
基于代价敏感学习的财务造假识别研究
2022-03-09 06:35:14宋海涛
财会研究 2022年2期
■/ 张 悦 宋海涛
一、引言
财务造假是一个长期困扰市场发展的世界性问题,放眼国内外,安然、世通、泰科等商业巨擘轰然倒塌,蓝田股份、银广夏等商业神话陆续破灭。由于我国证券市场发展时间相对较短,近几年财务造假现状愈发严峻,不断有上市公司前赴后继:乐视IPO 造假、瑞幸被浑水公司做空而后退市、康美连续三年造假,等等。财务造假不仅损害投资者切身利益,还对市场发展产生无法磨灭的深远负面影响。然而随着财务造假的加剧,审计、法务会计、舞弊审查师等专业人员受时间、精力、成本等限制逐渐无法满足监管需要,以机器学习与深度学习为主的数据挖掘技术为财务造假识别提供了有力的帮助。财务造假识别是一个典型数据不平衡问题,同时具有严重的代价敏感性,尽管发生概率相对较小但造成的损失极大。
现实世界的数据往往呈现长尾分布,数据分布空间存在偏斜,不同类别的数据存在数量级的差异,尽管财务造假公司数量攀升,但相对于庞大的上市公司基数仍旧是小样本,这就是数据不平衡(Data imbalance)。另一方面,遵循着“二八定律”,少数类数据往往包含着更重要的信息,在财务造假识别上漏报成本远远高于错报成本,这种误分类成本的不同引发了代价敏感性问题(Cost sensitivity)。目前机器学习和深度学习的标准算法研究大多基于类分布平衡或误分类成本相同假设,即认为数据集中的各类样本无显著差异,这将导致学习会因偏向数量多的类别而在财务造假识别的应用上效率低下甚至失效。
本文针对财务造假识别的数据不平衡与代价敏感性,首先构建代价敏感决策树作为财务造假识别模型,接着根据舞弊成因理论选择特征指标,再以2015年我国上市公司作为研究对象进行对比实验,以验证代价敏感学习模型的有效性,并通过对比实验结果的分析输出财务造假识别路径。
二、文献综述
在机器学习与深度学习中,数据不平衡和代价敏感性是阻碍分类性能的巨大挑战,其技术解决取决于三个因素:数据分布、分类器的选择和性能测量方法,对应着数据层、算法层、评估层方法。数据层面是在预处理阶段对数据集进行平衡,主要采用重采样技术,包括以SMOTE、Borderline-SMOTE、ADASYN、MWMOTE、DBCSMOTE 为代表的过采样,及以NearMiss、ENN、CNN、CBO 为代表的欠采样。算法层面以代价敏感学习为代表,主要对学习模型进行改造及参数调整,对误分类成本进行修正。集成学习将数据层与算法层方法结合,如EasyEnsemble、BalanceCascade。评估层面是一种事后处理,通过评价指标评价学习的有效性。另外,半监督学习和自监督学习经过验证也能够有效提高学习表现,通过对无标签数据的利用在数据和算法层面实现学习。
