
采用动态知识因子的基于知识共享的优化算法 *
2022-03-07 11:51赵艳玲
广西民族大学学报(自然科学版) 2022年4期
袁 磊,王 勇,2,赵艳玲
(1.广西民族大学 人工智能学院,广西 南宁 530006;2.广西混杂计算与集成电路设计分析重点实验室,广西 南宁 530006)
0 引言
元启发式算法在科学和工程等领域得到广泛的应用,其优越性也得到界内研究者的广泛认可,因而自20世纪70年代Holland提出遗传算法(GA)[1]以来,元启发式算法的研究越来越受到国内外研究者的重视。目前在国内外刊物或国际会议上发表的有关元启发式算法研究成果大体上可分为两类:一是原创性提出新算法(如粒子群算法(PSO)[2],蝗虫优化算法(GOA)[3],鲸鱼算法(WOA)[4],黑猩猩优化算法(COA)[5],社会模拟算法样式(SMO)[6]、教学优化算法(TLBO)[7],算数优化算法(AOA)[8]、哈里斯鹰优化算法(HHO)[9],知识共享算法(GSK)[10]等);一是修改或完善现有算法或混合各种算法(如文献[11-14]等)。由于包括文献[1-10]在内的这些新算法通常存在全局收敛速度慢、易陷入局部最优等不足,因而需要人们去完善这些现有算法,以改善其优化性能。
基于知识共享的优化算法(Gaining-sharing knowledge based algorithm for solving optimization problems, GSK)[10]是由Mohamed等人从人类获取和共享知识过程中得到启发,于2019年提出的一种新的群智能优化算法。GSK具有算法模型简单易懂、易于编程实现等优点。然而,GSK存在全局搜索能力不强、收敛速度慢、易陷入局部极值等不足,仍有待进一步完善。针对GSK之不足,Mohamed等人[11]提出改进版本的GSK,称之为APGSK,该APGSK用自适应概率参数来控制知识比率,以平衡全局探索与局部开发。然而从文献[11]给出的具体实例实验与仿真结果上看,APGSK的收敛速度相对较慢、优化精度也不高。Zhong等人[12]提出将GSK与HHO相结合的混合差分进化算法,称之为DEGH。该算法首先构建一个混合变异算子,用于平衡全局探索和局部开发;其次利用交叉概率自适应来加强差分变异、交叉和选择之间的联系。然而从文献[12]列出的具体实例实验结果上看,该算法的全局搜索能力不强、收敛速度较慢、优化精度不高。Xiong等人[13]只是将GSK应用于求解决太阳能光伏模型参数提取问题,并没对GSK进行改进。综合以上分析,文献[11]和[12]提出的改进版本GSK在优化精度方面比标准GSK有所提高,但提升的程度非常有限,仍存在较明显的全局搜索能力不强、收敛速度较慢、易陷入局部最优等问题,仍有待进一步完善。针对这一问题,本文对GSK进行改进,提出采用动态知识因子的基于知识共享的优化算法(Gaining-sharing knowledge based algorithm Using Dynamic Knowledge-factor,DKGSK),并通过具体实例仿真来验证本文提出改进策略的有效性和可行性。
1 GSK简介
基于知识共享的优化算法(GSK)将人类知识的获取分为初级(junior)和高级(senior)两个阶段:第一阶段称为初级获取与分享阶段;第二阶段称为高级获取与分享阶段。GSK算法把每个人(一生中)在中前期(幼年期或早期)、中后期(成年期)获得知识的阶段分别称为初级阶段和高级阶段。GSK算法模型如下:
设N为特定人群总人数(种群规模),D是人可获取知识的学科领域数(表示人的知识全部从D个学科获取,表征搜索空间维数是D),以xij表示第i人从第j学科中获取知识,以xi=(xi1,xi2,…,xiD)表示第i人的知识维度,f(xi)为其适应度值,i=1,…,N。
