
基于Neo4j图数据库的电影知识图谱构建与电影推荐研究
2022-03-22 02:59王卓岚张雨琦陈鸣宇苏意淇董春玲
现代电影技术 2022年3期
关键词:电影
王卓岚 张雨琦 陈鸣宇 苏意淇 宋 凯 董春玲
(中国传媒大学,北京 100024)

1 引言
随着我国经济的腾飞,拥有百余年历史的我国电影产业呈现出迅猛发展的态势。大数据时代的互联网为网络用户提供了丰富的影音资源,新冠疫情背景下,线上、线下观影模式融合互补。与此同时,海量的电影数据也给用户便捷获取自己喜爱的电影带来了挑战。因而,如何精准地为网络用户推荐电影变成了流媒体平台重点关注的问题。
个性化电影推荐系统研究的主要问题是如何从互联网海量电影数据中找到每个用户感兴趣的电影,并将这些电影推送给用户。本文依据知识图谱可存储丰富数据及数据间关系的特点,将其引入电影推荐系统进行模型构建。该方法在解决数据稀疏性问题、语义匹配精准度、推荐多样化和结果可解释性方面都有较好的效果,对电影推荐技术的发展有一定现实意义。
2 研究背景和意义
2.1 推荐系统研究现状
近年来,不少相关人士针对电影推荐系统进行了学术研究,同时也提出了相关推荐算法。传统推荐算法可分为四类:协同过滤推荐、基于内容的推荐、基于人口统计学的推荐和混合推荐。毛德磊等人在论文中改进了协同过滤算法,基于用户行为一致性、区别性和正负偏好信息提取用户偏好,融合偏好相似性与评分相似性进行协同过滤推荐;吕学强等人在论文中利用Text Rank、Wor d2 Vec等技术对影评进行关键词抽取和词向量构建,提出一种结合影评内容相似度和长短期兴趣模型来计算电影相似度的推荐方法;邓存彬等人在论文中利用动态协同过滤算法融入时间特征,运用深度学习模型学习用户和电影特征信息,最后将形成的隐向量融入动态协同过滤算法中进行电影推荐。
2.2 推荐系统面临的挑战
协同过滤算法依赖用户自身或用户其他已知的历史数据为该用户推荐喜爱的电影,当新用户或者新电影出现时,个性化电影推荐会因为缺乏历史数据而出现冷启动问题。同时,电影发明一个多世纪以来,网络相关数据库中生成了海量电影资源,其中仅有少数电影被用户观看并评分过,这就造成用户—电影评分矩阵中大量数据为空值,随之出现了难以避免的数据稀疏问题。因此依据评分矩阵进行推荐后的结果准确率较低,推荐质量也无法保证。
