
生成对抗网络及其个性化推荐研究
2022-03-03 13:46吴国栋刘玉良汪菁瑶范维成
小型微型计算机系统 2022年3期
杨 宇,吴国栋,刘玉良,汪菁瑶,范维成
(安徽农业大学 信息与计算机学院,合肥 230036)
1 引 言
随着信息技术的不断发展,网络上的数据呈现了爆炸式增长,人们难以从海量信息中提取自己需要的信息.为解决信息过载(Information overload)问题,出现了个性化推荐技术,其主要思想是帮助用户及时获取自己可能感兴趣的信息,具有“千人千面”的特点.推荐系统不仅缓解了用户选择难的问题,也可以通过对用户的行为、偏好等特征进行分析,发掘用户潜在的需求,更好的为用户做推荐.推荐系统可以根据算法类型分为基于协同过滤的推荐系统和基于内容的推荐系统,也可以根据模型输入的数据类型分为显式和隐式反馈推荐系统[1].虽然推荐系统的研究取得了较大的成果,但推荐系统仍然存在一些问题,如数据稀疏性问题、冷启动问题、时效性问题、多样性推荐问题等[2].近年来,生成对抗网络(Generative Adversarial Nets,GAN)[3]因其可以生成足以以假乱真的虚假数据,有效填充真实数据集,被许多学者用于个性化推荐领域方面的研究.GAN的核心是博弈论中的二人零和博弈思想,即参与博弈的二人,一人的收益必然意味着另一人的损失,且二人的收益与损失总和永远为“零”.由于原始GAN模型存在着训练困难、可控性较差、稳定性较差等问题[4],一些学者提出了GAN的变体,如条件生成对抗网络(Condition GAN,CGAN)[5]、信息生成对抗网络(InfoGAN)[6]、Wasserstein生成对抗网络(Wasserstein GAN,WGAN)[7]、带有梯度惩罚的Wasserstein生成对抗网络(Wasserstein GAN gradient penalty,WGAN-GP)[8]等.
本文在对GAN及其变体分析的基础上,根据模型所输入的是隐式反馈数据还是显式反馈数据的视角,对已有基于GAN的个性化推荐进行了探讨,并对当前基于GAN个性化推荐研究的不足和未来研究趋势进行了展望,以期对相关研究起到一定的借鉴作用.本文第2节对GAN及其常见变体进行了分析;第3节探讨了基于GAN和CGAN的推荐研究进展;第4节指出了GAN推荐存在的问题及不足;第5节展望了GAN推荐的未来研究方向;第6节对本文进行了总结.
2 生成对抗网络及其变体
2.1 原始GAN模型
原始GAN由两个部分组成,分别是生成器G(Generator)和判别器D(Discriminator).其中G负责捕获真实样本数据的分布,并尽可能生成与真实数据相像的虚假数据.D是一个二分类器,判断输入的样本数据来自真实数据分布的概率.GAN的模型结构如图1所示.

图1 GAN结构图Fig.1 Architecture of GAN

GAN的整体优化目标实际上是一个极小化极大问题,如公式(1)所示:

(1)
GAN每轮优化分为两步,第1步固定G,即不对G的参数进行更新,同时对D进行优化,找到当前最优的判别器.对于公式(1),此时G不再更新,而D(x)的输出结果的区间为[0,1],因此log(D(x))与log(1-D(G(z)))的取值范围为(-∞,0],为了使公式最大化,D(x)输出的值接近1,D(G(z))输出的值接近0,这代表D成功识别了真实数据与虚假数据.第2步固定D,同时对G进行优化,找到当前最优的生成器.此时公式(1)中x~pdata(x)[logD(x)]不会进行更新,只需关注公式中的另一项z~pz(z)[log(1-D(G(z)))].在每轮优化中,判别器的能力应该比生成器强一些,但是又不能强太多,因此一般来说,判别器更新多次,生成器才更新一次.G与D相互对抗博弈,最终二者都达到最优状态.
