
基于GFCC 和能量算子倒谱的语种识别
2022-03-24 10:00:20邵玉斌李一民
云南大学学报(自然科学版) 2022年2期
刘 晶,邵玉斌,龙 华,李一民
(昆明理工大学 信息工程与自动化学院,云南 昆明 650500)
语种识别(Language Identification,LID)是指计算机自动对一段输入语音进行识别并确认属于哪种语言. 目前,主要用于多语言语音处理系统的前端,对语音进行语种分类,然后送入相应语种的子系统处理[1]. 当前语种识别技术对无噪语种识别的准确率已经较好,但低信噪比下语种的识别率仍需要提升[2].
LID 技术的核心问题是提取有效的特征参数.传统方法提取特征参数包括梅尔频率倒谱系数(Mel-frequency Cepstral Coefficient,MFCC)[3]、滑动差分倒谱(Shifted Delta Cepstra,SDC)、感知线性(Shifted Delta Cepstra,SDC)[4]、感知线性预测系数(Perceptual Linear Predictive,PLP)[5]、伽玛通频率倒谱系数( Gammatone Frequency Cepstrum Coefficient,GFCC)[6]等. 随着深度神经网络的快速发展,Zhu 等[7]提取64 维的对数Mel 尺度滤波器组能量(log Mel-scale Filter Bank Energies,Fbank)特征作为语种特征进行识别,由于特征的各个维度之间相关性较大,分类效果不佳. 蒋兵等[2]利用深度神经网络模型[8-10]强大的特征抽取功能提取深度瓶颈特征,该特征在噪声环境下冗余信息较多,识别率低. 随着图像识别被引入到语种识别领域,Montavon 等[11]提取线性灰度语谱图特征(Linear Gray Scale Spectrogram,LGSS),将语种识别转为图像识别,该特征在噪声环境下会被掩蔽掉很多语种特征,低信噪比下识别效果不佳. 以上特征随着信噪比的降低,识别率急剧下降,甚至出现无法正常识别现象[12]. 因此,基于以上方法提取的特征的抗噪性有待提升,而且复杂的网络模型和环境导致工程应用还有一定的局限性.
本文在伽玛通频率倒谱系数特征基础上,提出了一种新的融合特征提取方法,很大程度上提升了低信噪比下的语种识别准确率. 本文的主要贡献如下:
(1)目前语种识别主要是对全语音段进行特征提取,但是有很多噪音段和静音段都会对识别造成干扰. 为了解决上述问题,在特征提取前端引入有声无声段检测,再提取有声段的GFCC(Sound-Gammatone Cepstral Coefficients,S-GFCC)特征参数,以消除噪声段和静音段的干扰.
(2)在低信噪比下提取的特征包含了很多噪声,识别率降低. 为了筛选出优质特征,利用主成分分析(Principal Components Analysis,PCA)对提取特征降维,得到新的特征参数(Sound-Gammatone Cepstral Coefficients Principal Components Analysis,S-GFCC+PCA),减少了噪声的干扰. 最后融合基于有声段提取的Teager 能量算子倒谱参数(Sound-Teager Energy Operator Cepstral Coefficients, STEOCC)得到融合特征集S-EGFCC. 实验结果表明,在低信噪比下融合特征集优于Fbank 特征.
1 构建模型
1.1 GMM-UBM 模型 本文采用高斯混合通用背景模型(Gaussian Mixture Model-Universal Background Model,GMM-UBM)[13]作为后端识别. 该模型可以很好地区分语言和公共背景,在训练集数据量较少的情况下也可得到高混合度的模型. 图1 显示了基于GMM-UBM 的语种识别模型框架,如果有S种语种需要识别,则采用N种语种样本训练UBM.本文需要识别的语种为5 种,因此语种背景数量N=5, GMM 训练数量S=5,训练出来的UBM 与目标语种通过模型自适应模块得到S种语种模型,测试语种与语种模型进行判决得到判定语种. 模型采用的混合高斯数目为32.


