
结合多层池化的卷积神经网络在表情识别中的应用*
2022-03-27 11:28:34陈佳昌周伟松
电讯技术 2022年3期
陈佳昌,肖 飒,周伟松
(重庆邮电大学 理学院,重庆400065)
0 引 言
近年来,卷积神经网络在视觉识别、图像识别中取得了不错的成果。2012年,Sutskever等[1]在Image Net[2]的图像分类竞赛中提出的Alex Net结构取得冠军之后,卷积神经网络开始成为计算机视觉方向广泛研究的对象。研究者们不断在结构上进行调整,使得网络层数增加,适用性更大,其中最典型的有VGG(Visual Geometry Group)[3]、Res Net[4]、Google Net[5]等。然而这些网络结构在人脸表情识别中会出现网络复杂度高、训练参数量过大、分类效果差以及严重的过拟合现象。因此在计算机视觉领域中表情识别(Face Expression Recognition,FER)一直是一个富有挑战性的问题。
针对这一问题,研究者们提出了一些深度学习相关的解决办法:文献[6]提出了一种利用深度残差网络ResNet-50进行人脸表情识别;文献[7]提出了一种带有注意机制的端到端网络人脸表情自动识别方法,结构模块分为特征提取模块、注意模块、构建模块和分类模块;文献[8]提出了一种加权混合深度神经网络,用于自动提取对Fer任务有效的特征,实现了人脸检测、旋转校正、数据增强等,在数据集Cohn-Kanade(CK+)上达到了97%的准确率;文献[9]运用改进的Alex Net网络进行表情识别,相比于Alex Net,改进之后降低了网络的隐藏层数和训练参数,加入了批量标准化(Batch Normalization,BN),在Fer2013和CK+数据集上的准确度分别是68.85%和97.46%;文献[10]针对图像局部特征表达存在的复杂性、模糊性等不足,采用多层池化的方式在ResNet101模型上进行优化,加快了模型的收敛并提高了精度。
