
认知边缘计算网络中的计算能效优化方案
2022-03-21 02:25刘伯阳郭天润宋佳佳万奕尧
西安邮电大学学报 2022年5期
刘伯阳,郭天润,宋佳佳,李 政,万奕尧
(西安邮电大学 通信与信息工程学院,陕西 西安 710121)
移动边缘计算(Mobile Edge Computing,MEC)技术的核心思想是MEC用户将复杂度高且处理时延低的业务数据卸载至位于网络边缘的MEC服务器,MEC服务器计算结束后将结果返回[1-2]。因此,可用的无线频谱资源是MEC网络能够正常工作的关键因素之一。
当前无线设备数量已达千亿级别,而适合无线通信的频谱资源却非常有限。采用的固态频谱分配策略几乎已经将所有适合通信的频谱分给不同的授权用户,即主用户(Primary User,PU),每个授权频段只允许PU专用,其他非授权用户,即次用户(Secondary User,SU)即使在PU频谱空闲时也不能接入PU频段,这将造成频谱资源的严重浪费。开放的公共频段,如工业、科学和医学(Industrial,Scientic and Medical,ISM)频段在用户设备密集的区域将变得非常拥塞,导致传输速率低,严重影响用户体验[3-5]。
针对目前频谱资源分配方式造成的频谱资源紧张与开放公共频段拥塞问题,提出了认知无线电(Cognitive Radio,CR),其是一种动态频谱共享技术。CR网络允许SU根据PU状态调整自身发送功率,在对PU造成的干扰小于一定干扰容限的前提下接入PU频谱[6-7]。CR可有效提升网络频谱效率,若将其引入MEC网络,则可为MEC网络中缺乏频谱接入机会的用户提供频谱接入机会。
关于CR-MEC网络架构的研究已得到国内外研究者的关注。利用CR与非正交多址接入(Non-Orthogonal Multiple Access,NOMA)技术提升了MEC网络中的频谱效率[8]。文献[9]考虑了一种合作式CR-MEC架构,其中SU协助PU进行数据发送,在PU发送结束后SU获得频谱接入机会,接入频谱进行任务卸载,其对该网络中的计算能效最大化问题进行了研究。在非合作式CR-MEC架构方面也进行了相关的研究,SU通过频谱感知技术对PU状态进行感知,在PU空闲时进行无线充能与任务卸载,在PU占用时SU降低发送功率进行任务卸载[10]。文献[11]采用无线充能与中继转发技术对CR-MEC中的SU能耗最小化问题进行了研究。同时,还研究了一个SU与多个PU的CR-MEC网络架构[12],通过对SU选择哪个PU信道进行频谱感知以及耗能进行优化设计,最大化SU能获得的长期期望计算量。以上关于CR-MEC网络的研究多为单PU单SU或单SU多PU场景,且只关心频谱利用率、SU能耗或计算任务量等单维度优化目标。
针对现有CR-MEC网络研究工作中优化目标维度单一的问题,拟提出一种SU任务计算效率最大化方案。该方案通过构建单PU多SU与多PU多SU网络架构,且利用CR提升频谱效率的同时对计算任务量与能耗进行综合考虑,研究CR-MEC网络中的SU计算效率最大化问题。在建立的CR-MEC网络系统模型的基础上,提出网络资源分配优化问题,采用Dinkelbach算法进行非凸问题转凸问题,并利用拉格朗日对偶等算法进行问题求解。最后,通过仿真分析验证所提算法的可行性。
1 系统模型
CR-MEC网络模型包括M个PU,K个SU以及一个搭载了MEC服务器的认知小基站,具体如图1所示。假设ΩM={1,2,…,M}与ΩK={1,2,…,K}分别表示PU与SU的集合。

