
3D SE-ResNet:一种从CT图像中自动分割COVID-19肺部感染模型
2022-03-10 09:34朱勇谢勤岚
中南民族大学学报(自然科学版) 2022年2期
朱勇,谢勤岚
(中南民族大学 生物医学工程学院,武汉 430074)
2019年12月,一种新型冠状病毒被世界卫生组织(WHO)认定为新冠病毒(COVID-19),被认定为急性呼吸道疾病爆发的原因[1].截止2020年11月30 日,疫情爆发约一年时间内,全球已有186 个国家和地区报告了62973267 例新冠肺炎病例,造成1463105人死亡.目前,COVID-19 具有与严重急性呼吸综合征(SARS)和中东呼吸综合征(MERS)类似的病理特征.因此,电子计算机断层扫描(Computed Tomography,CT)被认为是COVID-19 早期筛查和诊断的一种低成本、准确、高效的方法诊断工具.它可以评估肺部感染的严重程度,以及患者疾病的病变情况,这有助于做出治疗决定[1].因此,开发了一种基于深度学习的COVID-19 感染区域检测与分割网络,是可行的和有意义的.
针对COVID-19 图像分割问题,研究人员提出了很多分割方法.王生生[2]等人提出一种基于联邦学习和区块链的COVID-19 胸部CT 图像分割方法,该方法利用联邦学习和区块链结合的分步式训练方式来解决患者样本少和感染分布广等问题,采用轻量级的2D U-Net 降低运算量,得到Dice指标为0.632.GOZE[3]等人提出了一种利用二维切片分析和三维体积分析实现COVID-19 分割检测的系统.JIN[4]等人提出了一种COVID-19 快速诊断的AI 系统,首先利用分割模型获取肺部病变区域,然后利用分类模型确定每个病变区域是否具有COVID-19 感染特征.ZHOU[5]等人提出了一种基于注意机制的U-Net 分割网络.将注意力机制纳入UNet 架构,以捕获丰富的上下文关系,并引入了tversky 损失来处理较小的分割.在只有100 张CT切片的小数据集上进行的实验,得到的Dice 指标为0.691.MULLER[6]等人偏向于利用广泛的数据增强和多种预处理方式对数据处理,并采用标准的3D U-Net 模型对COVID-19 进行分割.从而避免了小数据集在复杂模型训练时产生的过拟合风险,最终Dice 指标达到0.761.基于此,提出了一种挤压与激励模块和注意力机制结合的残差3D U-Net 网络模型,并在U-Net 过渡层引入ASPP 模块,以实现对图像多尺度特征提取.减少上采样和下采样层数,降低模型计算量.实验证明,提出的方法较优于目前的分割方法.
1 材料和方法
1.1 网络工作流程
提出的用于COVID-19 CT 图像分割的3D SE-ResNet 网络及工作流程如图1 所示,包括四个主要阶段:训练数据准备、预处理和数据增强、网络训练、网络测试.具体的,首先将200 张图像经过数据预处理和大量的数据增强(如弹性形变,高斯噪声等)获得一个可供训练的变异数据库.基于实验的硬件环境,设置批处理大小为2,图片大小为160 ×160 × 80.接着传入3D SE-ResNet(如图2 所示)网络模型中,获得分割处理后的图像.最后,为了提高预测性能,将真实值图像裁剪成为8个小体块,每个小块大小为80 × 80 × 40.同样,分割得到的图像也经过相同的处理,计算对应体块的重叠率.通过组合再将图像还原至原先尺寸,计算8 个体块重叠率平均值,得到最终的DSC指标结果.
