
改进生成式对抗网络的图像数据集增强算法*
2022-03-27 11:28郭伟,庞晨
电讯技术 2022年3期
郭 伟,庞 晨
(西安科技大学 通信与信息工程学院,西安 710600)
0 引 言
传统图像领域的数据增强方法建立在一系列已知的仿射变换和图像处理手段基础上,例如旋转、旋转畸变[1]、极坐标变化[2]等。这种基于几何变换的数据增强方法生成的图像数据集与原始数据集区分不大且带有很多冗余信息,网络模型泛化能力不会得到大幅提升[3]。
生成式对抗网络(Generative Adversarial Network,GAN)[4]自2014年提出后,广泛应用于目标检测[5]、文本识别[6-7]、超分辨率[8-9]重建等方面。它的出现极大地解决了工程领域中出现的高维概率密度采样问题,对其他生成算法发展具有一定的启发价值,但是GAN的训练过程中会出现生成模型退化现象,持续生成的相同样本点导致模型无法继续学习而崩溃[10]。此后,研究者们不断提出各种GAN变体来改进传统GAN存在的缺陷:Mao等人[11]提出的LSGAN(Least Square Generative Adversarial Network)使用最小二乘损失替换交叉熵损失函数,该算法虽然保证了模型的稳定性,但无法更好测量真实数据与生成数据间的散度;Arjovsky等人[12]提出的WGAN(Wasserstein Generative Adversarial Network)采用EM(Earth-Mover)距离替换传统GAN的Jensen-Shannon(JS)散度来计算分布距离,解决了LSGAN存在的问题,但该方法不易确定权重裁剪值,且生成样本质量稳定性差;Takeru等人[13]提出SNGAN(Spectrally Normalized Generative Adversarial Networks)在神经网络中加入谱归一化层,解决了WGAN存在的1-Lipschitz问题。
Radford等人[14]提出的深度卷积对抗生成网络(Deep Convolutional Generative Adversarial Network,DCGAN),由于其出色的生成效果,广泛应用于图像数据集增强领域。Rafael等人[15]提出了通过DCGAN和风格迁移来增加帕金森病肌电图数据,识别率得到有效提高。鲁力等人[16]通过改进的DCGAN对军事SAR图像中的少数类样本进行扩增,尽管一定程度上提升了SAR图像的分类精度与模型泛化能力,但是未完全消除的噪声点仍较大程度地影响生成图像的清晰度。
