
采用可替代滤波器的卷积神经网络模型剪枝方法
2022-03-13 04:04:16周密张维纬陶英杰余浩然
华侨大学学报(自然科学版) 2022年2期
周密, 张维纬 , 陶英杰, 余浩然
(1. 华侨大学 工学院, 福建 泉州 362021;2. 华侨大学 工业智能化与系统福建省高校工程研究中心, 福建 泉州 362021)
近年来,深度学习和神经网络的发展使神经网络模型的效果越来越好,但随着无人驾驶与智能移动设备等相关领域的不断发展与创新,对计算能力较弱的边缘设备上的深度神经网络模型的要求越来越高.当神经网络模型部署在移动设备上时,由于深度神经网络的特性,参数量及浮点计算量都是极其庞大的.例如,当使用107层YOLO v3网络结构检测分辨率为416 px416 px的图像时,将产生240 MB的参数量及多达650亿次的乘法累加计算量.然而,支持百亿次计算量的边缘设备的成本是相对较高的,例如,在NVIDIA Tesla T4上运行YOLOv3网络结构,每秒可实时检测40帧图像,该设备市场售价近3万元人民币,远超出普遍的经济承受能力,而现有的神经网络模型在低成本设备上很难兼顾神经网络模型的精确性与计算速度.因此,对于移动边缘设备来说,应在保持精度不降低或者略微降低的情况下,尽可能保证低的存储空间及少的浮点计算量[1].
将神经网络模型剪枝部署于移动边缘设备具有优势[1],在非结构化修剪方式方面,Guo 等[2]提出一种动态的参数剪枝算法以逼近神经网络模型压缩的理论极限.Carreira-Perpinán等[3]通过两步(学习和压缩)交替优化的剪枝方法将原参数向约束表示的可行集投影,自动找到每层的最优稀疏比.Ding等[4]通过一阶泰勒展开式判断剪枝对最终输出造成的影响排序,网络中的权重根据排序进行分类.对造成影响较大的权重,采用常规的随机梯度下降(SGD)更新,对其他的权重则进行权重衰减,从而实现动态网络剪枝.非结构化的权重修剪方式能够有效降低神经网络模型的大小,但是剪枝完成以后的神经网络模型需要特定的硬件支持,故其泛化性较差.在结构化修剪中,He等[5]提出CP(channel-pruning)算法,通过添加范数约束权重L1进行LASSO(least absolute shrinkage and selection operator)回归,选择合适的稀疏通道对训练好的神经网络模型进行剪枝.Huang等[6]使用数据驱动的方式移除神经网络模型中多余的滤波器.You等[7]将通过纯残差方式连接的GBN分配到同一组,对全局滤波器重要性进行排序,并对排名较后的进行分组剪枝.He等[8]通过计算几何中心的方式对处于几何中心的冗余滤波器进行剪枝.
上述大部分剪枝策略都是基于启发式规则,此类方法着重于滤波器重要性的排序与修剪,但可能导致次优修剪,并且需要专家不断调节参数.确定性策略梯度算法中试错与奖惩的结合能够很好地检索剪枝策略[9].He等[10]通过使用深度确定性策略梯度(DDPG)算法得到各层剪枝率的最优组合,提出一种自动化剪枝AMC(automl for model compression and acceleration on mobile devices)算法.对神经网络模型所有层采用同一剪枝率的剪枝方法[8]可能会导精度下降,本文结合滤波器可替代的特性与强化学习,提出自动化可替代滤波器剪枝方法.
1 自动化可替代滤波器的剪枝方法
1.1 总体框架
手动剪枝方法依赖手动调节参数,对神经网络模型每一层进行相同压缩率的剪枝方法可能会降低神经网络模型的精度.受AMC算法的启发[10],利用强化学习的方式进行自动化剪枝,不需要专家手动调节参数,不仅避免耗时,还能获得组合剪枝策略.策略针对神经网络模型不同层实施不同的压缩率,使整体上达到目标压缩率.相较于随机性策略的强化学习方法,DDPG算法的效率更高,能够通过更少的数据获得连续且确定的动作输出.同时,DDPG算法中离线策略能够很好地避免确定性策略对环境探索存在的不足.在自动化剪枝过程中,引入可替代滤波器的搜索,搜索神经网络模型每一层中能够被同一层中其他滤波器表示的可替代滤波器.通过对可替代滤波器的剪枝,能最大程度保留原有神经网络模型的精度.
