
多特征融合的电气领域主观题自动评分方法
2022-03-31 12:21王金水郭伟文陈俊岩唐郑熠
贵州大学学报(自然科学版) 2022年2期
王金水,郭伟文,陈俊岩,唐郑熠*
(1.福建工程学院 计算机科学与数学学院,福建 福州 350118;2.福建工程学院 大数据挖掘与应用技术重点实验室,福建 福州 350118)
随着计算机、大数据以及人工智能等技术的兴起,智慧教育运用现代信息技术来实现教育的信息化和智能化。自动评分作为智慧教育的一项重要环节,不仅可以减少教师在阅卷过程中的工作负担,而且能够避免因个人主观因素导致的评分偏差的问题。在电气工程领域中,智慧教育被应用到高校教学、注册电气工程师考试和电网员工入职培训等环节,有助于学员完善电气领域的知识体系。自动评分作为智慧教育的一项重要环节,不仅可以减少教师在阅卷过程中的工作负担,而且能够避免因个人主观因素导致的评分偏差的问题。
现阶段,客观题自动评分算法已经非常成熟,并广泛运用于各类在线考试系统。另一方面,关于作文和短文本等领域无关的主观题自动评分的研究也取得很多成果[1-6]。铉静等[7]基于卷积神经网络的方法,使用全维度和单维度的卷积核进行卷积,得到词语之间长距离依赖信息。李寒[8]提出了基于深度学习的中文句子相似度计算方法,使用大量未标注数据进行训练模型参数,该模型在自动评分中具有更好的性能。胡艳霞等[9]在依存关系树的基础上使用深度学习的方法,采用多头注意力机制Tree-LSTM的神经网络实现句子相似度的计算。彭琦等[10]针对词语间信息内容的差异性的问题,为实现词语信息内容的相似度计算方法,提出了一种相似度计算策略应用于改进的《同义词词林》。但是,将作文或短文本自动评分算法直接应用在特定领域主观题评分的效果并不好[11]。评分算法无法准确地理解电气领域的专业术语,且缺乏对领域知识的理解,容易导致语义分析出现较大误差,进而影响评分结果的准确度。
本文以电气工程学科为背景,从本校电气工程研究生的专业课程中选取部分课程涉及的专业术语,以此为基础构建电气领域本体,并提出了一种多特征融合的电气领域主观题自动评分方法。该方法借助语义词典以及电气工程领域本体,分别完成对通用词语和专业术语的相似度计算,此后,方法通过加权融合句子的词形相似度、词性相似度和搭配词对相似度的特征,计算电气领域主观题的评分。
1 电气领域本体构建
领域本体作为专业性本体,具有非常强的领域区分性。通过构建电气领域本体,能够更准确地获取电气领域的专业术语、数据属性以及术语间的关系,进而有助于完成领域概念查找以及专业术语的相似度计算等任务[12]。将电气领域本体作为主观题自动评分的知识库,能够提高对电气领域专业术语的识别能力和语义理解能力[13]。电气领域本体构建的具体步骤图1所示。

图1 电气领域本体的构建步骤
在构建领域本体之前,需要结合本体的使用对象、应用目的和作用等因素,确定构建的本体所涉及到专业领域和范畴。由于电气领域包含的课程较多,因此本文从本校电气工程研究生的专业课程中的课程体系中选取了《电力系统概述》、《电机与电力拖动》、《电力工程基础》、《发电厂电气部分》等核心课程,从中尽可能多地列出课程涉及的概念、专业术语、以及概念详细的定义等知识。所构建本体所涉及部分概念和术语如表1所示。