2 特征参数提取及特征融合
有声段的GFCC 特征参数是基于人耳听觉感知模型提取的,提取过程包括有声无声段检测、Gammatone 滤波、分帧加窗、计算短时对数能量、计算DCT 倒谱等. 将提取的有声段S-GFCC 进行融合得到全语段的特征量S-GFCC. 每个有声段的Teager 能量算子倒谱参数(each-Sound-Teager Energy Operator Cepstral Coefficients,S-TEOCC)特征具有非线性能量的特性,提取过程包括有声段检测、分帧加窗、Teager 能量算子、归一化取对数、计算DCT 取平均值等. 每个有声段的融合特征(S-EGFCC)提取过程包括S-GFCC 采用主成分分析后融合STEOCC 构成S-EGFCC,融合特征既表现了人耳听觉特性,又结合了有声段间能量变化的特性,也减少噪声段和静音段对识别率的影响,更适合在噪声环境下进行语种识别. 最后,将提取的S-EGFCC 进行融合,得到全语段的特征量S-EGFCC. 特征提取和融合具体流程如图2 所示.

图2 特征提取和融合提取流程图Fig. 2 Flow chart of feature extraction and fusion extraction
2.1 基于有声无声检测后的GFCC 特征提取 传统的GFCC 是基于全语音进行特征参数提取,而实际中的全语音信号包括很多无声段和混合有噪声的有声段,因此使用全语音段上的特征会引入大量噪声部分,特别是在低信噪比情况下[14],位于有声段处的瞬时信噪比较全语音段上的平均信噪比则高得多. 文献[15]证明有声段包含大部分语音信息,具有训练时间缩短、抗噪性增强的优点. 本文在特征提取前端采用文献[16]的音节分割方法,首先将语音进行有声段检测,然后提取S-GFCC 特征. SGFCC 特征参数提取步骤如下:
步骤 1 有声无声段检测. 文献[16]分割算法在无噪的环境下切割准确率达到91.8%,在低信噪比环境下达到78.4%,本文仅采用该方法进行无音段的判别和切除,不做严格的音节分割,因此相对于采用全语音段进行特征提取,在低信噪比环境下依然可以剔除无声段和混合大量噪声段,间接提高整段语音的信噪比,从而提高语种识别率. 如图3 是10 dB音频的分割结果,图中虚线为有声段起始点,实线为有声段终点,粗点线为起始点和终点重合部分.从图3 中可以获取有声段的起始点T∈{t1,t2,···,tv}和终点B∈{b1,b1,···,bv}, 其中,tv为第v个起始点,bv为第v个终点,从而得到每个有声段的时间长度形成有声语音段:

图3 有声无声段检测Fig. 3 Detection of silent section and sound section


步骤 7 S-GFCC 特征融合. 再将每个S-GFCC进行融合得到S-GFCC 为:

2.2 S-TEOCC 参数提取 Teager 能量是由Kaiser 提出的一种非线性能量算法,具有跟踪语种信号非线性能量变化的特性,可以合理地呈现有声段之间能量变化[17].
第j个有声段Teager 能量算子倒谱(S-TEOCC)提取具体步骤如下:

由(14)式可知,Teager 能量算子可以消除零均值噪声的影响,达到增强语音的目的[16]. 将Teager能量算子应用低信噪比下的语种识别,可以降低噪声的干扰和增强语音信号能量,还可以反映不同语种有声段之间的能量变化,以便更好地区分不同语种.
步骤 3 进行归一化并取对数,得到每帧的Teager能量算子:


2.3 特征融合 为了构造更适合在低信噪比环境下的特征集,本文提出将S-GFCC 和S-TEOCC 进行融合形成新的特征集S-TGFCC. 本文对SGFCC 采用主成分分析,从一个有声段对应F帧选取贡献率大的前几帧,消除贡献率低的噪声影响.主成分分析(Principal Components Analysis,PCA)[19]技术作为非监督学习的PCA 方法,主要是线性代数里面的特征提取和分解,实现对原始数据进行降维.
具体融合步骤如下:
步骤 1 对提取的S-GFCC 特征集进行均值化处理:


3 仿真实验与结果分析
3.1 实验语音语料 语料来源于中国国际广播电台,包括汉语、藏语、维吾尔语、英语、哈萨克斯坦语等5 种语言. 音频采样率为8 000 Hz、时长10 s 的单声道语音文件. 随机选取每种语言300 条作为训练集,前50 条不加噪声,后250 条分别与Nonspeech公开噪声库里面的白噪声和粉红噪声构建形成SNR=[5,10,15,20,25]dB 的带噪语音,每种信噪比语音50 条,从而更好地模拟现实环境. 从剩下的音频中随机选取每种语种171 条作为测试集,分别构建两种不同噪声源的信噪比范围在 -5 ~20 dB 的测试语料库,UBM 模型自适应采用的是非目标语种的1 675 条覆盖各种信噪比下的广播语料.
3.2 实验结果 为了验证本文提出的融合特征方法优于Fbank 特征方法和GFCC 特征方法. 实验分为5 组,其中两组为对比方法,3 组为本文方法.
实验1 文献[7]提取64 维的Fbank 特征作为语种特征进行识别,由于Fbank 特征更适用于深度学习模型,因此采用残差神经网络 (Residual Neural Network,ResNet)作为语种识别模型.
实验2 文献[6]采用13 维静态GFCC 作为语种特征,使用GMM-UBM 作为语种识别模型,UBM 模型进行模型自适应,GMM 进行模型训练.
实验3 在实验2 的基础上,本文提取2.1 节的13 维S-GFCC 特征作为语种特征.
实验4 基于实验3,首先对提取的S-GFCC特征进行主成分分析最终得到13 维S-GFCC+PCA 特征作为语种特征.
实验5 在实验4 的基础上,提取2.3 节的SEGFCC 特征作为语种特征.
采用NIST 语种评测规则中的识别率作为性能评价指标,有:

3.2.1 白噪声环境下的语种识别效果 为了验证提出方法在白噪声环境下的识别效果,进行了5组实验,实验结果如表1 所示.
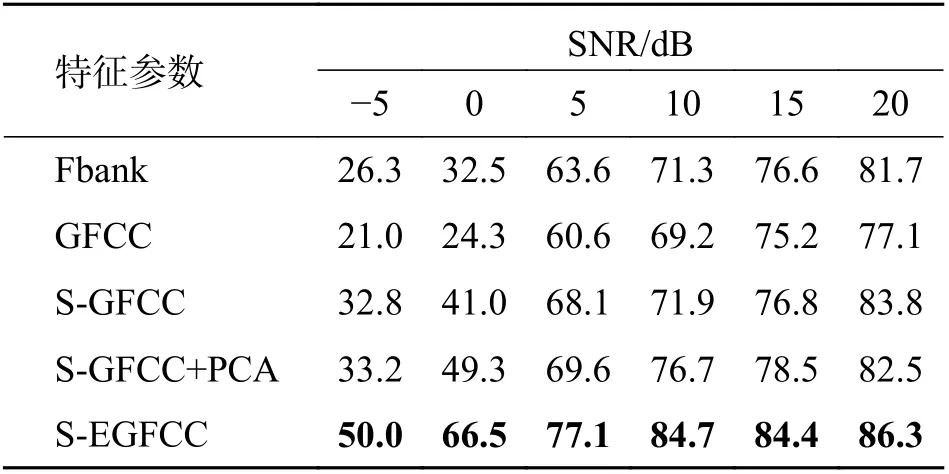
表1 白噪声环境下不同方法识别率对比Tab. 1 Comparison of identification rates of different methods under white noise environment %
对比实验1~3 的识别结果可知,GFCC 特征相对于Fbank 特征识别性能有所欠佳. 但是,本文提出的S-GFCC 在6 种信噪比下,相对于Fbank 特征都有小幅度提升. 由于S-GFCC 特征在特征信息提取前端加入了有声无声段检测,消除了部分噪声段的干扰,间接地提升了信噪比,而GFCC 特征和Fbank 特征都存在大量的噪声段干扰,导致识别率欠佳.
对比实验3、4 的识别结果可得,在6 种先信噪比等级下,采用S-GFCC+PCA 特征集相对于SGFCC 的效果更好. 信噪比为0 dB 时,识别率提高了8.5%,由于S-GFCC+PCA 特征是对S-GFCC 特征进行主成分分析得到的,选取了贡献率大的特征,舍弃贡献率小的特征和部分噪声,从而间接提高了识别率.
从实验4、5 的识别结果可知,相对于S-GFCC+PCA,S-EGFCC 在不同信噪比下的识别率都有很大的提升,在信噪比 -5 dB 和0 dB 下,识别率分别达到了50.0%和66.5%. 由于本文S-EGFCC 特征融入了反应有声段能量变化的s-TEOCC 特征,抗干扰的能力更强,从而提高了识别率.
3.2.2 粉红噪声环境下的定长语种识别效果为了验证本文提出方法在粉红噪声环境下的识别效果依然优于GFCC 特征方法,进行了2 组实验,实验结果见表2.

