
基于卷积神经网络的食品安全领域谣言检测方法
2022-03-18 05:01周丽娜马子豪吕芯悦
计算机应用与软件 2022年3期
周丽娜 谭 励* 曹 娟 马子豪 吕芯悦
1(北京工商大学计算机与信息工程学院 北京 100048)2(中国科学院计算技术研究所 北京 100190)
0 引 言
随着人们生活水平的提高,人们关注的重点从如何吃得饱到如何吃得好、吃得健康。据《2018年网络谣言治理报告》显示,微信平台于2018年拦截的网络谣言共计8.4万余条,其中食品安全领域是谣言传播的重灾区。前两年,福建出现的“塑料紫菜”谣言给整个紫菜加工行业造成了近亿元损失。食品安全谣言不仅会引发产业危机,造成经济损失,更严重的是会引发社会公众恐慌情绪,甚至造成一系列社会事件,危害社会公共安全。
只依靠人工审查的方式进行网络谣言检测,需要耗费大量的人力、物力和财力[1]。在谣言不断涌现的当下,自动谣言检测有着重要的研究价值和广阔的应用场景。本文研究的对象是食品安全领域谣言,这些谣言通常是蓄意捏造有误导大众意图的虚假信息,其数量庞大,多为长文本,涉及丰富的领域知识。目前,没有公开的食品安全领域谣言基准数据集可以用作研究。此外,自动谣言检测方法的主要研究对象是社交媒体上广泛传播的谣言,且多为以微博为代表的短文本。将现有方法直接应用于食品安全领域的谣言数据上,检测效果不佳。
针对上述问题,本文构建一个基于天天快报平台的食品安全领域谣言数据集,经过对数据集进行大量深入的分析,发现食品安全领域的谣言在实体特征层面具有较大的区分性,于是提出一种基于卷积神经网络的食品安全领域谣言检测方法。首先,采用文本卷积神经网络(TextCNN)进行文本特征提取,再采用领域实体抽取策略进行实体特征提取并做归一化处理。然后,将两类特征进行拼接融合。最后,神经网络输出每个样本被判定为谣言的概率,取概率值高的类别作为样本的预测结果。
1 相关工作
Castillo等[2]通过提取基于消息的特征、基于用户的特征、基于主题的特征和传播特征等四种手工特征来判断一条消息的可信度。Ma等[3]和Qazvinian等[4]为了挖掘基于社会特征的谣言进行了类似的研究。例如,在特征选择过程中,Yang等[5]提取事件和客户端程序的位置作为新特征,对微博上的内容进行分类。Jin等[6]关注微博中包含的图片,提出图像特征和统计特征来检测谣言。Zhao等[7]选择一些正则表达式作为谣言模式来识别谣言。Kwon等[8]应用一个情感分类工具对消息中的情感词进行提取,表达正面情感的词、表达感知类的词和表达行为倾向的词对谣言检测有效。
Zhou等[9]在新浪微博上建立实时新闻验证系统,提取谣言事件的一些关键词,并通过分布式数据采集系统收集相关微博。除了应用监督学习算法外,Jin等[10]提出一种发现冲突观点的新方法,基于对推特中观点的识别,构建了一个由支持或反对关系连接起来的消息可信度传播网络。在网络上进行可信度传播,通过迭代演绎产生新闻的最终评价结果。
与传统手工特征相比,深度神经网络可以学习视觉和文本内容的精确表示。Ma等[11]首次将递归神经网络(Recurrent Neural Network,RNN)应用到谣言检测领域,将谣言事件定义为由一系列连续消息组成的流,再将谣言建模成一个变长的时间序列进行特征获取和识别。Guo等[12]根据事件级谣言的数据结构特征,利用基于社交注意力机制的双向长短时记忆(Long Short-Term Memory,LSTM)网络进行建模。Yu等[13]研究表明,在早期的检测任务中循环神经网络性能并不好,并提出了基于卷积神经网络的谣言检测模型(Convolutional Approach for Misinformation Identification,CAMI)。潘浩彬[14]受到文本分类任务中Kim等研究的启发,将文本卷积神经网络应用到谣言检测任务中。
然而,上述方法大都是针对通用领域谣言进行分析建模的,研究的对象大都是微博等篇幅较短的文本,没有关注到不同领域谣言之间的差异性。本文的研究对象是天天快报平台上食品安全领域的谣言,大多为长文本,没有明显的情感倾向,也没有过多的外部信息。所以,要想对此类谣言进行准确判断,就必须从新闻的文字内容上入手。食品安全领域新闻主要涉及食品方面的知识,多以科普的表现形式向读者传递信息。通过对食品安全领域数据集进行大量统计和分析,发现该领域的谣言和非谣言在实体词上存在较大差异,本文的关键就是提取食品安全领域的实体特征,融合卷积神经网络提取的文本特征来提高谣言检测的准确率。
2 定义和数据集
2.1 定 义
常见的谣言定义有两种:(1) 广义定义。谣言是被广泛传播且未经证实的消息。(2) 狭义定义。谣言等同于虚假信息。现有工作[6,12,14]都使用此定义,有时候谣言又被称为虚假消息[15]或者假新闻[16]。根据食品安全领域谣言的特点,本文采用狭义定义。
谣言检测:一个二分类任务,目的是确定社交媒体上的消息是否被确认为真或者假[17]。
2.2 数据集
采集天天快报2016年7月29日到2018年11月30日的所有新闻,共计79 209条数据。对采集的数据进行预处理,每条新闻数据的预处理流程如图1所示。

