
Tn5转座子及其在生物技术领域的应用
2022-03-11 14:28高畅任鹏程李明格吕赫喆胡仪
中国实验动物学报 2022年8期
高畅,任鹏程,李明格,吕赫喆,胡仪
(1. 北京师范大学生命科学学院,北京 100875;2. 中国科学院动物研究所,北京 100101)
1 Tn5转座子及转座机制
1.1 Tn5转座子
Tn5是一种复合型转座子,其中心序列可表达3种抗生素(kanr、strr、bleor),两侧为高度同源的倒置序列IS50R和IS50L[1](图1A)。IS50R可以表达产生转座酶(transposase,Tnp)和抑制转座酶活性的抑制蛋白(inhibitor,Inh),IS50L表达产生两个非活性蛋白[2-3]。每个IS50序列都位于两个19 bp的倒置末端(外末端outside end,OE和内末端inside end,IE)之间。倒置末端为转座酶的作用位点,但OE和IE在序列上略有不同[1,4]。后续的研究发现,转座的发生只需其中的关键成分,即转座酶和两个19 bp的倒置末端,内部可以包含任何足够长的DNA片段(图1B)。并且,这两个19 bp的末端可以是倒置的OE和IE、两个OE、两个IE,也可以是两个马赛克末端(mosaic end,ME)。实际上,ME是一种人工构建的末端,其序列与OE存在3个碱基对的不同,且具有比OE和IE更高的转座速率[5]。

图1 Tn5转座子结构Note. A. Traditional transposon Tn5. It contains two inverted versions of IS50 (IS50L and IS50R) bracketing three antibiotic resistance genes (kanr, strr, bleor), and the IS50 elements are defined by the outside end (OE) and inside end (IE). IS50L encodes two inactive proteins, while IS50R encodes transposase (Tnp) and an inhibitor of transposition (Inh). B. Simplified transposon Tn5. Two outside ends (OE) or other ends (IE, ME) brackets sufficient DNA.Figure 1 Structure of transposon Tn5
1.2 转座酶结构
由IS50R编码的Tn5转座酶可以分成3个结构域:与转座子末端DNA结合的N端结构域、具有催化活性的中部结构域和负责蛋白质结合的C端结构域。N端结构域的二级结构仅包含α-螺旋和转角,用于与转座子末端序列的识别和结合;C端结构域也仅有α-螺旋和转角,可以与转座酶结合促进转座过程,也可以同Inh结合形成二聚体抑制转座[6]。而转座酶的活性位点则位于由约300个氨基酸残基组成的中部结构域内,该结构域内含有一个“核酸酶类H模体”起催化作用,且该模体在所有转座酶和逆转录病毒整合酶中都起类似的作用[6-8]。Tn5转座酶的“核酸酶类H模体”活性中心内有D97、D188、E326作为保守的氨基酸残基组成DDE模体,对转座酶的活性有至关重要的作用。该DDE模体与两个Mn2+结合,两个Mn2+分别与OE末端的3’-OH和5’-P配位作为催化活性中心[6]。此外,在DDE模体的谷氨酸残基后还存在一对保守的赖氨酸残基(E×××K××K),其中,第二个赖氨酸残基与Y319、R322及DDE模体中的E326组成了高度保守的YREK模体,该模体使得非转移链的5’-P发生位移,为靶DNA的结合留下了空间[9]。