2.2 CGAN模型
对于原始GAN,生成过程没有受到任何约束,导致生成的数据不可控.为了约束生成过程,Mirza Mehdi等人提出了条件生成对抗网络(Conditional Generative Adversarial Net,CGAN).CGAN与GAN的区别在于G和D的输入都额外增加了一个条件变量y,y可以是类别标签、描述文字、一张图片.CGAN通过条件变量y来指导并约束生成过程,使得G生成的结果可以拟合条件变量y.如果y是类别标签,则可以把CGAN看作是无监督学习GAN模型向监督学习的改进[9].CGAN的结构如图2所示.

图2 CGAN结构图Fig.2 Architecture of CGAN
CGAN的目标函数与GAN类似,只是在G和D的输入部分增加了条件变量y,目标函数的形式如公式(2)所示:

(2)
CGAN的训练步骤也与GAN类似.在公式(2)中,虽然变量的输入部分G(z|y)和D(x|y)被写成了条件概率的形式,但在CGAN的具体实现中,只需要将z或x与y拼接起来即可.
2.3 其他GAN模型
与CGAN类似,Xi Chen等人提出的InfoGAN也是为了解决G生成的数据不可控问题.作者认为GAN输入的噪声是混乱的,导致噪声的各个维度与真实数据的特征并不匹配.因此作者针对这种情况,将G的输入部分分为两个部分,一个部分仍为噪声z,另一个部分为代表真实数据不同特征的多个隐变量拼接而成的隐藏编码c.同时使用基于互信息的正则化约束项I(c:G(z,c))用来约束隐藏编码c和生成的虚假样本G(z,c)之间的相关程度.
Martin Arjovsky等人[10]证明了若将GAN训练到最优情况,损失函数等价于最小化真实数据分布与生成数据分布的JS散度,且值为常数log2,因此GAN模型优化的越好,梯度消失的情况越严重.针对这个问题,Martin Arjovsky等人提出了Wasserstein生成对抗网络(Wasserstein GAN,WGAN)模型,使用一种Wasserstein距离取代GAN中的JS散度计算方法.在试验中WGAN在训练的稳定性方面有着较好的表现,但仍然存在梯度爆炸或梯度消失的情况,并且生成的样本真实性较差.
针对WGAN存在着的梯度爆炸或梯度消失的问题,Ishaan Gulrajani等人提出的带有梯度惩罚的Wassertein生成对抗网络(Wassertein GAN gradient penalty,WGAN-GP)通过额外设置一个惩罚项以实现更好的效果.与WGAN相比,WGAN-GP只在WGAN损失函数上增加了一个惩罚项.实验结果证明了WGAN-GP利用梯度惩罚拟合了较为复杂的函数,能够生成质量更高的数据,并且解决了梯度爆炸和梯度消失的问题.但是,因为惩罚项的计算成本较大,导致WGAN-GP的训练所需时间较长.
3 基于GAN的个性化推荐研究
通过对近年来基于GAN的个性化推荐的分析,常见的应用在推荐领域的GAN模型有原始GAN和改进后的CGAN.GAN的实现比较简单,往往不需要太复杂的设计就能达到较好的效果.CGAN因为模型的输入额外加入了条件向量,生成的数据分布会更好地拟合真实数据分布,因此在推荐领域中的表现较好.本节对基于GAN个性化推荐相关研究进行探讨分析.
表1总结了现有基于GAN的个性化推荐研究中相关模型的优缺点.

表1 GAN个性化推荐的优缺点Table 1 Advantages and disadvantages of GAN personalized recommendation
3.1 原始GAN个性化推荐主要研究
3.1.1 基于隐式反馈的RecSimu推荐模型
Xiangyu Zhao等人[11]提出的RecSimu模型能够模拟真实用户行为,可以预先训练和评估推荐算法.RecSimu从用户的浏览记录中学得用户当前的偏好并推荐用户可能感兴趣的物品,然后预测用户对推荐物品的反馈(如浏览、点击或购买等等).RecSimu的结构如图3所示.