本文针对上述模型及文献中存在的问题,提出一种改进的生成对抗网络数据增强模型——RDCGAN(Relativistic Deep Convolutional Generative Adversarial Network),旨在解决模型训练过程中模型不稳定、生成图像质量差等问题。本文从以下几个方面进行改进:一是针对生成图像缺乏细节的问题,在生成网络中采用SeLU来替代原激活函数ReLU,生成更丰富的图像细节;二是采用相对判别损失函数的方法,通过提升伪造数据判为真实数据的概率,并降低真实数据判为伪造的概率,来产生稳定且高质量的数据样本;三是在生成网络中引入残差块来提升生成图像的分辨率。
1 DCGAN原理
基于GAN的思想基础,Radford等人[14]提出将监督学习中的卷积神经网络(Convolutional Neural Network,CNN)引入无监督学习生成式对抗网络的结构,即深度卷积生成式对抗网络(Deep Convolutional Generative Adversarial Network,DCGAN),该结构使GAN训练更加稳定。DCGAN主要由生成器G和判别器D构成,通过生成器和判别器相互竞争,最终达到纳什均衡。
图1为DCGAN网络的结构,隐变量z一般为服从高斯分布的随机噪声,z输入生成器中得到伪造数据G(z)。判别器获得G(z)后将其与真实数据进行比较,做出真假判断并反馈给生成器,判别器优化过程类似于二分类问题。

图1 DCGAN结构
整个过程可归纳为一个二元极小极大博弈,目标函数可定义为
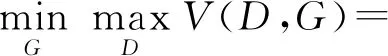
Ez~Pg(z)[lg(1-D(G(z)))]。
(1)

判别器的目标式为
V(G,D)=Ex~Pdata(x)[lgD(x)]+
Ez~Pg(x)[lg(1-D(x))]。
(2)
转化为积分形式为

(3)
求该积分的最大值即求f(x)最大值。令Pdata(x)=m,Pg(z)=n,D(x)=z,得到
f(z)=mlg(z)+nlg(1-z)。
(4)
(5)
代入式(3)得
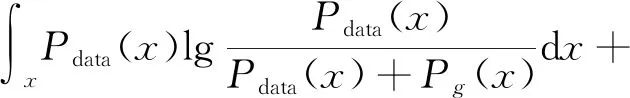
(6)
通过添加分子2,构造KL散度(Kullback-Leibler divergence),得到

(7)
JS散度公式为
(8)
则有
(9)

2 RDCGAN算法
2.1 激活函数改进
为了缓解神经网络训练中的梯度弥散现象,2010年Nair和Hinton提出了修正线性单元(Rectifier Linear Unit,ReLU),这一应用减少了网络训练的时间,模型识别率得到提升。在DCGAN网络中,ReLU激活函数主要作用是完成卷积层的非线性激活,过滤小于0的输入。而SeLU(Self-normalizing Neural Network)[17]保留了小于0输入的计算,提供了丰富的特征,并且经过该激活函数后样本的分布自动归一化到0均值和单位方差,公式如式(10):
