
基于基因表达式编程的多目标自动聚类算法
2022-03-18 05:01徐丽丽许春秀
计算机应用与软件 2022年3期
徐丽丽 许春秀 张 静 齐 峰
1(山东劳动职业技术学院信息工程系 山东 济南 250022)2(山东师范大学商学院 山东 济南 250014)
0 引 言
聚类是将一组未标记的对象分配到不同簇中,使得来自同一簇内的对象之间的相似性最大,而来自不同簇间的对象之间的相似性最小[1]。聚类算法目前已被广泛应用于许多领域,包括机器学习、模式识别、图像分析、信息检索、生物信息学、数据压缩和计算机图形学。
传统的单目标聚类算法具有简单、执行速度快且效率高等优点,但同时也存在着算法容易陷入局部最优,需要预先指定最终的聚类数目以及算法适应性低等局限性。与单目标聚类算法仅采用单个聚类标准来对对象进行划分不同,多目标聚类算法可通过同时优化多个聚类评价标准来获得聚类结果,这样可以增加算法对大部分聚类结果的鲁棒性[2-3]。其中,进化算法可以对聚类解空间进行全局搜索从而克服传统聚类算法容易陷入局部最优的缺点,因此,近年来基于进化计算的聚类算法逐渐成为科研人员关注的焦点[4-6]。除此之外,传统聚类算法需要预先设定聚类的数目,但是在实际应用中对于待聚类的数据通常缺乏与类别数目有关的先验知识,而基于进化计算的聚类算法借助进化机制实现聚类解空间的随机搜索,无须预先指定聚类数目。本文以基因表达式编程算法(Gene Expression Programming,GEP)为基础,结合设计的广义聚类代数算子和目标优化函数,提出了一种基于基因表达式编程的多目标自动聚类算法(MAGEP-Cluster)。MAGEP-Cluster算法不仅可以自动确定最优聚类的数目,还可以同时基于簇内数据紧凑性和簇间数据连通性两个衡量指标实现数据的有效划分。
1 相关工作
作为统计学、模式识别、机器学习、数据挖掘和生物信息学等几个领域的基础,聚类的目的是为了确定一组未标记数据的固有分组,其中每个组中的对象在某些相似性标准下是不可区分的。聚类将数据集划分为组(簇),其中组(簇)中的数据元素彼此有很高的相似性,而组(簇)间元素彼此间的相似性很低。
