
基于SPA-SSA-BP的小麦秸秆含水率检测模型
2022-03-14 07:57孟志军刘淮玉安晓飞尹彦鑫金诚谦张安琪
农业机械学报 2022年2期
孟志军 刘淮玉 安晓飞 尹彦鑫 金诚谦 张安琪
(1.黑龙江八一农垦大学工程学院, 大庆 163319; 2.国家农业智能装备工程技术研究中心, 北京 100097; 3.北京市农林科学院智能装备技术研究中心, 北京 100097; 4.农业农村部南京农业机械化研究所, 南京 210014)
0 引言
秸秆是农业生产过程中重要的生物质资源,其富含氮、磷、钾、镁、钙等重要元素以及粗纤维和有机质,是一种具有多用途的可再生生物资源,具有很大的利用价值。对秸秆资源的开发利用,不仅可有效改善人居环境,还能在一定程度上缓解全球能源紧缺的问题[1-2]。含水率是衡量秸秆品质的重要指标,含水率在一定程度上决定了秸秆的利用价值[3-5]。由于过去对其不够重视及缺乏相关检测技术,常造成不必要的经济损失和资源浪费。因此,研究一种快速、准确的小麦秸秆含水率检测方法,对于秸秆资源的高效利用具有重要意义。
目前,应用于秸秆含水率检测的方法主要有电容法、电阻法、近红外光谱法、微波法等。皇才进等[6]采用近红外光谱技术结合LOCAL算法建立秸秆含水率(5.13%~20.44%)和热值的近红外光谱模型;FALBO[7]基于电阻法设计了平面极板式含水率在线检测系统;万舟等[8]基于微波法通过对微波的衰减量和相移量的测量可测得秸秆的水分含量;郭文川等[9]基于电容法探究秸秆含水率(10.6%~19.6%)、温度(5~35℃)和容积密度(77.2~103.6 kg/m3)对输出电容的影响;FONSECA等[10]采用近红外光谱仪对秸秆含水率进行检测,研究表明旋转扫描方法检测精度更加稳定。其中,电容法具有适应性强、可靠性高、动态响应性好和结构简单易维护等优点[11],是目前农业物料含水率检测的主要技术手段。
基于电容法的秸秆含水率检测研究多考虑温度、含水率对电容的影响,较少考虑容积密度因素,且已有模型多为线性模型[9],存在容积密度适用上限低、含水率检测范围窄等问题。基于此,本文采用电容法原理,通过设计电容采集装置,使用LCR数字电桥采集不同含水率小麦秸秆在不同频率、不同容积密度与不同温度下的电容数据,采用BP神经网络结合特征频率筛选算法构建秸秆含水率定量分析模型,并引入麻雀搜索算法(SSA)对模型进行优化,分析模型的预测效果,确定小麦秸秆含水率的最佳建模方法。以实现小麦秸秆含水率的快速、准确定量分析。
1 材料与方法
1.1 试验材料
