
基于VAE-GAN 算法的信用卡欺诈检测模型
2022-03-02 12:42严嘉钰贝世之
北京电子科技学院学报 2022年4期
严嘉钰 贝世之 章 乐
北京电子科技学院,北京市 100070
引言
随着人们对美好生活需要的进一步提高,经济市场化程度不断提升,信用卡这一支付手段也日益普及,其为人们带来便利的同时,由伪造、冒用信用卡和伪装持卡人所造成的信用卡欺诈问题也为人民财产安全和市场交易秩序带来了严重危害,因而信用卡欺诈检测也成为亟需解决的主要问题。
信用卡欺诈检测,本质上是一个分类问题,就是将信用卡消费行为分为有欺诈风险和无欺诈风险的两类,其重点在于对信用卡交易中的异常数据进行识别。 近几年来,随着数据量和计算机计算能力的提升,越来越多的学者开始将机器学习方法应用于信用卡欺诈检测中。 莫赞等人[1]针对传统单个分类器在处理不平衡数据中的局限性,提出对抗生成网络-自适应增强-决策树算法,即GAN-AdaBoost-DT。 Zhang 等人[2]研究出基于加权支持向量机的信用卡欺诈检测方法,通过加权支持向量机SVM 算法,提高了异常数据检测性能。 陈荣荣等人[3]采用XGBoost算法令信用卡欺诈检测的AUPRC 值更接近1。Prasetiyo 等人[4]引用随机森林算法对合成的数据集进行训练和验证,其识别效果比简单的机器学习算法效果更好。 Lebichot 等人[5]运用评估增量学习策略,设计出一种基于评估增量学习策略的信用卡欺诈检测系统,其多样性迁移学习和集成学习方法提高了检测的准确性。 琚春华等人[6]运用k 最近邻(kNN)分类算法和合成少数类过采样技术(Smote)算法,设计了基于kNNSmote-LSTM 的信用卡欺诈检测网络模型,在提升模型性能的同时,克服了生成新样本时的局限性和盲目性。
在目前的银行欺诈检测系统中,主要采用的是群体行为分析,即仅通过交易是否满足欺诈行为来判断是否是欺诈交易[7],适用机器学习进行检测。 而关于用机器学习的方式检测信用卡欺诈行为,有监督的机器学习往往需要大量的人工标注数据,且只能检测同种特征行为的欺诈。在寻找更优的处理方式的过程中,人们寄希望于以无监督的学习方法进行信用卡欺诈检测,即异常检测[8]。
现有的深度异常检测通过使用无监督的深度学习来解决这个挑战,然而在他们之中表征学习与异常检测方法往往是分开的,例如自动编码器中的中间表征和生成对抗网络中的潜在空间,所以它可能产生次优的表征,甚至是不相关的。针对学术界目前的研究成果以及面临的难题,本文通过创新性地结合优势神经网络结构和学习方法,在无监督学习的基础上运用基于VAEGAN 的算法训练神经网络,帮助模型学习到更好的判别策略,不断逼近甚至超过现有的最佳结果。
Guansong Pang 等人提出了一种名为Dev-Net[9]的深度异常检测方法,其通过先为少量带标记的异常数据强制分配得分,然后根据先验概率计算一部分正常数据的得分均值作为基准值,由正常数据与异常数据得分的偏差作为优化目标,使异常数据得分逐渐偏离基准值。 该方法与本文方法在相同数据集下有着在AUC 值上约2%的优势,然而其模型训练时仍需要少量带标签的异常数据,并非真正意义上的无监督学习,因此与本文方法无直接比较性。 除此之外,本文的主要贡献如下:
