
基于注意力机制结合CNN-BiLSTM模型的电子病历文本分类
2022-03-24 04:00李超凡马凯
科学技术与工程 2022年6期
李超凡, 马凯
(徐州医科大学医学信息与工程学院, 徐州 221004)
自然语言处理(natural language processing,NLP)起源于20世纪40年代,集语言学、数学、计算机科学和认知科学等于一体的综合性交叉学科[1]。基于自然语言处理技术应用的临床信息系统覆盖了信息抽取、文本分类、医疗辅助决策、医疗信息问答、医学知识挖掘及知识库建立等诸多领域。电子病历文本的处理技术主要包含句法结构分析、文本分类、命名实体识别、实体关系识别、信息抽取、构建临床知识图谱等。
文本分类是指建立文本特征与文本类别之间的关系模型,从而进行文本类别的判定。文本分类的主要算法模型,基本上可分为3类:基于规则、基于统计和机器学习、基于深度学习的方法。
(1)基于规则的方法借助于专业人员的帮助,为预定义类别制定大量判定规则,与特定规则的匹配程度作为文本的特征表达[2]。受限于人为主观性、规则模板的全面性和可扩展性,最主要的是规则模板完全不具备可迁移性,所以基于规则制定进行文本分类模型并没有得到有效的进展。
(2)基于机器学习的文本分类算法主要包括决策树法(decision tree,DT)、朴素贝叶斯算法(naive bayesian,NB)、支持向量机算法(support vector machine,SVM)、K-邻近法(K-nearest neighbors,KNN)等算法。刘勇等[3]提出一种结合决策树分类效果和类概率的加权投票方法,同时采用随机搜索和网格搜索结合的方式优化模型参数,提升随机森林的决策能力。Chen等[4]构造不同类别的整体相关因子,通过平衡偏差和方差得到最优相关因子的计算方法,提升朴素贝叶斯的分类精度。胡婧等[5]提出一种基于粗糙集的词袋模型(bag of words,BOW)结合支持向量机的算法模型,利用粗糙集的属性简约算法清除模糊冗余的决策属性,增强文本的特征表达。Liu[6]提出一种基于Simhash的改进KNN文本分类算法,通过计算相邻文本的平均汉明距离[7]解决了传统KNN文本分类算法的计算复杂性和数据不均衡性。以上改进的机器学习模型虽然一定程度上提高了文本分类的效果,但是仍需要人为的进行特征选择与特征提取,忽略了特征之间的关联性,通用性和扩展性较差。
(3)基于深度学习的文本分类算法主要包括卷积神经网络(convolutional neural networks, CNN)、循环神经网络(recurrent neural network, RNN)、长短期记忆神经网络(long short-term memory, LSTM)等,以及各类神经网络模型的变种融合。随着word2vec[8-9]词向量模型的引入,可以将词序列转换为低维稠密的词向量,并包含丰富的语义信息,使得神经网络模型在文本分类任务得到广泛应用。