
基于财务指标的股价涨跌预测模型
2022-03-28 07:00:14刘新月程希明
北京信息科技大学学报(自然科学版) 2022年1期
刘新月,程希明
(北京信息科技大学 理学院,北京 100192)
0 引言
股票市场是一个具有投机性的领域,投资的高回报往往伴随着高风险,这种特性促使人们开始寻找在获得高回报的同时能够最大程度降低风险的方法。于是国内外许多研究者开始运用各种分析方法,试图能够准确预测出股票价格趋势。对股票价格趋势的研究可以分为两类:基本面分析和技术面分析。其中技术面分析单纯着眼于金融市场最简单的供求关系变化规律,通过交易数据构建指标,预测股价走势;而基本面分析则是对股票的内在价值进行挖掘和评估。
在对股票的基本面研究中,财务指标至关重要,它是企业总结和评价财务状况以及经营成果的相对指标。陆正飞等[1]以中国A股上市公司为研究对象,研究财务指标对股票超额回报的解释能力,发现反映公司发展能力的财务指标对股票投资者具有较强的指导意义,但存在财务指标的选取范围小、投资时间界定存在偏差等问题。蒋艳霞等[2]总结国内外学者通过财务数据预测股票的研究现状,得出了财务数据和数据挖掘方法适用于股票收益预测的结论,也指出了国内的预测方法较为单一的现状。随着国内证券市场逐渐完善,越来越多的国内研究者开始尝试使用不同的算法对股价进行预测分析。多因子模型[3]、神经网络模型[4]、随机森林(random forests,RF)模型[5]、结合参数寻优算法的机器学习模型[6]等都被应用于股价趋势预测。但因为每种模型都有其局限性,对数据的要求都有一定的特点,得到的预测效果并不理想。随着数据挖掘技术日趋成熟,许多学者开始尝试用组合模型的方法来提高股票数据与模型的适配性,以得到更加精确的预测结果。例如Huang[7]开发的支持向量回归(support vector regression,SVR)和遗传算法(genetic algorithm,GA)组合模型,贾秀娟[8]采用的基于随机森林的支持向量机(support vector machine,SVM)模型,以及傅航聪等[9]结合K近邻算法、支持向量机算法和时间序列算法的优点,整合其结果提出的综合预测算法等,都取得了优于基准的预测效果。需要注意的是,以往的大多数研究都没有处理财务指标数据存在的多重共线性问题。针对这一问题,胡照跃等[10]利用主成分分析法(principal component analysis,PCA)对输入变量进行降维处理;刘玉敏等[11]在模型建立之前选择随机森林和基于分类精度的序列前向选择方法对指标进行特征提取,这两种方法都在不同程度上提升了模型的精确度。
