
改进YOLOX 火灾场景检测方法的研究*
2022-03-17 10:17张剑飞
计算机与数字工程 2022年2期
张剑飞 柯 赛
(黑龙江科技大学计算机与信息工程学院 哈尔滨 150022)
1 引言
传统的火灾检测有基于烟雾和温度的传感检测,也有通过电动阀和排气阀的数据检测。随着深度学习的发展,喻丽春[1]等使用改进的Mask R-CNN,通过自下向上的特征融合以及改进的损失函数实现对火焰的高精度检测。吴凡[2]将YOLOv3[3]的主干网络替换为Densenet121 提升网络对火焰和烟雾的特征提取能力,并引入Focal Loss。赵民[4]等提出基于CenterNet[5]算法的复杂环境目标检测技术。李欣健[6]等使用深度可分离卷积来改进火焰检测模型,并使用多种数据增强技术提高检测精度。雒朝辉[7]使用基于YOLOv4框架的无人机进行实时火焰检测。
然而上述方法的模型相对复杂,计算量大,检测目标单一,难于部署。为解决这些问题,本文提出了一种改进的T-YOLOX 检测模型,对火灾场景下的火焰、烟雾以及受灾人员进行检测。
该方法基于YOLOX[8]架构,结合轻量级注意力模块对每个通道权重做调整,从而提升网络整体的特征提取能力;添加通道混合模块,提高各通道间交流能力,抑制过拟合;将主干网络最后一层换为MobileViT[9]模块,使用这个轻量级的Transformer[10]模块来增强主干网络对全局特征的学习能力。通过实验,验证了本文方法的有效性和优越性。
2 相关工作
2.1 YOLOX
YOLOX 是YOLO 系列工作之一,综合了YOLO系列网络优点,摆脱先验框约束,使用YOLOv4[11]的特征提取网络CSPDarknet 架构,引入YOLOv5 的Focus通道增广技术,运用Mosaic数据增强,创新的加入解耦预测头和SimOTA动态正样本匹配方法。
2.2 Transformer
Transformer 作为近期具有开创性的第四代神经网络,在CV领域产生了巨大的影响。先是ViT[12](Vision Transformer)将图片视为文本进行处理,取得了极佳的效果。而后BoTNet[13]用Transformer 模块替换卷积神经网络(Convolutional Neural Networks,CNN)最后一层,强化了主干网络对全局信息的捕捉能力。
3 改进的YOLOX算法:T-YOLOX
尽管YOLOX 已经具有了良好的检测性能,但针对本文所要解决的问题,仍然存在以下改进方面。
1)YOLOX 的CSPLayer 层包含大的残差边,残差操作在有效避免深层网络梯度消失的同时会将夹杂的噪声一同送入深层网络,这会对主干网络的训练产生影响。
2)残差操作会将输入特征拼接到输出特征上,但是单纯地对特征层进行拼接操作,效果并不理想,会存在通道信息难以良好融合的问题。
3)YOLOX 使用基于CNN 的CSPDarknet 主干网络。通过卷积核捕捉局部特征信息,但这样会忽视全局特征信息之间的关系。
因此,针对YOLOX在火灾场景检测上的不足,本文提出T-YOLOX模型,其模型架构如图1所示。

图1 T-YOLOX模型架构
3.1 轻量级注意力模块
残差操作会将不必要的噪声带入下一层网络,对网络训练产生影响。本文在CSPLayer 上添加轻量级注意力模块,通过对残差边施加注意力,进而对每个通道权重做调整,以此来削弱噪声对网络训练的影响。
其原理是通过特征融合和残差变换在强化通道信息的同时弱化噪声影响。模块主要包含三个分支,X1 首先借助全局均值池化(AvgPool)操作压缩高维特征,随后通过全连接层(fully connected layers,FC)以及δ(ReLU)激活函数对特征做FX1压缩操作,如式(1):
随着我国政府积极推广PPP模式,降低了电力设计企业进入非电行业的门槛,除了参与PPP项目的设计和咨询业务,还能与其他企业组建联合体作为投资方参与PPP项目的建设和运营,获得稳定的投资收益和工程收益,实现多元化发展。
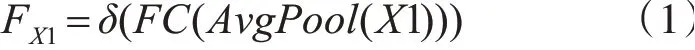
完成后再通过全连接层(FC)以及σ(Sigmoid)激活函数做扩展得到FX2,并将最终抽取的注意力权重FX2施加到X2上,过程如式(2)、(3)所示:

另外Input 会在堆叠的残差块上的进行特征提取操作得到X3,最后X2 与X3 通过拼接(⊕)操作汇聚在一起。轻量级注意力施加流程如图2 所示。

图2 轻量级注意力施加流程
3.2 Channel Shuffle通道混合技术
引入Channel Shuffle[14](CS)模块,对完成拼接操作的特征层做通道混合操作,以此来提升通道间交流。特征层拼接操作如式(4)所示:


该方法在相同的计算资源下,能强化通道间交流能力,避免过拟合,具体演示流程如图3所示。

图3 Channel Shuffle演示流程
3.3 轻量级Transformer:MobileViT
将主干网络最后一层替换为MobileViT Block,以此来提升网络对全局以及局部信息的感知能力,强化主干的特征提取能力。MobileViT Block 对给定输入特征X∈RH×W×C(其中C、H、W分别表示张量的通道、高度和宽度)先后使用n×n卷积(n=3)编码局部空间信息以及1×1 卷积将张量投影到高维空间(d 维,其中d>C),进而调整得到XL∈RH×W×d,接着对特征做通道展平(Unfold)操作得到XUnfold∈RP×N×d其中P=w·h,P代表宽(w)高(h)的patch像素数(w≤n,h≤n),N=HW÷P,N代表patch 的总份数,随后通过Transformer 模块对patch 间信息进行编码,得到XG∈RP×N×d,操作如式(6)所示:
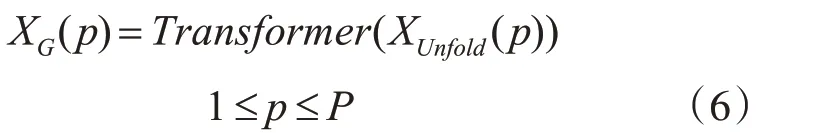
为避免丢失patch 之间的位置信息以及每个patch 内部的像素信息,随后将XG∈RP×N×d重新堆叠(Fold)还原得到XFold∈RH×W×d。然后将XFold送入1×1 卷积网络,将其投影到低维空间(C 维)得到X͂∈RH×W×C,通过将X͂ 与X拼接(Concat)得到X̂∈RH×W×2C,最后利用n×n卷积(n=3)融合局部特征X͂与全局特征X获得输出Y∈RH×W×C。MobileViT Block的结构如图4所示。