代价敏感学习通过引入代价矩阵描述不同类别的误分类成本来解决不平衡问题,其目标不在于误报率最小化,而在于误分类成本最小化,学习途径包括模型选择与损失函数改进。决策树常被看做是最适合解决样本不均衡问题的模型,因此学者们展开了对决策树的代价敏感学习,主要从决策阈值移动、中间节点分裂标准以及剪枝进行。Domingos(2002)提出MetaCost,根据贝叶斯风险理论将代价矩阵引入,为后续研究提供重要基础。Zouboulidis&Kotsiantis(2012)将集成学习、MetaCost 与代价敏感决策树相结合,用于希腊上市公司财务报表造假预测。Sahin et al(2013)提出了一种代价敏感决策树用于检测信用卡欺诈,分类效果优于其他标准算法。Kim et al(2016)结合MetaCost 构建出多分类代价敏感模型MLogit,识别出92%的故意财务错报。Moepya et al(2017)在SVM、KNN 和NB的基础上构建代价敏感模型,并在南非上市公司样本集取得良好效果,随后又对决策树与随机森林模型进行改造,并利用缺失值处理改善财务造假识别模型。Lin et al(2020)提出Focal Loss,通过改造交叉熵损失函数解决目标检测中的样本不平衡问题。从评估指标来看,可以考虑代价信息对标准指标赋予权重以改进。Sahin et al(2013)提出了Saved Loss Rate 用于衡量分类效果。Hajek&Henriques(2017)利用财务造假损失金额和审计费用度量分类错误成本,为错报率与漏报率赋予不同权重。Long et al(2020)提出一种均衡准确度为TPR和TNR赋予不同权重。
针对数据不平衡与代价敏感性问题,国外学者从不同角度进行算法研究并应用于欺诈检测,而国内研究主要集中在理论与算法上,相对缺乏对财务造假识别的应用。本文主要从算法层和评估层入手,选取决策树模型进行代价敏感学习,通过对损失函数和评价指标进行改进以优化财务造假识别模型。
三、模型构建
财务造假识别是一个典型的二分类问题,常用的分类算法有逻辑回归、支持向量机、决策树、神经网络等,但标准算法受不平衡数据集与代价敏感性的影响向多数类(正常)偏移。由于决策树作为ifthen规则集合具有可解释性强的优点,因此选择对决策树进行代价敏感学习。
决策树是基于树结构进行决策的分类与回归模型,由一个根结点、若干中间结点(特征)和叶结点(决策结果)构成。决策树学习主要包括特征选择、决策树生成和修剪:特征选择基于信息增益和基尼系数最大化原则,剪枝通常是基于整体损失函数最小化达成。经典算法有ID3、C4.5、CART,前两者只能处理离散变量,而CART算法还可以处理连续变量。轻型梯度提升树(LightGBM)是基于决策树的集成学习算法,在梯度上升决策树(GBDT)的基础上,通过直方图算法和具深度限制的leaf-wise生长策略等改善在训练速度缓慢、内存占用过大及过拟合方面的问题,且自身能够进行特征选择、分类特征处理与缺失值处理。