图1 系统模型
考虑了单PU(M=1)与多PU(M>1)两种场景,具体时隙结构分别如图2和图3所示。

图2 M=1时隙结构

图3 M>1时隙结构
由图2可以看出,在M=1的场景下,认知小基站可对PU状态进行频谱感知。根据感知结果协调各SU采用时分多址(Time Division Multiple Access,TDMA)方式接入频谱,并将待计算任务上传至认知小基站进行计算。时隙总长度为T;β0表示频谱感知时间长度;βk,j(k∈ΩK,j∈{0,1})表示在感知结果为j时第k个SU接入频谱的时间长度,j=0表示感知结果为PU处于空闲状态,j=1表示感知结果为PU处于占用状态。为保证PU传输性能,采用固定检测概率即PU处于占用状态时能够正确检测的概率的能量检测机制,检测概率固定为Pd时,对应的虚警概率即PU处于空闲状态但检测结果为占用的概率[13],其表达式为
(1)
式中:κ表示认知小基站接收的PU信号信噪比;fs表示采样率;Q(·)为标准高斯分布变量的互补累积分布函数。
由图3可以看出,在M>1的场景下,若PU均工作在相同频段,则无法对每个PU进行频谱感知。若多个PU工作在多个频段相比于单PU场景,认知小基站必须决定多个SU分别接入哪个PU信道,并考虑其接入性能收益与代价,需要引入整数变量,构建非线性混合整数优化问题,此场景可作为后续研究内容。因此,考虑PU均工作在同一频段的场景,频谱感知技术不适用,SU仍采用TDMA方式进行频谱接入,但必须满足各PU干扰功率约束,时隙总长度仍记为T,βk(k∈ΩK)表示第k个SU接入频谱时长。
2 问题建模
2.1 多SU单PU场景问题建立
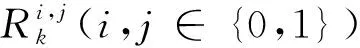
(2)
(3)
(4)
(5)


(6)
(7)

(8)
(9)
(10)
式中,hk,R表示第k个SU与PU接收机之间的信道功率增益。根据虚警概率与检测概率,可给出PU真实状态与感知结果的各种组合出现的概率,令αi,j(i,j∈{0,1})表示PU真实状态为i、感知结果为j出现的概率,具体表达式为
α0,0=P0[1-Pf(β0)]
(11)
α0,1=P0Pf(β0)
(12)
α1,0=P1(1-Pd)
(13)
α1,1=P1Pd
(14)
式中,P0与P1表示在PU处于空闲与占用状态的先验概率,可通过对PU的长期观测获得。根据上述概率,可知第k个SU被计算的平均计算比特数、平均能耗以及对PU造成的平均干扰的表达式分别为
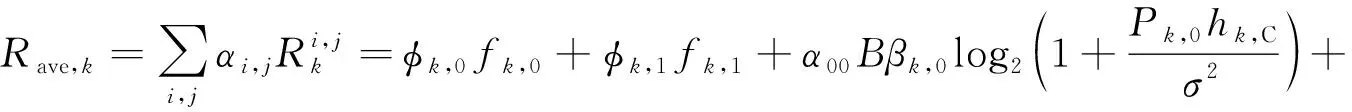
(15)
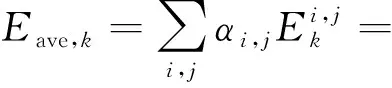
(16)
(17)
其中,
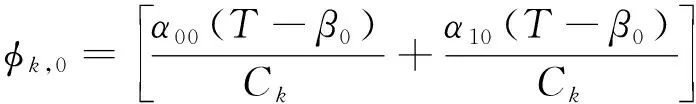
考虑SU的计算效率最大化问题,计算效率定义为
(18)
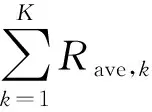
M=1场景的优化问题建立为
(19)

其中,
P=[P1,0,P1,1,P2,0,P2,1,…,PK,0,PK,1]
f=[f1,0,f1,1,f2,0,f2,1,…,fK,0,fK,1]
β=[β1,0,β1,1,β2,0,β2,1,…,βK,0,βK,1]
式中:ek、fk,max与Pk,max分别为第k个SU可用的能量、最大可用CPU频率以及最大发送功率;Ith为PU的干扰容限;Qk为第k个SU的需要完成的最小计算任务量;问题约束分别为能量因果性约束、PU干扰约束、SU发送时间长度约束、SU算力与发送功率约束及SU最小平均计算比特量约束。
2.2 多SU多PU场景问题建立
在M>1的场景中,各SU采用TDMA机制直接接入PU频谱,第k个SU能获得的计算比特量、能耗分别为
(20)
(21)
对第m个PU接收机造成的干扰为
Ik,m=pkhk,mβk
(22)
式中,hk,m为第k个SU与第m∈ΩM个PU的信道功率增益。
M>1场景优化问题建立为
(23)
Ik,m≤Ith,m
fk≥0,fk≤fk,max,0≤Pk≤Pk,max
Rk≥Qk

3 优化问题求解
3.1 多SU单PU场景
考虑目标函数为分式形式且约束变量存在耦合,问题P1为非凸问题。为对其进行求解,引入辅助变量{qk,z}k∈Ωk,z∈{0,1},使得qk,0=Pk,0βk,0与qk,1=Pk,1βk,1,从而消除了变量耦合,目标函数可以转化为
(24)
其中,