(10)
式中:λ≈1.050 7,α≈1.673 2。由于SeLU保留了小于0输入的计算,导致正向传播和反向传播过程中计算时间会有所延长,模型优化难度也进一步增加。为了获取更多丰富特征且不过多增加计算量,本文仅在生成网络中使用SeLU激活函数。
2.2 判别器改进
传统DCGAN中,随着伪造数据得分的提升,真实数据的得分并不会下降。假设D和G在每个交替步骤中都训练到了最佳,训练结束时,判别器D(xr)=1,D(xf)=0;生成器D(xr)=1,D(xf)=1。在训练交替过程中,D(xr)恒等于1,梯度恒为0,判别器暂停更新从而使模型崩溃。
理想情况下,如图2(a)所示,大多数xr和xf分别能够满足D(xr)平滑地从1到0.5,D(xf)平滑地从0到0.5。但是原始DCGAN网络时的损失函数为饱和损失,生成器如图2(b)所示,只增加D(xf)的值,但D(xr)的值不改变。而理想情况为,生成器D(xf)不但需要增加,同时D(xr)也要减少,如图2(c)所示。

图2 生成器训练过程对比图
在DCGAN网络中,当D训练较优时,计算梯度时不会考虑真实数据,仅关注如何使得伪造数据变得更真实,这样会使训练不稳定。若D(xr)逐渐减少,D(xf)逐渐增加,真实数据就可以被用于在DCGAN网络中进行梯度的计算,从而避免训练时产生梯度消失现象。本文的最终目的为需要一个真实数据作为先验知识引导判别器获得更准确的分类,使真实数据和伪造数据作为D网络梯度的一部分用于最小化损失函数。
为解决Dreal梯度不变化的问题,Alexia等人[18]提出了采用相对判别器的RGAN(Relativistic Generative Adversarial Network)网络,在训练过程中使得Dreal向Dfake移动,也使得Dfake向Dreal移动。本文在DCGAN网络中引入相对判别器概念,解决上述问题。首先将公式(1)改写为如下形式:
LD=Exr~P[f1(D(xr))]+Exz~Pz[f2(D(xf))],
(11)
LG=Exr~P[g1(D(xr))]+Ez~Pz[g2(D(xf))]。
(12)
式中:P是真实数据分布,Pz是多变量的高斯分布,期望为0,方差为1;f1、f2、g1、g2是判别函数。采用相对判别器,目标式变为
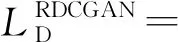
E(xr,xf)~(P,Q)[f2(D(xf)-D(xr))],
(13)
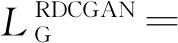
E(xr,xf)~(P,Q)[g2(D(xf)-D(xr))] 。
(14)