图3 RecSimu结构图Fig.3 Architecture of RecSimu
如图3所示,左侧生成器G的输入为用户的历史浏览记录(包括用户浏览过的物品集合以及对每个物品的反馈),先使用编码器学习用户的偏好,再使用解码器和用户的当前偏好预测用户可能会喜欢的物品Gθ(s).G额外加入了一个减少生成的推荐物品与真实的推荐物品之间差异的监督组件.图3右侧的判别器D的输入分为两部分,一部分为用户的历史浏览记录,另一部分为用户真实的推荐物品或预测的推荐物品Gθ(s),最终的输出为预测用户对推荐物品的反馈类别,共包括K个用户对真实推荐物品的反馈和K个用户对虚假推荐物品的反馈.D的目标不仅是区分推荐物品来自真实数据或生成数据,还要根据用户的浏览历史来预测用户对推荐物品的反馈类别.D同样额外加入了一个监督组件,监督组件的目标是减少用户的真实反馈与预测反馈所属类别的差异,以便能更好的预测用户对物品的反馈类别.
实验基于真实电子商务公司的数据,与LR[12]、GRU[13]、GAN、GAN-s[14]等模型进行了对比试验,在F1、MAP等指标上有所提升,与FM[15]、W&D[16]、GRU4REC[17]等模型比较了生成器的有效性,在MAP、NDCG等指标上提升了5%左右.实验结果证明了G所生成的推荐物品和D所预测的用户反馈都有着较好的效果,说明成功捕获了用户的潜在偏好.但模型本身较为复杂,没有考虑到多个反馈之间可能存在的依赖关系,而且在实际情况中,不同类型的反馈数量极不平衡,这也会对最终的推荐效果造成影响.
3.1.2 基于显式反馈的CoFiGAN推荐模型
Jixiong Liu等人[18]提出了CoFiGAN,一种融合了GAN的协同过滤模型,其与应用在信息检索领域的IRGAN[19]类似,生成器G的目标是生成与真实数据相似的高质量数据,判别器D的目标是分辨真实数据与生成的虚假数据.不同的地方在于IRGAN选择间接向G分配奖励或惩罚信号进行优化,而CoFiGAN选择让D通过对G生成的虚假数据进行判断,生成正样本(D所认为会获得高奖励的样本)和负样本(D所认为会获得高惩罚的样本)来直接指导G的训练过程.CoFiGAN的整体优化目标如公式(3)所示:

(3)
公式(3)中d~pθ(i|u)代表用户u所采样物品的概率分布,ptrue代表用户u真实偏好的分布,D(i|u)的输出代表物品i属于用户u真实偏好分布的概率.
因为真实数据是离散的,无法使用梯度下降法对G进行优化,因此CoFiGAN使用了公式(4)对G进行优化:
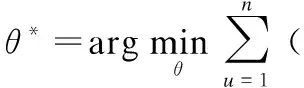
(4)
公式(4)中SG是指G生成的、在G看来会获得更高奖励的样本,SD是指D所认为会获得更高奖励的样本,距离函数Dist(SG,SD)用来衡量SG与SD之间的差距.因此,G为了获得更高的奖励,必须使得Dist(SG,SD)的值最小,即SG更像SD.
实验基于ML-100K、ML-1M、UserTag、NF5K5K等数据集,采用准确率和NDCG作为评价指标,与Neural-MF[20]、IRGAN等模型进行了比较.其中CoFiGAN在NF5K5K数据集上取得的效果最好,与IRGAN相比在两个指标上都提升了30%左右.
CoFiGAN通过类似于强化学习的方式对模型进行优化,加快了收敛速度,增加了虚假数据的多样性,并且在一定程度上避免了模型崩溃,但模型复杂度较高,且没有缓解数据稀疏性问题.
3.1.3 基于显式反馈的CnGAN推荐模型
DilrukPerera等人[21]等人针对跨领域推荐中非重叠用户无法获得较好推荐效果的情况提出了CnGAN,该模型通过学习从目标网络到源网络的偏好流形映射,生成非重叠用户的源网络用户偏好,再将得到的用户偏好应用在目标网络上进行推荐.CnGAN由生成任务和推荐任务两个部分组成.
