
一种基于特征曲线的自动土壤水分观测数据异常值检测方法*
2022-03-22 10:44周笑天陈益玲李长军张茜茹
中国农业气象 2022年3期
周笑天,陈益玲,李 芸,李长军,张 平,张茜茹
一种基于特征曲线的自动土壤水分观测数据异常值检测方法*
周笑天,陈益玲**,李 芸,李长军,张 平,张茜茹
(山东省气象防灾减灾重点实验室/山东省气象信息中心,济南 250031)
以土壤水分时间序列特征提取和形态匹配为基本操作,提出了一种基于特征曲线的自动土壤水分观测数据异常值检测新方法。首先确定检测序列X和模板序列Y的长度和范围,利用经验模态分解(EMD)方法对序列X和Y进行分解,分别获得特征重构序列C和序列Q,然后利用动态时间归整(DTW)算法对重构序列做匹配对齐操作,分别形成序列C和Q,通过序列C和Q计算获得变异序列D,并将序列D中变异系数超过门限值threshold的异常元素或异常片段标记出来,最终实现检测序列X中异常点的定位。运行实例表明:(1)检测方法无需引入土壤物理常数和气象条件等外在影响因素,避免了土壤水分计算过程中加入高低阈值、变化率阈值等相关参数。(2)方法使用同一站点相同深度的土壤水分连续数据,无需多站数据对比,且对于检测序列X和模板序列Y没有严格的长度一致性要求,因而计算更加灵活,适用性较强。(3)方法流程清晰,输入和输出对象简单明确,较为适合进行计算机编程开发和业务化运行部署。
特征曲线;土壤水分;EMD;DTW;异常点
土壤水分是土壤的重要成分也是最活跃的要素之一,它制约着土壤中养分的溶解、转移、吸收及土壤微生物的活动,对土壤生产力有着多方面的重大影响[1]。对土壤水分实现持续有效的监测,对于指导农业生产、保护生态环境以及研究气候变化都具有十分重要的意义[2−4]。中国气象局从2009年起,在全国范围内开展以FDR(Frequency Domain Reflectometry)频域反射法为技术标准开展自动土壤水分观测站网的建设工作,逐步取代传统人工烘干称重法获得土壤水分监测数据[5]。土壤水分观测自动化的实现,一方面可以大幅提高土壤水分数据的时空观测密度,为农事活动和农业气象服务提供第一手实时监测资料;另一方面,也可以极大减少人工劳动量,降低因人为操作而产生的随机误差。
与其他气象观测资料一样,土壤水分观测数据在投入使用之前,应当先经过数据质量的检测,剔除和订正异常(可疑)数据,保证数据的可靠性。目前,针对土壤水分观测数据的质量控制方法,国内外学者已有相关的研究成果。Dorigo等根据土壤含水量的时间序列特征以及与气象要素的关系,设计了一套应用于全球土壤水分数据网的质量控制方案,但是数据序列只包含了中国2000年之前部分人工测墒站点的观测数据[6]。在国内,王建荣等对安徽省自动土壤水分观测实时数据实现了质量控制[7];王良宇等给出了判定土壤水分异常的高低阈值和变化幅度阈值[8];张蕾等制定了土壤水分观测历史数据集质量控制方法,对土壤水分奇异值进行分析和校正[9];王佳强等对全国范围内土壤水分异常数据实行了分类[10]。以上的研究成果,充分结合土壤物理和水文特性等理论与经验,并参考地面气象要素质量控制中的空间一致性、时间一致性和内部一致性等方法[11−16],以单位时间内数据变化率计算为主要研究目标,最终查找出异常数据。这种方法是目前普遍采用的异常数据检测方法,但是,以上方法在实际应用过程中,仍然存在以下问题。