本文在以上方法的基础上对网络结构进行改进,将Inception结构和残差结构相结合,并采用多层池化的方式将不同层的池化结果整合进行优化。实验结果表明,Inception与残差结构结合的网络相比于传统神经网络精度更高,且加入多层池化之后效果更好。
1 改进的卷积神经网络
1.1 神经网络的结构
图片提取的复杂性使得单一尺度的卷积核特征提取不完全,导致当前层的信息丢失,精确度下降。改进的Inception结构在同一层分别采用3×3、5×5的卷积核大小提取不同尺度的信息,并且采用批归一化解决梯度消失的问题,同时加快模型训练。
卷积神经网络在训练过程中,由于图像经过卷积池化操作,网络的表现会逐渐降低,容易出现梯度消失的问题,而残差网络通过使用跳跃连接缓解了这一问题。
因此,本文通过Inception和残差相结合的结构进行多尺度并行特征提取,并将前几层的信息通过跳跃连接进行整合,对人脸表情进行分类。改进的结构如图1所示。由于人脸微表情复杂,小卷积核难以提取局部信息,因此取消Inception结构中1×1的卷积核,只保留3×3、5×5的较大卷积核,使其在表情的局部特征提取中效率更高。

图1 自定义卷积神经网络结构图
为了精确提取不同层次的特征,用多层尺度的池化取代单一池化,对高层次的特征图实行池化操作,三个不同分支对图片特征进行提取,提取出更加精确与全面的特征图信息。高层次的池化层提取出来的特征图通过信息采样成低层次大小的特征图,并通过整合函数进行信息整合,实现多层池化,其结构如图2所示。多层池化实现了不同层次的特征从局部到全局的特征信息的整合,避免了层次信息缺失,有效地将高维度特征信息语义与低维度的基本信息结合,提高了提取的精确度,为训练速度与分类器分类提供了基本的信息要素。
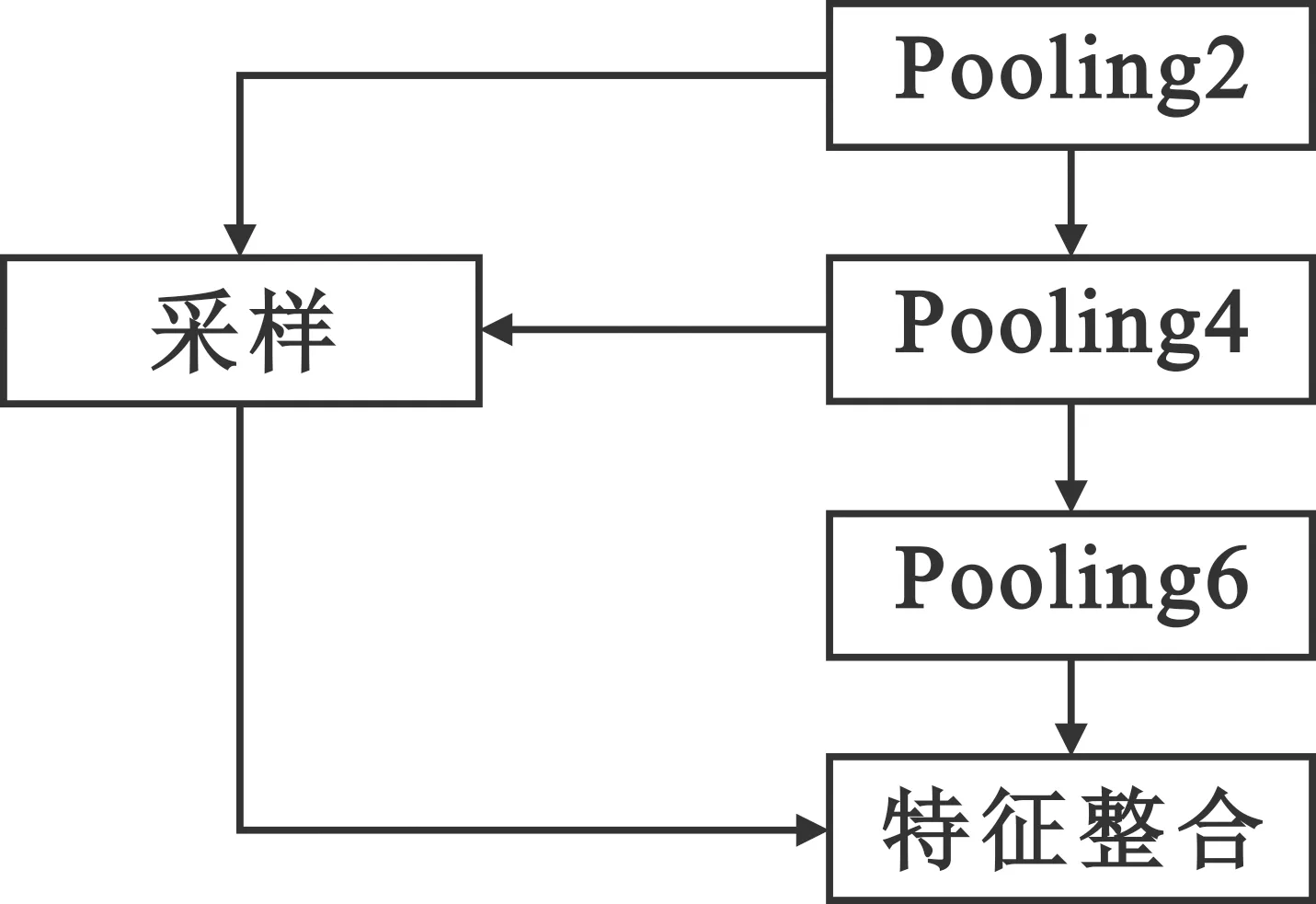
图2 多层池化结构图
表1是模型中每一层的参数设置,相比于文献[9]的模型,采用多层池化优化的Inception-resnet模型减少了卷积层的卷积核的数量,使得整个网络参数更少。

表1 网络参数设置
1.2 数据增强技术
为了防止过拟合现象,数据增强应运而生。深度学习中常用的数据增强方法有随机旋转、随机裁剪、水平翻转等。
