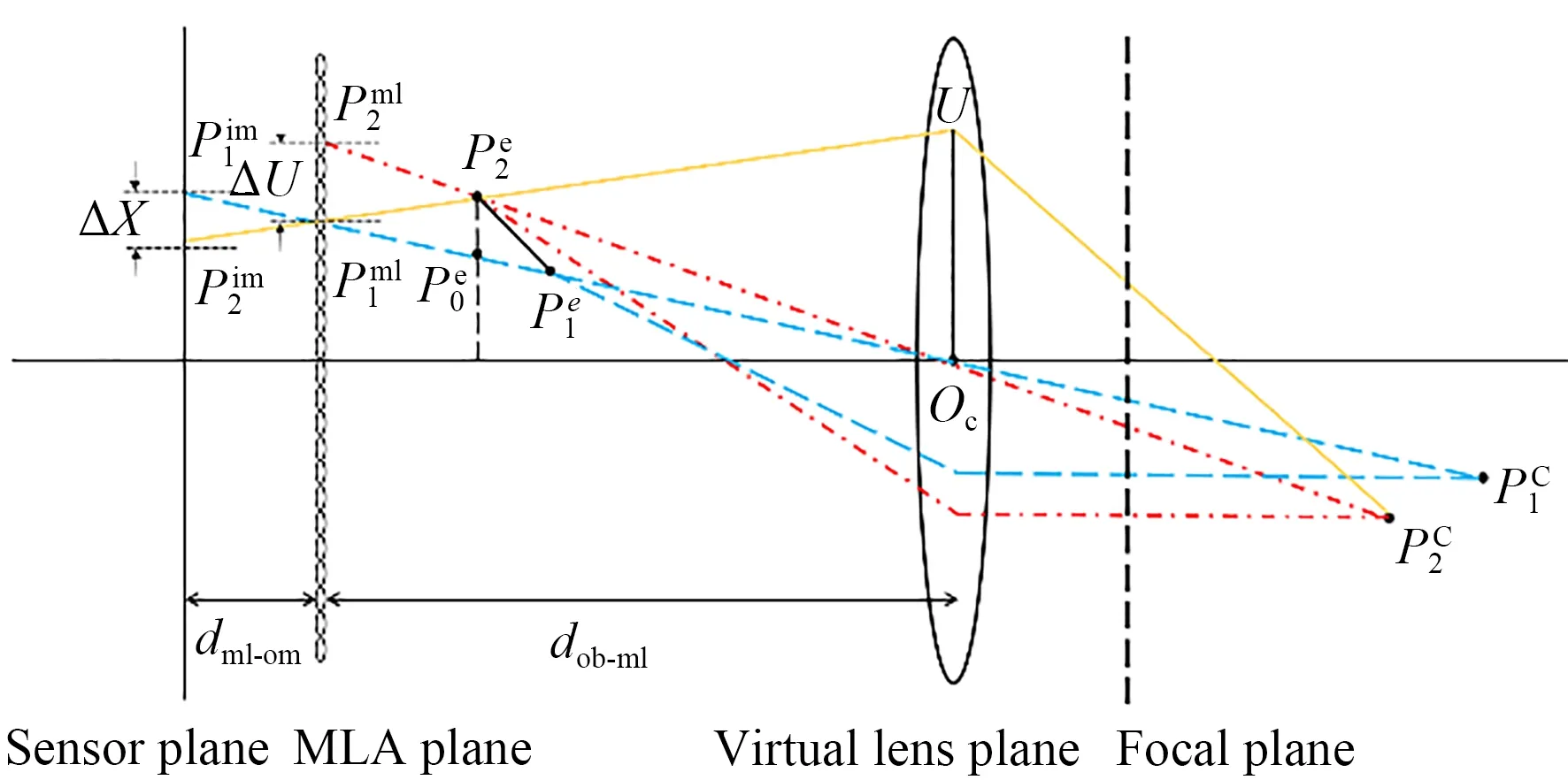
图2 三维光场腹腔镜的成像模型Fig.2 Imaging model of 3D light field endoscope

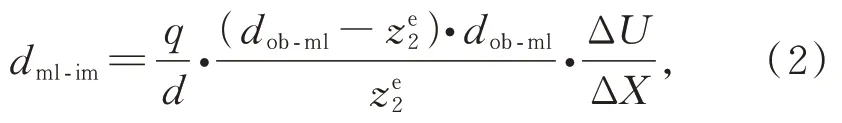
其中:q为传感器平面的像元尺寸;Ze2是特征点P2所成实像Pe2在相机坐标系中的Z坐标,该坐标值在第一步标定后,可通过基于EPI的方法计算得到[15];与单个特征点的光场视差不同,ΔX与ΔU反映在图像中,其对应的像素数值通常大于1个像素,即实现了视差放大功能。三维光场腹腔镜的标定即为求取式(1)与式(2)中的参数。
3 光场图像超分辨率算法
本文使用棋盘格标定板进行光场三维腹腔镜的标定。在标定过程中,使用中心子孔径图像进行第一步标定,其分辨率为354×236;使用元素图像与中心子孔径图像进行第二步标定,元素图像分辨率为13×13。子孔径图像与元素图像分别为光场图像的位置切片与角度切片,本文采用子孔径图像与元素图像分别超分辨的策略,即分别进行光场图像的位置超分辨与角度超分辨运算。本文基于SR DenseNet网络进行改进,针对标定特征点搜索算法对边界属性的要求,将通道注意力机制[16]引入超分辨率网络,总体结构如图3所示。
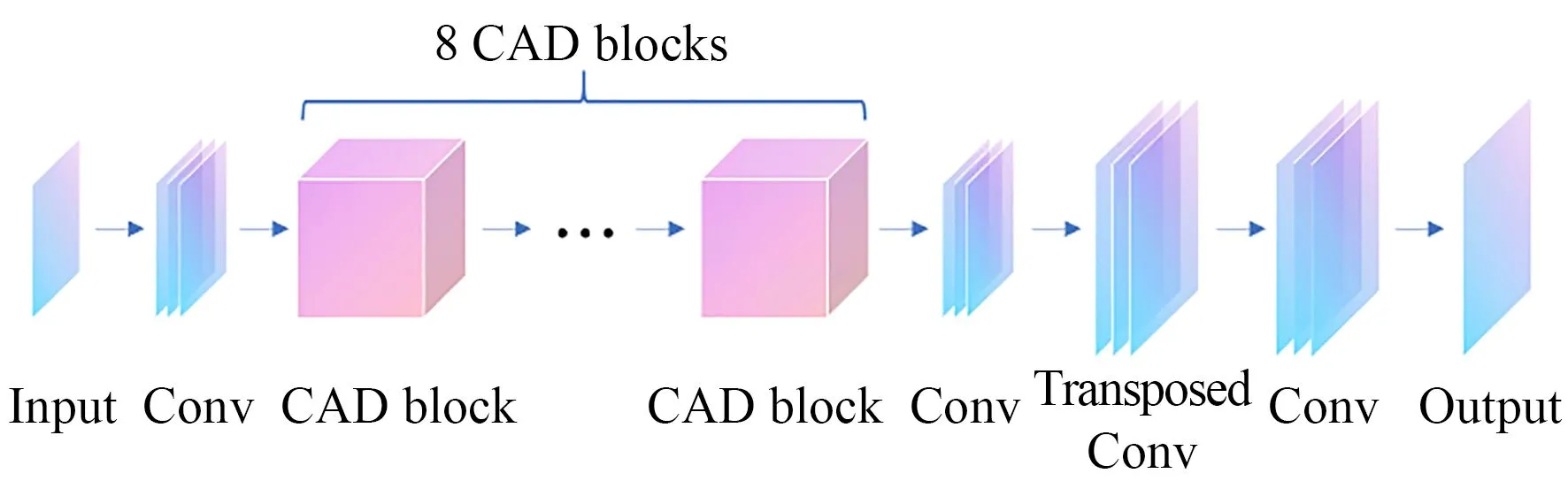
图3 超分辨网络的总体结构Fig.3 Overall structure of proposed SR network