以小麦秸秆为试验对象,秸秆样本于2021年6月在国家精准农业研究示范基地采集。由于试验盒内部尺寸为180 mm×125 mm×70 mm,为保证每份装入盒中的样本密度均匀,不因过于疏松或致密导致试验盒中不同样本的质量差距过大,因此将采集的秸秆粉碎成长度(30±5) mm的枝干状,并随机分为56个样本,每个样本80 g,装于自封袋中保存在25℃的室温环境下。
1.2 试验方案
1.2.1电容采集装置设计
电容采集装置结构如图1所示,主要包括亚克力试验盒, TH2830型LCR数字电桥及配套数据采集软件(常州同惠电子股份有限公司),DHG-9240A型鼓风干燥箱(上海一恒科学仪器有限公司),WDW-01S型微机控制电子万能拉压力试验机及配套软件(常州三丰仪器科技有限公司),MTB2000D型精准电子天平(深圳市美孚电子有限公司),西玛-AT1150型红外线测温仪(东莞万创电子制品有限公司)。
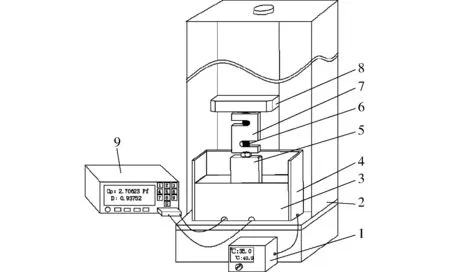
图1 电容采集装置结构示意图Fig.1 Schematic of capacitance acquisition device1.温控箱 2.拉压力试验机 3.亚克力试验盒 4.硅橡胶加热板 5.支柱 6.螺栓 7.拉压力传感器 8.升降台 9.数字电桥
亚克力试验盒内部尺寸为180 mm×125 mm×70 mm,将待测秸秆在亚克力试验盒内填满,为使得秸秆样本各处受力均匀,将压板覆盖于秸秆样本上;设计2块尺寸为120 mm×50 mm×2 mm的铜板对称布置在试验盒底部,二者相距3 mm,用于采集秸秆电容数据;设计硅橡胶加热板包裹在试验盒外壁,通过调节温控箱按钮,预设试验环境温度,达到改变试验盒内温度的目的;用螺栓将试验机压力台、拉压力传感器和支柱连接到一起,通过上位机软件控制试验机压力台升降,实现对试验盒内秸秆压力的调控,以达到改变秸秆容积密度的目的。
1.2.2样品制备
从秸秆样本中随机取出1份并置于105℃的电热鼓风干燥箱中4 h至质量恒定,测得小麦秸秆的初始湿基含水率为10.43%[12]。为配制不同含水率的样本,取56个(每个80 g)秸秆样本,通过添加不同质量的去离子水,得到56个不同含水率的样本并编号。为保证样品吸收水分均匀,将配好的样品装入PE自封袋中,置于25℃的室温环境下1~2 d。期间每天取出样本2~3次,充分搅拌后倒回袋中,以使水分分布均匀。
1.2.3数据获取
