
宽速域下神经网络对雷诺应力各向异性张量的预测1)
2022-03-20 15:52:34任海杰袁先旭陈坚强朱林阳向星皓
力学学报 2022年2期
任海杰 袁先旭, 陈坚强, 孙 东 朱林阳 向星皓,
* (空气动力学国家重点实验室,四川绵阳 621000)
† (中国空气动力研究与发展中心计算空气动力研究所,四川绵阳 621000)
引言
湍流模型是为了封闭Navier-Stokes (N-S)方程中的雷诺应力项而额外补充的方程,主要目的是构建时均流动、空间位置与雷诺应力张量或湍流涡粘之间的数学关系式[1].雷诺平均(Reynolds averaged Navier-Stokes,RANS)方程是当前湍流研究中使用最广泛的模型之一.RANS 框架的核心是确定流场的平均量,并针对脉动量对于平均场本身的影响进行建模;而脉动场则是通过雷诺应力张量的散度嵌入到RANS 方程中,RANS 模型正是需要对此张量进行建模[2].最早的有效黏度假设由Boussinesq 提出,该假设也是使用最为广泛的有效黏度假设,通常使用的两方程RANS 模型(例如k-ε,k-ω 模型)通过Boussinesq 涡黏假设完成雷诺应力的封闭.但Tracey 等[3]指出湍流涡黏模型的主要误差来源是无法解释雷诺应力的各向异性,即Boussinesq 涡黏假设认为湍流黏性系数是各向同性的标量.此外,有诸多学者根据推导出的雷诺应力输运方程进行求解,例如雷诺应力方程模型(RSM),闫超等[4]指出RSM 存在雷诺应力方程的建模困难、数值刚性问题较严重、计算量较大的问题.不同于RSM 的思路,Pope[5]针对各向异性提出了新的有效黏度假设.该假设的有效性已经得到了充分的验证[6],但由于其在N-S 求解器中较差的鲁棒性,并未得到广泛应用.这也意味着研究者往往需要从DNS,LES 等高分辨率数据中获得更加准确的雷诺应力各向异性张量.
随着机器学习方法的不断发展,在雷诺应力的封闭中结合机器学习的研究方法日益增加.主要的研究方向分为两种[7]:采用机器学习方法缩小RANS解与高精度数据或实验值的偏差;或是基于高精度数据或实验值直接构建某些湍流变量的代理模型.缩小偏差的方法既可以是改变模型的控制方程形式,也可以构建针对RANS 模型偏差函数进行叠加修正.代表性工作包括Tracey 等[8]构建了替代SA 模型控制方程中源项的神经网络模型;Wu 等[9]针对RANS 模型计算结果和高分辨率DNS 数据之间的雷诺应力偏差进行建模,提高了原有模型的准确性.相比于缩小偏差的方法,直接构建代理模型的方法同样颇具亮点.Zhu 等[10-11]通过径向基函数神经网络以及深度神经网络构建了涡黏系数νt 与平均流动变量之间的映射关系,并将得到的映射关系与N-S求解器耦合用于封闭湍流模型.而Ling 等[12]针对张量不变性分别在随机森林和神经网络中进行了测试.随机森林作为决策树的集合,是将多个决策树的预测组合成一个模型,其结构并不像神经网络一样容易改变,难以将Pope 的本构关系嵌入到随机森林中.而神经网络由于体系结构的灵活性在张量不变性的处理上别具优势.为了在RANS 模型的基础上,利用机器学习方法提高雷诺应力各向异性的计算精度,Ling 等[7]采用具有伽利略不变性的输入特征并提出张量基神经网络(TBNN)架构.诸多成果表明机器学习方法在湍流模型化工作中具有良好的前景[13].
对于TBNN,Ling 等[7]使用TBNN 预测了低速的管流、周期山流动.Fang 等[2]针对槽道流提出了新的神经网络模型,使其在低速槽道流的预测效果优于TBNN.而该研究也指出,其新的神经网络未能嵌入旋转不变性,且仅适用于特定流动.张珍等[14]也将TBNN 与一个预测涡黏系数的神经网络嵌入到了RANS 求解器中,并对低速周期山流动进行了预测,提升了RANS 求解的精度.由于TBNN 基于Pope的有效黏度假设构建,而该假设是Pope 针对绝大部分不可压缩流提出的,因此TBNN 的研究工作往往集中在低速的领域.
本文在蒙特利尔大学和谷歌开发的Theano 深度学习框架(https://pypi.org/project/Theano/)上完成了神经网络的编译.以Pope[5]修正的有效黏度模型作为理论基础,并基于Ling 等[7]搭建的TBNN 内核构建了神经网络模型.本文通过TBNN 构建了从雷诺平均方程(RANS)湍流模型的湍动能、湍流耗散率和速度梯度到高精度数值解的雷诺应力各向异性张量的映射.除了对低速槽道流、低速NACA0012翼型进行了预测以外,还将TBNN 的应用范围从低速拓展到了高超声速,较精确地预测了马赫6 的平板边界层的雷诺应力各向异性张量,并通过一组低速平板进行了模型泛化能力的进一步验证.验证了TBNN 在宽速域流动下对雷诺应力各向异性的预测能力.对于本文涉及的3 个TBNN 模型,经由槽道流训练得的模型标记为TBNN-C,翼型对应模型为TBNN-N,高超声速平板对应模型为TBNN-H.
1 计算方法
1.1 有效黏度假设
时均形式的N-S 方程为