1) 针对未来可能出现的、当前数据集中所不具备的新型欺诈数据,本文充分运用了更加符合实际情况的无监督学习方法,令模型具备检测出新型欺诈数据的能力;
2) 利用了信用卡欺诈检测数据集中正常样本数量占比极大、异常样本数量占比极小这一特点,在以无监督方式训练VAE 型网络重构能力的过程中,由于异常样本的占比极小,其影响可以忽略不计。 运用GAN 对抗获得生成能力更佳的VAE 型网络时,异常数据经过VAE 型网络映射后分布位置离正常数据较远这一特点,精确区分出异常数据和正常数据;
3) 实验表明,针对于信用卡欺诈检测问题,本文在采用无监督学习的情况下,测试结果的AUC 达 到0.9581,Recall 达 到0.9118,ACC 为0.9468。 数据集可以从该url①https:/ /www.kaggle.com/datasets/mlg-ulb/creditcardfraud中获取。
1 基础知识
对聚类算法的研究是机器学习领域的一个基础且重要的课题,变分自编码器和生成对抗网络是深度神经网络聚类算法的有力工具。 本部分将简要介绍变分自编码器和生成对抗网络的基本原理,以及如何结合变分自编码器和生成对抗网络构造信用卡欺诈检测模型。
1.1 变分自编码器
变分自编码器是由Kingma 等人[10]提出的基于变分贝叶斯(Variational Bayes,VB)推断的生成式网络结构,是一种借鉴变分推断原理的深度神经网络,通常作为生成模型,其中含有多个隐藏层,结构上包括编码器和解码器。 编码器可以将复杂分布的样本数据投影到简单的隐变量空间,将原始数据x转换为潜在特征z, 实现对样本数据的特征提取,编码表示为:z~Enc(x)=qφ()。 解码器可以还原在隐变量空间里取样的数据,将潜在特征z重构为新的样本数据解码表示为:其中参数φ、θ由变分自编码器的神经网络进行更新。 由于以上过程中的潜在特征z的分布无法直接观测,因此引入变分自编码器的编码过程qφ()来代替真实的后验分布pθ(), 为了使qφ() 和pθ() 近似相等,变分自编码器使用KL散度来衡量两者的相似度,并且通过参数φ、θ使KL散度最小化[11]:
根据相关文献[11]的数学推导,可以得到变分自编码器的损失函数通常为:
其中第一项是变分自编码器的KL损失函数,第二项是变分自编码器的重构损失函数,x为原始数据,z 为潜在特征,φ、θ为编码器和解码器的分布函数。
变分自编码器的作用是通过学习输入样本的潜在特征,然后通过重构数据的方式让输出与输入尽可能相似,这一点与传统的自编码器(Auto-Encoder,AE)有着相似之处,但自编码器主要采用重构误差的方式重构数据,寻找的是单值映射关系,其只能近似地复制,并只能复制与训练数据相似的输入,同时其是自监督算法,并非无监督算法。 而变分自编码器更关注原始数据对象的数据分布模式,寻找的是分布映射关系,更适用于生成数据,并且考虑了KL 损失函数和重构损失函数,使得生成的样本具有更强的泛化能力。 变分自编码器能够令输入样本被投影到隐变量空间时尽量满足标准正态分布,易于抽样处理,同时能够有效防止模型过拟合,在信用卡欺诈检测中具有更强的适应性。
