
面向乘员的船上服务冷启动个性化推荐方法
2022-03-24 04:18李亚鹏李敬花张子祥周青骅
应用科技 2022年6期
李亚鹏,李敬花,张子祥,周青骅
1.哈尔滨工程大学 机电工程学院,黑龙江 哈尔滨 150001
2.哈尔滨工程大学 船舶工程学院,黑龙江 哈尔滨 150001
随着海上生活服务平台、旅游平台、大型邮轮等具有高密集度人群的船海类产品不断发展,船上服务行业的重要性日趋突出,越来越多的远洋客船开始利用智能化、网络化的手段开发网络化服务系统,为船上乘员提供服务。同时,乘员在船上生活中的个性化服务需求日益增加,如何结合乘员自身特征为其提供个性化的服务成为船上网络化服务系统亟需解决的问题。推荐系统的概念提出后,在电子商务、菜品、音乐推荐等方面得到了广泛的应用,但结合船上服务的特殊环境,存在以下问题:
1)对首次登船乘员产生的服务推荐困难问题。由于远洋客船服务环境的特殊性,多数远洋客船在近几年逐渐应用网络化服务软件为乘员提供服务。多数乘员均为首次登船,且对于船上网络化服务软件的使用同样尚属首次。网络化服务软件无法获取这些乘员的服务偏好,无法为乘员提供个性化服务。
2)服务资源使用率问题。船上各类服务项目存在流行度差异,部分热门服务可能因为船上乘员过多存在排队时间长、人员拥堵等现象。如果按照传统的推荐方式向乘员推荐船上服务项目,许多冷门的服务项目可能会因为流行度较低而不被人关注。面向拥有小众爱好的乘员,无法真正为其进行个性化推荐。
船上乘员首次登船产生的服务推荐困难问题是典型的新用户冷启动问题。针对冷启动问题国内外已经进行了大量研究,并且在我们日常使用的订餐及购物等平台上已经应用,部分依然存在过拟合的问题,不能很好地满足用户的需求。关于冷启动模式研究还在不断发展,其中包括基于项目流行度、项目评分、用户参与、辅助数据、多媒体信息推荐、跨领域推荐等传统方式[1-2];也包含有融合用户偏好属性、热门物品惩罚因子、项目流行度的改进冷启动推荐模型[3-4],通过融合推荐项目属性信息、反向信息[5]或统计学信息[6]来进一步提高推荐准确程度。随着冷启动问题的深入研究,研究人员通过对基本的策略方法整合改进,建立了针对用户获得推荐信息前后场景动态变化的模型[7],包括考虑动态情景和动态时间的推荐策略方法[8];另一方面也有通过融合条件构建主体进行主体建模的方法[9-10],对不同以及新进用户进行高效推荐,更好地解决冷启动问题。为使船上乘员能够更好地享受船上服务,充分利用船上各类服务项目资源,提高船上网络化服务系统推荐质量[11],本文将结合某国产大型客船船上服务智慧社区系统研发项目,针对面向乘员的船上服务冷启动个性化推荐系统部分进行研究。通过将人口统计学方法和乘员初始标签与传统协同过滤推荐算法相结合的方式,进行乘员群体的预处理,同时根据项目的流行度和客容量对推荐内容进行实时调整,以达到对乘员的个性化推荐效果。
1 推荐算法
1.1 基于人口统计学的推荐算法