第一,以固定土壤物理常数作为计算土壤水分含量上下限极值或者变化率极值的条件,在方法上仍然具有一定的局限性。土壤水分观测站点在测定土壤水力特性时,大多假定土壤容重不随土壤水分状况发生变化。但实际上,土壤在干湿交替以及耕作等过程中会发生膨胀与收缩,从而使容重等物理指标发生显著变化,即土体产生“压实效应”,进而改变了土壤的持水特征[17]。因此,土壤水分含量上下限极值或者变化率极值,随着土壤容重等物理指标的变化,也应是一个动态变化的过程。
第二,现阶段仍然难以准确掌握影响土壤水分变化的主要外在因素。目前对于土壤水分变化主要外在影响因素的研究,主要集中在易于获得实测数据的降水或地温等气象因素上,但是除气象因素外,人工灌溉、植被种类、地势条件、地下水位等非实测数据,也都是土壤水分变化的重要影响因子。影响因子的枚举数量、排列组合方式或者权重赋值的不同,都会对土壤水分数据变化的合理性判别产生重大影响。中国幅员辽阔、生态与气候区域差异显著,采用多因素分析方法去阐释土壤水分的变化特征,依然面临很大的困难。
为此,不同于上述文献中的技术路线,本研究以土壤水分曲线在干湿转换过程中所呈现出的变化特征为研究目标,通过EMD特征提取、DTW匹配对齐和变异系数计算等步骤,最终实现观测异常值的拾取。本研究提出的新方法无需引入土壤物理常数或气象等外在因素,并且对于检测序列和模板序列无严格的长度一致性要求,可方便和快速地实现小时级观测密度的土壤水分数据检测。
1 资料与方法
1.1 资料来源
全国气象部门建设的基于FDR(Frequency Domain Reflectometry)频域反射法的自动土壤水分传感器是基于LC震荡电路,通过探测电容变化来计算土壤介电常数,从而获得土壤水分含量[5]。其中土壤体积含水量为一级探测数据,土壤重量含水率、土壤相对湿度和土壤有效水分储存量为根据一级数据计算出来的二级数据。
本研究资料来源于山东省气象局在省内布设的231个插针式DZN1型设备逐小时土壤体积含水量(Soil Volumetric Moisture Content, SVMC)一级数据,土壤探测深度为0−10cm,数据获取时间范围在2020年6−8月,其中,6−7月强降水较为集中,8月全省受台风“巴威”影响也有明显的降水过程。该时段全省土壤水分含量峰谷值出现较为频繁,土壤水分干湿交替过程中曲线特征明显,数据更具有代表性,便于选择典型案例对新方法进行流程演示和运行结果分析。
1.2 土壤水分原始观测时间序列的EMD分解与重构
EMD(Empirical Mode Decomposition)经验模态分解算法来源于Huang等在1998年提出的一种全新的信号时频分析方法,即希尔伯特−黄变换(Hilbert-Huang Transform,HHT)中的数据分解部分[18]。该算法将原始非平稳信号逐级分解为若干个本征模态函数(Intrinsic Mode Function,IMF)分量和一个余量(Residual,Res),分解过程为筛分(Sifting),具体步骤包括
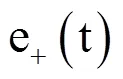
