
一种超轻量级指静脉纹络实时分割网络
2022-03-24 08:52曾军英陈宇聪林惜华秦传波王迎波朱京明田联房翟懿奎甘俊英
光子学报 2022年2期
曾军英,陈宇聪,林惜华,秦传波,王迎波,朱京明,田联房,翟懿奎,甘俊英
(1 五邑大学智能制造学部,广东江门529020)
(2 华南理工大学自动化科学与工程学院,广州510640)
0 引言
在众多生物特征识别技术中,手指静脉识别因其非接触式采集、活体识别、不易伪造、成本较低等优点,吸引了大量科研工作者的关注。手指静脉纹络提取是指静脉识别技术的关键步骤,直接影响后续指静脉特征提取、匹配和识别的准确度。虽然通过经典语义分割网络FCN[1]、SegNet[2]、RefineNet[3]等也能实现较好的指静脉纹络提取,但这些方法需要占用大量的存储空间和计算资源,难以有效地应用在当下的嵌入式平台和移动终端上,因此,设计轻量化深度神经网络架构是解决该问题的关键。
近些年来,轻量级神经网络模型的设计吸引了学术界和工业界的广泛关注,并提出了一系列轻量级模型[4-10]。Xception[4]将空间卷积和通道卷积分开,将两个方向上的相关性分开。SqueezeNet[5]将卷积层分为扩展层和压缩层,在压缩层实现对模型通道数的压缩。MobileNet[6]采用了深度可分离卷积,在提高性能的同时优化了模型的复杂度。MobileNetV2[7]颠覆了正残差的思想,提出了反向残差块。ShuffleNet[8]提出通道混洗的方法,解决了分组卷积中各组信息的交流问题。ShuffleNetV2[9]从模型实时性的角度思考,提出了网络运行速度更快的4 个基本原则。GhostNet[10]首次从特征冗余的角度思考,提出ghost 模块对模型进行压缩。此外,网络轻量化的方法还有神经网络模型的压缩方法,如知识蒸馏[11]、剪枝[12]、量化[13]、低秩分解[14]等,这些方法通过不同的角度对模型进行压缩,取得了丰硕的成果。基于神经网络架构搜索(Neural Architecture Search,NAS)的自动化神经网络架构设计,MobileNetV3[15]提出采用NAS 方法搜索更高效的神经网络,MnasNet[16]和NasNet[17]通过强化学习方法学习神经网络架构搜索策略,实现便携式设备上轻量化神经网络的自动化构建。
构建轻量级网络模型实现参数量减小的同时确保网络性能基本不变或略微下降是现在所面临的重要难题。注意力模块是提升网络性能的有效方法,最早提出注意力机制的SE[18]模块利用全连接层将通道特征赋予权重以加强网络性能,CBAM[19]在通道和空间维度上实现不同维度注意力分离策略,同时关注空间和通道上的特征。后续研究工作如GENet[20]和TA[21],通过采用不同的空间注意力机制或设计高级注意力块来深化这一方法的应用。A2Net[22]和CCNet[23]利用非本地机制来限制捕获不同类型的空间信息。CA[24]模块将频道注意力分解为两个并行的一维特征编码,将空间坐标信息整合到注意力中。但是大部分注意力模块在提升网络的性能同时引进大量参数,不利于网络轻量化,因此探索一种可以提升网络性能并使其引进参数可忽略不计的注意力模块是十分有意义的。
