
一种关系—图数据库混合存储系统设计
2022-03-28 06:31:42王佳慧马利民
北京信息科技大学学报(自然科学版) 2022年1期
王 宁,张 伟,2,王佳慧,马利民,2
(1.北京信息科技大学 计算机学院,北京 100101;2.北京信息科技大学 北京材料基因工程高精尖创新中心,北京 100101;3.国家信息中心信息与网络安全部,北京 100045)
0 引言
关系型数据模型最早在1970年由E.F.Codd[1]提出,逐渐成为主流数据库的常用模型。同时,随着互联网的发展,在社交、金融、物流、新零售等多个领域中,多表连接查询应用越来越普遍,涉及决策支持和复杂数据的数据库应用程序通常根据多表连接查询来得到其期望的结果。在关系数据库中进行复杂的多表连接查询会导致两种结果:一是数据库需要通过关联表间接地维护实体间的关系,导致数据库的执行效率低下,同时因此产生的关联表的数量急剧上升;二是面对大量实体之间的关系描述,传统的关系型数据库达到性能瓶颈。
在这种背景下,图数据库应运而生,且因其善于处理大量复杂、互连接、低结构化的数据受到了广泛的关注。但图数据库也存在缺点。Cheng等[2]经过大量的实验表明,相较于关系数据库,在处理多表连接、模式匹配、路径识别等查询方面,图数据库拥有更高的性能;但是,在分组、排序、聚合等查询方面,关系数据库的执行效率明显优于图数据库。而在处理包含多表连接、分组、排序、聚合等多种操作的复杂查询时,无论是关系数据库还是图数据库,都存在着一定的局限性。
为了解决这一问题,当前的研究方向主要可以分为两种:一种是以关系数据库为基础,结合图数据库潜在的可扩展性,使得关系数据库可以有效地存储和查询图结构的数据[3-4];另一种是将关系数据库和图数据库进行结合,构建多数据库的混合存储系统,以此充分发挥各个数据库的优势,掩盖单一数据库的不足。
A.Lentz[5]提出的OQGraph通过模仿存储引擎将用户查询代理表的操作解释为图遍历指令。尽管通过提供更多以图为中心的界面可以在某种程度上改善用户的体验,但是性能却无法与单一的图数据库相比。Sun等[6]提出的SQLGraph将关系存储用于存储邻接信息,并用JSON文件存储顶点和边的属性等信息,尽管这种方法确实提高了以图为中心的查询的性能,但是会损害常规查询的性能。Christopher J.O.Little[7]通过对关系数据库进行扩展提出了Grapht模型,该模型设计了一个内置的内存存储,通过查询处理器会将用户的查询分为针对关系数据库的以行为中心的子查询和针对图处理程序的以图为中心的子查询。
Jeff Shute等[8]研究的混合数据库F1,结合了NoSQL系统的高可用性和可伸缩性以及传统SQL数据库的一致性和可用性。Martin Grund等[9]提出了一种特定于企业应用程序的数据库系统,该系统将语义数据和图数据直接包含在同一个存储引擎中,并结合了在单个内存数据库引擎中处理关系数据和图数据的优点。