(25)
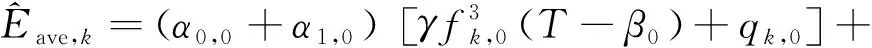
(26)
(27)
α10hk,Rqk,0+α11hk,Rqk,1≤Ith
fk,j≥0,fk,j≤fk,max
qk,j≥0,qk,j≤Pk,maxβk,j
式中,q=[q1,0,q1,1,q2,0,q2,1,…,qK,0,qK,1]。问题P2为凸问题,可以用一些标准的凸优化工具如CVX求解。在不考虑问题求解时间限制的情况下,可以用求解效率较低但功能强大的凸优化工具包进行求解。但是,在实际应用中,需考虑问题求解的时间效率。基于此,提供一种适用于工程领域的拉格朗日对偶算法对上述问题进行快速迭代求解。
问题P2的拉格朗日函数为

(28)
式中,z=[λ,μ,ο,ρ,υ],λ,μ,ο,ρ,υ为对偶矩阵,其分别表示为
λ=[λ1,0,λ1,1,λ2,0,λ2,1,…,λK,0,λK,1]
μ=[μ1,μ2,…,μK]
ο=[o0,o1]
ρ=[ρ1,0,ρ1,1,ρ2,0,ρ2,1,…,ρK,0,ρK,1]
υ=[υ1,υ2,…,υK]
问题P2的对偶函数为
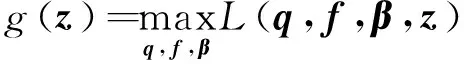
(29)
s.t.fk,j≥0,fk,j≤fk,max
qk,j≥0,qk,j≤Pk,maxβk,j
利用对偶分解理论,对偶函数求解可分解为多个子问题,具体如下。对于变量fk,0,对应子问题为
(30)
s.t. 0≤fk,0≤fk,max
其中,θ1,k=η(α0,0+α1,0)(T-β0)γ+λk,0(T-β0)γ。该问题为凸问题,利用KKT(Karush-Kuhn-Tucker)条件[15]可得其最优解为
(31)
对于变量fk,1,对应子问题为
(32)
s.t. 0≤fk,1≤fk,max
θ2,k=η(α0,1+α1,1)(T-β0)γ+λk,1(T-β0)γ
同理,用KKT条件[15]可得
(33)
对于变量βk,0与qk,0,对应子问题为

(34)
s.t.qk,0≥0,βk,0≥0
θ3,k=η(α0,0+α1,0)+λk,0+μkα10hk,R+ρk,0
该问题为凸问题,可以用分块迭代算法求解,首先初始化βk,0为一可行解,问题变为

(35)
s.t.qk,0≥0
通过KKT条件在给定βk,0的条件下,qk,0最优解为
(36)
其中,
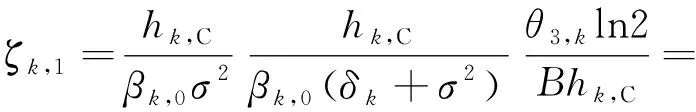
(37)
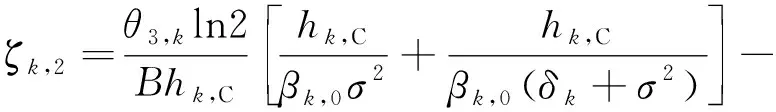
(38)
(39)
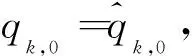

(40)
s.t.βk,0≥0
令Ψ(βk,0)表示该问题目标函数,即
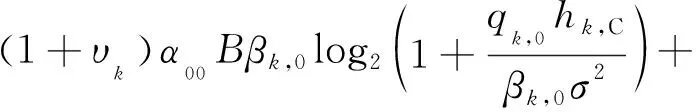
(41)
Ψ(βk,0)一阶导数与二阶导数分别为

(42)

(43)
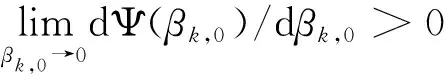


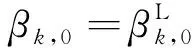

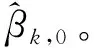

对于变量βk,1与qk,1,对应子问题为

(44)
s.t.βk,1≥0,qk,1≥0
θ4,k=[η(α0,1+α1,1)+λk,1+μkα11hk,R+ρk,1]
此问题可完全采用子问题P5,k的解法进行求解。
各子问题求解后,需求解问题P2的对偶问题,对偶问题为

(45)
s.t.z0
由于满足Salter条件[14],对偶问题式(45)最优值与原始问题最优值P2相同。
可采用次梯度法对对偶问题进行求解,优化对偶变量,针对对偶变量λk,0、λk,1、μk、ο0、ο1、ρk,0、ρk,1以及υk次梯度分别为
(46)