1.3 Tn5转座机制
Tn5转座需要多个步骤,主要包括转座酶二聚体的形成、供体DNA的切割、靶DNA的捕获与链转移、链转移复合物的脱离4个步骤(见图2)。首先,在缓冲液中加入Mg2+,两个转座酶分子的N端26~65位氨基酸残基及活性中心的几个氨基酸残基与Tn5转座子末端序列特异性结合,构成两个转座酶-DNA复合体[6,10]。紧接着,这两个复合体利用转座酶C端α螺旋交叉,发生剪刀状二聚化,形成一个转座酶二聚体[6-7]。在形成转座酶二聚体后,转座酶启动DNA的切割,并且,一侧的转座酶催化另一侧末端的反应,呈现出交叉作用的现象[11]。整个催化反应大致包括3个步骤:首先,转座酶活化的水分子与DNA链反应,使OE末端暴露出游离的3’-OH;其在接下来的反应中与互补链形成发夹结构,使转座子DNA从供体DNA骨架中脱离;最后,另一活化的水分子将该发夹结构打开,释放出3’-OH为链转移做准备[12]。在整个催化反应完成后,转座酶二聚体捕获靶DNA并进行链转移。许多研究表明,Tn5的链转移插入位点在大范围内是随机的,但是仍然存在优选的9 bp插入位点[13]。并且,研究者们发现了非转移链的5’-P会导致5’末端在空间上的运动,进而使得DNA构象发生改变,更易于与靶DNA结合,并将3’-OH暴露在一个空腔中使其更易发生链转移[9]。当转座酶二聚体与靶DNA结合后,转座子DNA的3’-OH分别在9 bp靶位点两侧进行亲核攻击完成链转移,并在转座子两端各形成一个9 bp的粘性末端。据推测,在体内实现链转移后,链转移复合物可能被宿主的某些功能释放,随后两个粘性末端被补平,形成9 bp的正向重复序列。而在体外时,Tn5链转移复合物十分稳定[14]。
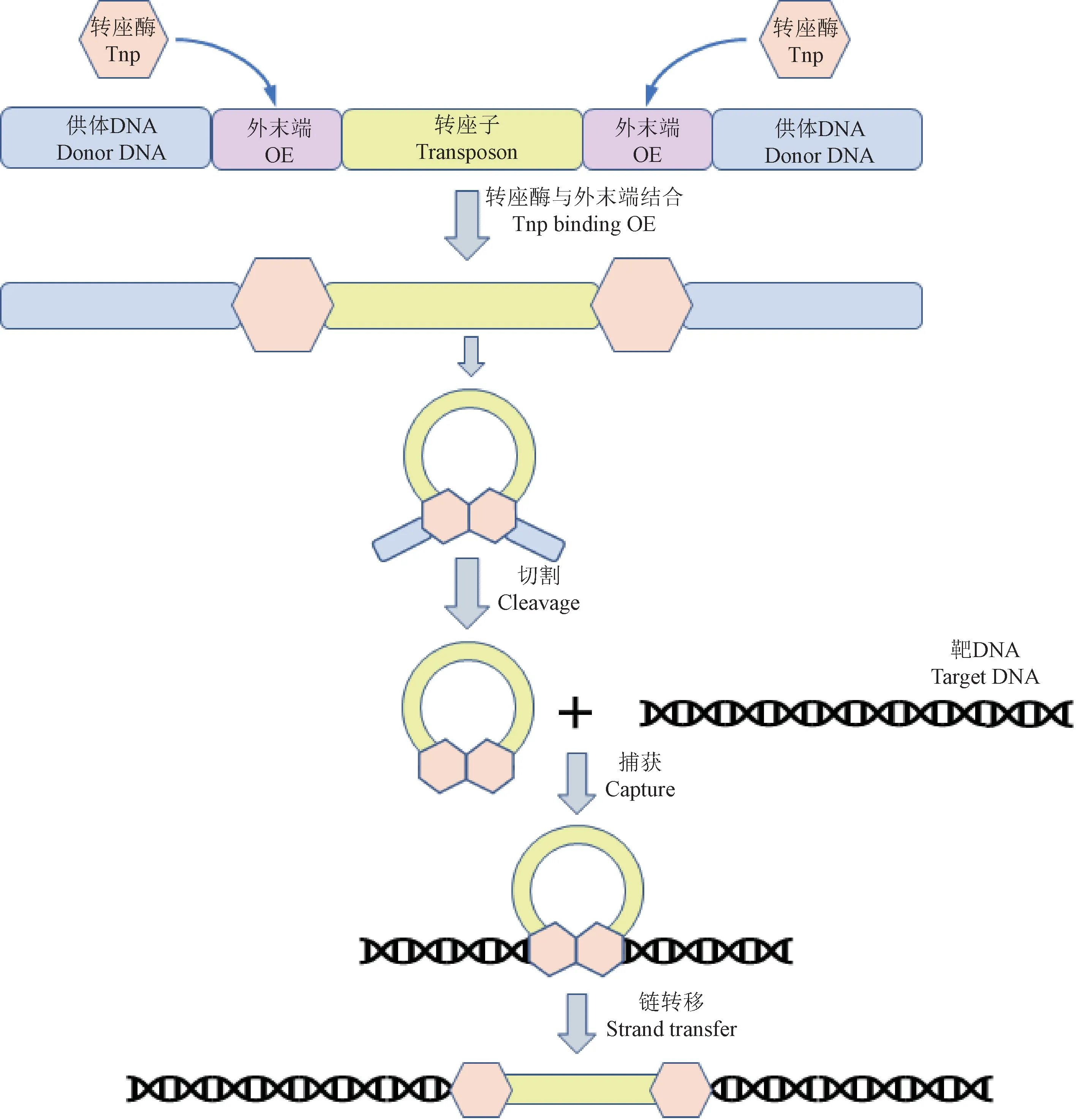
图2 Tn5的转座机制Note. Mechanism of Tn5 transposition. Two Tn5 transposases bind to the OEs and then dimerize forming the synaptic complex. Then, Nucleophilic reactions occur resulting in cleavage of transposon-donor DNA bonds. Finally, the synaptic complex captures the target DNA and strand transfer occurs.Figure 2 Mechanism of Tn5 transposition
2 Tn5建库方法
自人类基因组计划以来,DNA测序技术在生命科学领域的研究不断深入。二代测序技术的发展使大规模并行DNA测序成为可能[15]。二代测序技术的流程步骤主要包括样品提取、文库构建与测序及最后的数据处理与分析。其中,文库构建在很大程度上直接影响到数据分析的结果,是整个技术的核心。传统的文库构建流程通常包括DNA片段化(机械法或酶促法)、末端补齐、测序接头的连接和PCR扩增,在RNA-seq中还需要首先合成cDNA文库。尽管barcode接头的连接可以同时分析多个样本,但是对于开发一种样本起始量低、实验周期短、成本低的文库构建方法的需求越来越强烈[16]。
基于Tn5转座酶的文库构建方法大大缩减了传统方案中文库构建的步骤、时间和成本。在此方法中,Tn5转座酶的高活性衍生物的运用可以在短时间内将转座序列插入靶DNA中,直接引发双链DNA的片段化,同时将接头序列加至片段的两端[17]。其流程大致为,首先将测序接头和OE序列整合为包被接头,与转座酶在体外孵育,形成结合了DNA的转座酶二聚体;随后该复合体与待测序DNA共孵育并将其打断,形成可测序的DNA片段;最后加入酶将复合体插入时产生的切口补平,并通过PCR扩增完成文库的构建。此外,在PCR扩增时还可以引入barcode以实现大规模并行的DNA测序。