生成任务由判别器D与生成器G组成.G的目标是学习一个映射函数,能够将非重叠用户在目标网络上的已知偏好映射为源网络上的缺失偏好.D的目标是判断输入的源网络与目标网络的偏好是否是匹配对(匹配对是指在同一时间间隔内来自同一用户的源网络与目标网络的偏好).
推荐任务的目标是利用非重叠用户在时刻t的目标网络偏好和G生成的源网络偏好,以及在时刻t之前用户与物品的交互情况,预测用户在时刻t+1有可能交互的物品集合并进行推荐.推荐任务结构如图4所示.

图4 CnGAN的推荐任务结构图Fig.4 Recommender task architecture of CnGAN

CnGAN选择Twitter数据集作为源网络,YouTube数据集作为目标网络,与TBKNN[22]、TDCN[23]、CRGAN等模型相比,在命中率、NDCG等指标上有着提升.
CnGAN有效针对了非重叠用户推荐效果较差的问题,能够有效补充用户在源网络缺失的偏好,在TOP-N推荐中有着较好的表现,但是对于重叠用户的推荐效果没有达到预期.
3.1.4 基于显式反馈的其他推荐模型
同样是基于GAN的跨领域推荐模型,Cheng Wang等人[24]提出的RecSys-DAN用于解决跨领域中的数据稀疏和数据不平衡问题.通过训练源领域的生成器Gs用来初始化目标领域的生成器Gt,再训练评分函数用来判断Gt生成的用户、物品和交互行为与源领域的是否相似,最终可以得到在目标领域推荐效果最好的用户集和物品集.
为了缓解冷启动问题,Po-Lin Lai等人[25]提出了ColdGAN.ColdGAN使用一个基于时间的更新函数,用于将暖用户(评分过大量商品的用户)还原为冷用户(几乎没有评分过商品的用户).用户对商品的评分越早,越有可能保留在还原之后的冷用户状态中.将还原后的冷用户输入到ColdGAN中,生成器G的目标是生成该冷用户对应的暖用户,判别器D的目标为判断输入的暖用户是否为真实的暖用户.
针对社会化推荐存在着大多数用户的朋友比较少以及用户的朋友不一定可靠的问题,Junliang Yu等人[26]提出了RSGAN,一种基于用户对他们可靠的朋友所消费的物品感兴趣的假设所设计的模型.RSGAN通过生成用户的可靠朋友间接提高用户所获得的推荐效果.生成器G的目标是生成对该物品有着同样评分的可靠朋友,并使用Gumbel-Softmax函数[27]对可靠朋友消费的物品进行采样.判别器D判断用户对G输出的物品是否感兴趣,并将其转为有序物品集合进行推荐.如果生成器G生成的可靠朋友没有提高推荐效果,D将惩罚生成的可靠朋友并降低G生成此类朋友的概率.
Qingqin Wang等人[28]提出的GANMF首先构建了用户-物品矩阵,利用用户对物品的评分历史,使用基于图的混合协同过滤计算当前用户与其邻居节点的相似程度,并从多阶邻居节点中获取更多的用户偏好,构建包含用户信息的用户矩阵.使用同样的方式构建包含物品信息的物品矩阵.然后将用户矩阵作为G的输入,物品矩阵作为D的输入,并根据G预测的用户对物品的评分进行Top-N推荐.
3.1.5 基于隐式反馈和显式反馈的推荐模型
HomangaBharadhwaj等人[29]提出的RecGAN有效使用了GRU,模型目标是为了更好的利用用户和物品潜在特征的时间属性来提高推荐系统的有效性.为了更有效的模拟用户长短期行为和物品的潜在特征,作者对GRU做了修改,具体来说,在更新门中引入了ReLU激活函数,并在GRU模型中加入了协同技术.模型的整体优化公式如式(5)所示:

(5)
在公式(5)中,Gen和Dis分别代表生成器和判别器,i代表第i位用户,j代表第j个物品,t代表第t个时刻.Gen生成的用户i在时刻t对物品j的评分用(r|i,j,t)表示,学习到的用户偏好分布用Dgen|t表示,相应的,用户真实的偏好分布用Dreal|t分布.