在 Fer2013[11]数据集上进行实验时,由于该数据集的样本都是从网上爬取,且数量较多,对提升网络鲁棒性有较大帮助,比起 CK+[22]效果更好。数据集共含有35 886张图像,其中训练部分28 708张,验证部分和测试部分都是3 589张。每张图像都是分辨率为48 pixel×48 pixel的单通道图像,样本表情被分为anger、normal、happy、fear、disgust、surprised、sad共7类。Fer2013数据集的训练集﹑验证集和测试集的每个类别的数量分布如表2所示。

表2 Fer2013数据集
对Fer2013数据集进行数据增强,如图3所示。

图3 Fer2013数据增强
2 实验结果与分析
2.1 网络参数设置
实验室基于Pytorch1.6.0框架,模型相应的超参数设置如下:优化算法是自适应矩估计(Adaptive Moment Estimation,Adam);初始学习率为0.001;每次批量数据batch size为500,基于小批量而不是单个样本更新模型可以减少更新模型的方差,保证更稳定的收敛[13];激活函数为ReLU;损失函数为交叉熵。硬件参数:Intel(R) Core(TM) i7-6700HQ CPU;GTX 950;RAM 8 GB。
2.2 改进模型的实验结果
图4给出了Inception结构和残差结构相结合的网络是否带多层池化的两种训练结果。由图可以分析出不带多层池化的模型收敛到稳定的速度更快,但最终的精度只有69.97%;带多层池化的模型收敛速度降低,精确度却有明显的提升,达到了71.25%。
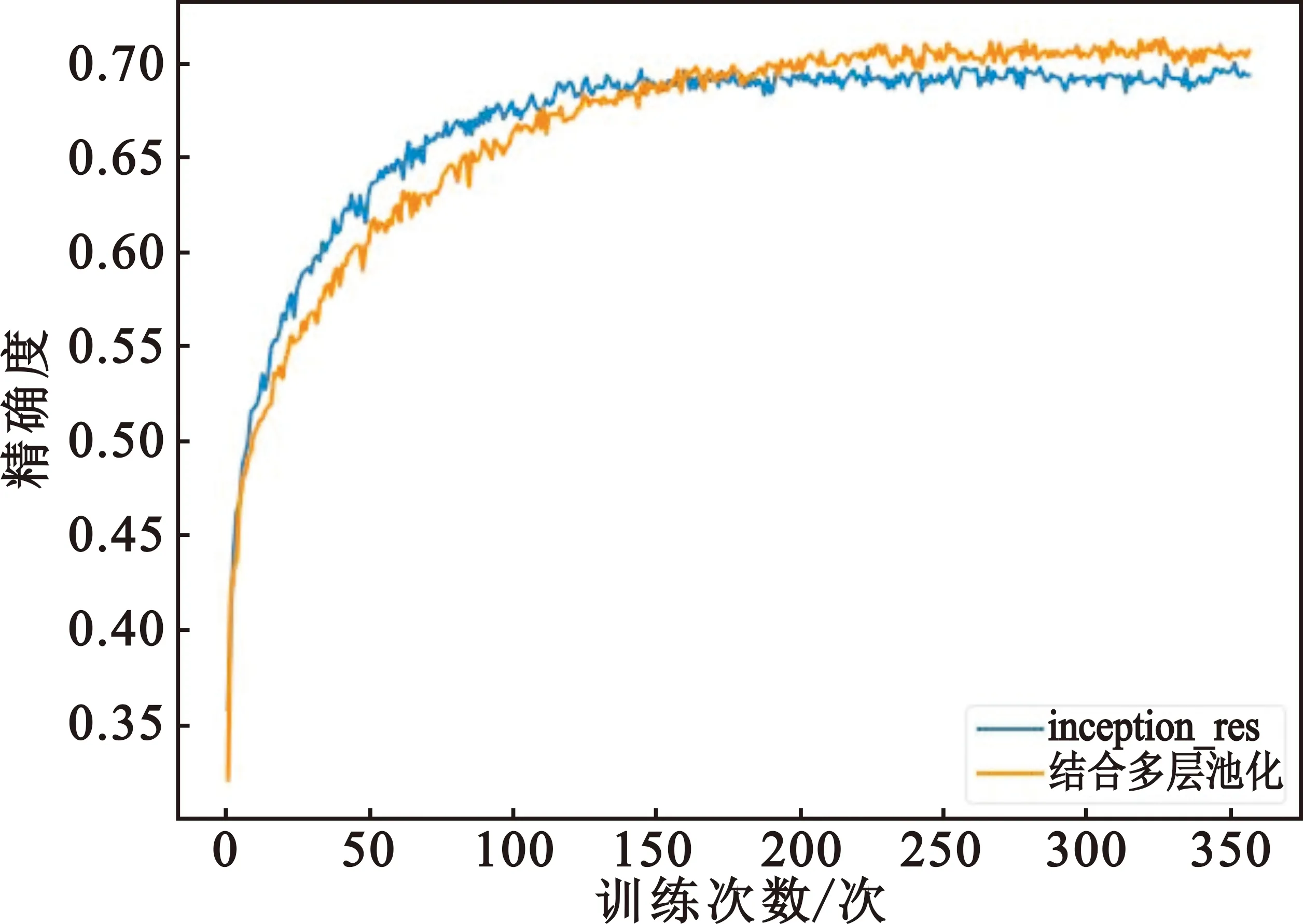
图4 多层池化对比精度图
一般用精确率、召回率和F1值来评价模型,其中精确率的计算公式为
(1)
式中:TP表示将厌恶类预测正确的数量,FP表示将厌恶类预测错误的数量。