基于以上研究背景,本文结合MySQL和Neo4j的特点,设计了一个混合存储系统:定义了一种类SQL语言C-SQL用来连接MySQL和Neo4j,为用户提供统一的数据库访问接口,以完成混合系统的查询工作;使用动态成本模型,来判断查询在MySQL和Neo4j中的执行时间,以挑选最优的查询计划,完成对复杂查询的优化;最后,为保证MySQL和Neo4j之间的一致性,通过解析MySQL的Binlog日志中的变更操作信息,获取增量数据实现数据从MySQL到Neo4j的同步工作。实验结果证明,与单一的MySQL和Neo4j的查询效率相比,本文提出的混合存储系统在保证查询结果正确及不降低性能的情况下,复杂查询的效率有了明显提升。
1 系统结构
混合存储系统主要用来提高在集成MySQL和Neo4j的系统中复杂查询的效率。混合存储系统主要包括查询解析器、优化器、连接器3个模块。系统结构如图1所示。
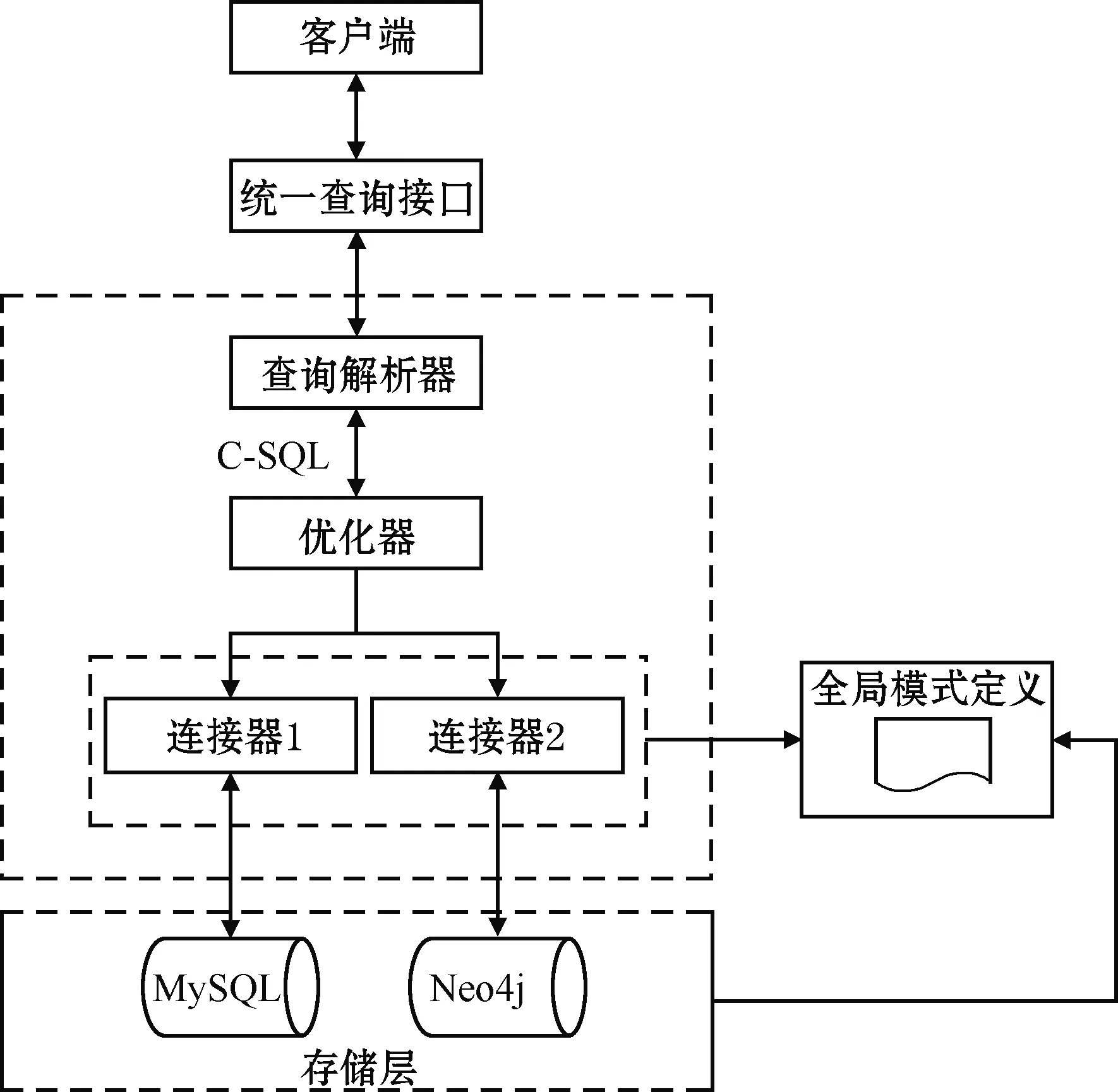
图1 混合存储系统结构
统一查询接口用来接受客户端传送过来的查询请求,然后由查询解析器将接收到的查询转换为由类SQL语言C-SQL定义的查询语句,并将其传递给优化器。
优化器中包含计划枚举器和成本模型等多个模块。它将收到的查询进行分解,并确定最优查询计划,随后将最优查询计划中的子查询传送到对应的与数据库连接的连接器中。如果最终的查询计划同时分布在MySQL和Neo4j两个数据库中,优化器会将两个数据库中的查询结果进行合并,并将合并后的查询结果发送给用户。
连接器模块直接与目标数据库连接,在连接器接收到来自优化器的子查询后,首先使用全局模式进行验证,随后将查询翻译成对应数据库的查询语言并发送到数据库,数据库执行查询并返回结果,连接器将查询结果转换为通用的格式,然后将其发送给优化器。
2 系统功能模块
本节主要阐述混合存储系统中各个模块的功能和实现细节。
2.1 全局模式定义
在混合存储系统中,每个数据库都定义了自己独有的数据存储模式,在进行查询的过程中,开发人员还需要了解不同数据库中的数据划分,且需要针对不同的数据库进行数据查询。为了解决这一问题,设计了一个存储着关系数据库和图数据库数据模式的全局模式,其中存放了数据库中所有表的相关信息。通过全局模式的定义,可以简化对接收到的查询进行验证的过程。
系统全局模式的定义参照了关系数据库的模式定义。同时,为了方便在图数据库上进行数据查询,根据Neo4j官网[10]提供的从关系数据转换成图数据的方法,将全局模式中的所有表定义为关联表和数据表两种结构,以方便将全局模式中的表和图数据库中的节点和边进行一一对应。
定义1关联表是另一个表未引用的关系,它恰好包含两个外键,并且可以具有其他的相关属性。
定义2数据表是一个关系,其中包含关联表以外的任何其他情况。这意味着该关系可以不包含任何外键,也可以包含多个外键,并且可以被另一个表引用。
以在MySQL中的案件信息表case(id,casename,judge)为例,以下为case表在全局模式的定义:
{
"tableName":"case",
"dataSource":"MySQL",
"tableType":"dataTable",
"fields":[{
"fieldName":"id",