该网络的基本思想是使用多个级联的CAD模块(Channel Attention Dense Block)对输入的低分辨率图像进行特征提取,再通过转置卷积上采样提升图像分辨率。网络共包含68个卷积层与16个全连接层,实现了输入二维图像的宽、高各2倍的超分辨处理。通道注意力机制体现在CAD模块中,输入经过可配置层数的k个密集连接卷积层后,再采用通道注意力机制对不同通道特征的自适应权重分配使重要特征的权重提升,进而增强特征提取与映射的效果。CAD模块的结构如图4所示。
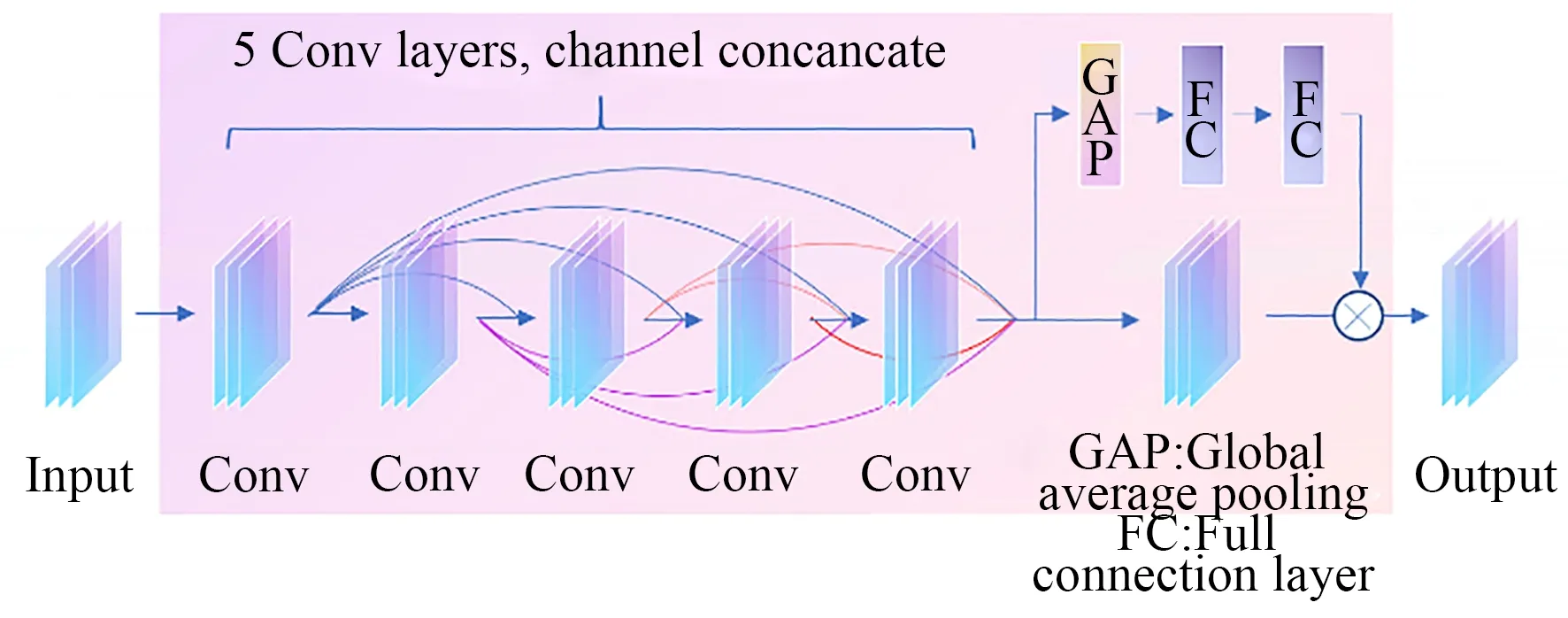
图4 CAD模块结构Fig.4 Structure of CAD module
在传统的卷积操作中,输入特征的每个通道权重是相同的。虽然网络可以通过整体调整对应卷积核的参数值来间接调整每一通道的权重,但这种方法无法实现对不同输入内容的自适应权重分配。在对标定板图像进行超分辨处理时,对于边界区域与其他区域的超分辨率要求不一,反映在网络中为不同通道特征的重要程度不同。为实现通道权重的自适应调整,本文采用通道注意力先对输入特征X的每一通道XC进行全局平均池化,得到对应每个通道的特征值uc:
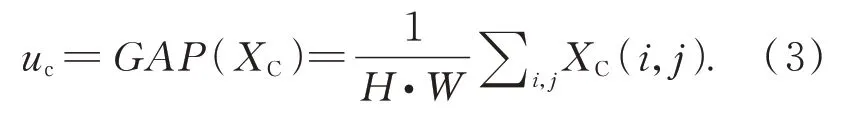