图4 MobileViT Block整体结构
4 实验
4.1 数据集
针对早期火焰数据集图像分辨率不高,信息反馈能力偏弱的问题。本文自制了火灾数据集,检测内容包含火焰、烟雾以及受灾人员三类。从网络上搜取火灾相关的数据,将采集到的数据进行筛选后整理出5000 张照片。使用LabelImg 工具构建火灾数据集,数据集包含Fire、Smoke、Person 三类,图像的标注信息会保存在xml文件中。
关于本次实验使用的火灾数据集,共有火焰标注7000 个左右,烟雾以及人员的标注2000 个左右。借助可视化数据图5(a)可以看出目标框中心位置分布均匀,图5(b)显示目标框相对图片的占比程度。不难发现,标注数据的分布和占比均匀且多样。
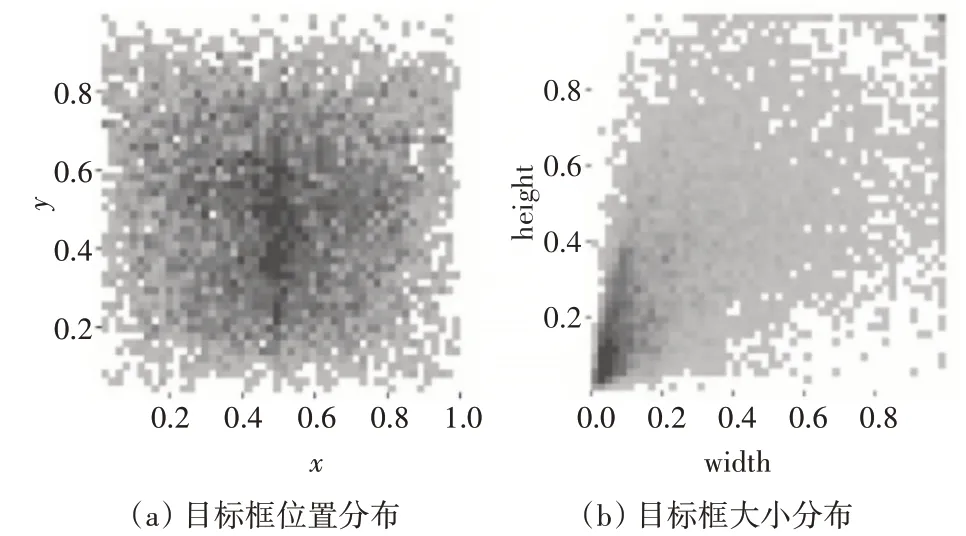
图5 数据可视化
4.2 数据增强
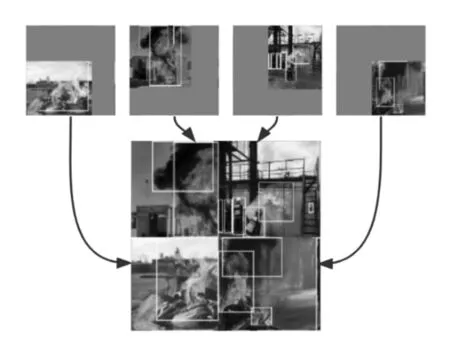
图6 Mosaic数据增强
4.3 实验环境
本次实验在Python3.8,CUDA11.1,PyTorch 1.9.1 环境上进行。 所有模型均在NVIDIA RTX3060 GPU上进行训练和测试。
在网络训练前,对模型使用了Kaiming 初始化[15]。训练时,数据集按照8∶2 划分为训练集和测试集,并从训练集中抽取10%作为验证集,输入的图片张量为(640,640,3),使用Adam优化器以及余弦退火学习率进行训练,训练批次为4,初始化学习率为0.0001,训练总共进行300次迭代。
4.4 评估指标
本文采用目标检测模型常用评估指标mAP(Mean Average Precision)以及FPS(Frames Per Second)进行模型评估。AP 指PR(Precision-Recall)曲线下面积、mAP 指每个类别AP 的均值,AP 以及mAP 值越大越好。Precision 和Recall 的计算公式如式(7)~(8)所示:
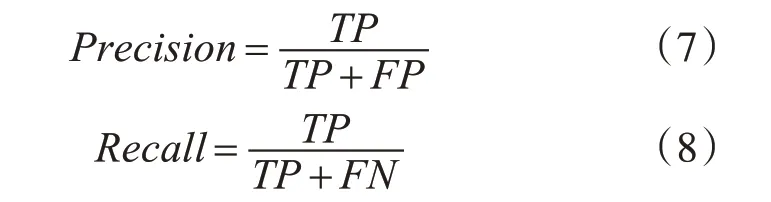
TP(True Positives)表示被分为正样本,且分对的;FP(False Positives)表示被分为正样本,但分错的;FN(False Negatives)表示被分为负样本,但分错的。
4.5 实验设计与结果分析
关于实验,T-YOLOX 模型的训练损失如图7所示。通过该图可以发现,随着训练轮数的不断增加,Loss 曲线逐渐趋于平稳。当Epoch 达到200 左右后,模型逐渐收敛,训练过程未出现过拟合现象。
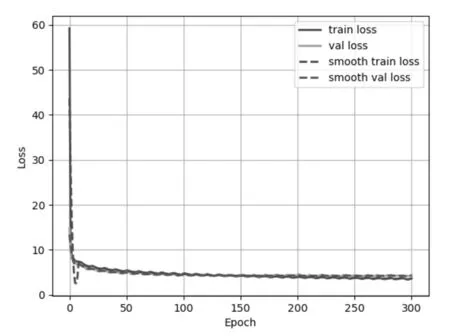
图7 Loss曲线
本文共设计了一组消融实验和一组对比实验,为符合模型部署要求,本次实验选取“-s”轻量级规格。通过消融实验检验本文不同改进部分对网络性能的影响,随后再通过T-YOLOX 与主流网络(CenterNet、YOLOv3)的对比实验,综合分析模型性能。
4.5.1 消融实验
为分析本文改进部分对模型性能的影响,共设计三组实验对不同的改进进行分析,每组实验均在相同训练参数,不同模型内容上进行测试。模型性能检测结果如表1 所示,其中“√”代表在改进模型中使用的策略,“×”代表在改进模型中未使用的策略。对表1 进行分析可见:改进1 添加Channel Shuffle 模块提高了通道间交流能力,避免了过拟合,mAP 有所提升。改进2 在此基础上添加轻量级注意力模块,引入注意力加强边后,提升了通道对空间信息的注意力,同时弱化噪声对深层网络的影响,mAP 提升了1.05%。改进3 加入MobileViT 模块,将CNN 与Transformer 进行融合,以此实现主干网络对局部以及全局信息的学习能力,mAP提升了1.02%。