代价敏感决策树主要通过引入代价矩阵,对损失函数和评价指标进行修改,从而实现性能优化。
(一)代价矩阵
二分类问题的代价矩阵(见表1)涉及4个分类成本,即CTN、CFP、CFN、CTP。可以认为预测正确的情况下不产生误分类成本,即CTN=CTP=0。误分类成本比CFP:CFN源于数据不平衡性与代价敏感性,其中数据不平衡性可以用样本不平衡度NN:NP衡量,代价敏感性来自上市公司审计费用与财务造假费用比值,即CostA:(CostF+CostA)。两者之间的关系通过寻优法进行确定。
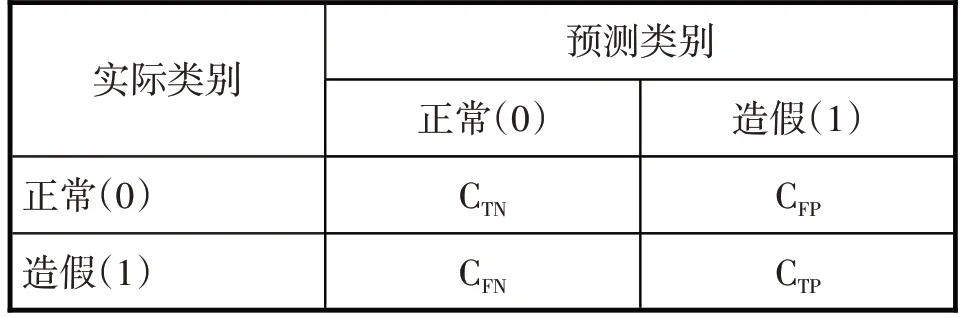
表1 代价矩阵
(二)损失函数
代价敏感学习通过引入代价矩阵对损失函数进行改造,用代价敏感交叉熵函数(CS_logloss)代替标准交叉熵损失函数(logloss):

(三)评价指标
集成学习在迭代过程中,利用代价敏感总损失(CS_costs)进行评价:
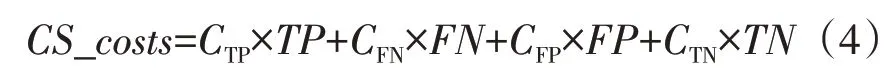
四、实验及结果分析
(一)样本选择与指标构建
1.样本选择。本文对2010—2020 年我国上市公司展开初步研究,数据来源于国泰安经济数据库、中国证监会等。霍华德M·施利特等(2012)将财务报表造假定义为“故意错报或漏报财务报表内容,使得在和其他可获得信息一并考虑时具有误导性,影响使用者判断或决策,以欺骗其他方如利益相关者和监管者”。基于此,我们对国泰安上市公司违规信息数据库截至2020 年12 月31 日的违规数据进行筛选:选择违规类型为虚构利润、虚列资产、虚假记载、推迟披露、重大遗漏、披露不实、欺诈上市、一般会计处理不当的数据,并结合证监会的处罚公告《行政处罚决定》进行准确筛选;剔除金融行业上市公司、关键数据缺失公司、上市前造假公司。
统计发现(见图1),2010—2020年的75起财务造假事件,共涉及73家上市公司,且财务造假行为具有连续性;财务造假的识别具有时滞性。2015年是财务造假高发年,共有27家上市公司财务舞弊,因此选择2015年国内上市公司作为研究对象。
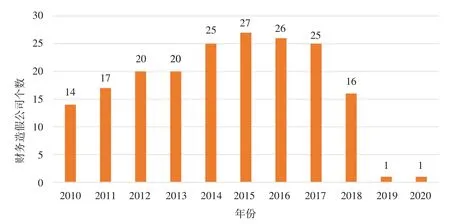
图1 2010-2020年财务造假上市公司统计