表3是两个模型的精确率、召回率、F1值对比,其中的生气、恐惧类别的识别率在两个模型中都相对较低,是因为Fer2013数据集将数据进行了错误的标签导致;未采用多层池化的模型在厌恶这一类的精确率明显高于多层池化后的结果。因此,表3的模型在做多层池化的操作时,虽然整体上图像的特征信息提取更全面,但也会牺牲掉某些类的信息。
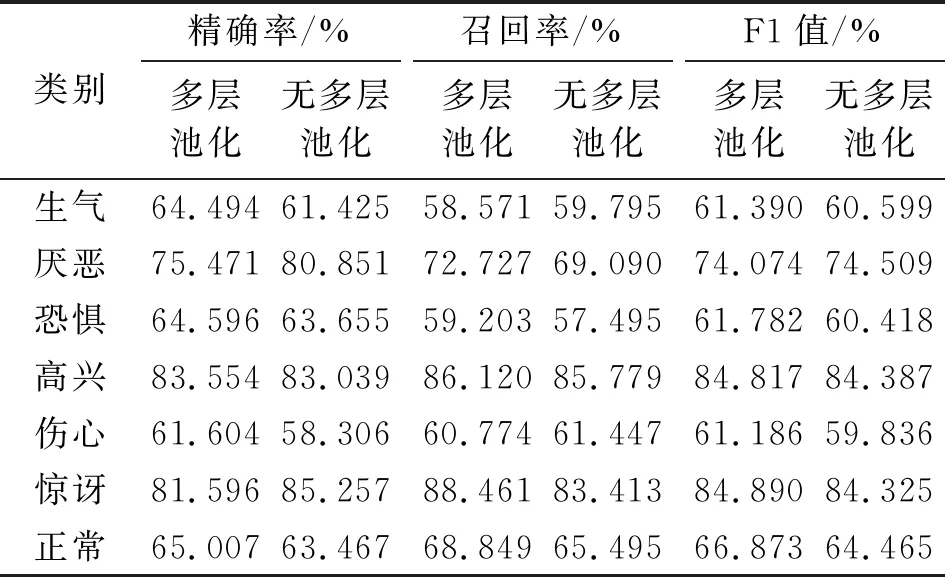
表3 两个模型的精确率、召回率和F1值
表4给出了本文中的两种方法与其他模型的精度对比,可见相比于文献[6],Inception结合残差结构参数更少,取得的效果却更好。

表4 实验精度对比
3 结束语
深度神经网络可以自动地从数据中学习特征,减少了对人和对数据的依赖。此外,结合Inception结构和残差结构的优点,使得网络在特征提取过程中发挥出了更多的价值,且模型在以上的基础上加入了多层池化的方式进行优化,使得全连接层能直接有效地获取不同池化层的信息,再结合数据增强技术扩充训练数据集,从而提高识别的精度。改进后的卷积神经网络结构简单,复杂度低,参数量少。与使用相同的面部表情数据库的文献相比,改进后的方法得到了有竞争力的结果。
下一步工作将引入犹豫模糊集构造正则项,提高模型的准确率和稳定性。
猜你喜欢
计算机工程与应用(2023年22期)2023-11-27 05:35:46
科学技术与工程(2023年3期)2023-03-15 10:34:12
网络安全与数据管理(2022年3期)2022-05-23 13:26:48
软件导刊(2022年3期)2022-03-25 04:45:04
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
北京航空航天大学学报(2020年10期)2020-11-14 09:26:02
自动化学报(2019年6期)2019-07-23 01:18:32
电子制作(2019年11期)2019-07-04 00:34:38
计算机技术与发展(2019年1期)2019-01-21 00:56:38
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
