
基于WKFCM⁃SMOTE和随机森林的风电机组故障诊断
2022-03-28 11:59孙海蓉曹瑶佳张雨晴
山东电力技术 2022年3期
孙海蓉,曹瑶佳,张雨晴
(1.华北电力大学控制与计算机工程学院,河北 保定 071003;2.华北电力大学河北省发电过程仿真与优化控制技术创新中心,河北 保定 071003)
0 引言
随着风电机组运行时间的增加,机组运行状态逐步趋于劣化,风电场运行及维护费用显著增加[1−2]。风电机组故障诊断对降低风电机组维护检修频率,保障风电机组安全、稳定运行和提升风电场经济效益具有重要意义[3]。
目前,风电场主要依靠数据采集与监视控制(Supervisory Control and Date Acquisition,SCADA)系统采集和记录风电机组的运行数据,因此基于SCA⁃DA 数据的风电机组故障研究受到了国内外学者的广泛关注。文献[4−5]在SCADA 数据基础上引入自适应神经模糊推理系统,通过预测误差和专家经验实现风电机组故障状态检测及故障类型分析。文献[6]针对SCADA 系统中历史数据缺失导致模型存在误差的问题,基于互信息理论并结合最大相关最小冗余的原则挖掘特征之间的联系,进行功率数据补齐,并通过相关向量机模型验证了方法的有效性。文献[7]采用核密度−均值法及ReliefF 算法进行偏航齿轮箱运行工况特征选取,基于误差反向传播(Back Propagation,BP)神经网络实现了风机偏航齿轮箱的故障类型诊断。文献[8]使用随机森林进行特征选择,采用网格搜索和交叉验证对极端梯度提升模型进行优化,提升风机故障诊断准确率。文献[9]基于多维缩放方式进行数据降维,降维后数据作为输入量,搭建随机森林模型进行风机轴承故障诊断识别,其识别的平均准确率提升5%。在SCADA 系统数据中,故障数据只占有少部分比重,即正常运行数据数量远大于故障数据数量。因此,SCADA 数据集是不平衡数据集。上述文献在数据优化过程中未考虑故障数据占比小的特点,直接利用SCADA 数据进行后续研究,忽视了故障数据的高度不平衡性对模型参数造成的影响,进而降低了模型精度。
为进一步提高风电机组故障诊断准确率,提出一种基于WKFCM⁃SMOTE和随机森林算法的故障诊断方法。首先依据随机森林袋外数据进行特征重要性排序,通过基于加权模糊核C 均值(Weighted Kernel Fuzzy C⁃means,WKFCM)改进的合成少数类过采样技术(Synthetic Minority Oversampling Technique,SMOTE)算法进行基于故障数据聚类中心的数据集扩充,降低数据集的不平衡度,而后搭建随机森林故障诊断模型,将网格搜索应用于随机森林模型的参数优化中,提升模型精度,保证风电机组故障诊断的准确性。
1 风电机组数据处理
1.1 数据预处理
SCADA 系统采集和记录风电机组运行过程中外部环境和风机主要部件运行状态的数据信息,包括风速、风向、环境温度、功率、发电机转速、电压、电流、齿轮箱轴温度、齿箱油温和电机轴承温度等。考虑到实际数据记录过程中存在大量干扰数据,在模型研究时有必要进行数据预处理,提高模型精度[10]。
风电机组运行状态如图1 所示,主要分为:待启动区、最大风能捕获区、恒功率运行区和停机[11]。数据预处理,剔除待启动阶段数据、停机阶段数据以及有功功率小于0的数据。此外,SCADA 系统对传感器采集数据直接记录,各监测量之间存在较大的量纲差别,因此还须进行归一化处理。

图1 机组运行阶段
1.2 特征选取
SCADA 系统采集记录的数据除与故障有关特征数据外,还包括大量无关特征数据和冗余数据,依据专家经验方法进行特征数据选择极易造成有关数据的缺失。使用随机森林(Random Forest,RF)算法进行数据特征的重要性排序,提升数据质量,可有效避免专家经验下数据选择带来的局限性。
随机森林利用Bagging 思想进行随机抽样,抽取2/3 的样本集数据作为训练集,剩余1/3 的样本数据构成随机森林的袋外数据[12]。假设随机森林由n棵决策树组成,其中每棵决策树的袋外数据误差值为es(s=1,2,...,n),通过对袋外数据加入噪声干扰,得到新的袋外误差值e′s,将其与原始误差值进行比较,进行特征的重要程度判断,并使用平均精度下降指标IMDA进行特征重要性评价。若加入噪声干扰后,袋外误差值有较大幅度增加,则证明该特征重要程度较高。IMDA的计算方法为

