
融合序列模式评分的策略梯度推荐算法
2022-03-18 06:16:06丁家满贾连印游进国
计算机应用与软件 2022年3期
官 蕊 丁家满 贾连印 游进国 姜 瑛
(昆明理工大学信息工程与自动化学院 云南 昆明 650500)(云南省人工智能重点实验室 云南 昆明 650500)
0 引 言
交互式推荐系统(IRS)在大多数个性化服务中起着关键作用[1]。不同于传统推荐方法将推荐过程定义为静态过程[2],IRS连续向用户推荐商品并获得他们的反馈,从这种交互过程中学习推荐策略。IRS方法分为两类:基于多臂赌博机(MAB)推荐和基于强化学习(RL)推荐。其中,基于MAB推荐尝试将交互推荐建模为MAB问题。Koren等[3]和Zeng等[4]采用线性模型来估计各臂的置信上限(UCB)。此外,一些研究者尝试将MAB与矩阵分解技术相结合进行推荐[5]。这一类推荐方法无法实时适应用户偏好的改变,虽然实现最大化用户的当前收益,但其忽略了用户的长期收益。
强化学习在需要动态交互和长期规划(例如Atari游戏、棋类博弈和自动驾驶等)的多种场景中应用取得了显著成功[6]。近几年,众多学者应用强化学习解决推荐问题,显示出其处理IRS交互性的潜力。基于RL的推荐方法将推荐过程定义为马尔可夫决策过程(MDP),对用户状态进行建模,以最大化长期推荐奖励[7],这一类方法包括:基于值(Value-based)的方法(例如,Q-Learning)和基于策略(Policy-based)的方法(例如,策略梯度),构成了解决RL问题的经典方法[8]。Taghipour等[9]提出将网页信息与Q-Learning算法结合解决网页推荐问题。有研究者在Q-Learning中引入值函数估计和记忆库机制,提出Deep Q Network(DQN)方法[10]。Zhao等[11]将正面和负面反馈均融入DQN框架,提出了将目标项目与竞争者项目之间Q值差异最大化,以引导推荐过程的方向和目标的统一。由于Q-Learning算法和DQN算法都是Value-based的学习方法,通过对Bellman方程进行迭代最终收敛到最优价值函数,这种方法计算量大,而且在一些特殊的场景下Q值难以计算[12]。