主应力和切应力的不同取决于坐标系的选择,而根据雷诺应力内在的差别可以将其区分为各向同性和各向异性

式中 kδij为各向同性张量,aij为各向异性张量.
为封闭RANS 方程,需要给出雷诺应力与平均流场间的关系,这一封闭的过程可基于有效黏度假设完成.最早的有效黏度假设由Boussinesq 提出,该假设也是使用最为广泛的有效黏度假设.基于该假设,雷诺应力可被定义为
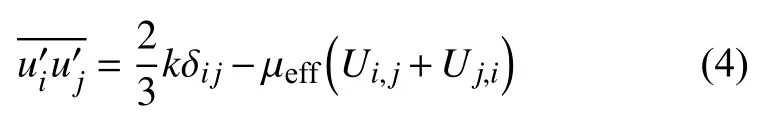
式中k 为湍动能,δij为克罗内克符号,μeff为有效黏度,Ui,j和Uj,i为速度梯度.发现Boussinesq 假设是基于各向同性假设的,这也使得该假设无法准确地捕捉各向异性.
为了更好的捕获雷诺应力各向异性张量,Pope[5]进一步修正了有效黏度模型.将各向异性张量通过湍动能进行归一化

Pope[5]根据Caley–Hamilton 理论推导了归一化的各向异性张量b 与基张量之间的本构关系的一般形式

式中 T(1),T(2),···,T(10)为基张量,λ1,λ2···,λ5为张量不变量,二者都是无量纲化后的张量S 和R 相关的函数.S 为平均应变率张量,R 为平均旋转率张量.不同于三维流场中的10 个基张量,该本构关系在二维流场中仅需要4 个基张量,具体表达为
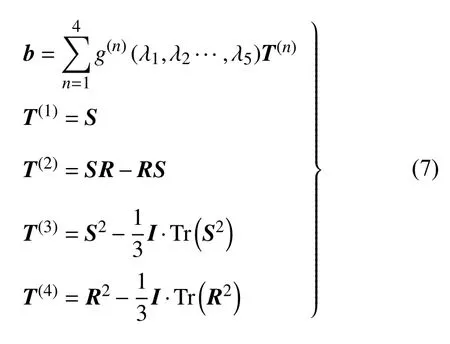
对于张量不变量的构造,Johnson[15]枚举了对称和反对称张量的7 个相关不变量:Tr(S),Tr(S2),Tr(S3),Tr(R2),Tr(R2S),Tr(R2S2)和Tr(R2SRS2).而Pope 将本构关系中的张量不变量确定为

无量纲化后的张量S 和R 表达式为

由于张量不变量和基张量的存在,任何满足该有效黏度模型的本构关系的张量b 都会自动满足伽利略不变性.
1.2 深度神经网络
全连接神经网络的大致结构如图1 所示.每一个圆圈代表神经元,其中包含两步计算:第一步为输入向量X 和权值向量W 及偏置b 的线性运算a=WX+b,第二步为激活函数y=h(a)的非线性运算.常用的激活函数h(x) 包括Tanh,Sigmoid,ReLU和阶跃函数等.本文沿用了TBNN 中采用了leaky ReLU 激活函数[6].

图1 深度神经网络结构Fig.1 Structure of deep neural network
通常采用带有梯度下降的反向传播方法来训练神经网络,本文选择了Adam 方法.该方法通过迭代调整神经网络中各节点的权重,从而在各向异性张量的预测值和真实值之间提供最低的均方误差,以使模型更适合训练数据.此外隐藏层的层数、每层的宽度也会显著影响神经网络的性能.神经网络的层数和节点数较多时能容纳更复杂的数据,但也容易造成过拟合.
1.3 张量基神经网络
TBNN 目标是确定式(6)中的g(n)(λ1,λ2,···,λ5)函数.一旦确定了函数,则可以使用公式(6)求解张量b.对于机器学习而言,将相同的流动在不同坐标系下的流场用于机器学习时,机器学习模型可能会产生不同的预测,因此在使用TBNN 时保证神经网络的伽利略不变性是必要的.
基于Pope 的有效黏度模型,将5 个张量不变量λ1,λ2,···,λ5作为TBNN 的输入变量,标量函数g(n)作为输出变量,从而避免在神经网络中引入张量运算,保证了其伽利略不变性.在完成了TBNN 模型的构建后,结合基张量进行式(7)的运算,即可得到归一化的雷诺应力各向异性张量b.TBNN 的结构图如图2 所示.
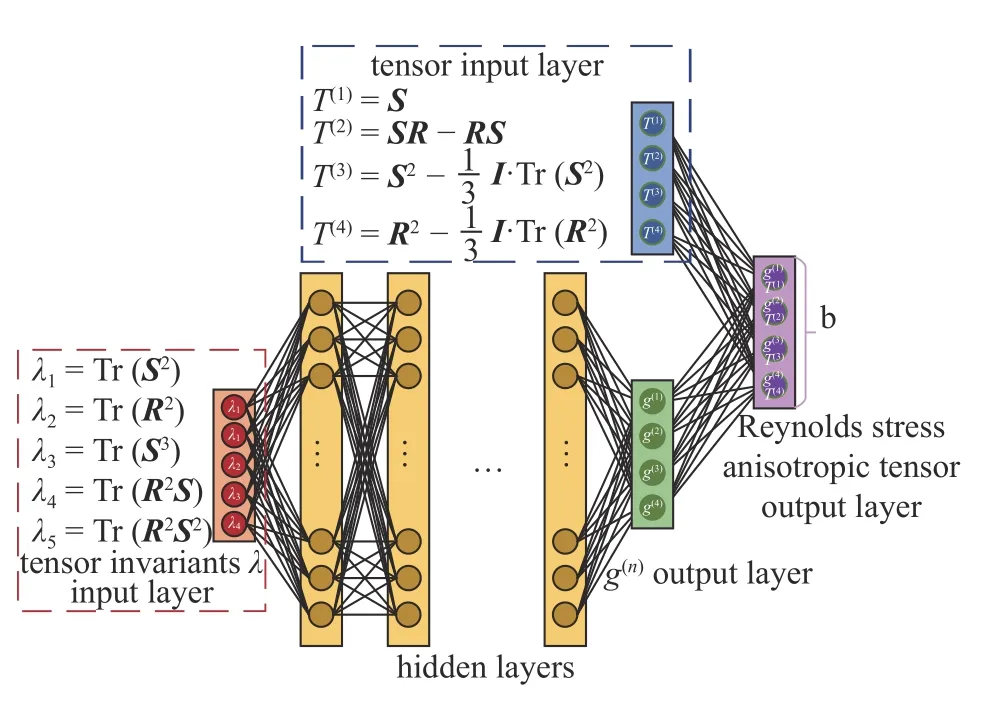
图2 张量基神经网络结构Fig.2 Structure of tensor basis neural network (TBNN)
此外为了衡量训练效果,引入均方根误差作为损失函数