使用全局池化的目的在于获取全局视野,利用整个通道的信息来提取特征。然后,本文使用两个全连接层对特征值进行非线性映射,得到每个通道的权重vc=f(uc),最终将通道乘以对应权重作为输出,即YC=vC×XC。通过上述架构,通道注意力实现了独立于空间特征的通道特征重分配,且这种分配是自适应、通过学习得到的。CAD模块尾部添加的通道注意力部分能够重新分配密集连接机制带来的多通道特征,两者的有机结合进一步提升了网络的超分辨性能。
超分辨率网络的理想应用场景是将现有的子孔径图像、元素图像作为输入,实现分辨率的增强。然而,由于我们无法获得高于现有光场腹腔镜图像分辨率16倍的图像,因此无法在有监督学习的框架下完成网络训练。考虑到低、高分辨率标定板图像的结构相似性,本文将原始图像进行降采样得到低分辨率图像(LR)[8],将原始图像作为高分辨率标签图像(HR),使用此LR-HR图像组作为训练数据完成网络训练。网络训练完成后,再将原图作为输入图像实现超分辨率的目标。角度、位置超分辨网络使用的数据集均为实验室自行拍摄,分别包含4.5万与1.2万组LRHR图像,按照4∶1的比例随机划分为训练集与验证集。
本文的深度学习实验环境为:Intel Core i7-8700 CPU,32 GB内存,Nvidia GeForce RTX 2080Ti GPU。软件平台为Windows10操作系统,Keras 2.2.4深度学习框架。两个网络分别进行了150轮训练,使用Adam优化器和均方误差(Mean Square Error,MSE)损失函数,初始学习率设置为10-5。位置、角度超分辨率网络在训练集与验证集上的峰值信噪比(Peak Signal-to-Noise Ratio,PSNR)训练曲线如图5所示,超分辨率处理结果如图6所示。