作为一种Policy-based学习方法,策略梯度(policy gradient)则不存在这一问题,这种方法可以直接对策略进行学习。Chen等[13]提出了一个基于层次聚类树的策略梯度推荐框架,通过寻找从树根到叶子的路径选取推荐项目。Chen等[14]提出将离线策略梯度修正的方法用于动作空间数以百万计的Youtube在线推荐系统,解决了因只能从之前记录反馈而产生推荐的数据偏差问题。
上述推荐算法均获得了良好的推荐效果,但在挖掘数据特性方面有待改进。为此,本文提出一种融合序列模式评分的策略梯度推荐算法(Sequence Pattern Rating Recommendation,SPRR),首先分析评分数据的序列模式,设计融合序列模式评分的奖励作为交互式推荐的反馈信息;其次针对策略梯度方差大的问题,通过对累计奖励回报设计标准化操作来降低策略梯度的方差,学习更优的推荐策略,解决电影推荐问题。
1 问题定义
利用强化学习解决推荐问题,通常基于马尔可夫决策过程原理建立推荐过程模型。马尔可夫决策过程由状态集S、动作集A、奖励函数R、状态转移函数T和策略函数π组成,利用五元组
奖励函数R(s,a)也称为强化函数,是一种即时奖励或惩罚。推荐系统根据当前历史交互记录s向用户推荐项目a之后,用户反馈给推荐系统一个奖励,表示用户对该推荐项目的评价。状态转移函数T(s,a)是一个描述环境状态转移的函数。由于状态是用户的历史交互记录,一旦推荐一个新的项目给用户,并受到用户的反馈,用户的状态也就发生了相应的变化。作为对时间步t选择执行动作at的结果,该函数将环境状态st转移到st+1。策略函数π(a|s)描述了Agent的行为,它是从环境状态到动作的一种映射。策略函数定义为所有可选的候选动作项目的概率分布。策略函数π(a|s)表示为:
(1)
式中:θ是策略参数。
包含上述MDP元素的序列(episode)为一次推荐过程,包含用户状态、推荐动作和用户反馈的序列(s1,a1,r1,s2,a2,r2,…,sn,an,rn,sn+1)。在此序列中,推荐算法根据用户状态s1向用户推荐项目a1,用户反馈给推荐系统此次推荐的奖励回报r1,用户状态s1相应的转变为s2,当序列到达满足预定义条件的状态sn+1时结束。