基于内容的推荐算法,其核心在于根据用户的兴趣与偏好,为用户推荐与其先前喜好内容相似的资源。在电影研究方面,该算法的缺点在于电影特征需要人工标注和提取,同时推荐系统还难以发现用户新的兴趣点。例如,某观影者过去仅倾向于观看爱情类电影,那么基于内容的推荐算法就会为其推送更多的爱情电影,而无法发掘出观影者对于科技类电影的潜在兴趣。此外,基于内容的推荐算法与协同过滤算法相似,由于缺少新用户的喜好历史,无法提取相应的电影特征信息,进而难以为新用户进行精准推荐。
基于人口统计学的推荐算法根据用户的基本信息进行推荐,而针对电影推荐问题的特殊性,用户基本信息与用户喜好并无紧密关联,因此该方法存在较大的语义失配问题。
混合推荐算法虽解决了单一推荐的局限性问题,但由于其实现过程复杂且投入成本过高,目前并未被广泛采用。
2.3 知识图谱对电影推荐系统的作用
2.3.1 弥补数据稀疏性干扰问题
针对电影评分数据存在的稀疏性问题,近年来不少研究将交互记录以外的辅助信息引入推荐系统,从而对用户和电影进行更精准、丰富的画像。此外,用户的注册信息、社交关系、标签等属性也可以为该方法提供更加精确的预测模型,但往往充分获取相关辅助信息需要付出很大的代价。
知识图谱中蕴含了丰富的电影及用户相关数据,尤其是其中的属性信息和用户间关系,可作为一类重要的辅助信息引入电影推荐系统,很好地弥补了数据稀疏性干扰问题,与此同时也减少了获取并存储庞大辅助信息的代价。
2.3.2 实现精准的语义匹配
在知识图谱中经由简单的知识推理即可发现众多实体或特征之间的语义匹配和关联,这一优点可以为电影推荐系统产生更准确的推荐结果。例如,对于电影 《勇敢传说》与 《魔发奇缘》的语义关联问题,可以通过电影类型图谱 (存有电影类型与影片名称的关系)发现如图1所示的语义链,从而将两部电影联系起来。

图1 电影类型语义链
2.3.3 完成多样化电影推荐
知识图谱引入了更多的语义关系,可以深层次地发现用户兴趣。基于知识图谱的电影推荐可以发现电影间的异质关联,从而从不同维度推荐电影。例如,在图2中若用户曾经观看过电影 《超凡蜘蛛侠》,依据知识图谱中电影导演、演员和电影类型这三种不同属性的关联,推荐系统可以向该用户推荐《和莎莫的500天》(都由马克·韦布导演)、《血战钢锯岭》(都由安德鲁·加菲尔德主演)和 《复仇者联盟》(都是科幻片)三部完全不同风格的电影。