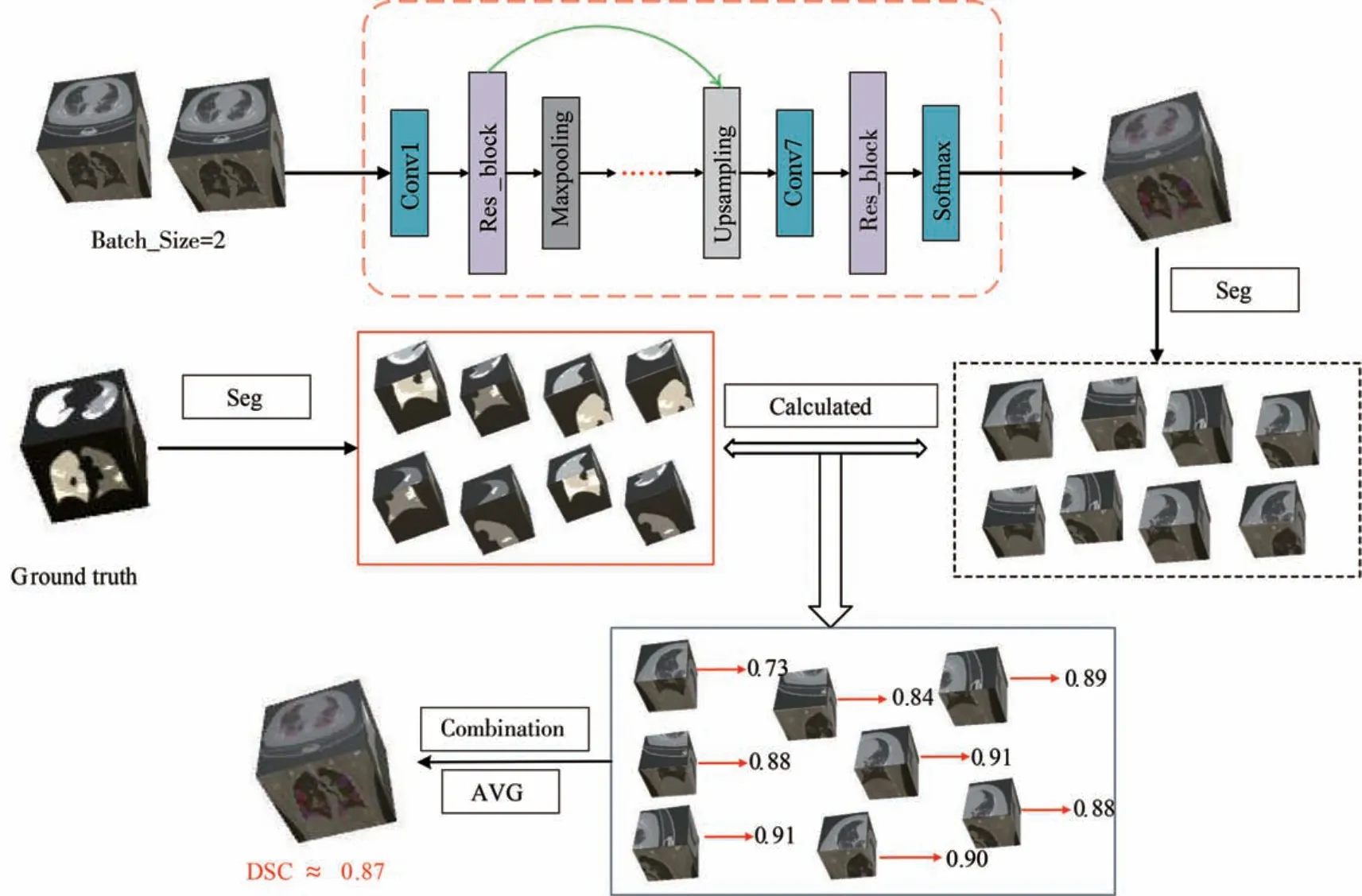
图1 所提出的深度学习算法整体网络框架,从图像传入到最后的数值分析Fig.1 The whole network framework of the proposed deep learning algorithm is introduced from the image to the final numerical
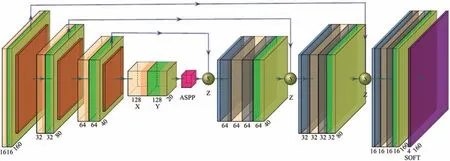
图2 融合模块的3D SE-ResNetFig.2 3D SE-ResNet of the fusion module
1.2 COVID-19-CT-Seg 数据集
实验数据集采用了MA 等人的公共数据集,其中包括20 个COVID-19 胸部CT 体积扫描图和1800多个带注释的切片[7-8].这20 张公开的COVID-19 CT扫描图可以通过CC BY-NC-SA 许可证免费下载.左肺、右肺、感染区域由初级审批员勾画,再由两名5年经验的放射科医师提炼,最后由一位10年以上胸片经验的资深放射科医师测试.一次CT 扫描250 个切片,需要400±45 min 才能勾画出轮廓[7].这些CT 扫描图分别为10 张来自Coronacases Initiative(CI)数据集分辨率为512 × 512 和10 张来自Radiopaedia(Ra)数据集分辨率为630 × 630 组成,切片数的平均值约为176(中位数为200).CT 图像分为四类:背景、左肺、右肺和COVID-19 感染区域.考虑到数据集的大小,为了提高神经网络的测试精度和通用性,在训练神经网络时需要进行数据扩充.
基于设计的网络模型,放弃了在传入神经网络之前使用参数变换来实现数据扩充.为了不改变原数据集的标注和勾画标准,通过将原本数据集复制9次,产生一个包含100张CI和100张Ra共200幅的CT体积扫描图的数据集.复制扩充是一个增加数据量最直观的方式.随着复制规模的增加,数据集中相同的图片也随之增加.为了解决这个问题,在数据传入模型训练之前,通过大量的概率性增强方式来增加相同图片之间的差异.例如,在数据不复制扩充时,采用15%的增强比重就可以产生一个变体数据库.随着复制规模的增加,当单张图片复制4次产生100张图像的数据集时,采用20%的增强比重;复制9次时,采用25%的增强比重.在不断增加图片的复制规模时,相应的增强比重也要增加,以加大相同图片的差异.在实验中,不通过复制扩充时,测试曲线上下波动幅度较大.随着复制规模的增加,波动幅度随之减小.当复制程度达到9次时,测试曲线趋于稳定.从而证明,扩充数据集方式有效地避免了过拟合风险.