学习率采用学习率衰减(learning rate decay),初始学习率为0.01,最小学习率为1 × 10-6.
并根据Banerjee 等[16]提出的湍流不变量与特征值方法的各向异性特性的表述,对b 和其特征值ξ1≥ξ2≥ξ3添加约束,从而对预测好的各向异性进行后处理

2 数据集
Ling 等[7]的工作对多种基础流动进行了研究,诸如管流(Reb=3500)、周期山流动等.张珍等[14]使用EVNN 和TBNN 的组合神经网络进一步研究了周期山流动.为了验证基于Pope 有效黏度模型的TBNN在宽速域和小样本的前提下的适用范围,本文选取了低速槽道流、低速翼型以及高超声速平板三类算例展开研究.由于获得的高精度数据均对应二维,本文采用翼型、槽道流以及高超平板的二维算例,以精确匹配高精度DNS 和LES 数据的二维工况.
针对低速工况,选择NACA0012 翼型以及槽道流作为研究算例.槽道流的DNS 数据来自Moser等[17-19],用于TBNN 训练的为Reτ=395 工况下湍流充分发展区域的一条截线上136 个点的流场数据,Reτ=590 工况对应的136 个点将作为外推的测试集验证TBNN 预测能力;针对Reτ=590,Krogstad 等[20]在风洞实验中通过热线风速仪测量了该工况的雷诺应力各向异性张量,相关实验中的18 个流场点可作为测试集的验证,与TBNN 预测结果和DNS 结果形成充分的对比,进一步衡量TBNN 预测能力.翼型来自Vinuesa 等[21-22]通过LES 求解的NACA0012 翼型,工况为Rec=4×105,AoA=0°,不可压缩.数据包含了流场上翼面的1800 个数据点,其中80%的点作为训练数据,余下20%的点将通过散点图和云图的形式对TBNN 的预测效果进行验证,对比测试中尚不包含实验结果.
高超声速流动涉及了强激波、强逆压梯度、强压缩效应等诸多因素[23],因此Pope[5]针对大部分不可压缩流动提出的本构关系在高超是否适用需要重新判断.本文选择一组Ma=6 的平板作为研究算例.该算例来自Sun 等[24]最新计算的高超声速平板,以边界层内的流场为研究对象,并于该平板上选取了8 条截线共计1540 个流场点进行研究,其中的6 条截线用于训练,相关DNS 计算方法[25]以及平板计算结果[24]见以下文章.而相较于低速槽道流的实验,高超声速工况下的雷诺应力难以使用热线风速仪进行测量.其它测量手段如纳米示踪平面激光散射技术(NPLS)[26]可以获得超声速、高超声速条件下的雷诺应力分布,但由于本文需要进行边界层内不同站位法向方向雷诺应力各向异性分量的定量对比,故仅采用DNS 计算结果与本文计算结果进行对照.
本文中用于TBNN 的训练集包含两部分.第一部分为RANS 求解所得结果,其中湍流模型采用k-ε,SST 模型进行求解.根据流场的湍动能、湍流耗散率和速度梯度构造无量纲化后的张量S 和R,进而计算出5 个张量不变量作为神经网络输入.第二部分为高精度的雷诺应力数据,经求解得雷诺应力各向异性张量,作为TBNN 的输出.在经过训练集完成训练后,便可运用TBNN 模型对筛选出的测试集进行预测.
在完成RANS 计算后,可基于RANS 求解结果并根据公式(12)对雷诺应力各向异性张量进行初步的反推[7]
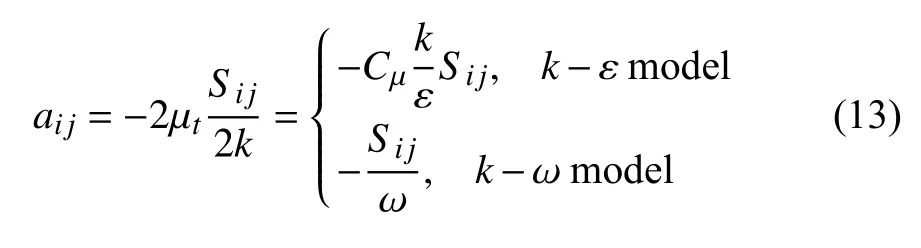
通过此式亦可对Boussinesq 涡黏假设在各向异性的预测能力进行初步的判断.
3 数值模拟结果
本文主要研究雷诺应力各向异性张量的预测,需要完成RANS 求解、训练集构建以及TBNN 的训练和预测.
3.1 低速槽道流
低速槽道流的RANS 计算由k-ε 模型完成.选择Reτ=395 的工况作为训练集,并将训练好的TBNN 模型命名为TBNN-C.将TBNN-C 用于Reτ=590 的工况进行外推算例的预测.开源的DNS 数据中[17-19]给出了完全发展后的一个截线,共有136 个流场点;两种工况在RANS 计算的网格细节如表1 所示.
表1 中Lx为计算域在x 方向的长度,δ 为槽道的半高,Ly=2δ 为y 方向的长度.Δx+为x 方向两个网格点的距离差,Δyc+为y 方向中心位置两个网格点的距离差.此处针对RANS 所用网格的进行了网格无关性验证.在确保了网格不会对求解精度造成影响后,选取其中湍流充分发展的位置作截线,与DNS 数据中的流场点进行匹配.由于槽道流的对称性,只取下半部分作为研究对象,网格尺寸为1024 ×257.在保证RANS 求解的速度型与DNS 相近之后,将RANS 求得的速度梯度、湍动能和湍流耗散率以及DNS 中的雷诺应力张量输入到TBNN-C 中.隐藏层的层数分别设置为2,4 和6 层并对训练结果的均方根误差进行对比,最终选择6 层,每层20 个节点.