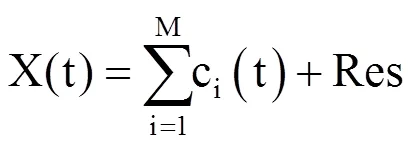
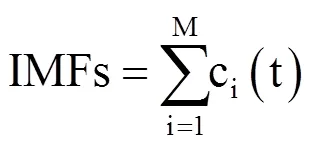
EMD分解算法具有以下特性:(1)分解自适应,与目前最为流行的小波分解算法不同,EMD算法在分解前不需要主观设定基函数和分解层数;算法分离出来的各个IMF分量大致是按照波形波动频率由高到低依次排列;(2)分解过程具有完备性,全部IMF分量和Res相加,可以还原原波形;(3)Res是一个趋势线,代表波动频率极低的波,它可以被看作是一个“基底”,全部IMF都建筑在Res之上;IMF和Res波形具有实在的物理意义,保留有原数据量纲[19]。该算法已被广泛应用于信号去噪的研究[20]。
对土壤水分原始观测时间序列曲线,可以截取有限的连续时间段,按照上述步骤进行EMD分解,在去除代表趋势的余项Res后,将得到的IMF累加序列IMFs首尾各延展一个值为0的时序元素,使重构曲线两端端点收敛于0,重构形成新序列,即
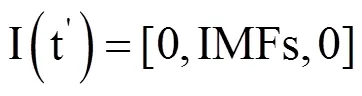
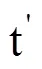
1.3 利用DTW算法实现特征曲线的匹配对齐
人体的个体差异造成了人声的个性特征,土壤的物理和外在因素差异同样也造成了土壤水分个性化变化特征。本研究借助DTW语音匹配算法思想进行土壤水分特征匹配操作。
DTW(Dynamic Time Warping)动态时间规整算法,是把时间规整和距离测度计算结合起来的一种非线性归正计算方法,它的最大优势是能够实现不同长度序列的相似度匹配,是语音识别中较为经典的算法[21],已被广泛用于孤立词语音识别系统中[22−23]。
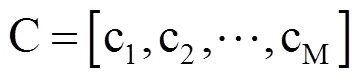
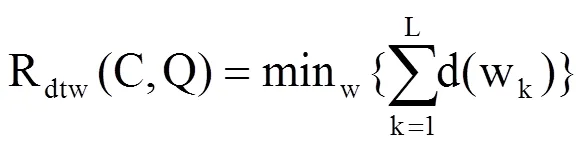
行走完毕后,原时间序列C被非线性缩放为C',Q被非线性缩放为Q',C'和Q'的长度相同,都为L。
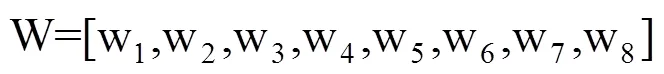
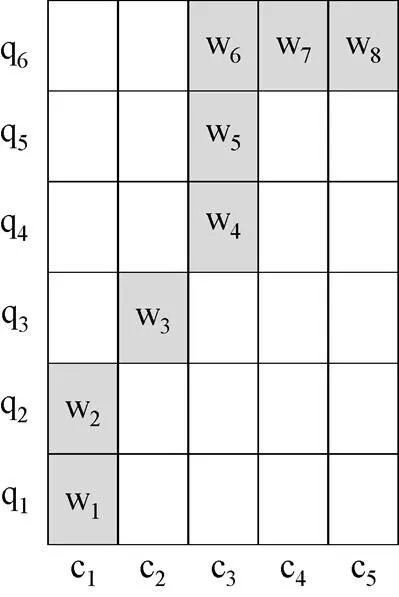
图1 DTW算法行走路径示意图(M=5,N=6)
1.4 变异系数计算与变异序列的获得方法
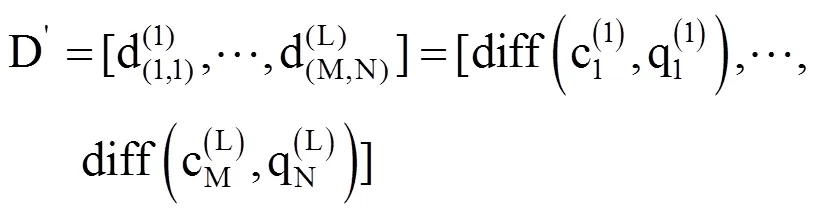
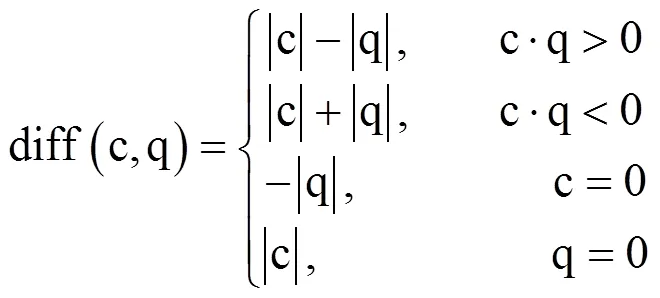
2 结果与分析
2.1 基于特征曲线的自动土壤水分观测数据异常值检测方法
2.1.1 方法总体流程设计
2.1.2 门限值threshold的计算
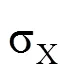
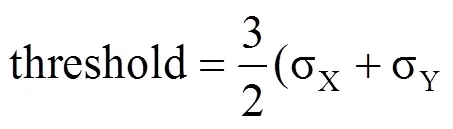
即以序列和序列标准差之和平均值的3倍作为门限值。
2.2 山东典型站点自动土壤水分观测序列异常值检测
2.2.1 郓城北站异常值检测运行过程