1.1 确定使用初级获取与分享知识的维度数
搜索开始时,首先计算第i人xi使用初级方案(初级获取)更新的维度数,从而也就确定了使用高级方案(高级获取)的维数。具体方法如下:设t时刻第i人的位置为xi(t)=(xi1(t),…,xiD(t)),则由公式(1)计算:
其中:k称为知识率,是大于0的实数(GSK在数值实验中取k=10),Tmax为最大迭代次数,t为当前迭代次数。记Djun为不超过D(juniorphase)的最大正整数。则在t+1时刻,xi(t)=(xi1(t),…,xiD(t))的前Djun个维按初级获取知识方案进行更新,后Dsen个维则按高级获取知识方案进行更新,其中:
1.2 不同阶段知识获取与分享方法
记xi(t)为第i人于t时刻的位置(i=1,…,N),f(xi)为其适应度值。根据适应度值将人群按升序排列:xbest(t),…,xi-1(t),xi(t),xi+1(t),…,xworst(t),并且从[0,1]中取一个随机数rand:
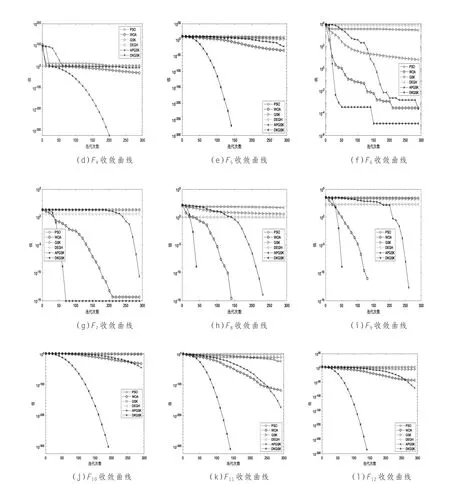
针对初级获取与分享阶段,首先给定kf(知识因子)和kr(知识比率),其中kf>0,0 若rand≤kr,则xi(t)的前Djun个维均按公式(3)更新知识: 否则(即rand>kr时)不更新,i=1,…,N,j=1,…,Djun。即xi(t)的前Djun个维均采用初级获取知识方案更新知识。其中:xi-1(t)和xi+1(t)分别是比xi(t)更好和更差的两个“人”,作为xi(t)获取知识的来源,再从群体中随机选择另一个“人”xr(t)作为知识共享的来源。注:若xi(t)为当前最优个体,则以xbest+1(t)和xbest+2(t)作为其获取知识的来源;若xi(t)为当前最差个体,则以xworst-1(t)和xworst-2(t)作为其获取知识的来源。 针对高级获取与分享阶段,首先将种群分为最好人群(人数为p⋅N)、中等人群(人数为(1-2p)⋅N)、最差人群(人数为p⋅N)三个群体(GSK在数值实验中取p=0.1)。然后每个“人”使用如下方案更新知识: 若rand≤kr,则xi(t)按公式(4)更新知识: 否则(即rand>kr时)不更新。i=1,…,N,j=Djun+1,…,D。其中xp-best(t)、xm(t)和xp-worst(t)为分别从最好人群、中等人群、最差人群中随机选择的一个个体。 GSK实现步骤如下: Step1:给定目标函数f(x),种群规模N,搜索空间维数D,最大迭代次数Tmax,知识率k,知识因子kf,知识比率kr,种群最好人群比例p。 Step2:初始化种群xi(t),评估每一个体的适应度值f(xi(t)),i=1,…,N。 Step3:根据适应度值将种群按升序排列:xbest(t),…,xi-1(t),xi(t),xi+1(t),…,xworst(t)。 Step4:利用公式(1)和(2)确定Djun和Dsen=D-Djun。 Step5:从[0,1]中取一个随机数rand,若rand≤kr,则xi(t)的前Djun维度均采用公式(3)更新知识,后DDjun维度均采用公式(4)更新知识;否则不更新。 Step6:评估每一个体的适应度值f(xi(t)),i=1,…,N。 Step7:判断是否满足终止条件:若满足则转Step8;否则转Step3。 Step8:算法终止,并根据适应度值将最优位置作为优化问题的最优解。 分析标准GSK算法模型:不管是在初级阶段还是在高级阶段,搜索个体的前Djun个维均按公式(3)更新位置、后D-Djun个维则均按公式(4)更新位置。