电容数据采集前,先将室内温度调至25℃恒定,将LCR数字电桥测量电极与2块铜板外接线相连,再开机预热30 min并校准清零。采集时,由于试验盒容积所限,从样本中取出40 g左右秸秆填满试验盒即可,剩余样本装回袋中继续密封;通过温控箱将试验环境温度依次设置为25、30、35、40℃,使用手持式红外线测温仪对电容采集装置内部温度进行定期测量;通过万能拉压力试验机改变对秸秆压力的方式来调节秸秆的容积密度,将试验机对秸秆的压力设置在500~3 600 N之间,故秸秆的容积密度在90.08~179.42 kg/m3范围内,每个秸秆样本在同一温度下从上述容积密度范围内随机选取3个容积密度,确保所有样本组合选取的容积密度在90.03~179.42 kg/m3之间均匀分布;在0.05~100 kHz共取100个呈对数正态分布的频率点,作为LCR数字电桥的检测频率,测量待测秸秆样本在上述不同容积密度、温度、频率点组合下的电容数据。
秸秆含水率测量装置主要由电子天平、电热鼓风干燥箱组成。测量前,先将电子天平开机预热15 min后并校准清零,测量时,将试验盒中样本与自封袋中剩余样本充分混合后分为2份,并分别置于105℃的电热鼓风干燥箱内干燥4 h,根据干燥前样本的鲜质量与干燥后样本的干质量可计算出各样本的实际含水率。
1.4 数据处理及建模方法
1.4.1样本集划分
试验共配制了56份样本,样本的湿基含水率在10.43%~25.89%之间,每个样本又在4个温度及3个容积密度条件下分别采集100频率点下的电容,共得到672组电容数据。通过对数据进行观察,采用马氏距离法剔除一些因仪器设备和试验操作原因产生的异常数据,剩余656组数据。采用留出法,随机选取样本数据中3/4的数据作为建模的校正样本,另外1/4的数据作为测试样本。划分结果见表1。
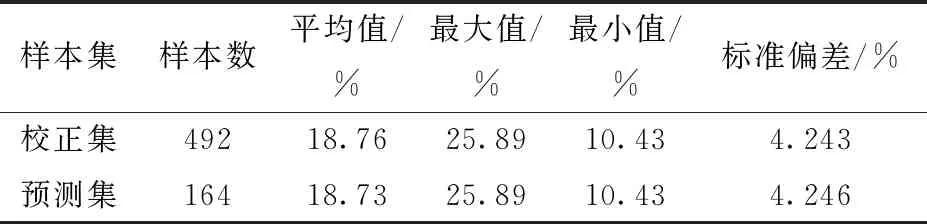
表1 校正集和预测集统计结果Tab.1 Statistics results of moisture content in calibration and prediction sets
1.4.2数据处理方法
因研究中所选的多个频率间可能会存在较强的线性相关,它们会包含较多的冗余信息,增加模型的复杂度,通过特征提取方法能够从原始数据中提取主要信息,达到在不损失过多原频率信息的基础上,降低模型的复杂程度[13-14]。本研究采用连续投影法(SPA)及主成分分析法(PCA)来选取特征频率。SPA是一种能够有效解决变量间共线性问题的变量筛选方法,利用向量投影可优选出冗余度低、共线性小又能反映样本频谱重要信息的特征频率。PCA是一种被广泛使用的数据降维算法。其主要思想是通过某种线性投影,将高维空间的数据映射到低维空间中,并通过计算特征频率的方差优选出信息量大的特征频率,以达到使用较少的数据维度就可保留住较多信息的目的[15]。PCA是对频谱数据进行主成分分析,在累计贡献率大的前几个主成分相应的权值系数曲线中,权值系数的绝对值与其相对应频率的贡献程度成正比,故选择曲线中波峰和波谷处对应的频率为特征频率[16]。