表1 槽道流RANS 计算的网格信息Table 1 Mesh information for channel flow in RANS
该工况的实验由Krogstad 等[20]在回流式风洞中完成,通过两个平行的光滑平板形成了槽道,试验段长5 m,入口面积1.35 m × 0.10 m,通过热线风速仪测量速度脉动,从而获得雷诺应力.图3 为Reτ=590 的工况下,雷诺主应力的各分量随着y+的变化.y+的计算公式如式(14) 所示,其中 uτ为摩擦速度(即湍流壁面附近的黏性速度量级),v 为运动黏度

图3 Reτ=590 雷诺应力各向异性分量随y+值的分布Fig.3 Reynolds normal stress anisotropy components vs y + at Reτ=590

区别于雷诺应力张量,从图3 结果我们可以发现,TBNN-C 的预测结果在y+较小的区域(即y+<5的黏性子层区域)有较大偏离,但在过渡子层以及完全湍流区域TBNN-C 的预测效果与DNS 以及风洞实验的结果相近,预测效果良好,能够揭示雷诺正应力的各向异性部分在槽道流中的发展规律.在y+>5的范围内,TBNN-C 预测的bii与DNS 结果的整体误差仅有10%左右,与实验相同点位上TBNN-C 的预测误差均不超过10%;而与TBNN 相比,RANS 的预测结果存在量级上的差异,也说明了基于Boussinesq涡黏假设的湍流k-ε 湍流模型无法准确捕捉雷诺应力各向异性张量.
此外,针对槽道流的TBNN-C 模型仅根据Reτ=395 的136 个流场点进行训练,在样本极小的情况下,训练完成的TBNN-C 模型针对Reτ=590 的不同流场外推预测依旧展现出极佳的泛化能力.这也说明对于槽道流这种外形简单的研究对象,Pope[5]提出的本构关系能够充分诠释其流动机理,从而极大的提升了TBNN 模型的泛化能力.
3.2 低速NACA0012 翼型
本文所研究的NACA 翼型为NACA0012.由于NACA0012 在零度攻角下的对称性,仅研究其上翼面.大涡模拟方法(LES)作为研究复杂湍流问题的重要工具,其求解结果拥有较高的精度[27-28],可作为神经网络的训练标签.在开源的LES 数据中,共有1800 个流场点[21-22],皆位于机翼上翼面近壁区.翼型RANS 计算选择的湍流模型为SST 模型.在完成RANS 计算后,将其中的流场点提取并与LES 流场点一一匹配.为验证RANS 计算精度,图4 中对比了RANS 解得的速度场云图以及LES 的1800 个数据点插值所得速度场云图,RANS 的计算结果能够初步的反映LES 结果中的速度变化趋势.