本文综合考虑6大类财务指标作为特征变量,以股票财报发布的实际日期为投资开始日,向后截取一个月作为研究区间,以求更大程度地提升数据时效性和预测准确性。重视数据间共线性问题,在建模时,提出递归特征消除法+随机森林、主成分分析+支持向量机、岭回归3种具体模型,进行对比分析。另外,本文提出对建模时输入的训练集和测试集的分配方式进行改进。在以往的研究中,大多数是从训练集数据中分割一部分作为测试集,本文提出使用与训练集有同种季节特征的现实数据作为测试集,为模型赋予了充分的现实应用价值。
1 机器学习算法
股市是一个复杂的非线性系统,影响因素众多,所以选取的研究算法应该擅长处理非线性高维数据。在之前的研究中可以看出,机器学习算法在这方面的表现普遍优于传统的统计分析方法,所以本文首先选取在股价预测方面表现较好的随机森林和支持向量机算法。针对特征变量之间存在的多重共线性,本文采用共线性处理方法和机器学习算法结合的方法,提出递归特征消除+随机森林、主成分分析+支持向量机两种具体模型,并与专门处理共线性问题的岭回归算法进行对比。
1.1 递归特征消除与随机森林
随机森林是一种包含多个决策树的分类器,是利用多棵树对样本进行训练并预测的一种集成算法。决策函数为
(1)
式中:MO为取众数的函数;hi(xt)为第i棵决策树对测试集样本xt的决策结果;Ntree为决策树个数。
针对特征提取问题,随机森林可以在决定类别时,利用袋外误差原理评估特征变量的重要性,再结合递归特征消除法对不同的特征组合进行交叉验证,通过计算其决策系数之和,得到不同特征组合的重要程度,选取出最佳的特征组合,从而克服变量间存在的共线性问题。特征X的重要性为
(2)
式中:Ei1为第i棵决策树使用相应子数据集袋外数据计算的袋外误差;Ei2为随机对袋外的所有样本的特征X加入噪音干扰后的袋外误差。
因为随机森林可以看作是将决策树模型嵌入到装袋算法框架中,所以参数寻优的方式可以从框架和决策树两方面考虑。首先对RF框架进行参数寻优,主要是对决策树个数(n_estimators)进行调节,将其他参数设为默认值,设置n_estimators的参数范围为(1,100),步长为1,对训练集进行10折交叉验证,得到使准确率最高的决策树个数。在对决策树参数进行调节时,主要考虑最大特征数(max_features),将n_estimators设为前面求解出的最优值,其他参数设为默认常数,训练集中有19个股票因子,所以max_features的范围是(1,18),步长为1,同样采取10折交叉验证,得出最优的最大特征数。最后利用寻得的最优参数组合对模型进行训练。