2 网络模型
基于COVID-19 分割的难度,常规的3D U-Net已经不满足检测所需,需要添加新的模块以增强网络模型数据拟合.根据U-Net 网络在分割领域的天然优势,在3D U-Net 的基础上搭建网络模型3D SE-ResNet,如图2 所示.在大量实验中,由于对图像特征提取不充足导致模型欠拟合的现象时有发生.因此,通过添加挤压与激励模块(SE)增强模型对图像信息特征提取的敏感程度非常有效[9].将SE 模块嵌入残差模块中,以优化网络结构(如图4).在U-Net 的中间层和上采样的瓶颈处,添加ASPP 模块.采用ASPP 模块的主要目的是希望模型能够更好地获得图像的多尺度信息,使得COVID-19 3D CT图像的空间特征信息能够被有效提取.网络模型还引用最近几年比较流行的注意力机制模块(如图6).由于模块的添加,网络变深,不仅牺牲了大量的训练时间,同时随着特征数的增加,使得计算机内存单元溢出.通过对3D SE-ResNet 的参数进行了调整,相对于标准的3D U-Net 网络,减少了下采样和上采样层数,并将初始通道数设为16,以降低模型参数量和计算量.通过实验证明,所提出的网络模型对图像分割展现出良好的性能.
2.1 嵌入挤压与激励模块的残差单元
残差块与普通卷积块连接,构成U-Net 网络的基本单元[10].普通卷积块由卷积层,ReLU 激活函数和批处理归一化层(BN)组成.残差块(如图3)分成两部分:短连接部分和残差部分.式(1)所示,h(xl)为短连接部分,将初始值输入保存;f(xl,Wl)为残差部分,其由两个卷积块组成.将两个部分输出结果进行加计算作为整个残差模块的输出.
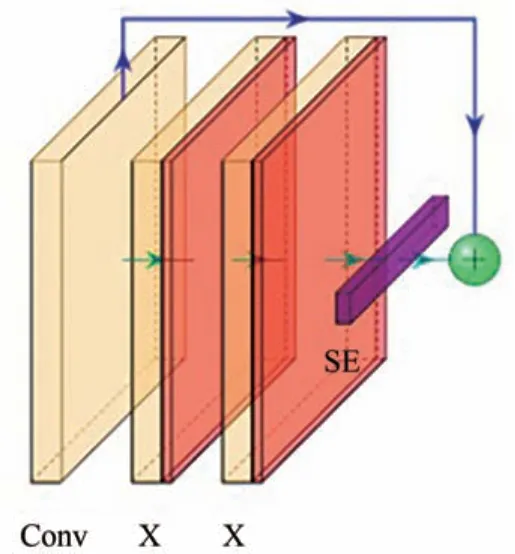
图3 Y由两个卷积模块、SE模块和短连接组成的残差单元Fig.3 Y is a residual unit composed of two convolution modules,SE module and short connection
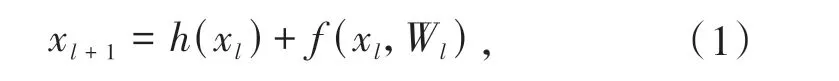
将SE模块(如图4)嵌入在残差模块中,以优化网络模型.SE模块主要包含Squeeze(压缩)和Excitation(激励)两部分.
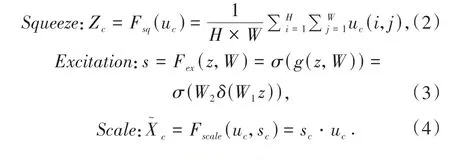
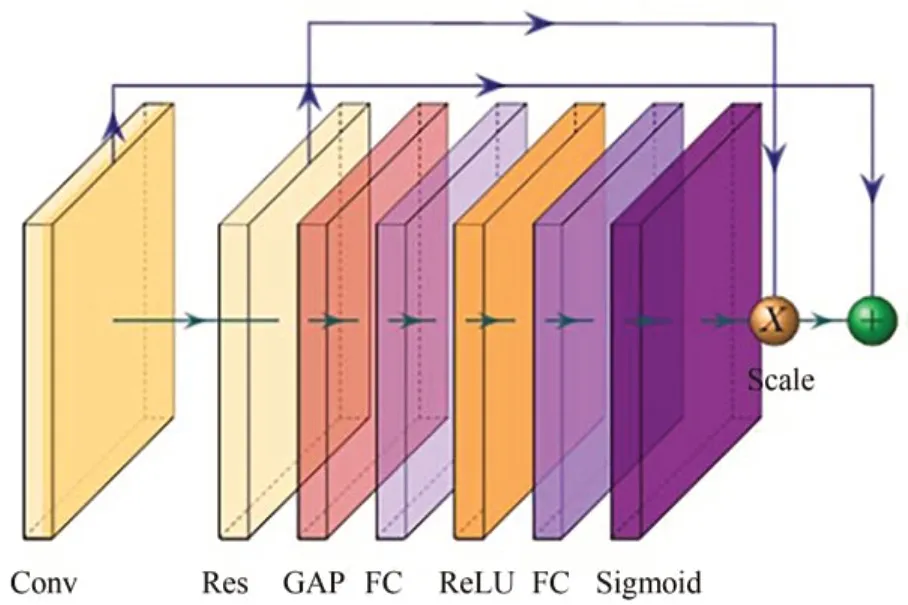
图4 来自SENet网络的主要模块,挤压与激励模块(SE)Fig.4 Main modules from SENet network,Extrusion and Excitation Module(SE)
具体操作:W×H×C的特征图经过全局池化压缩为1 × 1 ×C的向量,后经过第一个全连接层,通过缩放参数SERatio减少通道个数降低计算量.在这里设置缩放参数为1/16,输出为1 × 1 ×C×SERatio.经激活函数和第二个全连接层后,再经过激活函数输出为1 × 1 ×C,最后进行Scale 操作得出结果并输出.