为清晰展示方法流程中各步骤的执行细节,结合业务实际,从山东省气象局自动土壤水分采集数据库中,选择郓城北站(站号:D8815)2020年6−8月0−10cm深度土壤体积含水量(SVMC)逐小时实况数据对方法进行全过程演示。其中,将该站已通过站点质量核查和修正的6−7月逐小时数据作为模板序列Y,以尚未进行质量检查的8月逐小时数据为检测序列X,Y长度约为X长度的2倍,以使序列Y的时间跨度中包含更多特征数据信息,用以查找序列X中的特征异常。绘制出的逐小时土壤体积含水量时间序列如图3所示,序列统计信息如表1所示。
按照图2的流程,输入序列X和序列Y之后,需要将二者分别进行EMD分解和序列重构,以形成序列C和序列Q。该过程如图4所示,其中,图4a为序列X的EMD分解结果,其IMF分量的阶数为5阶;图4b为序列Y的EMD分解结果,其IMF分量的阶数为8阶,图4c为利用式(2)将各阶分量分别累加和延展后重构形成序列C和序列Q。
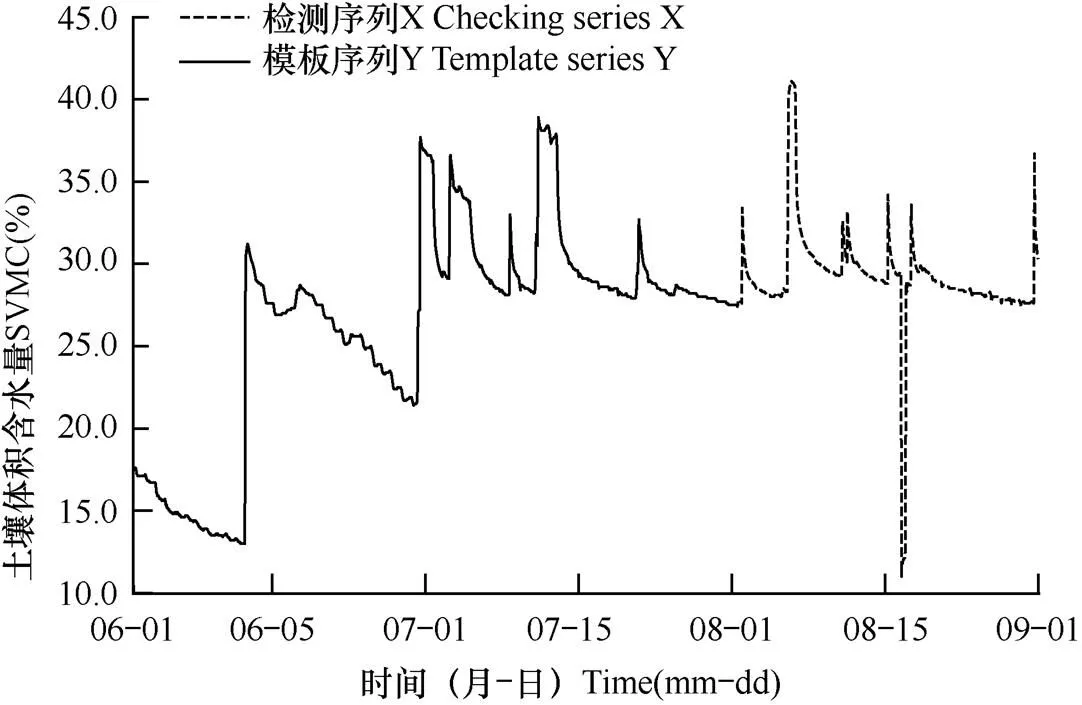
图3 山东省郓城北站(站号:D8815)2020年6−8月0−10cm深度逐小时土壤体积含水量(SVMC)检测序列X和模板序列Y

表1 D8815站土壤体积含水量(SVMC)时间序列的统计信息
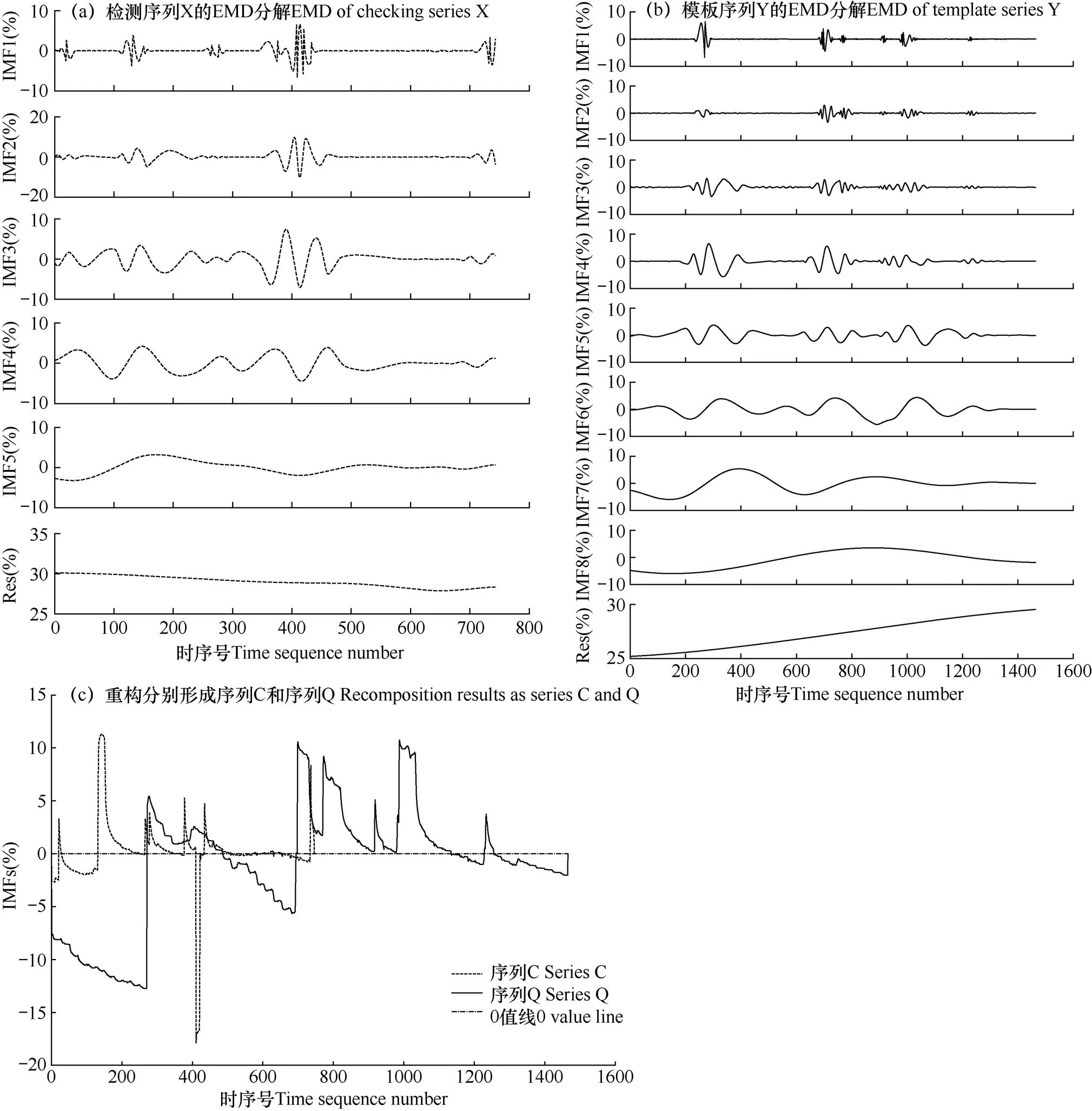
图4 D8815站检测序列X与模板序列Y的EMD分解与序列重构
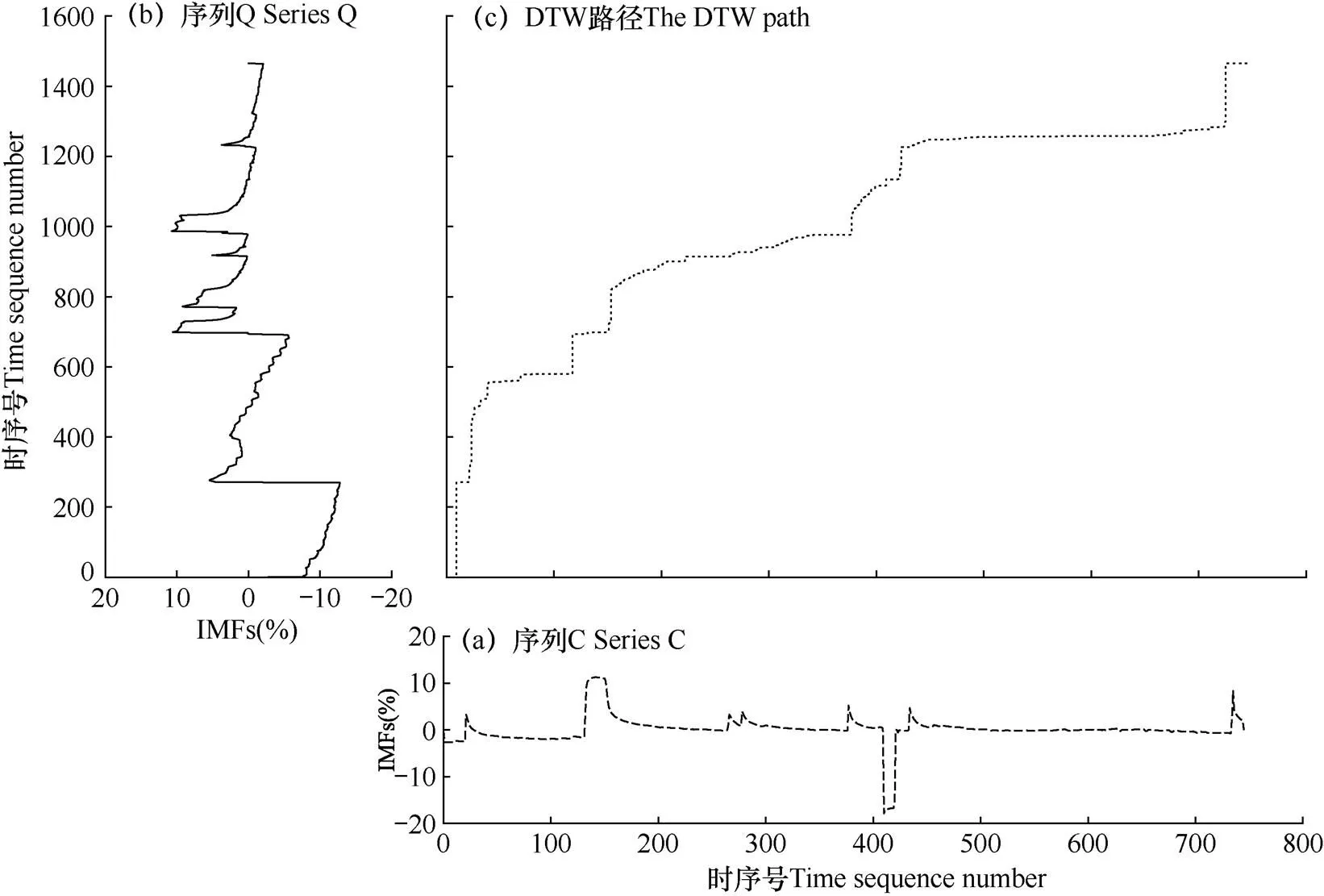
图5 D8815站序列C和序列Q的DTW行走路径
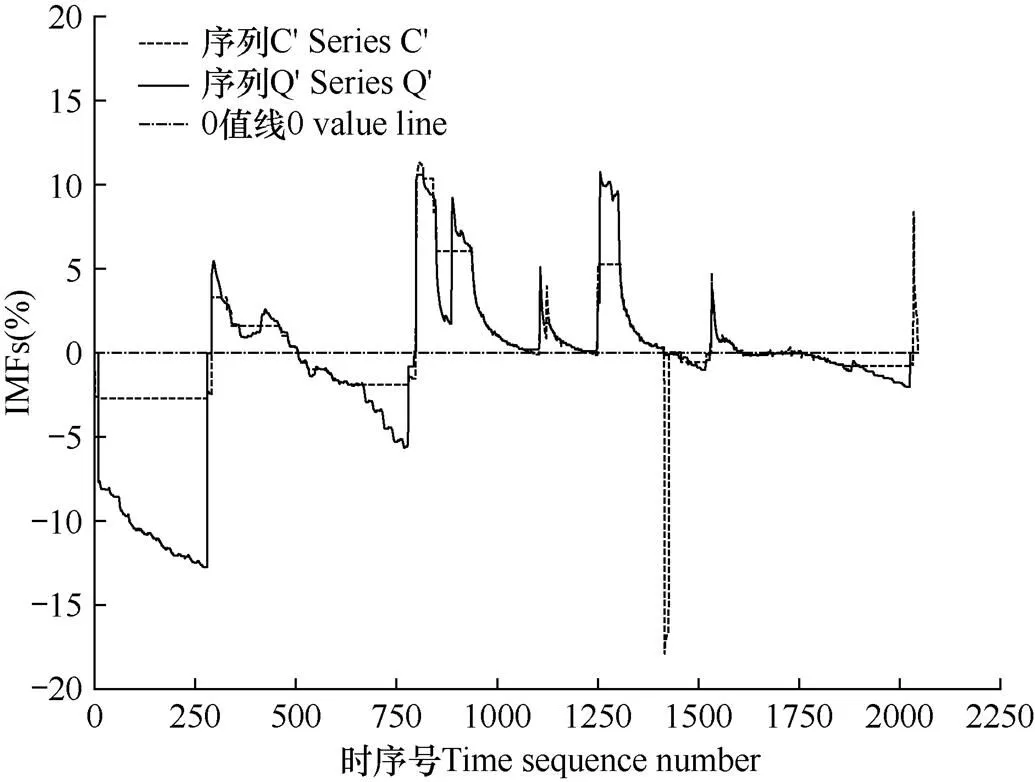
图6 D8815站序列C和序列Q经过DTW行走后获得序列C’和序列Q’
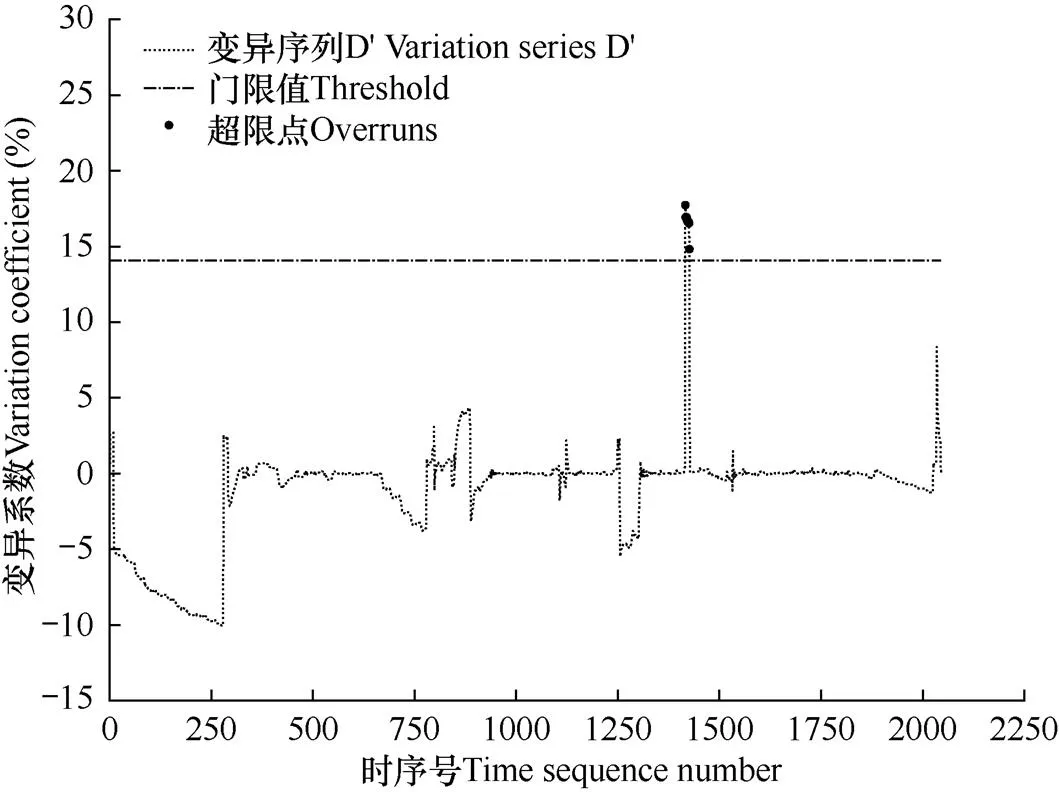
图7 D8815站通过变异序列D’和门限值threshold获得超限点
根据表2中的检测序列X中异常点的日期,可以在图3的基础上将异常点标记出来,如图8所示。
2.2.2 昌乐站和无棣站运行结果
使用本研究提出的方法和流程,对山东省昌乐站(站号:D2806)和无棣站(站号:D3805)2020年8月0−10cm深度土壤体积含水量进行了检查,图9展示了昌乐站被检出的异常数据,图10展示了无棣站被检出的异常数据。限于文章篇幅,此处仅对异常结果进行展示,不再进行完整计算过程展示。
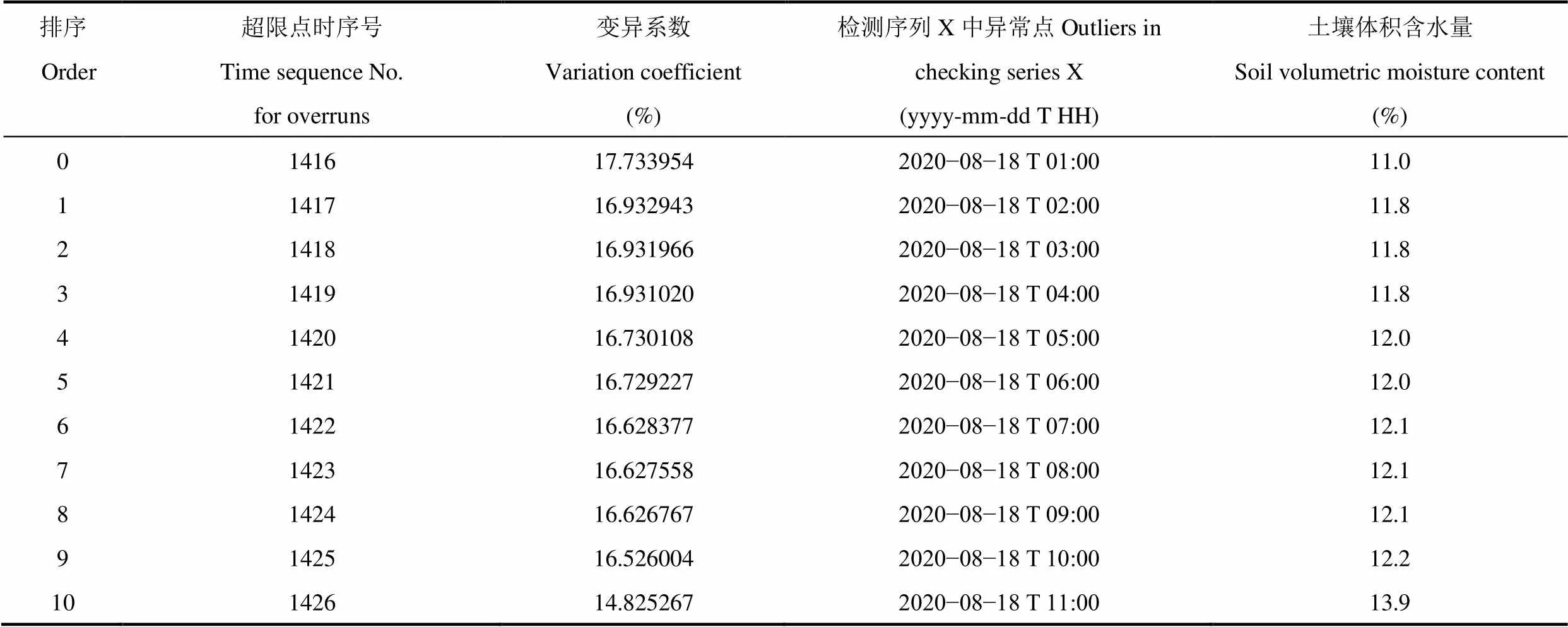
表2 D8815站异常点与超限点的位置映射信息
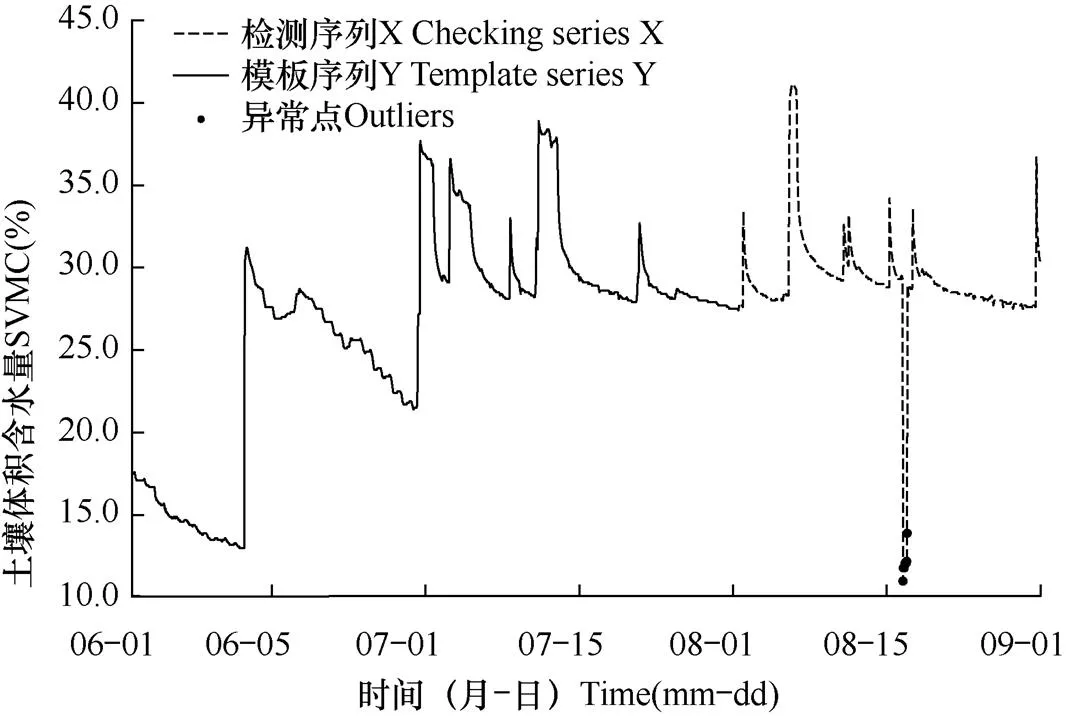
图8 D8815站检测序列X中的逐小时土壤体积含水量异常点
2.2.3 运行结果分析
结合表2和图8可以看出,在经过算法全流程计算后,D8815郓城北站检测序列X的观测异常时段出现在2020−08−18 T 01:00−T 11:00连续时间范围内,从直观角度上分析,该异常时间段呈现出了一个“V”字形的数据波动,而由于该“V”字形曲线特征在模板序列Y中找不到特征“记忆”,因而被算法认定为异常;另一方面,从图8中还可以看出,在此异常时间段以外,检测序列X中虽然也存在其他一些明显“突升”、“突降”数据跳变点,但是这些跳变数据的曲线特征由于能够在模板序列Y中找到特征“记忆”,因而未被算法认定为异常点。
