
有限样本条件下欠规范手语识别容错特征扩充
2022-03-09 05:49:56孔乐毅张金艺楼亮亮
计算机研究与发展 2022年3期
孔乐毅 张金艺 楼亮亮
1(特种光纤与光接入网重点实验室(上海大学) 上海 200444)
2(特种光纤与先进通信国际合作联合实验室(上海大学) 上海 200444)
3(中国科学院上海微系统与信息技术研究所无线传感网与通信重点实验室 上海 200050)
借助深度学习的手语识别是一种将底层物理特征映射为语义表征的自然语言处理过程,其不仅能帮助健听人理解聋哑人的肢体语言表达,还可以扩展到交警指挥、军事旗语、智能家电控制等手势指令领域.生活中存在各种随机的欠规范手语表达,如日常交流的动作简化、课堂中的拙劣练习、类似“口音”的地区特色等,部分手语表达语义表征相同,但持续时间、运动轨迹、速率变化等底层物理特征差异明显.深度学习模型需要训练集和测试集的样本结构服从同分布,有限样本作为训练集难以覆盖上述实际情况,模型容易过拟合导致识别准确率难以提高.
手语识别最初是在手势识别的基础上进行研究,但需要用到时序分割算法,存在过程复杂、误判率高等问题,目前采用深度学习从整体时序角度进行手语识别的研究正逐渐增多[1].多数方法在取得不错效果的同时也存在着一些不足之处,文献[2]表明,采用深度学习的手语识别方法大多忽略了音韵特征、语义单元这样的中间步骤,直接从底层特征得到语义概念,这样的分析不是很合适.部分深度模型容易在结构复杂、样本不足时出现过拟合现象,在测试集上效果良好,但较难满足欠规范手语容错识别的实际需求.因此,为避免手语表达因个体习惯不同而导致的语义表征模糊,满足生活中手语识别的容错需求,在标准特征集中还需额外扩充容错特征.
针对生活中手语表达的欠规范现象,本文提出一种有限样本条件下手语识别的容错特征扩充方法.该方法利用自编码器与生成对抗网络,将复杂的深度学习模型划分为内部关系更为紧密的表示学习模型与特征分类器模型,自动学习并扩充有用的特征用于后续手语识别的具体任务,从而降低模型的复杂度,避免因样本有限而出现过拟合现象.首先利用人体姿态估计技术提取骨架信息,降低光照、背景、身材等无关因素的干扰,面向手语的时空关联性构建自编码器,从少量原始样本中提取标准特征;再利用生成对抗网络从标准特征产生大量欠规范样本,通过自编码器在标准特征中扩充容错特征,构建新的容错特征集用于后续的手语识别任务;最后通过实验证明该方法生成的样本语义清晰,构建的容错特征集结构合理,有利于提高手语识别准确率,具有广泛的应用前景.
本文工作的主要贡献有4个方面:
1) 提出了一种基于自编码器与生成对抗网络的手语容错特征扩充方法,该方法能够在标准手语样本数量有限的条件下,不断生成欠规范的新样本并扩充带有容错信息的样本特征;
2) 针对手语存在的时空关联现象,设计时空图卷积与循环神经网络相结合的自编码器,该模型使用样本的全局特征与时隙特征表示原始样本;
3) 针对手语样本的全局特征与时隙特征设计生成对抗网络模型,该模型结合样本重构误差和判决器的判决误差,能够定制生成样本的欠规范程度;
4) 在CSL(Chinese sign language)[3]数据集上构建原始样本标准特征与欠规范样本容错特征组合而成新特征集,利用该特征集训练手语识别模型证明该方法的应用价值.
1 相关工作
手语识别模型依据样本的不同可分为基于骨架信息、视频RGB信息和前两者的混合模型.2016年起便出现了一系列基于循环神经网络(recurrent neural network, RNN)的手语识别研究[4-5],2018年Huang等人[6]在此基础上进行了一系列改进,逐步将人体轨迹数据、骨架关节点数据输入到循环神经网络中进行分类,这些基于骨架信息的模型在相对简单的基础上获得了不错的效果;2018年Huang等人[7]提出基于隐空间的分层注意力网络(hierarchical attention network with latent space, LS-HAN)并于2019年进一步改进[8],通过引入音韵特征、语义单元等中间步骤提高模型的识别准确率;2018年Wang等人[9]则提出基于时域卷积模块的双向递归神经网络,采用3维卷积神经网络从视频数据中提取时空相关特征进行处理,但基于视频的模型相对复杂,对硬件以及时间的要求比较高;2019年Cui等人[10]提出的双向长短期记忆网络(bidirectional long short-term memory, BLSTM)的手语识别框架,该方法同时融入光流、RGB-D等数据;2019年Liao等人[11]基于BLSTM网络,使用检测网络对手部进行分割,将分割后的手部特征与原始RGB数据一起进行手语识别.这些混合模型充分利用了卷积神经网络的特征提取能力和循环神经网络时序分类优势,但因模型过于复杂需要的样本较多.