2.2 并联特征金字塔模块
DeepLab 网络中提出了空洞卷积空间金字塔(Atrous Spatial Pyramid Pooling,ASPP)结构[11].空洞卷积是ASPP 模块的核心[11].U-Net 通过下采样提高感受野,会导致图像分辨率的降低,从而丧失了图像边缘或局部信息.空洞卷积可以在不降低图像分辨率的情况下扩大感受野,捕捉多尺度上下文信息.ASPP 模块使用具有不同采样率的多个并行空洞卷积计算,并将每个采样率采样的特征放入单个分支进行处理,最后融合生成最终的结果(如图5 所示).在模型的上采样瓶颈处添加ASPP,设置采样率为[1,6,12,18],达到对COVID-19 3D CT 图像的空间信息提取.具体地,将输入特征图X作为多尺度表征的第一个尺度.输入特征图X 经过4 个卷积核大小为3 × 3 × 3,空洞率分别为1、6、12 和18 的卷积层进行特征提取.最后,将5个尺度的特征图进行通道拼接和融合后得到最终的多尺度表征.
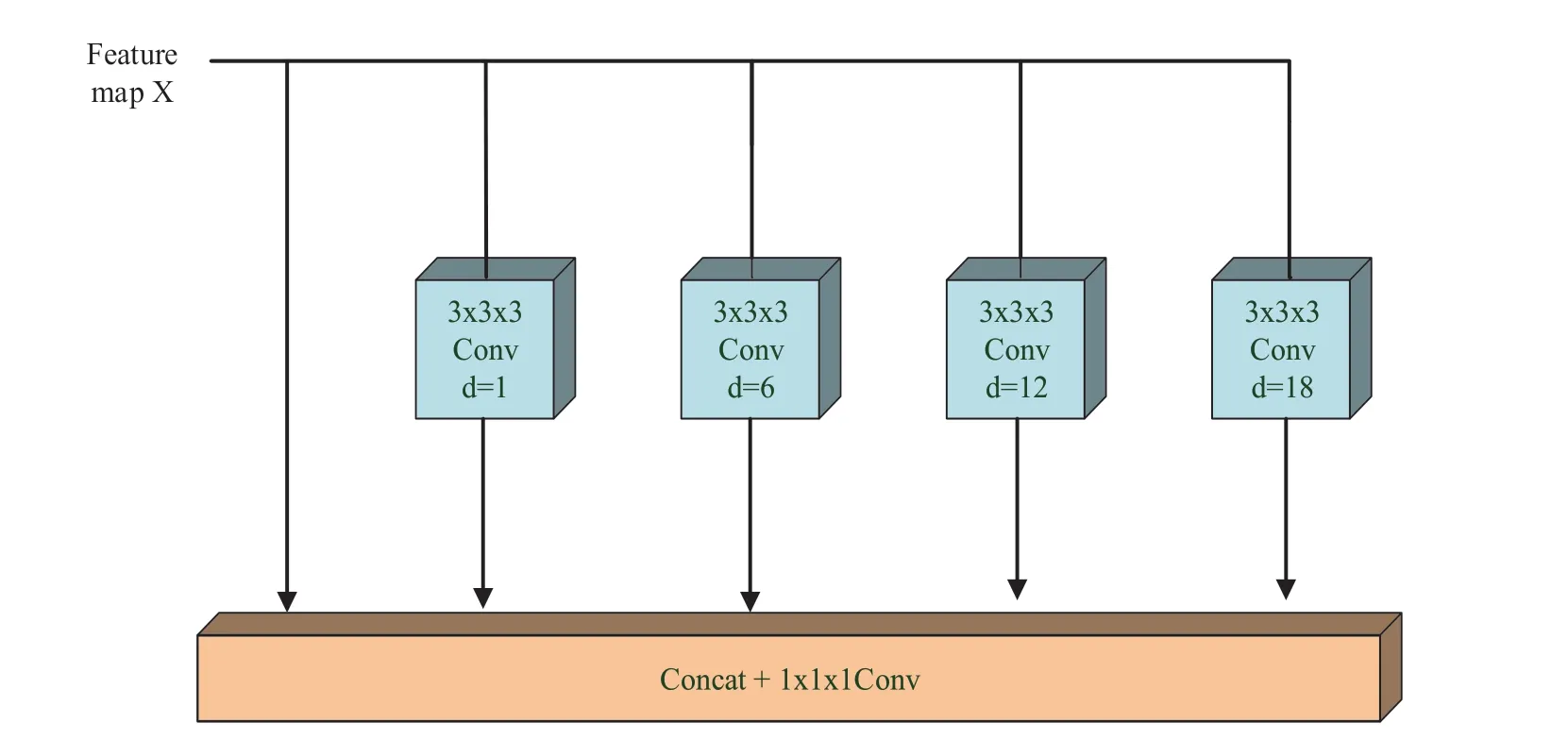
图5 ASPP结构Fig.5 The structure of ASPP
2.3 基于注意力机制的注意力模块
在上采样X处,添加注意力模块,其模型架构如图6 所示[12].相对于作者Oktay O,通过对注意力模块稍做修改以简化网络.标准3D U-Net,由编码器和解码器两个部分组成[13],跳跃连接允许解码器直接使用由编码器提取的特征.重建图像的掩模时,网络就学会了使用这些特征,因为编码器提取的特征与解码器的特征是连接在一起的.并且注意力模块可以逐步抑制不相关背景区域的特征响应,而不需要在网络之间裁剪感兴趣区域[14].基于此,在上采样的瓶颈处嵌入注意力模块(如图6 所示),可以使网络对跳跃连接相关的特征施加更多的权重,可以专注于输入的部分特征,而不是每个特征.