(47)
∇μk=Ith-α10hk,Rqk,0-α11hk,Rqk,1
(48)
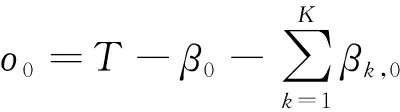
(49)

(50)
∇ρk,0=Pk,maxβk,0-qk,0
(51)

(52)
在给定η的情况下,问题P2得到求解后,需更新η取值,重复上述求解过程,直至算法收敛,具体算法步骤如下。
步骤1对参数η和最大迭代次数进行初始化。
步骤2求解问题P2并更新η,表达式为
(53)
步骤3判断当前的最优解是否到达目标,或是否达到最大迭代次数:若达到,则转至步骤4;否则,对其迭代次数加1并转至步骤2。
步骤4通过步骤3得到问题P2的最优解。
3.2 多SU多PU场景
与M=1场景相似,引入辅助变量uk=Pkβk与ϑ,同时利用Dinkelbach算法,目标函数变为
(54)
给定ϑ后,优化问题Q2变为
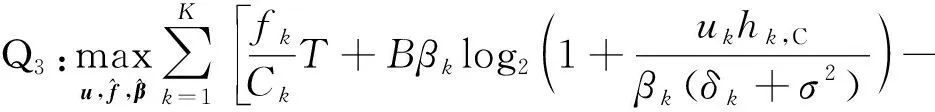
(55)
fk≥0,fk≤fk,max,uk≥0
uk≤Pk,maxβk
式中,u=[u1,u2,…,uK]。该问题求解过程与P2相似,可直接采用问题P2的求解方法进行求解,限于篇幅,不再给出具体求解过程。
4 实验结果及分析
4.1 仿真的环境和参数设置

表1 仿真参数
4.2仿真结果分析
归一化的Dinkelbach迭代算法收敛性能如图4所示。由图4可以看出,采用的Dinkelbach算法具备优良的收敛性能,能在较少的迭代次数之内达到收敛,使得算法复杂度较低,且PU用户数与算法收敛速度之间并无直接关系。