自动多目标聚类的目的就是为了解决需要预先确定最终聚类数目或分区数目的问题。MOCK(具有自动k-确定的多目标聚类)[7]是一种基于PESA-II[8]的多目标聚类算法,它被用于优化两个互补的目标函数:总体偏差(测量簇内数据的紧凑性)和连通性(考虑相邻数据项是否放置在相同的簇中)。以往的研究表明,在各种基准数据集中,MOCK的表现优于传统的单目标聚类算法。该算法适用于超球形或分离的簇,并且可以提供更好的聚类结果,但是MOCK在重叠簇上的聚类结果并不能令人满意。文献[9]中提出了一种基于对称性的多目标聚类算法(VAMOSA),该方法以基于模拟退火的多目标优化方法作为底层优化策略,借助聚类中心字符串化的编码规则,并在聚类中使用文献[10]中新提出的点对称距离来代替常规的欧几里德距离。实验结果表明,VAMOSA算法整体性能优于MOCK,但是,同样该算法对重叠数据集的聚类没有很好的鲁棒性。基于基因表达式编程算法[11],文献[12-14]提出了一类名为GEP-Cluster聚类算法,该类算法都借鉴了遗传进化过程中的某些生物特性,例如小生境等,相关实验结果表明该类算法的性能要好于基于原始GEP聚类算法的表现。
文献[15]针对层次聚类算法不足,提出了一种基于GEP计算模型的层次聚类算法(GEPHCA),寻找适应度最高的聚类中心。相关仿真实验表明,该算法不仅能够实现自动聚类,而且具有自适应迭代、速度较快、稳定高效等优点。文献[16]通过结合基因表达式编程和已有的串行聚类DBSCAN算法提出了一种GEP-DBSCAN协作过滤聚类算法来寻找最近邻居,改进基于密度的协作过滤方法,实验表明了算法的有效性以及提高了时间效率。文献[17]针对模糊C-均值聚类图像分割方法存在的对初始值敏感及抗噪性能差的问题,提出一种结合基因表达式编程与空间模糊聚类的图像分割方法。仿真实验表明,该算法在聚类划分系数、聚类划分熵和峰值信噪比等评价指标上总体性能优于其他比较算法。文献[18]对传统的基于基因表达式编程的聚类算法进行改进,提出了一种新的聚类合并准则解决原算法后期过合并的问题,同时改进算法编码方式并在进化过程中引入多目标来解决聚类问题。仿真结果表明,新算法的性能优于对比算法。文献[19]提出了一种改进的融合基因表达式编程和k均值算法的自动聚类算法,在GIS物流选址优化问题中实验结果表明,所提算法具有收敛速度快和聚类精度高的优势。
本文以GEP-Cluster聚类算法为研究对象,通过改进聚类代数算子、引入新的目标优化函数和设计聚类中心合并规则,提出了一种新的基于基因表达式编程(GEP)自动多目标聚类算法,称为MAGEP-Cluster。该算法不仅可以在没有任何先验知识的情况下自动确定聚类的数目,而且与其他聚类算法相比性能更优。