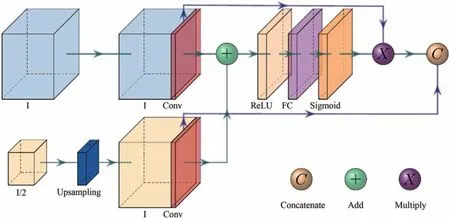
图6 在上采样和短连接处嵌入注意力模块如图2的球体SFig.6 The attention module is embedded at the upper sampling and short connection as shown in the sphere S in Fig. 2
3 实验训练与评估
3.1 训练
将所有的COVID-19 3D 图像随机分为80%和20%比例的训练集和测试集.通过对样本进行形状,色彩和噪声等大量数据增强处理,产生变体数据库供训练和测试所用.实验中,执行了一个k-fold交叉验证策略(KD5)来进行网络优化和整体评估[14].在数据集样本中,单个样本背景类的分布为89%,肺为9%,感染类为1%[6].平均绝对误差(MAE)损失和广义交叉熵(GCE)损失已被证明对图像分类具有噪声鲁棒性[15-16].但是,单纯地将其应用于分割任务中,由于前景和背景的像素个数不平衡,可能导致性能有限[17].为了解决这种不平衡,引入Tversky相似指数和交叉熵损失函数之和作为模型拟合的损失函数[6,17].并采用动态学习率,更好地进行模型拟合.设置初始学习率为1e-3,在训练15个轮次损失没有发生变换时,学习率除以10.为了防止陷入极小值点,设置最小的学习率为1e-5.大量实验表明,模型在训练平均250 轮次时,训练达到包含饱和状态,如图7左所示.本工作是在NVIDIA GeForce GTX 1080 TI GPU windows 7操作系统上使用TensorFlow后台、CUDA10.0和CUDNN7.6.0的Keras框架实现的.
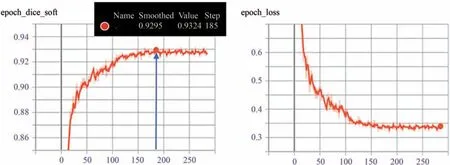
图7 通过监控训练数据和损失值,检测模型拟合状态. 在单次训练185轮次,训练精度达到0.9324.Fig.7 By monitoring the training data and loss values,the fitting state of the model was detected. In 185 rounds of single training,the training reached 0.9324.
3.2 评估指标
实验评估采用社区中广泛使用的三个医学图像分析评价指标进行推理模型性能,以衡量分割的预测和ground truth之间的重叠.(5)式中定义的骰子相似系数是计算机视觉中最普遍的度量.相比之下,敏感性(6)式和特异性(7)式是医学领域的指标之一.所有指标都基于混淆矩阵,其中TP(true positive)、FP(false positive)、TN(true negative)和FN(false negative)分别表示真阳性率、假阳性率、真阴性率和假阴性率.
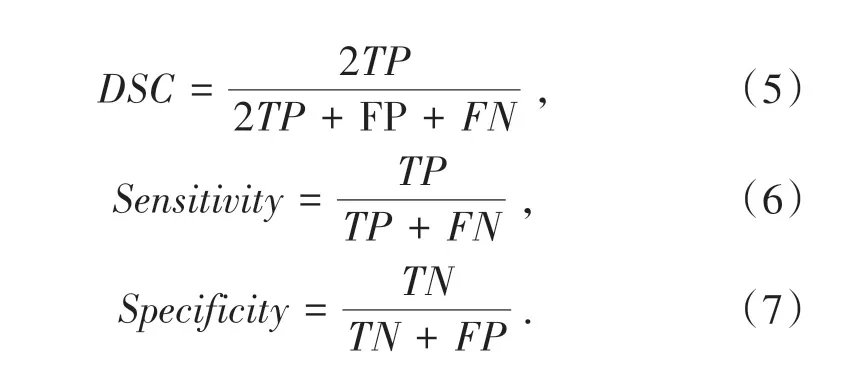
3.3 三维网络分割
从3D肺部体积图像第116切片处提取CT Scan,Ground Truth,Prediction 三幅图片对比了标准3D U-Net[6]网 络(2),3D ResNet[7]网 络(3)与3D SEResNet(1),如图8所示.