图4 Dinkelbach算法收敛性能对比
M=1场景下信道衰减指数α与Qk对计算效率的影响如图5所示。α越大,SU与认知小基站之间的链路质量越差,为了满足最低的计算任务量需求,SU需要花费更多的能量,从而导致计算效率的降低。同样,Qk越大,SU需要耗费更多的能量以提升计算任务量,使得计算效率降低。
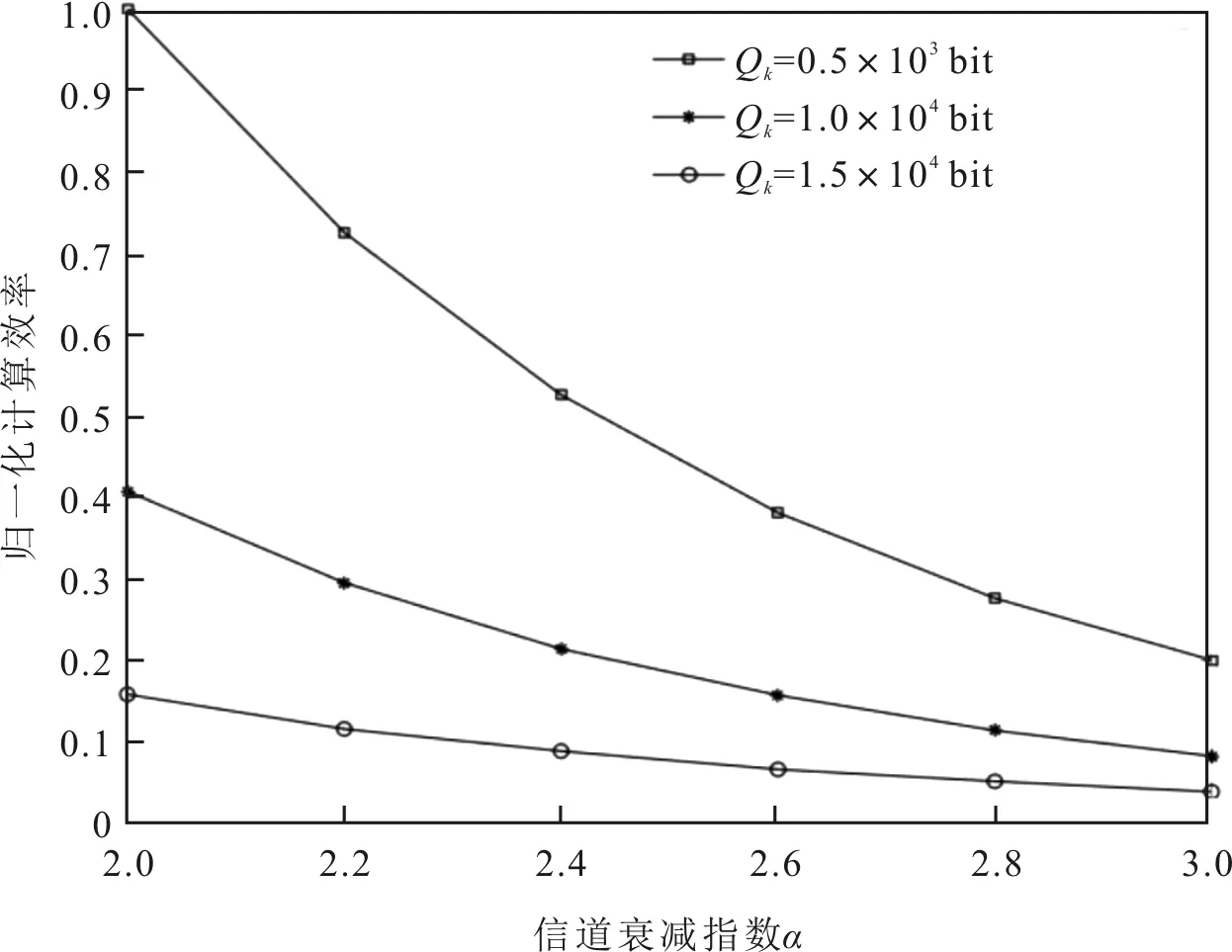
图5 信道衰减指数α与任务最小计算量Qk对计算效率的影响
M>1多PU场景下PU用户数M与Qk对计算效率的影响如图6所示。
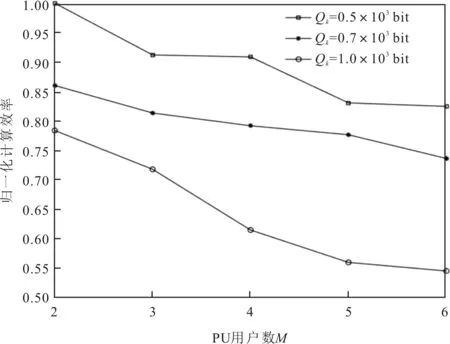
图6 PU用户数M与Qk对计算效率的影响
由图6可以看出,M越大,PU对各SU的干扰就越大。同时,当PU数量越多时,SU需要满足的PU干扰功率约束个数就越多,对SU的计算效率的影响也就越大。与单PU场景相似,Qk增大,各SU需要消耗更多的能量,从而导致计算效率下降。
M>1多PU场景下时隙长度T与信道衰减指数α对计算效率的影响如图7所示。时隙长度T越长,各SU可使用的计算与任务卸载的时间长度越长。SU能耗与计算任务量之间为非线性关系,其CPU频率与卸载功率降低最终可使计算效率降低。与图5相似,在多PU场景中信道衰减指数α的增加使各SU与认知小基站之间信道质量下降,导致计算效率降低。

图7 时隙长度T与信道衰减指数α对计算效率的影响
5 结语
由于目前CR-MEC网络中优化目标维度单一,因此针对单PU多SU与多PU多SU的CR-MEC网络资源分配问题,提出了CR-MEC网络的SU计算效率最大化的系统优化方案。所提方案利用Dinkelbach算法、变量替换与拉格朗日对偶算法对所建立的CR-MEC网络SU计算效率最大化问题进行求解,再对各个SU的CPU计算频率、发送功率以及接入频谱的时隙长度等参数进行联合优化设计。通过对所提方案在信道衰减指数、SU任务最小计算量、PU用户数以及时隙长度等参数下进行验证。验证结果表明,Dinkelbach算法能在较少的迭代次数之内达到收敛,证明所提具备优良的收敛性能且复杂度较低。同时,计算效率随着信道衰减指数、SU任务最小计算量和PU用户数的增大而减小,随着时隙长度的增大而增大。以上分析结果表明,所提方案性能合理,可解释,符合预期。
猜你喜欢
空间科学学报(2021年6期)2021-03-09
舰船电子对抗(2020年2期)2020-06-23
数学物理学报(2019年6期)2020-01-13
中学数学教学(2018年6期)2018-12-22
测控技术(2018年7期)2018-12-09
铁道通信信号(2018年9期)2018-11-10
舰船电子对抗(2016年3期)2016-12-13
广西大学学报(自然科学版)(2016年5期)2016-11-12
应用数学与计算数学学报(2015年1期)2015-07-20
电子设计工程(2014年19期)2014-02-27