1.4.3建模方法
常用的建模方法主要分为线性方法和非线性方法。线性建模方法主要有偏最小二乘回归(PLSR)、多元线性回归(MLR)和主成分回归等;非线性建模方法主要有支持向量回归(SVR)[17]、BP神经网络等。考虑到试验数据量大,线性建模方法不能很好地拟合非线性数据,支持向量回归(SVR)不善于处理大量数据。因此,本文选用适合处理大量数据,并且非线性拟合能力强的BP神经网络建立含水率检测模型。
BP神经网络是一种多层前馈神经网络。该算法处理信息的神经元可分为3层:输入层、隐含层、输出层,每层的神经元状态只影响下一层神经元状态。其主要特点是信号向前传递,误差反向传播,通过反向传播来不断调整网络的权值和阈值,使神经网络的误差平方和趋于最小[18],该算法具有很强的非线性映射能力,可映射任意复杂的非线性关系,并具有很强的鲁棒性和自适应能力。
影响小麦秸秆电容的主要因素有秸秆含水率、容积密度和环境温度,因此,设定小麦秸秆容积密度、环境温度和选取的特征频率为神经网络的输入参数,小麦秸秆含水率为输出参数,如图2所示,采用单隐含层的3层网络结构,隐含层节点数计算公式为
(1)
式中n——输入层节点数
l——隐含层节点数
m——输出层节点数
a——1~10之间的常数
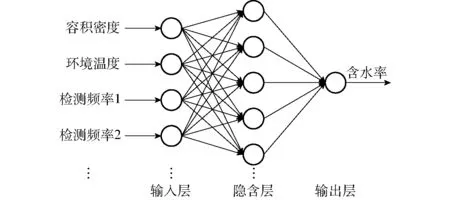
图2 BP神经网络结构Fig.2 BP neural network structure
通过反复试验确定输入层到隐含层的传递函数为S型正切函数tansig,隐含层到输出层的传递函数为线性函数purelin。常用的训练函数包括trainlm、trainrp、trainscg等,其中trainlm具有收敛速度快、误差小、训练效果优的特点,因此本文采用trainlm作为训练函数[19]。
BP神经网络训练前,为减弱各主控因素不同量纲的数据对网络模型训练与预测值的影响,各主控数据做归一化处理。计算式为
(2)
式中x——原始数据y——归一化值
xmax——同一影响因素响应值的最大值
xmin——同一影响因素响应值的最小值
ymax——归一化最大值,取1
ymin——归一化最小值,取0
1.4.4麻雀搜索算法优化BP神经网络模型