图4 RANS 与LES 的速度场对比Fig.4 Comparison of velocity field for RANS and LES
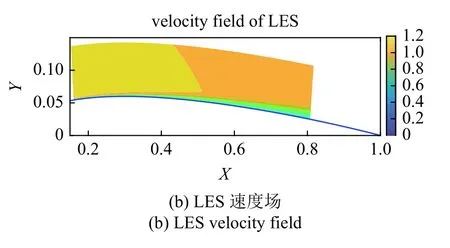
图4 RANS 与LES 的速度场对比(续)Fig.4 Comparison of velocity field for RANS and LES (continued)
在LES 数据中选择1440 个流场点作为训练集对TBNN 进行训练,训练完成后的TBNN 模型命名为TBNN-N.将额外的360 个流场点作为测试集输入到TBNN-N 模型中,检验神经网络对于翼型的预测效果.测试集测点分布如图5 所示.

图5 NACA0012 测试集流场点分布Fig.5 Distribution of NACA0012 test data set
在对隐藏层的层数进行了测试后,选择三层隐藏层,每层20 个节点进行训练.训练步数为8000 步,最终训练完成时训练集的均方根误差为0.052,训练的样本数为1440,样本数量较小.图6 和图7 给出了测试集的360 个流场点的各向异性分量b11,b22的分布,并选取关键区域的流场点插值绘制云图.插值方法为Matlab 中的V4 双调和样条插值(biharmonic spline interpolation).

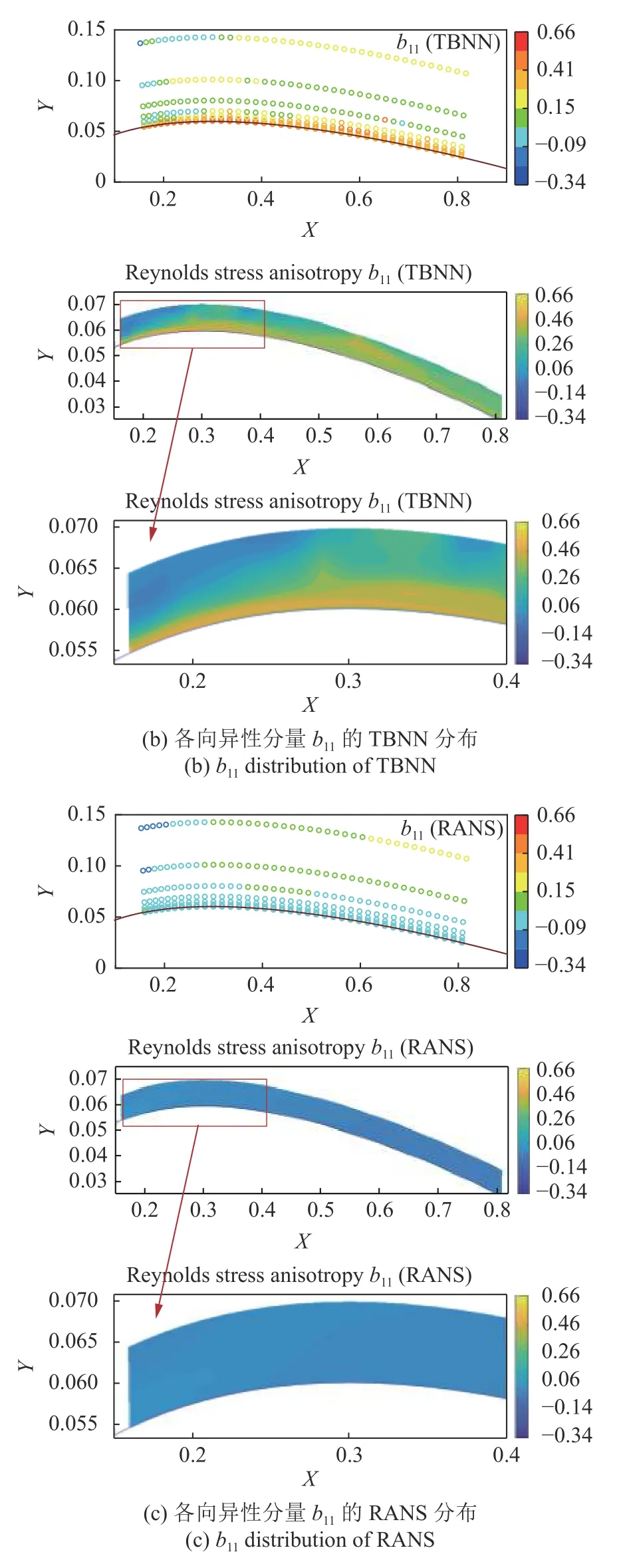
图6 雷诺正应力各向异性分量b11 结果Fig.6 The result of Reynolds normal stress anisotropy component b11

