
基于特征量融合和支持向量机的滚动轴承故障诊断
2022-03-24 04:00汪峰周凤星严保康
科学技术与工程 2022年6期
汪峰, 周凤星, 严保康
(武汉科技大学信息科学与工程学院, 武汉 430081)
滚动轴承是大多数生产流水设备和运输设备的核心[1]。一旦出现了故障,轻则造成生产停止,工厂效益受到影响,重则造成人员伤亡,影响整个作业间人员的生命安全。因此,对滚动轴承的各种类型故障进行精确诊断和定点维修具有重要的工程意义。
现代化的轴承故障诊断大多依托人工智能算法方法,首先需要采集轴承运行状态时的各种故障振动信号,然后从振动信号中提取出数学特征,再输入到人工智能算法中进行状态识别以完成故障诊断[2]。振动信号的特征提取一直是这一流程中的关键的一环。杨婧等[3]提出了将信号相关度分析方法和网格搜索算法结合来进行特征提取。王圣杰等[4]将集合经验模态分解引进到希尔伯特黄变换(Hilbert-Huang transform,HHT)实现对HHT的改进,将改进的HHT结合拉普拉斯变换进行特征提取。韩松等[5]通过比较了不同算法的标准差和拉依达准则对数据进行了预处理,再通过主成分分析(principal component analysis,PAC)降维特征数据实现了特征提取。
经验模态分解(empirical mode decomposition,EMD)依据信号自身的局部特征进行自适应分解成若干个本征模态函数(intrinsic mode function,IMF)分量,广泛应用于滚动轴承复杂、波动的振动信号的特征提取[6]。时域信号包含的信息量大,是机械故障诊断的原始依据,通过选择和考察合适的信号时域参数可以对不同类型的故障做出准确的判断[7]。提取出来的多维特征量之间的相关性容易影响故障诊断率且多维特征量不利于支持向量机算法(support vector machines,SVM)的训练和预测,而主成分分析是一种可以有效消除数据的冗余、复杂信息并对其进行压缩的方法。鉴于此,现选择将EMD分解得到的IMF分量的上、下包络值矩阵的奇异值和时域特征参数作为特征量来提取,提取出两种特征量后使用PCA降维融合成新的融合特征量完成特征提取,再将融合特征量输入到SVM模型中以实现轴承故障信号更精确的诊断。
1 相关理论
1.1 经验模态分解(EMD)算法
EMD算法本质是依据振动信号的特征时间尺度得出一套流程来对原始信号多次筛分,最终筛选出多个IMF分量[8]。各IMF分量必须满足下面两个条件:极值点的个数与过零点的个数必须相等或最多相差1个;信号局部极大值与局部极小值确定的包络线的均值为零。其算法流程如图1所示。

n为循环次数;hn为原始信号x(t)与上下包络线均值序列mn的 差序列;c(n)为分离出的各IMF分量;rn为余项序列图1 经验模态算法流程Fig.1 Empirical modal algorithm flow
1.2 包络值矩阵与奇异值
(1)对EMD分解出来的IMF分量c1(t),c2(t),…,cn(t)进行Hilbert变换[9],则有
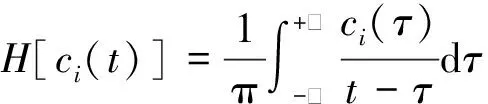
(1)
式(1)中:ci(t)为各个IMF分量;t为时间;τ为积分变量。
(2)再求出每个IMF分量的包络:

(2)
(3)由式(2)得到的振动信号的包络值矩阵记为C,假设C为m×n阶矩阵,由奇异值分解理论可知,存在正交矩阵U=[u1,u2,…,um]∈Rm×m和V=[v1,v2,…,vn]∈Rn×n,其中:um和vn分别为矩阵U和V的最后一列。使得
UTCV=diag[σ1σ2…σp]=S
(3)
则矩阵C的奇异值分解为
C=USVT
(4)
式(4)中:σ1≥σ2≥…≥σp≥0;σi(i=1,2,…,p)为C的奇异值;diag为取对角矩阵;S为奇异值组成的对角矩阵;矩阵U和V是C的奇异向量矩阵。
1.3 多分类支持向量机
标准SVM分类算法是二分类算法,只能将样本分为两类。轴承的故障类型往往不止两类,所以要用到SVM多分类器。SVM多分类器采用“一对一”算法[10],即在样本中任意选择两类训练成一个标准SVM分类器,N类样本则得到N(N-1)/2个标准SVM分类器。在预测过程中,将测试样本依次输入到这N(N-1)/2个标准SVM分类器,每个分类器都会预测出一个结果,然后统计出次数最多的预测类别即被认定为最终结果。标准SVM分类过程如下。
(1)将两个不同类别的样本(训练样本)的标签分别定义为1和-1。
(2)选定核函数类型,求解最优朗格朗日乘子a*。
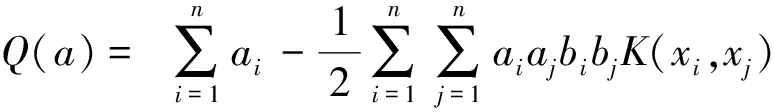
(5)
式(5)中:ai为拉格朗日乘子;K(xi,xj)为核函数;aj、bi、bj为推导过程变量。
(3)将任一支持向量X代入到式(6)中求偏差值b*得出判别公式f(X)构建SVM模型,将测试样本的属性值输入到SVM模型,根据判别公式f(X)输出的值将测试样本分类。

(6)
2 基于PCA的特征量融合
2.1 PCA原理
PCA是一种广泛用于特征降维融合的方法,通过线性变换将数据从高维空间映射到低维空间,消除了数据本身冗余、复杂的相关成分从而能更容易地对数据进行处理。将振动信号样本用向量矩阵表示成X=[x1x2…xn],xi为设备的各种故障信号,第l列Xl=[x1lx2l…xnl]T表示样本的特征量。其协方差矩阵[11]为

(7)
Sxui=λiui,i=1,2,…,n
(8)
计算样本xj和样本均值的差再与特征向量ui相乘得到对应的主成分分量为

(9)
所求特征向量构成n维正交空间,将样本投影到该空间即可得到对应的n维主成分量。定义累计贡献率为
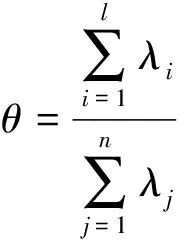
(10)
通常当累积贡献率θ≥0.95时,认为这l个主元包含了原始数据95%以上的信息,可用l个主元来表征原始数据,达到降维融合的目的。
2.2 特征量融合
由于振动信号的复杂性和不确定性,单一特征量无法全面地表征轴承振动信号故障特征信息,从而难以确保故障诊断准确率。因此,从轴承振动信号中提取出IMF分量上、下包络值矩阵的奇异值和原始信号的各种时域特征参数后,然后利用PCA将这两种故障特征量融合后得到信息互补的特征量,最后使用SVM进行故障诊断,故障诊断步骤如图2所示。
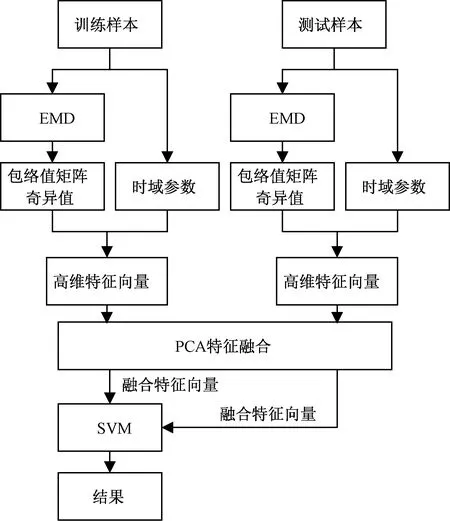
图2 故障诊断步骤Fig.2 Trouble shooting steps
3 实例分析
3.1 实验数据
实验的轴承数据选择美国凯斯西储大学轴承数据中心发布的轴承故障信号[12]。实验轴承为SKF6205深沟球轴承,电机荷载为0 hp,电机近似转速为1 797 r/min,采样频率为12 kHz,数据长度为2 048个点,具体的样本集如表1所示,样本集中4种状态下振动信号的时域图如图3所示。

