
基于BERT-DeepCAN-CRF 的中文命名实体识别方法∗
2022-03-18 06:20谢斌红张露露赵红燕
计算机与数字工程 2022年12期
谢斌红 张露露 赵红燕
(太原科技大学计算机科学与技术学院 太原 030024)
1 引言
命名实体识别(Named Entity Recognition,NER)是指识别文本中具有特定意义的实体,主要包括人名、地名、机构名和专有名词等,它是自然语言处理中一项基本且具有挑战性的任务,也是信息提取和机器翻译等许多高级任务的基础和关键组件。
命名实体识别的研究方法经历了基于规则的方法、机器学习和深度学习三个阶段,其中深度学习方法可以自动学习深层的特征,实现从非结构化的输入文本到实体识别结果的映射,与传统的基于规则和机器学习的方法相比,不需要建立不同领域的知识库和大量的特征,为解决命名实体识别问题提供了一种新的途径,引起了研究人员的广泛关注,并先后提出了多种形式的基于字符或词语嵌入的深度神经网络模型。下面分别从模型的输入分布式表示、上下文编码器结构和标签解码结构进行具体阐述。
1)输入的分布式表示
实体识别的成功在很大程度上依赖于它的输入表示,分布式表示可以自动从文本中学习和捕捉文本的句法和语义特征,在NER任务中目前有3种常见的分布式表示:词语级、字符级和混合表示。
(1)词语级别的表示是将句子中的每个词语分布式表示作为神经网络的输入。第一个词级神经网络模型是由Collobert 等[1]2008 年提出的,之后Huang 等[2]提出了一个基于词语级别的LSTM-CRF模型,有效提高了实体识别的性能。基于词语表示进行中文NER 任务时,通常会借助外部工具进行分词,而分词错误的传播将会影响后续实体识别任务的性能,而且分词之后,嵌入层的参数会显著增加,还将引入数据稀疏和过度拟合问题,此外,由于中文词汇量巨大,基于词语表示还会带来OOV(Out-of-vocabulary)问题。
(2)字符级别的表示是以单个字为粒度做分布式表示。该表示方法可以解决OOV 问题。Yang等[3]提出在神经网络卷积层设置一个固定大小窗口来提取字符级别的特征。Lample 等[4]采用了BiLSTM模型来抽取字符级分布式表示。
(3)混合分布式表示是将词语、字符等多种特征进行融合作为神经网络的输入。基于词汇增强的中文NER 有两种方式,其一设计一个动态框架,能够兼容词汇输入。作为融入词汇信息进行中文NER 的开篇之作,Zhang[5]等提出一种Lattice LSTM模型,通过词典匹配句子,将潜在词级信息集成到基于字符的LSTM-CRF 模型,有效提升了NER 性能。其二是基于词汇信息构建自适应Embed⁃ding。Peng 等[6]提出了一种在Embedding 层利用词汇的方法,对每个字符依次获取BMES 对应所有词汇集合,然后再进行编码表示。除了字词特征的融合,一些研究人员还纳入了一些其他信息。Dong等[7]引入汉字偏旁作为额外的特征。还有其他混合型方法用到了情感、语义[8]等特征。虽然引入外部知识可以提高实体识别的性能,但是会损害基于端到端的深度学习NER模型的通用性。
2)上下文编码器结构
循环神经网络RNN 及其变体GRU 和LSTM 由于其较强的序列建模能力在NER 任务上取得了显著效果。Huang 等[2]于2015 年首次引入了BiLSTM来解决序列标记问题。目前该模型在NER 任务中得到了广泛应用,之后一系列研究[7,9~11]都以BiL⁃STM 作为实体识别任务编码序列上下文信息的体系结构。