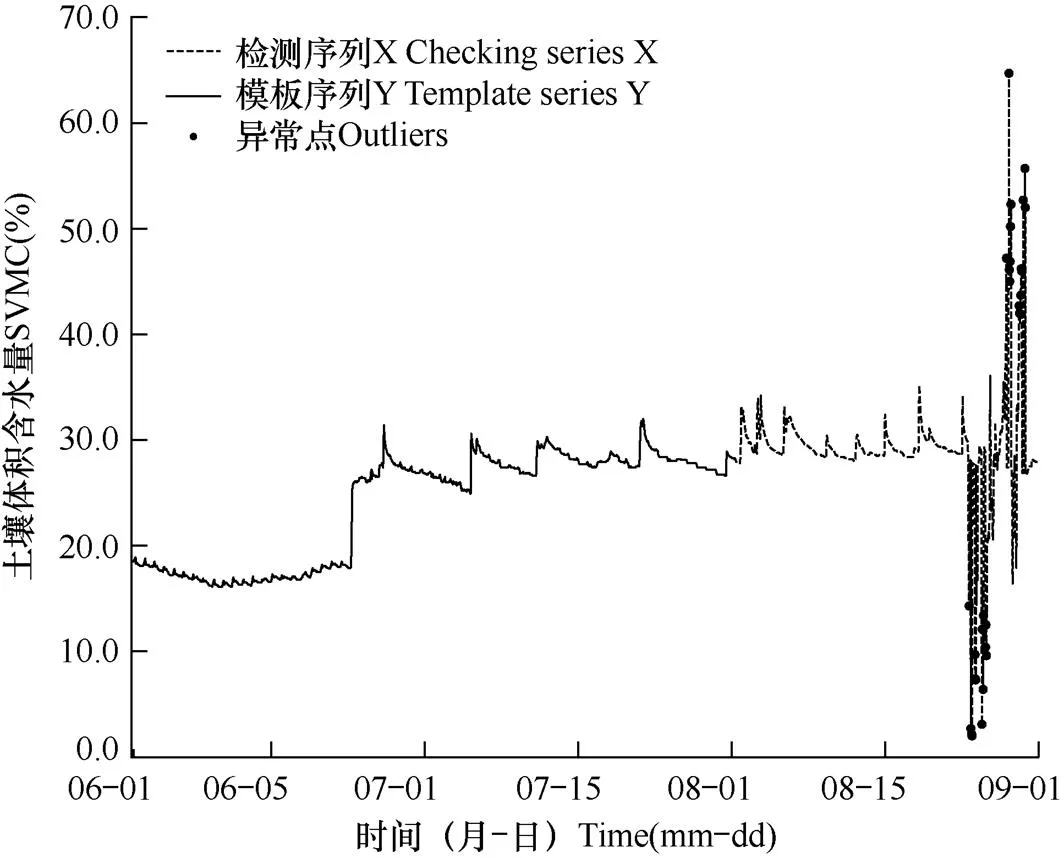
图9 山东省昌乐站(站号:D2806)2020年8月0−10cm深度逐小时土壤体积含水量异常点
同样,通过对图9和图10的观察分析可以发现,D2806昌乐站在8月下旬出现了幅值较大的高频波动,D3805无棣站在8月上旬出现了倒“V”字形的尖角特征。由于这些特征也明显区别于它们各自在6−7月模板序列Y中的特征“记忆”,因而也同样被算法认定为特征异常。
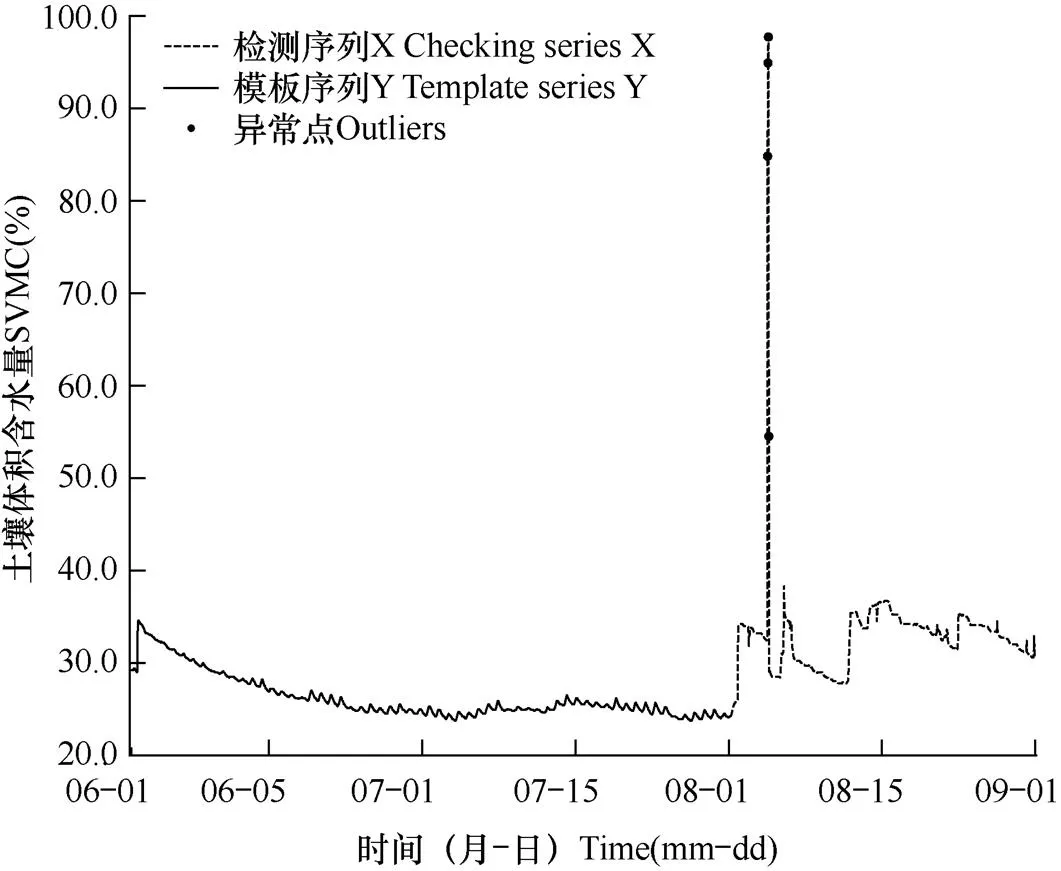
图10 山东省无棣站(站号:D3805)2020年8月0−10cm深度逐小时土壤体积含水量异常点
从以上三站的实况运行结果分析中可知,本研究提出基于特征曲线的异常值检测方法,能够有效检测出时间序列中的异常片段或异常点,且方法在判定过程中,没有对时间序列设置诸如“单位时间内变率”或“极值上下限”等全局性的门槛条件,减小了数据误判的概率,可合理保持土壤在干湿交替中所呈现出来的“个性化”变化特征。
3 结论与讨论
3.1 结论
(1)针对土壤在干湿交替过程中水分变化曲线特征,采用了类似于“特征记忆”的独特操作方式,通过将检测序列与模板序列进行特征对比,找出检测序列中曲线特征明显异于模板序列的要素点或者要素片段,从而进行异常点标记。
(2)使用来源于同一站点同一层次的连续观测数据,无需临近站点数据的横向对比,且对于检测序列X和模板序列Y无严格的长度一致性要求,操作灵活,适应性强。
(3)无需将土壤物理或水文等参数加入计算流程,从而避免了高低极值、变化率等阈值的设定;也无需引入气象因子等外在影响因素,避免了因影响因素枚举数量或者侧重点不同,造成评判指标的不一致。
(4)方法流程清晰,输入和输出对象简单明确,较为适合进行计算机编程开发和业务化运行部署。
3.2 讨论
(1)模板序列的选择具有关键作用。本研究实例中以6−7月数据作为模板数据,以8月数据作为检测数据,原因是考虑到6、7、8三个月为山东省传统的雨季,强降水频繁,土壤水分特征曲线明显,极端值出现概率较高,适合进行算法演示。而在实际工作中,模板序列的选择,可以考虑将观测站点业务化入网之前,人工对比期间的时间序列作为模板序列的起点,并结合季节、耕作以及方法运算效率等具体情况,进行择优选择;而有效的模板序列库的建立也是一个从起点开始不断滚动扩充的过程。

(3)对于同站不同深度层次的曲线特征相关性,本研究尚未涉及,这也是方法后续改进的另一个重要方向。
(4)因仪器安装或者校订等问题造成的数据误差,不在本研究探讨范围之内。
(5)农业气象中,土壤水分影响因子非常复杂,土壤“个性化”特征非常明显,需要进一步深入业务一线,不断总结和发现新的技术方法,该方法的思路也可以为其他影响因子复杂的农业气象观测项目,如设施农业或者农田小气候等的数据质量控制提供一个良好的借鉴。
[1] 李佳帅,杨再强,李永秀,等.不同水分条件下葡萄临界氮稀释曲线模型的建立及氮素营养诊断[J].中国农业气象, 2019,40(8):523-533.