麻雀搜索算法(SSA)是一种新型的群智能优化算法,该算法主要是受麻雀觅食行为和逃避捕食者行为启发而设计[21-24]。麻雀在觅食过程中会分为3种类型:发现者、加入者和侦察者,利用这三者间的关系及麻雀遇到捕食者时的行为可达到优化搜索的目的。同近年来新兴的群智能优化算法相比,麻雀搜索算法具有较好的全局搜索和局部开发的能力,在寻优过程中,能促进麻雀种群向全局最优值移动,有效避免易早熟收敛、收敛速度慢等缺点,具有良好的鲁棒性和收敛速度。整体过程如图3所示。
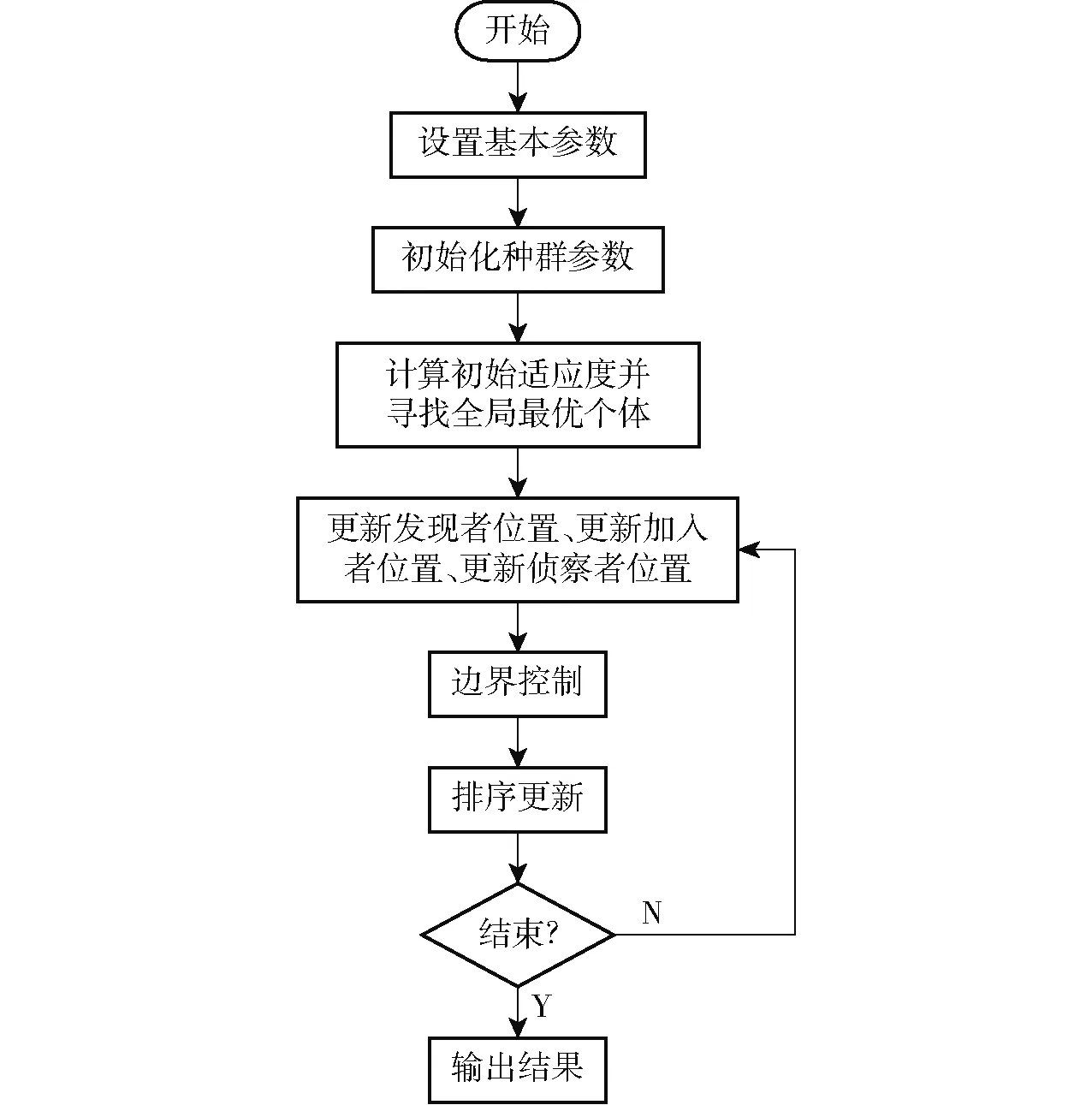
图3 麻雀优化算法流程图Fig.3 Process chart of sparrow optimization algorithm
SSA-BP算法的实施过程如下:
(1)读取数据。确定BP神经网络模型的校正集和测试集样本,对数据进行归一化处理,将本研究中不同量纲数据归一化到0~1之间,并根据式(1)确定最佳隐含层节点数。
(2)网络参数配制。将训练次数设置为1 000次,学习速率设置为0.01,训练目标最小误差设置为0.000 1。
(3)初始化参数。设置SSA算法的初始种群规模N和最大迭代次数T,本文将初始种群规模N设为30次,最大迭代次数T设为50次;设定种群中不同类型的麻雀比重和安全值,本文将安全值ST设为0.6,发现者数量NPD设为0.7,侦察者数量设为0.2。
(4)计算初始适应度。根据适应度计算出全局中最优个体。
(5)根据适应度将麻雀种群分类,并对不同类型的麻雀个体位置进行更新。
(6)若迭代次数达到最大迭代次数,学习过程结束,输出最优参数和适应度,否则返回步骤(5)重复上述过程。
2 结果与分析
2.1 各因素对秸秆电容的影响
图4为不同含水率的秸秆在相同环境温度和容积密度条件下电容随频率的变化曲线。在频率0.05~100 kHz范围内,秸秆的电容随频率的增大而减小。这是因为随着频率的不断增大导致偶极子的振动速度滞后于电场的变化,所以样本的电容会随着介电常数的减小而不断减小[25]。同一频率下,不同样本的电容受湿基含水率的影响不同,主要表现为:秸秆样本湿基含水率越高,电容越高。
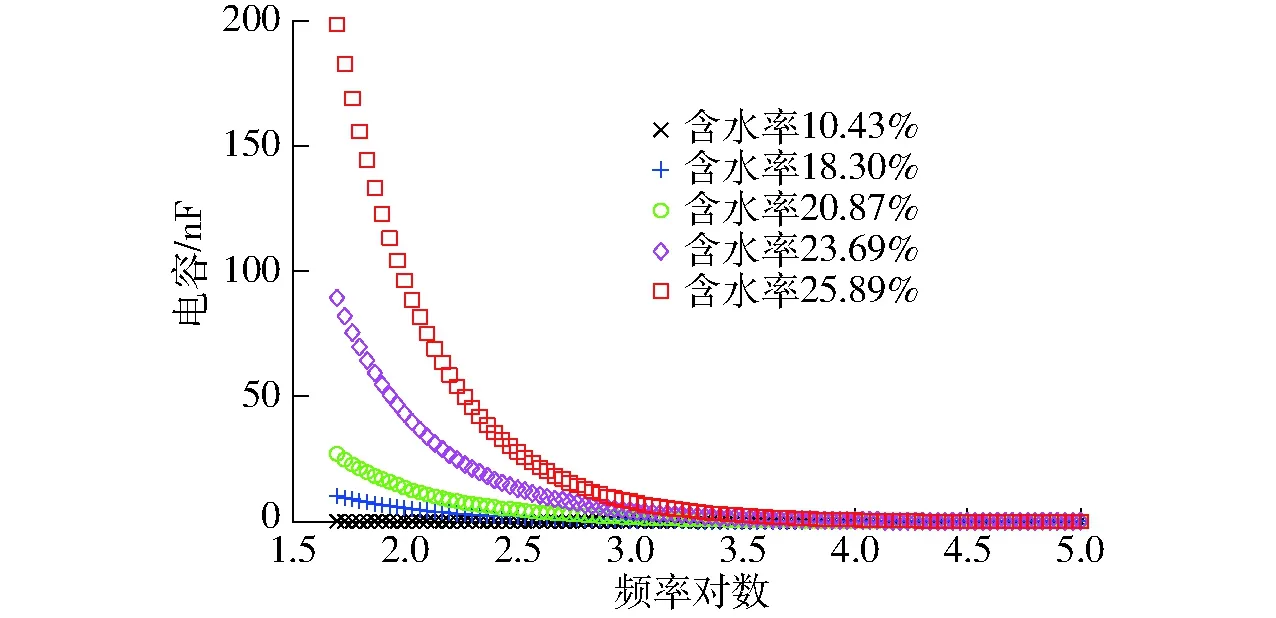
图4 不同含水率秸秆在不同频率下电容变化曲线Fig.4 Capacitance curves of straw with different moisture contents at different frequencies