2 MAGEP-Cluster算法
聚类可以被视为一个多目标优化问题。MAGEP-Cluster算法不仅可以自动确定聚类的数目,还可以基于簇内数据的紧凑性和簇间数据的连通性两个标准实现所有数据的有效划分。本节将对MAGEP-Cluster算法的核心部分进行详细阐述。
2.1 广义聚类代数算子
聚类算子是实现MAGEP-Cluster算法的关键,同时也是GEP染色体的核心构成元素,其设计的合理性直接决定了自动多目标聚类算法的效能。结合文献[20-21]中关于聚类代数算子的相关研究成果,这里提出了两种分别用于分割和聚合的广义聚类代数算子,将其命名为∪n和∩n,如图1所示。
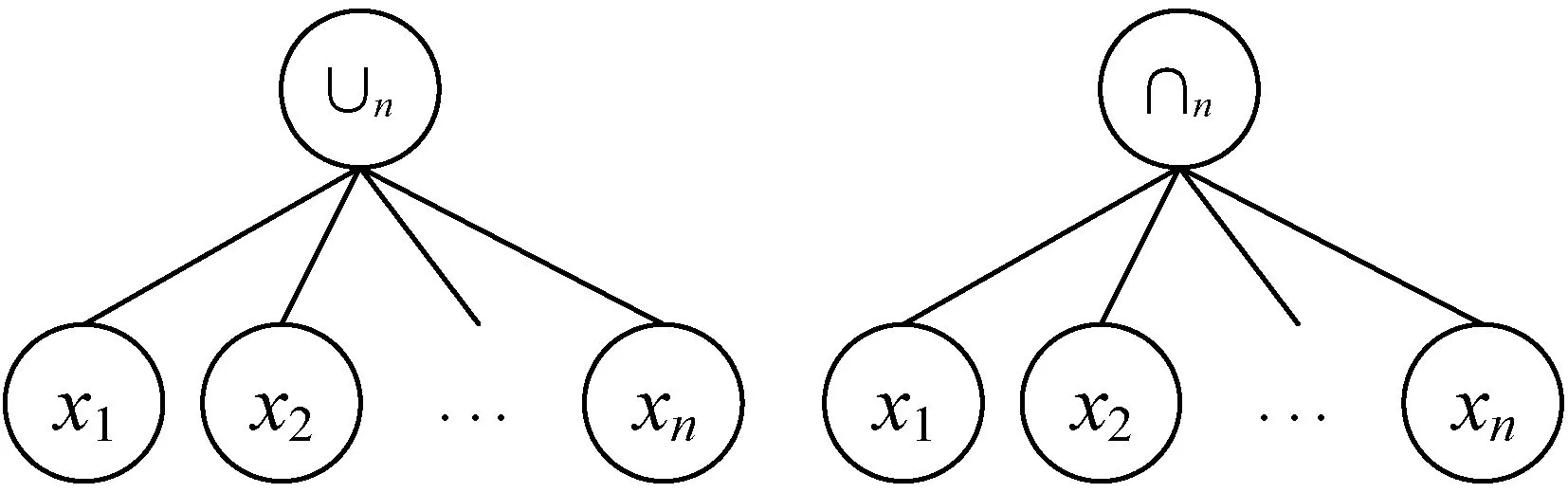
图1 广义聚类分割算子∪n和广义聚合算子∩n
假设Ox,Oy,Oz分别是簇Cx、Cy和Cz的d维度中心点,其中,Ox=(x1,x2,…,xd),Oy=(y1,y2,…,yd),Oz=(z1,z2,…,zd)。
当n=3时,广义聚类分割算子∪n和广义聚合算子∩n的计算规则如下:
(1) ∪3(Ox,Oy,Oz)={Ox,Oy,Oz}
(2) ∩3(Ox,Oy,Oz)={Oxyz}

2.2 GEP染色体编码
MAGEP-Cluster算法采用了与GEP相同的染色体编码方式,每条染色体由头部和尾部构成。头部可以包含函数节点或者终端节点,而尾部只能包含终端节点。MAGEP-Cluster算法中,函数节点集合为F={∪2,∩2,∪3,∩3,…,∪n,∩n},终端节点集合T={x1,x2,…,xm},i∈[1,m],其中xi表示数据集中第i个对象,m代表数据集中对象的个数。
根据GEP染色体编码的特点,这里使用F和T的元素组成GEP染色体的头部,使用T中的元素构建GEP染色体的尾部。GEP染色体在初始化时,若基因位位于染色体头部,则随机从集合F∪T中随机选取一个元素作为该基因位的取值;若基因位位于染色体尾部,则随机从集合T中随机选取一个元素作为该基因位的取值。
另外,特别需要注意的是,GEP染色体中的实数编码信息表示某个类别的聚类中心,而不是某单个数据对象,所以在染色体进化过程中允许有重复的终端节点。
假设h表示GEP染色体头部的长度,t表示GEP染色体尾部的长度。由于聚类算子的最大参数量是h,那么t=h(n-1)+1。从聚类表达树中可以看出,在最极端的情况下,一条GEP染色体最多可以表达h(n+1)个聚类中心。