2 SPRR算法
2.1 奖励函数设计
奖励回报作为用户对推荐Agent行为的反馈,是指导强化学习方向的关键。奖励函数设置的优劣将直接影响算法的收敛速度和学习效果,因此在强化学习中至关重要。目前大多数基于RL推荐方法的奖励函数设置较单一,一般定义用户评分、用户点击量和用户购买量等标量信息作为反馈,未挖掘推荐过程中用户反馈行为的评分序列模式。用户评分历史记录中,除了反映用户对推荐项目的满意度外,在一定程度上也反映了用户的评分偏好。若用户的连续正面评分记录越多,表示用户对已推荐项目的满意度越高,用户对于后续推荐项目的评分为正面的概率越大;若用户的连续负面评分记录越多,表示用户对已推荐项目的满意度较低,用户对于后续推荐项目的评分为负面的概率越大。
受文献[14]启发,本文在状态st下推荐动作at后,将用户反馈的奖励定义为两部分。一部分是经验奖励回报,定义为用户对推荐项目at的评分;另一部分是序列模式奖励回报,定义为在状态st下推荐项目at之前,用户的评分序列模式奖励。评分序列模式奖励定义为用户的连续正面平均评分和连续负面平均评分之差,利用计算正负面平均评分的方式学习用户的评分序列模式。奖励函数R(s,a)计算式为:
R(s,a)=rij+α(rp-rn)
(2)
式中:rij是用户i对推荐项目j的评分,若用户i未对推荐项目j评分则为0;rp是用户的连续正面平均评分,计算式为式(3);rn是用户连续负面平均评分计算式为式(4);α为平衡参数用以权衡经验奖励回报和序列模式奖励回报的比重。
(3)
(4)
式中:pi为连续正面评分计数;ni为连续负面评分计数。
2.2 改进的策略参数学习
本文通过强化学习中策略梯度方法REINFORCE来学习策略参数θ。策略梯度方法是强化学习中的另一大分支。与Value-based的方法(Q-learning,Sarsa算法)类似,REINFORCE也需要同环境进行交互,不同的是它输出的不是动作的价值,而是所有可选动作的概率分布。SPRR算法的目标是最大化期望累积折扣奖励J(πθ),表示为:
J(πθ)=ΕL~πθ[G(L)]
(5)
式中:L={xa0,xa1,…,xaN}是推荐列表。G(L)定义为推荐列表的累积折扣奖励,其计算式为:
(6)
假定一个完整推荐序列的状态、动作和奖励回报的轨迹为τ=(s0,a0,r0,s1,a1,r1,…,sn,an,rn,sn+1),则期望累积折扣奖励J(πθ)的梯度▽θJ(πθ)的计算式为:
▽θJ(πθ)=Gt▽θlogπθ(at|st;θ)
(7)
利用该梯度调整策略参数,得到策略参数更新式为:
θ=θ+η▽θJ(πθ)
(8)
式中:η为学习率,用来控制策略参数θ更新的速率。式(7)中的▽θlogπθ(at|st;θ)梯度项表示能够提高推荐轨迹τ出现概率的方向,乘以累积折扣奖励之后,可以使得单个序列内累积奖励回报最高的轨迹τ越“用力拉拢”概率密度。即若收集了很多累积奖励回报不同的推荐轨迹,通过上述训练过程会使得概率密度向累积奖励回报更高的方向移动,最大化高奖励回报推荐轨迹τ出现的概率。
在某些序列中,由于每个序列的累积奖励回报都不为负,那么所有梯度▽θJ(πθ)的值也均为大于等于0的。此时,在训练过程中收集的每个推荐轨迹,都会使概率密度向正的方向“拉拢”,很大程度减缓了学习速率,使得梯度▽θJ(πθ)的方差很大。因此,本文对累计奖励回报使用标准化操作来降低梯度▽θJ(πθ)的方差。
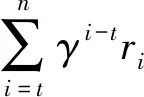
(9)
通过改进的累积奖励回报使得算法能提高总奖励回报较大的推荐轨迹的出现概率,同时降低总奖励回报较小的推荐轨迹的出现概率,保证策略参数θ沿着有利于产生最高总奖励回报的动作的方向移动,使好的动作得到更高的奖励。
本文提出的SPRR推荐算法的具体描述如下算法1。算法2取样序列算法描述了算法1中获取取样序列的过程。
算法1SPRR算法
输入:序列长度N,候选推荐集合D,学习率η,折扣因子γ,奖励函数R。
输出:策略参数θ。
1.forj=1 tondo
2.随机初始化策略参数θj;
3.end for