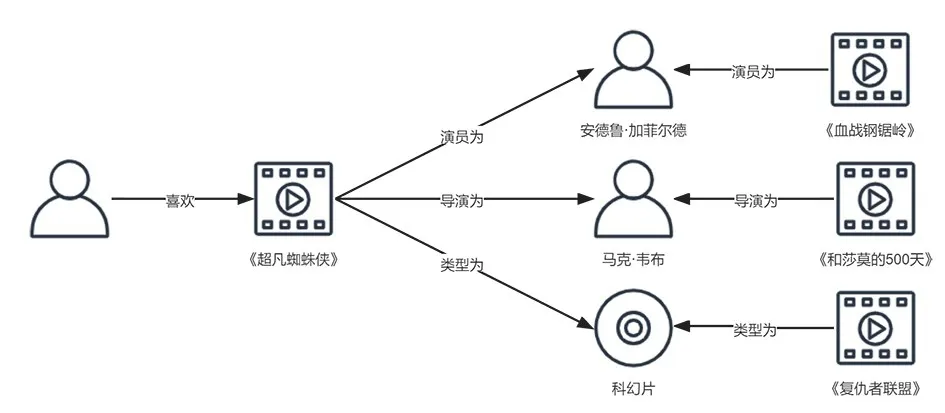
图2 多样化电影推荐
2.3.4 提供可解释性依据
知识图谱中存有的不同电影间的关联信息可用作电影推荐结果的可解释性依据。还以上例中看过电影 《超凡蜘蛛侠》的用户为例,将推荐系统推荐出的三部电影与 《超凡蜘蛛侠》的关联直接展现给用户,能够让用户更直观地了解系统如此推荐的理由,从而增强了接受该推荐结果的主观意愿。
3 理论介绍
3.1 知识图谱
在知识图谱中,假定我们用节点集合E代表实体或者概念。其中,实体代表具有可区别性且独立存在的某类事物,概念指具有同种特性的实体构成的集合,每个实体或者概念用一个唯一的ID标识;边R代表实体或概念之间的各种语义关系。由此,一个三元组 (h,r,t)就可以表示两个实体之间的某种关系,也可以称其为一条知识,其中h表示知识的头节点,t表示尾节点,r表示关系。即S={(h,r,t)|h⊆E,r⊆R,t⊆E}。
若干三元组的集合构成了一个知识图谱。如图3,知识图谱可以清晰地表示出影片、影片题材、导演和主演之间的关系。随着实体或概念种类的增加,知识图谱可表示的信息会更加全面。

图3 知识图谱样例
3.2 知识抽取
电影知识图谱构建的关键步骤是如何实现将数据从不同的数据源中抽取出来,按照一定规则加入到知识图谱中,这个过程我们称为知识抽取。知识抽取主要分为两个方面,分别是命名实体识别和关系抽取。最初在技术发展不成熟时,命名实体识别和关系抽取主要以人工编写规则或借用模板的方式进行抽取。但构造规则的方法会耗费大量的人力物力,并且一套规则仅适用于一种领域,其迁移性和泛化性很低。
知识抽取面向的数据分为结构化数据与非结构化数据,下面将简单介绍面向这两类数据的知识抽取。
3.2.1 面向结构化数据的知识抽取
结构化数据类似于关系库中以表格形式存储的数据,数据各项之间往往存在明确的对应关系,可以将其转化为RDF(Resource Description Fra mewor k)或其他形式的知识库内容。
3.2.2 面向非结构化数据的知识抽取