指静脉分割在嵌入式平台实现问题近似于一个多目标优化问题,要同时考虑到分割性能、网络参数大小与运行时间。为解决上述问题,本文提出了一种超轻量级指静脉纹络分割网络来实现指静脉纹络的提取。第一步,使用沙漏状的深度可分离卷积对网络进行初步轻量化,并引入轻量级高效通道注意力(Effificient Channel Attention,ECA)模块提高网络性能,并且该注意力模块所引进参数可以忽略不计。第二步,在网络中采用“低廉的操作”(Cheap operation)[10],将部分特征图通过简单映射得到,使网络进一步压缩。第三步,采用分组卷积替代沙漏状的深度可分离卷积中的点卷积,并通过特征信息交互解决了分组卷积中各组信息之间无法流通的问题。最后,将网络部署到嵌入式平台上,并与其他模型进行了对比。
1 方法
1.1 网络结构
SGUnet 网络是针对嵌入式平台实现实时指静脉纹络提取,即指静脉分割问题,需要综合考虑分割性能、网络参数大小和运行时间。因此在网络中采用多路分支减小模型的参数量或添加各种提高精度的模块,均会导致网络在嵌入式平台的运算速度大大降低。考虑到这些问题,本文将RONNEBERGER 等[25]提出的Unet 编码-解码的网络结构作为基础,提出一种超轻量级指静脉分割网络-SGUnet,如图1所示。具体方法为:1)利用沙漏状的深度可分离卷积构建一个新型的轻量分割网络SGUnetV1,在网络中保留了Unet编码-解码结构特点的同时,使模型初步轻量化。并且加入ECA 模块实现无降维的局部跨通道交互,提升网络的分割性能;2)考虑到部分通道卷积“懈怠”的现象,即所提取的特征图存在冗余,针对这一问题利用Cheap operation 生成部分特征图,进一步将模型进行压缩得到SGUnetV2,Cheap operation 具体结构如1(c);3)SGUnetV3 作为最终的模型,采用特征信息交互的方式,打破了卷积层的通道相关性和空间相关性是可以退耦合的设想,将各组特征均匀地随机排列重组,解决了分组卷积组间信息的交流问题。
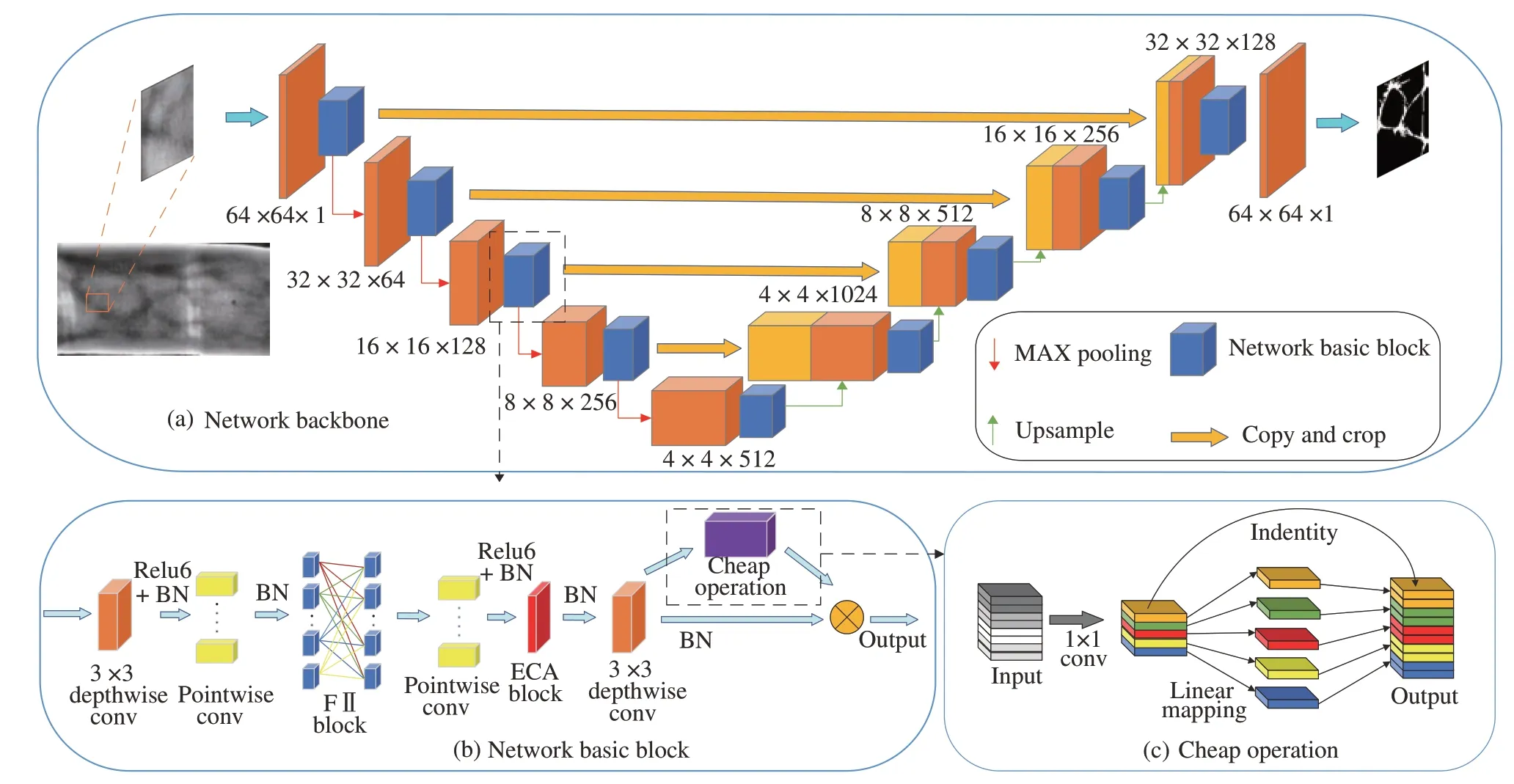
图1 SGUnetV3 算法整体结构Fig.1 The overall structure of the SGUnetV3
1.2 模型构建方法
1.2.1 沙漏状的深度可分离卷积和ECA 轻量级注意力模块