1.2 主成分分析与支持向量机
支持向量机是一类按监督学习方式对数据进行二元分类的广义分类器,是处理非线性分类问题的常用方法。但支持向量机对于处理多重共线性问题的能力较弱,所以在建模之前需运用主成分分析法进行数据降维,消除多重共线性。
在处理具有非线性且高数据维度特点的股市问题时,SVM需要用到核函数来计算映射函数的内积。在4种核函数中,径向基核函数(radial basis function,RBF)核是处理非线性问题的首选,因为只带有惩罚参数C的线性核与带有核参数(C,σ)的RBF核具有相同的性能。对于某些参数,Sigmoid核的行为也类似于RBF核。另外,超参数的数量影响了模型选择的复杂性,多项式核比RBF核具有更多的超参数。所以本文选取RBF核函数,构造最优化问题:
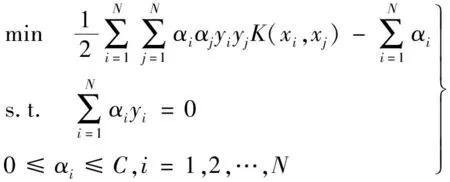
(3)
决策函数为
(4)

在非线性支持向量机的具体应用中,参数的调节非常重要。对于RBF的参数寻优,本文使用10折交叉验证对核参数(C,σ)进行网格搜索。两个参数的初始搜索范围为(C>0,σ>0),最优参数组合需要不断进行调试来寻找,首先进行粗网络的寻找,在网格上确定一个“较好的”区域之后,就可以对该区域进行更精细的网格搜索。因为交叉验证的准确性是正确分类的数据的百分比,所以交叉验证搜索出的最优参数组合是使训练集分类正确率最高的参数组合。本文中SVM建模最终寻找出的精细网格搜索范围为
(C:[0.1,1,10,20],σ:[0.01,0.1,1,10])
1.3 岭回归
岭回归是针对自变量之间存在多重共线性问题提出的一种改进最小二乘回归的方法。
岭回归算法也可以处理分类数据。岭回归算法中有分类器变体RidgeClassifier,可以在回归的基础上,将二进制目标转换为{-1,1},然后将该问题视为回归任务,优化与回归模式相同的目标函数,预测类对应回归预测的符号函数。分类型优化问题为
(5)
决策函数为
f(x)=sign(X·β*)
(6)
式(5)、(6)中:λ为岭参数;β*为系数最优解。
岭回归算法中需要估计的参数为岭参数λ>0,在寻找最优参数时,使用10折交叉验证的网格搜索,首先确定粗网格搜索范围,一般不宜过大,本文设置为[0.001,0.01,0.1,1,10,100],第一次搜索得出粗略的参数值,再围绕此值展开精细搜索,直到参数值不再变化,即为最优岭参数。