实验基于Netflix Challenge、MyFitnessPal等数据集,与RRN相比,RecGAN在RMSE指标上提升了0.5%.与PMF[30]、T-SVD[31]、AutoRec[32]等模型相比,RecGAN在MAP指标上提升了大约10%.RecGAN并没有对修改后的GRU进行详细的测试,无法判断修改后的GRU对模型带来的具体影响.
Zhou Yao等人基于此文献[33]的分析,提出了一种名为PURE[34]的基于GAN的推荐模型.PURE使用PU学习训练D,G学习用户和物品的潜在连续分布以生成高质量的用户和物品嵌入.通过与PMF、GMF、CFGAN[35]等模型的比较,PURE在精度、NDCG、MAP等指标上都有着提升.
RecSimu、CoFiGAN、CnGAN、RSGAN、GANMF、RecGAN、PURE等模型的主要目标是提高用户获得的推荐效果,RecSys-DAN与ColdGAN的主要目标则是缓解冷启动问题,不同的是RecSys-DAN针对的跨领域推荐的数据稀疏和数据不平衡问题,ColdGAN针对的是普通用户遇到的冷启动问题.为了更好地捕获用户偏好,RecSimu、ColdGAN、RecSys-DAN、CnGAN、RecGAN等模型都利用了用户的时间信息.考虑到数据的离散性,每个模型选择的优化方式都有所不同,RSGAN使用Gumbel-Softmax对模型进行优化,GANMF使用策略梯度方法对模型进行优化,ColdGAN、RecSys-DAN、CnGAN、RecSimu、RecGAN、PURE、CoFiGAN等根据模型自身特点使用了独特的优化方式,如设计了独特的优化函数、直接指定正负样本等等.
3.2 CGAN个性化推荐主要研究
3.2.1 基于隐式反馈的IRGAN推荐模型
Wang Jun等人在2018年提出了一种用于信息检索领域的IRGAN模型.与GAN不同,IRGAN中的生成器G的目标是从候选文档池中采样与查询相关的文档,使采样的文档分布不断接近相关文档的真实分布.判别器D的目标是尽可能分辨出与该查询相关或不相关的文档.模型的整体优化目标如公式(6)所示:
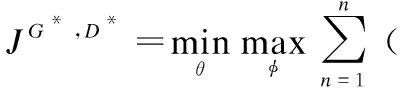
(6)
公式(6)中,qn是用户输入到信息检索模型里的查询,n的取值范围是[1,N],D是与qn相关的文档,r是qn与d的相关程度.d~ptrue(d|qn,r)为用户提交查询的相关文档的分布,pθ(d|qn,r)为G所学到的与用户提交查询的相关文档的分布.公式(7)展示了D的结构,其中fφ(dk,qn)为评分函数,因此D输出的值为查询q与文档d相关的概率.
(7)
因为文档是离散数据,而随机梯度下降法(Stochastic Gradient Descent)是无法应用到离散数据中的,因此IRGAN选择使用基于策略梯度(Policy Gradient)的强化学习(Reinforcement Learning)对模型进行优化.因此目标函数可以改写成公式(8):
(8)
公式(8)中log(1+exp(fφ(dk,qn)))作为从pθ(d|qn,r)中选择文档d的奖励,dk代表从G生成(或采样)的文档中采样得到的第k个文档.为了减少强化学习过程中的差错,也可以将奖励项替换为对应的优势函数.
IRGAN在网页搜索、问答系统和物品推荐这3个应用方向上做了实验,不同的应用方向选择了不同的数据集,分别为LETOR、InsuranceQA、ML-100K和Netflix,在不同的应用方向与多个模型做对比,IRGAN取得了较好的效果.但是仍然存在着可解释性不足的问题,并且在缺乏足够的用户反馈的情况下表现较差.
3.2.2 基于隐式反馈的CFGAN推荐模型
Dong-Kyu Chae等人指出IRGAN、GraphGAN[36]存在的问题,即随着训练的进行,G将会生成与真实样本完全相同的样本,而相同的样本会被打上不同的标签:当样本来自G时会被打上“假”标签,当它来自于真实样本时会被打上“真”标签.因此D会退化,无法更好的指导G,最终G与D的性能都会降低,推荐精度也会下降.
