
基于自选尾数压缩的高能效浮点忆阻存内处理系统
2022-03-09 05:49:20丁文隆汪承宁
计算机研究与发展 2022年3期
丁文隆 汪承宁,2 童 薇,2
1(华中科技大学计算机科学与技术学院 武汉 430074)
2(武汉光电国家研究中心(华中科技大学) 武汉 430074)
在科学与工程领域中,许多复杂的模型都会用线性系统Ax=b的形式表达[1],其中,A通常是一个庞大的高精度浮点稀疏矩阵[2].在这样的系统上进行求解会消耗大量时间与计算资源[3].目前主流的求解大规模稀疏线性系统的方法是克利洛夫(Krylov)子空间方法[1].该方法的求解过程涉及大量的矩阵向量乘法(matrix-vector multiplication, MVM)计算,所以改进MVM的计算模式是节省运算能耗与运算资源的关键途径.
近年来,关于用忆阻阵列进行原位MVM运算的有关加速器被不断地提出.最先提出的是一类用于执行机器学习和图形处理任务的忆阻加速器,它们通过向忆阻阵列施加电压,在阵列上原位地执行MVM运算[4-10].然而,这些忆阻加速器只提供8~16 b的计算,显然不支持一些以高精度浮点数为主的计算应用.于是,最新的研究提出了将IEEE-754双精度浮点数部署在阵列上的方式[11].该研究将浮点数的53 b尾数(包括前导1)分位片地部署到不同的阵列上,最后通过乘加缩减树整合不同位片的结果,实现高精度浮点数运算.
然而,目前仍然没有任何工作提出在一个系统内,能够为不同精度的应用提供计算能耗优化的方法.本工作致力于提出一个基于忆阻阵列的模拟MVM运算系统,既能够为精度较高的应用提供无损的浮点数计算模式,又能够让较低精度的应用执行低能耗开销计算.具体地,本文工作的贡献主要有4个方面:
1) 设计了一种自选尾数压缩机制,对于某些低精度的求解应用,可以在阵列运算中选择性地忽略激活若干权值较小的低位阵列,从而保证在满足具体任务的求解精度的前提下,减少运算阵列以及外围电路的能耗.同时提出了一种动态的对齐位优化机制,摒弃原有的静态对齐位的设定模式,根据矩阵实际指数范围的要求来设置参与运算的对齐位阵列,减少冗余对齐位带来的能耗.
2) 针对于尾数压缩和对齐位优化策略,提出了一种叶子结点数可变的流水乘加缩减树的结构.解决了激活运算的阵列数不确定所带来的偏移策略失效以及无法进行流水的问题.这种新型的乘加缩减树结构能够在激活任意数量的尾数位和对齐位阵列的情况下,都正常地进行流水求和运算.
3) 基于现有工作中的分块映射与片位部署的思想以及上述所提到的优化改进策略,设计完成整个模拟忆阻MVM原位运算系统.
4) 将带优化策略的MVM原位模拟运算系统集成到高性能线性代数的算法框架中进行求解计算.评估在不同的求解精度下,系统中关键能耗指标的减少程度.
1 背景知识
由于忆阻器阵列存内运算具有高能效、高并行性等优势,受到国内外学者广泛地关注.到目前为止,用忆阻器阵列进行MVM运算的方法已经被广泛地研究,包括从用于机器学习模型的忆阻加速器的研究到应用于科学计算的忆阻加速器的研究.
1.1 用于机器学习和图形处理的忆阻加速器
近年来,随着机器学习工作的流行性日益增加,学术界[12]和工业界[13]都提出了许多有关于机器学习的专用加速器的建议.这些加速器主要为机器学习模型提供MVM运算,通过加速这一过程的运算,极大程度提升机器学习模型的训练速度.


Fig. 1 Illustration of memristive crossbars computation图1 忆阻阵列计算示意图

Fig. 2 Array organization in a memristive cluster图2 忆阻存储簇中的阵列组织
2) 位切片(bit slicing)技术.由于模拟器件的精度受到非理想因素的限制,忆阻存储单元无法精确地表达映射值[14].针对这个问题,现有的工作提出了位切片技术,这种技术通过将矩阵元素按照位片映射到多个阵列上来减少对器件精度的依赖[4-7].一个位切片的例子,这个矩阵将被映射到3个二进制存储阵列中:

(1)
注意,在实际计算中,对于到来的电压Vi采取这种位切片技术.
3) 乘加缩减树.如图1所示,为了将各位片的点积结果进行求和运算,需要乘加缩减树进行整合[4-5],得到MVM运算的最终结果.乘加缩减树中有2类操作:①加法操作,即不同位片得到的结果求和;②左移操作,父结点整合左右子树时,高位片子树需要进行左移操作才能和低位子树对齐相加.一般地,乘加缩减树都是叶子结点数为2的整数次方的满二叉树,在这种树结构下,整合移位时将高位子树左移2i-1b即可(i为父结点到叶子结点的距离).
1.2 用于科学计算的忆阻加速器
1.1节提到的忆阻MVM加速器是针对机器学习模型来设计的,只提供8~16 b的计算[4-9].虽然这个运算精度大概率不会影响机器学习任务的推理准确度,但是对于高精度的科学计算求解来说,这种运算精度是远远不够的[15].
1) 浮点数的忆阻阵列部署.为了解决科学计算中的精度问题,Feinberg等人[11]首次提出了在忆阻加速器上部署科学计算.在IEEE-754标准中,双精度浮点数由53 b的二进制尾数(包括前导1)、11 b的二进制指数和一个符号位表示[16].这项工作首先提出了如何将53 b的尾数部署到忆阻阵列上进行MVM运算,它运用了多个存储阵列,每一个阵列代表矩阵中浮点数的一个位片,形成一个存储簇;然后再将不同的阵列通过乘加缩减树连接起来,如图2所示:
存储簇用于计算向量的一个位片与矩阵元素的乘积.在完成了位片映射后,进行3阶段的运算:1)电压加载在到模块A中的阵列上,列电流存储在采样—保持缓冲区中,该电流代表当前向量位片和对应的矩阵位片每一行的点积之和;2)在模块B中,选择器选择采样—保持缓冲区中代表相同行不同位片的电信号,经过ADC转化为数字信号后,送入乘加缩减树相加;3)模块C中乘加缩减树对模块B中输入的不同位片结果进行整合运算.
经过这3个阶段,得到了矩阵的1行与向量位片的点积结果.为获得最终结果,需要循环执行第2阶段与第3阶段,获得所有矩阵行与向量位片的乘积.
2) 异构阵列集合.Feinberg等人[11]的工作还提出了一种异构矩阵分块思想.采用不同大小的块去捕捉稀疏矩阵中非0元素的密集区域,并为每个大小的块设定一个非0元素阈值,若达到阈值就将该分块映射到存储簇上[11].对比使用单一阵列大小的工作[4-5,9],这种异构设计极大程度上增加了阵列非0元素密度,减少了阵列映射开销,保证了阵列的并行性和能源效率.
图3展示了矩阵元素分块的一种示例.其中,数据来源是SuiteSparse矩阵数据集合[2]中的685_bus矩阵.其中,图3(a)展示了该矩阵非0元素的分布情况,图3(b)展示了分块之后的结果.分别采用了32×32,16×16,8×8,4×4这4种不同大小的矩阵块对原矩阵进行分块,阈值分别为128,32,8,2.