算法完整框架,如图1所示.算法由DDPG算法、获取剪枝的目标滤波器和滤波器的剪枝操作3部分组成.在算法运行过程中, DDPG算法在获得当前神经网络模型层的属性特征以后, 经过降维转化,将原本的离散变量转化为连续的变量,并传导给演员网络与评论家网络,由演员网络输出确定性的神经网络模型的每一层剪枝压缩率,指导可替代滤波器进行剪枝.将可替代滤波器的参数值归零,从而达到剪枝效果,在执行完神经网络模型所有层的剪枝后,算法在验证集上根据浮点计算量进行准确性奖励,并将结果返回给评论家网络,同时,将当前的剪枝策略保存到经验采样池中,然后,执行下一轮的网络剪枝,直到所有剪枝周期结束.
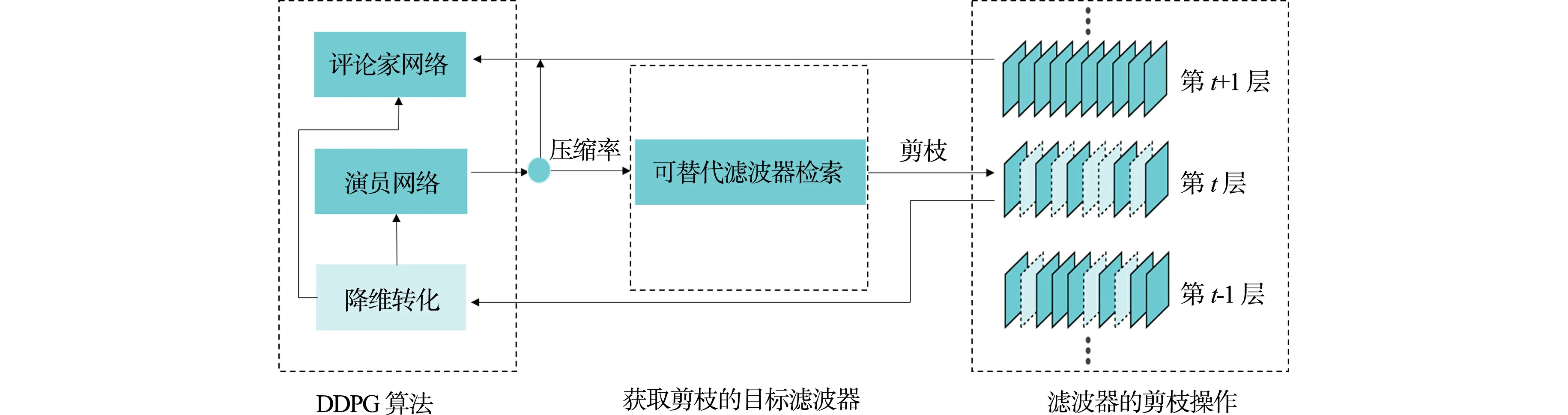
图1 算法完整框架Fig.1 Complete framework of algorithm
1.2 可替代滤波器的检索
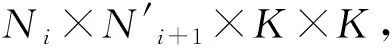
在可替代滤波器搜索策略上,通过几何中位数的方式进行搜索[11],如果该滤波器可以被几何中心点周围其余滤波器表示,即可判定其为可替代滤波器.由于几何中位数是欧几里得空间中数据中心性的经典鲁棒性估计[11],因此,可以使用几何中位数的方法获取第i层网络中所有滤波器的信息.同时,对处于几何中心的滤波器进行选择,神经网络模型第i层中某一个滤波器到其他滤波器的距离之和为
(1)
在寻找可替代滤波器的过程中,如果一个滤波器到神经网络模型某一层中所有其他滤波器的整个距离最短,就可以认为它是处于最靠近中心的滤波器.通过求解该滤波器与其他滤波器的最小欧氏距离,就能够找到其中最接近几何中心的滤波器,即认为选定的滤波器Fi,j*含有的信息能够被同一层中其他的滤波器含有的信息表示,所以修剪这些滤波器对于网络的性能几乎没有影响.由于计算几何中心十分耗时,且在滤波器的分布中可能存在没有任何一个滤波器处于几何中心的情形.所以,距离最短问题可以转化为所有候选层中的滤波器距离其他滤波器的距离和最小问题,即
(2)
在实际检索中,计算获得的几何中心并不能保证滤波器在该层中一定存在[8],即如果在该层的几何中心处不存在滤波器,那么距离其他滤波器距离和最小的滤波器可以认定为该层的几何中心滤波器.