非结构化数据的实体抽取较为复杂。举例来说,在非结构化数据文本中,实体抽取对象应选取文本中的原子信息元素,通常包含任命、组织/机构名、地理位置、事件/日期、字符值、金额值等标签,具体的标签定义可根据任务不同而调整。实体抽取的任务是找到命名实体名并进行分类;关系抽取是从文本中抽取出两个或多个实体之间的语义关系。其抽取方法包括:基于规则的方法、监督学习的方法、半监督学习或无监督学习的方法。
3.3 余弦相似度
余弦相似度又称为余弦相似性,是通过计算两个向量的夹角余弦值来评估它们的相似度。其计算公式为:

式 (1)中,A和B分别表示向量A、B的各分量。相似性的范围是从-1到1。-1代表两个向量指向的方向相反,1代表两个向量指向的方向相同,0通常代表两个向量之间是独立的。而在-1到1间的其余值则表示中间的相似性或相异性。
4 电影知识图谱构建与可视化
本文中的h和t用于存放用户ID、电影名称、电影类型以及出品方等属性信息,r则代表每对属性信息之间的关系。本文构建了多个知识图谱,分别包含电影—类型、电影—关键词、电影—出品方以及用户—电影等信息。
基于知识图谱的电影推荐系统构建主要分为四步:首先获取电影和用户数据;然后对原始数据进行处理 (即知识抽取),构建知识图谱三元组;接下来将处理后的数据导入Neo4j图数据库进行可视化;最后根据构建出来的知识图谱进行电影推荐。
4.1 电影知识图谱构建
4.1.1 数据获取
电影和用户数据来源于Kaggle上两个较为经典的数据集:T MDB(The Movie Database)和Netfil x Prize。T MDB数据集存储电影的各类属性信息,如电影名称、电影类型、电影关键词、电影时长、票房收入等各种信息;Netfilx Prize数据集存储用户对电影的评分数据 (评分等级从低到高依次为0~5),包含用户ID及其对电影的评分信息。
4.1.2 数据处理和知识抽取
本文对T MDB、Netflix Prize数据库以面向结构化数据的抽取方式进行知识抽取。首先获取各项之间存在的较为明确的对应关系,进而实现RDF数据集的创建和数据对象序列化。然后基于python编写解析程序进行数据解析和规范,对关键属性进行提取,从而生成属性数据集。
