
基于改进FP-Growth和AHP算法的电压暂降影响度分析
2022-03-23 04:56:20林焱林芳黄道姗方晓玲郭凯
电气传动 2022年6期
林焱,林芳,黄道姗,方晓玲,郭凯
(1.国网福建省电力有限公司电力科学研究院,福建 福州 350000;2.四川大学电气工程学院,四川 成都 610065)
随着电网中敏感设备的不断增加,电压暂降问题越来越突出[1]。对电压暂降对设备和用户造成的影响进行评估,可以为电力公司和用户采取合理措施、减少敏感用户的经济损失提供理论依据[2-3]。
现存的电压暂降严重程度评估方法主要可分为两大类,分别是随机预估法[4-7]和实测统计法[8-11]。其中,随机预估法包括解析法[4]、故障点法[5]和蒙特卡洛法[6-7]。解析法通过构建阻抗矩阵计算暂降电压幅值,但是所建模型与实际情形差异较大。故障点法通过假定系统中发生的故障位置,分析电压暂降的严重性,适用于各类故障运算,但需要进行大量仿真运算,在网络结构较大时不适用。蒙特卡洛法通过模拟预估计算网络中各节点的暂降指标,其无法同时满足较高的精度和效率。实测统计法基于实际的测量数据,可以准确地反映电压暂降严重程度,可分为综合评估法[8-9]和数据挖掘分析法[10-11]。综合评估法将多个指标进行权重组合来评估电压暂降影响,但是,忽略了指标之间的同质性且指标框架难以考虑全面。数据挖掘分析法通过数据挖掘方法挖掘不同电压暂降特征属性与电压暂降严重程度之间的关联规则,对电压暂降严重程度进行评估。文献[10]采用数据挖掘方法进行电压暂降数据挖掘,并通过灰靶理论对电压暂降严重度进行匹配评估。文献[11]在文献[10]的基础上提出了基于互信息与改进灰靶理论的电压暂降严重度数据挖掘分析方法。但是文献[10]和文献[11]都采用了基于传统Apriori 数据挖掘方法,Apriori 算法在对数据库进行扫描之前会加载较多的候选集,导致其计算效率较低,而且采用电压暂降严重度指标来评估暂降的严重程度,只考虑了系统侧的电压扰动,没有考虑敏感用户负荷特性。
针对上述情况,本文提出一种基于改进FPGrowth 和层次分析法(analytic hierarchy process,AHP)算法的数据挖掘分析方法来评估电压暂降影响度。对于评估区域电网的每次电压暂降事件,从电能质量监测记录中提取各节点的电压暂降特征属性,然后计算各节点对应的电压暂降影响度。运用数据挖掘方法挖掘电压暂降特征属性与电压暂降影响度之间的关联规则。对于任何实际的电压暂降场景,可以构造一组与该故障场景相对应的特征属性值,将该场景的特征属性与挖掘出的关联规则进行匹配,从而得到该场景下的电压暂降影响度。
本文所提方法选取电压暂降特征属性并对其进行分类,并且结合考虑电压暂降严重性和敏感用户负荷特性的影响度指标构建数据挖掘分析框架;采用改进的FP-Growth 算法对电压暂降事件进行数据挖掘,该方法避免了传统FPGrowth 算法产生无效规则的问题,有效提升了数据挖掘的效率;通过层次分析法构建关联规则匹配模型,对电压暂降影响度进行评估,提高了评估结果的准确性。最后,通过实例分析验证了所提方法的实用性。
1 数据挖掘准备
1.1 电压暂降特征属性
电能质量监测系统收集了大量反映电压暂降事件的数据,随着时间的积累最终形成了一个庞大的、信息丰富的数据库。在这些数据中,需要遵守一定的原则来筛选出与电压暂降严重程度相关的因素,以提高挖掘效率并且避免挖掘出“无意义”的关联规则。本文选取如表1 所示的6个维度因素参与和节点电压暂降影响度的关联规则挖掘。当然,用户也可以根据自身需求选取其他电压暂降特征属性。