在实际剪枝过程中,根据层次的不同,执行不同数量的滤波器剪枝,即通过不同层的压缩率与该层的滤波器数量计算执行剪枝的滤波器数量.在滤波器距离的排序中,将所有的滤波器进行几何中心距离计算,获得距离排序.按照需要剪枝的滤波器数量进行剪枝.该选定的滤波器为
(3)
剔除中心滤波器后,迭代计算,剔除选定距离的滤波器,直到满足该层剪枝数量的滤波器被全部找到为止.因此,所有选定的滤波器Fi,j*和该层剩余的滤波器共享绝大多数的基本信息,也即该滤波器所包含的信息可以被其他滤波器代替表示.为了避免删除滤波器导致网络模型的不规则,将冗余滤波器的权重参数设置为零,而不是直接将滤波器删除,剪枝以后的模型经过微调能够很快恢复到原始性能.
1.3 强化学习
对于模型所有层(敏感层与非敏感层)均进行相同压缩率的剪枝操作[8],模型每一层的滤波器剪枝数量为目标压缩率与该层的所有滤波器数量之积.此方式可能导致参数重要性高的敏感层的剪枝率过高,导致不必要的精度损失.以DDPG算法作为代理连续控制压缩比,对不同神经网络模型层次以不同压缩率进行自动化剪枝.DDPG算法由评论家当前网络、评论家目标网络,演员当前网络、演员目标网络4个神经网络构成.环境状态St的10个属性特征分别为n,c,h,w,stride,k,FLOPs[t],Reall,Rest,at-1.DDPG代理能够很好地将所有的卷积层区分开,卷积核大小为n×c×k×k,输入值为c×h×w;FLOPs[t]为第t层的浮点计算次数;Reall为前面所有已剪枝层减少的浮点计算量(FLOPs)的总数;Rest为余下各层中剩余的FLOPs总数.在这些属性特征传递给代理之前,所有的属性特征都会被压缩到[0,1],以避免因为数值大小对模型训练产生的影响.
由于模型的剪枝对于模型的稀疏程度十分敏感,随着离散动作数量的急剧增加,动作空间的搜索难度也急剧加大,导致很难做到高效且快速的检索.所以,通过选择a∈(0,1]的连续动作空间进行更精确的压缩.在强化学习指导剪枝的过程中,代理从滤波器剪枝的环境中获得其所处的第t层的环境状态St,获得当前特征向量φ(S).将St状态下的动作At作为当前层的压缩率,将目标压缩率下需要剪枝的滤波器的总数与已完成剪枝的滤波器数量的差值作为剩余需要剪枝的滤波器的数量,通过DDPG算法反馈的压缩率执行当前层剪枝过程.完成当前层的剪枝后,得到当前层剪枝完成以后的短期奖励R及第t层剪枝完成以后的新环境状态St+1.
将φ(S),At,R,St+1对应的特征向量φ(St+1)及判断是否为终止状态的is_end存放到经验回放池中,其中,is_end用来评估是否处于剪枝模型的最后一层.对于模型的下一层,代理会接收上一层剪枝完成后所产生的新环境状态St+1.执行与第t层网络模型相同的自动化剪枝流程,直到滤波器的剪枝数量达到目标剪枝数量.在判断完成最后一层的剪枝后,当is_end值为真时,模型会在验证集上评估剪枝完成的模型的准确性奖励RFLOPs并返回给代理,同时,将此次的剪枝策略及奖励RFLOPs存放到字典中.

(4)
每一次演员当前网络选择的动作A会增加一定的噪声N,并且噪声会在每轮剪枝完后呈指数衰减.最终和环境交互的动作A为
A=πθ(S)+N.
(5)
DDPG算法通过均方差损失函数、梯度反响传播的方式更新评论家当前网络的所有参数,并定期将其复制到评论家目标网络.即
(6)
式(6)中:φ(Sj)为当前Sj状态获得的特征向量;Q(φ(Sj),Aj,ω)由评论家当前网络获得.
损失函数通过梯度反响传播的方式更新演员当前网络的所有参数θ,即
(7)
式(7)中:Q(Sj,Aj,θ)由评论家当前网络计算所得.
在不损失模型精度情况下,为了准确找出压缩情况,算法通过总结文献[10]的研究经验,将奖励函数设置为
RFLOPs=-Error·ln(FLOPs).