在训练中,训练集实施了在线数据增强,在训练时对每张输入LR图像进行随机的高斯随机噪声叠加,以提升网络的稳健性与泛化能力。训练进行150轮后,位置超分辨率网络在进行了数据增强的训练集与验证集上的PSNR分别达到约36.6 d B与36.4 d B,角度超分辨率网络的PSNR均在32.8 d B左右。
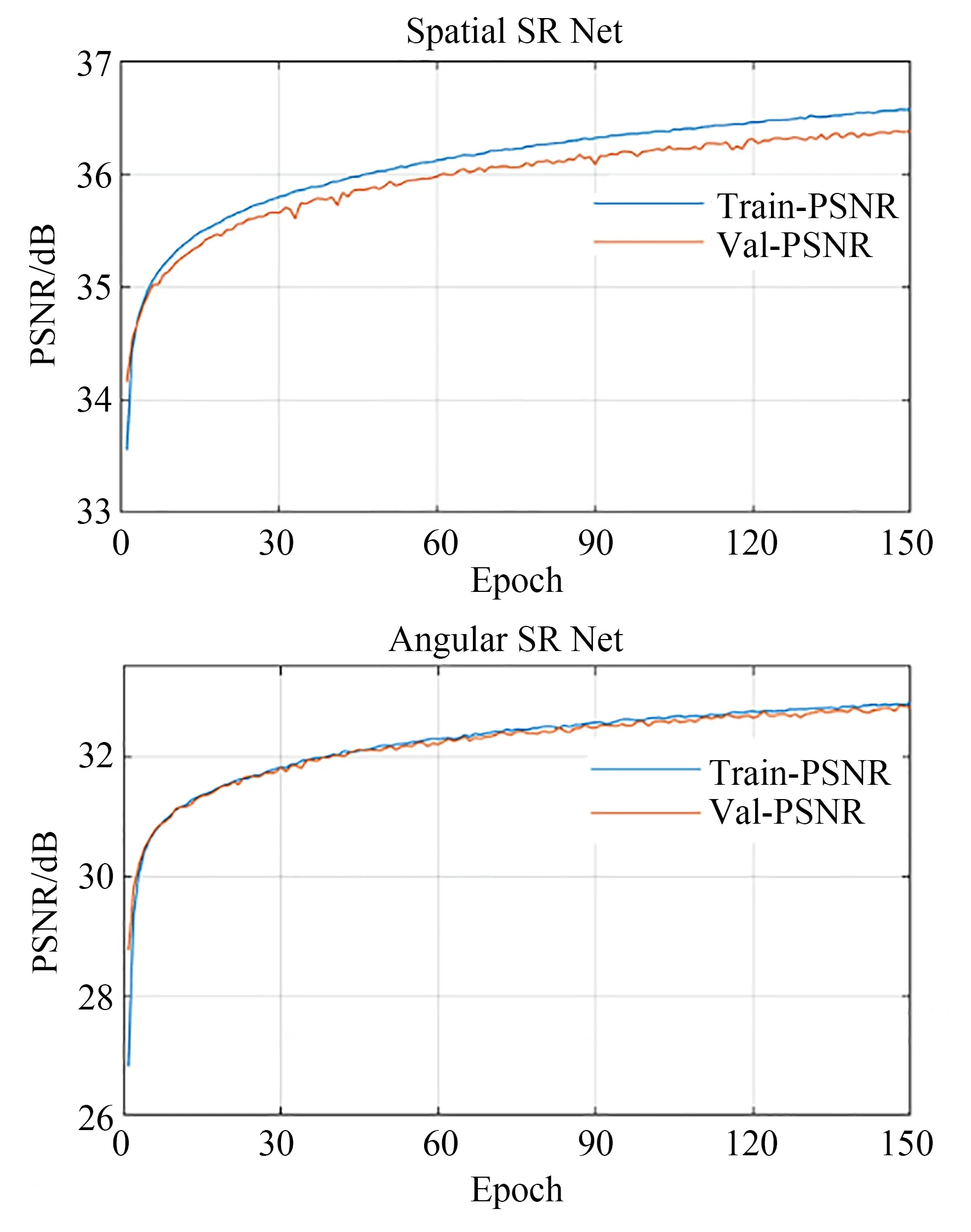
图5 超分辨率网络训练曲线Fig.5 Training curves of super-resolution network
Matlab的光场工具箱在进行元素图像重置时,采用双三次插值计算像素值。从获得“新”像素值的角度出发,双三次插值是一种基本的超分辨率算法。为评价本文提出的超分辨网络的性能,这里分别测试了双三次插值方法、经典SR DenseNet网络和本文提出网络在原始训练集LR图像上的超分辨效果。其中,经典SR DenseNet的训练轮数、优化方法等与本文提出的网络相同。对比结果如表1所示。
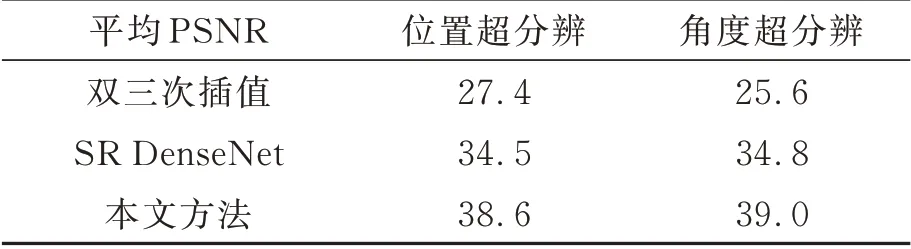
表1 超分辨率算法的性能对比Tab.1 Performance comparison between super-resolution methods (dB)
由表1可知,以标定板图像作为输入图像时,本文所提网络具有更好的超分辨率效果。需要指出的是,位置超分辨与角度超分辨网络的训练集不同,因此两者的PSNR数值不能用于直接对比。