综上所述采用人体骨架信息的模型相较于视频RGB信息的模型对硬件以及时间的要求比较低,更有利于手语识别在生活中的应用与普及,本文以骨架信息为基础展开研究.由骨架信息表示的手语样本的多元时间序列,由人体骨架中多个关键点的运动轨迹组合而成:
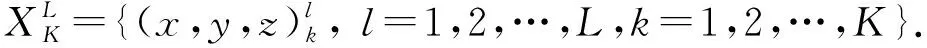
(1)
其中,L为手语样本的持续时间长度,K为人体骨架与语义相关的关键点个数.获得该多元时间序列需要对视频样本预处理,其过程如图1所示.首先手语视频中提取人体骨架信息,筛选与语义高度相关的部位.然后在x,y,z三个维度上对各关键点运动轨迹的相对位置进行归一化,获得与背景、身材等无关的人体时空图结构数据,进而整理样本为多元时间序列.
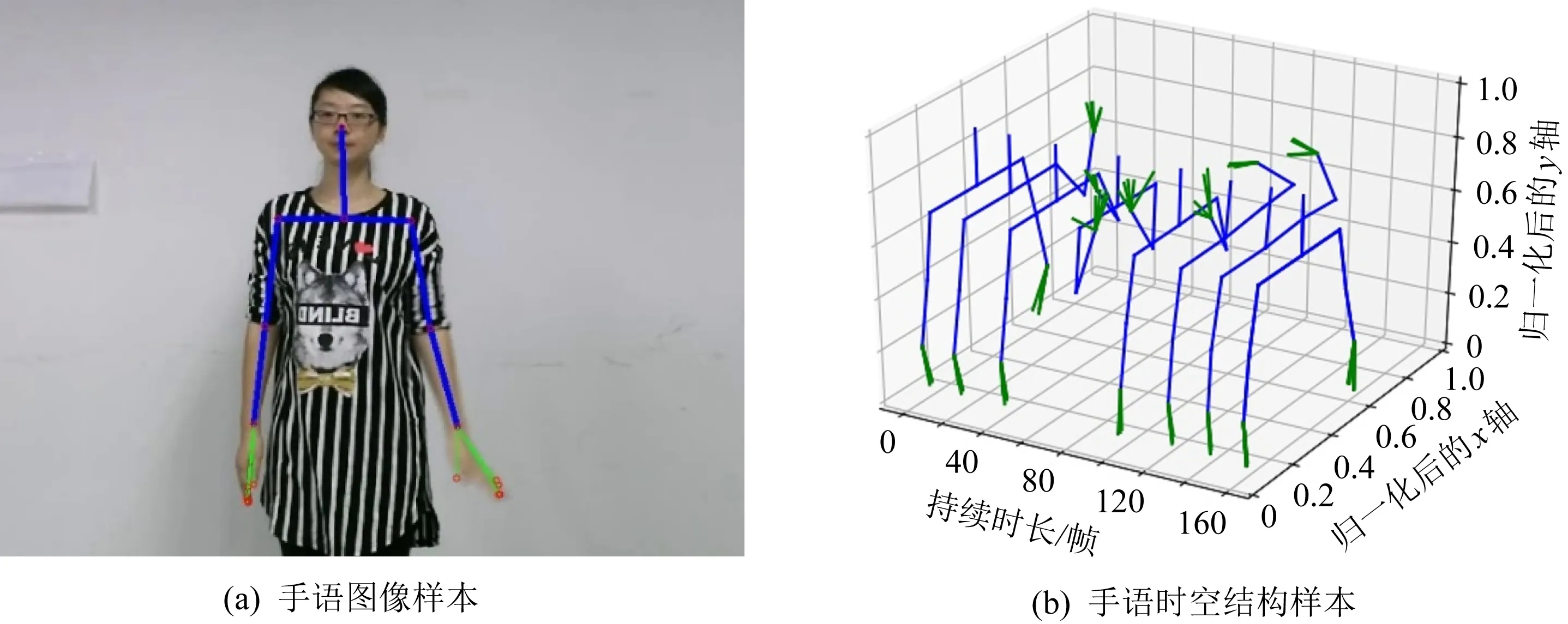
Fig. 1 Pretreatment of video samples图1 视频样本预处理
解读手语不仅需要时间维度中各关键点运动轨迹的上下文信息,还涉及空间维度中各关键点相对位置的空间结构信息.手语识别需要额外考虑特征间在整体时空上的动态关系,2种侧重不同时空关联现象,即关键点运动轨迹的上下文联系和空间内的相互影响:
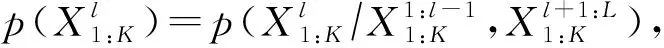
(2)
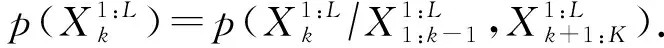
(3)
对比目前图像分类数据集的规模,手语语料库规模普遍较小.深度学习根据标签Y和样本X直接构建概率分布,设计复杂的神经网络拟合条件概率函数p(Y|X,θ),学习模型中的权重θ.但是手语样本存在上述复杂的时空关联性,与之相对应的深度学习模型往往结构复杂,在样本不足情况下,复杂的端到端神经网络容易过拟合.