图5为容积密度和温度对秸秆电容的影响曲面。由图5a可以看出,当频率和温度一定时,随着容积密度的升高,秸秆电容呈单调递增的趋势,这是因为秸秆受到挤压后密度增大,单位体积内秸秆量随之增加,并可以储存更多的电场能,所以测量仪器会测得更大的电容[26]。由图5b可以看出,当频率和容积密度一定时,秸秆的电容随温度的升高而增加,这是因为温度升高有利于加速秸秆内极性分子的取向运动和自由水的布朗运动,致使秸秆的相对介电常数增加,故秸秆电容也随之增加[27]。
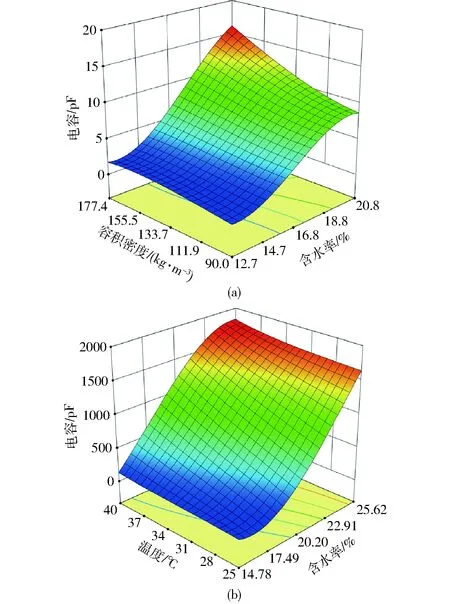
图5 秸秆容积密度和温度对电容的影响曲面Fig.5 Influence of bulk density and temperature of straw on capacitance
2.2 特征频率选取
2.2.1连续投影法特征频率选取
为保证模型性能可靠,设置选取的频率数量为2~30,以不同频率数量所对应的RMSE作为最佳的特征频率数的指标。当选取的频率数量为5时,RMSE最低(0.025 002),如图6所示。考虑到过多的特征频率会导致模型复杂度上升,故选取电容的5个频率作为SPA选取的特征频率。SPA算法选取的特征频率如图7所示。
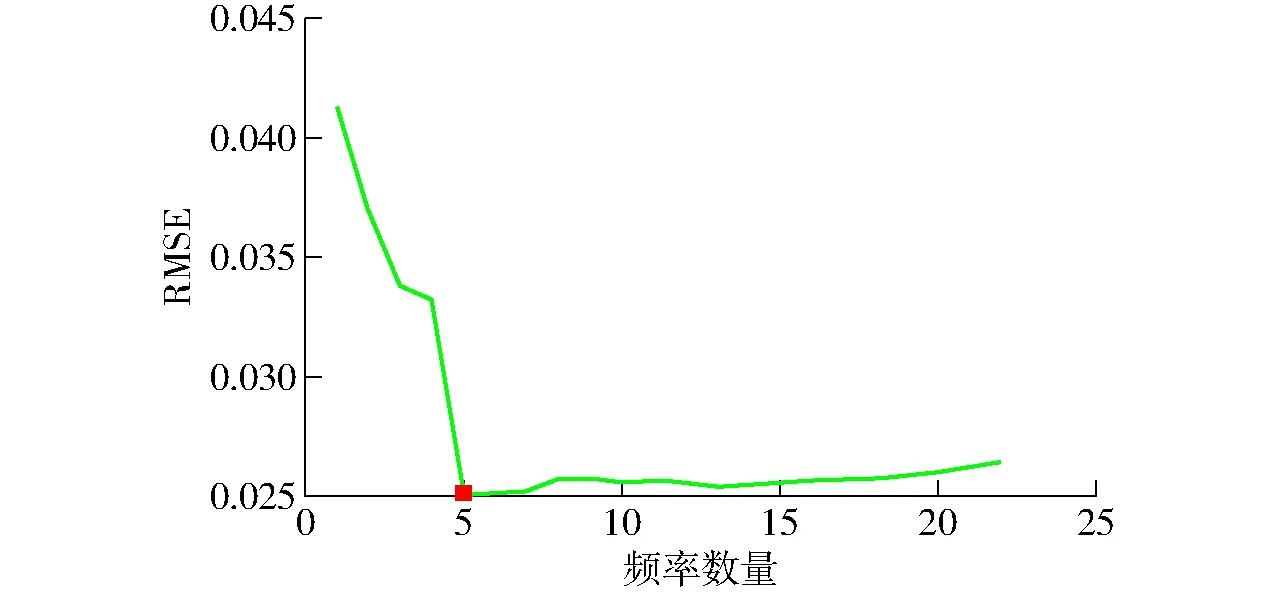
图6 RMSE随SPA选取频率数量的变化曲线Fig.6 Change of RMSE with selected characteristic frequency by SPA

图7 采用SPA算法选取的特征频率点Fig.7 Characteristic frequency points selected by SPA algorithm
2.2.2主成分分析法特征频率选取
在将PCA算法用于原始频率数据的提取过程中,主成分分析得到的前3个主成分累计方差贡献率接近100%,说明前3个主成分能够较为全面地反映绝大部分原始信息,从前3个主成分的权值系数曲线中提取4个特征频率。采用PCA法选取的特征频率如图8所示。全变量、SPA和PCA所选出的特征频率如表2所示。
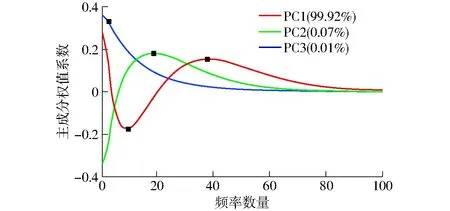
图8 采用PCA算法选取的特征频率Fig.8 Characteristic frequency selected by PCA algorithm
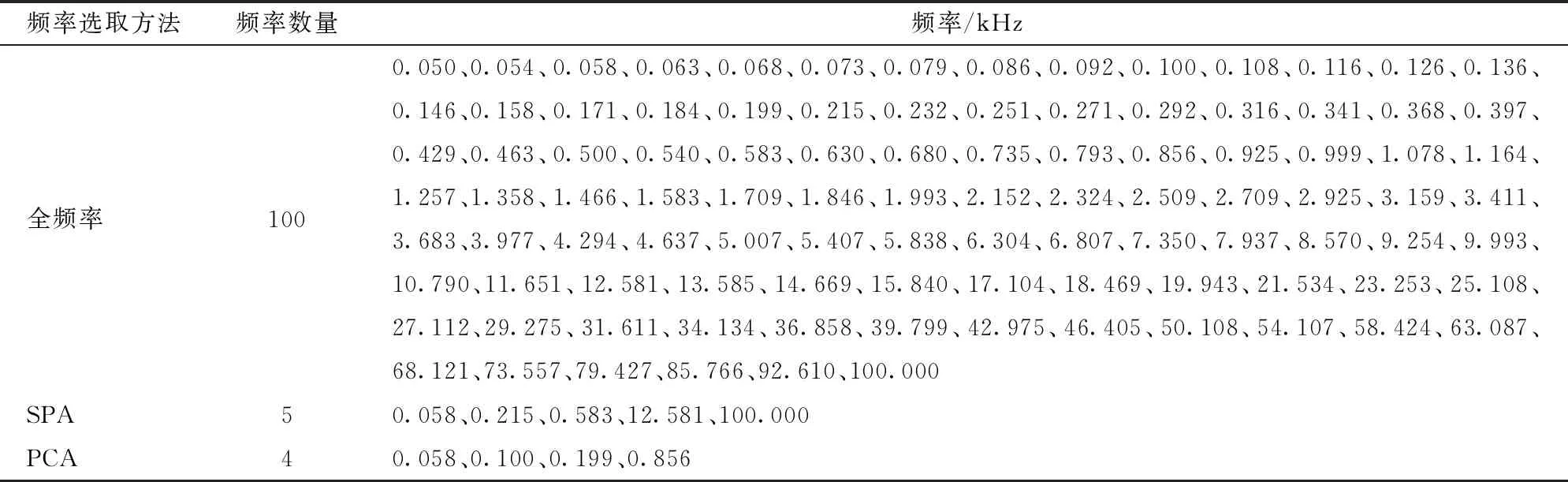
表2 SPA与PCA选取的特征频率Tab.2 Characteristic frequency selected by successive projections algorithm and principal component analysis