图2 为系统特征中与风电机组运行功率关联度较高的特征,将预处理数据按特征重要性进行排序,排序后的数据作为输入,进行基于随机森林算法的故障诊断。

图2 相关特征重要性排序
图3 为数据特征维度与故障诊断准确率曲线。由图3 可知,随着非重要特征的剔除,准确率逐渐升高,当特征维度为[7,10],具有较高的准确率。而随着特征维度的再次降低,准确率逐渐下降。因此,选取模型输入参数特征维度为7,包含转子转速、风速、发电机转速、电机轴承B 温度、叶片角度、齿轮箱轴1温度和齿轮箱轴2温度。
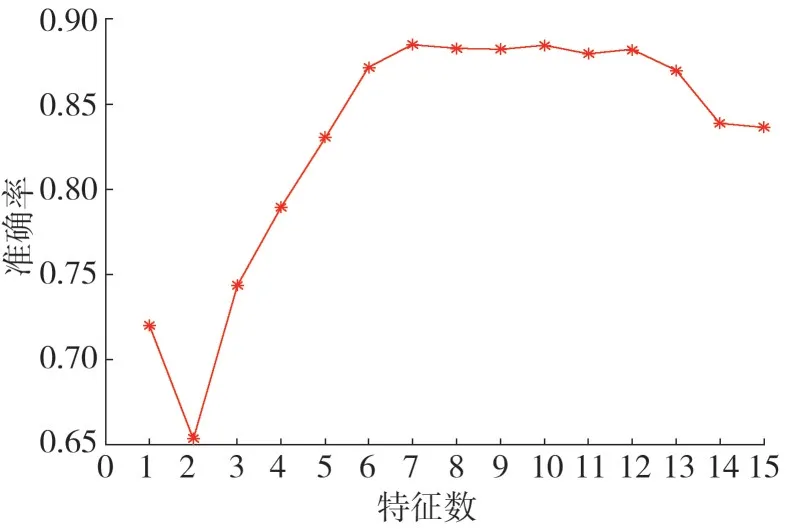
图3 特征数量-诊断准确率曲线
2 基于WKFCM⁃SMOTE 的随机森林故障识别模型
2.1 WKFCM算法
传统的模糊C 均值(Fuzzy C⁃means,FCM)算法是一种无监督模糊聚类算法,其主要思想为构造一个带约束的非线性规划函数,通过迭代实现聚类中心和隶属度矩阵的更新,求解目标函数的最小值,实现数据的聚类[13]。FCM 算法通常应用于低维数据的聚类分析中。
加权模糊核C 均值(Weighted Kernel Fuzzy C⁃means,WKFCM)算法是在FCM 算法的基础上,引入核函数思想,并对特征属性数据进行加权,通过构造一个加权矩阵,实现特征属性对不同特征重要程度的动态调整[14−15],提高聚类中心的精确度。
WKFCM算法的目标函数为
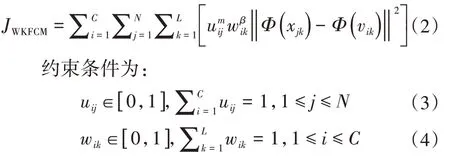
式中:N为数据集样本数;C为聚类数;L为样本数据维度;xj=(xj1,xj2,…xjL)为第j个样本数据;vi=(vi1,vi2,…viL)为第i个聚类中心;uij为第j个样本对第i个聚类中心的隶属度;wik为第i个聚类中心的第k个特征的权值;m、β为模糊指数和权重指数。
Φ为低维到高维的非线性映射函数:

式中:K为核函数,本模型采用的核函数为高斯核函数为高斯参数,特别地,K(x,x)=1。则目标函数可化简为

使用拉格朗日乘数法对隶属度矩阵U和权值W进行求解,可得其迭代公式为:

式中:r、t分别为在i、j、k为定值时对聚类数C和样本维度L的遍历。
设目标函数收敛阈值为ε,若则算法停止迭代,此时聚类中心V和隶属度矩阵U均为最优值。
2.2 WKFCM⁃SMOTE算法
SMOTE 算法是一种基于随机过采样算法的改进算法,基本思想为人工增加少数类数据,从而达到平衡样本数据、改善算法性能的目的[16]。SMOTE 算法基于已有的少数类数据,进行少数类数据点及其邻近数据点之间的线性插值,增加少数类数据的数量,实现少数类数据集的扩充。其插值为