也有一些研究人员采用卷积神经网络CNN 作为实体识别的主干网络。Strubell[12]和Gui[13]提出用CNN 来编码单词;研究表明[9,14]CNN是提取字符信息的有效方法;Wu 等[15]利用卷积层生成由多个全局隐藏节点表示的全局特征,然后将局部特征和全局特征结合起来识别中文命名实体。
Zheng等[16]认为重要的单词可能出现在句子中的任何位置,因此其提出将BiLSTM 和CNN 结合作为实体识别的特征提取器。使用BiLSTM捕获长距离依赖关系并获得输入序列的整体表示,然后利用CNN学习高级表示,最后输入分类器进行实体的识别。Li 等[17]使用CNN 网络训练出具有语义信息的特征向量,然后构建进行实体识别的BiLSTM-CRF神经网络模型。
3)标签解码结构
标签解码是命名实体识别模型的最后一个环节。目前主要有多层感知机结合softmax 和条件随机场等方法。其中,多层感知机结合softmax 将问题建模为一个多分类问题,每一个标签独立预测,没有考虑相邻标签之间联系;而条件随机场采用动态规划思想的维特比算法(Viterbi)进行解码,对实体标签进行预测,该方法考虑相邻标签之间的关系,是当前最常用的解码方法。
通过上述分析,本文提出基于字符级表示的中文NER 模型。采用BERT 预训练语言模型根据上下文动态生成字符的嵌入表示,用于解决中文中存在的多义词问题以及缓解实体识别对模型结构的依赖,为模型提供更好的输入表示。
编码器方面,由于BiLSTM 网络良好的序列建模能力,已成为命名实体识别的主流网络,但因其特征提取时需要跨越输入文本长度顺序进行计算,不能充分利用GPU 的并行性,限制了网络的计算效率。而且随着序列增长,长序列建模能力减弱。针对该问题,本文提出一种DeepCAN 网络,通过将卷积网络和多头注意力机制结合作为特征提取器。首先利用多个卷积核在整个文本序列上并行计算并有效捕捉实体的局部连续特征,同时利用深层CNN 网络堆叠,进一步增大感受野,提取句子的全局上下文高层语义特征。此外,为了解决句子中同一实体可能被模型预测不同标签出现上下文不一致问题,还引入了多头注意力机制提取句子全局上下文特征,解决长距离依赖问题。
解码器方面,本文选择目前主流的CRF进行解码,获得实体的标签预测。
2 命名实体识别网络模型
在本节中,将详细阐述基于BERT 模型和注意力机制的卷积神经网络模型。模型主要分为BERT层、DeepCAN 层和CRF 层。其中DeepCAN 层由N个相同的卷积注意力模块(Convolutional Attention Block,CAB)叠加而成。每个CAB 包括3 层CNN 叠加组成的非线性子层和一个注意力子层。模型的整体结构如图1所示。

图1 BERT-DeepCAN-CRF模型结构图
2.1 字符级向量表示
词向量是基于深度学习的自然语言处理的重要组成部分,它可以将离散、不连续的自然语言映射到低维、稠密的向量空间,使神经网络能够更好地理解语义,从而提升对自然语言的理解能力。
本文使用BERT 预训练中文词向量模型表征词的多义性,生成词的嵌入表示,使提取到的语义信息更加丰富,获得高质量的词向量,更有利于下游实体识别任务的进行。
另外,为了减少未登录词的数量,避免分词结果对实体识别的影响,本文采用基于字符级的嵌入表示方法。给定一个输入句子X={x1,x2,x3,…,xm},其中m为句子最大字数,将其输入BERT 预训练好的中文语言模型,得到一个A∊Rm*d作为实体识别模型的输入,其中d为每个字的特征维数。
2.2 DeepCAN层