显然,GSK的公式(3)和(4)中,每个维更新位置时,其步长均由知识因子kf确定,然而kf是给定的常数(GSK在数值实验中取kf=0.5),因此,GSK种群中个体每个维的搜索步长是固定的,也就是说,GSK种群中的每一个体在搜索空间中均采用“同一时刻步长完全相同、同步跳跃”的搜索策略。这使得种群个体搜索明显缺乏随机性和灵活性,限制了个体的搜索灵活性和自主性,降低了个体的搜索能力和效率,造成算法搜索效率低下,最终导致GSK的全局搜索能力不强、全局收敛速度较慢、优化精度不高之不足。针对GSK存在的问题,本文提出相应的改进策略,详述如下: i=1,…,N,j=1,…,Djun。其中r为[0,1]中的随机数。 i=1,…,N,j=Djun+1,…,D。其中w=(1-t/Tmax)4,L(λ)为列维飞行[14]: 公式(5)中的r⋅kf和公式(6)中的L(λ)⋅kf均是随机可变的, 而标准GSK的知识因子kf是固定的。因此,本文将r⋅kf和L(λ)⋅kf统称为动态知识因子(本文算法在数值实验中取kf=1.8)。 说明:a)公式(5)和(6)中的w⋅xi,j(t)表示:个体i对知识的吸取具有习惯性,并保持其这一习惯性趋势。w=(1-t/Tmax)4是一个关于算法搜索时间t的单调递减函数,当t=1时,w=(1-1/Tmax)4≈1(本文算法置Tmax=300),t=300时,w=0 。换言之,w从算法搜索前期到后期逐步从1单调递减到0;w在算法前期的值相对较大,从而加快了个体的搜索速度,使群体能以较快速度遍历整个空间。这有利于算法进行全局探索、可为后期开展局部搜索尽可能多地积累和反馈信息;w在算法后期下降较慢,并随着搜索时间t的增加而趋于0。因而在w的作用下,可提升个体的局部搜索精度,进而增强算法的局部开发能力。b)公式(5)表示:个体i是由向量w⋅xi,j(t)与向量rkf×Δ 根据平行四边形法则来控制其搜索的,其中Δ=[(xi-1,j(t)-xi+1,j(t))+(xr,j(t)-xi,j(t))]或[(xi-1,j(t)-xi+1,j(t))+ (xi,j(t)-xr,j(t))]。而r为[0,1]中的随机数,因而个体i可以在由第一部分w⋅xi,j(t)与第二部分rkf×Δ 所确定的平行四边形覆盖的范围内开展精细化搜索,其搜索步长具有随机性和灵活性,这使其全局探索与局部开发能力均得到了提升。c)公式(6)表示:个体i是利用w⋅xi,j(t)与L(λ)×Ω 来控制 其 搜 索 的,其 中Ω=kf⋅[(xp-best,j(t)-xp-worst,j(t))+(xm,j(t)-xi,j(t))]或kf⋅[(xp-best,j(t)-xp-worst,j(t))+(xi,j(t)-xm,j(t))]。由于列维飞行L(λ)具有随机行走特性和行走步长呈现重尾的分布特征,故采用这一方法来控制个体搜索可使搜索步长更具灵活性和随机性,当搜索个体陷入局部最优位置时,利用列维飞行能以较大概率实现大跨步跳出当前最优位置,进而可提升算法跳出局部最优的能力、增强算法的局部开发能力。d)到算法后期,w几乎为0,故个体i在算法后期主要由rkf×Δ或L(λ)×Ω控制,即其主要是从比其更优的个体中吸取知识,亦即在后期侧重开展局部搜索,进而增强了群体的局部搜索能力。 本文算法已对标准GSK中的“Step5:从[0,1] 中取一个随机数rand,若rand≤kr,则xi(t)的前Djun维度均采用公式(3)更新知识,后D-Djun维度均采用公式(4)更新知识;否则不更新”进行了修改,去掉其中的“从[0,1] 中取一个随机数rand,若rand≤kr”条件,进一步简化了算法实现条件。 