"characteristic":"primaryKey"},
{
" fieldName ":"casename",
" characteristic ":"ordinary"
},
{
" fieldName ":"judge",
" characteristic ":" ordinary "
}]
}
在以上全局模式中,定义了表名、数据源、表的类型、数据域4种属性。其中表名与MySQL中对应的表名相同,数据源为该表所在的数据库,表的类型表示了该表为关联表还是数据表,数据域中为该表所包含的字段,针对数据域中的字段,给出了“字段名称”、“字段特征”两个属性,其中“字段特征”定义该字段是主键、外键或普通字段。
从全局模式转换成图结构,每个数据表都可以转化成一个节点,其中表名为节点的标签,外键转换成与节点相连的边,普通字段转换为节点的属性。每个关联表转换成两个外键引用的两个节点之间的边,关联表中的其他字段转换成两个节点之间边的属性。通过这种方法,使数据表涵盖了所有实体,关联表涵盖了节点与节点之间的关系。图2展示了案件信息、嫌疑人、人员信息相关数据在关系数据库、图数据库和全局模式中的表示及对应关系。
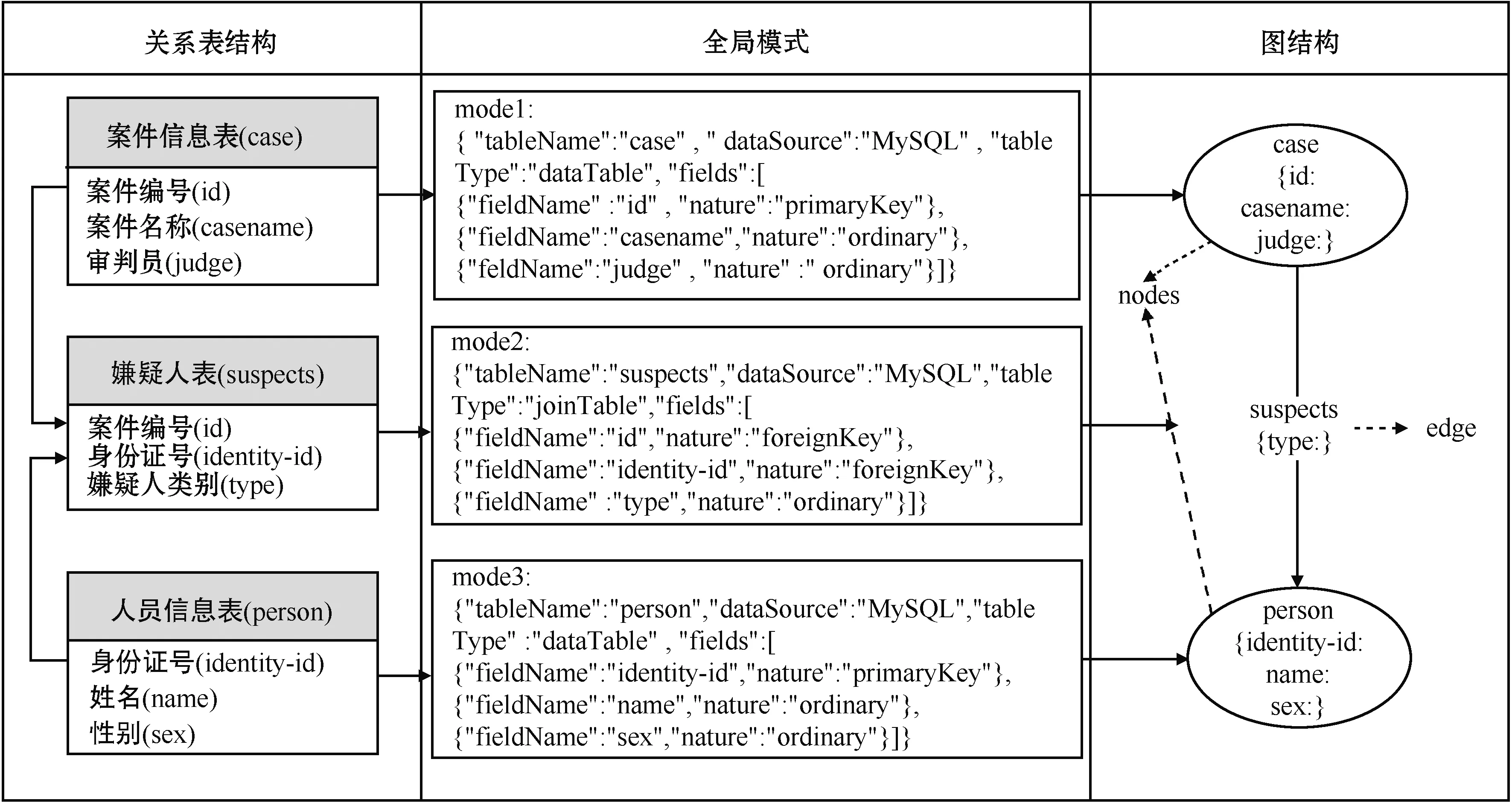
图2 案件信息、嫌疑人、人员信息在关系模型、全局模式、图模型中的表示
2.2 C-SQL定义
对于多个异构数据库,没有统一的数据库访问接口,通常情况下,对象关系映射(object relational mapping,ORM)仅仅连接到单个数据库上,开发人员需要学习多种查询语言。
因此,为了提供统一的查询接口,也为了简化SQL语句和Cypher语句之间的转化过程,本文结合SQL的语法规则和图数据模式,定义了一种简化的类SQL查询语言C-SQL。
C-SQL通过系统中的查询解析器生成,目前仅支持读取操作。本文使用扩展巴科斯范式(extended Backus-Naur form,EBNF)来定义C-SQL的语法规则,如表1所示。

表1 C-SQL的扩展巴科斯范式
表1中定义了带子查询的读取查询的结构。在C-SQL中,子查询作为父查询的一个额外查询定义,其目的是在图数据库上进行查询时,方便将C-SQL格式的查询语句转换为Cypher格式的查询语句。带子查询的C-SQL查询示例如下:
//父查询
parent_query->select("id")->
from("case")->
where("judge","=","张三");
//子查询
sub_query->select("*")->
from("suspects")->
whereIn("id",parent-query->result());
在以上示例中,使用查询查找了姓名为“张三”的法官所办理的案件中犯罪嫌疑人的信息。其中parent_query和sub_query为解析器中定义的变量名称。