表1 电气领域概念和术语示例
完成电气领域的关键知识和术语的获取后,需要确定本体中概念、属性以及彼此之间的关系。其中,关系类型的确定是构建本体过程中最关键的一个环节。由于电气领域专业术语的同一概念存在多种表述,并且概念之间存在上下位关系、部分与整体的关系,导致相关知识在通用词典中难以体现。因此,本文构建的本体关系类型涵盖了同义关系、继承关系、组成关系,以尽可能完整地涵盖相关领域知识。
2 电气领域主观题自动评分方法
如图2所示,多特征融合的电气领域主观题自动评分模型在获得学生答案文本和参考答案文本之后,通过文本分词、词义扩充、停用词过滤、句法分析等技术对文本进行预处理。基于电气领域本体、语义词典,分别计算专业术语和通用词语相似度,并结合三个特征的加权计算结果,得到学生答案文本的相似度。最后进行分数转换,得到学生答案的最终得分。
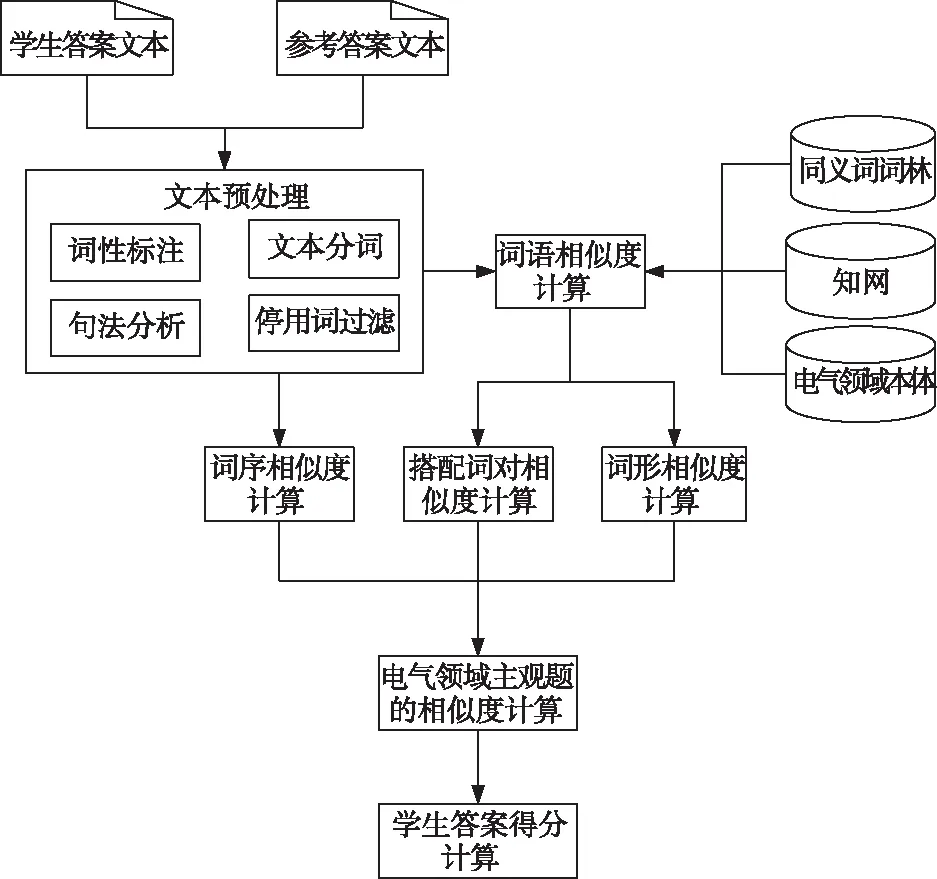
图2 多特征融合的电气领域主观题自动评分模型
2.1 词语相似度计算
根据文本中词语的所属类别(通用词语或专业术语),多特征融合的电气领域主观题自动评分方法采用以下三种方法计算词语的相似度:1)若词语两个词语都属于通用词语,采用融合《知网》和《同义词词林》的通用词语相似度计算方法;2)若两个词语都属于专业术语,采用基于电气领域本体的专业术语相似度计算方法;3)若其中一个词语是通用词语,另一个词语是专业术语。则设定两个词语的相似度为0。
2.1.1基于《知网》的词语相似度计算
与传统的语义词典不同,《知网》通过一系列的义原来描述义项,义项是对词汇的进一步解释。影响义原相似度计算的因素主要有节点密度、节点深度和义原距离等。用y1和y2表示两个义原,根据刘群等[14]提出的义原相似度转换成计算义原距离,y1和y2的相似度计算如下:
(1)
式中,D(y1,y2)代表y1和y2的语义距离,即y1和y2在义原树的路径长度;λ为可调参数。词语的不同语义是通过多个义项进行描述,根据刘群等对义项的研究[14], 将义项分为四个部分,分别为第一基本义原描述、其他基本义原描述、关系义原描述,以及符号义原描述。y1和y2在这四个部分的相似度分别记为S1(y1,y2)、S2(y1,y2)、S3(y1,y2)和S4(y1,y2)。
将Y1和Y2表示为两个义项,则他们的相似度分别由Y1和Y2在四个语义表达式的相似度组合而成,即义项语义相似度计算公式如下:
(2)
式中,ρi为可调参数,ρ1+ρ2+ρ3+ρ4=1。由于部分词语会包含多个义项,因此应取最大义项相似度作为词语C1和C2最终的语义相似度,计算如下:
(3)
2.1.2基于《同义词词林》的词语相似度计算
结合电气领域自动评分的特点,基于《同义词词林》的词语相似度算法考虑的主要因素是词语的语义距离,次要因素分别是分支节点总数n和分支间距k。按照底层到高层的结构顺序,根据朱新华等[15]提供的试验参数设计,本文对连接上下两层的有向边语义距离给予不同权重,分别设置为W1=2.5;W2=1;W3=2.5;W4=0.5。词语C1和词语C2的语义距离计算如式(4)所示。
D(C1,C2)=2×∑d≤i≤4Wi
(4)