卷积神经网络通过卷积核设置不同的权重,从而获取文本多维特征,通过池化操作提取局部关键信息,因其特有的权值共享策略使得训练模型参数较少,网络结构简单高效且鲁棒性强。传统的CNN改进方法大多关注于更有效的提取文本的局部关键信息,严重忽略了上下文语义关联对分类效果的影响。王海涛等[10]提出一种基于LSTM和CNN的混合模型,利用3层CNN结构提取文本的局部特征,利用LSTM存储历史信息的特征,再将各自输出向量进行融合,从而提升分类效果。赵宏等[11]提出先利用BiLSTM提取文本的上下文信息,再利用CNN对已提取的上下文特征进行局部语义特征提取,验证了串行混合模型的有效性。基于模型融合的方式虽然一定程度上丰富了词向量的语义表示,更好的提取文本特征,但是没有考虑到不同的特征对分类模型的影响。李昌兵等[12]通过将改进的TF-IDF对word2vec词向量进行加权表示,再利用CNN挖掘从局部到全局的特征表达,加强了词向量本身对于分类模型的信息贡献。注意力机制[13]的引入,更加有效地对神经网络输出进行特征筛选与特征加权,降低噪声特征的干扰,获取文本的重要特征。汪嘉伟等[14]通过CNN得到单词的上下文表示,引入自注意力机制计算文本相似度捕捉长距离依赖。田园等[15]利用Attention机制处理BiLSTM隐藏层的输出,增强文本中与标签类别相关的特征表示,进而得到文本的加权语义向量。刘鹏程等[16]更是以交互注意力机制,捕捉BiLSTM和CNN所提取特征中的关键特征融合形成分类特征,在多维数据文本分类中取得了优越的性能。
电子病历区别于其他文本存在高维稀疏、医学术语词汇密集的特性,存在文本分类精度低、算法模型收敛速度慢等性能问题。在传统CNN神经网络模型与BiLSTM神经网络模型的基础上,现提出一种基于词嵌入技术结合CNN-BiLSTM-Attention模型应用到中文电子病历疾病种类的文本分类任务;所提模型能够结合CNN和BiLSTM处理文本分类任务的优点,并利用Attention机制进行特征提纯,有效地改善模型的整体结构,提升模型进行文本分类的性能。
1 模型设计与方法
病历文本分类模型如图1所示,主要包含5层网络结构:词嵌入层、CNN层、BiLSTM层、注意力层和Softmax层。
(1) 词嵌入层:加载预训练的word2vec模型自定义embedding权重矩阵,依据分词处理后的病历文本序列(w1,w2,…,wn)转换为低维稠密的词向量序列,作为神经网络的输入。

图1 基于CNN-BiLSTM-Attention的病历文本分类模型Fig.1 Medical record text classification model based on CNN-BiLSTM-Attention
(2)CNN层:设置3个卷积核数量相同,大小不同的卷积层,经相同的池化层进行特征降维,扩大模型的感受野。利用Conatenate层串联3个池化层的输出,表征更加丰富的局部特征。