除了以上的定义外,为了满足不同类型的用户查询需求,对where关键字的功能进行了扩充,定义了不同类型的where函数以满足不同查询的条件。包括orWhere,whereIn,orWhereIn,whereLike,orWhereLike,whereExist,orwhereExist等。由此,除了可以通过C-SQL创建单一条件的查询、条件中包含子查询的查询以外,同时还可以创建多种类型的条件查询。
2.3 查询优化策略
在混合存储系统中进行查询时,如何将查询任务合理地分配到每一个数据库中直接决定了查询的效率。优化器的目的是在接收到用户的查询请求以后,根据查询的成本,找到一个最佳的查询计划,将查询请求推向合适的数据库,以达到提升查询性能的目的。优化器主要由计划枚举器和成本模型两个部分组成。
2.3.1 计划枚举器
优化器在接收到查询解析器发送过来的用户查询请求后,首先将其发送到计划枚举器中。计划枚举器的作用是根据接收到的查询请求构造枚举查询,包括查询内容、查询的目标表信息以及查询的过滤条件等。使用计划枚举器不仅是为了构建一组从用户的查询请求中派生出的枚举查询,而且是为了对枚举查询进行维护,包括从枚举查询中重构原始的用户查询。计划枚举器构造枚举查询后,将其发送至成本模型进行成本计算。
计划枚举器的原理如下:首先,计划枚举器检查输入查询中是否有多个表,如果存在多个表,则为所有可能的连接组合创建一个新查询,同时为具有条件语句和选择语句的每个表创建一个新查询。其次,如果存在多个条件,将为每个条件创建一个新查询,并将所有选择语句添加到新查询中。如果查询中没有上述两种情况,计划枚举器将使用一个表和select语句创建一个新查询,不包含查询条件。如果查询中没有条件且没有连接操作,算法将停止并返回输入查询。在对输入查询进行枚举后,对于创建的新查询,将会以每一个新查询作为枚举对象再次调用计划枚举器,进行递归枚举,最后返回所有的枚举结果。
计划枚举器的结果是查询的枚举,类似于树结构,树的根节点是用户的查询请求,每个子节点都是从根节点派生出来的子查询。以查询Q2.1为例,经过计划枚举器处理后的枚举查询如表2所示。

表2 查询示例Q2.1的枚举查询
查询示例:
Q2.1->select("*")->from("case","c")->from("suspects","s")->from("person","p")->where("c.id"," ="," s.id")->where("s.identity-id","p.identity-id")
由表2可知,q1~q5的查询都是包含连接操作和引用表的条件查询。q6~q8的查询中只包含了单个表的查询,不包含任何查询条件,因此后续处理中,将会删除枚举查询中类似的查询。
2.3.2 成本模型
在多数据库混合存储系统中,查询可能会在部分或者全部数据库上执行,执行计划并不是唯一确定的,为了优化查询执行的性能,需要成本模型来控制查询的成本。常见的成本模型有3种:黑盒模型[11]、自定义模型[12]和动态模型[13]。
黑盒模型将每个数据库视为一个黑盒,通过在每个数据库上运行大量的测试查询,以收集每个数据库的成本模型所需要的信息。自定义模型根据每个数据库构建单独的成本模型,然后汇总不同成本模型的结果来创建系统总体的成本模型。动态模型通过监视每个数据库运行时的实时数据来构建成本模型。相较于黑盒模型和自定义模型,动态模型可以选择更加准确的查询计划。