4.θ=(θ1,θ2,θ3,…,θn);
5.repeat
6.Δθ=0;
7.(s0,a0,r1,…,sM-1,aM-1,rM)←
SampleAnEpisode(θ,N,D,R);
//算法2
8.fort=0 toNdo
//式(9)
10.▽θJ(πθ)=Gt▽θlogπθ(at|st;θ);
//式(7)
11.end for
12.end for
13.θ=θ+η▽θJ(πθ);
//式(8)
14.until converge;
15.返回θ;
算法2SampleAnEpisode Algorithm算法
输入:策略参数θ,序列长度N,奖励函数R。
输出:推荐序列E。
1.初始化s0=[0];
2.fort=0 toNdo
3.取样动作at∈A(st)~π(at|st;θ)
//式(1)
4.rt+1=R(st,at);
//式(2)
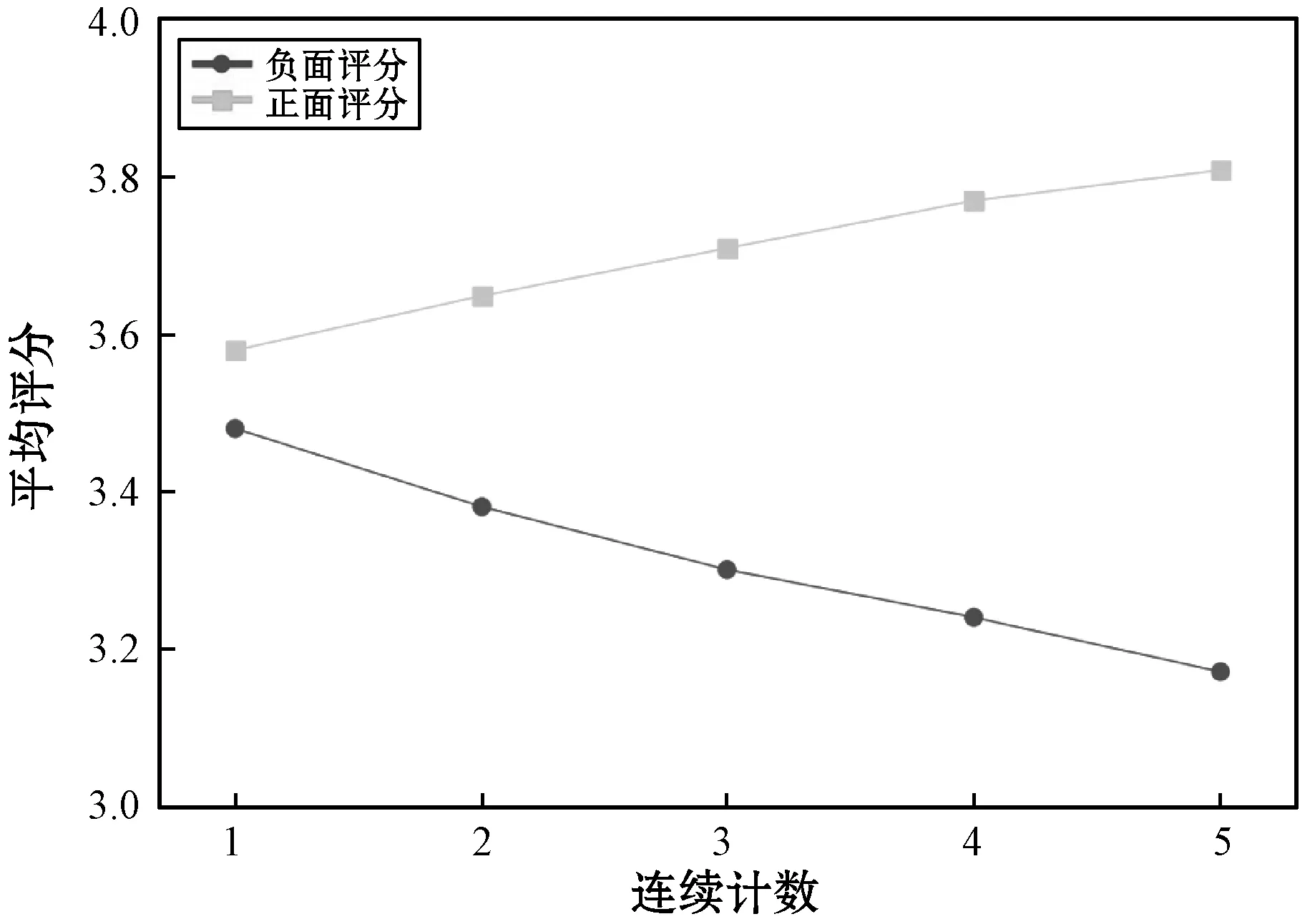
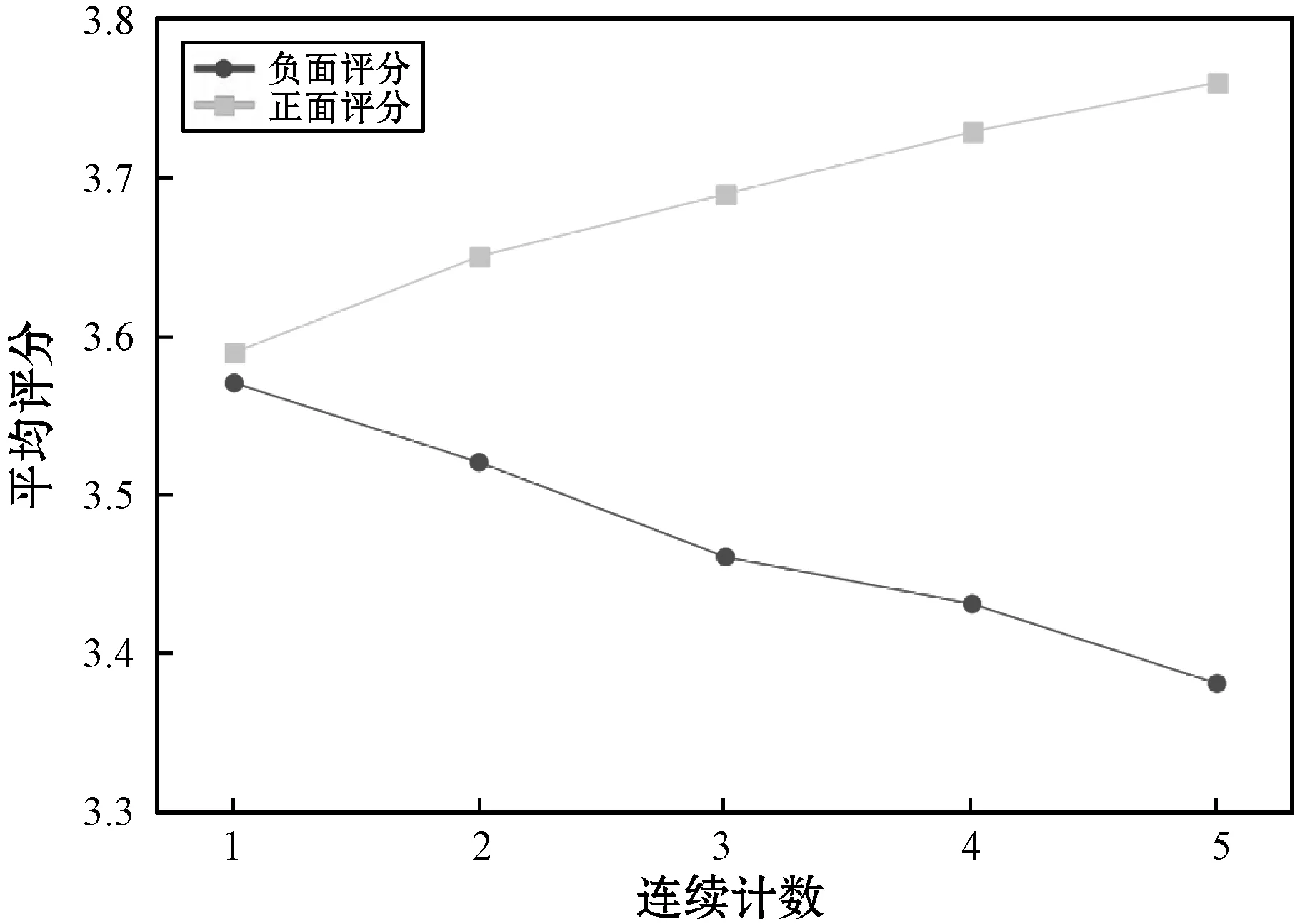
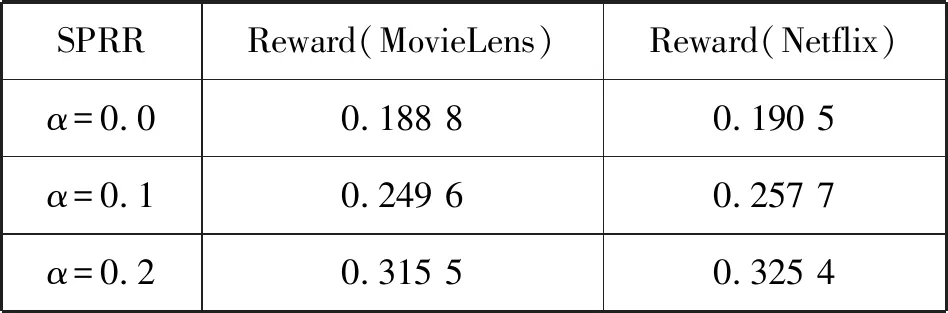
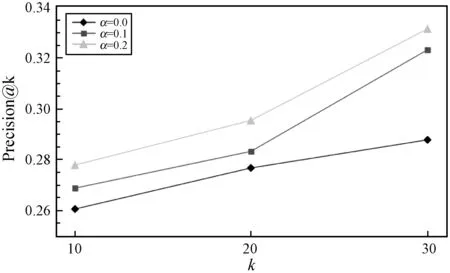
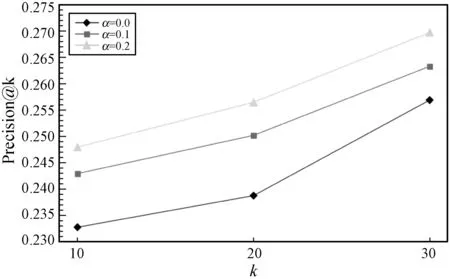
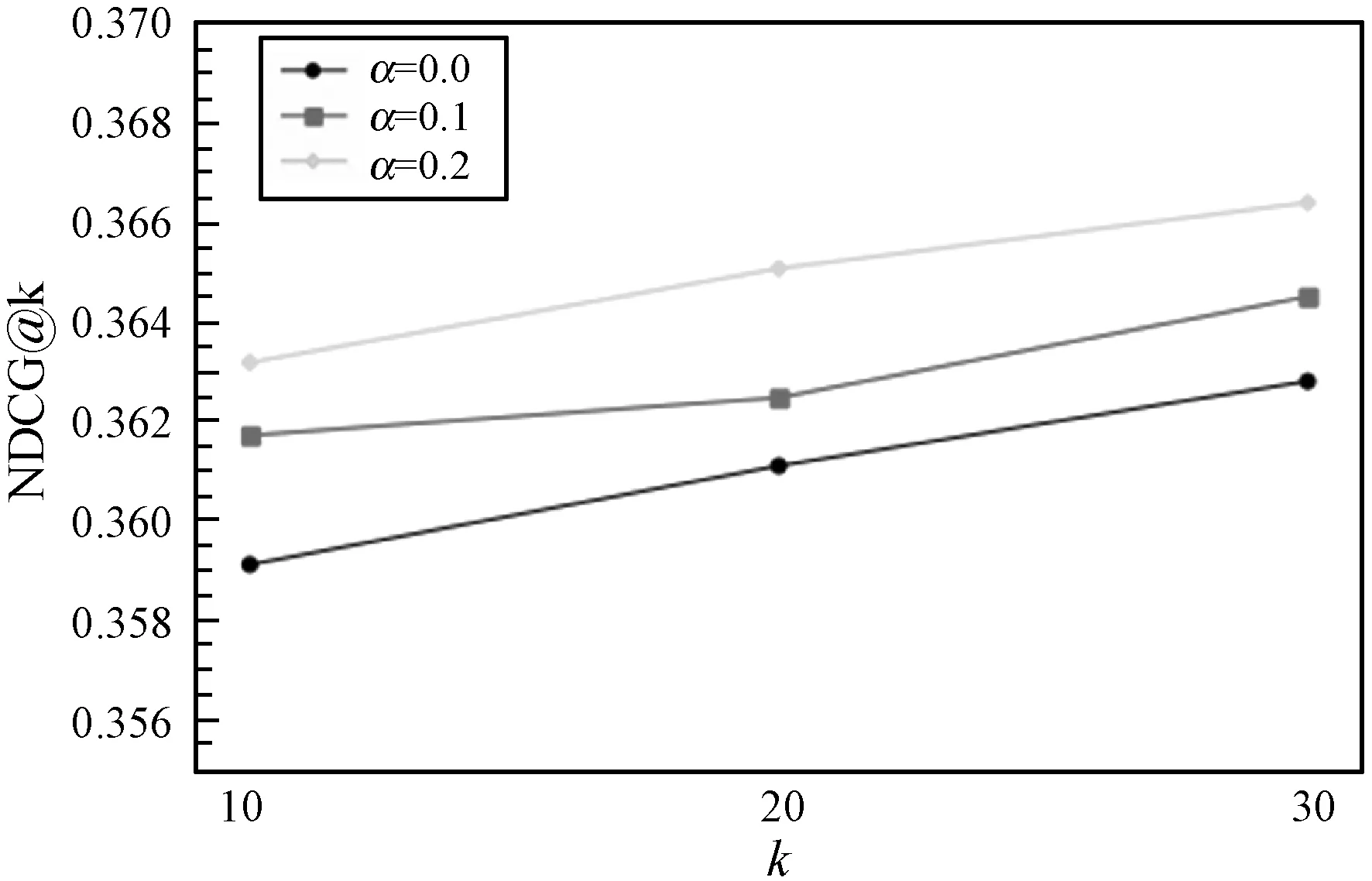
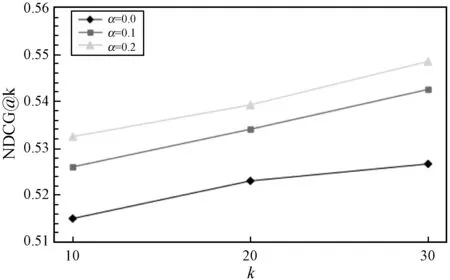
5.ift 6.转移st至st+1; 7.添加(st,at,rt+1)至E的末端; 8.end for 9.返回E; 实验采用MovieLens(10M)和Netflix数据集。MovieLens(10M)数据集包含从MovieLens网站收集的1 000万条用户对电影的评分。Netflix数据集包含从Netflix比赛中收集的1亿条评分。数据集的统计信息如表1所示。 表1 数据集的统计信息 本文对电影推荐中的数据集MovieLens(10M)和Netflix进行实证分析,来验证推荐过程中评分序列模式的存在。