表1 样本集Table 1 Sample set

图3 4种状态振动信号Fig.3 Four state vibration signals
3.2 IMF分量包络值矩阵的奇异值分析
EMD分解无须预先设定任何基函数,对任一信号具有自适应分解能力,分解的结果是唯一的,通常前几个IMF分量具有原始信号的主要信息[13]。所以本文选择对前5个IMF分量进行分析,图4为内圈故障1信号EMD分解的前5个IMF分量。由于篇幅有限,只给出图4中分量IMF1的上下包络图,如图5所示。
IMF分量突出了信号的局部特征且都是调幅调制信号,这样对IMF分量进行包络分析有利于特征提取。现在需要对包络信号定义一个合适的描述参数来作为特征量,奇异值是信号矩阵的固有特征且具有很好的稳定性,所以将奇异值作为特征向量显然是可以的。图6为前5个IMF分量上、下包络奇异值对比。
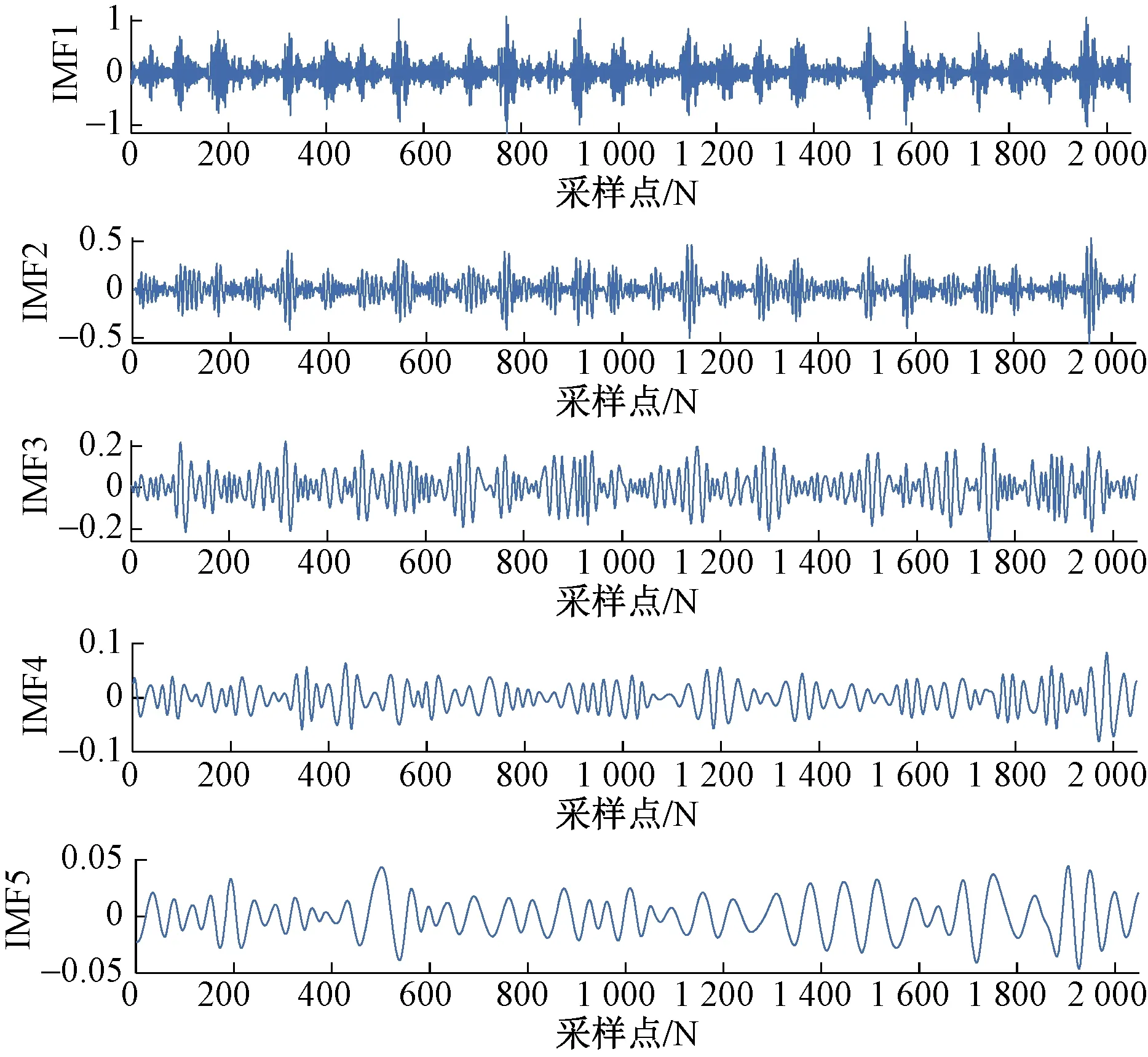
图4 内圈故障1信号前5个IMF分量Fig.4 The first five IMF components of the inner ring fault 1 signal
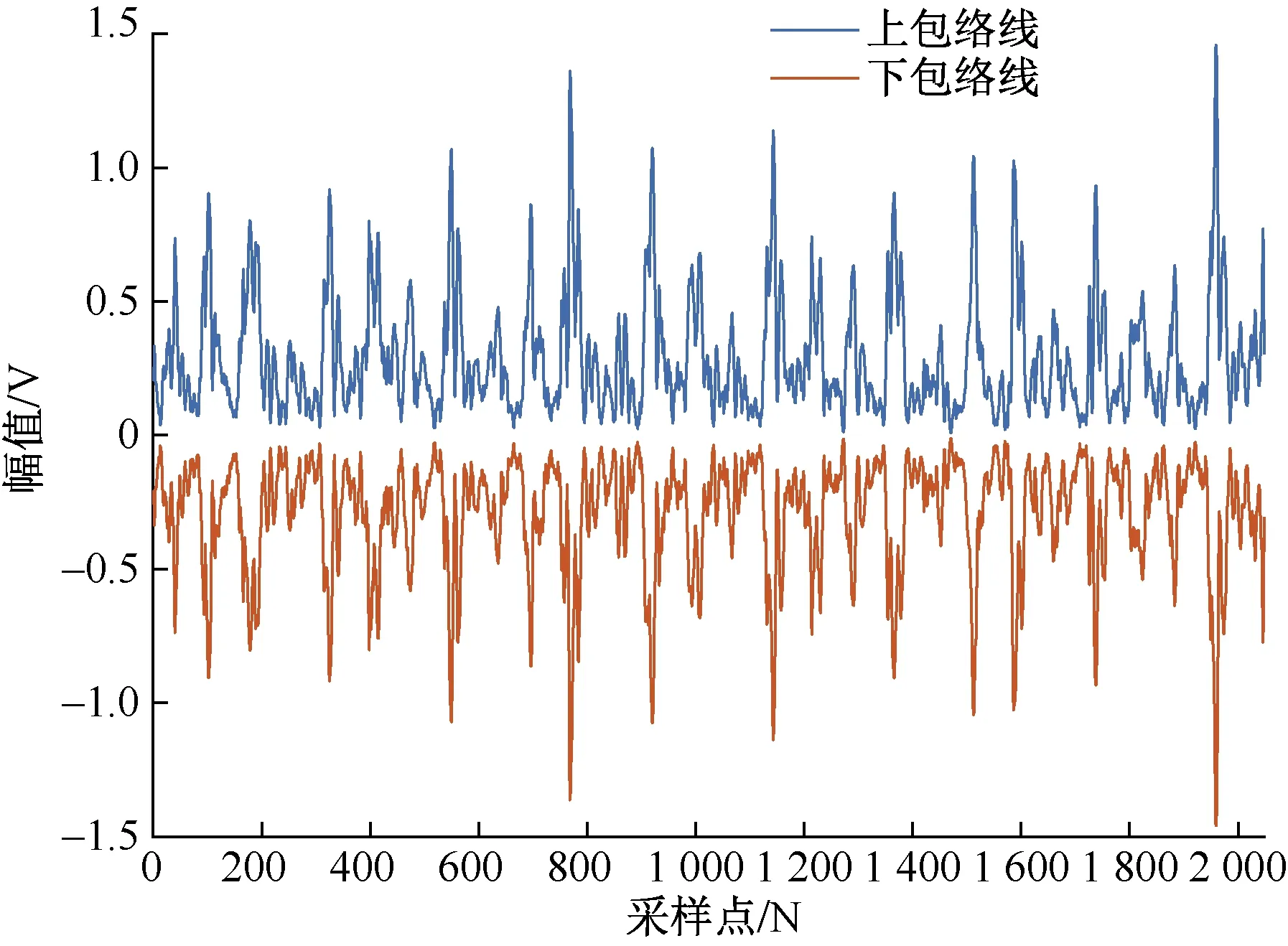
图5 分量IMF1的上下包络图Fig.5 Upper and lower envelope diagram of component IMF1