2 建模与分析
2.1 数据集介绍
本文使用通过Choice金融终端获取的创业板股票的年度报告数据,选取报告中的19个财务指标作为特征变量,具体如表1所示,选取年报公布日期后一个月的股票收盘价的涨跌类别作为因变量。具体为:
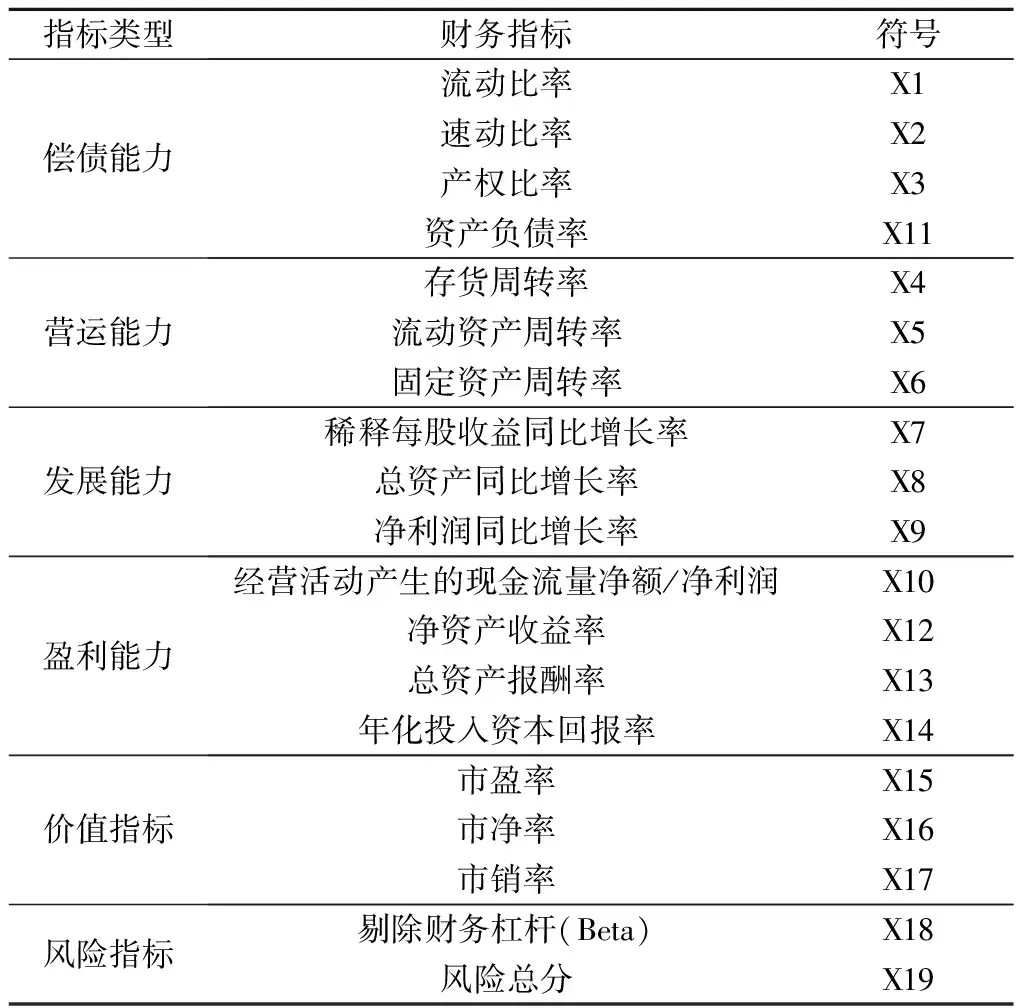
表1 财务指标类别及其符号
1)训练集:提取2019年创业板股票的年报数据和年报公布后一个月内的收盘价涨跌趋势,去除ST股票和具有缺失值的股票后,剩余638只股票。
2)测试集:提取2020年创业板股票的年报数据和年报公布后一个月内的收盘价涨跌趋势,去除ST股票和具有缺失值的股票后,剩余149只股票。
需要注意的是,许多股票在季度报告或者年度报告中都会有分红配股的操作出现。对公司来说分红配股可以壮大经营,扩大公司资金实力,但是分红配股的实施与后期除权除息操作会造成股价陡然下跌,所以需要对有分红配股操作的股票收盘价进行前复权,即保持现有价位不变,将以前的价格缩减,将除权前的K线向下平移,使图形吻合,保持股价走势的连续性。前复权可以消除由于除权除息造成的价格、指标的走势畸变,避免因除权除息导致的股价下跌对模型预测的影响。
2.2 建模流程
本文进行创业板股票价格涨跌预测的流程如图1所示。
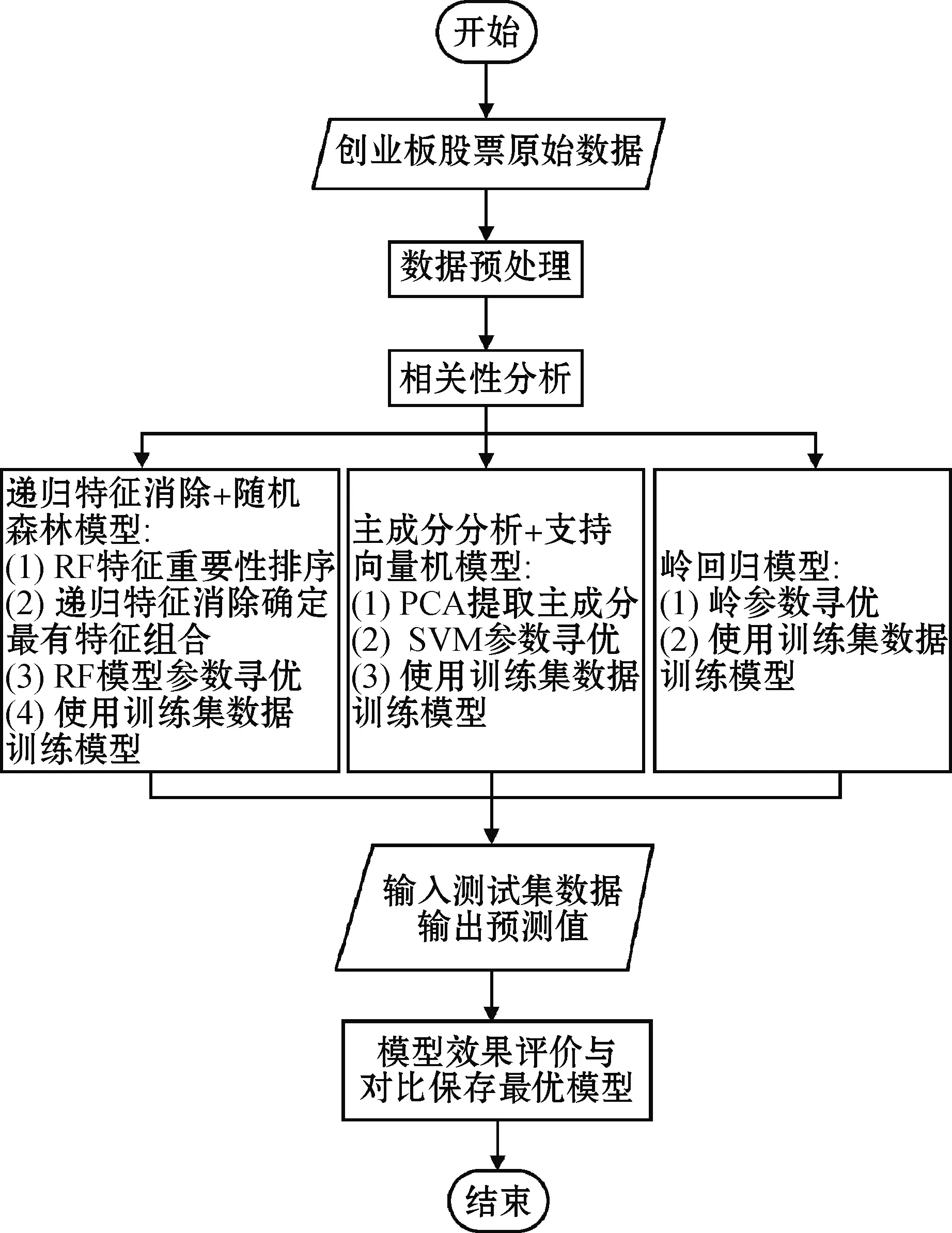
图1 创业板股价预测流程
在数据预处理阶段需要对原始的训练集和测试集数据进行简单的处理。对所有数据进行缺失值、异常值检测和剔除,然后对数据进行标准化来消除量纲影响。将因变量由连续型变量转化为{0,1}型分类变量。
对数据预处理后的特征变量进行相关性分析,得到相关性热力图,如图2所示。热力图显示有多处颜色呈现深蓝色,表明特征之间的正相关性较强,颜色趋向白色表明特征之间的负相关性较强。由此可以得出结论,特征变量之间存在多重共线性。因此采取共线性处理是很有必要的。

图2 特征变量相关性热力图
分别使用递归特征消除+随机森林、主成分分析+支持向量机、岭回归3种模型,在训练集上训练模型并且在测试集上进行测试,对比3种模型的数据适配性及预测准确性。本文对于模型分类性能评估选用的指标是预测精度、KS统计值以及AUC统计值。预测精度为
(7)
KS统计值为
(8)
AUC统计值为
(9)
2.3 结果及评价