但是PCR扩增易产生扩增偏差和错误[18],这在细胞异质性研究的单细胞测序中是极为不利的。因此,一种利用Tn5转座子插入启动子进行线性扩增的方法(linear amplification via transposon insertion,LIANTI)应运而生。该方法利用Tn5转座子将单细胞基因组DNA随机打断,同时在每个片段上添加T7启动子,再用DNA聚合酶补齐片段两端的单链T7启动子,最后进行体外转录。随后,再通过逆转录、RNA酶消化、cDNA二链的合成,最终形成LIANTI文库进行测序[18]。并且,若在LIANTI转座子和引物中添加组合barcode,也可以实现单细胞的高通量测序。此外,虽然Tn5偏好于包含鸟苷(G)和胞苷(C)的插入序列,导致插入间隔不够均匀,进而导致测序时的覆盖范围不够均匀,但是Tn5转座酶突变体Tn5-059可以有效解决这个问题[19]。同时,多种高活性Tn5转座酶的高效生产进一步降低了文库构建的时间和成本[20-22]。这些优势都使Tn5转座酶在建库领域备受青睐。
3 Tn5建库在表观测序中的应用
3.1 基于Tn5为全基因组亚硫酸氢盐测序建库
表观遗传是指基因序列不变时,通过一些表观修饰影响基因表达情况进而影响表型的现象。胞嘧啶5-C位置的酶促甲基化是一种广泛存在的表观遗传修饰,在基因调控方面有着重要作用[23]。全基因组亚硫酸氢盐测序(whole genome bisulfite sequencing,WGBS)是研究胞嘧啶甲基化分辨率较高且较为全面的一种方法[24]。该方法中,亚硫酸氢钠被用来处理基因组DNA,在5-甲基胞嘧啶保持非反应性的条件下将单链DNA中的胞嘧啶残基转化为尿嘧啶残基,随后用胞嘧啶甲基化处理的引物扩增并测序,序列中剩余的所有胞嘧啶残基代表基因组中先前甲基化的胞嘧啶[25]。随着大规模并行测序成本的下降,WGBS也越来越普及。但是WGBS有一个关键的限制因素是需要较大量的DNA样本,这对于许多实验是难以实现的[24,26]。据此,Adey等[27]开发了Tn5Mc-seq,该方法将Tn5转座系统用于WGBS来快速制备亚硫酸氢盐测序文库,先将传统的Tn5建库中与Tn5结合的接头中的胞嘧啶进行甲基化修饰,将基因组DNA片段化后再与亚硫酸氢盐反应。转座酶的使用使DNA的片段化、末端的补齐和接头的连接简化为单个反应且将DNA更有效地转化为测序兼容材料。因此其减少了建库过程中对DNA样本量的损耗,大大降低了WGBS所需要的基因组DNA起始量[27]。
3.2 基于Tn5对蛋白质与染色体的相互作用测定
染色质和蛋白质的相互作用在表观调控中也起到非常重要的作用,因此研究这种相互作用的众多方法相继诞生,染色质免疫沉淀测序(chromatin immunoprecipitation sequencing,ChIP-seq)就是一个十分典型的例子[28]。但ChIP-seq需要甲醛来介导DNA与蛋白质的交联,往往具有低信号、高背景且样本需求量大等缺点[28]。随后出现的CUT&RUN技术就是在此基础上的改进,它的大致思路为在非交联细胞中通过连续使用特定抗体,将蛋白A-微球菌核酸酶复合物(pA-MNase)导向蛋白质结合位点,随后通过钙离子的释放来激活核酸酶,将所要的片段释放到上清液中,最后进行文库的制备和测序等[29]。该方法可以将背景水平大大降低,也可以在一定程度上降低对样本的需求量,仅在100~1000个细胞中就可以产生高质量的数据,但是必须经过DNA末端的补齐和接头的连接才能制备测序文库,这会增加整个过程的时间、成本和工作量。