图6 前5个IMF分量上、下包络奇异值对比Fig.6 Comparison of the upper and lower envelope singular values of the first five IMF components
从图6中可以看出,奇异值的差异性逐渐在减小,这也说明了EMD分解的前几个IMF分量包含了原始信号大部分特征信息。为了从原始信号中挖掘出更多有用的特征信息以提高故障诊断准确率,选取前5个IMF分量。
3.3 特征量融合与故障诊断
轴承运行状态的改变引起振动信号的改变从而导致时域特征参数的变化,时域特征参数包含了其最根本的特征信息。在对每个样本提取出前5个IMF分量上、下包络值矩阵的奇异值后,再计算样本的13个时域特征参数,依次是最大值、最小值、峰峰值、均值、方差、标准差、均方根、峭度、偏度、波形指标、峰值指标、脉冲指标、裕度指标,即对每个样本提取出23维特征向量。所选时域特征参数计算如表2所示。
奇异值和时域特征参数包含了不同角度的故障信息,将它们进行融合将得到比信号单一特征更为敏感的特征向量。将得到的23维特征向量进行基于PCA的特征量融合,提取累计贡献率达到95%的主成分。经过PCA融合后,得到各主成分的贡献率及累积贡献率如表3所示。
从表3中可以看出,前5个主成分的累积贡献率已经达到了95.41%,因此,可以将前5个主成分代替原来的高维特征向量,剩余的主成分贡献率所占比重不到5%可以看作噪声成分而忽略不计。这样原来的23维特征向量被降维融合成了5维融合特征向量(前5个主成分)。同一故障尺寸不同状态和同一状态不同故障尺寸(以内圈故障为例)的前3个主成分绘制的样本空间三维图如图7和图8所示。