4 实 验
本文实现的三维光场腹腔镜实验系统由二维腹腔镜(沈大)、物镜(f=50 mm),微透镜阵列(Pitch=0.063 mm,f=2 mm),中继镜与单反相机(Canon 600D,5 184×3 456 pixel,q=4.2 um)组成。如图2所示,所有设备采用笼式结构固定,以保证光轴共轴。根据微透镜Pitch与传感器像元尺寸可知,光场腹腔镜的角度分辨率为13×13,子孔径图像分辨率为354×236 pixel。
4.1 超分辨率网络实验结果
本文使用棋盘格标定板完成三维光场腹腔镜的标定。光场腹腔镜拍摄棋盘格标定板,其中心子孔径图像如图6(a)所示。采用本文提出的位置超分辨率网络,将子孔径图像的分辨率提高至原始图像的4倍,即708×472 pixel,所得结果如图6(b)所示。在对式(1)所含参数进行标定时,选择棋盘格的角点作为标定特征点。如图6(b)所示,子孔径图像分辨率增加,角点邻域内的黑白区域边界更加锐利,这些变化有利于提高角点检测的准确性,进而提高标定精度。

图6 标定图像超分辨率结果Fig.6 Super-resolution results of calibration images
基于图2原理进行参数dml-im标定,需要在元素图像中搜索特征点,因此在位置超分辨率之后,采用本文提出的角度超分辨率网络,将元素图像的分辨率,即角度分辨率从13×13提高至26×26。如图6(c)~6(d)所示,元素图像的细节更加清晰,有助于提升特征点的搜索精度。