Fig. 3 Example of matrix blocking (685_bus matrix)图3 矩阵元素分块示例(685_bus矩阵)

Fig. 4 Example of alignment bits deployment in cluster图4 存储簇中对齐位部署示例
3) 存储簇中对齐位的部署.完成了矩阵分块之后,需要将每一块的浮点数都映射到存储簇中.然而同一矩阵块中元素的二进制指数不尽相同.为了使得不同元素的尾数按照指数对齐,需要以块中指数最大的元素作为基准,对较小指数的元素实行向右偏移部署的策略,然后在空余位补充0.
图4展示了存储簇中浮点数格式部署的一个例子.需要部署10.5,6.5,0.3这3个浮点数,其对应的二进制指数分别为3,2,-2.部署时以10.5对应的指数作为基准,6.5和0.3的部署分别向右偏移1 b和5 b,并将空余位置填充0.
4) 定点硬件上执行浮点运算.在系统实现过程中,图4所述的利用填充0实现的对齐步骤是在浮点数映射过程中实现的,该过程处于预处理阶段.在阵列运算过程中,不会再出现动态的移位对齐等步骤,整个运算是在定点硬件上进行的.所以,同一个存储簇中的阵列运算,仅涉及到定点运算.通过二进制分片策略与预处理填充对齐位的策略,实现了在定点硬件上执行浮点运算.而在整合不同存储簇的运算结果时,会涉及到定点数转浮点数,浮点数相加等纯浮点运算.故所构造的系统是一种以定点硬件运算为主,纯浮点运算为辅的系统.
2 观察与动机
之前的工作所使用的都是固定位数的浮点数尾数部署方式,这种部署模式可能会产生额外能耗开销.本节将讨论这个问题以及对应的优化策略.
2.1 为不同的应用优化计算能耗开销
在科学与工程领域中,虽然多数的线性模型的矩阵元素都是浮点数,但是不同应用所需的求解精度各不相同.例如,求解网页排序算法(PageRank)、求解线性回归等大规模数理统计模型时,所需要的求解精度都不高[17-18].已有的研究显示,在执行机器学习、图形处理任务时,只使用8~16 b精度就能达到令人满意的准确率[4-9].但是,对于一些由偏微分方程离散化得到的大型稀疏性方程组而言,需要的求解精度比较高[1],其代表领域有航天航空领域以及量子力学领域等.然而,执行高精度的求解运算必然会消耗更多的能量,这对于求解精度需求较低的线性系统来说是不划算的.
现有工作中,高精度浮点数采用的是固定位片数的部署形式[11],在每一个存储簇中,有53 b的二进制尾数阵列、64 b的对齐位阵列以及9 b的校验位阵列.在实际运算时,运算阵列与其外围电路的能耗都与激活计算的阵列个数呈正相关,也就是说,随着参与运算的阵列个数增多,计算能耗也会剧烈增加.然而,上述的浮点数部署模式是针对于通用IEEE-754双精度浮点数格式设计的,对于所有的双精度浮点应用都能够保证计算精度.对于低精度的求解应用而言,并不需要激活所有的53 b尾数、64 b对齐位进行计算就能够达到允许精度范围内的解,所以按照原有固定方式计算必然会产生不必要的能耗.
2.2 尾数压缩与对齐位优化策略
为了解决2.1节所述的为不同应用优化计算能耗开销的问题,在本节中将论述一种尾数压缩和对齐位优化策略,动态地决定实际运算时激活的尾数以及对齐位阵列数量.
1) 尾数压缩策略.在实际计算时,可以根据具体的应用精度,自行选择参与运算的尾数位数,从而大幅度减少运算阵列带来的能量消耗.例如,如果选择25 b尾数参与运算,在实际运算时只会激活高25 b尾数阵列进行运算,而不会对剩下的低位阵列(低28 b的阵列)施加电压,也就不会产生这些阵列对应的运算阵列和外围电路能耗.
2) 对齐位优化策略.在之前的有关于位片型忆阻阵列科学计算的系统设计中[11],对齐位是固定的64 b.然而,并不是所有的应用都需要多如64 b的指数范围.为了节省计算开销,采取一种动态的对齐位优化策略,只部署指数范围内的对齐位.例如,一个矩阵块中非0元素的二进制指数范围是1~20,即只部署19 b的对齐位阵列即可,这样便会一定程度上减少对齐位冗余带来的阵列计算消耗.
2.3 叶子结点数可变的流水乘加缩减树
由于本文所提出的系统应用了尾数压缩和对齐位优化策略,导致不同应用的计算中,尾数和对齐位的位数之和是不固定的.在这种情况下,进行计算的乘加缩减树中叶子结点的个数是可变的.所以,为了解决尾数压缩和对齐位优化策略带来的叶子结点数可变的问题,需要设计一种新型乘加缩减树结构,来完成存储簇中不同位片结果的整合.
1)乘加缩减树中的层级流水概念.假设目前存储簇拥有128个忆阻阵列,阵列大小为n×n,即对应的乘加缩减树为7层.每加载一次向量,该树就需要计算n次,以得到矩阵块每一行和向量相乘的结果.然而,由于树结点之间的计算可以并行操作,且同层之间没有数据依赖,可以把乘加缩减树的每一层看作一个流水部件,构建一个7级的流水线.假设每个结点的计算时间为单位时间,这样计算n个结果的时间为6+n.
2) 叶子结点数可变的流水.在以往固定位片的阵列部署模式下,叶子结点数是确定的,且数量往往是2的整数次方(若不为2的整数次方,则往往将叶子结点数补满到2的整数次方).在此情况下,所构造的树为满二叉树.现在由于叶子结点数可变,会导致整棵树不为原有的满二叉树形式,导致2个问题:①由于不是满二叉树,各叶子结点到根结点的距离不尽相同.若采用流水策略,各叶子结点数值无法同时到达根结点,产生计算错误.②若所计算的乘加缩减树不为满二叉树,则前面背景介绍中论述的高位子树偏移2i-1(i为父结点到叶子结点的距离)与低位子树对齐相加的策略就会失效,使用该方法来计算高位子树的偏移量会带来错误.为了解决这2个问题,需要提出叶子结点数可变的流水乘加缩减树(在3.3.3节详细论述).
3 基于异构阵列的自选尾数压缩系统设计
本节将展示一个基于异构阵列集合,拥有尾数压缩和对齐位优化策略,面向科学计算的MVM系统.
3.1 系统总体结构设计
如图5所示,系统主要由预处理模块以及阵列运算和整合模块构成.
1) 预处理模块.预处理部分主要负责处理原始矩阵,并提供阵列映射方案.具体地,该部分将对原始矩阵依次进行分块、分片、执行尾数压缩与对齐位优化策略,最终获得能直接映射在忆阻阵列上的0-1矩阵,并为后续计算提供阵列激活策略.
2) 阵列运算和整合模块.阵列运算和整合部分主要负责对于到来的向量x,通过阵列计算以及辅助处理子模块的整合,获得最终Ax的结果.具体地,需要先将向量位片按时序加载在存储簇上,然后在阵列上执行矩阵向量乘法运算,再在辅助处理子模块中对不同存储簇的结果以及未分块元素进行整合,最后得到矩阵向量的乘法结果b.