本文算法(DKGSK)实现步骤如下: Step1:给定目标函数f(x),种群规模N,搜索空间维度D,最大迭代次数Tmax,知识率k,知识因子kf,种群最好人群比例p(本文算法在实验中取kf=1.8,k=10,p=0.1)。 Step2:初始化种群xi(t),并评估适应度值f(xi(t)),i=1,…,N。 Step3:根据适应度值将种群按升序排列:xbest(t),…,xi-1(t),xi(t),xi+1(t),…,xworst(t)。 Step4:由公式(1)和(2)确定Djun和Dsen=D-Djun。 Step5:xi(t)分别根据公式(5)和(6)更新其前Djun个维和后D-Djun个维。 Step6:评估每一个体的适应度值f(xi(t)),i=1,…,N。 Step7:判断是否满足终止条件:若满足则转Step8;否则转Step3。 Step8:算法终止,并根据适应度值将最优位置作为优化问题的最优解。 设最大迭代次数是T,种群规模是N,探索空间维数是D。初始化种群的时间复杂度是O(N),计算初级阶段维数的时间复杂度是O(T),排序时间复杂度是O(N(N-1)T/2),因而标准GSK的时间复杂度是O(N(N-1)T/2)+O(NDT)+O(N)+O(T)。在AGSK中,引入自适应权重与列维飞行的时间复杂度为O(NT),故DKGSK的时间复杂度是O(N(N-1)T/2)+O(NDT)+O(NT)+O(N)+O(T),若略去时间复杂度之低次项,则两种算法的计算时间复杂度是一致的。 为 了 测 试 本 文 算 法(DKGSK)的 性 能,本 文 将DKGSK与 标 准GSK[10]、PSO[2]、WOA[4]、APGSK[11]、DEGH[12]作算法性能对比分析,以验证本文算法(DKGSK)的优化性能。 本文选取12个已被广泛用来测试算法优化性能的基准测试函数(具体见表1),作为算法数值实验与优化性能对比分析的测试实例,这些基准测试函数当中包含5个单峰函数和7个多峰函数。其中:单峰函数主要用来测试算法的收敛速度,多峰函数则用来测试算法的全局搜索能力和规避陷入局部最优的能力。 表1 基准测试函数 为了数值实验测试结果的公平性,本文实验针对六种对比算法均统一设置种群规模为100、最大迭代次数为300。对于GSK[10]、PSO[2]、WOA[4]、APGSK[11]、DEGH[12]这五种算法的其余参数,均与相对应的文献[10]、[2]、[4]、[11]、[12]的设置一致。 为了尽可能避免随机性对数值实验结果的影响,本文在做数值实验测试时,六种算法针对每一个测试问题都独立进行30次实验,并将运行结果(最优值、平均值、标准差)记录下来。这些评价指标总体上反应了算法优化能力的强弱以及算法稳定性的好坏。其中:“最优值”评价指标反映了算法的全局搜索能力和优化精度,“平均值、标准差”评价指标能够反映算法的稳定性能。本文针对30维和200维搜索空间分别做数值实验,得到的实验结果见表2。 为了便于观察和比较六种算法各自的收敛速度,本文也给出了六种算法分别求解这12个基准测试函数时得到的适应度进化曲线图,具体如图1所示。 本文根据实验数据表2和进化曲线图1来分析这六种对比算法各自的优化性能。 从“最优值”上看:本文算法(DKGSK)找到F1∼F5,F7∼F12这11个测试函数的理论最优值;WOA只找到F8和F9这两个函数的理论最优值;其余的四种算法均没有找到这12个测试函数的理论最优值。六种对比算法都没有找到F6的理论最优值,但本文算法(DKGSK)找到F6的最优值均比其他五种算法更接近理论最优值,且优化精度均比其他五种算法至少高2个数量级。这说明在六种对比算法当中,本文算法(DKGSK)的全局搜索能力最强、优化精度最高、比其他五种对比算法明显具有较大的优势。 