对于冷启动推荐系统,除了通过利用注册用户提交的基本信息,还可以结合用户对初始采集时特定项目的评分和浏览记录来引导乘员进行兴趣显示,设置初始化界面。目前,多数用户为获得软件或网站提供的个性化推荐信息,不介意提供个人的性别、年龄、职业、教育背景和兴趣爱好等相对不敏感的信息;更多的软件通过QQ、微信等社交软件进行登陆,这种方式能够获得更加完善的用户信息。基于人口统计学的推荐算法是将用户的性别、年龄、职业、地区等信息构建用户特征模型,并根据特征模型来计算用户之间的相似性,从而找到相似用户,获得推荐信息,其基本流程图1 所示。

图1 基于人口统计学算法基本
基于人口统计学的推荐算法不需要历史数据,没有用户冷启动问题,也不依赖于物品属性。但由于算法采样信息比较局限,获取信息精确度不够,不能够保证提供准确且根据用户习惯调整的推荐模型。因此本文设计的推荐系统在初始时刻考虑用户地区、年龄、职业等信息进行层次聚类以确定相似群体作为用户首次使用的推荐依据[12],并且通过初始兴趣爱好标签采集作为推荐打分的一部分,而后用户的个性化需求还需要与其他推荐算法结合使用,从而得到更加准确的推荐结果。
1.2 基于协同滤波算法的推荐算法
协同过滤算法通常可以分为基于用户的协同过滤算法(user-based collaborative filtering,UBCF)(如图2)和基于物品的协同过滤算法(item-based collaborative filtering,IBCF)[13]2 种类型。结合船上服务特点,本文将采用基于用户的协同过滤算法,以用户偏好的信息作为输入数据集,通过选择相似度计算方式对相似度进行量化计算得到最近邻用户集,以此为用户推荐个性化的服务项目。
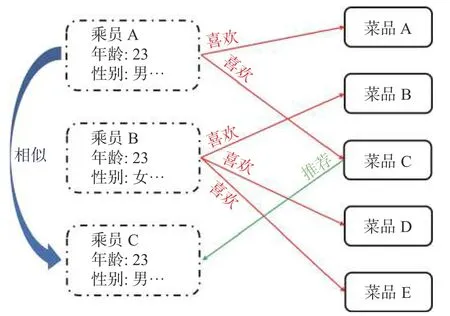
图2 基于用户的协同过滤算法
相似度计算需要找到目标用户的最近邻用户集,最终为目标用户生成一组推荐。通常包括以下3 个步骤。
1)用户数据表示。使用m×n阶矩阵来表示用户的评分信息,如表1 所示。评分分为5 个等级,其中一般是以1~5 的整数取值,用以表示用户对偏好的喜爱程度。
2)相似性计算。计算用户间相似性的目的是为目标用户找到最邻近的用户集,相似度一般用sim(s,t)来表示,在进行相似度计算时有欧式距离、余弦相似度和Pearson 相关系数等方法[14]。
欧式距离法。欧氏距离法通过计算2 点间的绝对距离来衡量相似性,用一行n列的行向量Au来表示用户u对所有项目的评分,其计算公式如下
式中:Au和Av表示用户u、v的特征向量;sim(u,v)值越大,说明用户间相似性越高。
余弦相似度法。通过2 个用户向量的夹角余弦值大小来量化用户之间的相似度,通过计算可得其余弦角越大相似度越高。余弦相似性的计算公式为
Pearson 相关系数法。设用户u、v进行过相同评分的集合为I,则用户u、v之间的 sim(u,v)可通过Pearson 系数进行计算。其计算公式为
式中:Ru,i、Rv,i分别表示用户u、v对偏好项目i的评分,和分别表示用户u、v对所有项目的平均评分。
3)生成推荐序列。选择一种相似度计算方式计算用户之间的相似度得到最近邻用户集,用Pu,i表示用户u对偏好项目i的预测评分,可通过用户u对最近邻集合U中用户的评分加权相似度的值得到。其计算公式为