图2展示了MAGEP-Cluster中GEP染色体三种表达形式。图2(a)展示了一条GEP染色体(h=4)的编码串形式,图2(b)展示了GEP染色体对应的GEP聚类表达树,图2(c)展示了GEP聚类表达树对应的GEP聚类操作算子表达式。

(a) GEP染色体编码串
2.3 GEP聚类表达树解码
由图2可知,GEP染色体编码串到GEP聚类表达树的转换是通过从左到右和从上到下的广度优先遍历操作来实现的。而GEP聚类表达树的解码即获得对应聚类代数算子表达式是通过从左至右和从上到下的深度优先遍历操作来实现的,并且在解码过程可根据聚类代数算子的定义对GEP聚类表达树中包含的聚类中心进行聚合和分割。
对GEP染色体对应的GEP聚类表达树解码的目的是为了了解染色体信息中携带的聚类中心信息。在实际解码时,可采取递归方式遍历聚类表达树来完成解码过程,其中主要包含聚合、分割和集中数据等操作。
解码过程的主要步骤如下:(a) 从聚类表达树的根节点开始处理。如果聚类表达树的根节点是∪n,则将以该节点的子节点为根节点的子树从左至右依次放置到n个不同的集合中,实现多个不同簇间的分割;如果聚类表达树的根节点是∩n,则从左至右依次遍历其所有子树,将所有子树中的数据放入同一簇中,计算所有子树根节点的平均值,将该平均值作为聚类中心点。注意,真正的聚类中心是由距离聚类中心点最近的数据对象来替代表示的。(b) 如前所述,递归地解码所有的子树。
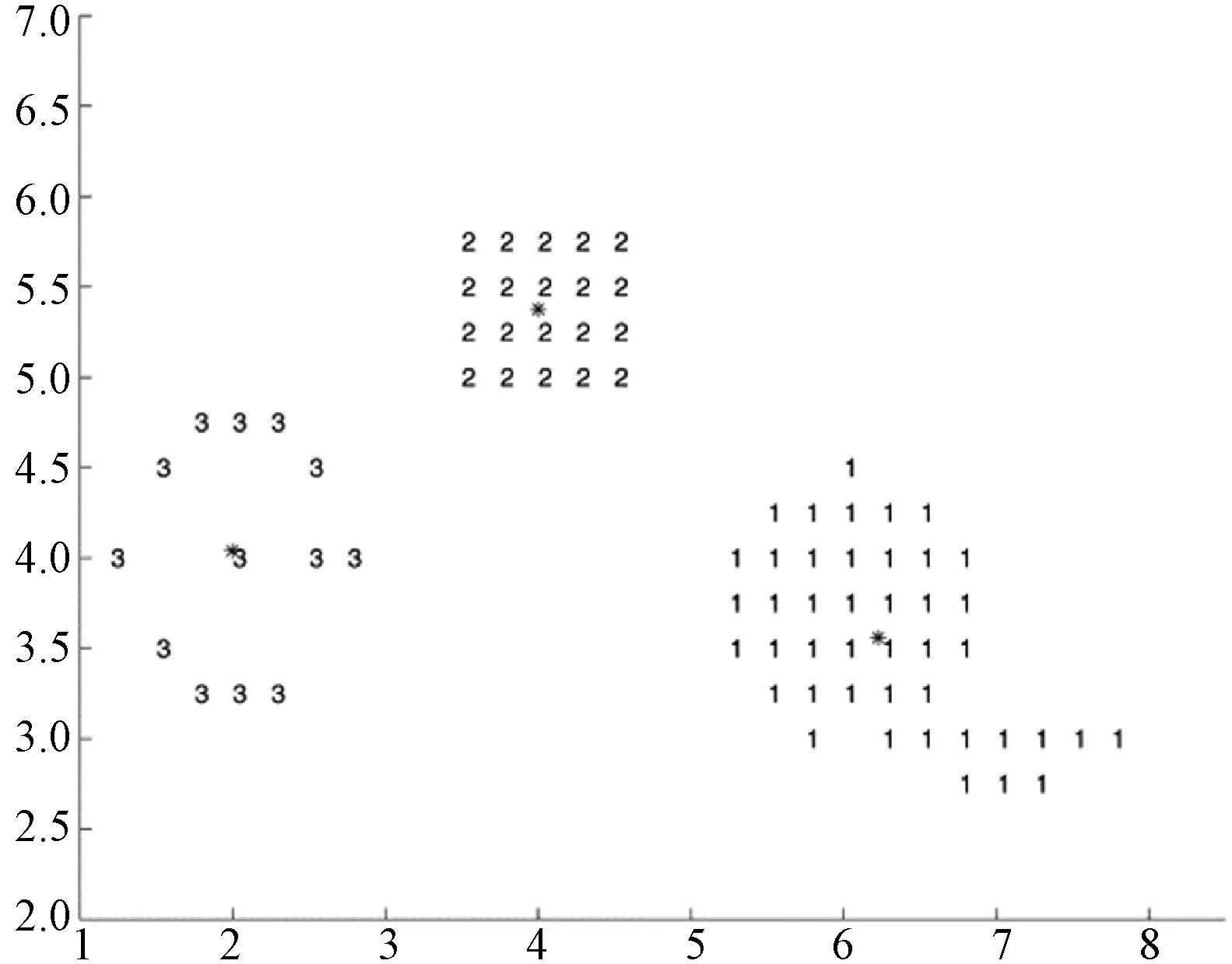
(a) MAGEP-Cluster在Data_3_2上的聚类结果
GEP聚类表达树解码算法的具体流程,如算法1所示。
算法1聚类表达树解码(寻找聚类中心)
输入:聚类表达树
输出:聚类中心
(1) 如果聚类表达树的根节点非空,则跳转到根节点;
(2) 判断根节点类型:
(3) 如果根节点为∪n,则依次将该节点的所有子树放置到集合I中;
(4) 遍历集合I中的所有子树并依次进行递归解码;
(5) 如果根节点为∩n,则依次遍历解码其所有子树;
(6) 聚类中心点←计算子树中的所有数据点的平均值;
(7) 寻找距离聚类中心点最近的数据点作为聚类中心;
(8) 返回所有的聚类中心;
(9) 算法结束。
2.4 GEP染色体遗传操作
与经典GEP算法类似,MAGEP-Cluster采用了三种遗传操作:选择、交叉和变异。