第一步使用沙漏状的深度可分离卷积对网络进行初步轻量化,并加入注意力ECA 模块提高模型性能。网络的基础模块如图2(b)所示,由此基础块构建的模型称为SGUnetV1。
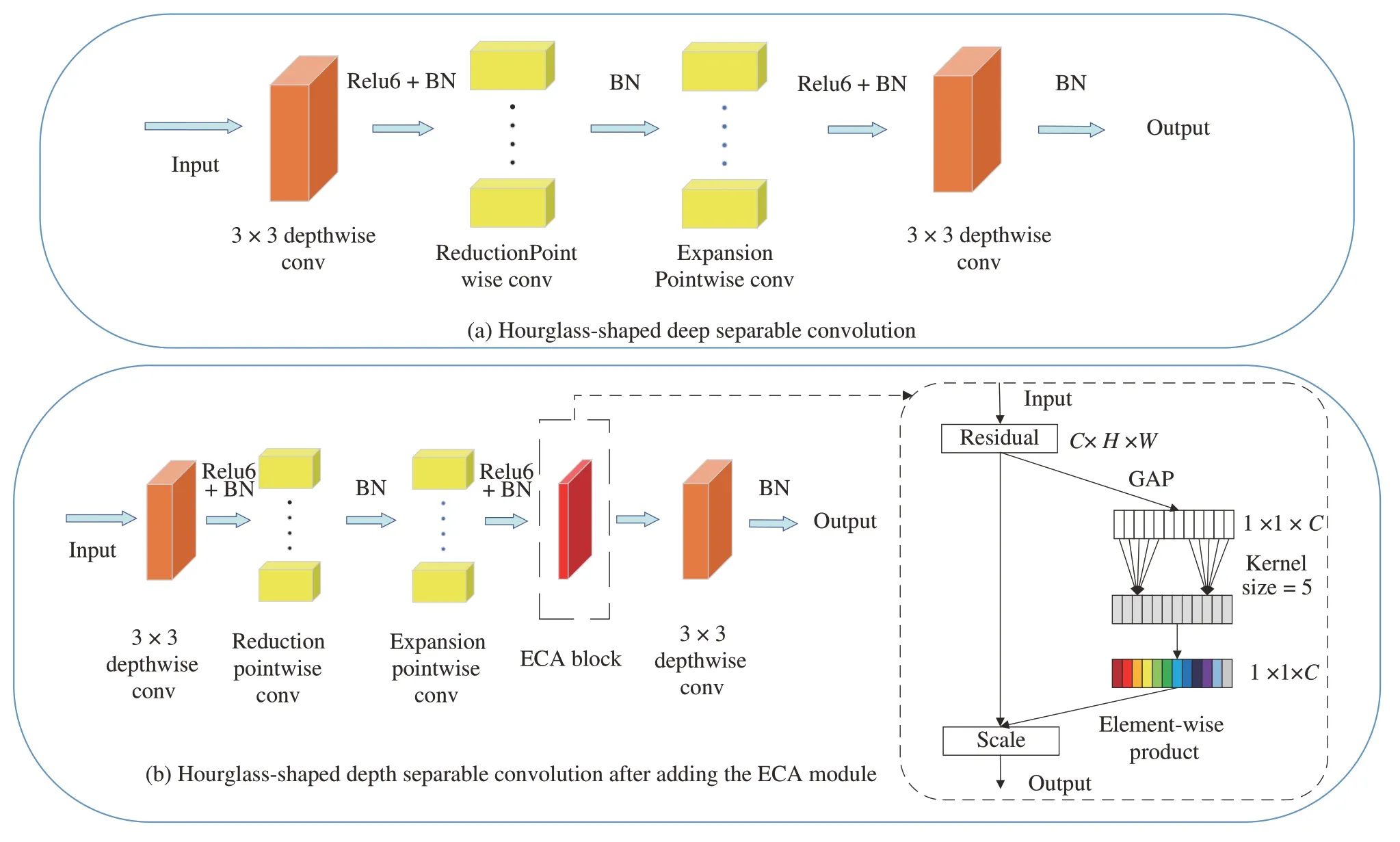
图2 SGUnetV1 基础块结构图Fig.2 SGUnetV1 basic block structure diagram
沙漏状的深度可分离卷积:由ZHOU Daquan[26]等提出的sandglass block 可以解决Inverted residual block[7]存在的特征信息不足的问题。本文采用sandglass block 作为模型基础块,替代普通卷积提取特征,如图2(a)所示。假设输入图片为,其中H,W,C分别为输入图片的长,宽和通道数。首先,利用3×3 逐层卷积(depthwise conv)对输入特征图进行深度方向上的特征提取,此时并没有对输入Xi进行维度上的压缩,所提取的空间特征具有更强的表达性。然后,将经过第一层逐层卷积后的特征图作为沙漏状的点卷积层(1×1 pointwise conv)的输入,沙漏状的点卷积层由两个点卷积构成,其设计遵循正残差的结构,第一个点卷积先将特征维度按比例r压缩,此时的输出为,第二个点卷积将维度恢复至输入的特征维度Ci,在提取到充足的通道特征信息的前提下,减小点卷积所带来的巨大开销。经过前面逐层卷积和点卷积之后,输入图片在深度和通道两个方向提取到丰富的特征,但在点卷积层中为了削减点卷积的开销,遵循了正残差的先压缩再扩展的思想,这会导致部分空间信息在缩小的点卷积处丢失,为了弥补这些特征的丢失,在最后再加入一层3×3 逐层卷积层来补充空间的特征信息,弥补所丢失的部分空间信息。为了验证所使用的方法,将初步改进的模型SGUnet 与Unet、Inverted residual block 融入骨干Unet 网络进行了对比实验,实现结果如表1所示,结果表明沙漏状的深度可分离卷积相比于普通卷积,逆残差块更轻量,效果更好。
由于考虑到在利用沙漏状的深度可分离卷积初步轻量化模型时,模型的分割性能可能会随着模型参数量的减少而下降,以及部分注意力模块存在降维操作破坏通道间与权重的直接对应关系,因此在沙漏状的深度可分离卷积的第二次点卷积(Expansion pointwise conv)之后和最后的3×3 逐层卷积之间中加入了ECA 注意力模块[28],结构如图2(b)。
ECA 轻量级注意力模块:SE 注意力模块[18](Squeeze-and-Excitation)可以提升网络性能这一结论已被证实,但大部分注意力模块的加入在提升性能的同时也为网络增加大量运算负担。首先回顾SE 注意力模块,令一个卷积块的输出为φs∈RH×W×C,其中W,H和C为宽度、高度和通道尺寸,SE 块中的信道权重计算为