从“平均值”和“标准差”上看:本文算法(DKGSK)求解F1∼F5,F7∼F12这11个测试函数时得到的“平均值、标准差”均与理论最优值相同;WOA求解F8和F9得到的“平均值、标准差”与理论最优值相同,而求解其余10个函数得到的“平均值、标准差”均与理论最优值有偏差;其余四种算法求解这12个测试函数时得到的“平均值、标准差”均与理论最优值有偏差。DKGSK求解F6时得到的“平均值、标准差”与理论最优值有点偏差,但偏差量比较小(小于10-4),且偏差的程度均比其他五种算法的小。这说明本文算法找到全局最优值的概率明显高于其余五种对比算法,算法的稳定性均好于其他五种对比算法;这对DKGSK用于求解工程等方面的优化问题提供了技术可靠性。 从图1的(a)~(l)上看:相较于其他五种对比算法,本文算法(DKGSK)的进化曲线均位于对比算法的进化曲线当中之最底下、下降的速度是最快的。本文算法求解F1∼F5、F7∼F12这11个测试函数时得到的进化曲线均到达理论最优位置;WOA只有求解F8和F9时得到的进化曲线能到达理论最优位置,其余的10个测试函数的进化曲线均没能到达理论最优位置;另外四种算法(GSK,PSO,APGSK,DEGH)求解这12个测试函数得到的进化曲线均没能到达理论最优位置。这说明了本文算法的收敛速度最快、优化精度最高。 图1 函数收敛图 为了进一步测试这六种对比算法各自的优化性能,本文再用六种算法分别求解表1中的12个函数当D=200时的优化表现,以考查六种算法的鲁棒性问题。具体得到的实验结果均列在表2中。 基于表2的实验数据进一步分析六种对比算法各自的性能。 表2 30/200维基准测试函数测试结果对比 本文算法(DKGSK)找到F1∼F5,F7∼F12这11个函数的“最优值、平均值、标准差”都是函数理论最优值;WOA只找到F8和F9这两个函数的“最优值、平均值、标准差”是函数理论最优值;其余的四种算法找到这12个测试函数的“最优值、平均值、标准差”都不是函数理论最优值,与理论最优值有偏差。本文算法找到F6的“最优值4.383E-06”非常接近理论最优值0,比D=30时找到的最优值9.906E-06还要好,找到的“平均值2.436E-05,标准差2.350E-05”也非常接近理论最优值,与D=30时找到的“平均值3.4565E-05,标准差2.057E-05”相当。本文算法找到F6的“最优值、平均值、标准差”都比其他五种对比算法更接近理论最优值,优化精度都比其他五种算法至少高2个数量级。标准GSK、DEGH、APGSK、PSO求解这12个函数时找到的“最优值”出现了明显地偏离理论最优值的“失灵”现象,且偏离还比较大。基于以上分析,说明了将搜索空间维度从30增加到200时,本文算法(DKGSK)的全局搜索能力并没有减弱、优化精度并没有下降、算法稳定性也没有下降,没有出现随着搜索空间维度的增加而出现“失灵”的现象。这进一步说明了本文算法的稳定性和鲁棒性比较好,规避陷入局部最优的能力比较强。 记p=最好人群/群体规模N。为了研究p之不同值对DKGSK优化性能的影响,本文针对p=0.1,0.2,0.3,0.4分别做数值实验。表1中的F6是一个具有多极小点但只有一个全局最小点(0,…,0)的多峰函数,由于受random[0,1)的扰动,要找到其全局最小点相对较难,故寻找F6的最小点是较能考验算法的全局探索和局部开发能力的。因此,本文就以F6作为确定p值之测试函数。实验种群规模为100,最大迭代次数300,D=30。针对p之不同值,均独立运行30次,考查p取不同值时算法稳定性的变化情况。利用绘制箱线图来反映30次运行结果,可容易观察到多组连续型定量数据分布的中心位置和散布范围。