Fig. 5 Overall structure design of the system图5 系统总体结构设计

Fig. 6 Design of the pre-processing step图6 预处理过程设计
3.2 预处理模块的详细设计
图6展示了预处理模块主要任务的设计流程:
1) 矩阵分块与分片.由用户输入最大块的边长L和最大块中允许的最少非0元素个数阈值p.分别运用边长为L,L/2,L/4,L/8的块来采集矩阵中非0元素密集的区域,其对应的非0元素阈值分别为p,p/4,p/16,p/64.在分块过程中,先用边长为L的块去铺排整个矩阵,根据阈值p去捕获达到密度的块,若密度达不到,则用4个边长为L/2的块去铺排这个边长为L的矩阵块,捕获非0元素数量超过阈值p/4的区域;以此类推,用L/4,L/8的块去铺排.若有非0元素没有被任何块捕获,则其会进入未分块元素集合,等待辅助处理子模块统一整合处理.
对于每个浮点数而言,需要获得其IEEE-754双精度浮点数表示形式(或者其科学记数法表示形式),进而提取其53 b尾数(包括前导1)、其指数以及其符号位.对于同一个矩阵块,需要对其中所有的非0元素执行此操作,获得一个具有(sign,significand,expval)三元组元素的矩阵,其中sign表示符号位;significand表示有效数,即带前导1的共53 b尾数;expval表示对应二进制指数.
2) 尾数压缩与对齐位优化.为实现自选尾数压缩策略,可以在系统上增加一个尾数选择压缩的接口mantissa_bits,其意义是用户设定的尾数保留位数,保留高mantissa_bits.
为实现冗余对齐位的优化,需要在矩阵分块之后,对矩阵块中每个非0元素的指数进行简单处理,获得该块中最大的二进制指数maxexp和最小的二进制指数minexp,本系统参考矩阵块中指数的实际范围来进行对齐位阵列的激活.同时,本系统同时还会给出一个可供用户设置的对齐位数阈值max_alig.对齐位数的设置形式:
alig_bits=min(maxexp-minexp,max_alig).
(2)
在一般情况下,对齐位数alig_bits=maxexp-minexp,这样做就可以用最少的对齐位数覆盖整个矩阵块的指数范围,相对于固定的对齐位方案而言减少了不必要的计算能耗.给定用户设置的阈值max_alig的目的是为了防止在矩阵块中有个别指数极小的元素,导致maxexp和minexp差距过大,需要用到过多的对齐位,白白耗费阵列资源.当然,如果具体的问题对求解精度要求不高但对于节省能耗的要求较高,用户也可以根据节省能耗和求解精度的具体要求选择较小的对齐位阈值,这一点是灵活的.
如果矩阵块中有元素的指数超过了阈值所限制的范围,则在预处理步骤中这些元素会重新被归类到未分块元素中,而不会在后续进行阵列映射.尾数压缩和对齐位优化的过程都在预处理步骤进行,即在阵列映射前完成.可以通过这2个步骤确定每一个存储簇中具体需要激活使用的阵列数量.
图7展示了尾数压缩与对齐位优化策略在预处理模块中整体的执行流程:

Fig. 7 Design of mantissa compaction and alignment optimization图7 尾数压缩与对齐位优化的设计
3) 映射.对于每一个矩阵块,需要将其映射到对应的存储簇上.假设矩阵块大小为N×N,一共需要映射的阵列个数为M个.则对应的存储簇由M个N×N的忆阻存储阵列组成,将得到的矩阵块尾数二进制串按照从高位到低位映射到这M个存储阵列上即可.
3.3 阵列运算与整合模块的详细设计
本节主要阐述,在一个已经完成映射的忆阻异构阵列集合中,从加载向量x,到计算出最后的结果Ax,这一完整过程的设计.
3.3.1 阵列运算与整合模块结构设计
图8展示了阵列计算和整合模块的设计结构.其中,在每个存储簇的输入缓冲区中,对于到来的向量x进行分片和对齐,并以时序展开,依次输入存储簇中进行运算.存储簇通过阵列点积的计算以及乘加缩减树的计算,将向量x的当前位片值与当前矩阵块的点积结果存在输出缓冲中.接下来的工作由辅助处理子模块完成,包括整合同一存储簇不同向量位片的结果,整合不同存储簇及未分块元素的结果.全局缓存区用于存储必要中间值以及最后的结果.

Fig. 8 Crossbar computation and integration module structure图8 阵列运算与整合模块的结构
3.3.2 负数的处理
在矩阵A和向量x中,会出现负浮点数,本节将对这2种负数的处理方式进行论述.
1) 矩阵块中的负数处理.为了处理矩阵A映射到存储阵列上的负数值,可以将一个矩阵块中的正数值和负数值分开映射(以三元组中的符号位元素作为判断标准),然后在后续整合模块的时候相减即可.这样,同一存储簇中就要维护2个阵列集合,分别对应该矩阵块的正非0元素和负非0元素.在存储簇c中,正存储阵列集合和负存储阵列集合分别为cpos和cneg.
2) 向量的负数处理.对于向量x来说,可以用负电压来代表x中的负数元素.但是这会导致一个问题,即产生的电流值会有负数,进而经过ADC转换之后会有负数值进入乘加缩减树.然而本工作中实现的乘加缩减树没有集成关于减法(或补码)的运算,这会导致其无法处理负数值.为处理这个问题,可以给进入乘加缩减树的电流转换值都增加一个数值为N的偏移,其中N为该存储阵列的大小.这样便能够将电流转换的取值范围从-N~N转换到0~2N.然后,由于在整合模块中正数阵列的值要和负数阵列的值一一相减,所以增加的偏移值会在运算中刚好抵消,而不用额外操作来消除偏移值.
3.3.3 叶子结点数可变的流水乘加缩减树的设计
如2.3节所述,相对于普通的叶子结点数固定的满二叉树形式,叶子结点数可变的树形式存在2个问题:移位策略失效、流水过程计算出错.下面将针对这2个问题提出正确的树的结构设计.
1) 解决移位策略失效的问题
在乘加缩减树是满二叉树时,假设当前结点到叶子结点的距离为i,现在该结点需要整合左右2棵子树的元素,即将右子树(规定右子树为高位子树)的值左移2i-1位,和左子树相加即可.例如,某个叶子结点数为8的满二叉树,这棵树共有3层.考虑其最高位元素,它相对于最低位的元素需要左移7 b.它在从叶子结点到达根结点前需要经历i=1,i=2,i=3这3层中对应结点的共3次移位,总共移动21-1+22-1+23-1=1+2+4=7 b,刚好符合移位要求.对于编号为奇数的叶子结点也同理,例如第5个元素,其需要左移4 b.它在到达根结点之前需要经历i=3层结点的1次移位(因为在i=1与i=2层中其为左子树不需移位),即总共移动23-1=4 b,符合要求.
现在由于应用了尾数压缩与对齐优化策略,叶子结点的数量不会固定为2的整数次方,乘加缩减树不再为满二叉树,会导致原有移位策略失效.若按照传统方法,从根结点开始构造该1棵叶子结点为6的尽量平衡的二叉树的话,结果如图9(a)所示.其中,结点A的实际偏移量应为5,而按照原有偏移策略算得的偏移量为22-1+23-1=2+4=6,产生错误.而如图9(b)模式构造树,符合原有的计算模式,其偏移为21-1+23-1=1+4=5,偏移值正确.