为了提高查询效率,本文基于动态模型,构建了以响应时间为测量标准的动态成本模型。
成本模型的执行流程如下:第一步,在MySQL和Neo4j中并行执行枚举查询中的每个查询,并将查询响应时间记录保存。第二步,遍历枚举查询的树结构,在遍历的过程中,比较每个节点的枚举查询在不同数据库上的响应时间,找到响应时间最短的数据库,将查询响应时间记录并标记为查询成本cost(v)。第三步,在树的每层汇总所有查询成本,并将汇总的查询成本与父查询的查询成本进行比较。如果查询成本低于父查询的90%,表明有优化的空间,遍历继续;如果查询成本高于父查询的90%,停止遍历;同时,当查询成本高于父查询的95%时,父查询为最后一步优化查询。通过以上方法,可以找到在数个数据库上执行的查询计划。最后,成本模型返回选择出的最佳查询计划,并执行该计划,得到符合用户查询请求的结果。
2.4 连接器实现
连接器连接底层的数据库,在接收到优化器传送过来的枚举查询后,连接器会与目标数据库建立连接,然后将查询翻译成目标数据库定义的查询语言,也就是Cypher和SQL,将其发送至数据库,并在数据库执行完查询后接收返回结果并将结果发送给优化器。因此,准确地将C-SQL格式的查询语句翻译成Cypher语句和SQL语句是保证系统正确查询的前提。
2.4.1 从C-SQL到Cypher的转换
大多数情况下,查询中都包含where语句用来过滤查询结果,在Cypher中,同样也有类似的WHERE子句进行条件过滤。但是将C-SQL语句转换成Cypher语句并不容易,一方面,Cypher中使用别名的方式不同于C-SQL,另一方面,需要对C-SQL中的外键等字段进行识别判断。
C-SQL中的别名,类似于SQL中的别名,是表的临时名称。而Cypher中的别名是节点或者边的临时名称。C-SQL查询中多次提及一个表时,需要对表提供别名,同理,在Cypher中多次引用节点或者边时,需要对节点或者边提供别名。
当查询语句中每个表只被引用一次的时候,C-SQL在编写用户查询的过程中,不需要为表提供别名,但转化成Cypher后,根据Cypher的使用规则,需要对表对应的节点提供一个别名。这种情况下,可以使用C-SQL中的表名来解决Cypher中的别名问题;但当查询语句中多次提及一个表或多个表的时候,需要按照C-SQL查询语句中表的别名将其转换成Cypher中节点与边的别名。
将C-SQL转化成Cypher的另一个问题是对外键的处理。在本文对以下格式的where条件语句进行定义。
定义3在由leftConf = rightConf构成的过滤条件中,如果leftConf和rightConf都是属性,其中一个必须是外键,另一个必须为引用属性。
在查询语句的过滤条件中,定义3中的过滤条件,在Cypher中表示为边而不是WHERE中的过滤条件,所以,在查询语句从C-SQL格式转换成Cypher格式的过程中,无法将C-SQL定义3中的where模块,转换成Cypher中的WHERE模块,所以在转换的时候,需要对定义3中的条件语句进行识别并将其删除。