(1) 选择操作:主要根据GEP染色体适应度值借助双人锦标赛方法来实现,同时精英选择策略也被使用,即每代种群最优个体自动保留到新种群中。
(2) 交叉操作:主要采用了单点交叉和双点交叉两种方式。大量实验结果表明,交叉概率设为0.87时MAGEP-Cluster呈现出更好的性能。由于交叉点是随机选取的,一旦产生的染色体后代是非法的,算法规定本次交叉操作将取消。
(3) 变异操作:是进化过程中跳出局部极值点的有效方式。大量实验结果表明,变异概率设为0.024时MAGEP-Cluster呈现出更好的性能。实际操作时,随机选择染色基因位进行变异,根据基因位所处位置分为两种变异操作:如果基因位在头部,则在集合F∪T中随机选择一个元素代替当前基因位的元素;如果基因位在尾部,则在集合T中随机选择一个元素代替当前基因位中的元素。如果变异后的染色体是非法,则重新随机选择基因位执行变异操作,直到产生合法染色体后代为止。
2.5 聚类中心合并算法
大量实验结果表明,虽然MAGEP-Cluster在解决多目标聚类问题方面效果很好,但有时最终获得的聚类中心不一定是最优的,例如会出现聚类中心过多的现象。因此,在通过MAGEP-Cluster获得数据的聚类中心后,有必要设计一种聚类中心合并算法。
通过研究相邻簇中数据点的相互关系,本文提出了一种聚类中心自动合并算法,算法流程如算法2所示。
算法2聚类中心自动合并算法
输入:MAGEP-Cluster聚类中心列表L
输出:合并后的聚类中心列表L
(1) 从L中随机选择一个聚类中心Ci,根据剩余聚类中心到Ci的距离对L进行排序,得到一个新的排序聚类中心列表Ls={Ci,Cj,…},其中Cj是距离Ci最近的簇,以次类推;
(2) 从Ci中选择一个最接近Cj的点xi;
(3) 从Cj中选择一个最接近Ci的点xj;
(4) 计算xi和xj间的欧氏距离Dij;
(5) 计算Ci的平均距离Di;
(6) 计算Cj的平均距离Dj;
(7) 如果Dij≤Di或者Dij≤Dj,则将Ci和Cj合并为Cij,同时替换L中的Ci和Cj;
(8) 重复上述过程,直到L中没有聚类中心可以合并;
(9) 输出合并后的聚类中心列表L;
(10) 算法结束。
2.6 聚类目标函数
多目标聚类算法性能在很大程度上取决于聚类目标函数的选择,这些目标函数应尽可能满足簇内紧凑,簇间稀疏的总体要求。本文考虑选取两个互补的目标函数:簇内紧凑性函数和簇间连接性函数作为多目标聚类算法中GEP染色体适应度值。