Fig. 9 Comparison of trees with wrong and correct shift computation modes图9 拥有错误与正确移位计算模式的树的对比
当前的目标是设计拥有正确移位模式的乘加缩减树的构造策略.即需要对任意数量的叶子结点,找到一种通用策略,构造如图9(b)所示的正确移位模式的树.受到偏移模式以及一些从叶子结点开始构造的树(如霍夫曼树)的启发,可以选择由叶子结点开始构造这样1棵具有正确模式的计算树.具体地,从叶子结点层开始,两两相邻的结点为一组,构造下一层父结点;若本层有落单结点(如果结点数为奇数则最后一个结点为落单结点),则该落单结点和新构造的父结点一起组成一个新的集合,继续构造接下来一层的父结点.如此循环地执行该构造策略,当新的集合中的结点数为1时,树的构造停止,该结点为根结点.
如此构造乘加缩减树,便可用i的值计算出这些结点所在的实际层数,保证每个结点在运算中能获得正确的偏移量,到达根结点的时候获得了正确的总移位值.图10左图用这种方法构造了1棵有11个叶子结点的具有正确移位计算模式的乘加缩减树.可以看到,在i=0这一层中,结点A落单,它与i=1层的5个结点一起,构造了i=2这一层的结点,然而,在这一过程中,结点A所对应的i值不变,仍然为0.同理,对于结点B,其为i=2这一层的落单结点,它与i=3这一层的结点一起构造了i=4这一层的结点,同时,结点B对应的i值仍然不变,即i=2.
所以,对于结点A的计算过程而言,其到达根结点C需要经过结点B和结点C的移位计算,其中在结点B处移位22-1=2 b,在结点C处移位24-1=8 b,一共移位2+8=10 b,符合要求.
2) 解决无法进行流水操作的问题
想要在改进后的乘加缩减树中执行层级流水策略,会因为各叶子结点到根结点的距离不同而导致计算错误.如图10左图所示,叶子结点D到根结点C的路径长为4,而叶子结点A到根结点C的路径长为2.由于每进行一次流水操作都要对叶子结点加载一批新的数值,所以,当结点A经过2次流水操作到达结点C时,同一时刻输入的结点D值还没到达结点C;当结点D值到达结点C时,此时从结点A到达结点C的值已经是2个周期之后加载在结点A的值.所以,在计算过程中始终面临着数据达到不同步的错误.
① 结点维护先进先出队列.为了解决无法流水的问题,可以让每一个结点都维护一个先进先出队列,用队列的长度来弥补某些叶子结点到根结点的距离比其他叶子结点短的问题.图10右图展示了图10左图中乘加缩减树对应的队列结构.可以发现,由于结点A,B,C这一计算路径长度为2,这个值要小于满二叉树部分的计算路径(例如从结点D经历3个中间结点到结点C,其路径长为4),所以需要结点A和结点C的队列长度为2,其余结点的队列长度为1.当父结点需要整合左右子树的值时,只需要从左右子树取出其队首的值进行操作即可,在图10右图中实线代表该子树需要移位后才能进入父结点进行相加操作,虚线代表可以直接进入父结点进行加法操作.具体地,若当前需要计算的父结点的取值队列为cur,左右子树的取值队列分别为left和right,则计算整合的过程描述为
cur.push(left.pop+right.pop≪2i-1).
(3)

Fig. 10 Example of the correct pipelined multiply-and-add tree图10 正确形式的流水乘加缩减树的结构示例
图10右图描述了第6次向树的叶子结点中加载数值时,树各结点中队列的存储情况.其中,ti代表该结点队列中存储值在数据流中的时间顺序,例如t4代表该值是由第4次加载在叶子结点中的数据流经过乘加缩减树对应位置计算得到的值.可以看到,在结点A和结点C中分别需要存储t4,t5和t2,t3的值,以保证在i=2层计算时,结点B要从结点A中获得t4时间顺序的值,且保证在i=4层计算时,结点C要从结点B中获得t2时间顺序的值.
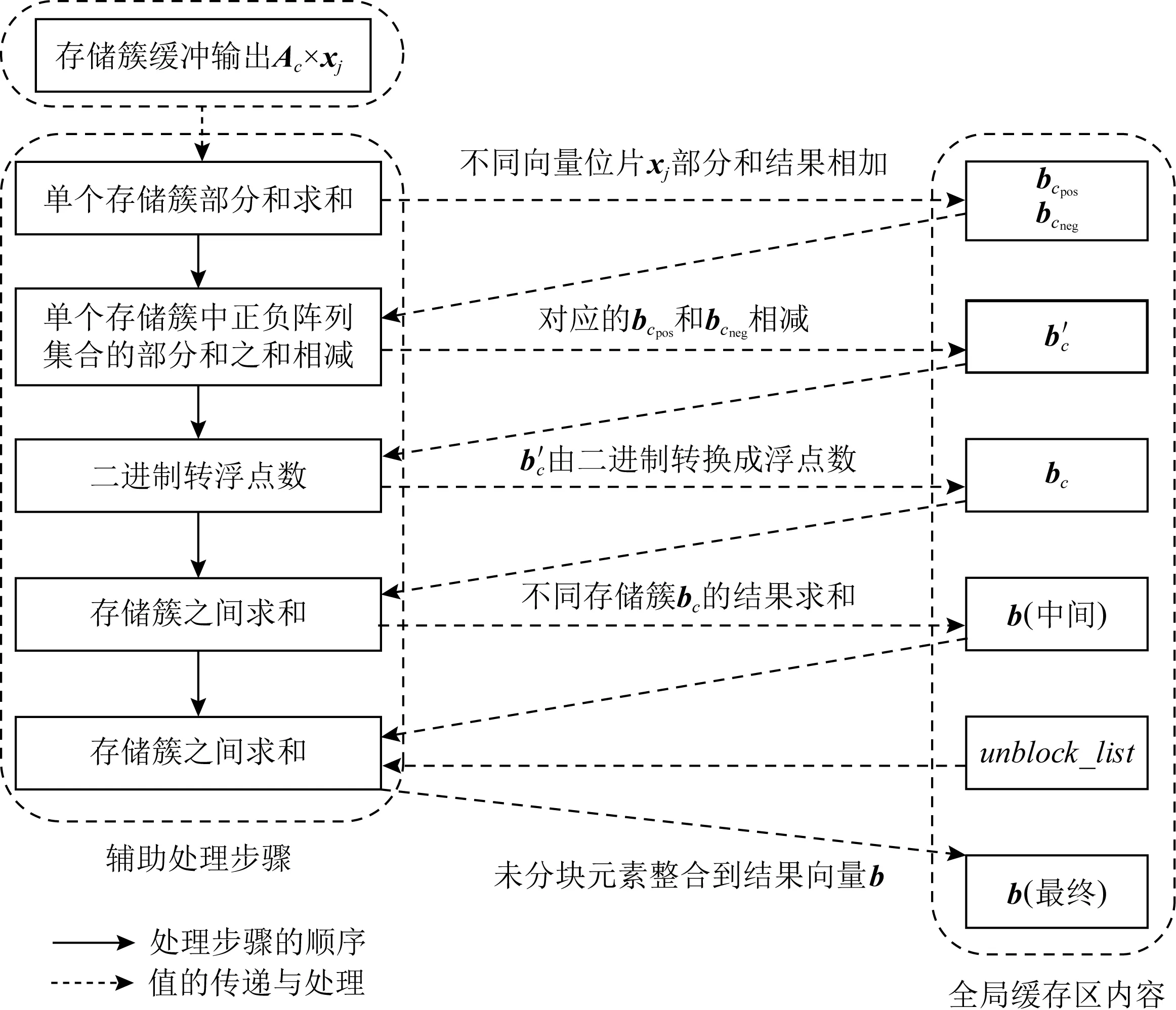
Fig. 11 Auxiliary processing module workflow图11 辅助处理子模块工作流程
② 维护正确的队列长度与存储值.现在设计的关键是要让所有叶子结点的计算路径上都存储相应长度的队列,这样层级流水才能取得正确的值.由此,在流水线没有充满的时候,不能够一次性地激活所有流水层级,而是一级一级地激活.以图10为例,第1次加载数据时,需要激活层i=0计算;第2次加载数据时,激活层i=1,即此时i=0和i=1这2层参与计算,直到最后第5次加载数据时,激活流水所有层级计算;并且在随后的计算中,都是每一次加载数据,然后流水的所有层级一起计算.这样一来,在激活i=1的时候,只有i=0和i=1这2个层级在计算,结点A按照顺序储存了2个待加值;同理,在激活层i=2和层i=3后,结点B按顺序储存了结果,符合预期.
3.3.4 辅助处理子模块的运算设计
图11展示了该过程中辅助处理子模块的处理步骤与全局缓冲区中的内容变化:
经过了阵列运算与乘加缩减树整合之后,每个存储簇的缓冲输出中都储存了矩阵块与向量位片的乘积结果,下面称这个结果为关于该向量位片的部分和.
辅助处理子模块将对这些结果进行整合,获得最后的Ax结果.具体解释:
1) 设该存储簇c存储的矩阵为Ac,其中正数与负数存储阵列集合为cpos和cneg,向量第j位片对应的部分和为Ac×xj.将不同位片的部分和相加,得到当前矩阵块正数元素以及负数元素阵列与向量x的乘积结果bcpos与bcneg.