在经过上述的别名转换和对C-SQL中where语句进行预处理后,便可以将C-SQL中的where语句转换成为Cypher中的WHERE子句。同时,对select中涉及的查询信息,经过全局模式的验证后,删除对外键的引用,同时将通配符“*”转换成相关属性名后,就可以转换成Cypher中的RETURN子句。
2.4.2 从C-SQL到SQL的转换
因为C-SQL是参照SQL进行定义的,所以将C-SQL语句转换成SQL语句的过程较为简单。
参照SQL语句的格式,SQL中读取操作主要包含以下几部分:
SELECT {selectItems}
FROM {fromItems}
WHERE {conditions}
按照selectItems、fromItems、conditions各部分在SQL中的定义,对C-SQL格式的查询语句进行提取整合就可以将C-SQL转换成SQL。
3 数据同步策略
为了保证系统运行过程中MySQL和Neo4j中数据的一致性,采用日志解析的方法从MySQL中获取数据变更操作并同步至Neo4j内。
首先,基于MySQL的主从复制机制,将同步程序模拟成MySQL的从节点,就可以实时从MySQL数据库中的Binlog日志中获取数据变更操作信息;接着对获取到的数据变更操作进行解析;然后将变更操作信息存入缓存队列以缓解系统压力;最后对数据变更操作进行复现,将数据存入Neo4j内。整个数据同步流程如图3所示。

图3 从MySQL到Neo4j的数据同步流程
日志过滤模块通过模拟MySQL的从节点连接MySQL数据库,从Binlog日志中获取事件信息并筛选出有效的变更操作信息。
日志解析模块将过滤后的日志文件进行解析分类,随后将解析结果转换为JSON格式的数据存入缓存队列中。
元数据模块中存放了关系型数据库中的表结构信息。图数据库数据以节点和节点之间的关系进行存储,在对日志进行解析后,通过元数据中的表结构信息获取操作的数据是否为主键或者外键,进而在操作复现时决定是对图数据库中的节点还是关系进行操作。另外,当关系型数据库中的变更操作为DDL操作时,在对日志进行解析后,将更改后的表结构信息更新至元数据模块中,以保持与关系型数据库中的表结构信息一致。
缓存队列模块用以保证后续操作的顺序,避免发生写入操作的并发,同时缓解系统压力。
操作复现模块将日志解析模块转换的JSON数据按照操作类型转换成对应的Cypher语句,将数据插入图数据库。
4 实验
为了验证混合存储系统的可行性,测试了混合存储系统、MySQL和Neo4j对于相同查询的查询效率。
另外,本文还对混合存储系统和图数据库AgensGraph进行了对比。AgensGraph是一种基于PostgreSQL的多模型数据库,允许开发人员集成经典的关系数据库模型的同时能够提供图数据分析环境。
实验平台的设备参数为:8 GB内存,4核CPU以及200 GB硬盘。
实验数据为某市某区人员关系数据及刑事案件数据,这两个数据集均为关系数据,存放在MySQL中,包括人员基本信息、人员关系信息、刑事案件基本信息、犯罪嫌疑人信息、判决信息等。通过实体、关系映射规则,将上述关系数据映射到Neo4j中,其中MySQL中的数据大小为1.6 GB,Neo4j中的数据大小为2.9 GB。