以双向生成对抗网络(bidirectional GAN, BiGAN)[12]为代表的表示学习通过融合自编码器与生成对抗网络,能够在生成新样本的同时学习样本的高层特征,这种特征提取方法为解决样本不足的问题提供新的思路.大规模双向生成对抗网络(big bidirectional GAN, BigbiGAN)[13]通过对BiGAN的判决器结构改进,提出了更稳定的联合判别器,增强了无监督学习方面的能力,在表示学习和图像生成方面取得优异成绩.此外信息最大化生成对抗网络(information maximizing GAN, infoGAN)[14]通过将特征分为动态和静态,给按类别条件生成样本提供了新的方法.本文在上述GAN方法的基础上,针对多元时间序列样本改进相关模型结构,将表示学习方法应用于手语容错特征扩充,解决手语识别因模型复杂样本不足而出现的过拟合问题.
2 特征集构建流程与特征提取方法
手语由多个顺序固定的基本手势动作组合而成,其排列组合可视为手语的样本特征.但是识别分割动作片段的过程繁琐复杂,利用表示学习可以自动学习相关特征用于表示样本,有助于简化手语样本特征集的构建.为保证特征集能够真实反映手语样本的特点,需要针对手语的时空关联性设计特征提取方法,用更有实际意义的特征表示原始样本.
2.1 手语样本容错特征集构建流程
本文围绕深度学习中因模型复杂、样本不足而出现的过拟合问题,一方面针对模型复杂,通过自编码器将样本X表示为高层特征Z,构建特征分类器预测结果Y,相对简单的自编码器与特征分类器替代复杂的深度学习模型:
p(Y/X)=p(Y/Z)×p(Z/X).
(4)
另一方面针对样本不足,采用如图2所示的流程,产生更多新的欠规范样本并从中提取带有容错信息的样本特征,构建新特征集以提高手语识别的准确率.其中编码器提取有意义的高层特征表示原始样本,生成器(解码器)拟合样本的分布情况,产生与原始样本类似的新样本,判决器衡量新样本语义表征是否清晰可辨.
通过编码器P(Z|X)将手语样本X合理映射在隐空间(latent space)[12]中,其结果可视为标准特征Z.利用标准特征生成欠规范样本X′,选择语义清晰能够欺骗判决器的欠规范样本再次通过编码器提取样本特征,重复该过程实现欠规范样本生成与容错特征扩充,构建新特征集用于后续的手语识别任务.为保证特征集构建的合理性,生成器P(X′|Z)从标准特征生成新的样本,衡量生成样本与原始样本间的重构误差保证该特征具有真实含义.判决器衡量新样本的拟真程度,确保新样本的语义表征清晰可辨.

Fig. 2 Construction process of sign language sample feature set图2 手语样本特征集构建流程
2.2 针对时空关联性的特征提取方法
本文根据手语2种侧重不同的时空关联性,将样本特征Z划分为全局特征ZG和时隙特征ZT.全局特征ZG不受时间变化影响,对应空间内不同关键点间的相互影响,从全局时空角度出发考虑人体关键点间整体运动轨迹与相对位置条件,保留样本整体的静态轮廓.时隙特征ZT逐帧考虑时序条件,对应关键点运动轨迹随时间的变化,在不同时刻捕捉手语表达时复杂的上下文关系,覆盖随时间变化的动态细节.针对全局特征ZG和时隙特征ZT对全局轮廓和时隙细节的不同追求,分别选择时空图卷积网络(spatial temporal graph convolutional networks, STGCN)[15]和RNN构成编码器,提取样本特征的过程,其中对动态细节的刻画离不开静态轮廓的先验知识:
p(Z/X)=pSTGCN(ZG/X)+pRNN(ZT/X,ZG).
(5)
全局特征ZG由STGCN通过手语样本的时空图结构获得,时空图结构能有效反映人体动作在时空中的运动轮廓,其由图1所示的骨架信息获取.一个时长为L且包含K个骨骼关键点的手语样本可由时空图G=(V,E)表示,其中节点集合V={vlk},其中l=1,2,…,L,k=1,2,…,K,图结构E={ES,ET},该结构每一帧中人体关键点相对位置的空间结构ES和连续相邻时间节点上相同关键点的时间结构ET:
ES={(vli,vlj)/(i,j)∈H,l=1,2,…,L},
(6)
ET={(vli,v(l+1)i)/i∈K,l=1,2,…,L}.
(7)
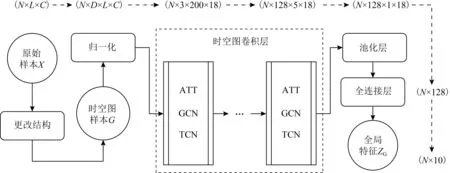
Fig. 3 Spatiotemporal graph convolution for global feature图3 提取全局特征的时空图卷积模型
式(6)中H是需要考虑相对位置关系的关键点对的集合,如人的双手、手腕与指尖等与语义关系紧密的人体关键点信息.将手语样本X更改为时空图G表示后,如图3所示通过STGCN网络提取特征结构维度为10的全局特征ZG,图3中时空图卷积层主要由3部分组合而成,分别是调整时空图G中节点权重的注意力模型(attention model, ATT)、面向空间结构ES的图卷积网络(graph convolution network, GCN)和面向时间结构ET的时间卷积网络(time convolution network, TCN).GCN可以很好地学习不同信道间的相互影响.TCN从整体时间的角度出发,有利于整合不同时刻关键点空间特征的整体时间关系.