2.指标构建。目前对财务造假成因理论的研究主要包括三角理论、钻石理论、3C模型、GONE理论、风险因子理论与冰山理论,尽管表现不同但其含义相互联通(见图2)。其中Bologna et al(1993)提出的GONE理论认为,贪婪与需要是舞弊者造假的主观因素,机会与暴露为舞弊行为创造客观条件,共同导致舞弊行为得以实现。“贪婪”反映舞弊者的道德水平及价值判断;“需要”反映舞弊动机,主要来自各类压力;“机会”主要指在公司内部与权力相关的因素,由于缺乏监督与制约而让舞弊者有机可乘,包括企业缺乏内部控制、无法正确进行工作质量评估、缺乏惩罚措施、信息不对称、能力不足以及审计制度不健全;“暴露”作为客观条件中的外部环境因子,包括舞弊行为被发现的可能性以及披露后对舞弊者的惩罚性质与程度,与“机会”共同促使舞弊行为的发生。

图2 财务造假成因理论
结合财务造假成因理论与财务造假案例的研究,从贪婪、需要、暴露、机会等角度将上市公司特征划分为财务数据与非财务数据以进行定性与定量分析(见图3),包含了说明性信息和特征信息。

图3 财务造假特征
说明性信息包括上市公司的所处行业、上市交易所、成立时间、上市时间等;非财务特征信息包含了公司的股本结构、股权性质、内部治理以及审计信息;财务特征信息主要从偿债能力、经营能力、盈利能力、获现能力、发展能力、综合表现、风险水平以及结构分布等,由当年静态数据和动态增量数据共同构成。
(二)实验与结果分析
1.实验过程。首先对数据集进行划分。针对2015 年国内上市公司创建样本集,正常样本与造假样本2815:27,以4:1 等比例划分训练集与测试集,并保证子集数据分布与原数据集一致。
基准模型(逻辑回归与支持向量机)需要进行预处理,包括独热编码、缺失值处理、标准化处理等。由于轻型梯度提升树内嵌相关功能,因此无需进行其他预处理操作。
训练过程中利用网格搜索与交叉验证(Grid-SearchCV)对训练模型进行参数优化,涉及的主要超参数包括learning_rate、max_depth、num_leaves等。
2.评估指标。混淆矩阵是评估的基础,由四个一级指标构成(见表2)。
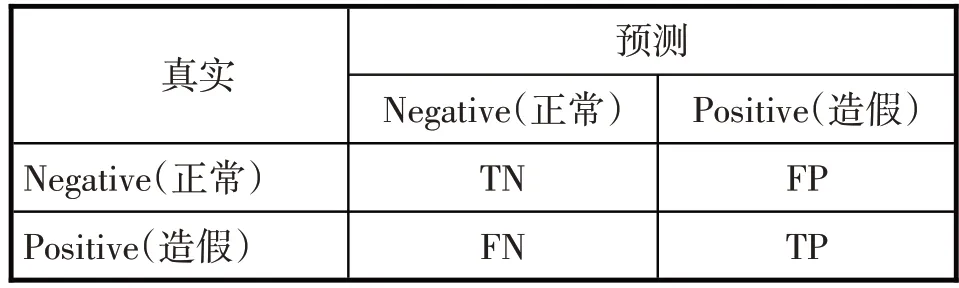
表2 混淆矩阵
根据混淆矩阵,构成单一标准的二级分类评估指标:

由于在标准评价指标的鼓励下大部分方法识别正常样本比识别造假更准确,因此,在这类问题上需要明确,查全率(recall)比查准率(precision)更重要,高敏感性(sensitivity)比高特异性(specificity)更重要。F-score能够同时衡量查全率与查准率间的关系,而受试者工作特征曲线(ROC)可根据特征曲线下的面积(AUC)同时衡量TPR和FPR。
3.实验结果。根据寻优法发现,误分类成本CFP:CFN=1:50 时性能最佳,考虑到数据不平衡度与代价敏感性两者的共同作用有所交叉。