图1 一条数据预处理的流程
首先,经过人工筛选,过滤掉与食品安全领域不相关且质量低的数据,剩余13 754条。然后,对余下的数据打上可信度标签,标签分为两类,规定0表示非谣言,1表示谣言。为了保证可信度标签的客观性,对每条数据的真实性都进行查证,查证平台有三个,分别是腾讯较真、丁香医生和微信辟谣助手。这三家辟谣平台具有涉及数据多、分类广和权威性等特点。对标为谣言的数据,为其标注出谣言存在的段落。将所有数据经过上述流程,得到谣言数据2 511条,非谣言数据5 898条。但是,由于食品安全新闻数据涉及的领域知识丰富,要查证每条数据包含的所有内容的正确性十分困难,最后有5 345条数据未能确定其类别为谣言或者非谣言。在后续实验时,不考虑这种不确定类别的新闻数据。
对数据集进行统计分析,可得文本的平均长度为840字,内容长度在500到1 500字之间的占比高达72%。数据集中的文本大多涉及日常饮食、医疗药品、保健养生等方面的内容,目的是向读者科普有用的知识。对2 511条谣言数据中高频词的频数生成词云,如图2所示,展示了前100的高频词。其中,食物、作用、导致、身体和症状等词出现频率很高,这些词与食品安全领域的关系更为紧密。

图2 食品安全谣言数据的词云
3 基于卷积神经网络的食品安全领域谣言检测模型
3.1 模型架构
本文提出的基于卷积神经网络的食品安全领域谣言检测模型TCNN-DEC,模型架构如图3所示。模型主要分为三部分:(1) 采用本文提出的领域实体抽取策略提取领域实体特征并归一化;(2) 采用TextCNN模型表示深度文本特征;(3) 将两类特征进行拼接融合,最终输出样本被预测为谣言的概率。