综合考虑了性能提升和运算量增加两方面的取舍,以及注意力模块降维会破坏通道间与权重的直接对应关系,在SGUNet的网络结构中加入了ECA 注意力模块[27]。ECA 模块先将输入特征图通过全局平均池化(GAP)可用式(2)表示,将输入特征转化为为


1.2.2 从特征图冗余的方向进行模型压缩
在SGUnetV1 的基础上,将Cheap operation 置于沙漏状的深度可分离之后,从特征图冗余的角度进一步压缩了模型参数量。此时的网络基础块如图3所示,第二步改进后得到的网络称为SGUnetV2。

图3 加入Cheap operation 后的基础模块结构Fig.3 The basic module structure after joining the Cheap operation
Cheap operation:绝大多数卷积神经网络没有考虑到特征图可能存在一定的冗余,这些冗余的特征图存在极大的相似性,它们可以通过一些简单的变化从相似的特征图中得到。HAN K 等[10]提出的GhostNet 正是从特征图冗余的角度思考,对模型进行压缩。在采用深度可分离卷积的网络架构中,大量的1×1 卷积还会占用庞大的MAC(Memory Access Cost)和参数量。Ghostnet 中所提出的Ghost 模块,从特征图冗余的角度,将两张十分相似特征图的其中一张看作另一张特征图的“影子”,这类特征图可以通过Cheap operation 所得,从而减少大量1×1 卷积。
Cheap operation 是针对1×1 卷积的压缩方式,此处针对1×1 卷积运算削减量进行分析。对于输入特征图Xi可将其表示为Hi×Wi×Ci,所需的输出特征图Xo可表示为Ho×Wo×Co,由于1×1 卷积仅改变特征图的维度,因此不采用Cheap operation 需要Co个1×1×Ci卷积核,此时得到目标输出特征图所需要的计算量为Co×Hi×Wi×Ci。如果采用Cheap operation 对1×1 卷积按比例K 进行压缩,1×1 的计算量则有,需要线性变换的计算量为。此时Cheap operation 的运算量为。实际压缩的参数之比为

由于在浅层的网络中输入特征图的大小Hi,Wi≫K,在深层的网络中输入通道数往往成百上千,即Ci≫K,此时可将式(5)近似于

将Cheap operation 用作针对点卷积参数量减小的方法,每层网络都采用了该方法得到部分特征图,进一步减小网络大小。
1.2.3 分组卷积和特征信息交互
第三步,在利用分组卷积减轻1×1 卷积负担的同时,采用特征信息交互的方式来弥补分组卷积缺乏组间信息交互的缺点,具体操作如图4(b)所示,图4(a)所展示的为添加Channel shuffle[8]后的网络基础块,将由图4(a)构建的网络称其为SGUnetV3。