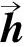
(4)Attention层:对BiLSTM层的输出进行特征凸显,即为不同的特征赋予相应的权重,对影响模型分类效果的关键特征进行聚焦操作,增强病历文本的特征表达。
(5)Softmax层:引入全连接层降维,并输入softmax 分类器计算病历文本属于疾病类别标签的概率分布,直接输出预测结果。
2 模型构建
2.1 数据预处理
实验数据集来自徐州医科大学附属医院真实电子病历文本,从入院记录、病程记录与诊疗计划等方面,合理筛选包含疾病与诊断、症状与体征与治疗方面的1 164条病理描述句,包含608条糖尿病数据与556条帕金森病数据,如图2所示。
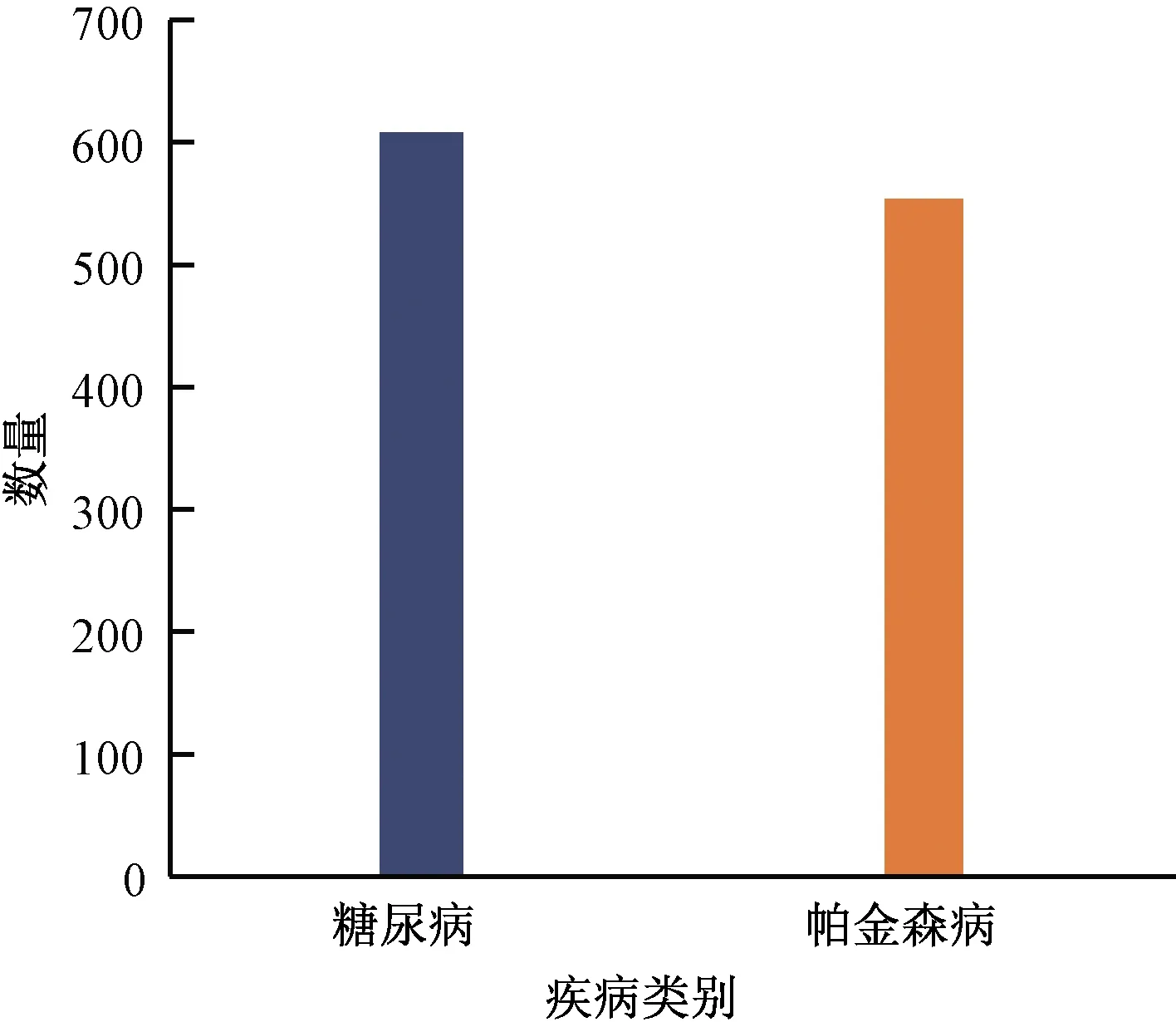
图2 电子病历数据集样本分布Fig.2 Sample distribution of EMR dataset
对于原始电子病历数据集,首先利用Jieba分词模块加载用户自定义词典,如医学术语表ICD-10[17]、MedDRA[18]等,以精确模式对文本序列进行分词处理。在分词任务结束后,结合哈工大停用词表、百度停用词表等构建停用词表库,遍历分词结果,去除停用词,形成原始语料库。
2.2 词向量表示
统计语言模型可视为词序列的随机概率过程,以相应的概率分布反映其属于某种语言集合的可能性。在自然语言处理中,主要采用独热表示(one-hot representation)和分布式表示(distributed representation)两种方式进行词向量表示。One-hot编码以词表大小作为维度表示词向量,极易造成高维稀疏性和维数爆炸的问题。分布式表示主要有基于矩阵、基于聚类和基于神经网络的3类表示方法。Google的word2vec[8-9]是目前最主流的基于神经网络的词向量计算模型,包含跳字模型(skip-gram)和连续词袋模型(continuous bag-of-words,CBOW)两类神经网络训练模型。Skip-gram是以中心词预测周围词,得到当前词上下文多重样本,适用于较大的数据集,CBOW工作方式则相反。
对于语料库的词嵌入方式,采用Turian等[19]提出的方法,以预训练的形式利用word2vec工具在领域内大规模语料上进行无监督学习,默认采用skip-gram模型,生成词向量并加载word embedding查找表。查找表对原始语料库的词序列进行词向量的映射,并在过程中不断学习和更新,使得目标词汇得到更完整和真实符合的语义向量表示。
采用One-hot编码对疾病类别标签进行独热编码,引入Tokenizer分词器对文本序列的每个词进行编号,将文本序列转换为词编号序列并采用补齐的方式调整语句序列长度,便于神经网络模型训练。
2.3 CNN神经网络层
对于病历文本输入序列S=(w1,w2,…,wn),wi∈Rd为word2vec预训练的词向量,其中d为词向量维度。卷积核的宽度与词嵌入维度一致,每次卷积操作的窗口取词数记为h,即卷积核ω∈Rh*d。对于每一次窗口滑动的卷积结果ci为