为了解决这个问题,Dong-Kyu Chae等人提出了一种基于GAN的协同过滤框架CFGAN.CFGAN中G的目标是生成与真实购买向量比较相似但绝对不一样的购买向量,而不是生成用户可能感兴趣并会购买的商品,这种方法有效防止了G生成的样本会被打上不同的标签.D的目标是区分生成的购买向量与用户真实的购买向量.
考虑到数据非常稀疏,用户与物品有交互(即购买)时元素为1,否则为0,而G会倾向于不考虑用户偏好,使生成的购买向量元素值全部为1.为了解决这个问题,作者提出了3种新的CF方法:CFGAN_ZR、CFGAN_PM、CFGAN_ZP,它们共同的核心思想是在每次训练中,每个用户随机选择一部分从没有购买过的物品,将其设置为负物品,表示用户对该物品的购买向量值不是缺失的,而是0.然后G生成的用户购买向量中,对应的负物品值接近0.这样在G生成的购买向量中,用户购买过的元素值接近1,没有购买过的值接近0,就可以避免G生成的购买向量的元素值全为1.模型结构如图5所示.

图5 CFGAN结构图Fig.5 Architecture of CFGAN

实验选择了Ciao、Watcha、ML-100K、ML-1M等数据集,与BPR、FISM、CDAE、IRGAN、GraphGAN等模型进行对比,实验结果显示CFGAN在准确率、召回率、NDCG、MRR等评价指标上有着较好的表现,在TOP-N推荐上有着较好的效果.但CFGAN在缺乏足够的用户交互的情况下表现较差,并且模型的稳定性有待提高.
3.2.3 基于隐式反馈的其他推荐模型
Sudhir Kumar等人[37]提出的c+GAN用于真实电商平台的服装推荐.对于任意服装图像都需要先进行处理,以去除模特图像,并切割为上装和下装两个部分.为了更好的学习真实图像的分布,基于Sajjadi等人[38]的工作,作者提出了一种新的随机标签反转概念.c+GAN在必应商城中进行了应用,推荐的结果无论是在图像质量还是在多样性上都有着较好的效果.
Linh Nguyen等人[39]提出的用于跨领域推荐的D2D-TM是UNIT[40]的扩展模型,它既能提取不同领域间的同质特征,也能提取不同领域间的差异特征.D2D-TM由CGAN、VAEs[41]、Cycle-Consisterncy[42]3个部分组成.生成器G由VAEs和Cycle-Consistency构成,目标为重构本领域的交互向量,并生成在另一领域的交互向量.判别器D的目标为判断交互向量的真假,具体来说,对本领域的交互向量的判断结果为真,对G生成的交互向量的判断结果为假.
3.2.4 基于显式反馈的GraphGAN推荐模型
Hongwei Wang等人注意到了图神经网络中丰富的信息,提出了一种图表示学习框架GraphGAN.对于一个给定的结点vc,生成器G(v|vc;θG)的目标是拟合它的潜在真实连接分布ptrue(v|vc),并生成(或采样)最有可能与vc有连接的结点v,结点v形成的分布记为G(·|vc;θG),D的目标是判断生成的结点v与vc之间是否存在连接,并输出它们之间存在边的概率.整体优化目标如公式(9)所示:

(9)
公式(9)中θG和θD分别是结点v的k维表示向量的聚合.GraphGAN使用的softmax函数有两个局限性,首先softmax函数会计算图中所有的节点,导致计算效率较低,其次softmax函数没有利用图的结构信息.针对这些问题,作者提出了graph softmax函数.graph softmax函数具有能够生成有效的概率分布、利用图的结构信息、计算效率高等优点.具体来而言,从顶点vc开始对图g进行广度优先搜索(Breadth First Search,BFS),最终形成了一棵以为根节点的广度优先搜索树Tc.在Tc中任取一个节点v,其邻居(直接与v连接的节点)集合记为Nc(v).节点v及其邻居vi的相关概率计算公式如式(10)所示:
(10)
公式(10)中gvi和gvj代表对应节点的k维表示向量.对于Tc中任何一个节点来说,都有一条唯一的路径可以从根节vc点到达该节点.使用graph softmax函数定义的生成器G(v,vc;θG)如公式(11)所示:
(11)
GraphGAN创新性的通过生成对抗的思想去更新网络节点向量,并且提出了graph softmax函数.实验基于arXiv-AstroPh、arXiv-GrQc、BlogCatalog、Wikipedia、ML-1M等数据集,与DeepWalk[43]、Line[44]、Node2Vec[45]、Struc2vec[46]等模型比较,在arXiv-AstroPh和arXiv-GrQc数据集上的链路预测正确率分别提升了大约3%和10%,在节点分类上的正确率提升了大约11%和20%.在推荐方向上与其他模型相比,准确率提升了38%-156%不等.但是因为需要对每一个节点生成BFS,模型的时间复杂度和空间复杂度都比较高,花费的代价较大.