根据以上性质,本文将测试集输入到训练好的变分自编码器中,变分自编码器将输入数据投射到隐变量空间,由于训练效果好的变分自编码器有较强的“欺骗能力”,因此正常数据在隐变量空间中的分布将会非常贴近原始数据,而分布位置离正常数据较远的数据则可以标记为异常数据。
1.2 生成对抗网络
生成对抗网络由生成器G 和判别器D 组成,生成器G 的作用是将输入样本映射到近似真实数据空间的隐变量空间之中,生成与输入样本尽可能相似的虚假样本,从而尽可能地“欺骗”判别器D。 判别器D 是一个二分类器,其作用是判定输入样本是否来自于真实的数据集。
生成对抗网络的训练过程是一个博弈的过程,在训练过程中,先训练判别器D,提高其判别能力,以正确区分真实数据和生成数据,而后训练生成器G 以混淆当前版本的判别器D,根据判别器D 的判别结果进行优化,从而提升生成样本的能力。 循环上述过程,交替训练判别器D和生成器G,逐渐提高判别器D 的判别能力和生成器G 的伪造能力,直到生成器G 生成的样本接近真实样本,判别器D 无法判别真实样本和生成样本,达到动态平衡。 理论上,当生成数据空间和真实数据空间完全重合时,判别器就无法再区分真实数据和生成数据了,而生成器也达到最优而无法进一步训练,该平衡点被称为纳什均衡[12]。 生成对抗网络的损失函数通常为:
其中Pdata(x) 为真实样本的数据分布,Pz(z) 为生成样本的数据分布,x为真实样本,z为服从某一分布的随机变量。
信用卡欺诈检测问题的数据维度较大,数据分布极不平衡,数量稀少的异常样本所提供的信息量很难使分类器具有很强的分类能力。 生成对抗网络可以通过模仿原始数据生成相似的异常数据与相似的正常数据,不用收集大量的原始异常数据也可以很好地进行模型训练,非常契合异常数据极少的信用卡欺诈检测问题。 因此,将一个变分自编码器作为生成器G,通过生成对抗网络的判别器D 提升生成器G 的映射能力,根据输入样本被映射后的分布位置判定样本正常与否,可以作为信用卡欺诈检测的一个新思路。
2 VAE-GAN 算法
根据变分自编码器可以将数据映射到隐变量空间的优势和生成对抗网络可以在博弈的过程中优化生成器G 和判别器D 的优势,本文参考Larsen[13]等人提出的VAE-GAN 模型结构,将变分自编码器作为生成对抗网络的生成器G,与判别器D 共同训练,共享参数,提出了一种VAE-GAN 算法,将变分自编码器作为最终的判别模型。 在采用本文所描述的VAE-GAN 算法时,训练好的模型具有更强的正常数据生成能力,结合样本空间上的分布差异,能够有效检测出异常数据。
2.1 无监督的学习方式
常见的有监督或半监督机器学习方法往往需要大量的带标签数据,具体到信用卡欺诈检测领域中,即需要大量的实际欺诈数据作为其训练集。 然而,在现实生活中,信用卡交易信息极为庞杂,且随着信息技术的不断发展与普及,数据量将变得更加惊人,相比之下,欺诈数据的数据量极少,而欺诈手法又不断更迭,这些小样本数据的监督学习标签具有较大的局限性,在效果与实用性上差强人意。
本文使用无监督的学习方法进行信用卡欺诈检测,其总体流程为:对交易原始数据进行预处理得到特征矩阵;通过PCA 对特征值进行降维;最后通过本文所提出的算法对降维后的特征矩阵进行无监督学习,得到聚类模型。