簇内紧凑性函数用来度量簇内所有数据点的总对称距离,即计算数据对象与其对应的聚类中心之间的总对阵距离。簇内紧凑性函数定义为:
(1)

簇间连接性函数用来评估相邻数据点被放置在同一个簇中的重要程度,定义为:
(2)

聚类目标函数包括簇内紧凑性函数和簇间连接性函数的一个重要原因是它们能够平衡彼此增加或减少簇总数的趋势,从而不必预先指定聚类簇个数k。与紧凑性相关的目标值必然随着簇个数的增加而提高,而连通性恰好相反,两者之间的相互作用对于保持簇个数的动态变化至关重要。
2.7 MAGEP-Cluster算法流程
本节将对所提出的算法MAGEP-Cluster算法流程进行详细描述,具体的算法流程如算法3所示。MAGEP-Cluster算法采用了与经典多目标遗传算法:NSGA-II[22]类似的进化流程,其中非支配排序和拥挤度计算规则与NSGA-II完全相同。
算法3MAGEP-Cluster
输入:数据集D,染色体头部长度h,种群大小N,最大进化代数Gmax,最大簇个数Kmax,贡献簇间连通性的邻居个数L,变异概率Pm,选择概率Ps,交叉概率Pc。
输出:数据集D的聚类中心列表。
(1) 根据数据集D的特点及实验要求,设置参数h、N、Gmax、Kmax、L、Pm、Pc、Lmax的初始值。
(2) 根据GEP染色体编码规则,创建初始种群Pt(t=0),种群规模为N。
(3) 根据GEP染色体解码规则,结合两个聚类目标函数和算法1,对种群Pt进行非支配排序和拥挤度计算。
(4) 依概率Pc和Pm对种群Pt进行单点交叉操作、双点交叉操作和变异操作,生成一个新的规模为N的种群Qt。
(5) 构建中间种群Rt=Pt∪Qt。
(6) 根据GEP染色体解码规则,结合两个聚类目标函数和算法1,对种群R_t进行非支配排序和拥挤度计算,借助双人锦标赛选择法和精英保留策略,从中间种群R_t中选择N个染色体生成新种群P_(t+1),令t=t+1。
(7) 如果t≤Gmax,则返回第(4)步,否则转向第(8)步。
(8) 取当前种群的最优GEP染色体执行算法2,返回最优聚类中心列表。如果满足实验要求,则转第(9)步,否则转第(2)步。
(9) 算法结束。
3 实验与结果分析
3.1 数据集
为了验证MAGEP-Cluster算法的有效性,这里选择了3个人工数据集和6个UCI标准数据集来比较MAGEP-Cluster和其他三个聚类算法的性能。