从T MDB数据集中提取出每一个电影对象所需要的属性值 (包括电影名称、电影类型、电影关键字、电影出品方),将其表示为节点,其中,电影名称为主要节点,其他属性为电影名称节点的信息节点。其次是关系的构建,节点关系定义了两个节点之间存在的特定关联,在知识图谱中,它可以被描述为两个节点实体间的有形边。以构造电影类型三元组为例,表1中Avatar、Spectre等字段为电影名称节点,Action、Adventure等属性字段为电影类型节点,Genre即为Avatar节点 (电影名称)和Action节点 (电影类型)之间的边,其含义为:电影(《阿凡达》)的类型为Action。本例中实际存储数据集文件时,只用存储两个节点即可,节点关系由Neo4j存储时使用cypher语言说明。

表1 电影类型数据集 (部分)
从Netfil x Prize数据集中提取出用户对电影的评分矩阵,将电影名称和用户ID作为节点 (实体),以用户对该电影的评分值作为边,进行电影名称节点和用户ID节点间的关系创建。如表2中,用户684(用户ID)和电影(《伴郎》)(电影名称)之间的边 (关系)值为4,其含义为:用户684对电影(《伴郎》)的评分等级为4。
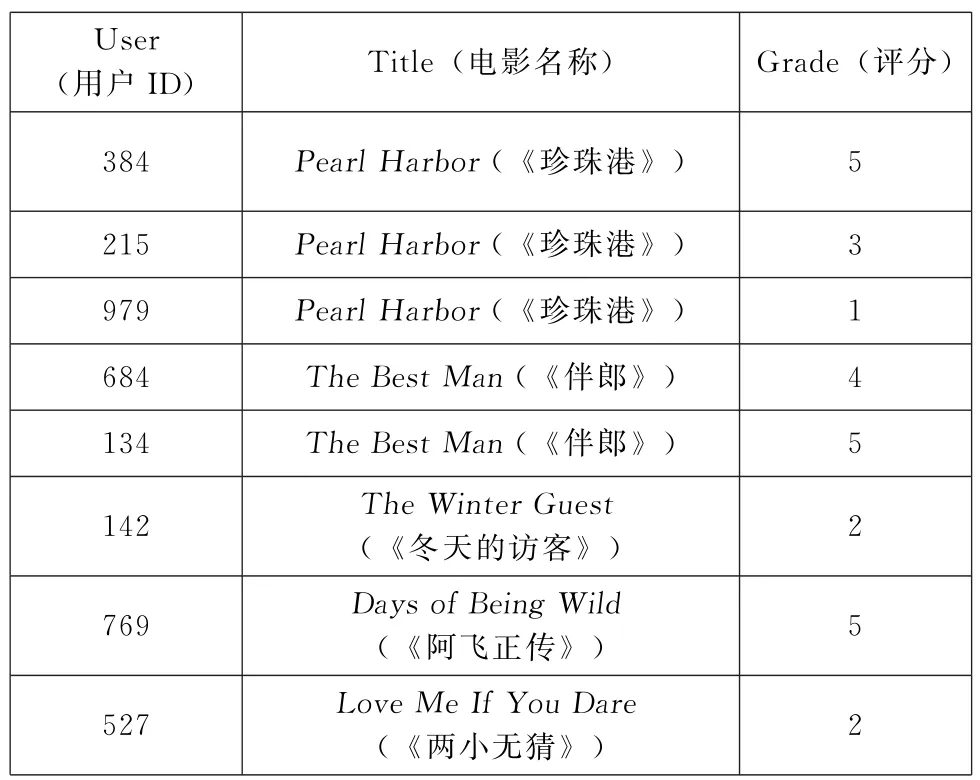
表2 用户评分数据集 (部分)
其他三元组的构建也应用上述方法。这样就构建出了知识图谱中实体以及实体之间的关系,本文构建的电影知识图谱实体以及关系如表3所示。

表3 实体关系表
以上就是数据处理和知识图谱的构建过程。处理过后的数据集是符合Neo4j导入要求的CSV文件,文件中包含电影名称、电影关键词、电影类型、电影出品方、用户ID等实体以及电影名称与电影类型、电影名称与出品方、电影名称与电影关键词、用户ID与电影名称 (包含用户给电影的评分)等实体关系。
4.2 电影知识图谱存储
4.2.1 Neo4j存储的优点
目前知识图谱的存储方式主要有关系型数据库、图数据库和基于RDF结构的存储方式。图数据库存储方式最大的优点在于,图结构即为知识图谱结构:图中的节点代表知识图谱的对象,图中的边代表知识图谱对象之间的关系。目前使用最广泛的图数据库为Neo4j。