表2 粉红噪声环境下不同方法识别率对比Tab. 2 Comparison of identification rates of different methods under pink noise environment %
对比表1、2 实验2、5 的识别结果可知,在粉红噪声环境下,两种方法的识别效果都有所下降.由于粉红噪声的频率分布和语音的频率分布类似,因此干扰更大,而白噪声在频率分布上较为固定,有一部分噪声分布在人耳不敏感区域,所以导致粉红噪声下识别效果不佳. 但是本文方法依然很大程度上优于GFCC 特征方法,说明本文方法在粉红噪声环境下有效.3.2.3 白噪声环境下的不同长度语音识别效果 为了验证本文提出方法在不同长度广播语音和白噪声环境下识别效果,本文对输入的10 s 语音进行裁剪,分为3 、6 、10 s,然后再进行语种识别,实验结果见表3.
从表3 的识别结果可知,对语音进行剪切后,由于语种信息相对减少,导致所提方法随着语音的长度减少,语种识别效果稍有下降,但是依然保持60%以上的识别率.

表3 白噪声环境下S-EGFCC 不同时长下的语种识别平均值Tab. 3 Average language identification values of S-EGFCC for different durations in a white noise environment %
3.2.4 白噪声环境下的5 种方法的平均识别率图4 比较直观地描述了5 组实验不同信噪比下平均识别率. 从图4 中可知,S-EGTCC 相对于GFCC提升了20.2%,相对于Fbank 提升了16.1%. 由于有声段长度占全段长度的60%左右,对有声段语音进行特征提取,意味着实际信噪比较全语音段提升了3 dB 左右. 进行PCA 降维,选取有声段所有帧中贡献率最高的2 帧,去掉了大部分贡献率低的噪声和一些贡献率低的语音信息,实际信噪比较全语音段提高了若干dB,识别效率也有所提高. 因此,融合特征集方法比Fbank 特征和GFCC 特征在低信噪比下提升10 dB 左右, 进一步验证了融合特征集S-EGFCC 识别率高于Fbank 特征和GFCC 特征.