虽然人工数据集看起来很简单,但都包含一些特殊特征,例如Data_5_2中部分数据高度重叠,Data_4_3中存在部分噪声点(仅在两个不同的簇之间),这些特殊特征会对聚类目标优化函数产生干扰,影响聚类算法的最终效果。因此,选取人工数据集目的就是为了验证算法能否在处理这些具有特殊特征数据集时具有良好的鲁棒性。
表1中给出了数据集的简要描述,主要涉及总样本数据点数(n),分类簇个数(k)和样本数据属性个数(d)三个方面。
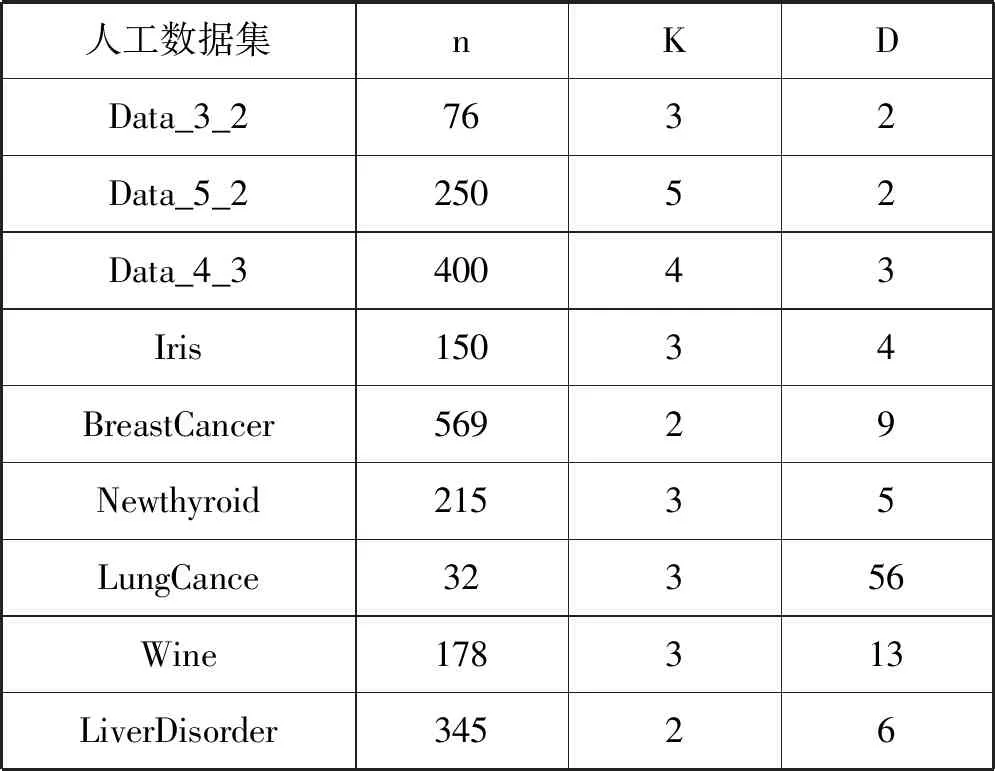
表1 人工数据集和UCI数据集
3.2 性能评价
为了评价算法性能,除了选取聚类数目作为衡量标准外,还引入了簇精度(ClusterAccuracy,CA)作为评价4种算法性能的指标,CA主要用来评估聚类结果中正确分类的数据点(由算法获得的聚类标签)所占比例,其计算式为:
(3)
式中:rj,sj分别表示数据xj∈Ci所对应的聚类标签和真实标签;|Ci|是第i个簇中的数据点个数;δ表示指示函数,定义如下:
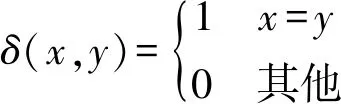
(4)
CA本质上表示的是通过聚类获得的标签与实际标签相同的数据点的数量。显然,CA越大,聚类效果越好。
3.3 结果分析
为了更好验证MAGEP-Cluster算法的性能,这里分别选取了另外三种算法:GEP-Cluster、Mock和VAMOSA作为比较对象。由于每种算法的初始种群是随机生成的,为了保证比较的公平性,对于每个数据集,每个算法独立运行200次,以使聚类结果具有可比性,然后分别计算每种算法得到的最优簇数(K)和簇精度(CA)的平均值。另外,由于MAGEP-Cluster与GEP-Cluster均使用类似的GEP染色体编码和解码规则,在实验时,规定两个算法中GEP染色体的头部和尾部相同,唯一区别在于两个算法使用的函数集不同,MAGEP-Cluster采用了广义聚类代数算子即算子的操作数大于等于2,而GEP-Cluster采用的是二元聚类代数算子即算子操作数只能为2。
表2和表3分别给出了四种算法在人工数据集和UCI数据集上的K和CA比较结果。
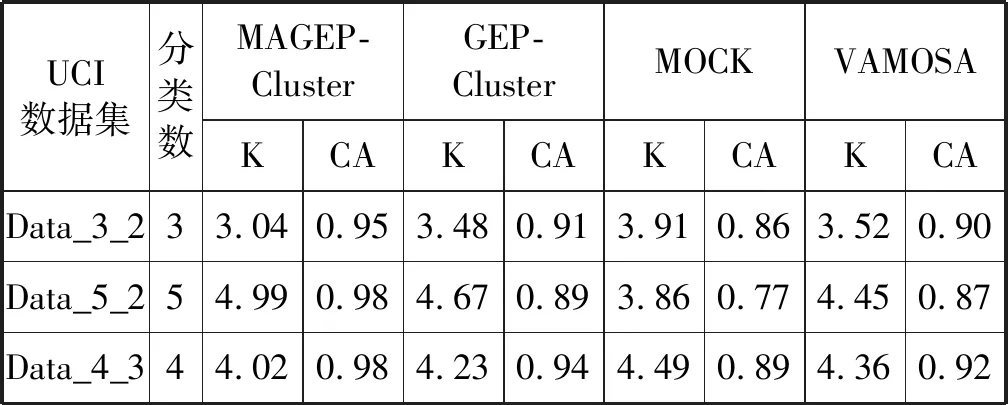
表2 人工数据集最优簇数(K)和簇精度(CA)
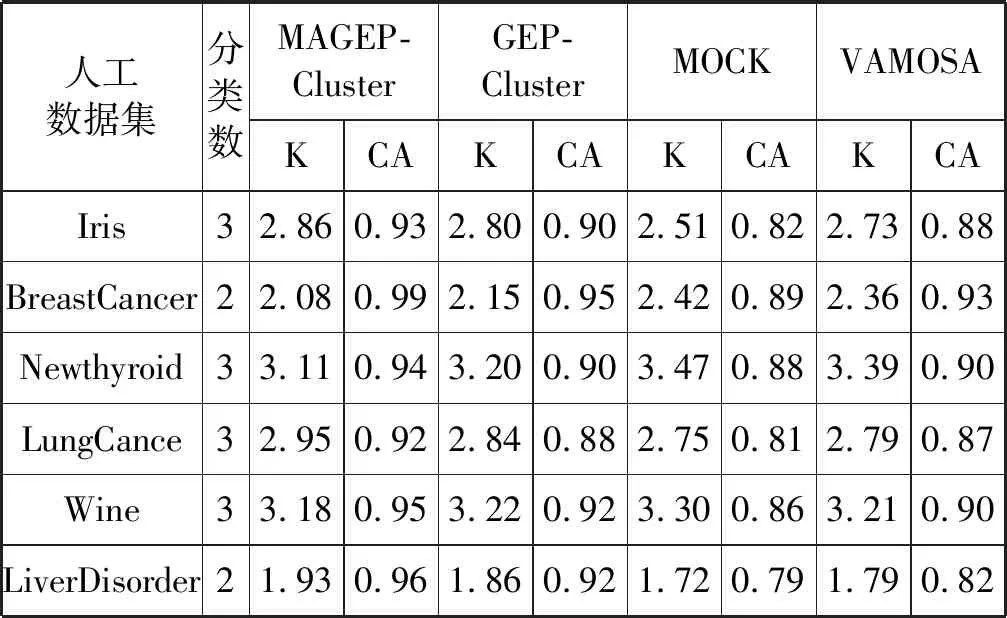