两个数据集中均包含许多用户会话,每个会话根据时间戳包含用户对不同项目的评分且两个数据集均为五级评分。假定3分及以上的评分为正面评分,其他评分为负面评分。假设用户u对推荐项目i评分之前有b个连续正(负)评分的评级,将连续正(负)计数定义为b。因此,每一推荐动作可以与特定的连续正(负)计数关联,设置b为1~5,计算具有相同计数b的平均评分。图1-图2给出了在两个数据集下不同连续正(负)计数下相应的平均评分,可以观察到用户评分行为存在的序列模式,即对连续正计数较大的项目用户,倾向于给出线性较高的评分;反之,连续负计数较大的项目用户倾向于给出线性较低的评分。原因可能是用户之前观看的电影越让其感兴趣,用户满意度越高。因此,用户倾向于对当前推荐的电影给予较高的评价。若用户之前观看的电影越让其不感兴趣,用户满意度越低。因此,用户倾向于对当前推荐的电影给予较低的评价。 图1 MovieLens在不同连续计数下的平均评分 图2 Netflix在不同连续计数下的平均评分 所有实验中,由于基于RL的方法的目标是获得最大的累积奖励回报,因此本文使用测试集中用户对推荐项目的平均奖励(Reward)作为一个评价指标。平均奖励指的是测试集中的用户对于算法推荐项目的评价。若平均奖励越大,说明用户对于推荐项目越感兴趣,整体满意度越大;反之则说明用户对于推荐项目越不感兴趣,整体满意度越小。此外,采用了准确性(Precision@k)和归一化折扣累积增益(NDCG@k)作为评价指标。Precision评测推荐的准确性,NDCG评测推荐列表的优劣。算法目标是将用户感兴趣的项目尽量靠前推荐。k分别取10、20和30验证算法效果。对于每个用户,所有评分大于等于3.0的项目都被视为用户感兴趣的相关项目,而小于3.0评分的项目则被视为用户不感兴趣的项目。 将两个数据集分别分为训练集和测试集,其中训练集占80%,测试集占20%。在所有实验中,根据训练经验分别设置学习率η和折扣因子γ为0.02和0.9,奖励函数中的平衡参数α为0、0.1和0.2进行实验。当α=0时,此时奖励函数只考虑用户评分进行推荐。