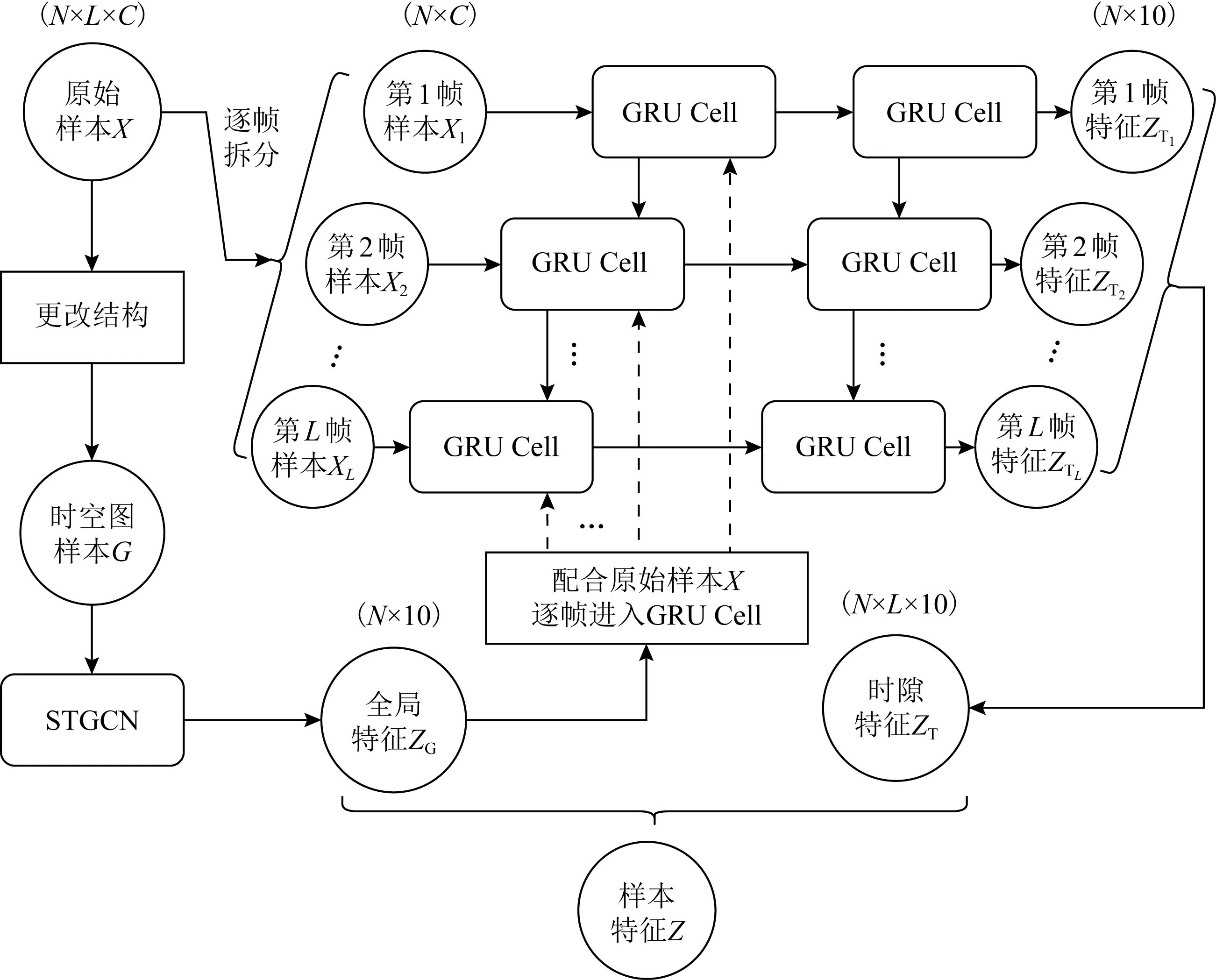
Fig. 4 Recurrent neural network for timeslot feature图4 提取时隙特征的循环神经网络
图3中时空图样本G所包含的节点集合V可整理为4维矩阵N×D×L×C后送入该模型.其中,N是样本数量;D代表关键点的维度特征,通常一个关键点包含x,y,z三个维度;L代表样本的持续时长,将其归一化为200个时间单位,方便卷积层完成时间卷积操作;C代表人体关键点的数量,选择与手语信息相关的18个骨架关节点.训练前首先对语料库在时间和空间维度下进行归一化,然后通过5层时空图卷积层,最后利用池化层与全连接层提取人体全局特征ZG.
时隙特征ZT的提取由RNN网络完成,其由2层门控循环单元(gated recurrent unit, GRU)组成,如图4所示.RNN通过神经网络中神经元的迭代更替,可以捕获各种随时间变化的动态细节,逐帧建立不同时刻的上下文关系.
RNN在保留时间维度信息的条件下,每一帧的通道维度逐渐减少到10,样本时隙特征为L×10的矩阵.其中每帧时隙特征zl同时受上一帧时隙特征zl-1、全局特征ZG、本帧样本xl共同影响:
ZT={z1,z2,…,zl}={pRNN(x1,ZG),
pRNN(zl-1,xl,ZG)|l=2,3,…,L}.