根据项目需求情况采用单个项目的相似度或者平均相似度作为依据标准,选择评分最高的个偏好项目推荐给目标用户。
2 面向船上服务的乘员个性化推荐算法
2.1 用户相似度的计算方法
为缓解乘员首次登船时产生的冷启动问题,对基于人口统计学的推荐算法进行改进。在考虑用户属性对相似度的影响时,会存在如用户a和用户b在用户性别、年龄等基础属性上差异较大,但兴趣爱好类似的情况。由此考虑在推荐船上服务项目时,兴趣爱好这一属性的权值应大于乘员基本属性。因此,在乘员首次登船使用船上网络化服务软件或系统时,提供爱好标签供乘员进行选择,记录乘员的兴趣爱好标签信息。
乘员在登船时,通过乘员注册信息可以获取到的用户基本属性包括年龄、性别、职业,如表2所示。原始的乘员人口统计学信息需要处理后使用。
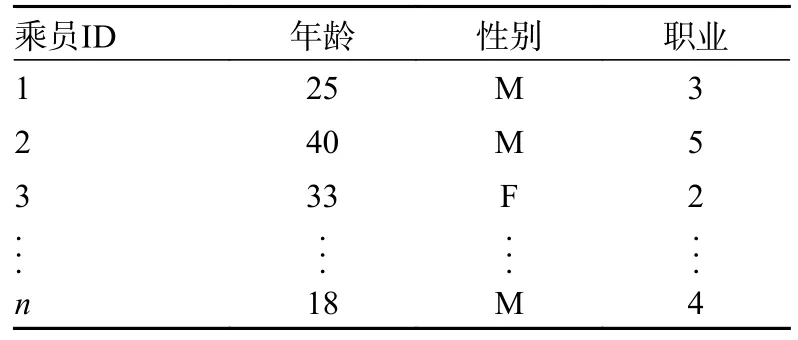
表2 乘员人口统计学信息
乘员年龄。首先根据年龄段对乘员年龄信息进行处理,将乘员年龄划分为7 组数据(用数值1—7 表示):年龄小于18 岁、年龄18~25 岁、年龄26~33 岁、年龄34~41 岁、年龄42~49 岁、年龄50~57岁以及年龄58 岁及以上。
乘员性别。性别男(M)、女(F)分别用1、0表示。
乘员职业。原有乘员表中有X个分类,根据《中华人民共和国职业分类大典》,将所有乘员职业分为7 类,使用数字1—7 表示。
用户属性差异度值越大,说明用户间相似性越高。
乘员在首次使用船上网络化服务软件或系统时,选择个人的爱好属性标签,即通过字段来描述这一属性。通过用户标签与已有用户选择标签的情况进行对比分析得到之间的相似度情况,并将得到的相似度情况作为首次使用的推荐情况,计算公式为
式中:n为可供选择的所有标签数,k为目标用户s与已有用户t之间共有标签的数量。
在进行用户间相似度计算时,引入权重系数W,用来调节不同属性在进行相似度计算时各自所占的权重[15]。为保证算法在目标用户产生评分信息后仍然能够持续地进行推荐,将上述根据用户属性的相似度计算方法与Pearson 相关系数法结合,形成的用户s和t之间的相似度计算方法为
式中w1+w2+w3=1。
目标用户项目评分预测:在完成目标用户与现有用户相似度计算后,按照相似度从高到低选取K个用户作为目标用户的近邻用户集,记为Ni=(N1,N2,···,NK),同时,合并所有近邻用户Ni的评分项目集合为C。
对所有船上项目x属于集合C,计算目标用户的预测评分,计算公式为
式中:Pi,x为目标用户i对项目x的预测评分,Rx为用户i的近邻集,Rj,x为用户j对项目x的评分,sim(i,j)为用户i与用户j之间的相似性。
将目标用户对其近邻项目集合C中所有项目的预测评分按照按降序进行排序,选取前N个项目作为目标用户的推荐序列。
2.2 考虑项目流行度和客容量的推荐修正