使用3种不同的模型训练数据集,得到的模型性能指标整理后如表2所示。可以看出,运用递归特征消除+随机森林算法拟合的模型,在训练集和测试集上的3种评价指标差值都较大,模型在训练集和测试集上的表现相差较大,表明存在过拟合现象,模型不适用于此类股票数据,故舍弃该模型。主成分分析+支持向量机组合模型在预测精度、KS统计值以及AUC三种评价指标上均表现良好。本文的训练集和测试集是取自不同年份、相同月份的股票数据,而模型在训练集和测试集上的效果相差很小,说明模型对于此类股票数据的适配性良好。岭回归分类器算法适用于处理多重共线性的问题,所以在此类股票数据上的表现很好,达到了和主成分分析+支持向量机组合模型同样高的预测精度,而另外两类指标AUC和KS具有相似的判别标准,即在训练集和测试集上的分数相同的情况下,差异越小,说明模型的适配性越高,所以在数据适配性的方面,岭回归表现不如主成分分析+支持向量机组合模型。

表2 三种模型效果评估
3 结束语
本文应用机器学习理论,基于股票财务指标数据的多重共线性,提出递归特征消除法+随机森林、主成分分析+支持向量机、岭回归3种模型,对创业板股票短期价格进行预测并对比模型效果。此外,本文在训练集及测试集的选择方面进行了创新,应用同季度不同年份的股票数据作为训练集和测试集,最大程度消除季节性特征,使模型的实际应用价值有所提升。从模型的仿真结果来看,主成分分析与支持向量机的组合模型有着高达77.18%的预测精确率,且模型在训练集数据和测试集数据上均有良好的表现,有极高的数据适配性,将此模型用于创业板股票的短期预测有着较强的准确性和可行性。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28 07:02:46
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19 08:28:36
科学与财富(2021年3期)2021-03-08 10:56:02
——以多重共线性内容为例
长沙航空职业技术学院学报(2019年2期)2019-07-13 01:45:42
温州大学学报(自然科学版)(2019年2期)2019-06-04 11:52:00
股市动态分析(2016年23期)2016-12-27 19:01:58
股市动态分析(2016年22期)2016-12-27 10:39:02
股市动态分析(2016年7期)2016-09-29 11:18:25
股市动态分析(2016年4期)2016-09-29 08:39:10
高中生学习·高三版(2016年9期)2016-05-14 09:12:05