(8)
自编码器获得标准特征虽然能够有效表示原始样本,不过样本有限的问题依然存在,但是有效的特征提取方法是重构样本的基石.下文通过手语样本标准特征和生成对抗网络,解决样本有限带来的过拟合问题.
3 欠规范样本的容错特征扩充
生活中欠规范的手语表达语义表征模糊,使用有限样本训练手语识别模型较难满足实际需求.其原因是从有限样本中提取的样本特征数目有限,用于训练的特征太少进而出现过拟合现象.生成对抗网络产生的新样本与原始样本间不可避免会出现偏差,利用该特点并对偏差加以控制,可以不断产生欠规范程度不同的新样本.然后通过自编码器提取带有不同程度容错信息的样本特征,解决上述情况导致的欠规范手语识别准确率较低问题.
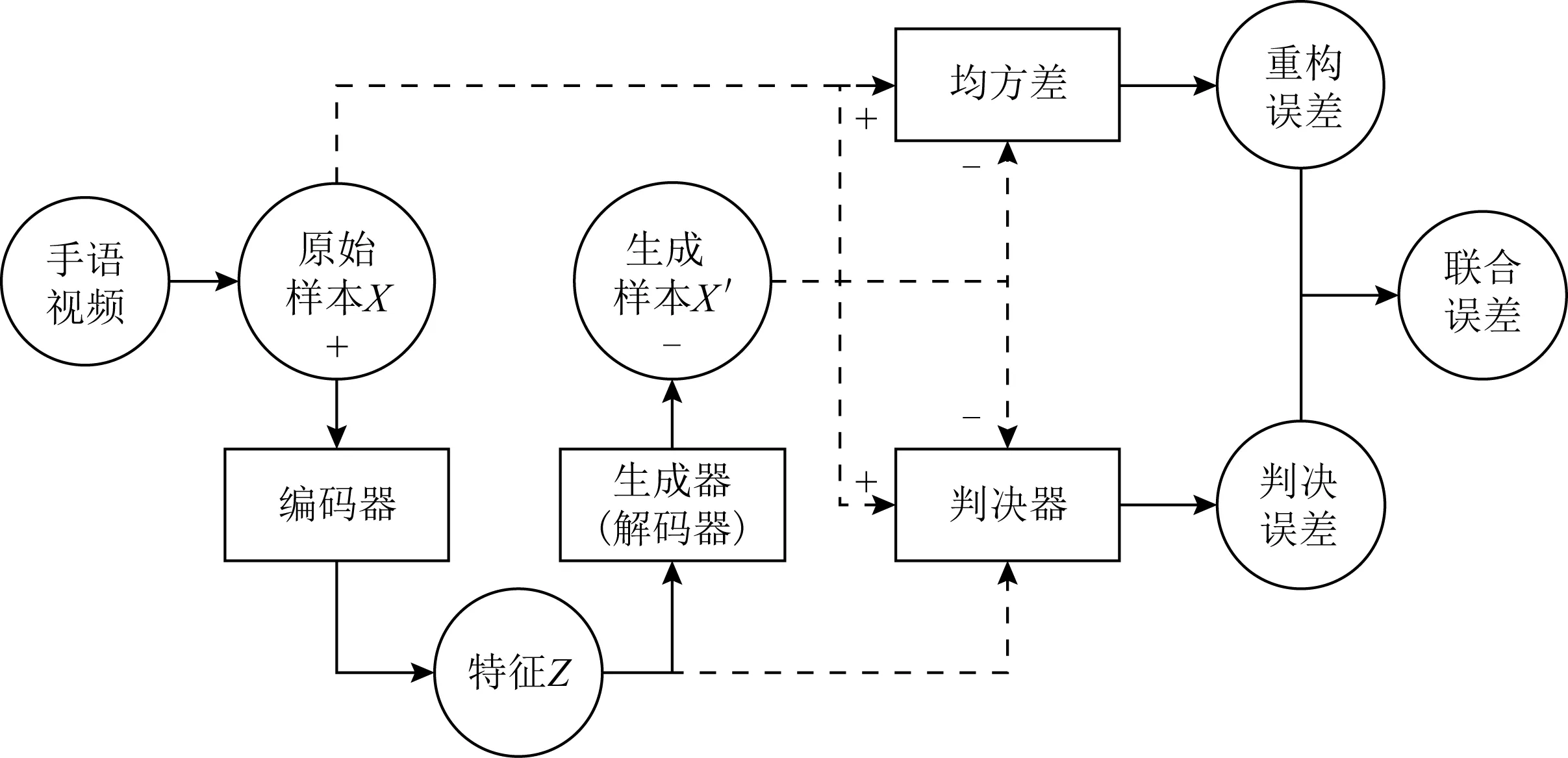
Fig. 5 Joint error calculation process图5 联合误差计算流程
3.1 欠规范样本生成与偏差控制
用于扩充容错特征的欠规范样本X′由生成器产生,该过程由具有前后向隐藏层的双向循环神经网络(bidirectional recurrent neural network, BRNN)[16]实现.生成器综合考虑向前、向后2个不同的循环神经网络的信息,为时序序列的生成提供了强大的建模能力:

(9)
其中,d为全连接层,ul表示前向和后向隐藏状态的序列,其分别由2个不同的前向、后向循环神经函数生成,该过程将全局特征ZG作为背景条件,嵌入到时隙特征ZT中.