节点总数n和分支间距k属于词语相似度计算的次要因素,作用是对语义距离进行修正,并且该修正只能微调,因此将这两个调节参数加入词语相似度计算中,从而降低计算公式对参数n和k的敏感度,以此避免修正幅度过大。由此得到基于《同义词词林》的相似度计算如下:
(5)
2.1.3通用词语相似度计算
通过分析2.1.1和2.1.2小节中两种词语相似度计算方法,可以发现各自计算规则是不一致的。考虑到两个语义词典的知识体系是不一致的,其性质和结构具有较大的差别,因此有必要设计一种融合不同语义词典的通用词语相似度算法以弥补单一方法的不足,从而提高词语相似度计算结果的准确性。该算法根据词语在《知网》或《同义词词林》的收录情况计算两个词语的相似度,算法过程描述如下。
算法1融合《知网》和《同义词词林》的通用词语相似度算法
输入:词语C1和C2
输出:C1和C2的相似度S(C1,C2)
1 if(C1∈ZandC2∈Z-T)
3 else if(C1∈TandC2∈T-Z)
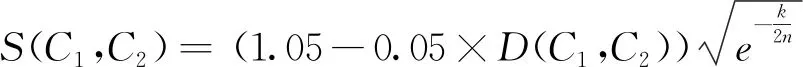
5 else if(C1∈Z-TandC2∈T-Z)
6 {
7G=getSig(C2) //查找C2的同义词集合
8M=NULL
9 ForeachwinG:
11M.append(S(C1,w))
12S(C1,C2)=max(M)//取M集合中最大值
13 }
14 else if(C1∈Z∩TandC2∈T∩Z)
15S(C1,C2)=
16else
17S(C1,C2)=0
18 returnS(C1,C2)
2.1.4专业术语相似度计算
专业词语相似度计算通过引入电气领域本体作为知识库,对该领域的专业术语进行相似度计算。其中专业术语的语义相似度是由节点距离相似度和节点信息相似度构成。在电气领域本体中,各个节点间的有向边代表的作用是不一致的,对于电气领域本体中任意两个节点h和t的节点距离相似度计算如下:
(6)
式中,d(h,t)表示节点h和t之间的语义距离;dmax是电气领域本体中节点的最大深度。
节点信息相似度通过最低公共祖先进行表示,当概念间共享的信息量越多,则说明概念的相似度越高。当上层节点细化到下层的多个节点时,下层节点得到了父节点的信息,因此可以说相同的公共祖先是下层节点间共享信息的表现之一。任意两个节点h和t的节点信息相似度计算如下:
(7)
式中,I(c(h,t)),I(h),I(t)分别是最低公共祖先节点、h节点、t节点的信息量。
综合考虑以上两个因素,得到专业词语的相似度计算如下:
sonto(h,t)=λsd(h,t)+ηsi(h,t)
(8)
式中,λ、η表示调节因子权重。
2.2 句子相似度计算
2.2.1句子的词序相似度计算
词序相似度反映的是参考答案文本A1和学生答案文本A2之间词语的相对位置关系,根据词语的顺序来衡量句子的相似度。本文用m表示文本A1和文本A2中同时出现且仅出现一次的词语集合大小。词序相似度的计算方法如下:
(9)
式中,C(A1,A2)表示文本A1和文本A2的逆序数。
2.2.2句子的词形相似度计算
词形的相似度反映的是参考答案文本A1和学生答案文本A2中所包含的词语在形态层次上的语义相似度。当两个词语相似度大于指定阈值时,记为相似词。结合公式,词形相似度计算方法如下:
(10)
式中,W(A1,A2)表示文本A1和文本A2中相似词的个数;L(A1)和L(A2)分别表示文本A1和文本A2的词语总数。
2.2.3句子的搭配词对相似度计算
搭配词对相似度是从中心词的相似度、依存词的相似度和词语间关系类型三个维度来量化句子相似度。搭配词对可用采用三元组<中心词,关系类型,依存词>进行表示。搭配词对虽然丢失了词语之间的顺序关系,但可以呈现词语之间的内在逻辑关系和深层语义关系。
通过提取文本的搭配词对,并对搭配词对进行简化。首先,运用词语相似度计算方法对搭配词对中的词语进行词语相似度计算,进一步获得搭配词对的相似度矩阵;其次,遍历矩阵并取出每行中数值最大的元素;最后,得到搭配词对的相似度。其中,遍历的元素集合和搭配词对相似度计算方法分别如下:
Nmax(A1,A2)={Amax1,Amax2,…,Amaxp}
(11)
(12)
式中,p表示Nmax(A1,A2)的容量。
考虑到矩阵的不对称性,需要进一步计算文本A1和文本A2的搭配词对相似度。通过对调文本A1和文本A2的位置,可以得到文本A2和文本A1的搭配词对相似度SN(A2,A1)。最终搭配词对相似度的计算方法如下:
(13)
综合考虑句子的词序、词形和搭配词对相似度,采用三个特征全面描述一个答案文本,以此衡量学生答案文本和参考答案文本的相似程度,可以得到电气领域主观题自动评分计算方法如下:
S(A1,A2)=αSo(A1,A2)+βSw(A1,A2)+γSN(|A1,A2|)
(14)
式中,α、β、γ是可调参数,分别代表词序相似度、词形相似度和搭配词对相似度的权重值。
3 试验分析
3.1 试验数据和评价指标
为了验证本文提出的主观题自动评分算法模型的有效性,本文试验引入TF-IDF句子相似度算法的主观题自动评分方法(方法A)、基于语义树的短文本相似度算法的主观题自动评分方法(方法B)[16]作为对照试验,分别对试验数据进行自动评分,统计三种算法模型的评分结果。试验使用的主观题数据来自于《电力系统分析》、《电机及拖动基础》和《发电厂电气部分》三门课程的课后习题。在此之后,我们邀请10个来自本校电气工程专业的研二学生进行答题,并收集其提交的答题结果。我们为所有主观题都提供一份参考答案,并邀请了三位具有相关专业助教背景的研究生对答题结果进行评分。最终,我们将三位研究生评分结果的平均值作为基准评分标准,并通过对比不同评分算法对学生答案的评分结果与手工评分结果的差异来分析不同评分算法的优劣。
本文通过选取均方误差(mean square error,MSE)、平均绝对误差(mean absolute error,MAE)、均方根误差(root mean square error,RMSE)、对称平均绝对百分比误差(symmetric mean absolute percentage error,SMAPE)四个评价指标,进一步客观评价本文方法对于主观题自动评分的效果。
3.2 结果分析
本文方法模型、TF-IDF评分模型、基于语义树的评分模型和人工对每道题目的评分结果如图3所示。
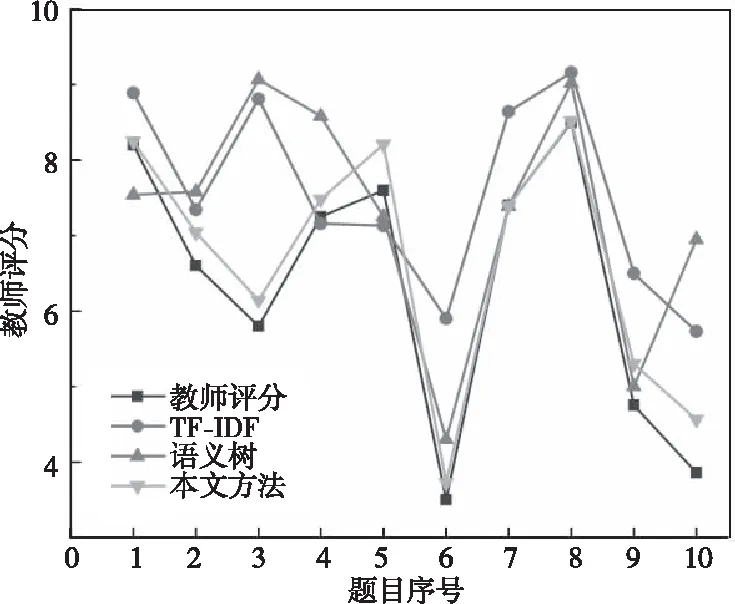
图3 自动评分结果对比