4) 将未分块元素列表unblock_list中的元素都整合到向量b的中间结果中,得到b的最终结果.
4 基于异构阵列的自选尾数压缩系统实现
本工作将用软件模拟实现所设计的忆阻MVM系统.具体地,将用Python程序模拟实现硬件的存储结构、运算框架的构造以及数据在系统中的计算.本节将对系统中关键的存储结构、系统处理流程的具体实现作出详细的介绍.
4.1 硬件结构的实现
本系统需要模拟的硬件主要包含忆阻运算阵列(存储簇)以及乘加缩减树结点.本系统将用Python的类(class)中的成员变量来模拟各个存储结构所包含的存储项,若在运算过程中需要请求使用硬件资源,则只需要用软件编程方法实例化对应的类即可.具体地,本系统存储结构需要实现3种类.首先是有关阵列的2个类,分别是单个忆阻阵列和相同大小忆阻阵列组成的存储簇,表1展示了其模拟存储结构(类中需要储存的成员);其次是乘加缩减树结点硬件所对应的类,表2展示了其模拟存储结构.

Table 1 Data Storage Structure of a Storage Cluster and a Single Memristive Crossbar

Table 2 Storage Structure of Nodes in Multiply-and-Add Trees
4.2 系统处理流程的实现
在实现了模拟忆阻存储结构的基础上,可以对忆阻阵列进行映射与计算.下面将介绍整个系统处理过程的实现要点.
4.2.1 整体实现流程
本节将从总体角度介绍如何用程序模拟数据在忆阻系统中的计算.图12显示了整个系统的实现流程,下面将对照该图论述数据在系统中的计算以及系统的总体实现结构.

Fig. 12 Overall system implementation process图12 系统整体实现流程
首先,从文件中读取原始矩阵A(具体地,用Python的scipy.io库读取原始“.mat”文件,具体数据信息在5.1.2节中介绍).然后,进入预处理过程,该过程得到了经过尾数压缩与对齐位优化后的异构二进制矩阵块,以及各矩阵块对应的信息.对每一个矩阵块,都实例化对应的存储簇和乘加缩减树结点的Python类,以达到用软件方法模拟实现硬件资源的目的.预处理过程(包括分块分片、尾数压缩和对齐位优化过程)都用Python源代码实现,封装成一个Python程序模块,预处理具体数据时调用该模块即可.最后进入运算过程,分为3个步骤:1)阵列运算,将向量x与忆阻阵列中0-1矩阵进行点乘,运算结果存储在对应变量中(用变量模拟图8所示的缓冲输出).2)进行乘加缩减树运算,按照3.3.3节中的描述,编程实现每一个结点的移位和加法操作,同时维护结点正常的队列长度,保证数据流在树结构中的正常路径.3)辅助处理子模块中运算的过程.主要包括部分和的求和、定点数转浮点数、不同存储簇结果与未分块元素的整合,用变量来模拟图8中的全局缓存区.用Python源程序实现整个运算过程,封装成一个模块,接收已完成数据映射的忆阻存储结构以及输入向量x,返回矩阵向量乘法的结果.
4.2.2 预处理过程与阵列运算的实现
预处理过程主要包括分块、分片、尾数压缩和对齐位优化、矩阵映射4个步骤,完成了映射之后,便可以加载向量元素进行阵列运算.
1) 分块信息表block_list和未分块信息表unblock_list的构造与维护.在矩阵分块过程中,按照块由大到小循环遍历整个矩阵,这个过程中需要记录分块元素信息,存在block_list中.表中元素为元组(x,y,size),分别代表该分块的左上角在原矩阵中的行数值、列数值以及块的大小.如果遍历到最小块仍然满足不了分块阈值要求,或者遍历完整个矩阵后有没有处理到的边角元素时,需要记录其中的非0元素(即未分块元素),存在unblock_list中.该表中元素为元组(x,y,val),分别代表该元素在原矩阵中的行数值、列数值以及对应的浮点数值.
2) 矩阵块处理映射过程.当block_list构造完成之后,便可以进行相应处理将每个矩阵块映射到对应的存储簇上.首先,根据(x,y,size)提取当前需要处理的映射块A′=A[x:x+size,y:y+size].对该矩阵块A′进行分片、尾数压缩与对齐位优化,获得一个提供最终映射信息的矩阵A″,其矩阵元素为(符号位,压缩与对齐后的有效数二进制串,指数)三元组.通过这个信息矩阵不难将矩阵块按位片映射在表1所示的存储簇结构上,存储关键数据信息.需注意,处理过程中要根据“符号位”的数值为1或0,选择将其映射在负数阵列集合还是正数阵列集合中.
3) 阵列运算.完成映射后,需要根据当前存储簇结构存储的y和size值,提取需要相乘的向量片段x′=x[y:y+size].然后,对x′进行分片与对齐,按照位片从高到低加时序地载到存储簇的电压端.对于每一次向量位片的加载,经过流水乘加缩减树的运算整合,输出其与矩阵块的乘积,即该向量位片对应的部分和.
4.2.3 部分和求和的实现
1) 部分和求和计算.每加载一次x位片,乘加缩减数就输出一次部分和.在此,采用动态策略进行部分和的求和运算,即每产生1次部分和,就进行1次加法运算,每一次求和计算:

(4)
其中,cpos(cneg)为当前进行部分和求和的存储簇c对应的正数(负数)阵列集合,j代表加载第j个x位片,向量b则为该系统最后需要求得的结果,即Ax的结果.bcpos,j(bcneg,j)则代表当前存储簇中正数(负数)阵列集合在第j个x位片的作用下得到的部分和结果;bcpos,jsum(bcneg,jsum)代表前j个部分和结果相加得到的最终结果.
2) 部分和求和的提前终止策略.在上述过程中,随着输入的x位片指数降低,其在结果中的权值降低.事实上,在后续二进制转浮点的操作中,结果中多余的低位片数值将会被截断.本工作利用文献[11]提到的方法,应用部分和求和提前终止策略,设定结果最多保留位数为m(一般m=53),则当结果bcpos,jsum(bcneg,jsum)的高m位稳定不变时,求和过程结束.记结束时,当前存储簇c中cpos和cneg对应的部分和求和结果是bcpos和bcneg.
求和终止需要满足3个条件:1)后续求和区域与高m位没有重叠.2)高m位后面出现一个值为0的阻隔位,用于吸收后续求和元素产生的进位.3)值为0的阻隔位出现之后,需要再计算1次,若阻隔位没有变成1,则求和才能终止.这一步是为了避免阻隔位翻转让后续计算向高m位产生进位.部分和求和终止时的形式如图13所示:

Fig. 13 Partial sum early termination strategy图13 部分和求和提前终止策略
4.2.4 定点数转浮点数

expvalc=len_c+min_x+min_c-mantissa_bits,
(5)
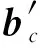
4.2.5 不同存储簇结果与未分块元素的整合
4.2.2~4.2.4节所述的阵列计算、部分和的求和计算,均是针对同一个存储簇中的运算而言的.要获得Ax的结果,需要将不同的存储簇中的结果整合起来.在这一过程中,需要全局地维护结果向量b.
1) 不同存储簇结果的整合.遍历所有的存储簇进行运算,都会产生对应的MVM运算结果bc,对所有存储簇c整合到b中:
b[i+c.x]=b[i+c.x]+bc[i],
i=0,1,…,c.size-1.
(6)
2) 未分块元素整合.计算的最后一步是将unblock_list中的元素整合到结果向量b中,对于unblock_list中的第i个元素(xi,yi,vali)进行计算(假设unblock_list的长度为len_u):
b[xi]=b[xi]+x[yi] ×vali,
i=0,1,…,len_u-1.
(7)
4.3 预处理部分开销分析
整个系统的开销主要包括预处理开销与运算开销.其中,运算开销主要包括模拟电路开销(以运算阵列开销为主)与数字电路开销(以ADC转换开销为主).运算开销的评估与分析将在第5节作详细讨论,本节主要对预处理部分的关键开销进行定性分析与评估.
预处理部分的主要开销来自于原始矩阵分块开销、确定块内指数范围开销、构造叶子结点数可变的乘加缩减树开销这3个方面.其中,后2个开销是原系统[11]中没有涉及到的,即是由于应用了尾数压缩和对齐位优化策略,系统在预处理部分多出的开销.
1) 原始矩阵分块开销.假设一个矩阵中非0元素的个数为Nnz,按照本文提出的算法,将用4种不同大小的块对原矩阵的非0元素密集部分进行捕捉,每个元素最多遍历4次,即在最坏情况下需要进行4×Nnz次操作.已有的工作发现,在平均情况下,对于原始矩阵分块的开销大约为1.8×Nnz次操作[11].
2) 确定块内指数范围开销.为确定实际需要激活的运算对齐位个数,需求得每个矩阵块元素中最大指数和最小指数的差值,这就要遍历矩阵块中所有非0元素.由于矩阵块捕捉的都是原始矩阵中非0元素的密集区域,假设原矩阵中非0元素密度为K,边长为l,则这一步骤总开销(对整个原始矩阵)与Kl2成比例.

4.4 实现上的限制分析
本系统在实现时会遇到一些限制,本节将从硬件物理实现和实际测试负载应用2个角度讨论.
1) 硬件物理实现.本文所提出系统的实现与评估都是通过编写软件程序模拟仿真实现的.这是由于目前的忆阻阵列制备工艺尚不成熟,不能够支持如此大规模、拥有多阵列尺寸大小的忆阻系统的物理实现.但使用软件实现的模拟系统在评估测试中也有其独特的优势,可以灵活调节软件参数来改变分块大小、压缩位数等重要参数,快速得到各种情况下的理论结果.
2) 实际测试负载应用.尚未找到一种方法,能对所有的测试负载都找到效果可观的尾数压缩和对齐位优化方案.实际应用该系统时,可能会由于部分参数选择不当(如尾数压缩位数、对齐位阈值),达不到需要的优化效果或精度要求.
5 评估与分析
本节将在线性代数求解框架中集成所实现的系统,对不同求解精度下的各种能耗节省比例进行评估.
5.1 评测数据与评估方法
下面将对模拟MVM内核集成到算法框架中的方法、评估所用的数据以及评估方式作详细论述.
5.1.1 MVM内核的集成方法
1) 算法求解框架.常用的高性能线性代数迭代求解算法有共轭梯度法(conjugate gradient method, CG)[19]、双共轭梯度稳定法(biconjugate gradient stabilized method, BICGSTAB)[20].在本课题中,将使用Python的scipy.sparse.linalg库中已经实现的CG/BICGSTAB算法框架来进行测试评估.这种算法框架支持以线性运算符(linear operator)的形式将模拟MVM内核应用于迭代求解,算法框架(以CG为例):