Li J S,Yang Z Q,Li Y X,et al.Establishment of a critical nitrogen dilution model for grapes and nitrogen nutrition diagnosis under different water conditions[J].Chinese Journal of Agrometeorology,2019,40(8):523-533.(in Chinese)
[2] 张媛铃,郭晓磊,王娜,等.基于决策系统模拟不同降水年型旱作冬小麦的最佳播期[J].中国农业气象,2021,42(6): 475-485.
Zhang Y L,Guo X L,Wang N,et al.Analysis on the optimal sowing date of dry-land winter wheat under different precipitation pattern based on wheat decision system[J].Chinese Journal of Agrometeorology,2021,42(6): 475-485.(in Chinese)
[3] 代立芹,李春强,康西言,等.基于气候和土壤水分综合适宜度指数的冬小麦产量动态预报模型[J].中国农业气象, 2012,33(4):519-526.
Dai L Q,Li C Q,Kang X Y,et al.Dynamic forecast model of winter wheat yield based on climate and soil moisture suitability[J].Chinese Journal of Agrometeorology,2012, 33(4):519-526.(in Chinese)
[4] 王蔚丹,孙丽,裴志远,等.典型旱年农业干旱遥感监测指标在东北地区生长季的表现[J].中国农业气象,2021,42(4): 307-317.
Wang W D,Sun L,Pei Z Y,et al.Performances of remote sensing monitoring indices of agricultural drought in growing season of typical dry year in Northeast China[J].Chinese Journal of Agrometeorology,2021,42(4): 307-317.(in Chinese)
[5] 黄飞龙,李昕娣,黄宏智,等.基于FDR的土壤水分探测系统与应用[J].气象,2012,38(6):764-768.
Huang F L,Li X D,Huang H Z,et al.Soil moisture detection system based on FDR and its application[J]. Meteorological Monthly,2012,38(6):764-768.(in Chinese)