式中:Yi为最近邻数据中第i个数据点,Yi=(1,2,…,M),M为最近邻数据中少数类样本的个数;r为0~1之间的随机数;X为少数类数据。
基于WKFCM 改进的SMOTE 算法使用WKFCM算法的聚类中心替代SMOTE 算法中的随机数据点,保证插值数据类别的精准度。具体实现步骤如下。
1)WKFCM 算法聚类并计算聚类中心。选择原始数据中的少数类数据,WKFCM 算法进行聚类并计算聚类中心。将少数类数据分为C个聚类,聚类中心分别为{c1,c2,…,cC} 。
2)数据插值。与原始数据点相比,聚类中心能更好地表示数据的特性,使用聚类中心进行插值计算可以有效降低数据点的偏向性,保证数据集的平衡。新的插值Xn′ew为
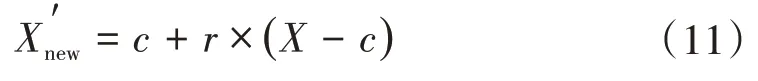
3)不平衡度判断。新生成插值数据并入少数类中,判断数据整体是否满足预设的不平衡度(少数类数据与多数类数据的比值),若不满足,返回步骤2),继续进行数据插值。
风电机组运行数据中故障数据占比较少,模型诊断结果易向多数类数据即正常运行结果倾斜。WKFCM⁃SMOTE 算法,通过基于聚类中心的人工数据插值方式,改善随机样本点插值造成的数据边界模糊问题,降低数据集的不平衡度,有效解决了后续模型诊断过程中存在的诊断结果倾斜的问题。再将WKFCM⁃SMOTE 算法与RF 算法组合,能够更好地解决故障诊断结果不精确的问题。
2.3 故障诊断模型
基于WKFCM⁃SMOTE算法结合随机森林算法的故障诊断模型主要有3个阶段,即对处理后数据进行特征选择、数据聚类分析及插值和基于随机森林算法的故障诊断。组合模型流程如图4所示,算法步骤如下:

图4 WKFCM⁃SOMTE⁃RF 组合算法框架
1)数据预处理,进行SCADA 数据筛选,剔除待启动阶段数据、停机阶段数据及异常运行数据,进行数据的归一化处理;
2)基于随机森林的袋外数据进行特征重要性排序,实现数据的降维处理,降低后续模型复杂度;
3)WKFCM 算法计算数据聚类中心,SMOTE 算法基于聚类中心进行少数类数据插值,并进行数据集不均衡度判断;
4)基于网格搜索算法进行随机森林模型参数优化,提升随机森林模型计算结果的准确率;
5)进行模型验证,通过模型评价指标验证模型准确性。
3 试验结果与分析
3.1 模型参数优化
本文数据源自华北某风电场SCADA 系统采集记录的1.5 MW机组2号风机2018年5月15日至5月17 日的运行数据,已知机组在5 月16 日13:21 发生故障并进行停机维修。经数据处理后共有数据3 109条,包含机组正常运行状态和故障状态。
使用网格搜索算法和K折交叉验证进行模型的参数寻优。K折交叉验证将数据集划分为K份,轮流取其中的1 份作为测试集,剩余数据作为训练集进行参数优化,重复K次至样本中每个数据均在测试集中出现一次[17],本模型取K值为5。为减少网格搜索算法所用时间,提升参数准确性,首先进行随机森林模型参数取值范围的粗调,通过逐渐缩小参数取值范围、降低搜索步长的方式确定模型参数。随机森林参数取值如表1所示。

表1 随机森林参数取值
3.2 模型结果
对于二分类问题而言,判别结果分为TP、FP、TN、FN共4种情况。二分类的混淆矩阵如表2所示。

表2 二分类混淆矩阵
本文选择准确率A、精确率P、召回率R、F1值来衡量不同模型算法性能,同时选取接受者操作特性(Receiver Operating Characteristic,ROC)曲线和AAUC完善二分类评价指标。准确率A指分类正确样本占全部样本的比例;精确率P指预测为正类样本中真正的正类所占的比例;召回率R指所有正类中被预测为正类的比例;F1值兼顾精确率和召回率;ROC 曲线以假阳性率为横坐标、真阳性率为纵坐标,曲线越接近左上角的点,模型效果越好;AAUC指ROC 曲线覆盖区域面积。