Neo4j图数据库以图形结构的形式存储信息,关联的数据本身就是它所包含的数据,因此它可以直接显示关联数据特征以及数据之间的关系。Neo4j导入节点的数量大、速度快、支持查询算法,并且相较于传统的关系型数据库,Neo4j的遍历算法设计借助图结构自然伸展的特点,不需要复杂的连接运算,因此数据及其关系复杂程度的增加不会导致搜索效率的下降。
4.2.2 知识导入
将数据导入Neo4j主要使用以下三种方法:第一种是使用cypher CREATE语句,为每条数据创建一条CREATE语句;第二种是使用cypher语法中的LOAD CSV语句;第三种是使用Neo4j官方提供的neo4j-i mport工具。cypher语言的LOAD CSV语句可以适用于任何情况下的数据导入。本文通过LOAD CSV语句将经过数据预处理后的电影CSV文件导入到Neo4j数据库中 (需要将处理好的数据放到Neo4j安装路径下的i mport文件夹中)。
4.2.2 .1 导入数据并创建节点
节点导入模型:
variable:Lable{key1:val ue1,…,key N:value N}
节点标签对应关系型数据库的表名,而属性对应关系型数据库中表的列。在被创建时,每个节点都会自动获得一个默认的内部属性ID,其值为整数。同时,节点的ID属性值在图数据库中是逐次递增且唯一的。
以 “用户”和 “电影”两个节点的导入为例,具体的语句为:
LOAD CSV WITH HEADERS FROM'file:///grade.csv'AScsv
MERGE(m:电影{title:csv.title})
MERGE(u:用户{id:toInteger(csv.user_id)})
4.2.2 .2 创建节点之间的关系
关系构建模型:
(start Node)-[variable:relationship Type{key1:value1,…,key N:value N}]→ (end-Node)
关系模型中圆括号内字段表示节点,方括号内字段表示关系,花括号内字段表示关系的属性。关系类型形式上类似于节点标签,且在创建新关系时,关系类型必须被唯一指定。在cypher语言中,关系可分为两种:使用一对短横线 (即--)表示一个无方向的关系;若在无方向关系的一端加上箭头 (即→或 ←)则表示一个有方向的关系。
以上面构建的 “用户”和 “电影”两个节点为例,构建两个节点之间的关系,即用户给电影的评分。具体语句为:
CREATE(用 户)-[:RATED{grading:toInteger(csv.grade)评分}]→ (电影)
当上例中节点与节点关系创建成功,如图4所示。
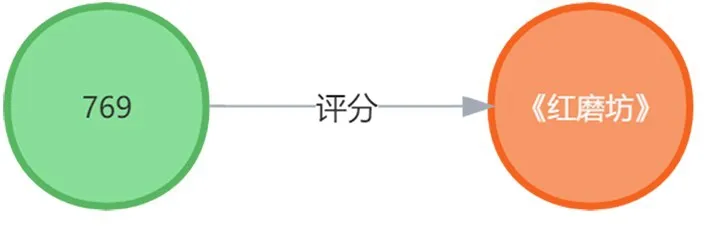
图4 三元组
橙色 (右)表示为 (电影(《红磨坊》))实体,绿色 (左)表示为用户实体 (用户769),箭头描述的是用户与电影之间的关系,意味该用户给该电影评分过。将类似的多个三元组相互连接便形成了知识图谱,如图5和图6所示。所构建的知识图谱中节点与关系数量统计如表4所示。

图5 电影知识图谱的可视化

图6 电影知识图谱实体关系图 (部分)
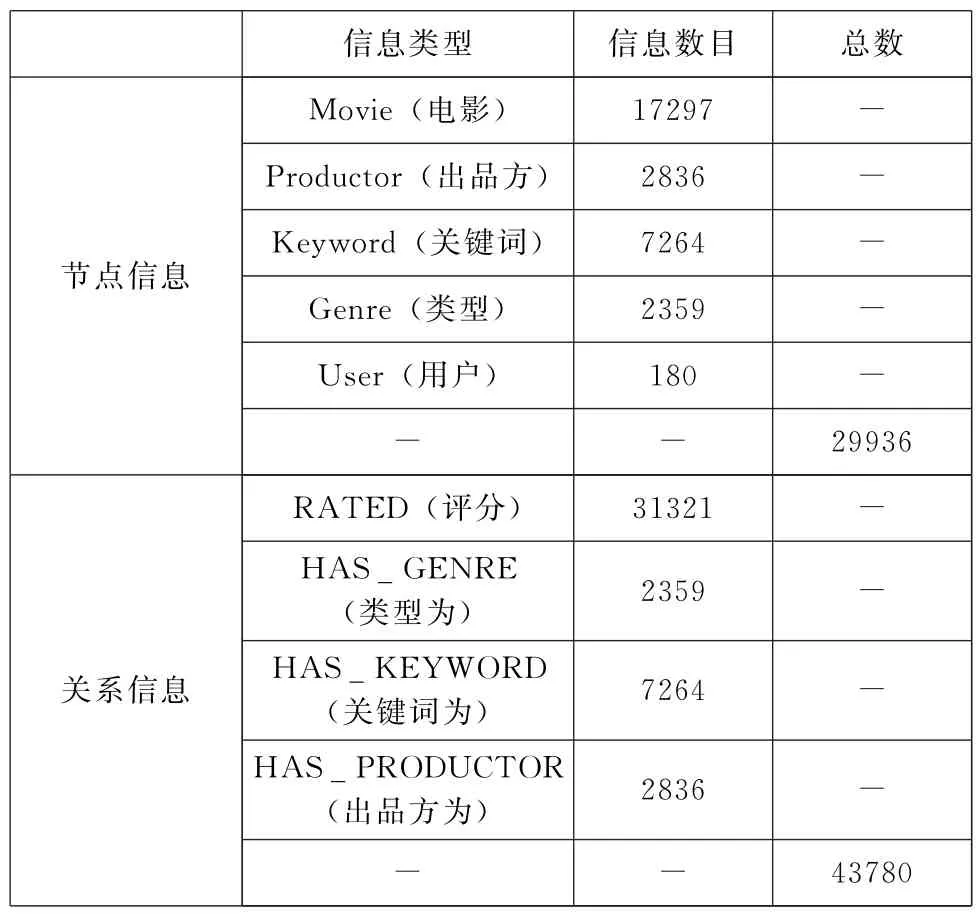
表4 节点与关系数量统计表
5 基于知识图谱进行电影推荐
知识图谱构建完毕后,依据知识图谱 (图6)存储的内容,可以提炼出节点实体间不同语义的路径。根据关系路径推断出目标用户对电影的喜好关系,初步找到可能被其喜欢的电影集合M。再基于知识图谱,以电影集合M中的每部电影为桥梁找到目标用户的关联用户 (例如用户1和用户2)。

接着计算用户之间的相似度,从关联用户中找到相似用户,将相似用户对于电影集合M中平均评分高的电影筛选出来,推荐给目标用户,从而使推荐结果更准确。
5.1 获取电影集合M
本文以用户134和电影(《夜鹰》)的喜好关系为例,从我们已经构建好的知识图谱中可以抽取出以下路径 (图7):

图7 语义推理路径 (1)
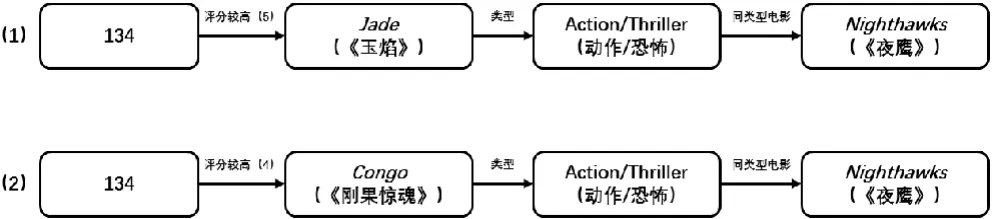
捕捉到的路径 (1)(2)描述的是同类型电影间的特征关系,由此可以推断出用户134可能会喜欢的电影是(《夜鹰》)。
从我们已经构建好的知识图谱中还可以抽取出以下路径 (图8):
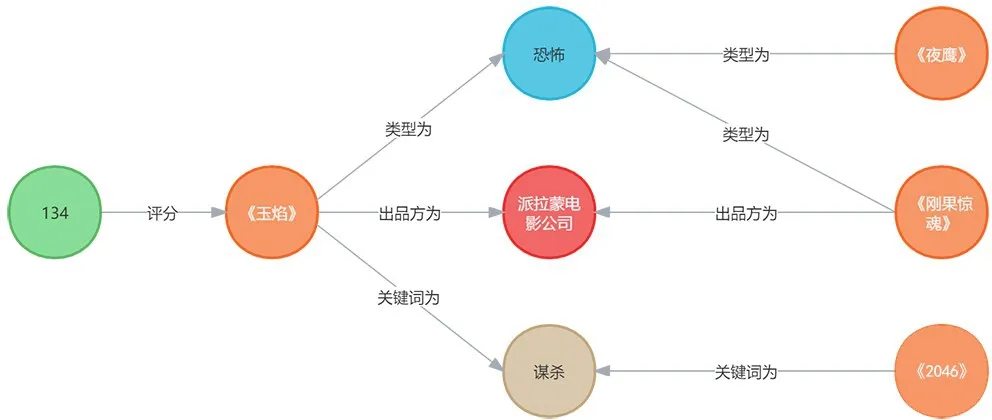
图8 语义推理路径 (2)

捕捉到的路径 (3)(4)(5)描述的是从用户134喜欢看的电影(《玉焰》)的各种属性信息出发,检索出具有相同属性信息的其他电影。通过多种语义路径得到类型丰富多样的电影集合M(部分)如表5所示:
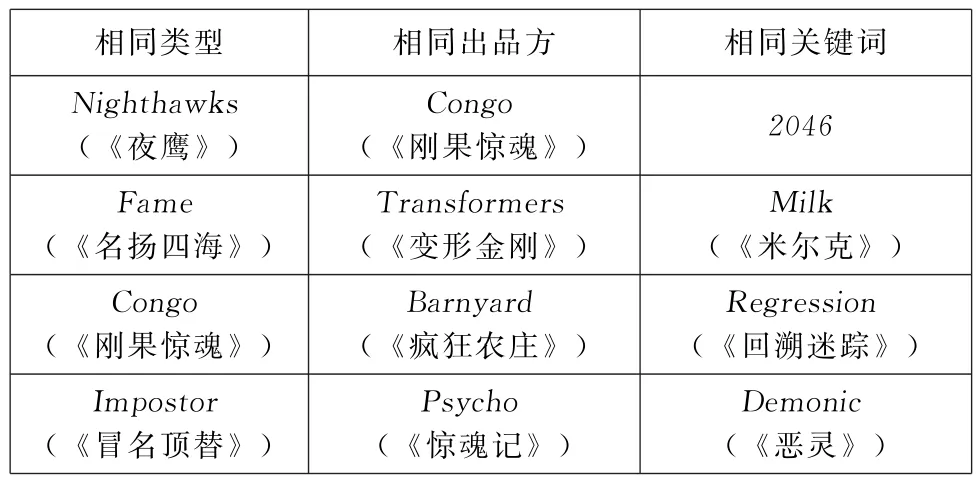
表5 基于知识图谱找到的电影集合M(部分)
5.2 基于相似用户进行电影筛选
使用余弦相似度计算关联用户间的相似度,将用户评分记为向量,筛选出相似用户 (设定阈值,相似度大于90%则认为相似),生成相似用户的知识图谱SI MILARITY(图9)。
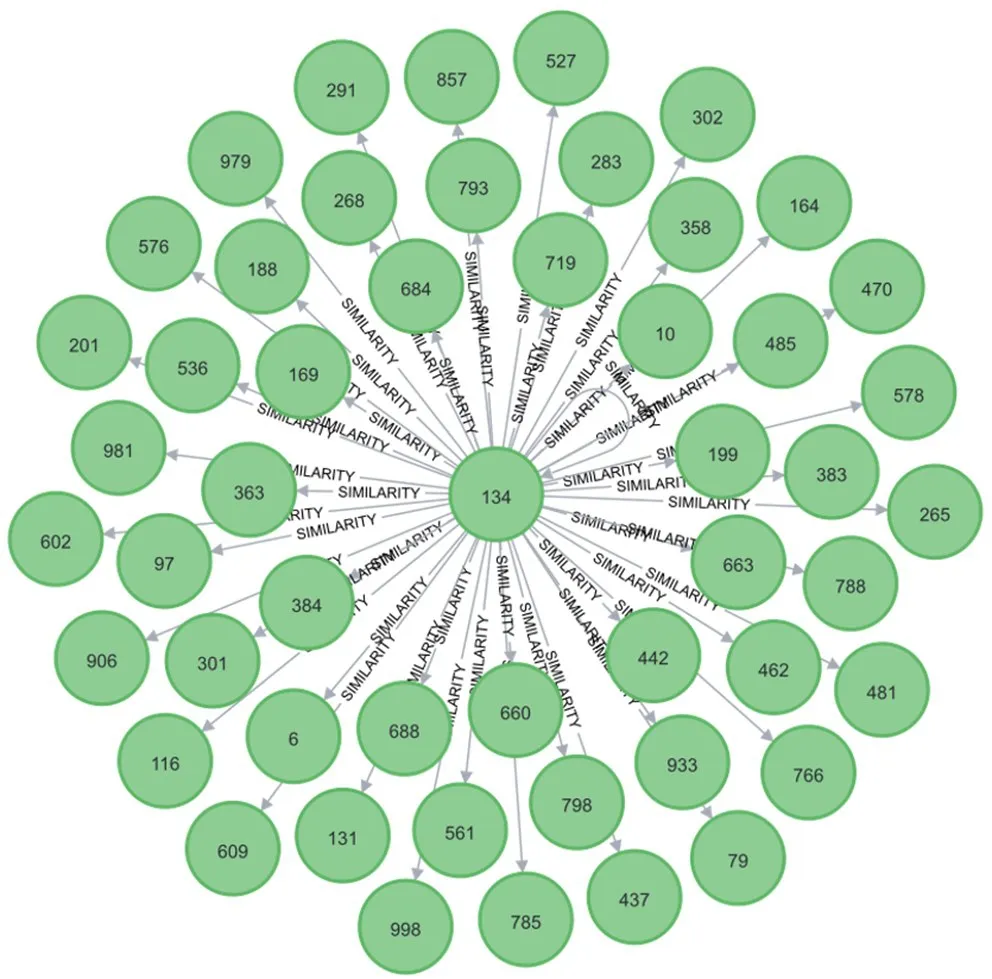
图9 相似用户知识图谱SI MIL ARITY
依次检索电影集合M中的每部电影,统计当前电影与SI MILARITY中每个实体 (用户)间关系的值 (评分),缺少关系数据则忽略,计算每部电影的平均评分,降序排列后按顺序为其推荐。最终为用户134推荐的电影结果如表6所示。

表6 用户134推荐结果 (基于相似用户推荐)
6 结语
本文以T MDB电影数据集和Netflix Prize电影评分数据集为例,构建了电影知识图谱,基于Neo4j图数据库实现了知识的存储,并依据知识图谱进行电影推荐,解决了传统电影推荐算法面临的一些难题。推荐结果也更加精准多样,同时具有很好的可解释性。而基于知识图谱的电影推荐系统为电影推荐技术的发展开拓了新思路。知识图谱应用是一个较新的领域,本文做了一些探索。下一阶段的研究重点将放在改进电影推荐算法上,尝试解决推荐系统中常见的流行度—机会偏差 (Popularity-Opportunity Bias)问题,使推荐结果更精准,力求在电影推荐领域做出更多的贡献。
①冷启动问题,如何在没有大量用户行为数据的情况下进行有效推荐的问题。
②RDF,即资源描述框架。RDF以三元组形式存储数据且不包含属性信息。
猜你喜欢
电影文学(2016年16期)2016-10-22
电影文学(2016年16期)2016-10-22
电影文学(2016年16期)2016-10-22
电影文学(2016年9期)2016-05-17
电影文学(2016年9期)2016-05-17
电影文学(2016年9期)2016-05-17
电影文学(2016年9期)2016-05-17
电影文学(2016年9期)2016-05-17
电影文学(2016年9期)2016-05-17
电影文学(2016年9期)2016-05-17