在每个推荐序列中,一旦一个推荐项被推荐给用户后,该项目将会从候选推荐集中删除,避免在一个推荐序列中重复推荐。将提出的SPRR算法同基于MAB的方法HLinearUCB和基于RL的方法DQN-R对比。表2列出了平衡参数取0.2时,SPRR推荐算法和对比算法在平均奖励上的对比结果。 表2 不同数据集的Reward值 由表2可知,因基于RL的方法具有动态交互和长期规划的能力,与基于MAB的方法比较时,基于RL的方法DQN-R和SPRR均获得了较高的平均奖励。在基于RL的方法中,本文提出的SPRR取得了最高的平均奖励,在MovieLens和Netflix数据集上较DQN-R分别提高了24%和28%。分析可知,SPRR取得了较高的平均奖励主要有两个原因:(1) 融合序列模式评分的奖励给SPRR方法加入了额外的用户偏好信息;(2) 与传统的基于RL决策方法不同,本文提出的改进的策略参数更新方法,通过设计的基准可以实现让策略参数沿着有利于产生最高奖励回报的动作的方向移动,可以使用户可能感兴趣的动作得到更高的奖励,学习到更好的推荐策略。 表3列出了随着平衡参数的增大即在算法中不断增加序列模式奖励回报的比重,SPRR推荐算法在两个数据集上的平均奖励的变化,用以验证评分序列模式对算法的影响。由表3可知,随着平衡参数α的递增,SPRR算法在两个数据集上平均奖励均逐渐提高,在Netflix数据集上提高了近71%。表明融合序列模式评分的奖励具有提高SPRR推荐平均奖励的能力。平均奖励的提升,也说明用户对于推荐项目满意度越大。 表3 两个数据集下不同平衡参数的Reward值 图3和图4是随着平衡参数α的递增在两个数据集上SPRR算法准确性。由图3和图4可知,随着α递增,一方面,k取10、20和30时的算法准确性逐渐提高,当k=30时,算法准确性最高;另一方面,在α取0.2时,算法在k取10、20和30时的整体准确性都达到最好的性能。 图3 MovieLens上的Precision@k值 图4 Netflix上的Precision@k值 图5和图6是随着平衡参数α的递增在两个数据集上的NDCG值。