[6] Dorigo W A,Xaver A,Vreugdenhil M,et al.Global automated quality control of in situ soil moisture data from the international soil mosture network[J].Vadose Zone J,2013.12(3). DOI:10.2136/vzj2012.0097.
[7] 王建荣,江双武,董得宝.自动观测土壤体积含水量实时资料自动质量控制方法[J].计算技术与自动化,2013,32(4): 134-137.
Wang J R,Jiang S W,Dong D B.The method of automatic quality control for real-time data from automatic soil- moisture station[J].Computing Technology and Automation, 2013,32(4):134-137.(in Chinese)
[8] 王良宇,何延波.自动土壤水分观测数据异常值阈值研究[J].气象,2015,41(8):1017-1022.
Wang L Y,He Y B.Research on outlier threshold of automatic soil moisture observation data[J].Meteorological Monthly,2015,41(8):1017-1022.(in Chinese)
[9] 张蕾,吕厚荃,王良宇.土壤水分历史观测数据集奇异值分析与校正[J].气象,2017,43(2):189-196.
Zhang L, Lv H Q,Wang L Y.Analysis and calibration of singular historical observed data of manual soil water[J]. Meteorological Monthly,2017,43(2):189-196.(in Chinese)
[10] 王佳强,赵煜飞,任芝花,等.中国自动土壤水分观测资料质量控制方法设计与效果检验[J].气象,2018,44(2):244-257.
Wang J Q,Zhao Y F,Ren Z H,et al.Design and verification of quality control methods for automatic soil moisture observation data in China[J].Meteorological Monthly,2018, 44(2):244-257.(in Chinese)
[11] 刘小宁,鞠晓慧,范邵华.空间回归检验方法在气象资料质量检验中的应用[J].应用气象学报,2006,17(1): 37-43.
Liu X N,Ju X H,Fan S H.A research on the applicability of spatial regression test in meteorological datasets[J].J Appl Meteor Sci,2006,17(1):37-43.(in Chinese)
[12] 张强,涂满红,马舒庆,等.自动雨量站降雨资料质量评估方法研究[J].应用气象学报,2007,18(3):365-372.