图3 TCNN-DEC模型架构
3.2 领域实体特征抽取策略
不同的领域实体名词在谣言和非谣言中出现的概率存在较大差异,领域实体特征能很好地表现该领域的特点,谣言和非谣言在此层面上有较大的区分度,所以提取领域实体特征是本任务的重点。在食品安全领域中,表示实体的词数量庞大,需要先对其进行归类,再进行后续研究。抽取领域实体特征主要分为三个步骤:(1) 抽取领域实体名词;(2) 构建领域实体类;(3) 基于统计得到领域实体特征。整个过程都是自动化进行的,无需人工干预。
(1) 抽取领域实体名词。首先,对数据集中每条数据进行预处理,包括分词、去停用词。再做词性标注,用到的分词工具是HanLP。根据实体都是名词的特点,取出所有标注为名词性的词语,组成一个实体词集。在此实体词集中,除了包含食品安全领域的实体词,还包含大量与该领域相关性较小的实体词。然后,利用文本特征选择的三种方法对预处理后的样本数据进行特征选择。但是得到的特征词不能保证全为名词,所以用实体词集对上述特征词分别进行筛选,再对剩余的三组特征词进行相互筛选。最后,取筛选得到的前250个词作为领域实体名词。具体流程如图4所示。
其中,用到的特征选择方法有文档频率(DF),即计算数据集中有多少样本包含这个词。在实验中,可以先去掉某些无意义的词,即把DF小于5且大于3 000的词去掉,因为它们分别代表了没有代表性和没有区分度两种极端情况。将每个词按照文档频率值从大到小排序,选取前3 000个词作为特征词。
用信息增益(IG)方法选择特征词,提取步骤如下:先统计正负分类的文档数N1和N2;统计每个词的正文档出现频率A、负文档出现频率B、正文档不出现频率C、负文档不出现频率D;计算信息熵,公式如下:
(1)
计算每个词的信息增益:
InfoGain=Entropy(S)+
(2)
将每个词按照信息增益值从大到小排序,选取前3 000个词作为特征词。
前两种方法都是考察特征对整个数据集的贡献,没有具体到某个类别上,它们只能做全局特征,但谣言和非谣言分别存在各自的特征集合,所以再用卡方值(CHI)选择文本特征。先统计数据集中样本的总数量N,再统计计算A、B、C和D值(含义同上)。每个词的卡方值计算式表示为:
(3)
将每个词按卡方值从大到小排序,选取前3 000个词作为特征词。
(2) 构建领域实体类。经过上一步得到领域实体名词后,需要对其进行归纳整合得到领域实体类。要实现这步操作,需要用到词向量(Word2Vec)和无监督的聚类算法。首先,将250个实体词通过词向量映射得到相应的向量表达。然后,将其作为K-Means算法的输入并进行聚类。实验汇中先给K值事先设定一个范围[1,20],然后根据误差平方和(SSE)这个指标来确定最终的K值。SSE的计算式表示为:
(4)
式中:Ci是第i个簇;p是Ci的样本点;mi是Ci中所有样本的均值;SSE代表了聚类效果的好坏。在实验中,当K=10时,SSE值较小且变动幅度已经慢慢变小,故将食品安全领域实体分为10类。
(3) 提取领域实体特征。经过上一步,得到10个食品安全领域的实体类。分别统计这10个实体类包含的实体名词在一个样本中出现的总次数作为实体特征,每一个样本都可得到10维特征。将特征归一化到区间[0,1],再通过激活函数tanh,表示为fv。
3.3 基于文本卷积神经网络的特征提取
TextCNN是由Kim[18]于2014年提出的,将卷积神经网络应用到文本分类任务中,利用多个不同的尺度的卷积核来提取句子中的关键信息,从而更好地捕捉局部相关性。此外,在计算效率上同循环卷积神经网络(RNN)及其变种结构LSTM、GRU[19-21]等方法相比,它的并行效率更高、训练速度更快。
TextCNN深度文本特征提取模型架构如图5所示。通常先将文本利用分词工具进行序列化,利用词向量将文本构建成矩阵的表示,矩阵的维度为(N×K),其中:N表示该文本单词的数量;K表示词向量的维度。假设存在一个长度为N的文本序列T,将T表示为[w1,w2,…,wN],有词向量矩阵E∈R|V|×K,|V|表示字典的大小。通过字典查询的方式,可以找到wi对应的词向量xi,最终将得到的词向量按列拼接得到大小为(N×K)的矩阵X,表示为:

图5 TextCNN深度文本特征提取模型
X=x1:N=x1⊕x2⊕…⊕xN
(5)
然后,网络为了获取不同粒度的序列局部特征,设置了长度为(2,3,4)的等宽卷积核,其中每种长度的卷积核包括M个。卷积操作的过程表示为:
convi=f(w·xi:i+h-1+b)
(6)
式中:h表示卷积核的长度;K则表示卷积核的宽度;w为卷积核的权重;b为偏置项;函数f表示非线性激活函数ReLU。对于一个(h×K)大小的卷积核,通过卷积操作得到的特征图大小为(N-h+1,1)。这个过程可以看作利用卷积核进行h-gram特征的抽取过程,特征图的向量表示为:
c=[c1,c2,…,cN-h+1]
(7)
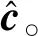