4.2 三维光场腹腔镜标定
与经典标定方法相似,本文使用中心子孔径图像实现标定,选择棋盘格标定板的角点作为特征点,采用张正友标定法完成式(1)所含参数的标定。针对dml-im,本文选择元素图像的中心点作为图2所示的特征点P1的像点Pim1,选择元素图像中像点垂直于黑白交界的垂足作为特征点P2的像点Pim2。为实现dml-im的标定,如图2所示,需分别确定特征点P1,P2在MLA平面的像点Pml1,Pml2。采用中心子孔径图像,根据光场成像原理,微透镜在微透镜阵列中的位置索引即为该微透镜对应的元素图像中心点在中心子孔径图像中的坐标,因此,与特征点P1的像点Pim1对应的像点Pml1在中心子孔径图像的坐标,即为Pim1对应的微透镜在微透镜阵列中的索引。对于Pml2的确定,依据光场成像原理,元素图像可视为微透镜拍摄主透镜所成的像,因此元素图像中特征点间的几何关系在中心子孔径图像中仍成立,即特征点P2在中心子孔径图像中的像点Pml2应为Pml1垂直于黑白交界的垂足,如图7所示。
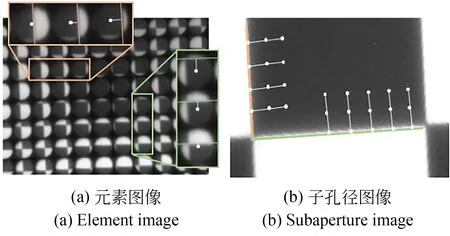
图7 d ml-im标定特征点Fig.7 Calibration feature points d ml-im
本文采用27幅位置、角度不一的标定板图像完成第一步标定,在元素图像、中心子孔径图像中选择300对特征点完成第二步标定。经优化,使用与不使用超分辨率网络的三维光场腹腔镜的标定结果如表2所示。