命名实体识别需要兼顾局部特征和全局特征对实体进行标签预测。DeepCAN 层旨在通过叠加多层CAB 模块构建强特征器对输入字符序列进行编码。其中,CAB 中的卷积网络可以兼顾词义、词序和上下文关系对局部连续特征进行提取,为实体识别提供有利的局部特征信息。自注意力机制可以学习句子中任意两个字符之间的关系,从句子层级进行特征的提取,同时使用多头注意力从句子不同层面进行信息挖掘,提取更加丰富的特征。DeepCAN 网络不受限于序列长度,可最大限度地利用GPU资源并行运算以节省大量时间和成本。
2.2.1 卷积注意力模块CAB
卷积注意力模块CAB 由3 层CNN 叠加组成的非线性子层、多头注意力子层,残差连接和层归一化构成。下面对其内部结构详细阐述。
1)卷积层
卷积神经网络是一种可并行、可训练、推理速度快且具有深度结构的前馈神经网络。CAB 模块通过卷积操作实现对输入字符嵌入的特征学习和表示。首先将经过BERT 预训练语言模型获得的文本矩阵A作为卷积神经网络的输入,为了处理句子边缘信息,同时为了避免随着网络深度增加特征图大小的急剧减小,选用SAME 进行padding 操作,保证输出与输入同等大小。
本次将卷积核高度h设置为3,宽度d为词向量的维度,同时为了使获得的特征多元化,使用了200 个卷积核进行特征信息的提取,每个句子的滑动窗口为{x1:h,x2:h+1,…,xm-h+1:m},对文本矩阵的每个窗口xv:v+h-1进行卷积操作,计算如式(1)所示:
ci为卷积后的运算结果,Wh∈Rh*d为卷积核的权重,bh∈R为卷积核的偏置,v代表卷积核滑动窗口的参数,⊗为卷积计算,f(x)为激活函数,本文采用可以更好学习和优化的relu 函数作为激活函数。最后得到输出结果sub-Layer(x)=[c1,c2,…cm-h+1],如图2 所示。多层卷积将局部特征进行组合从而获得更为抽象的高层表示,因此本次研究使用3 层卷积网络叠加合并全局上下文来表征长文本。

图2 卷积操作示意图
2)多头注意力层
在中文实体识别中有时候邻近上下文信息与实体关系比较弱,根据局部特征对实体进行标签预测会出现同一实体标签上下文标注不一致情况,因此模型需要提取更多长距离的上下文信息,整合句子的全局特征才能更准确地对实体进行标注。自注意力机制可以显式地学习句子中任意两个字符间的依赖关系,有效解决远距离依赖特征间的距离问题。因此,在模型中采用了Vaswani 等提出的多头注意力机制,将CNN 网络提取到的特征作为输入,并使用单独的归一化参数在同一输入上多次应用自注意机制,并将结果结合,从而使模型可以学习到不同表示子空间的相关信息。
多头注意力机制的结构如图3 所示,图的中心是缩放点积注意力,它是点积注意力的变体,与使用单层前馈神经网络实现的标准加法注意力机制相比,点积注意力利用矩阵产生,可以更快计算同一句子中任意两个字符之间的相关程度。为了使训练过程中具有更稳定的梯度,利用维度d起到调节作用。缩放点积注意力的计算如式(2)所示:
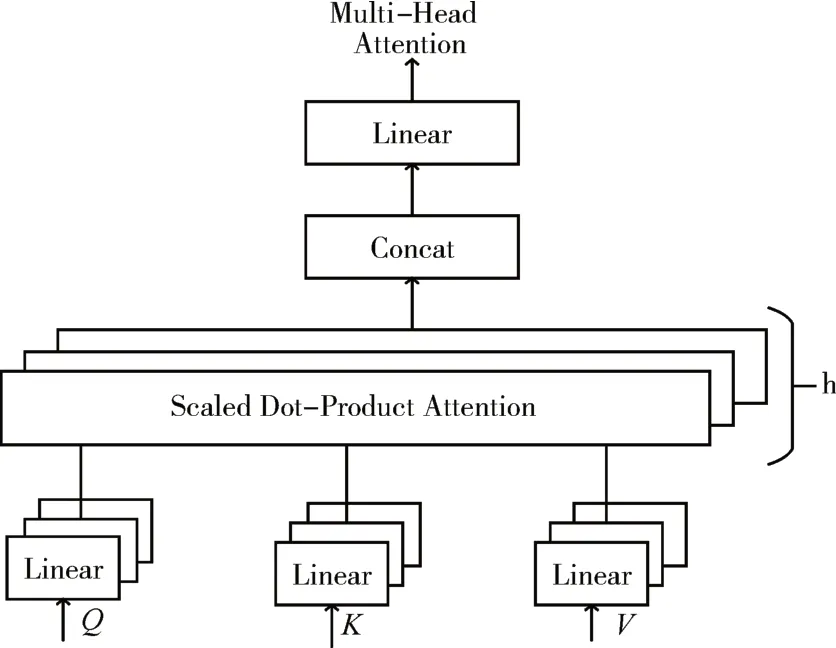
图3 多头注意力示意图
最后将4 次缩放点积注意力的结果进行拼接,再进行一次线性变换得到输入文本中更丰富的句法和语义信息,使模型聚焦于对实体识别任务更为关键的信息。计算如式(4)所示:
2.2.2 深度结构
本文将3 层CNN 网络和多头注意力层结合构建了一种卷积注意力模块CAB,通过堆叠多层实现深度结构,进而构建更强的特征学习器。由于多层迭代结构会带来梯度消失或爆炸问题,因此,通过引入残差连接缓解梯度不稳定带来的网络退化问题。随着深度网络的多层运算之后,样本特征分布松散,这样会导致神经网络学习速度缓慢甚至难以学习,因此在残差网络之后使用了归一化处理,使网络快速收敛,模型训更加容易和稳定。