表1 电压暂降特征属性Tab.1 Characteristic attribute of voltage sag
在表1 中,“观测位置”为变电站在电网中的地理位置;“电压等级”为关联母线的额定电压;“天气”为暂降发生时变电站位置处的天气情况;“故障原因”为引起此次暂降的原因;“季节”为暂降发生的季节;“时间”为暂降在一天当中发生的时间。
对于关联规则的挖掘而言,需要将电压暂降特征属性转化为定性量进行表示。在表1中,“电压等级”、“天气”、“故障原因”为定性的语言描述类数据;“季节”和“时间”可以根据社会生活习惯进行定性划分;对于“观测位置”数据,采用K-means 聚类方法离散为东北、东南、中部、西北、西部、西南6个定性量。
1.2 电压暂降影响度
为了衡量电压暂降对敏感用户造成的影响,需要从电压暂降的严重程度和敏感用户负荷特性两个方面考虑。电压暂降的严重程度除了应考虑暂降的幅值和持续时间外,还应考虑敏感设备的电压耐受能力,本文采用不兼容度指标[12]来衡量电压暂降的严重程度,该指标计算如下:
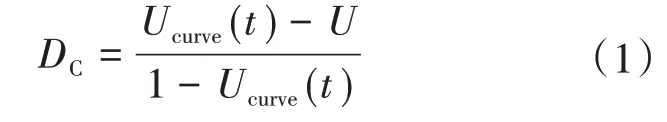
式中:DC为不兼容度值;U为电压幅值标幺值;t为暂降持续时间;Ucurve(t)为暂降持续时间为t时耐受曲线上的电压幅值标幺值,本文采用SEMI F47曲线。
对于敏感用户来说,除了考虑了电压暂降的严重程度,还需要考虑设备的优先级、容量和运行状态等敏感用户负荷特性。因此定义电压暂降影响度为

式中:Ck为第k台设备容量占节点总容量的百分比;ξ为设备故障率;ω为负荷重要性权重系数。
根据敏感设备的电压耐受曲线,如图1所示,采用考虑能量损失的设备故障敏感度概率模型,基于能量损失计算设备故障率ξ[8]。敏感设备的耐受曲线可以通过实验获取[13]。

图1 敏感设备耐受曲线Fig.1 The tolerance curve of sensitive equipment
图1 中,Umax,Umin为敏感设备对暂降电压的耐受阈值;Tmax,Tmin为敏感设备对暂降持续时间的耐受阈值。敏感设备对电压暂降的响应可分为正常运行区域、设备故障区域和不确定区域。曲线1 的外部区域(U>Umax,T<Tmin)为设备正常运行区域;曲线2 的内部区域(U<Umin,T>Tmax)为设备故障区域;曲线1 和曲线2 之间为设备运行不确定区域,包括A 区域(Umin<U<Umax,Tmin<T<Tmax)、B 区域(U<Umin,Tmin<T<Tmax)和C 区域(Umin<U<Umax,T>Tmax)三个部分。
实际电压暂降位于负荷耐受曲线的位置是随机的,即U,T必定满足累积分布概率函数。而对敏感设备而言,设备故障与否取决于暂降能量损失大小,用能量损失公式E=构造累积分布函数则可得设备故障率计算公式为

若B 区域和C 区域内随机变量T,U的概率密度分别为fx(U),fy(T),则A 区域内随机变量U,T的联合概率密度函数为fx,y(T,U)=fx(U)fy(T),所以可得A区域内的设备故障率计算公式为

若该节点上连接有多种敏感设备,则该节点电压暂降的综合影响度为
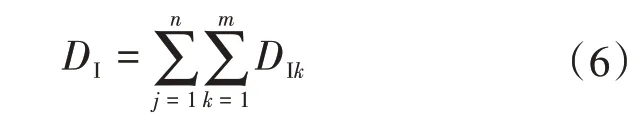
式中:DIk为第k台设备的影响度;m为第j种设备的总台数;n为敏感设备的种类。根据电压暂降综合影响度的大小,将其划分为5个等级:优(0 ≤DI<1)、良(1 ≤DI<2)、中(2 ≤DI<3)、较差(3 ≤DI<4)、差(DI≥4)。
2 关联规则挖掘
2.1 关联规则概述
关联规则形式为:X→Y,其中X⋂Y=∅[14]。通常采用支持度(S(X→Y))和置信度(C(X→Y))两个指标来进行关联规则的挖掘,其中规则支持度表示规则在数据库中出现的频率,规则置信度表示规则的可靠性。二者的计算公式为