图4 SGUnetV3 网络基础块结构Fig.4 The basic block structure of SGUnetV3 network
特征信息交互:即使经过第二步的改进,网络运算量和参数量依然大量堆积在1×1 卷积处,ZHANG X等[8]采用分组卷积来减轻1×1 卷积计算量的同时提出Channel shuffle 解决了分组卷积之间每组特征信息无法交互的问题。在SGUnetV2 的基础上,本文也采用了相同的方法,将分组卷积替代沙漏状的深度可分离卷积中的1×1 卷积,非常可观地减小了1×1 卷积的花费,并且采用特征信息交互的方法解决分组卷积中每组特征间缺乏信息交互的问题,在进一步压缩模型的同时,保证模型的性能。
Channel shuffle 设计思路具体如下,假设使用S 组分组卷积来替换昂贵的1×1 卷积,为了解决组间信息传递的问题,将每组的分组卷积提取到的通道特征随机地分为S'组(S'=S),记为,然后通过特征信息交互的方法,将随机选取每组划分后的其中一组特征ηj,其他各组的操作也相同,最后将提取到的各组特征相叠加后进行特征转置,使从S 组中得到小组信息充分融合。具体实施方法如图4(b)所示。图4(b)左侧为传统的分组卷积,每种颜色代表一组分组卷积,右侧为采用Channel shuffle 后的分组卷积,解决了各组之间特征信息无法交互的问题。
2 实验
2.1 数据预处理
本文算法所采用的公开指静脉数据库为山东大学SDU-FV 和韩国全北国立大学MMCBNU_6000。将SGUnet 与不同的分割网络进行对比,并且在嵌入式平台上进行对比实验。SDU-FV 数据集共有106 个受试者,分别收集了每个人左右手的食指、中指和无名指三个手指的指静脉图像,每个手指采集6 张图片。因此,该库中共有636 类(106 人×6 个手指)3 816(106 人×6 个手指×6 样本)张图像。MMCBNU_6000 数据集共有100 个受试者,分别采集了每个人左右手的食指、中指、无名指三个手指的指静脉图像,每个手指采集10 张图片,且该数据集给出了提取好的ROI 区域。因此,该库中共有600 类(100 人× 3×2 个手指)6 000(600 人×6 个手指×10 样本指)张图像。
在训练的过程中随机选取数据集的五分之四作为训练集,剩余五分之一作为测试集。在训练和测试中对原图采用分块策略,每张图像分为2 000 个块(patch),在宽和高均为五个步幅的情况下,对每张图像提取多个连续的重叠块,通过对覆盖像素的所有预测块的概率进行平均估计,从而获得该像素是静脉血管的概率。为了保证不超过硬件平台的内存限制及实时性,在指标与时间中权衡选取步幅为5 的patch 最为合适,在网络输出patch 结果后按照分patch 中的顺序,采用交叠滑窗策略保留中心区域结果,舍弃预测不准的图像边缘,重新拼接成一张完整的原图。
2.2 实验环境配置与嵌入式平台
为了展示本文方法的高效性和普适性,本文分别在PC 端和嵌入式平台进行对比实验。PC 端对比实验的运行环境为Ubuntu18.04 系统、英特尔i9-10900k@3.7GHz CPU(10 核20 线程)、内存32GB、显卡Nvidia GeForce RTX 3090 TURBO(24GB/技嘉)、CUDA11.2、Pytorch1.8.1、Python3.6.5。使用Adam 优化器进行梯度下降,学习率为0.001,batch size 大小为512。
此外,在NVIDIA 全系列的嵌入式平台JETSON NANO、JETSON TX2、JETSON XAVIAR NX、JETSON AGX XAVIAR 上验证本文方法的普适性(嵌入式平台算力顺序:NANO<TX2<NX<AGX)。为了让在不同嵌入式平台上的数据更具有对比性,将所有嵌入式平台环境配置设为一致Jetpack4.4、pytorch1.8.0、python3.6.9。从实验数据中可以证明该方法相较于以往的方法更高效、更轻量。
2.3 网络性能评价指标
在对比实验中,本文采用Dice,AUC,Accuracy,Specificity,Precision 5 个分割指标作为评估网络性能优劣的依据,其中以Dice、AUC 和Accuracy 作为最主要的评估指标,在本小节中将简单介绍所采用的评估值标。
Dice 是指使用频率最高的分割指标,分割结果和标注(ground truth)两个相交面积占总面积的比值,完美分割为1。AUC(Area Under roc Curve)的值为处于ROC(Receiver Operating Characteristic)曲线下方面积的大小。指标越接近1 代表分割出来的性能越好。Accuracy 是指对于给定的测试数据集,分类器正确分类的样本数与总样本数之比。Specificity 是指在实际为正确的样本中正确判断的概率。Precision 是指在分类为正确的样本中正确判断的概率。
2.4 网络实验对比
在网络改进的第一步中,采用沙漏状的深度可分离卷积对基础网络进行初步的轻量化,得到SGUnet,并且为了验证该网络的高效性,将SGUnet 与经典的Unet,用逆残差改进后的MobileV2+Unet 进行了对比,结果表明SGUNet的模型表现优异。与Unet 相比,SGUNet的参数量约为UNet的3.8%,Mults-Adds 约为UNet的2%,Dice,AUC 和Precision 三个评价指标显著提升,提升量分别为5.84%,5.48%,3.48%,Accuracy也提升了0.73%。与MobileV2+Unet 相比,SGUNet的模型参数量和Mults-Adds 分别只占其1/10 和1/4,在分割性能上SGUnet 大大超越MobileV2+Unet,具体实验数据如表1所示。

表1 改进网络SGUnet 与基础Unet、MobileV2+Unet 性能对比表Table 1 Improved network SGUnet and basic Unet,MobileV2+Unet performance comparison table
在SGUNet的基础上加入ECA 模块提升了模型性能,将所采用的ECA 模块与具有代表性的SE 模块,最新的CA 模块[24]分别用于SGUnet 模型上进行对比实验,以此来验证所加入ECA 模块更适合在SGUnet网络中使用。此外,本文还探究了各个模块中设置不同的参数对实验结果的影响。实验结果如表2所示。(CA 模块后的数字为模块压缩尺度设置,ECA 模块后的数字为1D kernel size 的尺寸)。