2.3 CRF层
DeepCAN 层网络的输出结果是语句中每个字对应各实体类别的分数,虽然可以选择分数最高的类别作为实体预测结果,但是该结果并没有考虑实体标签之间的依赖关系,而CRF可以加入一些约束条件去考虑实体标签之间的上下文关系,来保证最终预测结果是最优的。这些约束可以在训练数据时被CRF 层自动学习得到,因此本文选择CRF 来建模标签序列。
对于给定输入句子X={x1,x2,x3…xm},其对应的标签序列y={y1,y2,y3…ym},标签序列的分数计算如式(5)所示:
其中Oi,yi表示句子中第i字符xi是标签yi的分数。T是一个过渡分数矩阵,它表示两个连续标签的转换分数。
所有标签序列y的概率计算如式(6),其中y͂表示任意标签序列,Yx是输入X的所有可能输出标签序列的集合。
对于给定集合{xi,yi},最大似然函数计算如式(7)所示:
在解码中,使用Viterbi算法来预测获得最高得分的标记序列,将其作为最终的实体识别结果序列,计算如式(8)所示:
3 实验与分析
3.1 实验数据
本次实验所选取的数据集为SIGHAN2006[19]的实体识别数据集,包含了人名、地名和机构名三类实体。该数据集包括训练集,验证集,测试集。数据集规模如表1所示。

表1 数据集规模表(句子)
3.2 模型构建和参数设置
本次实验环境为Windows 操作系统,Tensor⁃flow 版本为1.14.0,python 版本为3.7。实验参数设置如表2所示。

表2 模型参数设置
3.3 实验结果
在这一小节中,主要对本次研究所做实验结果进行分析。
3.3.1 验证模型的有效性。
为了验证本次所提模型的有效性,论文进行了以下对比实验:1)为了验证模型深度对实体识别效果的影响,选择了模型深度为6 层、8 层和10 层分别进行实验;2)在最佳模型深度基础上,使用BERT和Word2vec 两种生成词嵌入方法进行实体识别;3)将论文提出的DeepCAN+CRF模型和主流的BiL⁃STM+CRF模型进行对比,实验结果如表3所示。
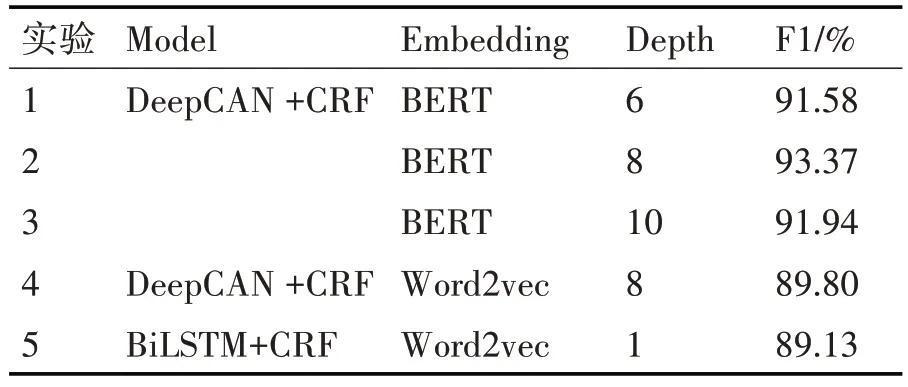
表3 对比实验结果
根据表3分析可以获得:
1)实验1、2、3 结果表明,使用BERT 预训练模型获得词嵌入表示时,模型在深度为8时F1值最高达到93.37%,随后是深度为10 时F1 值为91.94%,深度为6 时,F1 值最低为91.58%。表明适当增加网络深度有利于实体识别性能的提升,但随着模型加深会引起网络退化,学习能力下降问题。
2)实验2、4 表明,在模型相同情况下,使用BERT预训练语言模型生成词嵌入的方法进行实体识别的F1 值为93.37%,比使用Word2vec 获得词向量的方法进行实体识别的F1 值89.80%提高了3.57%。表明BERT 预训练语言模型获得嵌入有助于提升模型性能。
3)通过实验4、5 相比,在输入同时使用Word2vec 做词嵌入表示时,DeepCAN+CRF 模型的F1 值比BiLSTM+CRF 模型的F1 值高0.67%。表明DeepCAN 既可以使模型学到局部连续特征又可以捕捉长距离文本关系,学习能力更强
3.3.2 模型训练过程
图5 展示了DeepCAN+CRF 模型使用不同词嵌入方式和在不同深度下随着训练轮数F1 值的变化。其中BERT+DeepCAN+CRF 模型在深度为6 时训练30 个epoch 时F1 值达到最大为91.58%,深度为8 时在训练34 个epoch 时F1 值达到最大值为93.37%,深度为10 时在训练31 个epoch 时F1 值达到最大值为91.94%。利用Word2vec 做词嵌入时,模型深度为8 时DeepCAN+CRF 在训练25 个epoch时F1值取得最大为89.80%。