前述研究中,基于船上新乘员的人口统计学数据以及喜好标签信息,初始化其与其他乘客的相似度列表,得到最近邻用户集,以此来预测新乘客的偏好信息。但是,在整个过程中,船上不同偏好项目的权重始终保持为一种状态是不合理的。因为从社会学角度来看,所有事物都遵循着“马太效应”。比如在电商网站中,流行的商品容易被更多人购买,同时冷门的商品则会变得愈加不被人们发现与了解,显然这并不符合个性化推荐的初衷。船上各类服务项目预设有每日客容量属性,但由于存在流行度差异,部分热门服务可能因为船上乘员过多前往而导致出现排队时间长、人员拥堵等现象。以此在进行推荐模型建立的过程中也需要避免产生过拟合的情况,即为所有用户都推荐最热门的项目的同时需要考虑船上服务项目容量属性,并进行均衡。考虑到一些用户的个性化需求的特点,冷门项目的推荐则更能体现系统针对用户的细微特点偏好提供的优质服务特性,同时避免了过量用户非个性化兴趣的数据所占权重过大情况。
在船上各类服务项目使用过程中,船上网络化服务系统能够采集到所有项目每日使用情况,结合项目预设每日客容量,在目标用户项目评分预测公式中引入考虑项目流行度和客容量的权重因子。船上项目x预设每日客容量为m,实际每日接待乘员数量为n,权重因子计算仅统计最近30 d乘员使用数据。将每个项目的平均使用率作为项目流行度,则Qx=n/m为每日项目使用率,Q¯x为近30 d 内该项目的每日平均使用率,即该项目在近30 d 内的流行度。用Qmin表示最不流行项目的流行度,Qmax表示最流行项目的流行度,则项目流行度和客容量的权重因子为
因此,将考虑项目流行度和客容量的权重因子添加到目标用户评分预测公式中进行修正,得到新的评分预测公式:
通过加入项目流行度作为约束条件对模型进行改进得到新的最近邻项目集合,将目标用户对其近邻项目集合C中所有项目的预测评分按照降序进行排序,取前N个项目作为目标用户的推荐序列。
3 实验结果与分析
3.1 运行平台
本文所介绍船上推荐服务系统通过与某国产大型客船船上服务智慧社区系统研发项目相结合,并与船上订餐系统和船上导航系统实现集成兼容,作为系统子环节进行乘客服务,面向大型邮轮、客船人员密集、对服务质量要求高的特点,进行针对性的冷启动服务,以提供更好的用户体验。系统主要功能界面如图3 所示。

图3 高技术客船网络化服务平台主功能界面
本文验证设备及环境参数如下:操作系统为windows10-64 bits,环境配置为Anaconda3、Python3.8.8,处理器为intel i7-8550U,内存为 8 GB。
3.2 案例验证
在对所设计推荐算法的具体验证中结合船舶智能化推荐服务中需求,本文将以菜品推荐为例进行面向冷启动乘员的船上服务个性化推荐方法验证分析,其中测试数据集选择来自大众点评,数据信息说明如表3 所示,用户评分数据格式如表4 所示。

表3 数据信息说明

表4 用户评分数据格式
测试数据集由restaurants、ratings 和links 这3 个部分数据构成,其中rating 部分包含口味评分rating_flavor、环境评分rating_env 和服务评分rating_service。本文只选择利用口味评分作为打分依据,通过对数据(其中包括缺失数据及异常数据清理)预处理,针对餐厅评分数据进行匹配推荐,将推荐结果通过映射关系为特色菜品评分,从而满足本文实验验证分析需要。