表2 在SGUNet的基础上加入ECA 模块与经典SE 模块、CA 注意力模块的性能对比表Table 2 Performance comparison table of ECA module,classic SE module and CA attention module added on the basis of SGUnet
由于考虑到ECA 模块放置不同也会导致网络性能有所影响,为此本文设计了a,b,c 三种方案,见图5,并进行了大量的对比实验,最终发现采用a 设计方案的网络性能更好,具体设计方案性能对比见表3。

表3 a,b,c 三种不同方案的网络性能比较Table 3 Comparison of network performance of three different schemes a,b,and c

图5 ECA 模块放置的三种方案Fig.5 Three options for ECA module placement
在网络的第二步改进中,使用Cheap operation 替代部分“懈怠”卷积操作,进一步减轻网络的大小以及运算量,此时将所得到的SGUnetV2 与Unet,用深度可分离卷积改进的MobileV1+Unet,使用逆残差改进的MobileV2+Unet 在模型大小上进行对比见表4,在SGUnetV1 的基础上模型参数减小100k,Mult-Adds 减小13M,在模型压缩上我们保持十分明显的优势。

表4 SGUnetV2 与其他网络的参数比较表Table 4 Comparison of parameters between SGUnetV2 and other networks
2.5 模型可视化
为了更直观地展示网络模型的分割效果,本节展示了在两个指静脉数据集上的分割效果图,其中每个数据库各选取五张图进行结果展示,如图6,并且在图7 中展示了在将每张原图分成多张patch 后,单张patch在网络中的可视化效果,进一步验证网络模型对指静脉的细节分割效果较好。

图6 指静脉分割效果图Fig.6 The effect of finger vein segmentation
图7 为单张patch 在SGUnetV3 网络中的可视化效果。其中Imgae 为原图分成的patch,Groud truth 为单张patch 所对应的标签块,Last encoder layer 展示了最后一层编码器中所提取到patch 中的指静脉的边界、轮廓等深层特征,Last decoder layer 为网络最后一层解码器中所提取到指静脉纹络。对比网络最后一层解码器与其所对应的标签块,可以明显地看出所提取到的指静脉与标签几乎无异。
2.6 与大型网络在PC 端的对比实验
在PC 端将SGUnet 系列网络与同基础的网络U-net、变更的网络R2U-net 以及DU-net 在SDU-FV 和MMCBNU_6000 两个数据集上进行了对比实验。本文采用常用的图像分割评判指标Dice 系数、准确性(Accuracy)、特异性(Specificity)、精确率(precision)、AUC(Area Under roc Curve,AUC 为ROC curve 下方与x轴围成的面积大小)来判断网络性能的优劣。实验结果如表5 和表6。
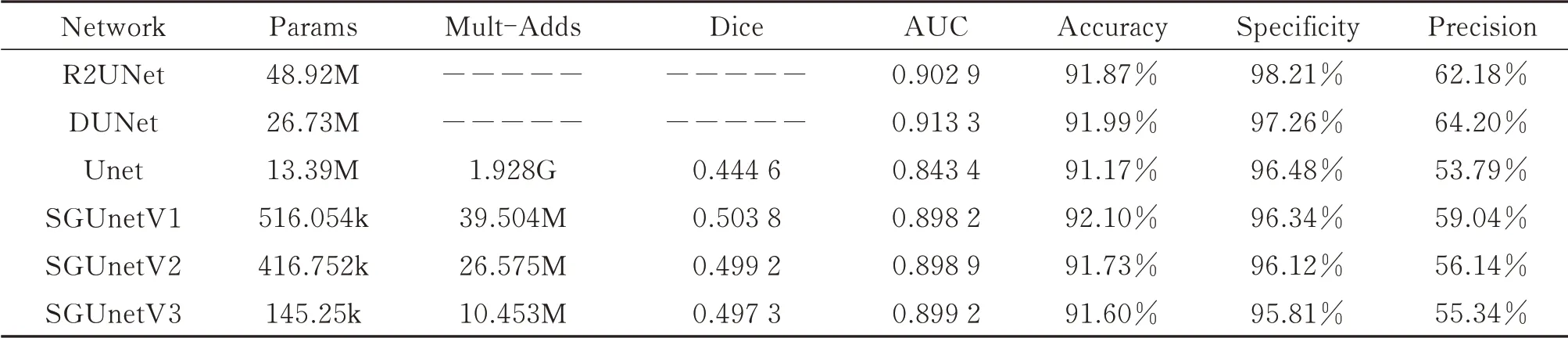
表5 SGUnet 系列网络与大型网络在SDU-FV 数据集上的实验结果Table 5 Experimental results of SGUnet series network and large-scale network on SDU-FV data set