紧接着出现的CUT&Tag技术是对CUT&RUN技术的改进,研究人员将MNase替换为Tn5转座酶并使用Mg2+在特定时期激活pA-Tn5融合蛋白组成的转座体,在获取靶DNA的同时直接插入测序接头,进一步简化了实验步骤,降低了时间成本[30]。在实际操作中,CUT&RUN和CUT&Tag技术都需要将细胞与磁珠结合,由于磁珠的悬浮性较差等因素,酶的效率往往会下降,于是研究者们又对磁珠进行改良,有效改善了这一问题,提高了检测的灵敏度[31]。最近,研究者们在原有的CUT&Tag技术上进一步创新,开发出了multi-CUT&Tag,可以同时映射同一细胞中的多个染色体蛋白质,直接检测不同蛋白质在同一细胞中的共定位[32]。与此同时,与CUT&Tag技术一样基于抗体将Tn5靶向目的位点的技术还有ACTseq[33]、CoBATCH[34]和ChIL-seq[35]等,在单细胞表观测序方面都具有深远意义和广阔的发展前景。
通常情况下,染色质可分为松弛型和紧密型两种状态,紧密型染色质往往不易于与蛋白质等调控因子结合,可及性较弱;而松弛型染色质更容易被调控因子等识别并结合,可及性较强,因此染色质可及性的研究也是基因组研究的一大重点。以转座酶为载体研究染色质可及性的技术(assay for transposase accessible chromatin with high-throughput sequencing,ATAC-seq)在这一领域有着极为重要的地位。该技术利用Tn5转座酶优先结合DNA中未受核小体保护的区域的特点,将测序接头引入染色质的松弛区域进行测序,以测定全基因组的染色质可及性[36]。相比以往染色质可及性的测定方法,ATAC-seq中Tn5的使用使DNA的切割和接头的插入同时进行,简化了实验流程,从而大大降低了对样本量的要求。但同时ATAC-seq也存在一些问题,例如,由于Tn5转座酶在插入测序接头时方向随机,一个片段两端的接头可能相同,导致仅有一半的片段可被测序[37]。此外,当片段过大时,也难以进行体外的PCR扩增[37]。
近年来,研究者们对ATAC-seq技术进行了多种改进。THS-ATAC-seq技术是利用类似LIANTI技术的方法将T7启动子引入染色质可及位点并进行体外转录,随后对转录本进行建库测序。并且,为了解决ATAC-seq中片段两端接头相同导致测序效率降低的问题,研究者们还设计了由两套转座体复合物二聚体先后进行转座以分别加入两端测序接头的方法[37]。此外,Single Cell ATAC-seq技术提供了单细胞染色质可及性的测定方案,使异质性细胞染色质可及性的差异得以检测[38-40]。Omni-ATACseq技术在转座反应中使用PBS以增加信噪比,可以消除线粒体的干扰,提高染色质可及性数据的质量[40-41]。UMI-ATAC-seq技术通过把带有标准TruSeq测序接头的 UMI(unique molecular identifiers)应用到ATAC-seq中,将PCR导致的重复序列与固有的重复序列区分开,能更准确地量化染色质可及性[42]。近期,新开发的ATAC-MS技术将ATAC-seq与质谱技术相结合,使开放染色质结合蛋白得到更精确的检测,这相比之前在ATAC-seq后通过数据分析猜测蛋白质结合位点要更加精准[43]。
4 Tn5建库在长片段测序中的应用