表2 所选时域特征参数

表3 主成分贡献率及累积贡献率

图7 同一故障尺寸不同状态前3个主成分样本分布图Fig.7 The sample distribution diagram of the first three principal components of the same fault size in different states
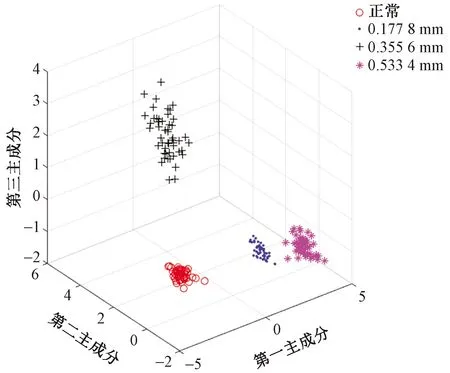
图8 同一状态不同故障尺寸前3个主成分样本分布图Fig.8 Distribution diagram of the first three principal component samples of different fault sizes in the same state
从图7和图8中可以看出,同一状态不同故障尺寸的故障信号分离情况较好,而同一故障尺寸不同状态的故障信号也基本得到分离,只有正常和滚动体1这两种状态出现了少部分干涉现象。下面将使用SVM进行更精确的故障诊断,将表1样本集的10种类型的样本标签依次定义为0、1、2、3、4、5、6、7、8、9。将样本进行PCA融合提取出融合特征向量后,对训练集进行SVM算法训练建立起SVM分类模型后,将测试集输入到模型中进行分类识别。为了验证融合特征量诊断的优越性,同样对表1样本集提取出前5个IMF分量的能量熵后输入SVM中进行故障诊断。能量熵和本文融合特征量的分类结果如图9所示。
由图9可知,能量熵的分类准确率为90.6%,融合特征量的分类准确率达到了98.6%,诊断准确率有了明显的提升。
4 结论
对滚动轴承的故障诊断问题进行了研究,得到以下结论。
(1)使用PCA将奇异值与时域特征参数两种不同的特征量相融合以提高故障的诊断准确率,结果表明融合特征量比常用的特征量诊断效果要更好。
(2)基于PCA的特征量融合能够将不同角度的特征信息进行融合得到更为敏感的特征,剔除了无用、冗余、复杂的特征信息从而更简洁、全面地表征了滚动轴承各种运行状态。
猜你喜欢
九江职业技术学院学报(2022年1期)2022-12-02
保定学院学报(2022年2期)2022-04-07
当代陕西(2019年19期)2019-11-23
智族GQ(2019年9期)2019-10-28
军事运筹与系统工程(2019年4期)2019-09-11
数学大世界(2019年7期)2019-05-28
英美文学研究论丛(2018年1期)2018-08-16
中国港湾建设(2017年11期)2017-12-19
中华建设(2017年1期)2017-06-07
雷达学报(2017年6期)2017-03-26