为尽可能地涉及分组、聚合、排序、连接等多种查询类型,挑选了下列查询来分别对MySQL、Neo4j和混合存储系统进行实验:
Q1:查找案件编号000001的案件。
Q2:统计所有类型案件的数量。
Q3:查找量刑最高的抢劫案。
Q4:查找犯罪嫌疑人1的父亲。
Q5:查找审判长1审判的纵火罪的犯罪嫌疑人信息。
Q6:查找审判长1在2018年判决的纵火罪的犯罪嫌疑人信息。
Q7:查找既犯了抢劫罪又犯了盗窃罪的犯罪嫌疑人的亲友信息。
Q8:查找2019年审判案件最多的审判长判决的案件中量刑最高的案件的犯罪嫌疑人信息。
上述查询中,查询Q1~Q3为比较常见的分组和聚合查询,查询Q4为简单的join查询,查询Q5~Q8则包含了大量连接、聚合、排序操作的复杂查询。
以查询的响应时间为测量标准,实验结果如图4所示。
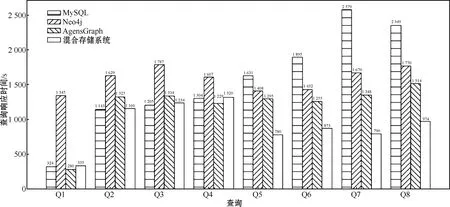
图4 MySQL、Neo4j、AgensGraph和混合存储系统的查询响应时间
对Q1~Q8在混合系统中的查询计划进行分析发现,混合存储系统在执行上述查询时,查询Q1~Q4仅在MySQL上执行,查询Q5~Q8为混合查询。
通过分析实验结果,查询Q1~Q4在混合存储系统中执行的响应时间近似于在MySQL上的执行时间,远优于在Neo4j上的执行时间。而复杂查询Q5~Q8在混合系统中的查询响应时间,显著优于单独在MySQL和Neo4j上的响应时间,也优于AgensGraph数据库的响应时间。实验结果表明,混合存储系统在进行复杂查询时,相比Neo4j查询效率提高了50%以上,较AgensGraph数据库也有较为明显的优势。
5 结束语
本文基于MySQL和Neo4j,实现了一个混合存储系统。通过C-SQL连接MySQL和Neo4j,为用户提供统一的数据库访问接口,以完成混合系统的查询处理;基于动态成本模型对查询进行分解优化,确定最优查询计划,提高复杂查询的效率。实验结果表明,与MySQL、Neo4j和AgensGraph进行比较,本文提出的混合存储系统在保证查询结果正确的情况下,对于复杂查询的效率有了明显提升。
猜你喜欢
山东冶金(2022年2期)2022-08-08 01:51:30
速读·上旬(2022年2期)2022-04-10 16:42:14
新一代信息技术(2021年8期)2021-07-30 13:37:14
哈尔滨轴承(2020年2期)2020-11-06 09:22:36
发明与创新·大科技(2019年12期)2019-03-17 09:23:31
科技创新与应用(2016年6期)2016-05-14 13:09:56
中国教育信息化(2015年12期)2015-08-24 07:58:36
电测与仪表(2015年10期)2015-04-09 11:48:20
河北大学学报(自然科学版)(2015年1期)2015-02-27 13:06:13
江西理工大学学报(2013年1期)2013-03-20 14:57:13