Zhang Q,Tu M H,Ma S Q,et al.Quality assessment of the observational data of automatic precipitation stations in China[J].J Appl Meteor Sci,2007,18(3):365-372.(in Chinese)
[13] 王海军,刘莹.综合一致性质量控制方法及其在气温中的应用[J].应用气象学报,2012,23(1):69-76.
Wang H J,Liu Y.Comprehensive consistency method of data quality controlling with its application to daily temperature[J]. J Appl Meteor Sci,2012,23(1):69-76.(in Chinese)
[14] 周笑天,褚希,姚志平.一种基于k-means聚类的实时气温动态质量控制方法[J].气象,2012,38(10):1295-1300.
Zhou X T,Chu X,Yao Z P.A dynamic method of quality control for real-time temperature measurements based on k-means cluster algorithm[J].Meteorological Monthly,2012, 38(10):1295-1300.(in Chinese)
[15] 任芝花,张志富,孙超,等.全国自动气象站实时观测资料三级质量控制系统研制[J].气象,2015,41(10):1268-1277.
Ren Z H,Zhang Z F,Sun C,et al.Development of three-step quality control system of real-time observation data from AWS in China[J].Meteorological Monthly,2015,41(10): 1268-1277.(in Chinese)
[16] 封秀燕,何志军,王荷平,等.自动气象站实时资料质量控制开放式平台设计[J].应用气象学报,2010,21(4):506-512.
Feng X Y,He Z J,Wang H P,et al.The design of an open platform for automatic weather stations on real time data quality control[J].J Appl Meteor Sci,2010,21(4):506-512.(in Chinese)
[17] 陈祯.土壤容重变化与土壤水分状况和土壤水分检测的关系研究[J].节水灌溉,2010(12):47-50.
Chen Z.Research on relationships between soil bulk density change and soil water regime as well as soil water monitoring[J].Water Saving Irrigation,2010(12):47-50.(in Chinese)
[18] Huang N E,Shen Z,Long S R,et at.The empirical mode decomposition and the hilbert spectrum for nonlinear and non-stationary times series analysis[J].Proceedings of the Royal Society of London,1998,454:903-995.
[19] 徐晓刚,徐冠雷,王孝通,等.经验模式分解(EMD)及其应用[J].电子学报,2009,37(3):581-585.
Xu X G,Xu G L,Wang X T,et al.Empirical mode decomposition and its application[J].Acta Electronica Sinica,2009,37(3):581-585.(in Chinese)
[20] 王婷.EMD算法研究及其在信号去噪中的应用[D].哈尔滨:哈尔滨工程大学,2010:89-114.
Wang T.Research on EMD algorithm and its application in signal denoising[D].Harbin:Harbin Engineering University, 2010:89-114.(in Chinese)
[21] Tormene T,Giorgino S,Quaglini M.Stefanelli matching incomplete time series with dynamic time warping: an algorithm and an application to post-stroke rehabilitation[J]. Artificial Intelligence in Medicine,2008,45(1),11-34.DOI: 10.1016/j.artmed.2008.11.007.
[22] 周炳良.非特定人孤立词语音识别算法研究[D].南京:南京邮电大学,2018:32-54.
Zhou B L.Research on speech recognition algorithm of speaker-independent isolated words[D].Nanjing:Nanjing University of Posts and Telecommunications,2018:32- 54.(in Chinese)
[23] 吴晓平,崔光照,路康.基于DTW算法的语音识别系统实现[J].电子工程师,2004,30(7):17-19.
Wu X P,Cui G Z,Lu K.The realization of speech recognition system based on DTW algorithm[J].Electronic Engineer, 2004,30(7):17-19.(in Chinese)
[24] 李正欣,张凤鸣,李克武,等.一种支持DTW距离的多元时间序列索引结构[J].软件学报,2014,25(3):560-575.
Li Z X,Zhang F M, Li K W,et al.Index structure for multivariate time series under DTW distance metric[J]. Journal of Software,2014,25(3):560-575.(in Chinese)
An Outliers Detection Method for Automatic Soil Moisture Observation Data Based on Characteristic Curve
ZHOU Xiao-tian, CHEN Yi-ling, LI Yun, LI Chang-jun, ZHANG Ping, ZHANG Qian-ru
(Key Laboratory for Meteorological Disaster Prevention and Mitigation of Shandong/Shandong Meteorological Information Centre, Jinan 250031, China)
A new outliers detection method for automatic soil moisture observation data based on characteristic curve is proposed. The main and basic idea of this method was feature extraction and the morphological matching between two soil moisture time series, and the detailed operation processes were as follows: firstly, the method took X as the expected checking time series and took Y as the corrected template time series, and also gave the range and elements of these two series. Secondly, the method decomposed series X and Y by empirical mode decomposition (EMD) method to obtain the recomposition series C and Q respectively. In this process, series C was the total accumulation of IMFs of series X and series Q was the total accumulation of IMFs of series Y. Thirdly, the method obtained series Cand Qby using dynamic time warping (DTW) algorithm which was designed to align series C and Q. Fourthly, the method obtained the variation series Dwhose elements were calculated by the variation coefficient between series Cand Q, and then, the method also traversed each element of series Dand marked the elements whose value was greater than threshold as overruns. The threshold was obtained by comprehensive calculating the standard deviation of series X and Y. Finally, the outliers in the checking series X could be found through the mapping relationships between series X and series D. The example showed that: (1) the method did not need to introduce external factors such as soil physical constants and meteorological conditions, and avoided adding relevant parameters such as high and low boundary and slope in the calculation process. (2) The method used the continuous soil moisture data of the same depth from the same station instead of multi-station data comparison, and had no strict length consistency requirements for series X and series Y, so the calculation was more flexible and applicable. (3) The routine of the method was clear, and all of the input processes and output processes in this method were specific. The method was suitable for computer programming and business operation. The technical route of this method might be provided for other agrometeorological data quality control research.
Characteristic curve; Soil moisture; EMD; DTW; Outliers
周笑天,陈益玲,李芸,等.一种基于特征曲线的自动土壤水分观测数据异常值检测方法[J].中国农业气象,2022,43(3):229-239
10.3969/j.issn.1000-6362.2022.03.006
2021−05−24
山东省发展和改革委员会“山东现代农业气象服务保障工程”[鲁发改农经(2017)97号]
陈益玲,高级工程师,研究方向为气象数据质量控制与气象档案管理,E-mail:lotushumor@126.com
周笑天,E-mail:xtzhou1981@163.com
猜你喜欢
建材发展导向(2022年20期)2022-11-03
农业工程学报(2022年10期)2022-08-22
建材发展导向(2022年12期)2022-08-19
云南大学学报(自然科学版)(2022年4期)2022-08-03
农业工程学报(2022年5期)2022-06-22
作文周刊·小学一年级版(2022年24期)2022-06-18
水土保持学报(2022年3期)2022-05-26
中国农业气象(2022年2期)2022-02-10
建材发展导向(2021年20期)2021-11-20
金桥(2021年7期)2021-07-22