在传统DCGAN网络中,g1为0,因为传统的网络中G只需考虑C(xf)尽可能高,但是在改进后的网络中g1不为0,将真实数据的判别值减去伪造数据的判别值作为衡量标准。在G中确保g1越小越好,对应产生一个引导C(xr)向更小方向移动的梯度,在训练过程中Dreal逐渐降低至与Dfake相同。
2.3 引入残差块生成高分辨率图像
本节在前文的基础上引入残差块[19]改进现有的网络结构,通过提升网络的学习能力来进一步改善生成图像的分辨率。以生成48 pixel×48 pixel大小的图片为例,结合文献[20],本文构建的基于深度残差生成式的生成网络模型如图3所示。
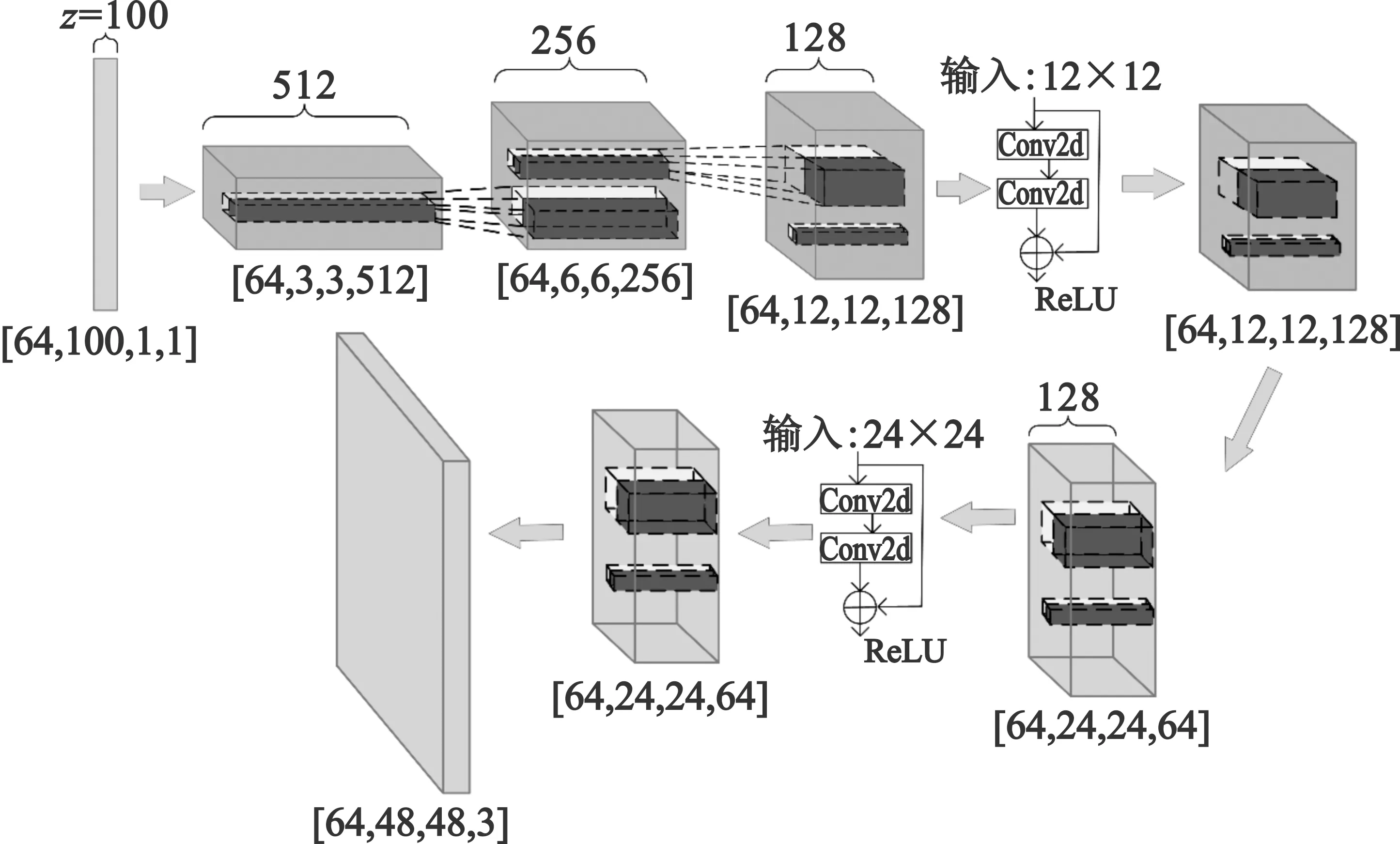
图3 改进生成网络结构图
确定生成模型的四维张量,批处理样本个数假设为64,输入噪声维度z为100,初始噪声样本像素1×1,初始样本维度为[64,100,1,1]。通过在生成模型中加入两个残差结构组成的残差网络后保持输出维度不改变,最终输出一张48 pixel×48 pixel的三通道的图片。
本文在上述改进DCGAN网络基础上,对多次转置卷积操作后得到的特征图引入残差网络进一步提取其细节,保证在进入下一转置卷积层之前上层网络的图像特征尽可能细节化和丰富化,避免了特征信息的丢失。
3 训练结果
3.1 激活函数影响
为说明改进激活函数对模型性能的提升,现将改变激活函数的DCGAN网络(IM_DCGAN)与原始DCGAN网络(OR_DCGAN)进行对比,除激活函数外,两个网络其余变量、参数均保持一致。两种网络在本文所采用的数据集上的生成样本如图4所示,结果表明改进前的网络模型存在重复样本多、图像模糊,以及模式崩塌现象;而改进后的DCGAN尽管仍存在一定程度的模式崩塌现象,但是生成样本中则包含更加丰富的细节,图像质量明显优于改进前的网络模型。

图4 两种网络模型生成图像对比图
3.2 判别器影响
本文通过引入相对判别器提升网络的判别能力,为验证本文所提方法的有效性,现将未改进判别函数的网络D与改进网络RD在SAR图像上进行样本识别准确率检验,对比结果如图5所示。
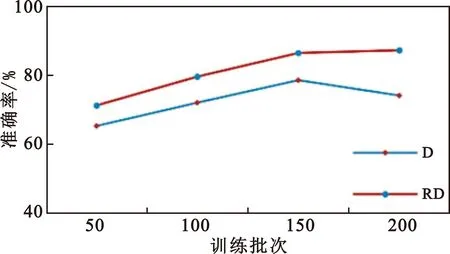
图5 网络D和网络RD识别准确率检验对比结果
实验结果显示,随着训练批次的升高引入相对判别器的RDCGAN网络在SAR数据集对地车辆卫星图片中的识别准确率逐渐升高,且高于原DCGAN网络,这表明引入相对判别器能够有效地缓解模式坍塌现象,从而提升生成样本的质量。
3.3 引入残差块的影响