(8)
式(8)中:ln(FLOPs)以e为底的对数,且与Error成反比,该奖励函数对误差敏感,能更好支持模型剪枝中对FLOPs的减少.
提出的自动化可替代滤波器剪枝算法,如算法1所示.
算法1
Input:training data:X.
Initialize:model parameter W = {W(i),0 ≤ i ≤ L} Action,Ni
for episode=1;episode≤episodemax;episode + + do
Update the model parameter W based on X
for i = 1;i ≤ L; i + + do
Initialize the reduced model size so far
Wall=∑LWL
Wrest=∑L=i+1WL
Wduty=α*Wall-Actionmax*Wrest-Wreduced
Actioni=max(Actiont,Wduty/Wi)
Wreduced=Wreduced+Actioni*Wi
Find Actioni*Ni+1filters that satisfy Equation 2
Zeroize selected filters
If i==L
Update the Reward
end if
end for
end for
Obtain the compact model W*from W
Output:The compact model and its parameters W*
2 实验结果与分析
2.1 实验环境
搭建Pytorch环境进行训练,系统为Ubuntu18.04,电脑硬件配置为Intel(R)Core(TM)i7-6700 CPU@3.4 GHz,NVIDIA GeForce TITAN Xp;软件配置为CUDAToolkitv10.0,Anaconda3和Pycharm 2019.
2.2 数据集与网络模型
算法在公开的CIFAR-10数据集的VGGNet-16和ResNet-56[12]两种模型及公开的ImageNet[13]数据集的Mobilenet-V1和Mobilenet-V2两种模型上进行实验.CIFAR-10数据集包含10类,每一类包含6 000张图片,共60 000张图片,每张图片均是分辨率为32 px×32 px的三通道RGB(三原色)图片,其中:50 000张为训练集图片,10 000张为测试集图片.ImageNet数据集作为大型数据集,训练集包含分辨率为224 px×224 px的1 000类图片,每类图片包含1 300张图片.测试集包含50 000张图片.
2.3 对比算法
对比算法有CP算法[5]与AMC算法[10].实验效果衡量指标主要有算法准确率、参数量及浮点计算量.算法准确率用来衡量模型分类结果的好坏.参数量用来衡量神经网络所占计算机内存的大小,参数量的压缩比例是指剪枝后的参数量与未剪枝的参数量的减少比例.浮点计算量指的是浮点运算次数,用来衡量网络模型复杂程度,浮点计算量的减少说明网络在实际运算中可以取得加速效果,减少量越大,说明加速效果越明显.
2.4 CIFAR-10数据集实验结果
将提出的算法运用到不含直连的VGGNet-16与含有直连的ResNet-56神经网络模型上,VGGNet-16模型,ResNet-56模型在CIFAR-10数据集上的剪枝比较,如表1所示.表1中:η为压缩率;ε为精度,Δε为精度变化.

表1 VGGNet-16模型,ResNet-56模型在CIFAR-10数据集上的剪枝算法比较Tab.1 Comparison of pruning algorithms using VGG-16 model and ResNet-56 model On CIFAR-10 dataset
由表1可知:VGGNet-16神经网络模型的压缩率为20%时,相较于CP算法与AMC算法,文中算法性能降低得最小,精度仅降低了1.1%;ResNet-56神经网络模型压缩率为50%时,相较于CP算法与AMC算法,文中算法性能降低得较小,精度仅降低了0.7%.
对于FLOPs约束下的常用模型的剪枝,文中算法通过强化学习执行不同剪枝率,保证学习过程产生最优剪枝组合策略,能够很好地避免敏感层的过度剪枝.对比根据经验手动调参方法与启发式方法,处于几何中心的冗余滤波器的剪枝能获得更好的剪枝效果,能够很好地保留对模型精度影响大的滤波器.对比引入静态正则项进行自动化剪枝的AMC算法,文中算法通过对可替代滤波器进行冗余滤波器剪枝,能够很好地保留包含较多有用信息的滤波器,从而获得更低的精度损失.
2.5 ImageNet数据集实验结果
将提出的算法运用到ImageNet数据集上,在保持相同压缩率下,文中算法在Mobilenet-V1模型和Mobilenet-V2模型上的剪枝效果比较,如表2所示.表2中:-表示未执行剪枝操作;ε(Top-1)为排名第一的类别与实际相符的精度.
由表2可知:在保持相同压缩率条件下,文中算法保留的模型能够获得更好的精度保留;当FLOPs为41×106次时,相比于基准算法,文中算法在Mobilenet-V1模型上的精确度高出7.5%,文中算法在Mobilenet-V2模型上的精确度高出4.7%.