表1 不同改进方法的实验结果
4.5.2 模型对比
为了验证T-YOLOX 改进模型的检测性能,将其与主流目标检测模型YOLOv3、CenterNet、YOLOX 做对比实验,对比实验结果如表2 所示。由表2分析可知,T-YOLOX算法的mAP 达到了69.54%,较原始YOLOX 算法提高了2.24%,结合表中Fire、Somke、Person 三类的平均AP 值进行分析可得,本文方法检测火焰、烟雾以及受灾人员的AP 值比原始YOLOX 算法均有不同程度的提高,相比其他主流目标检测模型(CenterNet、YOLOv3)具有更好的检测性能。同时在检测受灾人员方面T-YOLOX有明显的优势,在保证高精度检测的同时,模型的FPS 并未出现大幅度下降,检测速度与主流模型相比仍然具有一定优势。
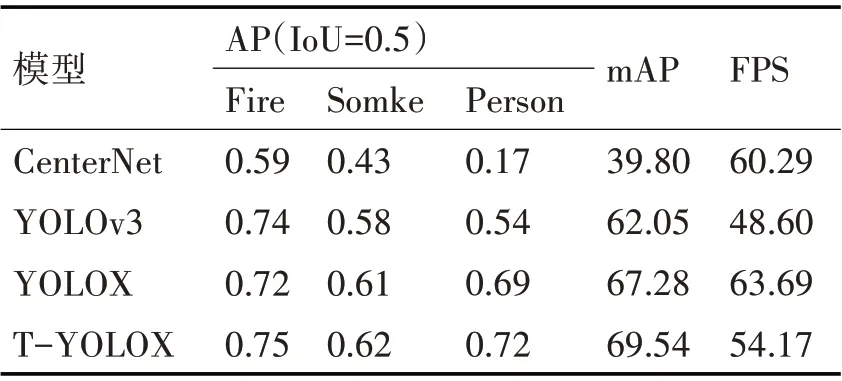
表2 主流目标检测模型性能对比
5 结语
本文针对现有目标检测模型难以在复杂火灾场景下对火灾场景进行及时高效的反馈问题,提出了一种改进YOLOX 的火灾场景检测模型T-YOLOX。该方法在YOLOX 模型基础上,引入了强化通道交流能力的Channel Shuffle 模块,施加通道注意力权重的CSPLayer_attention 模块,以及将CNN与Transformer相融合的MobileViT模块。检测效果如图8 所示。实验表明,本文所提出的检测方法,针对复杂火灾场景有良好的性能表现。

图8 T-YOLOX检测效果展示
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
广东教育·高中(2022年1期)2022-03-16
河南教育·基教版(2017年8期)2017-09-08
第二课堂(课外活动版)(2016年2期)2016-10-21
文理导航·趣味课堂(2016年6期)2016-09-09
故事作文·高年级(2009年7期)2009-08-20
中学英语之友·高一版(2008年10期)2008-12-11
中学理科·综合版(2008年3期)2008-03-07