3.2.5 基于显式反馈的其他推荐模型
针对冷启动和数据稀疏性问题,Dong-Kyu等人[47]提出了AR-CF,一种使用多个CGAN生成虚拟但可信的用户和物品,将其作为附加信息来扩充评分矩阵的CF模型.通过在ML-100K、Watcha、ML-1M、CiaoDVD等数据集上的实验,证明了确实在一定程度上缓解了冷启动问题,同时在推荐精度上也有所提高.但模型较为复杂,对算力要求较高.
Wang等人[48]针对不活跃用户获得的推荐效果较差提出了AugCF.AugCF基于DADA[49]的标签系统将数据标签从两个(喜欢,不喜欢)扩充到了4个(真实&喜欢,真实&不喜欢,虚假&喜欢,虚假&不喜欢),成功将数据扩充阶段与推荐阶段融合进模型中.在数据扩充阶段,D作为二分类器判断数据是真实还是G生成的虚假数据.在推荐阶段,D作为协同过滤模型判断用户是否会喜欢该物品.AugCF在数据较为稀疏的情况下有着较好的表现.
Zhao Wei等人[50]提出的PLASTIC融合了矩阵分解和RNN,利用用户历史交互记录预测用户在某个时间可能会感兴趣的物品列表,并进行Top-N推荐.
IRGAN作为第1个应用在推荐领域的GAN模型,为推荐领域的研究提供了新的方向,尤其是开创性地使用策略梯度方法优化GAN推荐模型,影响了后续很多基于GAN的个性化推荐模型.从应用方向上来看,AugCF主要用于缓解数据稀疏性,其它模型都可以应用在TOP-N推荐方向,其中IRGAN可以应用在网页搜索、问答系统等方向,GraphGAN可以应用在链路预测、节点分类等方向,AR-CF可以缓解冷启动.在优化方式上,IRGAN、CFGAN、GraphGAN、PLASTIC等模型都是用了策略梯度方法对模型进行优化,而c+GAN、D2D-TM、AR-CF、AugCF使用了其他方式对模型进行了优化.
4 已有GAN个性化推荐研究中存在的问题
GAN推荐虽然在提升推荐精度、缓解数据稀疏性上有着较好的表现,但在某些方面仍然存在着一些不足.
1)稳定性较差.基于GAN的推荐模型都存在着稳定性较差的问题,因为需要小心协调生成器和判别器的训练程度.若是顾此失彼,导致一方训练地较好,而另一方训练地较差,模型的推荐效果就会非常差.另外,在训练过程中,梯度很容易消失,进而导致模型容易坍塌.随着训练的进行,生成器会倾向于生成最简单的且永远不会犯错的数据,导致生成的数据同质化严重,且没有任何值得参考的价值.可以尝试使用经过优化后的GAN模型,如InfoGAN、WGAN-GP等缓解这种现象.
2)缺少通用的优化方法.对于使用反向传播进行优化的GAN模型而言,模型所需要的真实数据分布必须是连续的,不能是离散的,不然会导致无法使用梯度下降法对模型进行优化.对于离散数据,基于GAN的个性化推荐模型虽然可以通过策略梯度方法、Gumbel-Softmax函数等方式对模型进行优化,但仍然缺少一个通用的优化方法.