由图5和图6可知,随着α递增,本文算法在Netflix数据集上NDCG有较明显的提升,推荐列表的质量较高。在α=0.2和k=30时,算法的NDCG取得最高值,实现尽可能将用户感兴趣的项目靠前推荐,提升用户体验。分析可知,首先增加评分序列模式奖励的比重给算法增加了额外的用户评分偏好信息,使得算法的推荐准确性逐渐提高;其次本文通过奖励反馈信息不断调整推荐策略,k值越大,使用户兴趣被策略参数更好地学习,算法准确性越高。 图5 MovieLens上的NDCG@k值 图6 Netflix上的NDCG@k值 本文提出一种融合序列模式评分的策略梯度推荐算法。一方面,将推荐过程建模为马尔可夫决策过程,设计融合序列模式评分的奖励作为交互式推荐的反馈信息,帮助推荐;另一方面,通过对累计奖励回报设计标准化操作来降低策略梯度的方差,实现提高累积奖励较大的推荐轨迹的出现概率,同时降低累积奖励较小的推荐轨迹的出现概率,学习更优的推荐策略,解决推荐问题。实验结果表明,SPRR推荐算法不仅有效,而且提高了推荐准确性。在以后的工作中,将继续挖掘影响推荐性能的因素,得到性能更优的推荐模型。3 实验与结果分析
3.1 评分序列模式验证
3.2 结果分析

4 结 语
猜你喜欢
数学物理学报(2021年6期)2021-12-21 06:24:38
新世纪智能(数学备考)(2021年9期)2021-11-24 01:14:34
中学生数理化·中考版(2021年3期)2021-07-22 07:41:30
新世纪智能(数学备考)(2020年9期)2021-01-04 00:25:12
中学生数理化(高中版.高考数学)(2020年9期)2020-10-28 08:43:52
应用数学(2020年2期)2020-06-24 06:02:50
成都信息工程大学学报(2019年4期)2019-11-04 00:56:02
阅读与作文(英语初中版)(2019年8期)2019-08-27 03:59:25
数学年刊A辑(中文版)(2018年2期)2019-01-08 01:59:52
小学生学习指导(低年级)(2018年11期)2018-12-03 05:05:00