式中:N(X⋃Y)为同时包含X和Y的事务的数目;N(D)为数据库D包含事务的数目。
式(7)表示同时包含X和Y的事务数占数据库D中事务的比值;式(8)为在数据库D中同时包含X和Y的事务占所有包含X的事务的比值。
2.2 改进FP-Growth算法
FP-Growth 算法[15]将数据库中转化为一棵频繁模式树(frequent pattern tree,FP-Tree),在保留原数据库中各项目间关联信息的同时,实现了数据库的压缩,并且提高了数据挖掘效率。相较于传统的关联规则挖掘Apriori 算法,该算法不会产生候选项集,并且可以减少扫描数据库的次数,可以有效提高挖掘效率,尤其在数据库较大时[16]。
传统的FP-Growth 算法可以挖掘任意属性之间的关联规则,对于关联特性的条件和结果没有限制。但是,当采用关联规则来评估电压暂降的影响度时,关联规则的结果必须是电压暂降的影响度指标,而条件为电压暂降特征属性。所以采用传统的FP-Growth 算法挖掘特征属性与影响度指标时会产生大量的无效规则[17],所以本文提出一种改进的FP-Growth 算法以避免这种情形,算法的步骤如下:
1)扫描数据库,找出并统计每个特征属性项出现的次数。根据特征属性项出现的次数进行降序排列以得到特征属性项频繁列表,同时删除不满足设定最小支持度的数据项。以表2中数据集为例,数据项a,b,c,d,e 和f 为特征属性项,数据项g 和h 为影响度指标项,扫描全部特征属性项并计算出不同数据项出现的频次。其中特征属性项a 出现了6 次,特征属性项c 和b 出现了5次,特征属性项e 出现了4 次,特征属性项d 出现了3 次,而特征属性项f 则出现了1 次。设定最小支持度为0.25,亦即项目最少出现次数为2次。

表2 数据库Tid表Tab.2 Tid table of database
2)将所得满足最小支持度的特征属性项放到频繁项集表中,如表3 所示。按照每个特征属性项出现的次数将表2中数据集从大到小进行重新排序,且将影响度指标排到末尾,重新排列后的数据库如表4所示。
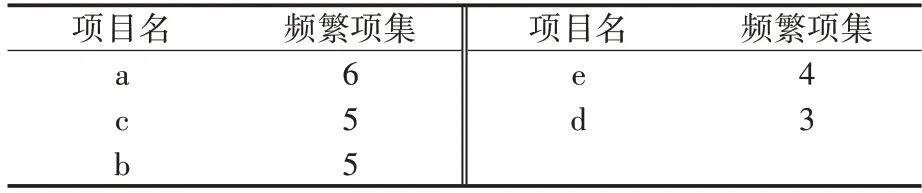
表3 频繁项集表Tab.3 Frequent itemsets table
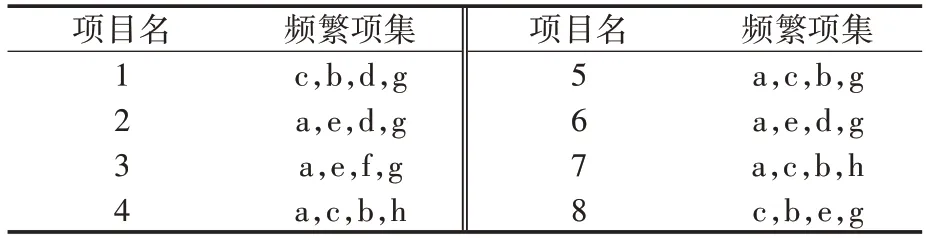
表4 整理后数据库Tid表Tab.4 The restructured Tid table of database
3)再一次扫描数据库,创建FP-Tree 的根节点,以Null 表示。将再次扫描所得的每条事务按照频繁项列表的排列顺序(影响度指标排到末尾)插入到FP-Tree 中,以此来创建一条路径。如果在建立FP-Tree 的过程中出现了相同项,则在相关项的节点数上加1。根据整理后的数据列表4,按照表3 给出特征属性项顺序依次将表4 中的项目集加入FP-Tree中,即可得到如图2所示的树状图。
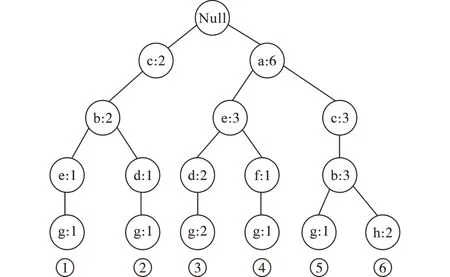
图2 FP-Tree树状图Fig.2 FP-Tree graphs
4)对于图2 所示的每一条树枝,统计尾节点影响度指标项数目。若该节点指标项数目满足最小支持度,则将此节点为结尾的路径与影响度指标项作为候选规则输出。其中,影响度指标项的数目占总事件数目的比值为该规则的支持度,影响度指标项的数目与上一节点特征属性项的数目之比为该规则的置信度。
如树枝③节点的影响度指标项g的数目为2,满足最小支持度,且置信度为1。则a,e,d,g作为候选规则集。根据图2得到的候选规则集如表5所示。