当p取不同值时,DKGSK 的中位数线均靠近全局最小位置,且大部分数据都接近理论最优位置。这说明DKGSK具有较强的全局寻优能力、较强的跳出局部最优能力和较好的优化精度,采用的改进策略是有效和可行的。从箱线图的高度上看,p取4个不同值时,大部分数据点都没有严重偏离理论最优位置。从偏离理论最优位置上看,当p=0.1时,没有出现偏离理论最优位置的数据点,而p取其余3个值时,均出现偏离理论最优位置的数据点。因此,本文算法(DKGSK)在数值实验中取p=0.1。 其次,为了研究知识因子kf之不同值对DKGSK 优化性能的影响,本文针对kf= 0.5,1,1.2,1.5,1.8 分别做实验。实验设置种群规模为100,最大迭代次数为150,D=30。从实验结果上看:DKGSK求解F1∼F5和F7∼F12在kf=1.8时的表现最好、求解F6在kf=1.5时的表现比较好。因此,本文算法(DKGSK)在实验中取kf=1.8。 为进一步验证本文算法(DKGSK)的寻优性能,将DKGSK分别与GSK,DEGH,APGSK,PSO,WOA算法进行Wilcoxon秩和检验。在显著性水平为0.05的条件下检验算法之间的显著差异性,其中p表示检验的数值,若p值小于0.05,则表明算法之间的寻优结果存在显著性差异,否则无明显差异。N表示数据无效即检验的所有样本数据相同,算法不具有显著差异性。从测试数据可以看出,p值小于0.05的占绝大多数。因此,DKGSK与其他五种对比算法具有非常显著的差异性,并且DKGSK的全局优化能力最强。 针对标准GSK之不足,本文提出采用动态知识因子的基于知识共享的优化算法(DKGSK)。首先,利用单调递减自适应权重函数来控制个体的移动步长,使个体在算法前期能以较大步长在搜索空间中进行全局探索活动,让种群个体尽快遍历整个搜索空间,增强了算法的全局探索能力,为算法后期的局部搜索活动提供了更多有用的信息;个体在算法后期以较小步长开展局部搜索活动,提升了个体的局部搜索能力,增强了算法的局部优化能力,从而使算法的全局探索和局部开发能力均得到提升。其次,利用动态知识因子来调控个体搜索,针对初级获取阶段和高级获取阶段,分别通过0至1之间的均匀随机函数和列维飞行函数来调控个体搜索,使个体搜索步长更具随机性,提升了个体搜索能力,从而增强了算法的局部开发能力。此外,当个体搜索陷入局部最优时,借助列维飞行可使其跳出当前最优位置,从而使算法跳出局部最优的能力得到提升。通过与标准GSK和改进版本GSK作数值实验与仿真结果比较,验证了本文算法在全局收敛速度、优化精度、算法稳定性方面均得到了明显的提高,规避陷入局部最优的能力得到了增强。后续研究将重点考虑将本文算法应用于数据分类、工程优化设计等方面的应用中。2 本文算法
2.1 针对GSK公式(3)之不足,本文对其作如下改进
2.2 针对GSK的公式(4),作如下改进
2.3 算法实现步骤
2.4 算法时间复杂度分析
3 数值实验
3.1 测试函数

3.2 实验参数设置
3.3 实验结果分析


3.4 DKGSK主要参数确定方法
3.5 Wilcoxon秩和检验
4 结论
猜你喜欢
数学物理学报(2022年4期)2022-08-22
数学物理学报(2022年2期)2022-04-26
太原科技大学学报(2022年1期)2022-02-24
计算机仿真(2021年1期)2021-11-18
计算机工程与设计(2020年4期)2020-04-23
金桥(2018年4期)2018-09-26
物联网技术(2017年5期)2017-06-03
赤峰学院学报·自然科学版(2015年15期)2015-03-21
中国卫生(2014年5期)2014-11-10
医学理论与实践(2014年23期)2014-03-06