欠规范样本在与原始标准样本语义清晰一致的同时,需要在底层细节上保持一定的偏差用于引入容错信息.生成对抗网络构建判决器进行样本的拟真程度判断,衡量生成样本的语义表征是否清晰.而自编码器比较原始样本与生成样本间的重构误差,更偏重于底层物理细节一致.结合两者的优势,以样本具有真实语义表征为门限,控制重构误差可以生成欠规范程度不同的新样本.
在生成欠规范样本时要评估引入的具体偏差,并决定什么程度的欠规范是可接受的.可以通过对设置不同的门限以满足不同精度条件下的容错需求,实现对欠规范程度的定量刻画.逐帧比较两者之间的样本偏差,利用重构误差衡量欠规范程度:
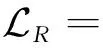
(10)
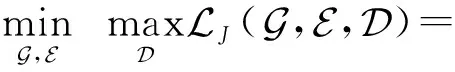
(11)
通过在模型的训练过程中融入了重构误差,可以满足对不同欠规范程度的具体需求,图5是训练模型时使用的联合误差计算流程图.该训练方法将原始样本与样本特征为一组作为正样本,样本特征与新生成的欠规范样本为一组作为负样本,一方面计算原始样本与生成样本间的均方差作为重构误差,另一方面通过式(11)判断这对数据来自编码过程还是解码过程.判决器模型与图3主体架构一致,仅在最后一层将经过多层时空图卷积的样本X与特征Z一起进入全连接层,降低维度到1维即获得判决结果.如果判决认为这对数据对来自编码器,则判决为真输出1;若是来自生成器,则判决为假输出为0.
联合误差由重构误差与判决误差加权相加而来,重构误差权重越低,生成样本的欠规范程度越大.通过调节两者间比重,可以训练出满足不同容错需求的生成器模型.从而控制新样本的欠规范程度,作为后文扩充容错特征的基础.
3.2 容错特征迭代扩充
原始样本的标准特征在隐空间中分布稀疏,存在不同语义间边界不清晰、容易相互混淆等问题.容错特征由欠规范样本通过自编码器生成,散布在原始样本标准特征周围,可以有效填补隐空间中标准特征间的空隙.随着隐空间中的特征覆盖度提升,不同类别的特征间边界逐渐清晰,彼此不易混淆.
但是大量高度相似的冗余特征缺乏实际价值,例如对标准特征做适当扰动变化产生的新特征等,反而可能增加模型的过拟合程度.因此在标准特征与容错特征组合的新特征集中,特征分布应该具有一定的空间结构,比如特征间应留有一定的间隔.这种复杂的结构需要特殊设计,特征分布却无法直接控制,本文通过合理的欠规范样本生成流程间接实现该目标.
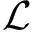
扩充容错特征需要编码器、生成器、判决器相互配合进行训练,本文提出的容错特征迭代扩充算法重点关注模型的训练方法与应用过程,模型结构与算法本身相对独立,该算法的具体步骤为:
步骤1.针对需求设计深度学习模型,有选择地将其中一层隐变量作为特征,本文以手语识别为例,如式(4)所示划分为编码器与特征分类器.
步骤2.首先串联编码器与特征分类器,因涉及语义分类任务,故利用分类结果与原始标签间的交叉熵作为损失函数进行预训练.然后串联编码器与生成器,利用重构误差进行预训练.最后联合交叉熵与重构误差进行训练,直到模型出现过拟合,编码器训练完毕.
步骤3.保持编码器权重不变,初始化生成器权重.依据容错需求不断调节重构误差与判决误差间的比重,利用联合误差交替训练生成器与判决器,保留不同的模型权重用于生成欠规范程度不同的样本.
步骤4.模型训练完毕后,利用自编码器构建原始样本的标准特征集,作为初始特征集在其中扩充欠规范样本的容错特征.
步骤5.从当前特征集中随机采样,通过生成器产生新的欠规范样本.清洗无法通过判决器检验的欠规范样本,再利用自编码器提取容错特征加入特征集.
步骤6.改变生成样本的欠规范程度,在将特征送入生成器前添加随机噪声或更换不同的生成器权重,重复步骤5直到满足实际容错需求
步骤7.导出包含欠规范样本信息的容错特征集.初始化特征分类器的权重,利用该特征集训练特征分类器,完成步骤1中提出的需求.
欠规范样本是扩充容错特征的保障,为衡量生成器的有效性,选择欠规范手语样本的语义分类结果评价其质量.该指标反映样本间的语义表征是否容易分辨,当识别准确率较高时,表明生成器模型产生的新样本语义表征清晰易辩.
通过计算容错特征集与标准特征间的平均距离,衡量扩充的容错特征是否围绕在标准特征周围,不同类别特征间边界是否清晰.为衡量容错特征扩充后特征集空间结构的合理性,本文改进FID(frechet inception distance)指标[17],记为FID.将距离用矢量计算保留的空间位置信息作为真实样本特征Z与生成样本特征Z′间距离的度量:
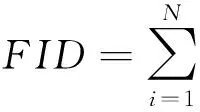
(12)
其中,N为标准特征个数,M为扩充容错特征个数,若扩充的欠规范特征在标准特征周围均匀围绕,FID趋近0.在容错特征集迭代扩充过程中,评估每轮扩充后的容错特征集FID指标,若该指标大幅增加可进行回滚.通过在容错特征扩充方法引入控制流程与评估方法,可以针对不同的欠规范需求定制合适的容错特征集.