2.3 建模并比较分析
为了选取最佳检测模型,以全频率、SPA和PCA分别选取的特征频率与容积密度、环境温度组合作为建模分析的自变量,秸秆样本含水率为因变量。选用BP神经网络算法分别与上述3种变量组合构建模型,建模结果如表3所示。
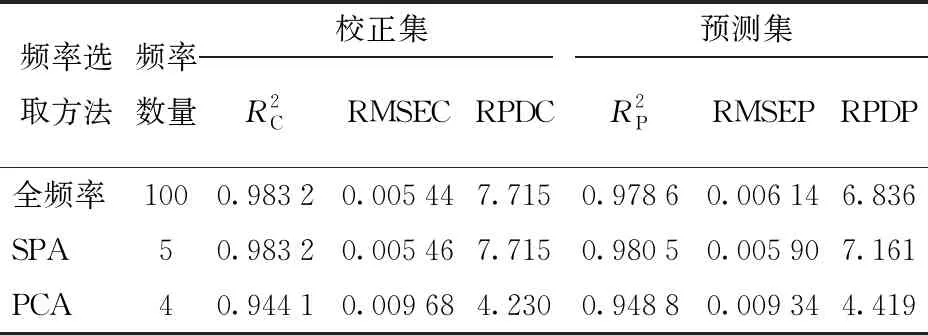
表3 基于不同特征频率选取方法的BP建模结果Tab.3 BP modeling results based on different characteristic frequency selection methods
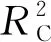
从模型复杂程度来看,基于全频率构建的BP模型中存在大量冗余信息,增加了模型复杂程度。基于SPA和PCA算法能有效提取全频率中的重要信息,会大大简化模型复杂程度,减少模型的运算量并提高程序运行速度。
建模结果表明,提取特征频率有效地减少大量冗余信息和损害模型的信息,在大幅降低模型复杂度的基础上,依旧保持较高的预测精度。因此,基于电容法采用SPA和PCA提取特征频率并分别与容积密度、环境温度组合建立的BP神经网络模型均具有较高的含水率预测精度和可靠性。
2.4 SSA算法优化模型
为进一步探究SSA算法对BP模型预测精度的影响,引入SSA算法对基于不同特征频率选取方法构建的BP模型进行优化,并继续比较分析。
由表3和表4可以看出,SSA-BP建模方法中模型R2较BP建模方法中模型的R2更高,RMSE更低,RPD则更高,这表明经SSA算法优化后的模型具有更高的预测精度和可靠性。
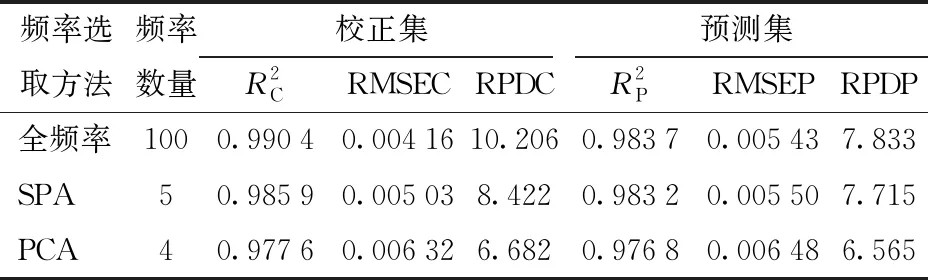
表4 SSA-BP模型结果Tab.4 Results of SSA-BP model
2.5 模型验证
为探究最佳模型对不同秸秆样本含水率的预测效果,随机配制了含水率为10.62%~25.59%的13个秸秆样本,将环境温度分别设置为25、30、35、40℃,在容积密度90.03~179.42 kg/m3范围内随机选择4个容积密度和频率0.058、0.215、0.583、12.581、100.000 kHz下采集上述秸秆样本的电容,共形成156组数据,对模型进行验证。图9为SPA-SSA-BP的预测结果,可以看出样本集中于回归线(y=x)附近,预测效果较佳。因此,最终选择SPA-SSA-BP作为小麦秸秆含水率的检测模型。图10统计了样本含水率预测值与烘干法测得的实际值的相对误差,相对误差为-5.27%~5.52%,其中96.8%的预测误差集中在±5%范围内,说明该模型具有较高的准确性和较好的鲁棒性。