表6 SGUnet 系列网络与大型网络在MMCBNU_6000 数据集上的实验结果Table 6 Experimental results of SGUnet series network and large-scale network on MMCBNU_6000 data set
从实验数据中可以观察得到所提出的网络SGUnetV3 与大型网络R2UNet,DUnet,以及Unet 在模型大小上的比值分别为0.2%,0.5%,1%。SGUnetV3 在参数量,运算时间和计算量上极具优势,并且SGUnetV3在性能方面相比Unet 有显著提升。
在SDU-FV 数据集上,SGUnetV1,V2,V3 分割性能得到全面提升,分割系数Dice 和AUC 提升显著,证明本文改进的方法是卓有成效的。SGUnetV3 网络与大型经典网络R2UNet,DUnet 相比,各项指标接近,由于模型在压缩过程中存在性能下降的情况,这是不可避免的,考虑到在网络大小和模型参数上的这一巨大差距以及在嵌入式平台上实现,可以认为SGUnetV3 网络是高效的。
在MMCBNU_6000 数据集上,SGUnet 系列网络在性能方面超过R2UNet,DUnet。SGUnetV1 的Dice系数达到了最高的0.538 4,每一步改进后网络的AUC 指标都远超大型网络。SGUnetV3 中AUC,Accuracy两个指标都有很大的提升,超过了大型的R2Unet,DUnet,Precision 指标也仅稍稍低于DUnet,与R2Unet,DUnet 在Specificity 指标上相比整体相差较小,由于SGUnetV3 模型大小与大型网络相差巨大,并且在部分指标上超越了大型网络,与基础的Unet 相比,SGUnetV3 网络大幅提升分割的性能,还将模型大小压缩至145k,这一结果也证明了网络的高效性。
2.7 与轻量化网络的对比实验
为了证明本文方法的实时性,本文在计算能力较弱的NVIDIA 系列的嵌入式平台上部署SGUnet 系列网络,并进行了测试实验。此外,本文还将一些经典的轻量化网络用在传统的Unet 上与本文方法从模型大小、分割性能和运行时间等多个方面进行综合比较。实验结果如表7、表8所示。

表7 SGUnet 系列网络与其它轻量级网络在SDU-FV 数据集上的实验数据Table 7 Experimental data of SGUnet series network and other lightweight networks on SDU-FV dataset

表8 SGUnet 系列网络与其它轻量级网络在MMCBNU_6000 数据集上的实验数据Table 8 Experimental data of SGUnet series network and other lightweight networks on MMCBNU_6000 dataset
2.7.1 模型大小
经过初步改进的SGUnetV1 已经超越了经典的轻量级模型Squeeze_Unet,Mobile_Unet,Ghost_Unet,虽然在参数量上Shuffle_Unet 与SGUnetV1 相当,但是SGUnetV1 在Flops、Mult-Add 两项重要指标上分别比Shuffle_Unet 减小了25.3MFlops、18.46M。由此可见SGUnetV1 模型大小在第一步就超越了众多轻量级模型。然后,经过第二步利用Cheap operation 代替SGUnetV1 中部分懈怠的卷积核,得到了进一步的网络SGUnetV2,使模型参数降低至416.752k,Flops 为29.26M,Mult-Add 为26.575M。最后,通过利用分组卷积和特征信息交互,使网络再次压缩得到最终的SGUnetV3,其参数量只有145.25k,Flops仅为13.13M,Mult-Add只有10.453M。
2.7.2 分割性能
本文在两个公开的手指静脉数据集上验证了SGUnet 系列网络高效性。SGUnetV1 的性能超过了各种轻量级模型以及Unet,在SDU-FV 数据集中,Accuracy 指标达到了92.10%,AUC 达到了0.898 2,Dice 系数为0.503 8;SGUnetV2 进一步压缩模型大小的同时,保证了网络的分割性能,其各项指标与SGUnetV1 十分相近,AUC 指标更是超越了SGUnetV1;最终的模型SGUnetV3 只有145.25k 参数,其AUC 指标得到了最高的0.899 2,在其它指标上虽然略差于V1,V2,但也超过以往的轻量级网络和Unet,这一突破是巨大的。在MMCBNU_6000 数据集上,SGUnetV1 全面超越了所有的轻量级网络,相比于基础Unet,SGUnetV1 的AUC,Dice,Accuracy 这3 个关键指标分别增涨了0.051,0.064,1.69%;SGUnetV2,V3 也仅仅在Specificity,Precision 指标上相比于Ghost_Unet 稍弱,其它性能指标上也远超过了其他网络。
2.7.3 实际分割效果
图8、9 分别为SGUnet,Unet 和各种轻量级网络的分割结果图,在两个数据集中分别选取同一张图片对网络分割性能进行比较,图8 中Unet 分割效果并不理想,Squeeze_Unet,Mobile_Unet,Ghost_Unet 和Shuffle_UNet的分割效果有所改进,但是部分极细的血管并没有很好地分割出来,以及分割得到的血管整体效果不够平滑。网络SGUnetV1 不仅在性能指标上获得了出色的表现,实际分割得到的血管也更平滑,更符合人体血管的特点,从SGUnetV3 的分割图中所标注的红框可以看出,部分极细的毛细血管也可以完美地分割。所提出的SGUnetV1、V2 和V3 在MMCBNU_6000 数据集上也同样展现了强大的分割效果,可以清楚地从图9 中观察到,其它轻量级网络在细节分割方面并没有优势,虽然它们都得到了比Unet 更好的分割结果,但是在血管平滑程度和毛细血管的准确分割这两个方面还较为不足,SGUnet 正好满足了这两个优势,图9 红框所标注多个位置处的毛细血管被精准地分割,再次证明了SGUnet 网络的高效性。