表2 超分辨率前后三维光场腹腔镜的标定结果Tab.2 Calibration results of 3D LFE with&without super-resolation
本文采用超分辨率前后的反投影误差与直线拟合的确定系数(R 2)评价标定结果以及超分辨率处理对标定性能的提升效果,如图8所示。可见第一步标定中27张图像超分辨前有个别图像的误差显著高于平均值,超分辨处理后这些图像的误差明显降低;使用与不使用超分辨的平均重投影误差分别为0.058 pixel和0.050 pixel,使用超分辨网络后的平均重投影误差降低了约16%。
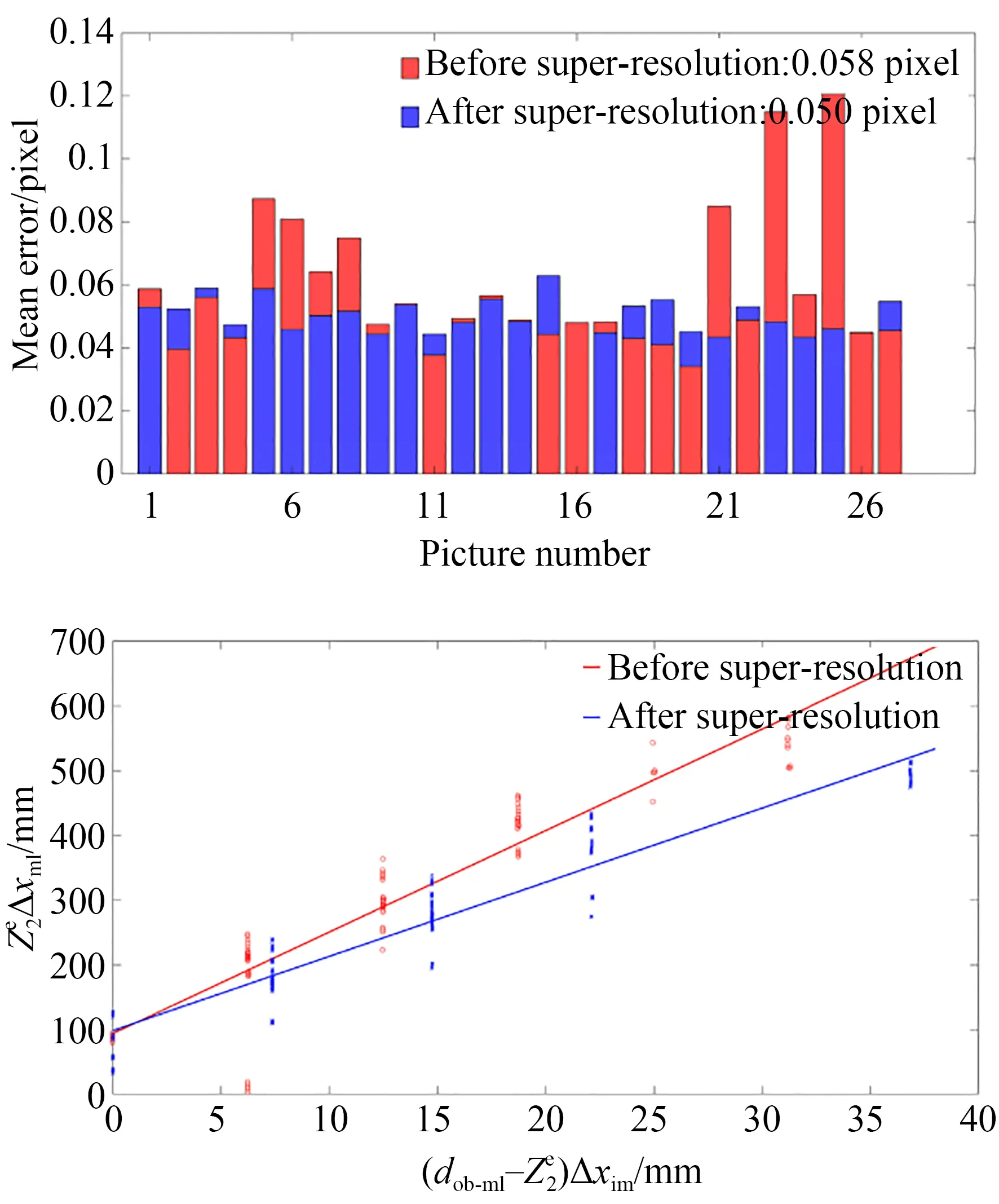
图8 标定反投影误差和R-SquareFig.8 Re-projection error and R-square of calibration
第二步标定中,使用与不使用超分辨网络的直线拟合R 2系数分别为0.86和0.91。可见超分辨后的R 2提升了约6%,数据点在回归直线附近的分布更加密集,说明超分辨网络能够降低第二步标定的随机误差,提升直线拟合的准确度。
综上所述,本文提出的超分辨网络能够提升光场腹腔镜标定图像的清晰度,降低光场腹腔镜第一步和第二步标定过程的随机误差,帮助计算得到更精准的标定参数。
5 结 论