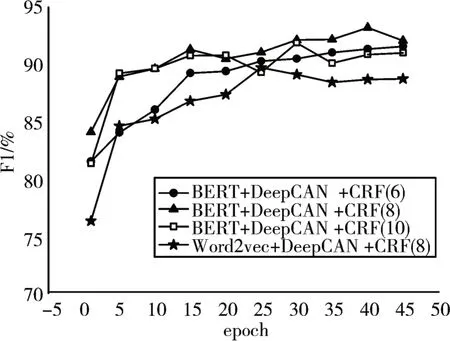
图4 不同模型训练过程
3.3.3 不同模型训练时间对比
为了验证本文特征提取器的并行能力,对模型训练所需时间进行了比较,结果如图5所示。

图5 训练时间对比图
根据图5 可知,使用BERT 预训练语言模型训练深度为6 层的DeepCAN+CRF 模型45 个epoch 所需时间为398min,深度为8 层时所需时间为400min,深度为10 层时所需时间为401min;使用Word2vec获得词嵌入表示时,BiLSTM+CRF 模型训练45 个epoch 所需时间为81min,深度为8 层的DeepCAN+CRF 模型训练45 个epoch 所需时间为52min。
由此可以看出CNN 模型相比于BiLSTM 模型具有良好的并行计算能力,训练速度更快;同时由于BERT 模型参数量大,导致使用BERT 模型比Word2Vec所需训练时间大幅度增加。
3.4 与现有其他方法的对比
为了验证所提出BERT+DeepCAN+CRF 的性能,与现存的下列方法方法进行了比较。
1)Luo and Yang[20]首先训练一个分词模型,然后将分词作为额外的特征进行实体标记,在SIGHAN2006数据集上达到了89.21%的F1值;
2)Cao and Chen[21]提出了基于自注意力机制的命名实体识别对抗性迁移学习网络,将实体识别与分词两个任务同时进行训练,将词语级特征引入实体识别任务。在SIGHAN2006 数据集上达到了90.64%的F1值。
3)Yin et al[22]提出一种融合字词的BiLSTM 模型,分别用BiLSTM-CRF训练基于字和词的实体识别模型,最后将两个模型进行融合,在SIGHAN 2006数据集上达到90.45%的F1值。
对比结果如表4 所示,根据表4 给出的实验结果可以观察到,本文提出的方法没有引入额外的特征,将F1 值从90.64%提高到93.37%,验证了模型的有效性,尤其是BERT 预训练语言模型的引入,对性能的提升有重要的作用,在未来研究中整合或微调预先训练的语言模型嵌入将成为神经网络的新范式。

表4 与现有方法对比结果
4 结语
本文提出了一种基于BERT 模型和深度卷积注意力网络进行中文命名实体识别的方法。实验表明该方法比现存方法可以实现更好的结果,主要原因有以下点:1)BERT 预训练语言模型比主流的Word2vec 方法具有更好的学习能力,可以提取高层的抽象信息,提高了模型表征词语的能力;2)深度卷积注意力网络DeepCAN 可以提取丰富的长序列文本特征,而且其有良好的并行计算能力,兼顾时间和精确度,表现出更好的性能。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
中国外汇(2019年18期)2019-11-25
车迷(2018年11期)2018-08-30
海峡姐妹(2018年3期)2018-05-09
哲学评论(2017年1期)2017-07-31
传媒评论(2017年3期)2017-06-13
领导决策信息(2017年9期)2017-05-04
领导决策信息(2017年9期)2017-05-04
第二课堂(课外活动版)(2016年2期)2016-10-21
公民与法治(2016年10期)2016-05-17