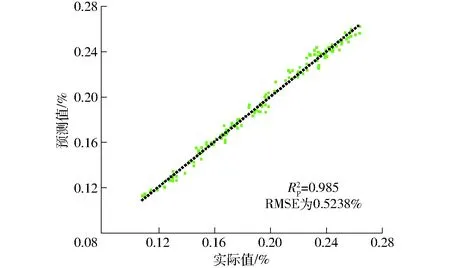
图9 SPA-SSA-BP模型的含水率预测结果Fig.9 Moisture content predicted results of SPA-SSA-BP model
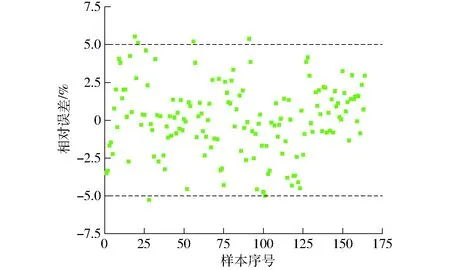
图10 模型对不同含水率秸秆的预测相对误差Fig.10 Model prediction relative error of different moisture contents of straw
3 结论
(1)探究了不同含水率、容积密度、环境温度、频率下秸秆电容的变化规律,在含水率10.43%~25.89%范围内,电容随样本含水率的增大而增大;在频率0.05~100 kHz范围内,电容随频率的增大而减小,当频率大于1 kHz时,减小趋势平缓;在容积密度90.03~179.42 kg/m3范围内,电容随容积密度的增大而增大;在温度25~40℃范围内,秸秆电容随环境温度的升高而增大。结果表明含水率、容积密度和环境温度对电容的影响极显著。
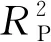
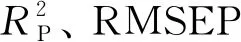
(4)对13个含水率为10.62%~25.59%的秸秆样本进行预测,结果表明,模型预测结果相对误差为-5.27%~5.52%,其中96.8%的预测误差集中在±5%范围内,模型具有较高的准确性和较好的鲁棒性,本文提出的方法可进一步提高小麦秸秆含水率检测模型的检测精度,并为其他作物秸秆含水率预测提供了思路和理论参考。
猜你喜欢
中国现代医生(2022年19期)2022-11-04
农业工程学报(2022年13期)2022-10-09
中南林业科技大学学报(2022年7期)2022-09-26
长江科学院院报(2022年7期)2022-08-09
小学生学习指导(高年级)(2022年4期)2022-04-26
人民长江(2019年7期)2019-09-10
读写算·高年级(2017年6期)2017-06-27
学苑创造·B版(2016年5期)2016-07-18
知识就是力量(2016年6期)2016-05-31
中学生数理化·高二版(2016年5期)2016-05-14