处理后的数据,分别进行基于FCM、KFCM 和WKFCM 算法的聚类中心计算。聚类算法评价指标对比如表3所示,各模型评价指标对比与表4所示。
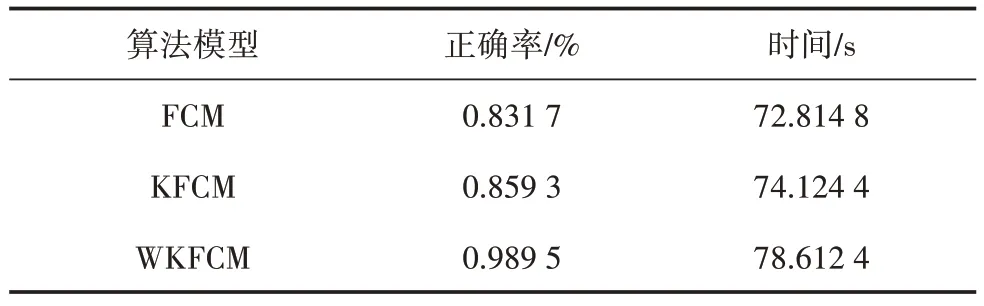
表3 聚类算法准确率

表4 模型评价指标
从表3 中可知,3 种聚类算法均需较长运行时间,其中WKFCM 算法耗时最长,但WKFCM 聚类算法的正确率明显高于FCM 和KFCM 算法,说明其聚类中心对范围内数据具有更好的代表性。
表4 中RF 表示未插值数据直接作为模型输入搭建的故障诊断模型,FCM⁃SMOTE⁃RF、KFCM⁃SMOTE⁃RF、WKFCM⁃SMOTE⁃RF 分别表示FCM⁃SMOTE、KFCM⁃SMOTE、WKFCM⁃SMOTE 数据插值与随机森林算法相结合的数据模型。由表4 可知,插值数据模型A值、AAUC值及F1值均明显高于未插值数据模型,其中WKFCM⁃SMOTE⁃RF 模型的A值、AAUC值、F1值均为最高,分类准确率A比FCM⁃SMOTE⁃RF、KFCM⁃SMOTE⁃RF 模型提高了4%~5%,F1值提高了1%,AAUC值达到了0.979,表明基于WKFCM⁃SMOTE 和随机森林的风电机组故障诊断模型提高了故障诊断准确率,验证了其在风电机组故障诊断中的优越性。
3.3 模型对比
为验证模型的有效性,建立基于逻辑回归(Lo⁃gistic Regression,LR)算法的风电机组故障诊断模型进行对比试验,使用相同数据集进行模型测试,两种模型的评价指标对比如表5 所示,ROC 曲线对比如图5所示。

图5 对比模型ROC曲线

表5 对比模型评价指标
由表5 和图5 可知,在风电机组故障诊断中,WKFCM⁃SMOTE⁃RF 算法在A、P、R和F1等几项重要指标值均超过LR 算法,且在ROC 曲线中LR 算法曲线基本处于模型曲线右下方,因此WKFCM⁃SMOTE⁃RF 模型比逻辑回归模型对风电机组故障诊断更加准确。
4 结语
提出基于WKFCM⁃SMOTE和随机森林算法的风电机组故障诊断方法,随机森林能够有效进行特征选择,消除冗余特征的不良影响;WKFCM⁃SMOTE 算法进行少数类数据的扩充,改善SMOTE 算法模糊数据边界的问题,保证数据的准确性,降低数据集的不平衡度;建立基于随机森林的风电机组故障诊断模型,将网格搜索应用于随机森林模型参数优化中,提升模型精度,满足风电机组运行安全、稳定及高效的要求。试验结果表明,基于WKFCM⁃SMOTE和随机森林算法的模型具有较高的故障诊断准确率,证明了所提方法在风电机组故障诊断中的有效性。
猜你喜欢
导航定位学报(2022年3期)2022-06-10
现代电力(2022年2期)2022-05-23
一重技术(2021年5期)2022-01-18
建材发展导向(2021年13期)2021-07-28
海峡姐妹(2020年8期)2020-08-25
新生代(2018年16期)2018-10-21
电子制作(2018年10期)2018-08-04
北京航空航天大学学报(2017年2期)2017-11-24
北京航空航天大学学报(2016年6期)2016-11-16
风能(2016年12期)2016-02-25