为了验证引入残差块这一方法的有效性,本文将传统DCGAN网络的与改进网络的判别损失函数进行对比,从训练结果中截取训练次数16 000~26 000进行分析。由于改进网络引入更加稳定的相对判别损失函数,如图6所示,判别器损失值更加稳定,极少情况下出现波动情况,损失值最终稳定在0.25左右,而原始DCGAN的判别损失函数如图7所示,最小损失值0.5,高于改进网络的最小损失值,并且训练过程中出现多次大幅振荡现象,模型不稳定。
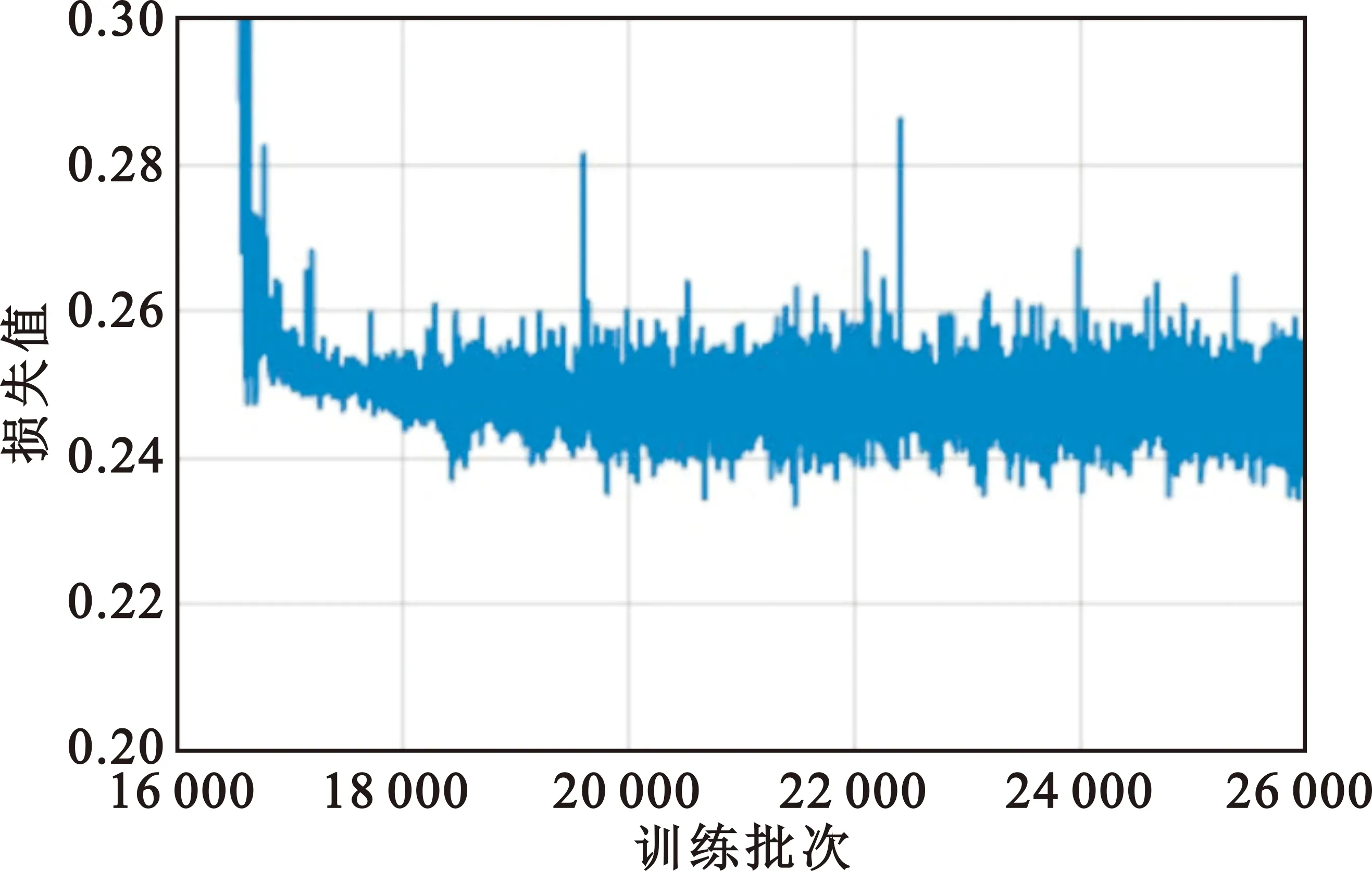
图6 RDCGAN网判别器损失
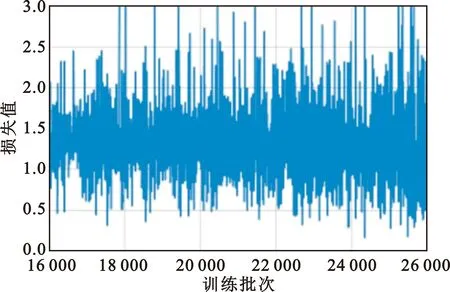
图7 DCGAN网络判别器损失
4 实验仿真与分析
为进一步验证本文所提方法的有效性,将改进的RDCGAN网络与其他现有数据增强方法进行对比实验。实验采用Intel i5-10210U CPU、Win10操作系统,基于TensorFlow 1.8-CPU的网络架构,训练数据集使用MNIST手写数据集、对地车辆目标SAR图像数据集与血液细胞数据集,与GAN、DCGAN、LSGAN、WGAN、SNGAN进行实验对比。其中对地车辆目标SAR图像数据集采用美国国防高等研究计划署(Defense Advanced Research Projects Agency,DARPA)公布的实测SAR地面静止目标数据,血液细胞数据集采用权威医学数据集BCCD血细胞数据集。
经多次实验对比选择最优参数并设置如下:判别模型与生成模型学习率均为0.000 2,优化器参数图像批处理为64,训练批次为50次。
4.1 增强效果分析
图8为生成器在MNIST数据集上分别在训练次数为0、1 000、2 000、3 000、4 000左右时的结果。训练次数为0时,GAN模型有大量噪声,WGAN模型生成的图像模糊且无法识别数字类型;训练次数为1 000时,RDCGAN、DCGAN模型能够清晰识别图像类型,其余生成模型较为模糊;当训练到2 000和3 000次左右时,除GAN和SNGAN外所有模型均可以识别出数字类型,仅有少部分数字较为模糊;训练至4 000次时,LSGAN与WGAN模型生成图片质量明显差于上一阶段,说明这两种模型均产生不同程度的模式崩塌现象,而GAN与SNGAN的生成图片全程伴随大量噪声,其中SNGAN更为严重,DCGAN虽未产生大规模模式崩塌现象,但是与RDCGAN相比,在生成图像的细节方面仍旧存在一些数字模糊不清无法分辨的现象,而本文的改进模型RDCGAN从始至终生成图像质量稳步提升,未产生大量噪声且未出现模式崩塌。

图8 训练结果对比图
4.2 量化评价指标分析
本文采用灰度方差函数(Sum of Modulus of gray Difference,SMD)评价生成样本的清晰度与Fréchet Inception Distance(FID)评价样本间的相似度,如式(15)所示:
(15)
式中:g、r分别代表生成图像与真实图像,μg与μr是各自特征向量的均值,Σg、∑r表示各自特征向量的协方差矩阵,Tr表示矩阵的迹。
SMD的数值越大,图像清晰度越高。表1的对比结果表明,RDCGAN在三个数据集上的生成样本的SMD值均高于DCGAN,改进后的网络模型较大地提升了图像质量。

表1 生成图像质量对比
使用训练3 000次左右后的生成图像,从生成样本中随机选取100张图像,计算其平均值作为量化评价指标。FID评价指标具有原则性和综合性,能准确反映生成样本和真实样本之间的相似性,值越小样本间相似度越高,生成效果越好。改进后RDCGAN的FID值在这三类数据集上较GAN和DCGAN相比均有明显的降低,具体结果如表2所示,FID值分别降低41.9%、18.0%与20.8%。由于WGAN与本文改进模型RDCGAN在SAR数据集上FID值与其他模型相比较为接近,故使用相同超参数分别在训练2 000、3 000、4 000、5 000次左右进行FID量化值评定,结果如表3所示,经过多次训练得出结论:WGAN在训练过程中,随着训练次数的提升,FID值出现了回升现象,训练过程不稳定,而本文的改进算法RDCGAN随着训练次数的增加,FID逐步减少,训练过程稳定,且生成图像质量清晰,细节丰富。

表2 各数据集上FID值比较
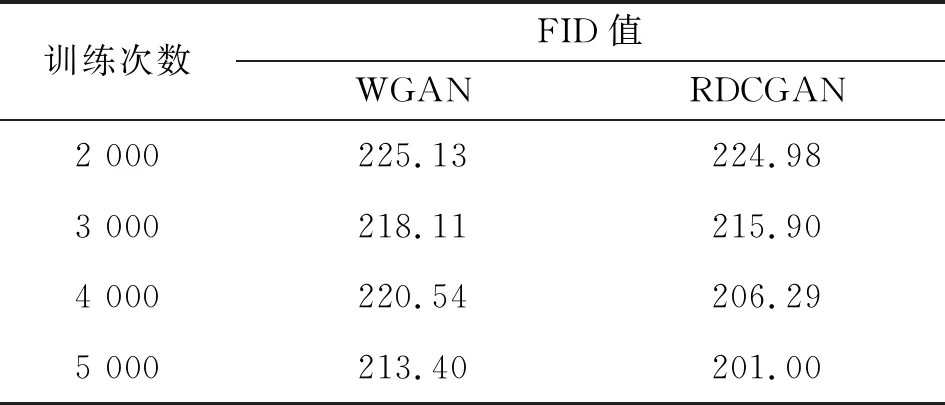
表3 不同训练次数FID值比较
5 结束语
为了解决现有DCGAN算法在小样本图像数据增强过程中由损失函数引起的模型稳定性差及模型结构带来的生成图像清晰度不理想等问题,本文构建了一种基于残差网络的深度卷积生成对抗相对判别模型RDCGAN,在MNIST手写数据集、SAR数据集和血液细胞数据集进行多次对比试验,从强化效果和量化指标两方面分析,实验结果均表明本文算法优于其他生成对抗网络,证明了本文所做改进的可行性和有效性。在未来的工作中,需要将本文算法应用于更多更具挑战性的数据增强场景中。
猜你喜欢
成都信息工程大学学报(2022年2期)2022-06-14
网络安全与数据管理(2022年3期)2022-05-23
北京航空航天大学学报(2021年9期)2021-11-02
数学小灵通·3-4年级(2021年5期)2021-07-16
北京航空航天大学学报(2020年10期)2020-11-14
电子制作(2019年13期)2020-01-14
北京航空航天大学学报(2019年9期)2019-10-26
电子制作(2019年11期)2019-07-04
今日农业(2019年15期)2019-01-03
北京航空航天大学学报(2018年1期)2018-04-20