3)模型较为复杂,时空间复杂度较高.GAN本身的结构较为简单,将其应用到推荐系统后,要想达到较好的推荐效果,往往需要与其他模型、函数进行融合.考虑到GAN本身存在的优化问题,又需要使用其他的手段对模型进行优化,最终模型变得较为复杂,时空间复杂度都较高.除了提高硬件水平之外,也可以像EBGAN[51]那样,可以通过预训练使模型的一部分先获得较强的能力,降低时间复杂度对实际业务带来的影响.
4)缺少通用的评测指标.在推荐领域中,可以通过NDCG、准确率、召回率等指标分析GAN推荐的效果,但目前没有一个通用的评测GAN模型训练程度的评测指标,或许可以通过计算生成样本与实际样本之间的相似系数来评估GAN模型训练的程度.
5 GAN个性化推荐未来研究方向
随着互联网数据的急速增加和不断提高的无监督学习的重要性,基于GAN的个性化推荐研究与应用越来越多.未来GAN推荐的主要研究方向:
1)提高模型稳定性.如何协调生成器和判别器之间的训练程度,提高GAN的稳定性一直是GAN模型所要解决的重要问题之一,提升GAN推荐的稳定性,避免模型出现难以训练、易坍塌的问题,仍是今后研究的一个重点.
2)缓解推荐过程中数据的稀疏问题.GAN最大的优点在于能够生成虚假的数据,并且在极小化极大思想的指导下,生成的数据分布能够不断拟合真实数据分布,这能够很好的缓解数据稀疏性问题.目前已经有部分GAN推荐模型用于缓解数据稀疏问题、冷启动问题,但是总体而言针对数据稀疏问题的模型仍然较少.针对缓解数据稀疏问题的GAN推荐模型仍然需要研究.
3)多场景融合的GAN推荐.随着互联网的发展,需要推荐领域的不仅仅是电子商务平台,包括社交工具、视频平台、信息聚合平台等等各种平台.在不同的场景下,所能获取的数据类型也是不同,如视频、音频、社交关系、文本、时间序列等等,融合不同类型场景,结合上下文感知、社交关系、时间序列或多种数据进行推荐,也是GAN推荐的一个研究方向.
4)融入图神经网络的GAN推荐.图神经网络含有丰富的信息,包括用户-用户、用户-物品、物品-物品等等,除了节点本身的属性外,节点之间的边也可以表示多种信息,如购买历史、社会关系等等.若是GAN能够有效利用图神经网络里的信息,更好的提取图中的数据与关系,相信能够很好的提升推荐效果.虽然目前的研究较少,但此方向值得关注.
6 结束语
生成对抗网络自2014年被提出以来,在各个领域都受到了诸多关注.得益于GAN基于极小化极大的核心思想,GAN在无监督学习上具有一定优势,最近几年,基于GAN的模型数量在快速提升.GAN推荐因为所使用的模型、优化方法等等都不一样,在不同的领域有着不同的效果,在实际运用时需要根据所要针对的领域选取不同的GAN推荐模型,更好的利用其优势.本文从基于GAN的个性化推荐所使用的基础模型类别出发,针对当前GAN推荐的研究现状进行了分析,并探讨了各个模型的优缺点.针对GAN推荐存在的稳定性较差、缺少通用优化方法、模型较为复杂、缺少通用评测指标等问题.进行了简单介绍,并对提高模型稳定性、着重缓解数据稀疏问题、融合多场景和融入图神经网络等方向对GAN个性化推荐的未来研究方向进行了展望.
猜你喜欢
教学研究与管理(2022年3期)2022-04-25
华东师范大学学报(自然科学版)(2019年3期)2019-06-24
福建基础教育研究(2019年3期)2019-05-28
西部资源(2018年1期)2018-11-01
小天使·二年级语数英综合(2017年3期)2017-04-01
中学生数理化·高三版(2016年9期)2016-05-14
小天使·四年级语数英综合(2015年7期)2015-07-06
小天使·一年级语数英综合(2015年8期)2015-07-06
读者·校园版(2015年13期)2015-07-01
中学生物学(2008年2期)2008-07-07