4 实验与结果
4.1 数据集与实验步骤
为验证有限样本下连续语句手语识别的效果,本文使用CSL数据集进行实验.CSL连续手语语句数据集包含100种不同类别的样本,每种类别包含250个语义相同的手语样本(分别由50位志愿者各演示5次),共包含25 000个样本.本文选取前45位志愿者的样本作为训练集,后5位志愿者的样本作为测试集.实验过程分为模型训练、特征扩充、应用验证3个环节.在模型训练阶段利用图5的方式训练编码器、生成器和判决器模型,实现手语样本特征提取与欠规范样本的生成.在特征扩充阶段利用容错特征的迭代扩充方法,将原始样本标准特征与欠规范样本容错特征共同构建为新特征集.在应用验证阶段利用该特征集训练特征分类器进行手语容错识别工作,评估特征分类器在测试集上的识别准确率.
除上述在CSL数据集上的工作外,为对生成器模型与容错特征扩充方法进行多角度评价,本文提出如下评价方法.使用生成样本的识别准确率衡量生成器模型,该指标用于评估生成样本的语义表征是否清晰易分辨;使用特征集的FID指标衡量特征集中的特征分布是否具有一定的结构,评估容错特征扩充方法构建的特征集结构是否合理.
4.2 结果验证与分析
4.2.1 标准特征集构建与欠规范样本生成
原始样本由式(5)所示的编码器进行特征提取后,可构建为原始样本的标准特征集.但此时标准特征的维度依然较高,为方便展示与理解,将该特征集通过主成分分析(principal components analysis, PCA)降低维度到3维空间,然后在各维度上归一化并展示其特征分布情况.本文从测试集的前20种类别、5位志愿者中每位随机抽取一个样本共计100例,用于展示该过程,模型本身可满足全部类别的欠规范样本生成和容错特征扩充.相关案例如图6所示,其展示了由原始样本到标准特征集的映射过程,此时样本复杂的高维物理信息被映射为3维空间中的一个特征点,其中类别相同的样本特征点颜色一致.由图6中可知此时由有限样本构建的标准特征集在3维空间中分布稀疏,不同类别的特征间相互混叠难以划分边界,生成更多欠规范样本并扩充容错特征能够解决此问题.

Fig. 6 Original sample and standard feature set图6 原始样本与标准特征集
欠规范样本由标准特征通过式(9)所示的生成器模型产生,生成样本与原始样本间高度相似,表明标准特征蕴含了重构不同类别样本所需的各种信息,间接表明利用自编码器提取的特征具有实际意义.生成器模型可由其生成样本的类别是否易于区分衡量,串联自编码器与特征分类器可完成手语样本的类别识别工作.图7展示了由标准特征集生成的欠规范样本与欠规范样本的识别混淆矩阵,虽然手语样本包含18个关键点在3维空间中共计54条运动轨迹,但为了方便观察,结果验证中仅展示其中与语义相关度较高的4条运动轨迹曲线.
由图7中识别混淆矩阵可知该组欠规范样本的平均识别准确率高,证明生成的欠规范样本语义表征清晰易分辨,特征集中不同语义的特征间保留了各自类别的特点,有助于后续特征分类器的训练工作.
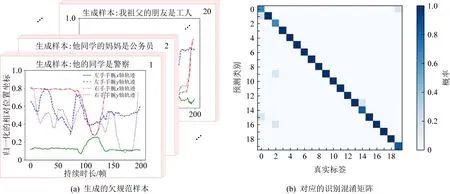
Fig. 7 Generating substandard sample and identifying confusion matrix图7 生成的欠规范样本与对应的识别混淆矩阵
4.2.2 容错特征的迭代扩充与应用验证
在验证编码器与生成器模型的有效性后,利用欠规范手语容错特征扩充方法构建手语容错特征集.该方法主要由生产欠规范样本和扩充容错特征2个步骤交替进行,由图8展示的是语义类别为“他的同学是警察”的欠规范样本迭代生成过程.通过控制重构误差门限生成欠规范程度不断加大的样本,然后利用判决器筛选语义表征清晰的样本用于扩充容错特征.图8中第2代、第5代、第10代欠规范样本与原始样本间的均方根差分别为0.027,0.039,0.07.对比可知每代样本在欠规范程度不断加大的同时保持了原有轮廓,该算法生成欠规范样本的流程合理.