ci=ReLU(ωwi:i+h-1)+b
(1)
式(1)中:ReLU为非线性激活函数;wi:i+h-1为每次卷积操作的取词数;b∈R为偏置项。
序列S的长度为n,窗口滑动n-h+1次,卷积汇总结果c=[c1,c2,…,cn-h+1]。接着依据池化层的窗口大小和步长对卷积层结果进行MaxPooling操作,增大上层卷积核的感受野,保留词嵌入向量序列的主要特征,降低下一层的参数和计算量,防止过拟合。
设置词窗大小不同、卷积核个数相同、设置padding参数为same模式保证输入向量和输出向量的维度一致、卷积核步长为1的3层CNN结构,对词嵌入向量矩阵分别进行卷积和池化操作。对3层CNN神经网络的输出按轴向进行concatenate操作,丰富CNN模型对词窗卷积的上下文语义含量,更好的表征病历文本序列的局部特征。
2.4 BiLSTM神经网络层
Hochreiter[20]为了解决循环神经网络因处理信息过多产生的长期依赖,导致梯度消失或梯度爆炸的问题,提出了长短期记忆神经网络,使用长短期存储单元替换RNN中隐藏层单元结构,有效的解决这一问题。LSTM单元结构如图3所示,通过将存储单元、输入门、遗忘门与输出门相联结,从而控制与更新门控单元的相关参数进行模型的学习和训练,即调整信息更新、遗忘的程度,使得存储单元能够有效地保存较长序列的语义信息。
在LSTM单元的具体实现过程中,对于t时刻,输入内容包括当前时刻输入向量xt、上一时刻存储单元信息ct-1与上一时刻隐藏层输出信息ht-1,输出内容为当前时刻的存储单元信息ct和隐藏层输出信息ht,其中σ为sigmoid函数,tanh为激活函数。it、ot、ft分别为输入门、输出门和遗忘门。
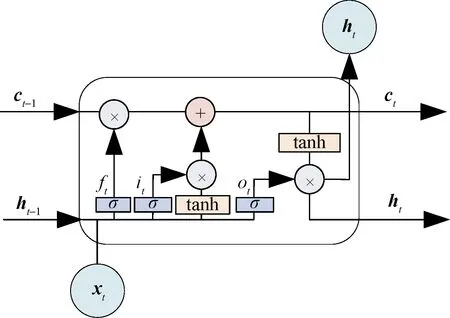
图3 LSTM单元结构Fig.3 LSTM unit structure
LSTM单元门控机制的计算过程如下
it=σ(Wixt+Uiht-1+bi)
(2)
οt=σ(Wοxt+Uοht-1+bο)
(3)
ft=σ(Wfxt+Ufht-1+bf)
(4)

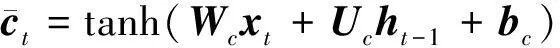
(5)
式中:Wi、Wo、Wf、Wc为不同门控机制对输入向量xt的权重;Ui、Uo、Uf、Uc为不同门控机制对隐藏层状态向量ht-1的权重;bi、bo、bf、bc为偏置向量。


(6)
当前t时刻的LSTM单元隐藏层输出ht由输出门与存储单元ct相计算得到。
ht=οttanh(ct)
(7)
BiLSTM模型将t时刻LSTM单元的前向和后向的输出进行拼接:
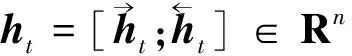
(8)
式(8)中:Rn为n维向量集。