影响三维光场腹腔镜标定精度的主要原因在于较小的光场视差与较低的图像分辨率。针对第一个问题,本文提出了一种光场视差放大的方法,将标定中单个特征点的光场视差计算,转变为两个特征点在不同特征图像中的距离计算,从根本上避免了小视差带来的系统误差;针对第二个问题,本文提出了一种适用于光场图像的超分辨网络,实现了比经典SRDenseNet更清晰、准确的超分辨重建效果,能够有效提升光场腹腔镜图像的角度分辨率与位置分辨率。实验结果表明,光场腹腔镜的角度分辨率从13×13提高至26×26,位置分辨率从354×236提高至708×472,光场腹腔镜的整体分辨率提高了16倍。此外,使用本文方法后,光场腹腔镜标定的反投影误差下降了约16%,直线拟合确定系数提升了约6%。使用超分辨率图像后,在标定方法不变的情况下,标定精度的提高进一步验证了本文超分辨率网络的有效性。在今后的工作中,会考虑在网络中加入3D或4D卷积结构,以获得更好的重建效果。
猜你喜欢
电子与信息学报(2022年5期)2022-05-31
计算机工程(2022年3期)2022-03-12
小型微型计算机系统(2022年1期)2022-01-21
科学(2020年5期)2020-01-05
天津大学学报(自然科学与工程技术版)(2018年6期)2018-05-30
制造技术与机床(2017年11期)2017-12-18
CHINESE JOURNAL OF AERONAUTICS(2017年5期)2017-11-17
雷达学报(2017年1期)2017-05-17
现代计算机(2016年3期)2016-09-23
安徽医科大学学报(2015年9期)2015-12-16