1)进行人口统计学分类处理。如表2 所示,通过在系统初始冷启动阶段对乘员人口统计学信息的收集,对其中包括年龄、性别、职业、地区及与菜品口味的关联情况进行聚类分析。此处针对菜品推荐,选择将国内地区作为主要因素进行差异性层次系统服务进行层次聚类分析,划分不同口味。淡味区:江苏、浙江、上海、福建、广东、香港、澳门;微辣区:山东、江西、北京、广西、陕西、宁夏、甘肃、青海、新疆;重辣区:湖北、湖南、贵州,重庆、四川;多味区:河南、安徽、河北、天津、黑龙江、吉林、辽宁、内蒙古、西藏、云南、海南、台湾。根据K-means 聚类结果,将每个类组作为考虑项目流行度和客容量的协同过滤推荐系统的输入数据进行处理,以提高系统在冷启动时的推荐精度。输入数据经过处理表现形式通常为1 个如表1 格式的i×j的用户评价矩阵,其中i是乘员数,j是菜品数,Matrix[i,j]表示第i个乘员对第f个菜品的评价。
2)进行基于协同过滤算法的推荐。程序具体实现步骤如图4 所示。
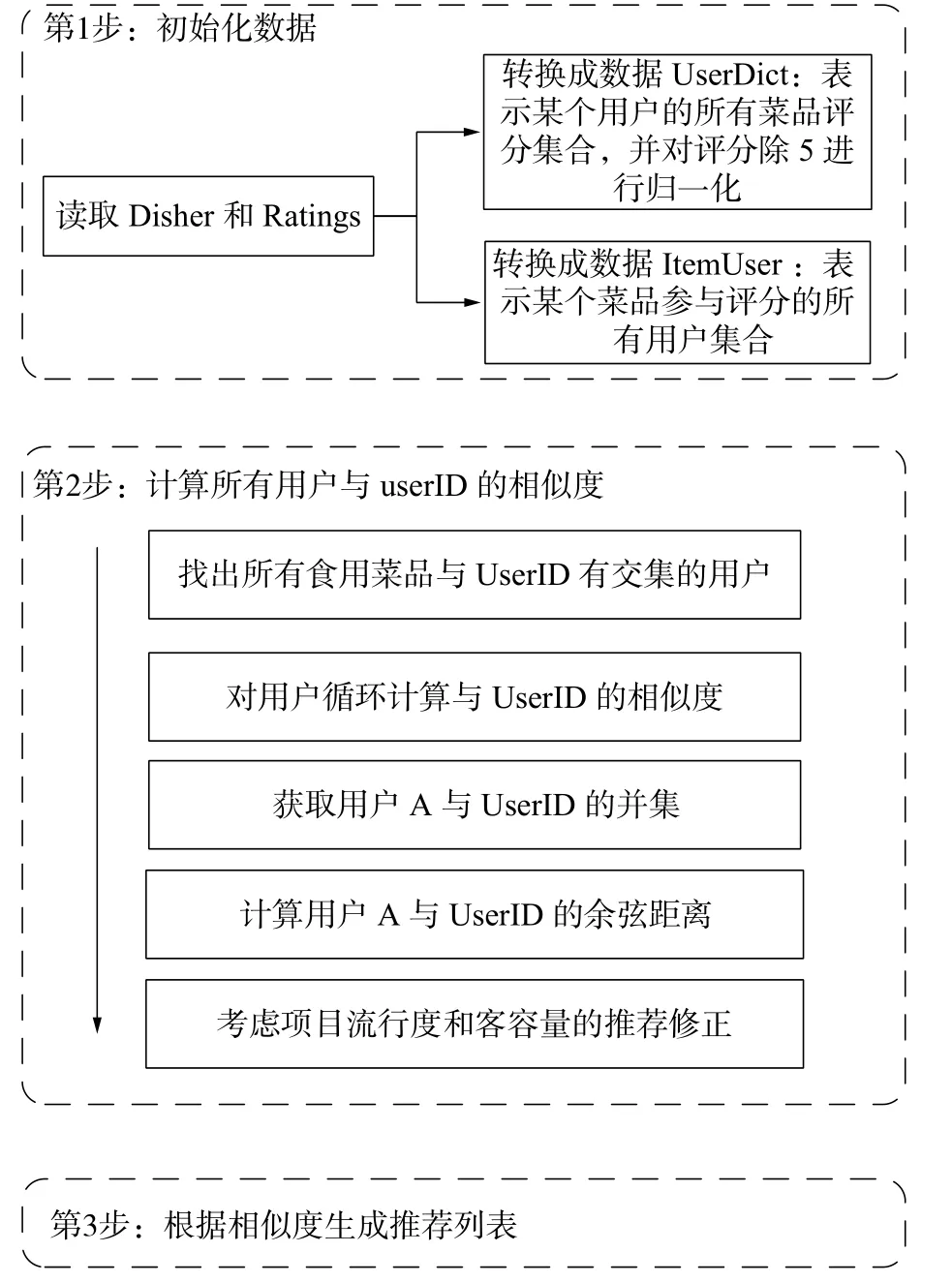
图4 协同过滤步骤
在结合数据集进行算法验证过程中通过设置用户1 为目标推荐用户进行推荐,其中关于目标用户1 的相关数据如表5 所示。通过上述所设计模型得到推荐结果如表6 所示,其中设置相邻用户n为6,设置推荐个数k为4。
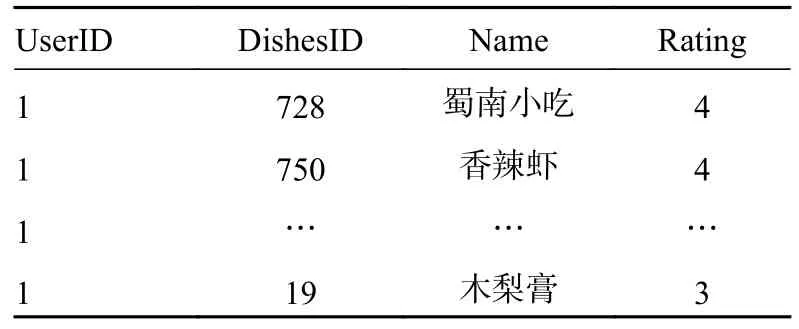
表5 目标推荐用户1 相关数据

表6 推荐结果
4 结论
本文通过对船上服务冷启动进行分析,建立服务推荐模型,在传统协同过滤推荐算法基础上,结合人口统计学方法和乘员初始标签选择,实现对新乘员进行个性化推荐,进而提升乘员的服务体验。通过在实际海上客运服务系统中进行实例验证,证明可用于船舶服务智能化推荐。
本文研究方法可使船上乘员能够更好地享受船上服务,充分利用船上各类服务项目资源,提高船上网络化服务系统推荐质量。本文方法仍需做进一步改进研究,存在诸如针对每种服务仍然要进行不同的人口统计学分析,进行菜品推荐时地区因素所占权重较高,但在进行电影推荐时年龄及性别因素所占权重就要大于地区,这些问题都有待进一步优化服务场景,以进行更加准确的相似度计算。此外,对不同船上服务项目推荐实现需要与船上服务项目客容量、交通等设施的动态变化相融合,通过对用户属性权重进行动态调整以达到更好的推荐效果。
猜你喜欢
中国特种设备安全(2022年6期)2022-09-20
重庆大学学报(2022年6期)2022-06-23
客联(2021年2期)2021-09-10
文苑(2020年4期)2020-05-30
新闻传播(2018年12期)2018-09-19
汽车电器(2018年1期)2018-06-05
汽车与新动力(2016年6期)2017-01-04
汽车文摘(2015年11期)2015-12-02
中国卫生(2015年1期)2015-01-22