BiLSTM神经网络层以CNN神经网络层的输出向量为输入,对门控机制的权重矩阵W和偏置矩阵b进行随机初始化正态赋值,LSTM单元基于上一个时刻的隐藏层输出信息与当前时刻的输入信息,计算遗忘门、输入门、输出门的数值,并与上一个时刻LSTM单元的存储信息整合,得到当前时刻的LSTM单元输出,同时更新当前时刻LSTM单元的隐藏层输出信息与存储信息,作为下一个时刻LSTM单元的输入[21]。最后进行前后向LSTM单元输出向量的拼接,输出具有双向语义的特征向量。同时,在LSTM单元的输入端和隐藏层的输出均引入dropout机制,解决训练模型参数量较大导致的过拟合问题。
2.5 基于Attention机制的特征加权
BiLSTM神经网络虽然可以建立前后文相关的语义向量信息,但是没有突显当前语义信息与上下文的关联性。在BiLSTM层的输出端引入注意力机制,可以有效地强调当前信息在上下文信息中的重要性与关联性,增强语义信息的特征表达,提升模型病历文本分类的性能。
首先计算注意力权重得分ei:
ei=tanh(wiht+bi)
(9)
式(9)中:wi为权重矩阵;ht为BiLSTM神经网络层的输出向量;bi为偏置向量。
其次使用softmax函数对注意力权重得分计算权重向量pi:
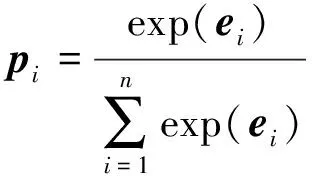
(10)
最后对BiLSTM层的输出向量ht与权重向量pi进行点乘与累加操作,得到注意力层的输出Att,依据权值大小给隐藏层输出分配相应的注意力资源,构成特征向量的加权语义向量表示,增强病历文本序列的特征表达。

(11)
2.6 输出层
在注意力层之后引入全连接层,将病历文本特征加权向量映射到疾病种类的标记空间中,并在全连接层之后引入Dropout机制,避免权值更新只依赖部分特征和模型过拟合现象。使用softmax分类器计算病历文本所属疾病类别的概率分布,直接输出模型预测结果。
2.7 损失函数
设置softmax交叉熵损失函数为模型整体训练的损失函数:

(12)
3 实验结果与分析
3.1 实验环境与方法
实验软件环境为Window10操作系统,Python 3.6编程语言,深度学习框架Tensorflow 1.14.0,Keras 2.2.5,分词工具jieba 0.42;硬件环境为Inter Core i7-10700K-3.8GHz,32 GB内存,Nvidia GeForce 3070显卡。电子病历文本数据集采用交叉验证的方式进行实验,按照3∶1∶1的比例划分训练集、验证集与测试集。
3.2 实验超参数
采用Word2vec词向量工具的Skip-gram训练100维词向量,上下文词窗口设置为4,更好地表示词向量的语义信息。采用3层CNN模型架构,词向量卷积窗口分别设置为3、4、5,经池化操作后,融合各层输出,丰富上下文的局部特征。设置LSTM单元数为128,dropout比例0.5,随机失活50%神经元,防止模型出现过拟合现象,提升模型的泛化能力。采用多分类交叉熵损失函数,设置批处理样本量为32,训练轮数为20,优化器Adam,交叉验证评估模型的预测性能,模型超参数设置如表1所示。