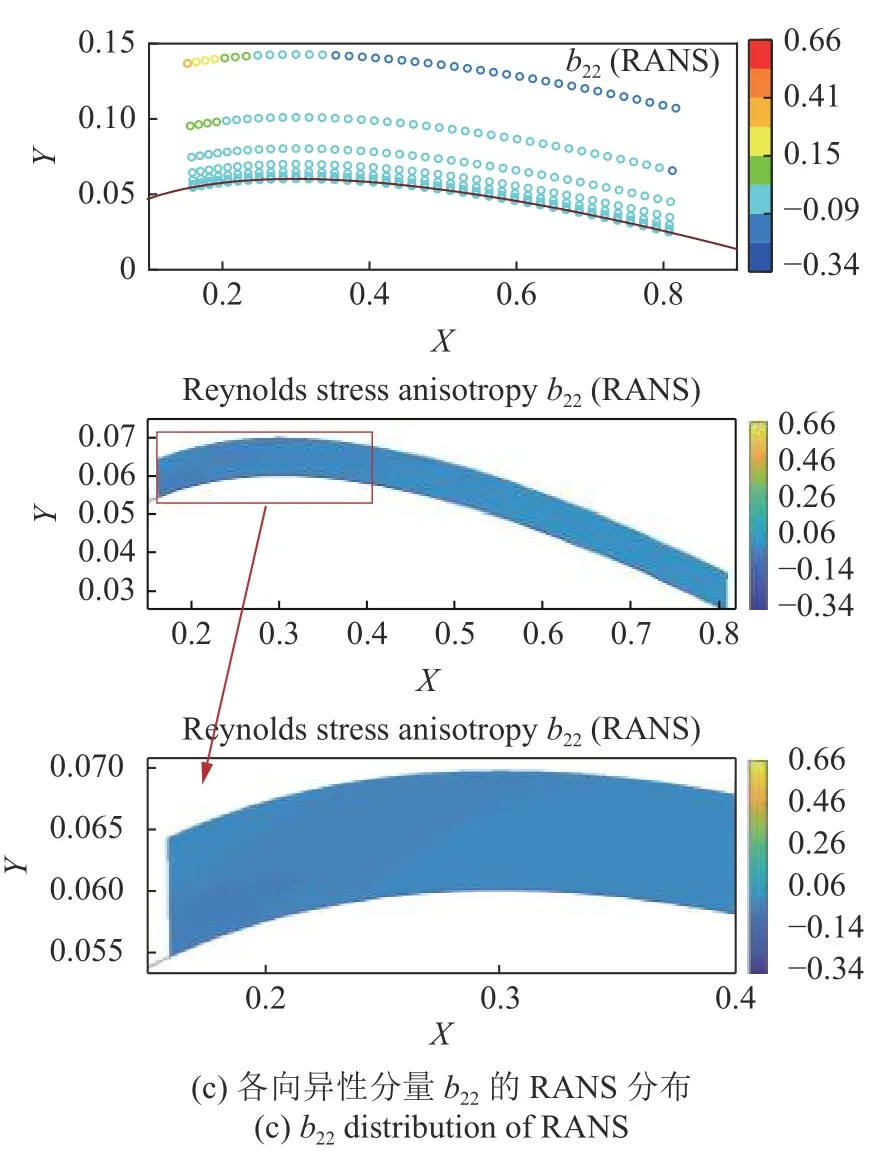
图7 归一化雷诺正应力各向异性分量b22 云图分布Fig.7 The result of normalized Reynolds normal stress anisotropy component b22
对于NACA0012 翼型,基于RANS 求解的平均速度场几乎完全无法捕捉雷诺应力各向异性分量,而基于RANS 结果预测的TBNN-N 各向异性分布在个别流场点的预测较差,但在重点关注区域TBNN-N 能够较好地预测雷诺应力各向异性.同样在低速工况下,TBNN-N 针对翼型的预测相比于槽道流精度有所下降,但在小样本的前提下TBNNN 取得的预测效果尚可接受,较RANS 结果显著提升.要对翼型进行精准预测,可考虑进一步扩大样本范围,以提升TBNN 的预测精度.
3.3 高超声速平板
针对低速工况的模拟方法面对高超声速往往会产生不适用性[29-30],故通过高超声速平板来衡量TBNN 在高超声速下预测的精确度.当前所拥有的平板DNS 数据为二维算例[24],来流参数中马赫数为6,单位雷诺数为12 000,在湍流区域共有8 条截线.选取截线位置边界层内的数据用于本算例,其中B11 距平板前缘点51.68%处,各截线位置以及边界层厚度如图8 所示.
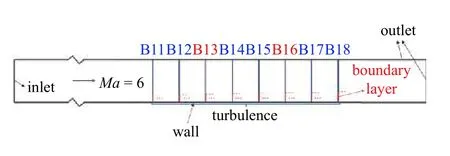
图8 平板DNS 数据各截线位置以及边界层厚度Fig.8 Position of transversals and boundary layer thickness of DNS data
在8 条截线中,选择B13 和B16 作为测试集,其余6 组截线数据作为训练集对TBNN 进行训练,训练完成后的模型命名为TBNN-H.训练集中共有1155 个流场点,用于预测的B13 和B16 截线分别有187 和199 个流场点.
高超声速平板的RANS 计算由Fluent 完成,使用可压缩k-ε 模型作为湍流模型.根据边界层厚度在RANS 结果中完成B11 到B18 的各截线位置的匹配.RANS 计算的网格尺寸为3869 × 320,在完成网格无关性验证后,保证相同站位RANS 与DNS 边界层厚度一致,对比结果如图9 所示.此外,如图9还给出了边界层内近壁区域的网格加密.
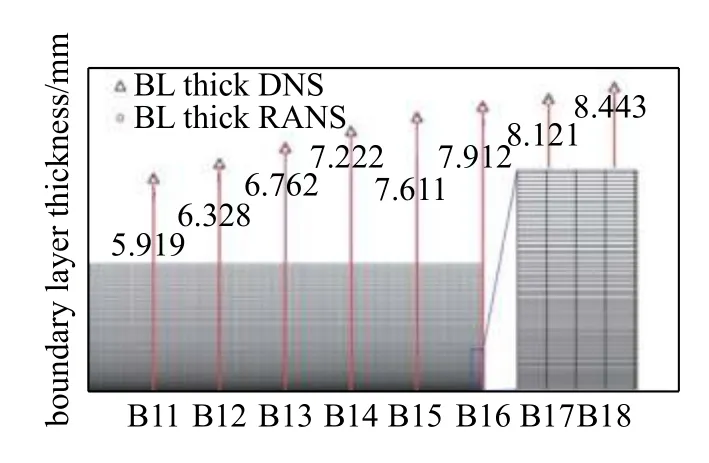
图9 Ma6 平板RANS 边界层网格以及边界层厚度Fig.9 The mesh for RANS and boundary layer thickness
根据DNS 计算结果,截线B13 的边界层厚度δ=6.77 mm,B16 的边界层厚度δ=7.91 mm.在边界层厚度相同的情况下,相比于DNS 计算结果,RANS的速度发展较慢.以此RANS 结果为基础的TBNN-H依旧取得了极佳的预测效果,如图10 和图11 所示.(由于流场点过多,进行数据点显示控制以美观曲线,每两个点显示一个点)