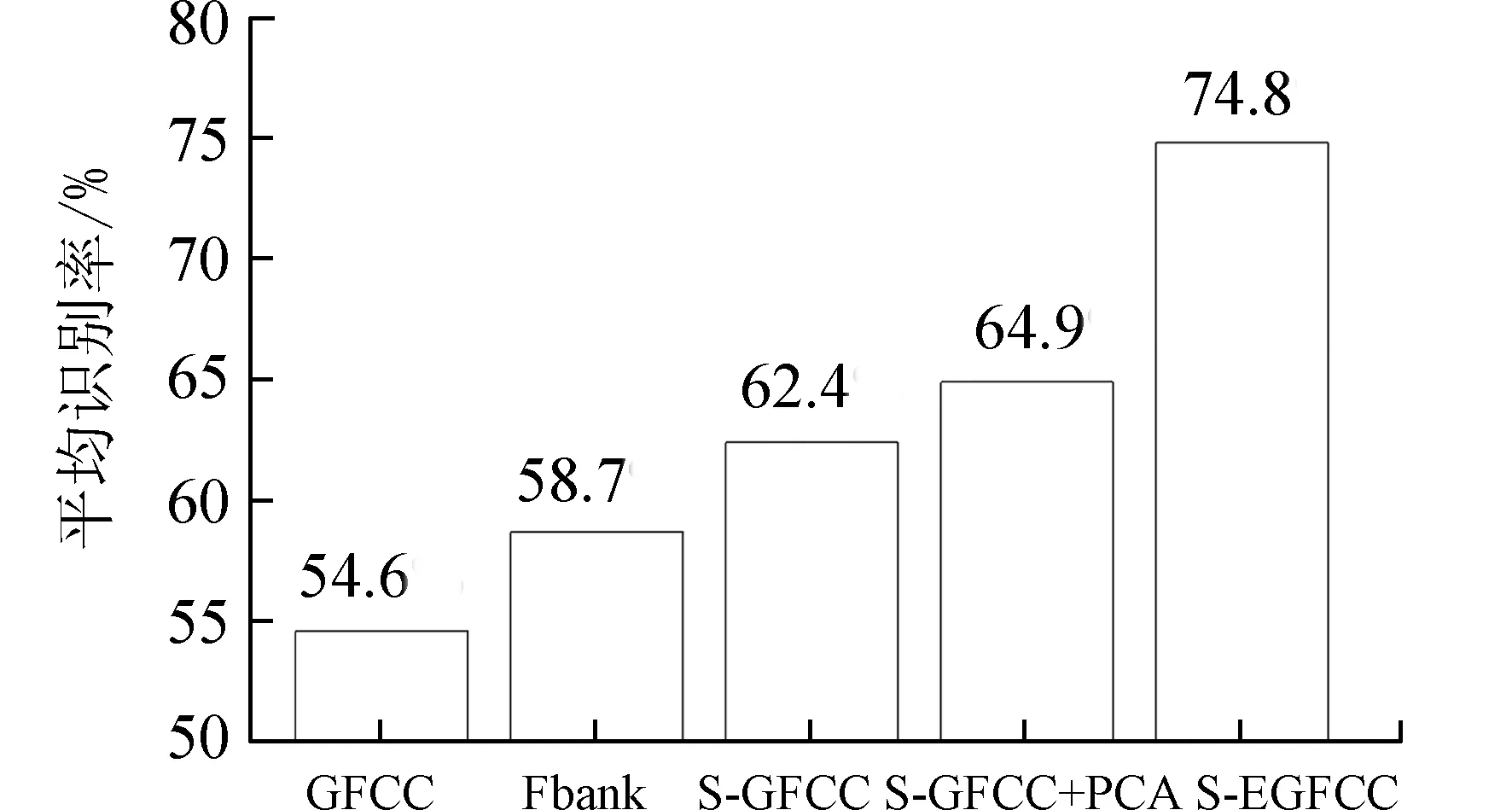
图4 不同方法下的平均识别率Fig. 4 Average identification rate under different methods
4 结论
本文从语种识别核心问题之一的特征提取入手,在伽玛通频率倒谱系数特征基础上,将有声无声段检测应用到语种特征提取前端,然后提取有声段语音GFCC 特征,并验证S-GFCC 特征集在识别率是否提升. 在此基础上,对S-GFCC 特征集进行PCA 降维,减小贡献率小的噪声干扰. 为了获得在低信噪比下更好的识别率,将有声段提取的STEOCC 特征和S-GFCC+PCA 特征进行融合得到特征集S-EGFCC. 相对于使用深度学习的Fbank特征方法,在信噪比为-5~0 dB 情形下,S-EGFCC特征识别率分别提高了23.7%~34%. 然而本文未涉及对非广播语种的研究,相对来说有一定的局限性,后续会考虑将该方法使用深度学习语种模型进行测试,并将工作重点转移到解决多种复杂环境下的语种识别问题.
猜你喜欢
时代邮刊(2021年8期)2021-07-21 07:52:44
计算机工程(2020年3期)2020-03-19 12:24:50
中国听力语言康复科学杂志(2019年3期)2019-06-24 09:51:20
电子制作(2018年19期)2018-11-14 02:37:08
中国交通信息化(2018年3期)2018-06-13 03:27:58
疯狂英语(双语世界)(2017年3期)2018-01-19 01:40:05
自动化学报(2017年11期)2017-04-04 02:52:58
中国交通信息化(2016年2期)2016-06-06 07:28:02
噪声与振动控制(2015年4期)2015-01-01 07:08:21
轴承(2010年2期)2010-07-28 02:26:12