二代测序技术虽然实现了人们对基因的进一步研究,但是它只能有效读取短片段的特点使得最初的长片段测序往往需要先将长片段打断,测序后进行拼接。这种方法不仅复杂繁琐,而且给基因组中同源序列的辨别和染色体结构变异的鉴定带来困难。Peters等[44]利用稀释法将长片段相互分离后打断,并在打断后的每个短片段上添加barcode和测序接头,在测序后利用barcode区分不同的长片段并完成拼接。但将混合的长片段稀释为单条片段操作复杂,且后续处理成本高。2017年,stLFR(single-tube long fragment read)的开发解决了这一困难。研究人员利用Tn5在被SDS去除之前都一直与DNA片段结合且不脱落这一特性[45],将Tn5转座酶先与长片段DNA结合后,再与表面含有不同barcode的磁珠共同孵育[46]。由于转座酶上结合的特殊DNA片段可以与barcode侧翼链杂交并连接,不同的长片段会附着在不同的磁珠上。随后加入SDS可打断长片段并将磁珠表面的barcode转座到每一个短片段中,最后通过PCR加入测序接头即可进行常规测序[47]。该方法弥补了二代测序的不足,相比三代测序成本更低,准确性更高,具有广阔的应用前景。
5 Tn5建库在转录组测序中的应用
在常规转录组建库中,往往需要先富集目标RNA再将其片段化,随后进行一链和二链cDNA合成、接头连接和PCR扩增等。尽管Tn5转座酶建库方法的普及简化了其中的步骤,但是其仍然无法满足对微量RNA样本方便、快捷地进行转录组测序及分析的需求。2020年,Tn5转座酶被证实可以直接作用于DNA/RNA杂交链,基于此,研究者们开发了一种转录组建库新方法,并命名为TRACE-seq(transposase-assisted RNA/DNA hybrids cotagmentation)(见图3),该方法可以简化实验流程,降低建库成本及样本的输入量[48-49]。TRACE-seq具有广阔的应用前景,它有望用于获取与复杂的宿主背景混合而无法体外培养的低滴度病毒的全基因组[50]。近期,TRACE-seq也被证明具有获取综合信息的潜力,可用于表征复杂的宿主与微生物组之间的相互作用[51]。
6 小结与展望
Tn5转座子独特的转座机制使其可以将文库构建中DNA的片段化、末端的补齐和接头的连接3个步骤简化为单一且快速的反应,这大大简化了文库的构建流程,同时降低了对样本量的需求,这在疾病的研究中具有深远的意义和广阔的前景。此外,LIANTI的应用降低了由PCR扩增带来的扩增偏差和错误,使得文库中DNA的扩增更加保守。在长片段测序中,Tn5转座酶的应用弥补了二代测序短读长的缺点,相较于三代测序其成本更低,准确性更高,这使得一些染色体疾病的检测变得更加便捷。
除此之外,Tn5转座酶还被应用在多个领域中。例如BAT Hi-C技术利用Tn5转座酶进行染色体3D构象的捕获[52];FACT-seq技术利用Tn5转座酶开发出有效分析福尔马林固定石蜡包埋组织中组蛋白修饰的方法[53];SorTn-seq技术利用Tn5转座酶高通量筛选细菌基因表达的调节因子[54]。Tn5转座酶在各种技术中的应用显著降低了对样本量的要求,这使许多稀缺的样本也能够满足各种测序的要求。同时,Tn5转座酶与barcode等技术的结合提高了单细胞测序的可行性。目前,Tn5转座酶在单细胞测序领域的研究还相当稀缺,对相关技术的开发和改进还有待研究。但Tn5转座酶所具有的单细胞测序潜力在细胞分化、肿瘤异质性的研究中备受关注。虽然目前Tn5转座酶的使用并未普及,但是随着技术研究的不断深入,Tn5转座酶有望打开单细胞测序等领域的新局面。
猜你喜欢
林业科学(2022年1期)2022-03-23
中国农业科学(2020年7期)2020-04-11
资源导刊(信息化测绘)(2018年2期)2018-08-15
考试周刊(2018年26期)2018-04-19
求知导刊(2017年6期)2017-04-15
浙江农林大学学报(2016年6期)2016-12-12
贵州师范学院学报(2016年1期)2016-12-01
安徽大学学报(自然科学版)(2016年2期)2016-09-20
赤峰学院学报·自然科学版(2015年18期)2015-03-20
有机氟工业(2014年4期)2014-06-01