表1 实验参数设置
3.3 评价指标
常采用精确率(preciscion,P)、召回率(recall,R)及F1(F-measure)作为评价文本分类模型性能的指标:

(13)

(14)

(15)
式中:TP为正确文本预测为正确类别数目;FP为错误文本预测为正确类数目;FN为正确文本预测为错误类数目;F为精确率与召回率的调和平均值。
3.4 对比实验
为了验证本文方法的有效性,同时探讨CNN神经网络、LSTM神经网络和Attention机制在进行模型融合的作用机制,设置了10组对比实验,输入均为word2vec预训练的词向量,验证各类模型在进行文本序列处理时,对于文本特征的表达和提取效果,从而对文本分类模型造成的影响。对比实验构造如下。
(1)CNN:直接使用CNN对词向量进行卷积、池化、Flatten操作,提取文本序列局部特征,利用全连接层降维,并利用softmax分类器输出预测结果。
(2)TextCNN:设置3个不同大小的卷积核窗口,其他参数一致的卷积层和池化层,按行拼接池化层输出向量,丰富文本局部特征语义表达。
(3)LSTM:直接对输入序列进行后向语义建模,提取病历文本的高层特征,连接两个全连接层降维,直接输出预测结果。
(4)CNN-LSTM:先利用CNN提取输入序列的局部特征,再利用LSTM提取CNN输出的后向语义信息。
(5)LSTM-CNN:先利用LSTM进行后向语义建模,再利用CNN对LSTM的输出进行局部特征提取。
(6)CNN-BiLSTM:先利用CNN提取输入序列的局部特征,再利用BiLSTM提取CNN输出的前后向语义信息,进一步构建病历文本的特征表达。
(7)BiLSTM:直接对输入序列进行前后向语义建模,提取病历文本的高层特征,连接两个全连接层降维,直接输出预测结果。
(8)CNN-Attention:先利用CNN提取输入序列的局部特征,Attention机制对文本特征进行特征加权,降低噪声特征对分类效果的影响。
(9)BiLSTM-Attention:BiLSTM对输入序列构造前后文语义信息,提取病历文本的高层特征,Attention机制对文本特征进行特征加权,降低噪声特征对分类效果的影响。
(10)CNN-BiLSTM-Attention:先利用CNN提取输入序列的局部特征,再利用BiLSTM提取CNN输出的前后向语义信息,进一步构建病历文本的特征表达,Attention机制对文本特征进行特征加权,降低噪声特征对分类效果的影响。
经多轮实验,并对实验结果进行交叉验证,各类基线模型与融合模型的评价结果如表2所示,模型执行时间如图4所示。
为了进一步直观地展示CNN-BiLSTM-Attention模型进行病历文本分类任务的优越性,对每个模型的训练过程进行分析,为各模型训练过程验证集的准确率变化过程如图5所示。
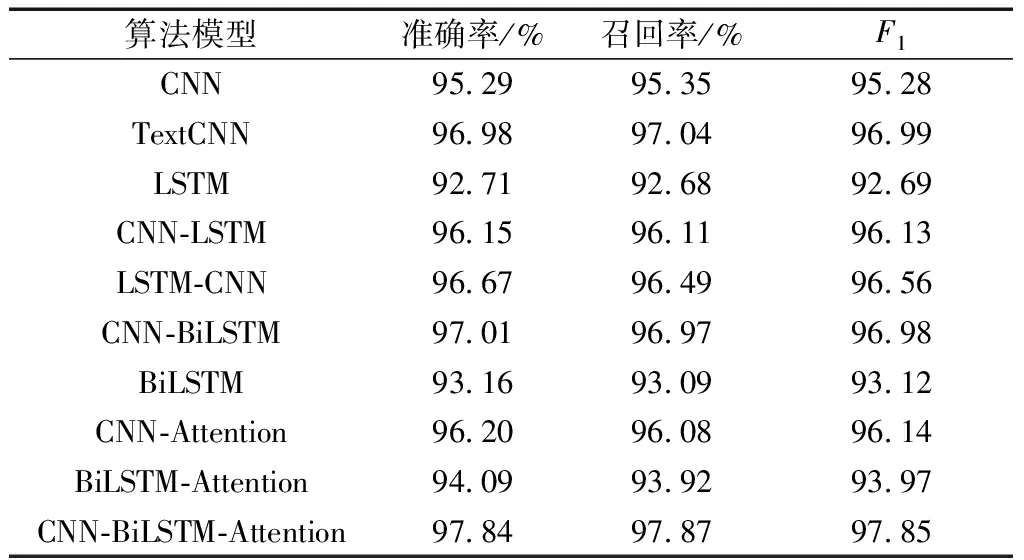