表3 UCI数据集最优簇数(K)和簇精度(CA)
MAGEP-Cluster在三个人工数据集上的聚类结果如图3所示。
如算法2和算法3所示,通过本文提出的MAGEP-Cluster算法获得的聚类数的平均值最接近每个数据集中的实际聚类数,与GEP-Cluster、MOCK和VAMOSA相比,MAGEP-Cluster算法在聚类方面具明显的优势。此外,从算法2和算法3中还可以看出,对于所有的数据集来说,所提出的MAGEP-Cluster算法产生的聚类精度(CA)的平均值高于GEP-Cluster、MOCK和VAMOSA的平均值,表明MAGEP-Cluster可以为不同的数据集找到更好的聚类分区。
4 结 语
本文通过改进聚类代数算子、引入新的目标优化函数和设计聚类中心合并规则,提出了一种新的基于基因表达式编程(GEP)自动多目标聚类算法,称为MAGEP-Cluster。所提出的MAGEP-Cluster可以通过优化簇内数据紧凑性和簇间数据连接性两个目标函数来自动计算簇的最佳数量并提高了聚类算法的准确性。实验部分分别在3个人工数据集和5个UCI数据集,比较了MAGEP-Cluster与GEP-Cluster、MOCK和VAMOSA的聚类性能。实验结果表明,MAGEP-Cluster算法能够有效地计算最优聚类数目,并在一定程度上提高了最终聚类结果的准确性。MAGEP-Cluster与GEP-Cluster相比之下,除了使用的函数集不同外,其他部分相似性很高,但在使用时前者却表现出了更好的鲁棒性,其中一个很重要的原因在于MAGEP-Cluster采用了广义聚类算子,但该算子对MAGEP-Cluster算法具体的影响机制尚不明确,因此,广义聚类算子的影响机制将成为未来研究工作的重点。
猜你喜欢
汽车实用技术(2022年4期)2022-03-07
睿士(2020年6期)2020-08-18
校园英语·上旬(2020年1期)2020-05-09
南方周末(2019-12-19)2019-12-19
华东师范大学学报(自然科学版)(2019年5期)2019-11-11
南方周末(2019-07-18)2019-07-18
南方周末(2019-05-09)2019-05-09
卷宗(2017年16期)2017-08-30
电子技术与软件工程(2016年23期)2017-03-06
国外科技新书评介(2014年12期)2015-01-05