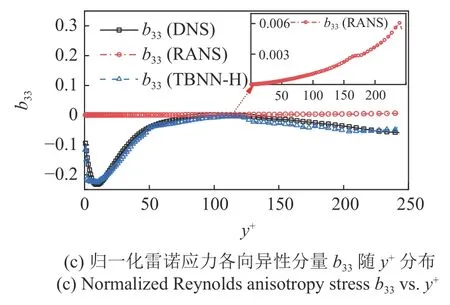
图10 截线B13 的雷诺主应力各向异性分量的分布Fig.10 Reynolds normal stress anisotropy components on transversals B13
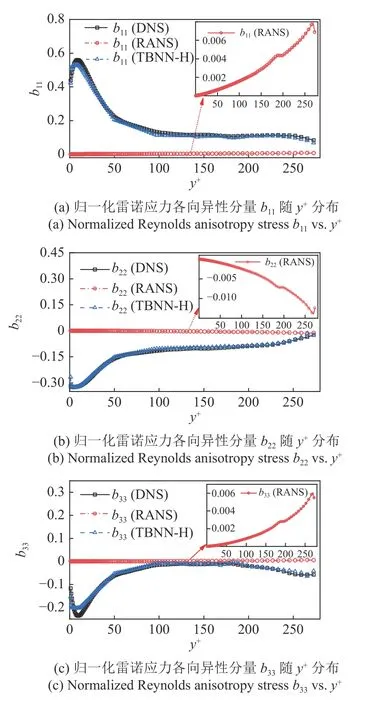
图11 截线B16 的雷诺主应力各向异性分量的分布Fig.11 Reynolds normal stress anisotropy components on transversals B16
针对高超平板的TBNN-H 使用了4 个隐藏层,每层18 个神经元.在训练完成后,训练集的均方根误差(root mean square error,RMSE)维持在0.01 左右,而训练好的TBNN-H 对于测试集的预测表现良好,RMSE 约为0.015 左右.从结果中可以发现,在y+较小的区域(即y+<5 的黏性子层区域)TBNN-H 的预测结果有一定偏离;与槽道流相同,TBNN-H 在过渡子层以及完全湍流区域TBNN-H 的预测效果与DNS 的结果相近,预测效果良好.这也说明了TBNN 的预测在一定程度上可能会受到k-ε 模型的固有限制,因此在湍流边界层的黏性子层的预测效果较差.
此外,从图10 和图11 的结果中我们可以发现TBNN-H 对于高超声速平板边界层依旧具有良好的预测能力,尽管Pope 的本构关系针对不可压缩流动提出,但基于该本构关系构造的TBNN-H 依旧能够对强压缩性的高超声速平板流动雷诺应力各向异性张量进行预测.而这也意味着通过高超声速样本构建的TBNN 模型可以用来提高可压缩模型的针对性,为高超声速湍流模型的定制化提供方法基础[1].
3.4 模型泛化能力验证
神经网络模型的泛化能力至关重要,本节将对训练好的TBNN 模型能否应用于与训练算例不同的算例展开讨论.在3.1 节中,TBNN-C 模型由Reτ=395 的低速槽道流完成训练,并对Reτ=590 的槽道流工况进行了较好的预测,初步验证了TBNN 的外推能力.为了进一步验证其泛化能力,本节选取了一组Reθ=1100 的低速平板作为验证算例,该平板的DNS 结果由Jimenez 等[31]计算.将Reτ=395 的低速槽道流作为训练数据,通过训练好的TBNN-C 模型对该低速平板进行预测.
验证算例的开源DNS 数据[31]给出了边界层厚度为δ99=2.756 8 的对应截线上的数据点,其中边界层内的流场点共有130 个.该算例的RANS 计算由standard k-ε 模型完成,网格参数见表2.