(8)
在输出端元素中,x为线性系统的解,flag为收敛标志(0代表收敛).在输入端参数中,A代表原始矩阵或者线性运算符,b代表线性方程组的右手向量,x0代表解向量的初始值,默认为零向量;tol代表解的容差,即|b-Ax| 2) 运用线性运算符集成MVM内核.在式(8)中,输入参数A可以是线性运算符,其作用是包装一个函数,函数输入为x,返回Ax的结果给算法求解框架.Python的scipy.sparse.linalg库提供线性运算符的包装方案,其框架: A=LinearOperator(A.shape,matvec,rmatvec), (9) 其中,matvec和rmatvec是2个关键函数,它们的输入都是x,返回分别为Ax和ATx.为实现MVM内核的集成,需编写这2个函数,在函数体中调用实现的MVM模拟系统,通过输入的向量x和固定的矩阵A,计算得到对应的Ax或ATx,作为函数的返回. 3) 预条件子的使用.在式(8)中,输入参数M代表预条件子矩阵.预条件子是在解决大型稀疏矩阵求解问题时的一种常用优化手段[21-22].关于预条件子矩阵,通俗的解释就是需要找到一个和稀疏矩阵A相似的矩阵M,对于对原等式Ax=b作出M-1Ax=M-1b的变换.其中M-1A和M-1b都可以直接算出,而且由于M和A为相似的矩阵,所以M-1A的值接近于单位矩阵,极大程度上减少了求解的步数.有一种通用的预条件子方法为0级不完全LU分解(incomplete LU factorization with level-0 fill in, ILU(0)),该方法利用单位下三角矩阵L和上三角矩阵U构造M=LU,使得M接近于A,并在矩阵中执行0级填充,保持矩阵原有的稀疏模式.在Python的scipy.sparse.linalg库中,有spilu这样一个求解类,可以用于构造ILU(0)预条件子,并集成到算法框架中.在后续测试中,存内硬件求解器都将集成ILU(0)预条件子. 5.1.2 评测数据集 评测将采用SuiteSparse矩阵集合[2]中的矩阵作为数据集.SuiteSparse矩阵集合是科学与工程领域中的实际应用产生的稀疏矩阵集合,该集合被广泛地用于稀疏矩阵算法的开发和性能评估. 根据需要,选用了大小不一的6个稀疏矩阵,作为评测数据.其中,部分数据文件只给出了矩阵A的值但是没有给出右手向量b的值.对于这部分数据,在进行CG/BICGSTAB算法求解时参照文献[21]的做法,构造全是1的右手向量b进行测试.表3显示了6个矩阵的名称、矩阵行数(rows)、非0元素数量(Nnz)、平均每行非0元素个数(Nnz/rows)等基本信息. 为了后续评估不同求解精度下的能量消耗比例,需要一些有关于忆阻器件的参数来辅助进行能耗评定.表4列举出了一些真实的忆阻器件参数[9,23]. Table 3 Evaluated Matrices Dataset表3 评测矩阵数据集 Table 4 Memristive Device Parameters表4 忆阻器件参数 5.1.3 评估方法 在下面的评估中,主要考虑只进行对齐位优化、尾数保留35 b、尾数保留25 b、尾数保留15 b这4种优化策略(3种尾数保留策略也是在对齐位优化的基础上进行).在忆阻MVM运算中,这4种策略所激活的阵列个数依次减少,会导致求解精度下降,但是会获得极大的能耗节约. 为了评估所设计的自选尾数压缩机制和动态对齐位优化机制的有效性和效果,将在CG和BICGSTAB这2种算法下评估4种策略的3个指标:1)相对于软件求解基线的相对残差及对应的迭代次数.2)运算阵列能耗相对于能耗基线的优化程度.3)ADC能耗相对于能耗基线的优化程度.其中,能耗基线指在原系统[11]对应的条件下(尾数53 b、对齐位64 b固定不变)测得的对应种类的能耗(在本文的测试中,对齐位阈值也选择为64 b). 通过评估这3个指标,可以分析出随着激活运算阵列的减少,计算精度的下降(通过计算对于软件求解基线的相对残差来体现求解的精确程度),运算阵列和ADC能耗的优化程度.验证所提出的系统是否可以在为高精度应用提出无损浮点计算功能的同时,又能有效降低较低精度应用的能耗开销,以体现系统实现方案的有效性和良好效果. 由于只进行对齐位优化的情况下并不会影响MVM的计算精度,即此策略下的解向量与迭代次数与软件求解完全一致,所以不再对其进行单独测定.本节主要关注5.1节提到的3种尾数压缩策略. 5.2.1 评估标准 用残差来描述不同策略下求解精度相对于软件求解基线的差距,求解残差: (10) 5.2.2 评估结果与分析 本节展示在各种尾数压缩策略下,求解结果相对于软件基线的相对残差以及算法求解的迭代次数. 1) 各种尾数压缩策略下解的相对残差.图14分别显示了在BICGSTAB(图14(a))、CG(图14(b))测试算法下,3种尾数压缩策略相对于软件基准的相对残差.总体来说,在对6个数据集测试结果进行对数平均处理后,3种策略的相对残差分别在10-9,10-7,10-3这一数量级.具体地,对于同一种尾数压缩策略,2种算法解向量的相对残差是几乎相同的,可以认为压缩策略影响的是映射矩阵本身的性质,不会因为算法框架的改变而发生太大的结果变化.对于每一种算法的每个测试矩阵而言,随着保留位数的减少,相对残差都会成数量级地增大. 2) 各种尾数压缩策略下算法的迭代次数.图15显示了在2种测试算法下各策略对应的算法迭代次数.总体来说,进行适当范围内的尾数压缩不会对迭代次数产生大的影响.但是,如果压缩的位数太多,保留位数太少,可能会增大迭代次数(如图15中保留15 b尾数时的测试矩阵msc00726的测试结果).为了进一步验证该想法,分别继续测试了测试矩阵msc00726在只保留15 b,12 b,9 b,6 b这4种尾数位情况下2种算法的迭代次数.结果显示,BISGTAB算法的迭代次数对应分别为2,2,3,5,CG算法的迭代次数对应分别为3,3,4,9.可以看出,如果尾数保留位数过少,会显著增加求解迭代次数,使得迭代求解过程需要更多的时间和能耗.故在实际应用中,需要谨慎选择尾数压缩位数,尽量不选择过少的保留位数(如15 b以下),以防止尾数压缩策略给求解带来的负面影响. Fig. 15 Algorithm iteration times under various compaction strategies图15 各种压缩策略下的算法迭代次数 运算阵列能耗是模拟电路中最大的能耗来源.进行阵列运算时,电压加载到电阻上,会产生瞬时功率.为了使得采样—保持数组能够获得正确的电流值,通常需要使得电流维持一段时间,所以会产生能量消耗.本节将展示在4种优化策略下,运算阵列能耗相对于能耗基线的减少比例.能耗基线的值是在已有未优化系统[11]的条件下评估得到的,其尾数为固定的53 b,对齐位为固定的64 b. 5.3.1 评估指标 参数如表4所示,每一个存储单元的瞬时功率: (11) 采样—保持数组需要电流维持的时间主要取决于其RC时间常数,它与分辨率,即lbN是成比例的,其中N是当前忆阻存储阵列的大小(行数),即一个存储单元的计算能耗与P×lbN是成比例的[11]. 为了获得进行一次Ax运算所对应的运算阵列能耗Ecrossbar,需要依次进行3个具体步骤计算: 1) 对于加载1次电压(1个向量位片)而言,需要对所有阵列中的所有存储单元的能耗值进行求和,得到忆阻存储结构的整体能耗; 2) 对于每一次向量位片的加载,将上述整体能耗进行累加,得到Ecrossbar; 3) 为了求解迭代过程中的运算阵列总能耗,需要对所有Ax步骤的Ecrossbar求和,得到一个与迭代阵列消耗总能量成比例的值Ecrossbar_tol. 5.3.2 评估结果与分析 评估求解过程中,各策略Ecrossbar_tol的相对比例. Fig. 16 Computation crossbar energy ratio under various strategies图16 各种策略下的运算阵列能耗比例 1) 各种压缩/优化策略下的运算阵列能耗比例.