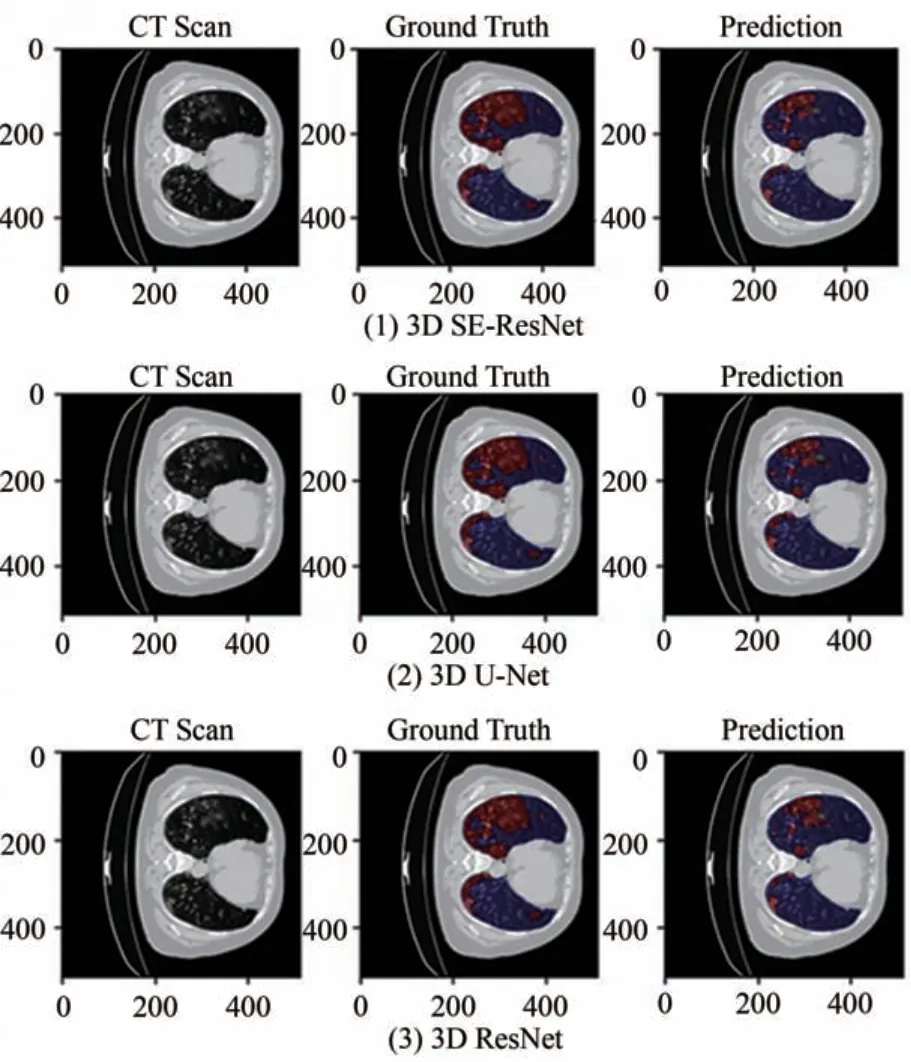
图8 不同网络对3D CT图像分割效果图Fig.8 3D CT image segmentation effect of different networks
ResNet 相对于U-Net 网络来说,随着网络的加深,由于短连接的存在,实现了对图像深层次特征和高频信息的提取.由3D SE-ResNet 网络分割得出的效果图来看,网络不仅能够整合其他网络的优点,而且能够获取图像整体信息.这得益于采用的ASPP 模块,加强对图像多尺度信息特征的提取.嵌入的挤压与激励模块,也为增强了全局信息来选择性地强调信息性特征.但由于,COVID-19 感染区域分布广泛且形状不一,边缘区域像素少等因素也增加了分割的难度.这也是目前3D 分割的难题.相对比来说,所提出的网络模型能实现图像整体和细节部分的分割且较优于其它的网络.
3.4 基于五折交叉验证
使用K-fold 交叉验证策略将数据集给与每个小组(K=5),并对每组独立进行统计分析.受制于数据集的大小,没有将数据集划分给每个小组,而是将每个小组的训练和测试数据都引用原始数据集.每个小组将获得200 个数据样本,并将其独立随机的划分为训练和测试数据,比例为4∶1.为了使交叉验证获得更好地效果,在训练每一个fold时,大量的数据增强会产生一个变体数据库,包含200 幅相同尺寸但不同的3D CT 图像.而且,在训练每个fold 时,会实时产生不同的变体数据库.基于5 折交叉验证的检验结果在敏感度、特异性、DSC 方面如表1 所示.在第四次训练中,监控肺部感染区域的三个指标都得到最好的结果,DSC 达到了89.40%.而在第五次训练中,监控肺感染区域的三个指标均得到最低的结果,主要原因可能在于每次训练测试中,使用一个25%概率数据增强的变体数据库,其中包含200 张不同的3D CT 图片,从而导致指标不一或低于均值的结果.由此可见,交叉测试策略的有效性.在五次交叉测试之后,肺,背景和COVID-19 感染区域分割的平均DSC 分别为0.974,0.998 和0.870.显示了实验提出的3D SE-ResNet 在分割方面的高效性.为了进一步评估网络的性能,在相同环境和硬件配置下,进行3D ResNet,3D U-Net,3D SE-ResNet网络的对比实验结果如表2所示.可以看出,所提出的3D SE-ResNet 网络相对于3D ResNet,3D U-Net,在DSC 方面分别提升了1.03%,2.85%.从医学角度来看,CT 图像有三个维度,二维卷积神经网络不能充分利用图像数据的三维特征和空间信息[18].而由于GGO的多样性和肺实变形态[6],造成了目前3D网络模型分割精度较低的情况.随着近几年,深度学习的快速发展,网络分割精度会有更多的提升.