选择标准逻辑回归(LR)、支持向量机(SVM)和轻型梯度上升树(LGBM)作为基准模型,各个模型在测试集的预测结果如表3所示:

表3 实验结果
在标准算法中:三种算法在总体准确度上表现都很出色,能达到95%以上;从综合表现来看,轻型梯度上升树明显优于其他两种算法,在保证正常样本识别率达到98%的基础上能够正确识别40%的造假样本;但三种方法对于造假样本的正确识别率都非常低,其中支持向量机的造假查全率甚至为0。实验结果验证了标准算法在不平衡数据集上会出现向多数类的偏移,导致实际应用效率低下。
经过代价敏感学习的轻型梯度上升树(CS_LGBM)在各个方面性能都有所提升,尤其是对于财务造假公司的识别,正确率能够达到60%,并输出树形结构(见上图4)与特征重要性(见图5),反映与财务造假风险相关的关键指标。例如,当上市公司成立年数为14、17、18、19、27、28、32 时,每股净资产大于3.44,且资本支出与折旧摊销比小于等于0.389时,财务造假概率较大。

图4 决策树
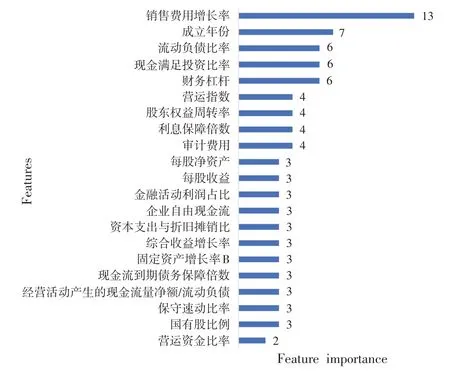
图5 特征重要性
4.结果分析。根据对比实验,将LGBM与CS_LGBM的输出结果进行可视化对比,发现两个模型的异同,并聚焦于代价敏感模型(见图6),其中节点大小代表不同特征的重要性。
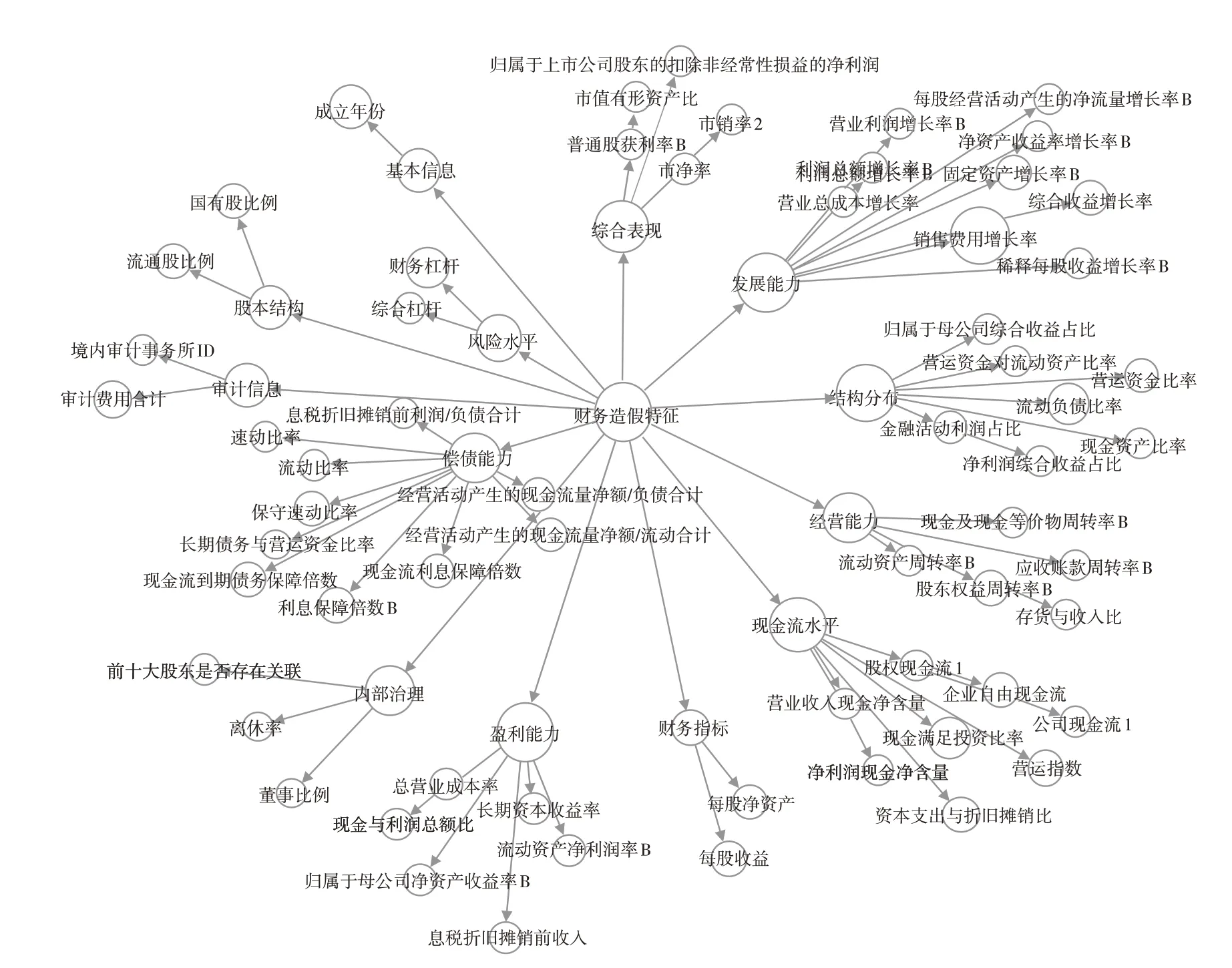
图6 CS_LGBM模型特征
通过对代价敏感模型的输出结果进行进一步的聚类与分析,发现财务造假行为的识别可以从财务压力引起的动机、公司的综合能力以及可能存在隐患的异常项目三个方面展开(见图7)。
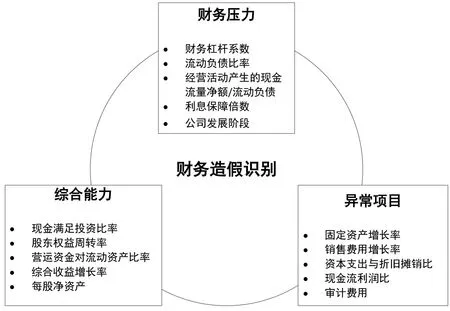
图7 财务造假识别路径
根据成因理论,压力与需要是公司财务造假的重要因素,而过高财务杠杆与偿债压力将提高公司的财务造假动机。偿债能力可通过流动负债比率、利息保障倍数、经营活动产生现金流金额与流动负债比进行衡量。另外,当负债居高不下的同时存款也很高时,是财务造假的一个重要信号。公司处于不同发展阶段将面临不同的发展压力,因此成立时间也可能是识别财务造假的入手点。
经营能力、盈利能力、获现能力、发展能力等特征是评估公司综合能力的重要方面,在一定程度上从现实反映公司财务造假的可能。销售费用的异常增长是财务风险的重大信号,隐含着盈利问题,以瑞幸和新大地为代表。现金满足投资比率偏低表明企业经营活动产生的现金无法支持资本支出、存货增加以及现金股利发放,暴露公司经营能力的不足。营运资金对流动资产比率衡量资产结构健康程度,综合收益增长率衡量公司持续发展能力,每股净资产综合衡量上市公司的内在价值,是财务风险的重要衡量指标。