表2 不同算法模型的文本分类结果

图4 各类模型执行时间Fig.4 Execution time of various models
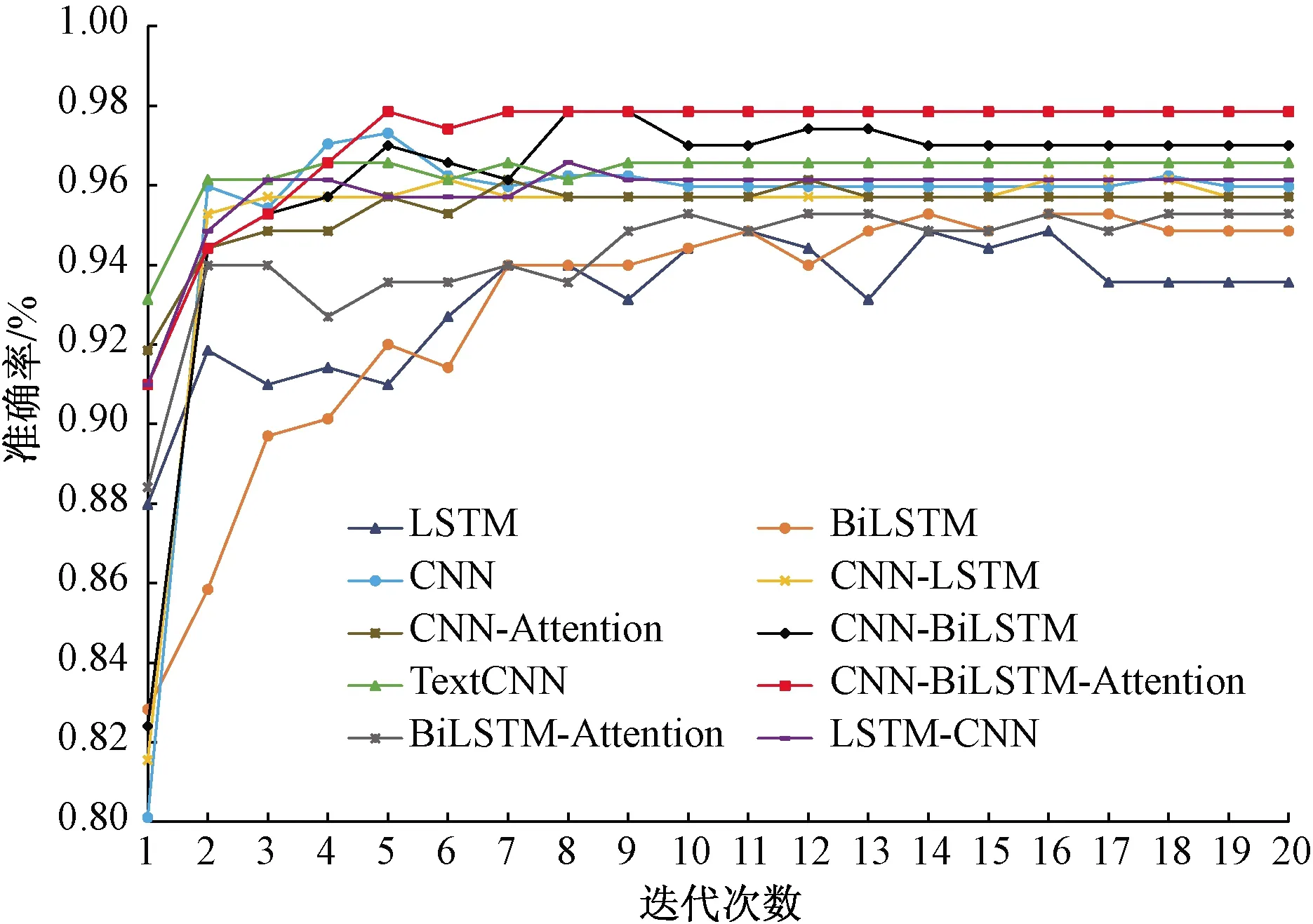
图5 各类模型验证集准确率变化趋势Fig.5 Accuracy trend of validation set of various models
3.5 实验结果分析
通过表2的实验结果可以得出,所提出的CNN-BiLSTM-Attention模型在评价指标结果中取得了最优异的效果,F1达到97.85%,相较于基线模型,总体效果提升2%~5%,由此可以得到本文模型在文本分类任务中的优越性。
对于CNN和LSTM的基线模型,CNN的模型性能明显优于LSTM模型。主要的原因在于所采用的原始病历数据集是由人工进行预筛选,对疾病的主要病症、诊疗方面的短文本描述句,上下文关联性不强,且含有众多临床术语,整体词向量具有高维稀疏性。CNN对于短文本擅长捕捉局部特征信息,短文本的特征大多是独立无关或者集中在句子的某个局部,而LSTM捕获的上下文特征信息较为冗杂且相关性不高,所以在所应用的病历文本数据集中,CNN模型的分类效果比LSTM模型高2.6%左右。
以CNN作为基线模型,以CNN、TextCNN、CNN-Attention与CNN-BiLSTM-Attention为例,TextCNN通过不同的卷积核尺寸提取文本序列的N-gram信息,再利用相应的池化操作提取卷积操作的关键信息,然后再将池化层的输出进行拼接,相较于CNN结构,更加丰富地抓取了局部特征,进行了词窗内词向量的多维表示,所以在总体评价指标上优于CNN结构,F1高于基线模型1.7%。相较于CNN-Attention结构,Attention机制为CNN提取的局部特征进行特征加权,降低了噪声特征对分类效果的影响,因此在整体性能上也提升0.9%左右,但是仍略低于TextCNN,原因主要是由于对于病历短文本陈述句,最大池化操作的作用就是突出各个卷积核操作提取的关键信息,与Attention机制的作用效果相像,而后续还会拼接多个池化层的输出通过全连接层进行特征组合,所以会造成分类结果上略低于TextCNN。
以LSTM作为基线模型,以LSTM、BiLSTM与BiLSTM-Attention为例,对于BiLSTM模型而言,单一方向的LSTM单元处理病历文本序列并不能有效地表征前后文语义信息,而BiLSTM同时拼接两个方向LSTM单元的输出,加倍提升了模型计算复杂度,所以在整体分类效果上只提升0.4%左右。Attention机制的引入,明显提升了模型的分类效果,相较于LSTM和BiLSTM整体分类精度提升1.3%和0.8%左右,进一步验证了注意力机制进行特征加权,提升分类模型效果的作用。