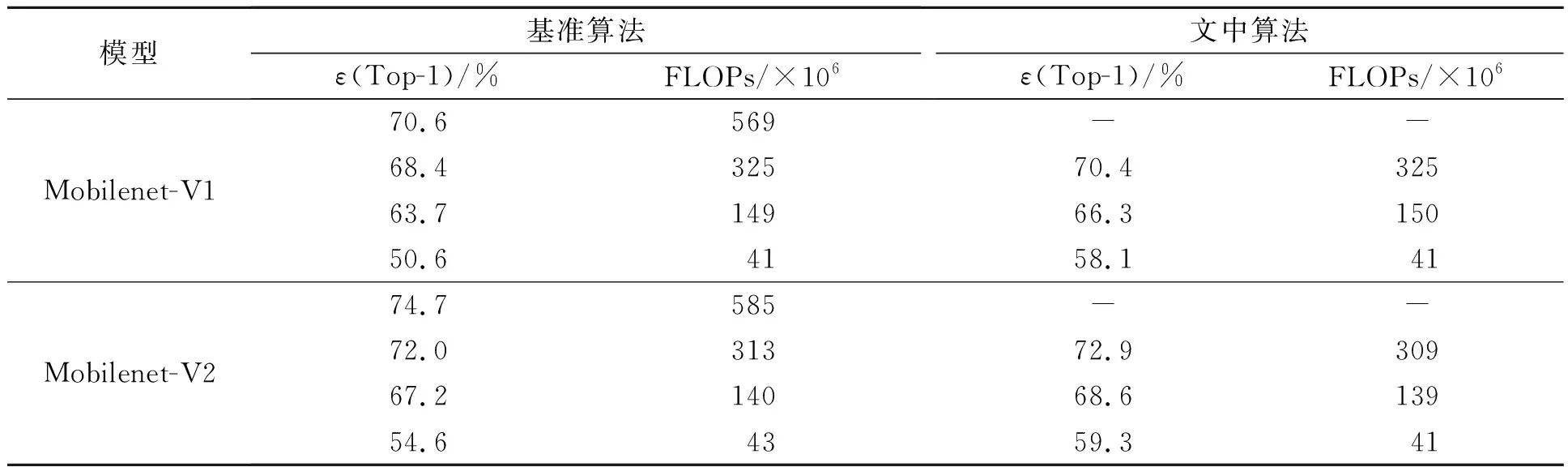
表2 文中算法在Mobilenet-V1模型和Mobilenet-V2模型上的剪枝效果比较Tab.2 Comparison of pruning effect of proposed algorithm on Mobilenet-V1 model and Mobilenet-V2 model
文中算法与AMC算法的Top-1准确性比较,如表3所示.由表3可知:与AMC算法相比,文中算法能够更好地保留模型中重要的滤波器.同时,对于保留相同数量的滤波器,能够保证更小的精度损失,而获得更好的结果.具体表现为在保持基本相同的FLOPs减少量的基础上,文中算法在精度损失上更小,剪枝完成后的Mobilenet-V1模型精度提高了0.1%,Mobilenet-V2模型精度提高了0.9%.

表3 文中算法与AMC算法的Top-1准确性比较Tab.3 Accuracy comparison of proposed algorithm and AMC algorithms
3 结束语
针对卷积神经网络庞大的浮点计算量,提出对可替代滤波器进行自动化剪枝的方法.在保证精度基本不降低的情况下,文中算法大幅度了降低浮点计算量,保证了对不同结构的神经网络模型的良好适应性.对于要求极严苛的超小型边缘设备的小存储量,未来的工作将在保证精度降低不大的前提下进行模型的进一步压缩与加速.
猜你喜欢
保健医苑(2022年5期)2022-06-10 07:47:22
导航定位学报(2022年2期)2022-04-11 03:17:34
成都信息工程大学学报(2021年6期)2021-02-12 03:00:54
铁道通信信号(2019年4期)2019-10-10 03:42:38
科学与财富(2018年26期)2018-10-24 15:31:44
科技信息·中旬刊(2018年4期)2018-10-21 03:34:14
天津诗人(2017年2期)2017-03-16 03:09:39
滁州学院学报(2016年5期)2016-12-16 07:41:46
科教导刊·电子版(2016年23期)2016-10-31 21:27:33
电测与仪表(2015年18期)2015-04-12 00:45:24