以测试矩阵mesh3em5在BICGSTAB算法下的测试得到的Ecrossbar_tol为单位能量,画出在2种算法下,所有矩阵在各种策略下的能耗值,如图16所示.首先,对于同一个算法同一个测试矩阵而言,随着每个存储簇中激活运算的阵列越来越少(从只进行对齐位优化,到尾数保留位数分别只有35 b,25 b,15 b),运算阵列消耗的能量也逐渐变少,符合预期.同时,可以观察到,矩阵中非0元素越多,消耗的阵列能量明显越多.这是因为其非0元素多,导致其映射电阻中Ron较多,导致能耗较大.并且注意到,消耗的运算阵列能量与原始矩阵大小没有直接关系,比如在6个测试集中,最大的矩阵(行数最多的)为测试矩阵Chem97ZtZ,但是其中的非0元素没有测试矩阵bcsstk27多,所以消耗能量明显比测试矩阵bcsstk27小很多.对于同一个测试矩阵而言,由于CG算法的迭代次数多于BICGSTAB,所以消耗的运算阵列能量也成比例的增加. 2) 各种压缩/优化策略下的运算阵列平均能耗优化.表5展示了对于所有6个测试矩阵平均值而言,使用每一种策略时运算阵列能耗相对于能耗基线减少的比例.可以发现,BICGSTAB和CG这2种方法的能量优化比例是几乎相同的,并且随着运算时激活阵列的减少,能耗优化比例会越来越大.具体地,在相对于软件方法有0~10-3范围的求解残差时,2种算法下的平均运算阵列能耗都相对已有的未优化系统减少了5%~65%. Table 5 Average Computation Crossbar Energy Optimization Ratio ADC是将采集-保持数组中的电信号转化为数字信号的部件,只有经过这种转换,乘加缩减树才能对阵列中的计算结果求和.ADC能耗是外围数字电路能耗的主要来源.本节中将展示4种优化策略下的ADC的能耗相对于能耗基线(已有未优化系统[11]条件下评估得到)的减少. 5.4.1 评估指标 假设一个阵列的大小是N,则其所需要的ADC分辨率为lbN.因为ADC的平均功耗随分辨率呈指数增长[24-26],故其功耗和N成比例.又因为ADC的转换时间与分辨率lbN成正比,所以列电流的转换能耗与N×lbN成正比[11]. 假设某个存储簇中有M个存储阵列.即对于每一个存储簇,每一个单独的向量x位片要进行M×N次列电流的计算,则存储簇进行一次计算ADC的总能耗与M×N×N×lbN成正比. 为了获得一次Ax的完整ADC能耗EADC.需要在算法执行过程中对所有存储簇,所有的向量x位片的ADC能量求和,得到最终EADC.注意EADC的值只是与真实的ADC能耗成比例,而非真实ADC能耗值,其只会被用来计算相对于能耗基线的能量节省比例. 最后,为了计算求解迭代过程中的ADC总能耗,需要对所有Ax计算产生的EADC求和,得到求解整个算法ADC消耗的总能量值EADC_tol,该值与迭代求解过程中真实的ADC能量消耗成比例. 5.4.2 评估结果与分析 评估求解过程中,各策略下EADC_tol的相对比例. 1) 各种压缩/优化策略下的ADC能耗比例.以测试矩阵mesh3em5在BICGSTAB算法下的测试得到的EADC_tol为单位能量,画出所有矩阵在各种算法、各种执行策略下的能耗比例.图17显示出一些与运算阵列能耗优化(图16)相同的性质.比如,矩阵块的非0元素越多,ADC的能耗明显越多,因为需要更多的阵列进行运算,对应的ADC转换过程也就越多.再比如由于CG算法的迭代次数明显比BICGSTAB算法要多,所以其ADC能耗也成比例的多. 对同一个算法同一个测试矩阵而言,随着每个存储簇中激活运算的阵列越来越少,ADC能耗基本上也逐渐变少,符合预期.但是需要注意,对于测试矩阵msc00726和测试矩阵nos5而言,应用对齐位优化策略相对于能耗基线并没有一个明显的ADC能耗下降,这是因为其矩阵块内指数范围太大,超过了设定的阈值64,对齐位优化效果不明显. 对于大多数矩阵而言,ADC能耗随着保留的尾数位数的减少而降低.但是对于测试矩阵msc00726而言,在保留15 b尾数的时候,其ADC能耗反常地比保留25 b时要多,这是由于尾数截断过多使得算法迭代的次数增加,导致要用到更多计算步骤来使得算法收敛.所以须注意,由于压缩位数过多导致迭代次数增加,最终导致计算能耗过多的情况也会发生,对于ADC能耗来说可能更明显,需要谨慎选择压缩位数. Fig. 17 ADC energy ratio under various strategies图17 各种策略下的ADC能耗比例 2) 各种压缩/优化策略下的ADC平均能耗优化.表6展示了对于所有6个测试矩阵平均值而言,每种执行策略的ADC能耗相对于能耗基线减少的比例.和运算阵列能耗一样,各种策略在应用于BICGSTAB和CG这2种算法的情况下,对ADC能耗减少的比例几乎是一致的,且随着运算激活阵列数的减少,能量优化比例逐渐增大.具体地,在相对于软件方法有0~10-3范围的求解残差时,2种算法下的平均ADC能耗都相对于已有的未优化系统减少了30%~55%. Table 6 Average ADC Energy Consumption Optimization Ratio 与运算阵列能耗优化的情况不同的是,ADC能耗在只应用对齐位优化时,其能耗优化程度约为30%,它大于同样策略下的运算阵列优化的数值(约5%).但是,随着存储簇中阵列激活数量(保留尾数位数)的逐渐减少,ADC能量优化的效果没有运算阵列能量明显.运算阵列的能耗在保留15 b的时候优化比例在65%左右,而ADC能耗在尾数保留位数15 b时优化比例只有55%左右. 在科学与工程领域中,浮点数线性系统的求解问题十分普遍.现有的研究提出将IEEE-754双精度浮点数部署在忆阻阵列上,进行高能效的存内计算.然而,还没有研究提出为不同求解精度的浮点线性系统优化运算能耗.为解决这个问题,本文创新性地提出了一种具有尾数压缩与对齐位优化策略的浮点MVM计算系统,并针对该策略的特征提出了一种叶子结点数可变的流水乘加缩减树.评估结果表明:本系统既可进行高精度浮点数无损运算,又可对低精度求解应用大幅度优化运算阵列与ADC的能耗. 作者贡献声明:丁文隆提出了本文工作的思路,设计完成了实验,并撰写论文;汪承宁协助改进系统框架,在论文写作过程中提供理论基础的帮助;童薇对整个工作提出指导意见并修改论文.

5.2 不同策略下的求解精度与迭代次数

5.3 不同优化策略下的运算阵列能耗评估



5.4 不同优化策略下的ADC能耗评估


6 结束语
猜你喜欢
数学小灵通·3-4年级(2022年9期)2022-12-31 17:13:20
临床小儿外科杂志(2022年4期)2022-07-16 01:45:46
中国医疗器械信息(2020年21期)2020-12-07 07:22:32
延安职业技术学院学报(2020年4期)2020-10-26 01:32:56
启迪与智慧·上旬刊(2019年10期)2019-09-10 07:18:41
数学物理学报(2018年1期)2018-03-26 08:16:42
实用骨科杂志(2018年11期)2018-03-16 16:29:07
反射疗法与康复医学(2017年7期)2017-01-16 01:11:30
小天使·二年级语数英综合(2015年1期)2015-01-14 11:29:13
电子设计工程(2014年12期)2014-02-27 11:58:23