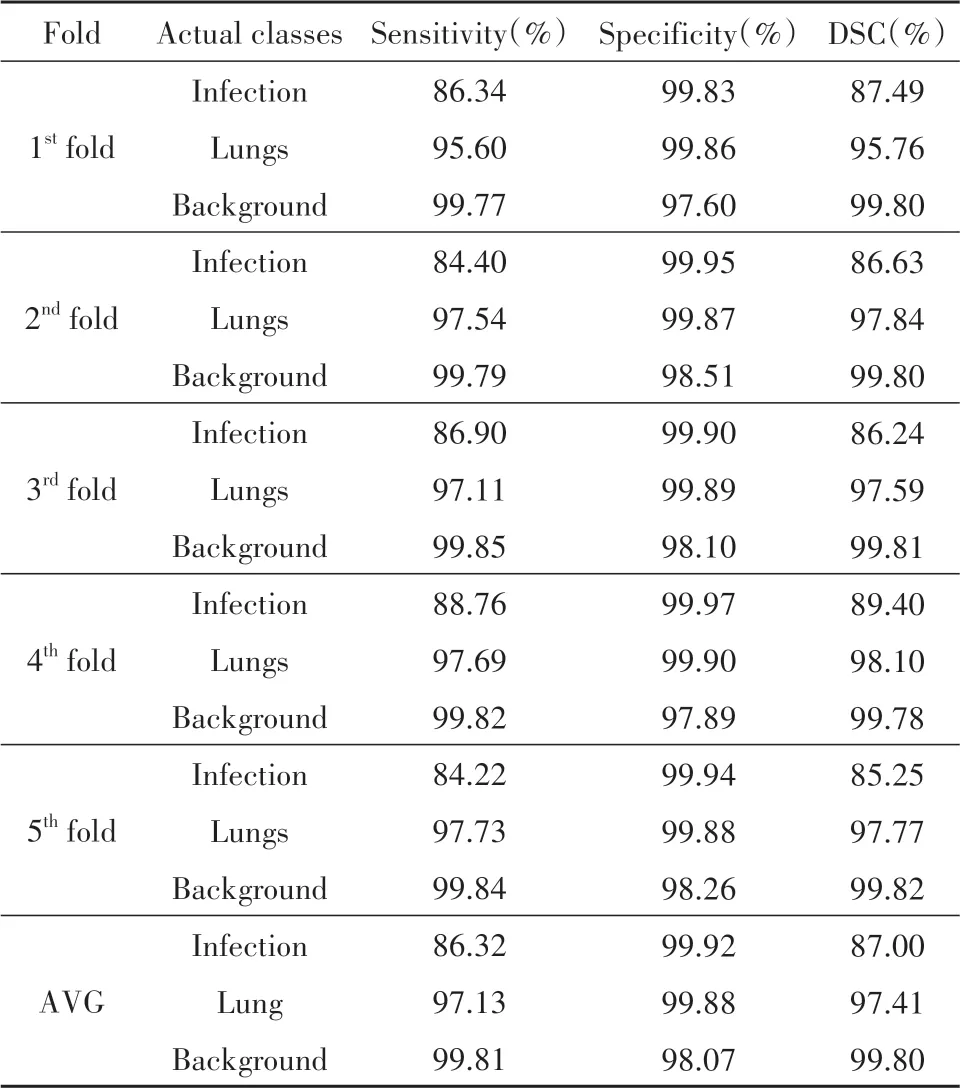
表1 基于5折交叉测试不同类别的评价指标数值Tab.1 The evaluation index values of different categories were verifiedbased on 5 fold cross validation
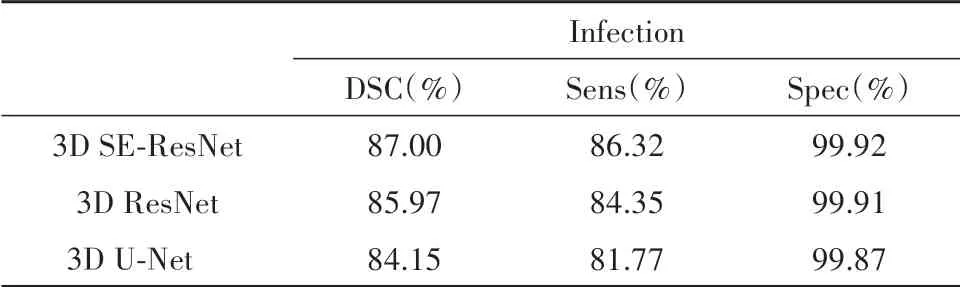
表2 不同网络对感染区的分割均值统计Tab.2 The mean segmentation of infected areas by different networks was counted
4 讨论与总结
通过大量实验结果显示了3D SE-ResNet在检测与分割感染区域具有高精度和有效性.同时还证明了在训练数据不充分的条件下,利用扩充数据的方式,在每一个Fold运行之前,通过大量的数据增强形成一个独立的变体数据库供训练测试使用,对模型拟合和避免U-Net 在小数据集上表现的过拟合倾向具有高效性.作者MULLER D[6]使用相同的数据集,利用标准的3D U-Net,达到COVID-19感染区域分割的DSC为0.761.通过扩充数据集以及数据增强产生变体数据集的方式,利用标准3D U-Net作对比实验,COVID-19 感染区域分割的DSC 达到0.841,证明了扩充方式对精度提升有很好的作用.在大量的实验中,每个Fold并不需要300轮次进行训练,而在平均250 轮次达到饱和状态,并且在训练中通过监控Training和Loss(如图7所示),并未发现过拟合现象.模型训练时,每张160 × 160 × 80 的3D 图片处理时间大约为3秒,这也为该网络模型进入医疗影像作为辅助诊断提供了可能.