从以上结果可以看出,本文方法得到的评分结果比TF-IDF算法和基于语义依存树的算法得到的评分结果更加贴近人工评分结果,同时波动较小。这主要是由于本文方法在相似度计算过程中考虑了词序、词形和搭配词对三种特征相似度,并应用融合语义词典的算法提高了通用词语的相似度的计算结果。同时主观题相似度计算过程中会涉及到电气领域的专业术语,通过引入电气领域本体,解决了分词结果不全面导致计算结果存在误差的问题。对于含有专业术语较多的答案文本,例如题目1、题目3和题目10,本文算法模型构建的领域本体和搭配词对相似度算法,能够准确识别专业术语,并且较为准确地计算专业术语的相似度。但是,对于题目7和题目9,由于这两道题涉及的电气领域专业术语较少,本文算法引入的电气领域本体并没有较大的影响,与语义依存算法的评分结果差异较小。
为了进一步明确不同算法之间的差异,通过MSE、MAE、RMSE以及SMAPE四个评价指标对评分结果的质量进行评估,其结果如表2所示。
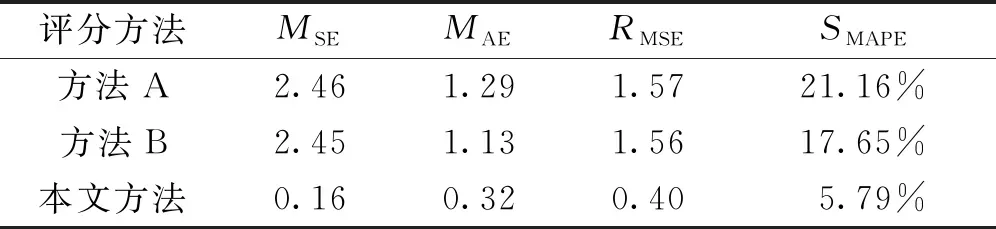
表2 评分方法的评价指标结果
在电气领域的主观题自动评分中,由表2可以看出,本文算法模型能够在MSE、MAE、RMSE和SMAPE都取得最小值。由于三种自动评分方法考虑的特征不一致,导致评分结果有所偏差。TF-IDF评分方法主要考虑的是文本中单词词频,没有考虑句子成分间的语义结构,因此在句子的语义相似度计算方面具有一定的不足。基于语义树的评分方法是从句法的结构信息出发,对于句子的理解较为充分,但是只保留了两层的语义树,从而丢失了深层的语义结构信息,导致自动评分结果不佳。本文方法综合考虑词语的语义结构,句子深层的句法结构,引入领域本体提高了专业术语相似度计算结果的准确率。试验结果表明,本文算法的评分结果与人工的评分结果的拟合度更高,同时相对于基于语义树的评分方法和TF-IDF评分方法,整体的评分效果具有较为明显的优势。
4 结语
本文提出了一种多特征融合的电气领域主观题自动评分方法,该方法引入了电气领域本体,提高了对电气领域专业术语的语义理解,有效地解决了对专业术语分词不准确的问题。同时在文本相似度计算中综合考虑了词形、词序以及搭配词对相似度三个特征,解决了语义关系考虑不全面等问题,进一步提高了主观题自动评分的准确度。
由于学生答案文本具有多样性,如果可以构建更大的参考答案集合,能够增强学生答案的覆盖范围。目前深度学习和神经网络广泛应用于中文信息处理领域,后续可以对基于深度学习的神经网络模型进行研究,并且引入神经网络模型进行主观题自动评分方法中,从而提高句子相似度的计算精度以及评分方法的自适应能力。
猜你喜欢
亚太教育(2022年17期)2022-11-20
中学生数理化·高三版(2022年6期)2022-07-08
齐鲁艺苑(2022年1期)2022-04-19
哈哈画报(2021年10期)2021-02-28
健康人生(2019年4期)2019-10-25
现代商贸工业(2016年22期)2016-12-27
新课程·小学(2016年10期)2016-12-12
图书与情报(2013年1期)2013-11-16
卷宗(2013年6期)2013-10-21
试题与研究·高考语文(2009年1期)2009-04-16