表2 验证算例RANS 计算的网格信息Table 2 Mesh information for validation case in RANS
表中Lx为计算域在x 方向的长度,Ly为y 方向的长度,Δx+为x 方向两个网格点的距离差.RANS计算的y 方向的网格分布与DNS 计算保持一致.此处针对RANS 所用网格的进行了网格无关性验证.在确保了网格不会对求解精度造成影响后,选取其中湍流充分发展的位置作截线,与DNS 数据中的流场点进行匹配以便于最终进行对比.
将RANS 算得的平板边界层的湍动能、湍流耗散率以及速度梯度输入到TBNN-C 模型中,得到预测的结果.同时将预测结果与DNS 结果以及通过公式(13)解得的RANS 结果进行对比,如图12 所示.

图12 Reθ=1100 平板边界层的雷诺主应力各向异性分量的分布Fig.12 Reynolds normal stress anisotropy components on Reθ=1100 boundary layer
相比于3.1 节的结果,基于槽道流的136 个流场点训练的TBNN-C 模型对于不同工况的平板边界层的预测精度尽管稍有下降,但与DNS 结果相比误差仍不超过20%,依旧较为准确的预测了雷诺应力各向异性张量,验证了TBNN 模型的泛化能力.而使用上述模型预测翼型以及高超声速平板边界层,结果显示模型的预测的精度大幅下滑,在一定程度上说明了模型性能对于训练数据的依赖.尽管TBNN 是基于Pope 的本构关系构建,但依旧会受到神经网络特性的固有限制.
4 结论
本文宽速域下TBNN 对雷诺应力各向异性张量的预测结论如下.
(1) 无论是低速还是高超声速,基于Boussinesq有效黏度假设的RANS 模型均难以准确地捕捉雷诺应力各向异性张量.
(2) 基于Pope[5]提出的有效黏度假设构造出的TBNN-C 对于槽道流的预测结果较好,在训练样本仅有136 个流场点的极小样本的情况下,依旧可以准确地预测不同雷诺数下槽道流的雷诺应力各向异性张量.TBNN 预测结果与DNS 误差在10%左右,部分点位与风洞实验结果误差亦在10%以内,泛化能力较好.
(3) TBNN-N 对于NACA0012 翼型的预测在个别流场点存在偏差.在选取了流场中1440 个点作为训练集之后,TBNN 对于同流场额外的360 个点的预测结果尚可.在小样本的训练前提下,TBNN-N 能够对NACA0012 的关键区域进行较为准确的预测.与槽道流相比,TBNN 对于复杂流场需要增大样本量以提升准确性.
(4) 对于高超声速平板,在以湍流区域部分位置进行训练后,TBNN-H 能够较好地给出流场中其他位置的雷诺应力各向异性张量分布.尽管Pope[5]有效黏度假设是针对不可压缩流提出的,TBNN-H 依旧可以在小样本的前提下对高超声速平板边界层内的流场进行精准的预测.
(5) 在低速槽道流和低/高超声速平板中,TBNN在黏性子层(即y+<5 区域)表现较差,猜测原因可能是训练集的RANS 部分来自于k-ε 模型求解,TBNN 的预测能力会受到RANS 结果的固有限制.
(6) 低速槽道流训练的TBNN-C 模型能够较为精确的预测低速平板算例,模型的泛化能力得到了验证.而相同模型对于翼型和高超声速平板的预测出现的预测精度下滑则在一定程度上说明了模型性能对于训练数据的依赖.
本文在宽速域下,对TBNN 预测能力进行了充分的验证.相比于Pope 针对不可压缩工况提出的本构关系,神经网络凭借出色的从数据中提取信息的能力在映射关系中学习到了可压缩相关的信息,使得基于Pope 本构关系的TBNN 能够对高超声速工况进行较好的预测.尽管神经网络的“黑匣子”性质使得TBNN 难以像本构关系一样具有可解释性,但本工作对于高超声速的雷诺应力各向异性的求解仍具有参考价值.
在下一步的工作中,将针对更多的高超声速复杂工况展开研究,同时增加三维的相关预测.在进一步完成TBNN 在复杂高超声速工况的适用性验证后,将通过单向耦合的方式将训练好的TBNN 模型与可压缩湍流模型以及N-S 求解器耦合,尝试改善对于流动的预测精度.而耦合对应的稳定性与收敛性的问题将是研究的重点与难点.此外,还将通过在神经网络中添加物理约束,构建物理驱动的张量基神经网络(physics informed tensor based neural network),进一步增强TBNN 在小样本的泛化能力.
致 谢
感谢Julia Ling 于https://github.com/tbnn/tbnn开源的TBNN 内核代码;感谢Ricardo Vinuesa 提供的Naca0012 翼型LES 数据和帮助;感谢Robert D.Moser 提供的槽道流DNS 数据以及Jimenez 提供的低速平板DNS 数据.
猜你喜欢
军民两用技术与产品(2022年2期)2022-06-01 06:29:48
凤凰动漫(军事大王)(2022年1期)2022-04-19 11:35:10
数学物理学报(2021年1期)2021-03-29 03:13:38
五邑大学学报(自然科学版)(2020年4期)2020-12-09 06:28:48
车迷(2018年11期)2018-08-30 03:20:20
车迷(2018年12期)2018-07-26 00:42:24
小哥白尼(趣味科学)(2018年5期)2018-06-21 06:24:32
山西大同大学学报(自然科学版)(2016年2期)2016-12-12 03:19:27
中国汽车界(2016年1期)2016-07-18 11:13:34
太空探索(2014年5期)2014-07-12 09:53:28