(8)
(9)
通过卷积池化的操作之后,得到文本消息的深度表征向量r,优化参数包括θ={W;wf;bf},其中:W为词向量矩阵;wf和bf分别表示卷积核的权重参数和偏置项。
实验采用Word2Vec模型将预处理后的新闻数据表示为d个词向量x1,x2,…,xd,d是文本的最大长度。实验采用基于新浪微博语料训练的Word2Vec模型,词向量维度为300维,w∈R300。x1,x2,…,xd通过TextCNN的卷积和池化过程得到文本特征向量xv。
3.4 特征融合及分类
将文本特征向量xv和领域实体特征向量fv,通过向量拼接的方法融合得到向量v,表示为:
v=xv⊕fv
(10)
最后,将v输入一个全连接层得到向量v′,对v′进行Softmax分类得到一组得分p,选择p中数值较大的所代表的类别作为分类结果。v′和p的计算式分别表示为:
v′=ReLU(wv+b)
(11)
p=Softmax(v′)
(12)
TCNN-DEC模型采用交叉熵损失函数来度量预测值和真实值之间的距离。在输入样本数据后,模型计算得到损失并以最小化该损失为训练目标。交叉熵损失函数计算式表示为:
(13)
式中:M表示训练数据;ym表示m的真实标签;pm表示m的预测为谣言的概率。
4 实验与结果分析
4.1 数据集
取2.2节介绍的数据集中全部谣言样本和数量相等的非谣言样本构成本实验的数据集,共计5 022条。训练集和测试集的划分比例为4 ∶1。
4.2 实验设置
(1) NB模型[2]:采用TF-IDF方法进行特征表示,使用朴素贝叶斯模型对样本进行分类。
(2) SVM模型[5]:采用TF-IDF方法进行特征表示,使用线性支持向量机对样本进行分类。
(3) BiLSTM模型[12]:采用300维的Word2Vec模型将文本转换为词向量形式,文本的最大输入长度为1 500,LSTM模型隐层单元数为128,学习率为0.001。
(4) TextCNN模型[18]:采用300维的Word2Vec模型将文本转换为词向量形式,文本的最大输入长度为1 500,TextCNN模型卷积核的长度分别为2、3和4,每种卷积核的数量为200个。Dropout的概率为0.5。
(5) BiLSTM-DEC模型:参数设置与BiLSTM模型相同。
(6) TCNN-DEC模型:参数设置与TextCNN模型相同。
其中,NB模型和SVM模型采用五折交叉验证求平均的方式得到最终结果。BiLSTM-DEC模型和TCNN-DEC模型均为融合了领域实体特征的神经网络模型。神经网络模型的参数优化采用Adam[22]优化方法进行更新,模型的输入数据将进行整体随机重排,设置每一批次训练256个样本。
对于评估指标,本文采用准确率、精确性、召回率和F1值进行综合评价。
4.3 结果分析
为了验证本文方法在食品安全领域谣言检测任务中的有效性,将本文方法和现有通用谣言检测方法在同一食品安全谣言数据集上进行实验,各模型的准确率如表1所示。

表1 各模型准确率对比
本文提出的基于卷积神经网络的食品安全领域谣言检测模型TCNN-DEC达到了最高的准确率87.7%。由此可见,本文方法对食品安全领域谣言检测十分有效。BiLSTM模型和TextCNN模型判别的准确率都高于NB模型和SVM模型,说明用深度神经网络模型拟合复杂数据,可以提高谣言检测的性能。BiLSTM模型和TextCNN模型分别融合领域实体特征得到BiLSTM-DEC模型和TCNN-DEC模型,BiLSTM-DEC模型和TCNN-DEC模型实验的准确率都高于没有融合领域实体特征的模型,这说明了领域实体特征对食品安全类谣言的检测具有重要作用。
表2和表3分别展示了各模型针对谣言和非谣言两类数据判别时性能的差异。TCNN-DEC模型在对谣言和非谣言的判别上,精确性、召回率、F1都比其他方法高。BiLSTM-DEC模型对谣言判别的F1值为85.5%,对非谣言判别的F1值为86.2%,分别比TCNN-DEC模型对应指标低2百分点和1.7百分点,这也是本文方法选择TextCNN模型提取深度文本特征的原因。在食品安全领域数据集上,BiLSTM模型的性能不如TextCNN模型的高,可能的原因是,食品安全类的新闻数据大多为长文本,BLSTM模型在处理过长的文本时,长距离依赖的问题会比较突出,TextCNN模型不存在此问题。

表2 谣言数据的各模型性能对比

表3 非谣言数据的各模型性能对比
5 结 语
本文针对社交媒体上食品安全领域谣言体量大、检测困难这一现象展开研究。首先构建一个食品安全领域谣言数据集,确保本实验能顺利进行,也为以后的研究提供便利。由于现有谣言检测方法对特定领域谣言的判别效果差,本文提出基于卷积神经网络的食品安全领域谣言检测方法,利用领域实体特征抽取策略得到K维实体特征,再与文本卷积神经网络表示的深度文本特征进行拼接融合,最后进行分类。使用本文方法明显地提高了谣言检测的准确率,表明该方法很适用于食品安全领域的谣言检测。本文实验用到的食品安全谣言数据集的可信度标签是篇章级的,但大多数样本的谣言部分只存在于某一段或某几段中,其余段落则可以忽略。但由于段落级标注成本太大,所以下一阶段,将针对长文谣言进行分段研究。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
舰船科学技术(2022年11期)2022-07-15
中国教育信息化·高教职教(2022年4期)2022-05-13
计算技术与自动化(2022年1期)2022-04-15
环球时报(2022-04-13)2022-04-13
煤气与热力(2022年2期)2022-03-09
小雪花·小学生快乐作文(2020年4期)2020-10-12
上海师范大学学报·自然科学版(2019年5期)2019-12-13
民生周刊(2017年22期)2017-12-12
软件(2017年6期)2017-09-23