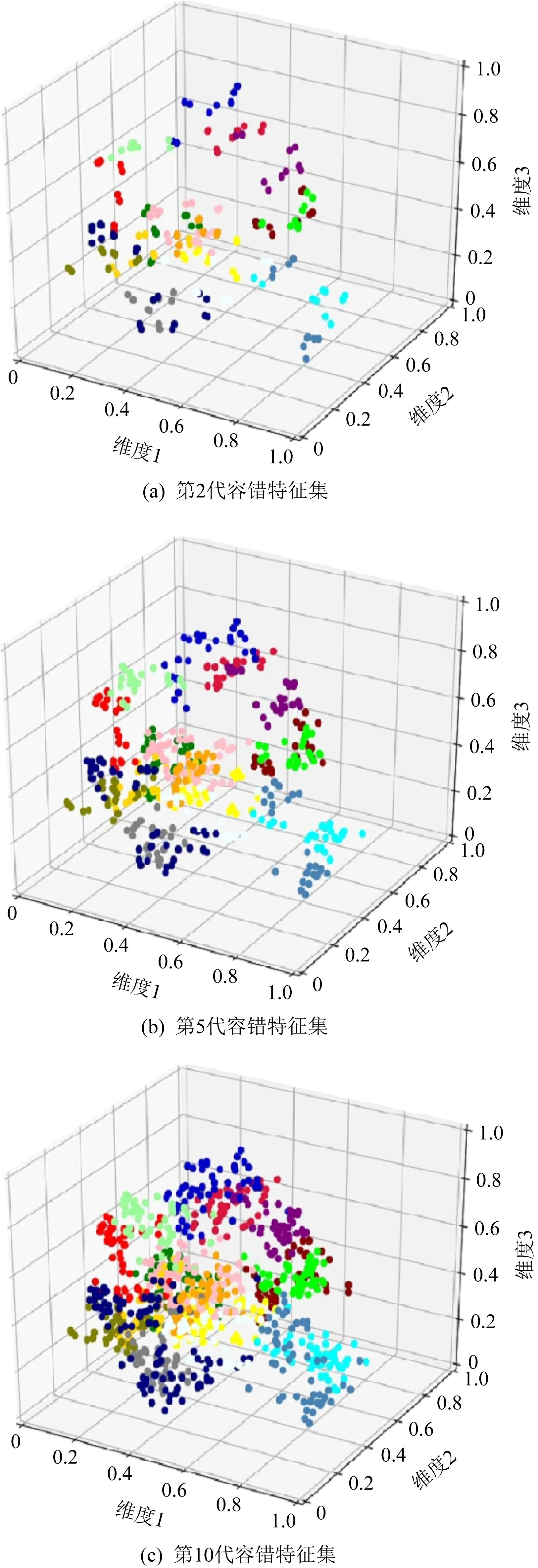
Fig. 9 Tolerance feature extension diagram图9 容错特征扩充示意图
图9是有限样本条件下的容错特征扩充过程,在扩充完每代容错特征后,展示特征集经PCA降维后在3维空间中的分布情况.对比图6中标准特征的分布情况,容错特征填充了标准特征集中的空隙,不同类别的特征间边界更加清晰.随着样本的欠规范程度提高FID上升趋势保存稳定,第2代、第5代、第10代的FID分别为0.17,4.50,6.57.可知扩充的容错特征虽然距离标准特征更远,但都较为均匀地环绕在标准特征四周,表明经扩充后的容错特征集空间结构合理.最后验证本文方法的实际应用价值,利用CSL数据集中的训练集构建容错特征集,训练特征分类器模型在测试集上进行验证,与其他主流算法对比如表1所示:

Table 1 Recognition Accuracy Rate of Different Methods on CSL Dataset
由表1可知本文相较其他基于骨架信息的手语识别方法[18-19]提高13.1%的识别准确率,在仅采用骨架信息的情况下,依然优于基于RGB与骨架信息的混合模型方法[20-21],满足生活场中欠规范手语识别的容错需求.综上所述,本文方法在CSL数据集和实际场景中都取得了不错的效果,其优势体现在不仅可以无限生成新样本,而且能够提供欠规范样本扩充容错信息,使手语识别模型摆脱样本有限的枷锁进而得到充足的训练.在目前人体姿态估计技术快速普及、成本降低的趋势下,节省RGB信息可以简化模型的复杂度,降低硬件资源开销.可见该方法不仅有助于欠规范手语识别在实际生活中普及,在有容错需求的交警手势识别、智能家电控制、人体动作理解等相关生活领域中,同样具有广泛的应用前景.
5 结 论
本文提出了一种在有限样本条件下欠规范手语识别的容错特征扩充方法.该方法针对手语存在的时空关联现象,设计结合时空图卷积与循环网络的自编码器,分别提取手语样本的全局特征与时隙特征.然后同时从重构误差和判决器的判决误差入手,控制生成样本的欠规范程度,完成容错特征的迭代扩充.最后通过实验证明,生成样本拟真程度高,容错特征集结构合理,有利于后续任务的开展.
作者贡献声明:孔乐毅负责完成实验并撰写论文;张金艺提出了算法思路和实验方案,并与楼亮亮一起提出指导意见并修改论文.
猜你喜欢
疯狂英语·新阅版(2023年5期)2023-05-31 05:43:06
开放教育研究(2020年2期)2020-03-31 01:54:14
活力(2019年15期)2019-09-25 07:23:06
成都信息工程大学学报(2018年3期)2018-08-29 01:08:40
电子设计工程(2017年20期)2017-02-10 03:39:29
现代语文(2016年21期)2016-05-25 13:13:44
电子器件(2015年5期)2015-12-29 08:42:24
青少年科技博览(中学版)(2015年8期)2015-10-28 21:26:56
大连民族大学学报(2015年2期)2015-02-27 08:28:11
作文大王·笑话大王(2014年11期)2014-11-13 09:01:43