对于CNN与LSTM的混合模型,可以明显得出LSTM-CNN比CNN-LSTM的串联模型性能更加优越。CNN虽然可以较好的提取词窗内的语义特征,同时也会造成信息丢失,在只对单向LSTM进行后向序列信息计算时,会造成一定的信息差异。而LSTM向后传递的语义信息是完整的,再通过CNN的局部关键信息提取,所以LSTM-CNN模型的分类效果略高于CNN-LSTM模型。相较于CNN-BiLSTM模型,BiLSTM对CNN的输出进行前后向序列化特征加工,对模型的分类效果起到了正向作用,比另外两种递进结构分别提升0.8%和0.4%左右。
依据算法模型的执行时间来看,CNN因其网络结构简单高效,执行效率最快,约为0.46 s/epoch(epoch为使用训练集的全部数据对模型进行一次完整训练),LSTM较CNN计算复杂度高,且BiLSTM加倍了计算复杂度,故BiLSTM-Attention执行速率最慢,约为2.44 s/epoch。本文模型的执行效率约为2.11 s/epoch,虽然在整体对比实验中处于劣势,但是其总体性能仍是本文的主要考虑因素。
依据各类算法模型在训练过程中的验证集准确率变化趋势来看,由于电子病历文本的特性,以CNN为基线的各类模型基本上在10个epoch后达到收敛状态,且准确率居高。以LSTM为基线的模型在整体上均有动荡的趋势,基本上在18个epoch才达到收敛。本文模型的验证集准确率变化趋势最为优异,在7个epoch后达到收敛状态,且准确率收敛在97.85%,明显高于对比实验的其他模型,进一步验证本文模型的有效性和鲁棒性。
4 结论
针对医疗领域的电子病历文本特点,结合CNN、LSTM和Attention机制的特性,提出了一种基于CNN-BiLSTM-Attention的文本分类模型,通过多层CNN结构提取词窗内的文本局部特征,通过拼接操作丰富文本的局部特征表示,作为BiLSTM的输入。通过BiLSTM进行前后向文本语义建模,获取文本序列的高层特征表达,再通过Attention机制进行特征加权,降低噪声特征的影响。实验结果表明,CNN-BiLSTM-Attention模型的执行效率和准确率在各类模型对比实验中均取得优异的效果,适用于电子病历文本分类任务。在接下来的研究中,将着重从词向量编码、注意力机制算法、整体模型结构以及模型的超参数设置等方面进行进一步分析,提升模型的文本分类任务的整体效率。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
趣味(语文)(2021年9期)2022-01-18
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
数学小灵通·3-4年级(2020年9期)2020-10-27
开放教育研究(2020年2期)2020-03-31
中国修辞(2017年0期)2017-01-31
中国卫生(2016年10期)2016-11-13
中国社会历史评论(2016年2期)2016-06-27
高中生学习·高三版(2016年9期)2016-05-14
长江学术(2016年4期)2016-03-11