表5 候选规则集Tab.5 Candidate rulesets
3 关联规则匹配模型
对于挖掘出的关联规则,若要用于指导实际生产,则还需要与实际故障场景相匹配,通过建立合适的匹配模型,在与实际场景不完全相同时,输出相似结果。
本文采用层次分析法来构建关联规则的匹配模型,采用层次分析法[18-19]构建关联规则匹配模型的步骤如下:
1)根据实际场景与关联规则匹配体系,将匹配度最大确定为目标层,将电压暂降特征属性各维度隶属度确定为准则层,挖掘出的关联规则库为方案层。
2)根据指标层各指标间的关系确定判断矩阵。通过文献[18]中的标度来定义判断矩阵A。最后构成判断矩阵A中元素的定义如下:

式中:n为指标数目。
3)由判断矩阵A得到该矩阵的最大特征值λmax及其对应的特征向量ξ,将特征向量进行归一化以得到权重矩阵W:

式中:wi为第i个指标的权重。
4)检验判断矩阵的一致性比率是否满足要求,首先通过最大特征值λmax和指标数目n计算一致性指标CI,计算公式如下:
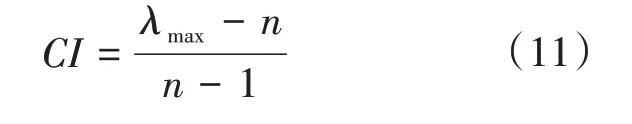
然后查找文献[18]中一致性指标RI,并计算一致性比例CR,计算公式如下:

当CR<1.0 时,则判断矩阵满足要求,否则应适当修正判断矩阵,重新计算一致性比例CR,直至满足要求为止。
5)计算关联规则暂降特征属性各维度隶属度,通过权重矩阵W计算关联规则与实际场景之间的匹配度,计算公式如下式:

式中:μki为第k条关联规则第i个特征属性隶属度。根据匹配度的大小对关联规则进行排序,并将匹配度最大的关联规则作为结果输出。
4 算例分析
4.1 关联规则有效性验证
以某电力公司电能质量监测记录为原始数据,提取电压暂降的特征属性作为事件分析的历史数据库。该数据库时间跨度为2016 年1 月—2019年12月,包括220 kV及以上母线节点99个,其他节点402个。
使用K-MEANS 聚类方法对电压暂降观测位置的经纬度值进行聚类,得到6 个定性部分。根据当地气象局信息记录得到暂降时的天气信息。由监测数据得到每次暂降事件的故障原因和时间信息,并进行分类。结合故障事件报告、监测数据与电网拓扑,计算所有事件所有母线节点的电压幅值;并根据已知历史暂降事件的电压幅值、持续时间与敏感设备耐受能力,结合关心节点所接敏感负荷特性,计算该节点电压暂降影响度。
为验证关联规则的有效性,将2016 年1 月—2018 年12 月的数据作为训练样本集,建立电压暂降影响度数据库。再以2019 年1 月—2019 年12 月的数据作为测试集,进行关联规则的匹配与验证。当依据2016 年—2018 年数据库挖掘出的关联规则在2019 年的暂降事件中仍具有相似的置信度时,则说明挖掘出的关联规则可以指导用户采取相应措施降低损失。
首先对作为训练样本集的数据进行数据挖掘,从挖掘出的关联规则内随机选取30条关联规则,参考式(8)定义关联规则在测试集中的置信度CS(i)和定义准确率η(i),如下式所示:

式中:N(Xi)为测试场景中满足故障场景Xi各暂降特征属性的节点电压暂降记录数;N(Xi→Yi)为满足关联规则Xi→Yi各暂降特征属性的节点电压暂降记录数;C(i)为关联规则自身置信度;CS(i)为关联规则在测试集中的置信度。
选取的30 条关联规则的置信度和准确率如图3所示。规则自身置信度C(i)与规则在测试集中置信度CS(i)具有相同的变化趋势;准确率η(i)在95%附近波动。说明挖掘出的关联规则不局限于所挖掘的数据库,具有普遍性。
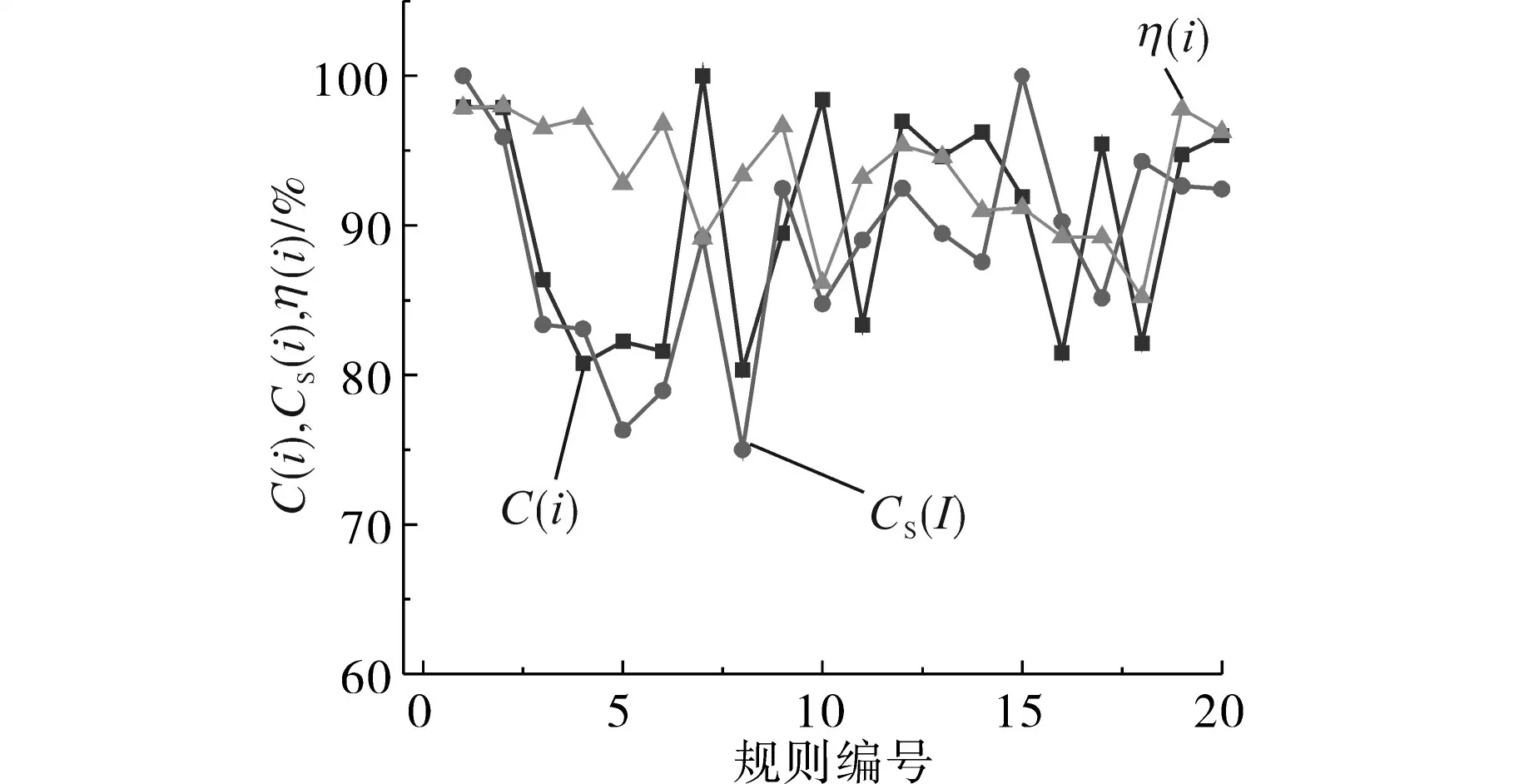
图3 关联规则准确率Fig.3 Association rule accuracy
4.2 关联规则匹配模型
针对区域内某关心节点,设置其故障场景为{东南,110 kV,冬季,早上,阴,单相接地},将故障场景与关联规则库中各规则进行匹配,当特征属性相同时,隶属度取1,其他情况都取0。运用层次分析法获得特征属性各维度隶属度权重如表6所示。根据表6中各特征属性隶属度的权重计算关联规则的匹配度,根据匹配度的大小输出关联规则,匹配结果如表7所示。