从医学角度来看,三维图像相对于二维图像,更能表现出空间信息.为此,实验致力于三维图像分析.所提出的3D SE-ResNet网络,通过引入挤压与激励模块,根据网络的通道数调整缩放因子为1/16,使得网络能够自适应地重新校准通道特征响应,并通过卷积层重新校准信道上的信息来消除不太有用的表示.引入ASPP 模块,以增强网络模型对COVID-19 3D 图像多尺度空间信息的提取.在相同数据集,相同实验环境下做了三组对比实验,实验结果如图9所示,箱型图能够使实验数据更加透明和直观.受纸张页宽限制,箱型图只展示了ResNet 和SE-ResNet 数据对比图.由此可以看出:所提出的3D SE-ResNet 在COVID-19 分割上优于最突出的深度学习方法(如3D ResNet和3D U-Net).
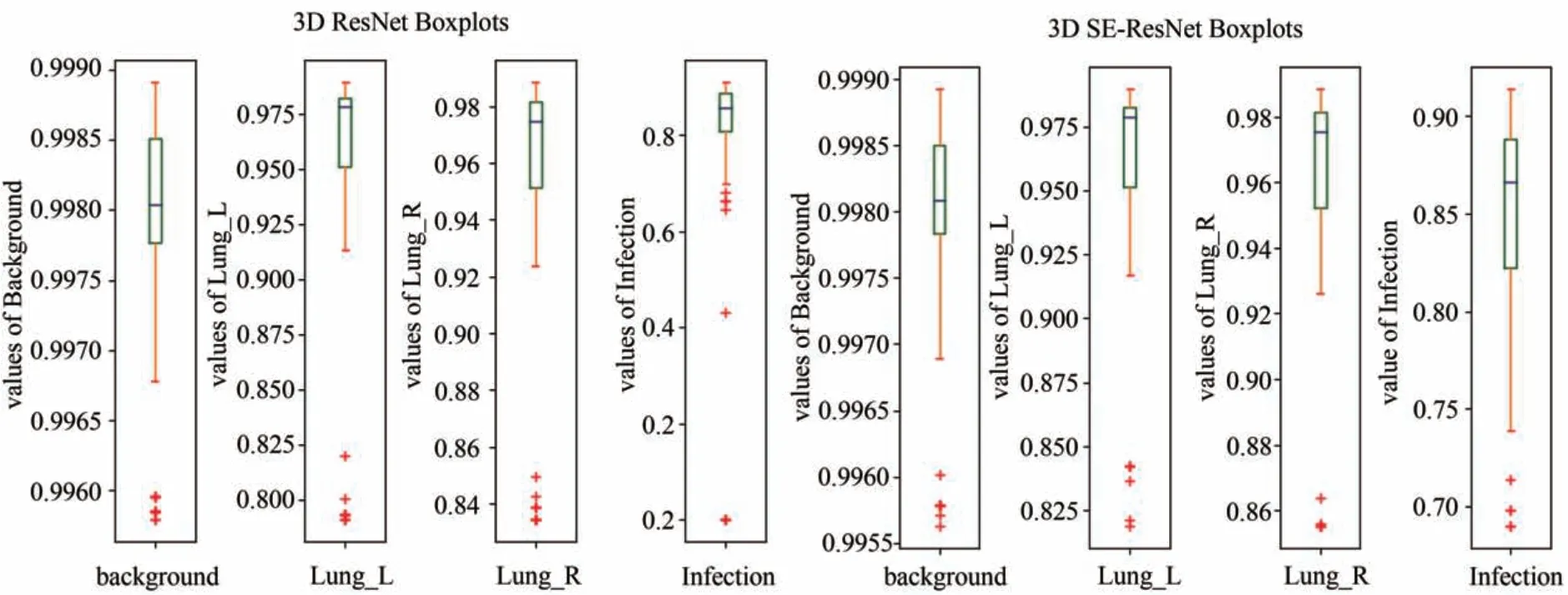
图9 箱形图显示不同类别基于5折交叉测试的实验结果Fig.9 Box plot shows the experimental results of different categories based on 5-fold cross validation
猜你喜欢
农业工程学报(2022年12期)2022-09-09
心理学报(2022年9期)2022-09-06
成都信息工程大学学报(2022年2期)2022-06-14
心理学报(2022年4期)2022-04-12
北京大学学报(自然科学版)(2022年1期)2022-02-21
汽车工程师(2021年12期)2022-01-18
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
中学生数理化(高中版.高考理化)(2021年5期)2021-07-16