图8 SGUnet 与各个轻量化网络在SDU-FV 数据集上的实际分割效果图Fig.8 The actual segmentation effect diagram of SGUnet and each lightweight network on the SDU-FV dataset

图9 SGUnet 与各个轻量化网络在MMCBNU_6000 数据集上的实际分割效果图Fig.9 The actual segmentation effect diagram of SGUnet and each lightweight network on the MMCBNU_6000 dataset
2.7.4 实时性实验
表9、10 中分别记录了SGUnet 系列网络与各种轻量化网络在NVIDIA 全系列嵌入式平台上分割单张指静脉图片的运行时间,本文分别在SDU-FV 和MMCBNU_6000 两个数据集中选取20 张图片进行测试。在SDU-FV 数据集中,SGUnetV1 仅在NVIDIA NANO 上的运行时间略慢于Ghost_Unet,在其他嵌入式平台上运行速度完全超越了各种轻量化网络模型。虽然SGUnetV2,SGUnetV3 与V1 相比速度有所下降,这是由于网络轻量化引入了相比卷积更为复杂的操作,但V2,V3 更加轻量,V3 模型大小不到V1 的1/3,我们认为这是可以接受的。在MMCBNU_6000 数据集中,SGUnetV1 在所有的嵌入式平台上的运行时间超越了所有的轻量化模型,证明SGUnet 系列网络在MMCBNU_6000 数据集上具有更好的效果。

表9 SGUnet 系列网络与其他轻量级网络在NVIDIA 嵌入式平台上处理单张SDU-FV 数据集图片的运行时间Table 9 The running time of SGUnet series and other lightweight networks to process a single SDU-FV data set image on the NVIDIA embedded platform

表10 SGUnet 系列网络与其他轻量级网络在NVIDIA 嵌入式平台上处理单张MMCBNU_6000 数据集图片的运行时间Table 10 The running time of SGUnet series and other lightweight networks to process a single MMCBNU_6000 data set image on the NVIDIA embedded platform
由图10 可以得到SGUnet 系列模型从模型大小和性能指标两方面都胜于以往的经典轻量化方法。在图10(a)、(b)中可得,SGUnetV3 模型远小于以往的轻量化模型,证明本文的轻量化方法效果更好;从图10(c)~(h)可知,SGUnetV1 模型在AUC、Accuracy 和Dice 三个重要的分割指标上超过了以往的轻量化方法,证明本文方法在压缩模型同时兼顾分割性能提升。SGUnet 系列网络不仅是在轻量化方面取得了好的成果,在性能提升方面也得到明显的增长,这一结果进一步证实了本文方法的优越性。


图10 与经典轻量级网络的重要指标对比Fig.10 Comparison of important indicators with classic lightweight networks
从上述实验结果可以说明SGUnet 系列网络可以轻松地部署在计算能力较弱的平台上,本文方法不仅压缩了模型大小,减轻了运行模型所需的苛刻的硬件条件,并且取得了优秀的网络性能,分割效果和运算速度。
3 结论
针对在嵌入式平台上部署轻量级指静脉分割网络时,存在参数减小导致分割性能急剧下降、算力受限和实时性等问题,本文提出了一种超轻量级指静脉纹络实时分割网络。通过沙漏状的深度可分离卷积和轻量的ECA 模块构建网络基础块,减小模型参数和提高分割性能;通过Cheap operation 生成重影的特征图,减少冗余特征图;利用特征信息交互打破组间信息传递障碍,解决了分组卷积带来的难题。SGUnet 系列网络在两个指静脉数据集上取得了出色的效果,在模型大小上,SGUnetV3 网络参数量仅为145k,Flop 仅为13M,Mult-Add 仅为10M;在分割性能上,SGUnet 系列网络的分割性能超过了以往的轻量化模型和经典大型分割网络。此外,在NVIDIA 全系列嵌入式平台上验证了SGUnet 网络的高效性和实时性,测试速度高达0.27 秒/张。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
汽车实用技术(2022年15期)2022-08-19
汽车实用技术(2022年11期)2022-06-20
汽车实用技术(2022年9期)2022-05-20
计算技术与自动化(2022年1期)2022-04-15
参花(下)(2022年1期)2022-01-15
上海师范大学学报·自然科学版(2019年5期)2019-12-13
智富时代(2019年2期)2019-04-18
智富时代(2019年2期)2019-04-18
数学大王·低年级(2018年3期)2018-03-27