为虚增现金流与利润,财务造假的一般手段包括虚构资产、虚减费用与损失,反映为一些重要项目的异常。固定资产、在建工程等长期资产项目是公司虚增资产的重要手段,例如康美药业通过将不满足会计确认和计量条件工程项目纳入报表以达到虚增固定资产的目的,因此过高的固定资产增长率值得警戒。一些公司还会通过对长期资产的费用资本化并对折旧、摊销、减值的操纵以低估费用与损失,可通过资本支出与折旧摊销比分析。经营现金流净额利润比和现金利润比可对利润与现金流的来源进行检测,以防虚增利润资金。另外,实验结果表明,异常的审计支出也是一个关键点。
五、结论
为应对财务造假识别的数据不平衡与代价敏感性问题,研究提出了一种基于代价敏感学习的轻型梯度提升树模型,通过向损失函数与评价指标引入代价矩阵实现。理论研究和对比实验表明:一是代价敏感轻量梯度提升树比其他标准模型综合表现更好,能够在保证总体准确度83%的同时,将造假公司识别率提高到60%;二是对上市公司财务造假的识别可以从“动机+现实+可能”出发研究财务压力、公司综合能力及异常项目三个方面,对财务杠杆、流动负债比率、现金满足投资比率、营运资金比率、综合收益增长率、每股净资产、销售费用增长率、固定资产增长率、现金流与利润比等指标展开分析。
虽然如此,但研究仍有不足:一方面,样本标签源于证监会对财务造假行为的披露,然而由于造假行为的隐秘性及造假披露的时滞性,可能存在部分造假公司隐匿于正常公司中;另一方面,模型对财务造假公司识别的准确率尽管有所提高,但仍未达到较高水平,以神经网络为代表的深度学习分类能力更为出众,但由于其黑箱模型的本质对财务造假识别缺乏解释性。针对不足,半监督学习可以通过少量标签利用大量无标签样本,另外,随着人工智能步入后深度学习时代,融合认知和推理的双驱动可解释人工智能成为研究热点,如何用知识增强数据也将是未来研究的一个重要方向。
猜你喜欢
数学小灵通(1-2年级)(2021年4期)2021-06-09 06:25:56
成都信息工程大学学报(2019年3期)2019-09-25 08:31:20
中学生数理化·七年级数学人教版(2019年4期)2019-05-20 10:06:32
电子制作(2018年16期)2018-09-26 03:27:06
中学生数理化·七年级数学人教版(2018年6期)2018-06-26 08:36:06
海峡姐妹(2017年12期)2018-01-31 02:12:22
初中生世界·七年级(2017年9期)2017-10-13 22:27:46
作文与考试·初中版(2017年12期)2017-04-19 20:24:45
中央民族大学学报(自然科学版)(2016年4期)2016-06-27 08:06:04
中学生(2015年12期)2015-03-01 03:43:53