表6 特征属性隶属度权重Tab.6 The weight of membership degree of characteristic attribute
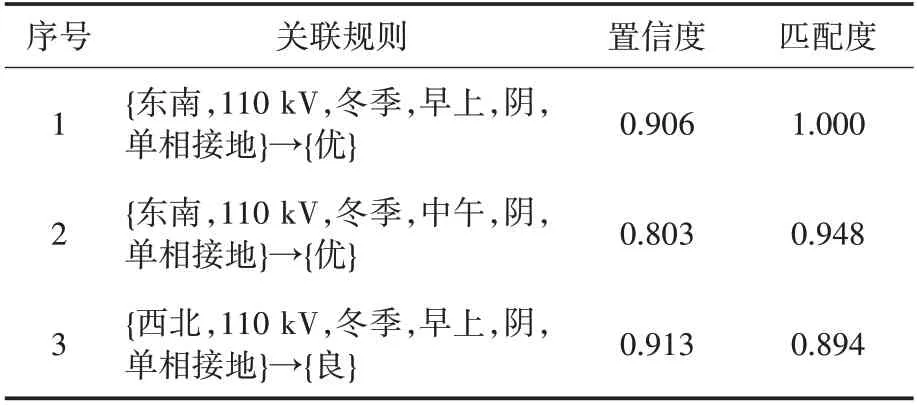
表7 关联规则匹配结果Tab.7 The match result of the association rule
根据表7可以得出在此故障场景下的电压暂降影响度。序号1的关联规则具有较高的置信度和匹配度,可以用序号1 对应的关联规则中的电压暂降影响度等级衡量该节点在此故障场景下的电压暂降严重程度。即该节点在此故障场景下的电压暂降严重程度为“优”,说明在此故障场景下发生电压暂降对该节点所接用户影响较小。
5 结论
本文提出一种基于FP-Growth 算法和层次分析法的数据挖掘分析方法来评估电压暂降影响度。所提方法可以挖掘电压暂降特征属性与电压暂降影响度之间的关联规则,并且可以通过将实际故障场景与挖掘出的关联规则相匹配来获得该故障场景下的电压暂降影响度。同时,根据挖掘出的关联规则还可以指导敏感用户选择合适的入网点。最后,通过实例分析验证了所提方法的实用性。
但是,与电压暂降影响度相关的特征属性较多,仅根据文中提到的特征属性无法完整地进行描述。因此如何选取合适的电压暂降特征属性将会是下一步的研究方向。
猜你喜欢
小猕猴智力画刊(2022年3期)2022-03-29 01:09:42
数学小灵通(1-2年级)(2021年4期)2021-06-09 06:26:14
大众投资指南(2021年35期)2021-02-16 01:06:26
当代陕西(2019年15期)2019-09-02 01:52:00
学苑创造·A版(2018年11期)2018-02-01 06:29:20
Coco薇(2017年11期)2018-01-03 20:59:57
电力与能源(2017年6期)2017-05-14 06:19:37
读者(2017年5期)2017-02-15 18:04:18
暨南学报(哲学社会科学版)(2016年9期)2017-01-15 13:52:02
信息通信技术(2015年6期)2015-12-26 01:16:46