2.2 算法简介
在无监督的学习方式下,基于生成模型的异常检测方法不要求数据带有标签,能够直接学习并获得输入数据的分布,之后根据重构损失的大小判定异常数据,即异常数据的重构损失较大,正常数据的重构损失较小。
运用VAE 型生成网络,将输入样本送入编码器进行编码后可以得到隐特征向量,根据数据分布的不平衡性,使生成网络具有较强的泛化能力。 但如果泛化能力过强,也将导致部分与正常样本存在交集的异常数据重构误差较小,从而影响检测效果。 GAN 的思想可以解决这个问题,判别器可以限制生成样本的分布质量,强制重新编码后的数据与真实的数据分布的偏差保持在合理的范围内。 在信用卡欺诈检测模型方面,目前尚未有人结合无监督学习方法和VAE-GAN算法进行异常值检测,而本文运用上述方法取得了较为可观的实验成果。
本文所提出的VAE-GAN 算法流程如图1所示。
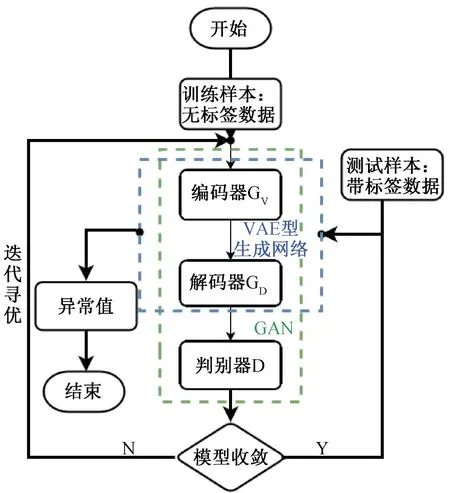
图1 VAE-GAN 算法流程
其在网络结构上由VAE 型生成器G和判别器D两个子网络组成。 VAE 型生成器G中又包含编码器GV(x) 和解码器GD(z)。 对于输入数据,首先经过编码器GV(x) 学习其特征分布,获得其潜在特征表示z的概率分布,z在重新参数化成正态分布后,经过解码器GD(z) 得到x的重构数据x-。 具体步骤如下:
步骤1 输入n 个真实样本x={x(1),x(2),…,x(n)};
步骤2 编码输入样本z~Enc(x)=qφ();
步骤3 假设z~p(z|x)=N(μ,σ2),引入外部向量e~N(0,1),通过z=μ+e×σ计算编码z;
步骤4 解码z同时忽略,生成重构样本
与单独使用传统的生成对抗网络生成样本不同的是,传统的生成对抗网络会将均匀分布随机采样得到的噪声点放入生成网络之中,这种方法所生成的重构数据与真实数据将存在较大差距,如图2 所示,即生成的重构数据无意义,导致无论是正常数据还是异常数据经过重构后都与原始数据较差较远。
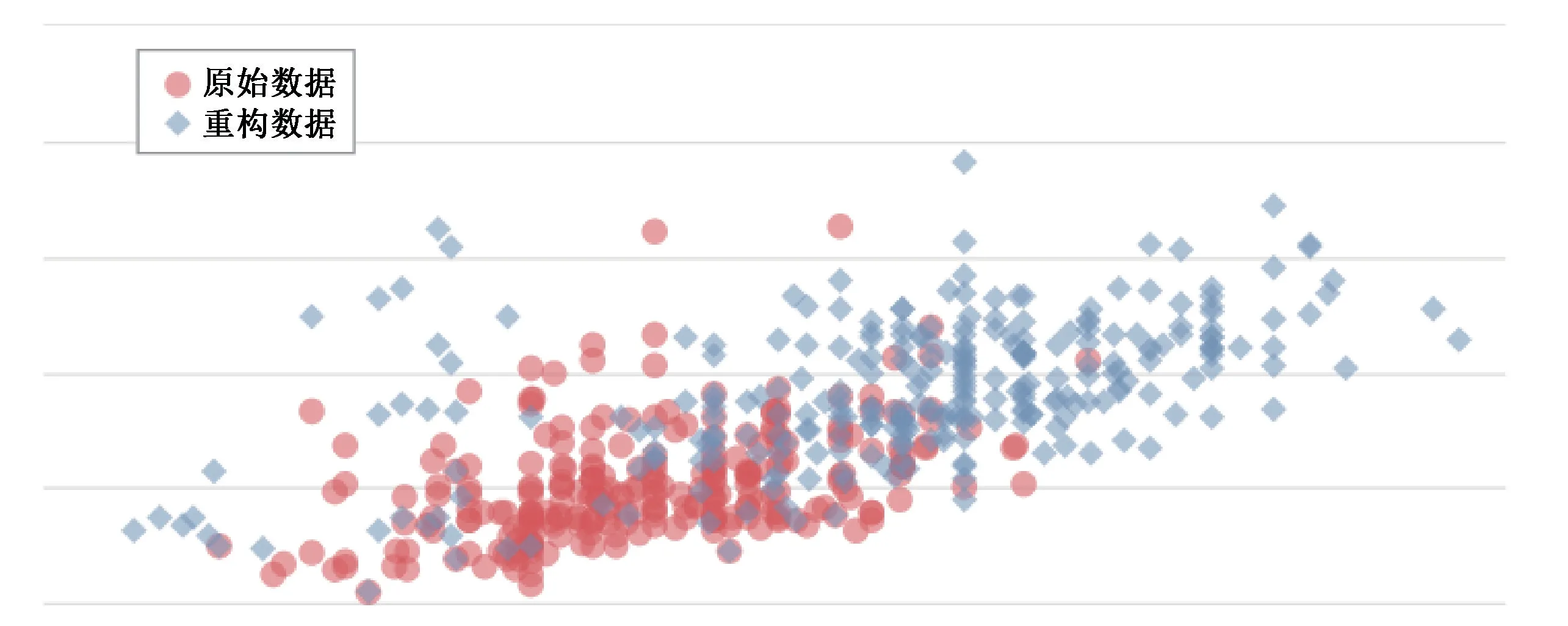
图2 GAN 网络生成样本分布
而本文VAE-GAN 算法中运用VAE 型生成器G学习到输入数据的潜在特征,有效降低了生成对抗网络重构数据时带来的不确定性,根据信用卡欺诈检测数据集极不平衡的特性,生成器G学习到的潜在特征将更趋向于正常数据,此时原正常数据的重构数据x-的分布将极为接近正常数据,而异常的数据经过映射到隐变量空间后,其分布位置将会离正常数据较远,如图3所示。
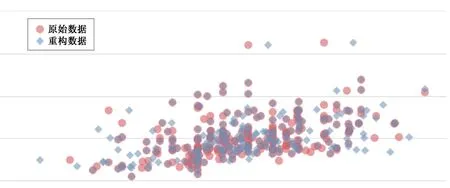
图3 VAE-GAN 生成样本分布
VAE-GAN 算法中的生成器G通过学习输入更趋向正常数据分布的潜在特征后,其输出的重构数据x-被输入到判别器D中进行判别,判别器D在被“欺骗”的过程中不断优化,再将判别结果反馈给生成器G, 生成器G根据判别结果继续优化自身的“欺骗”能力,两者不断迭代寻优,直到达到动态平衡。
2.3 模型训练
对VAE-GAN 算法模型的训练过程就是获得正常输入样本的潜在特征,并利用其经过映射后的分布特征区分正常数据和异常数据的过程,其结构如图4 所示。
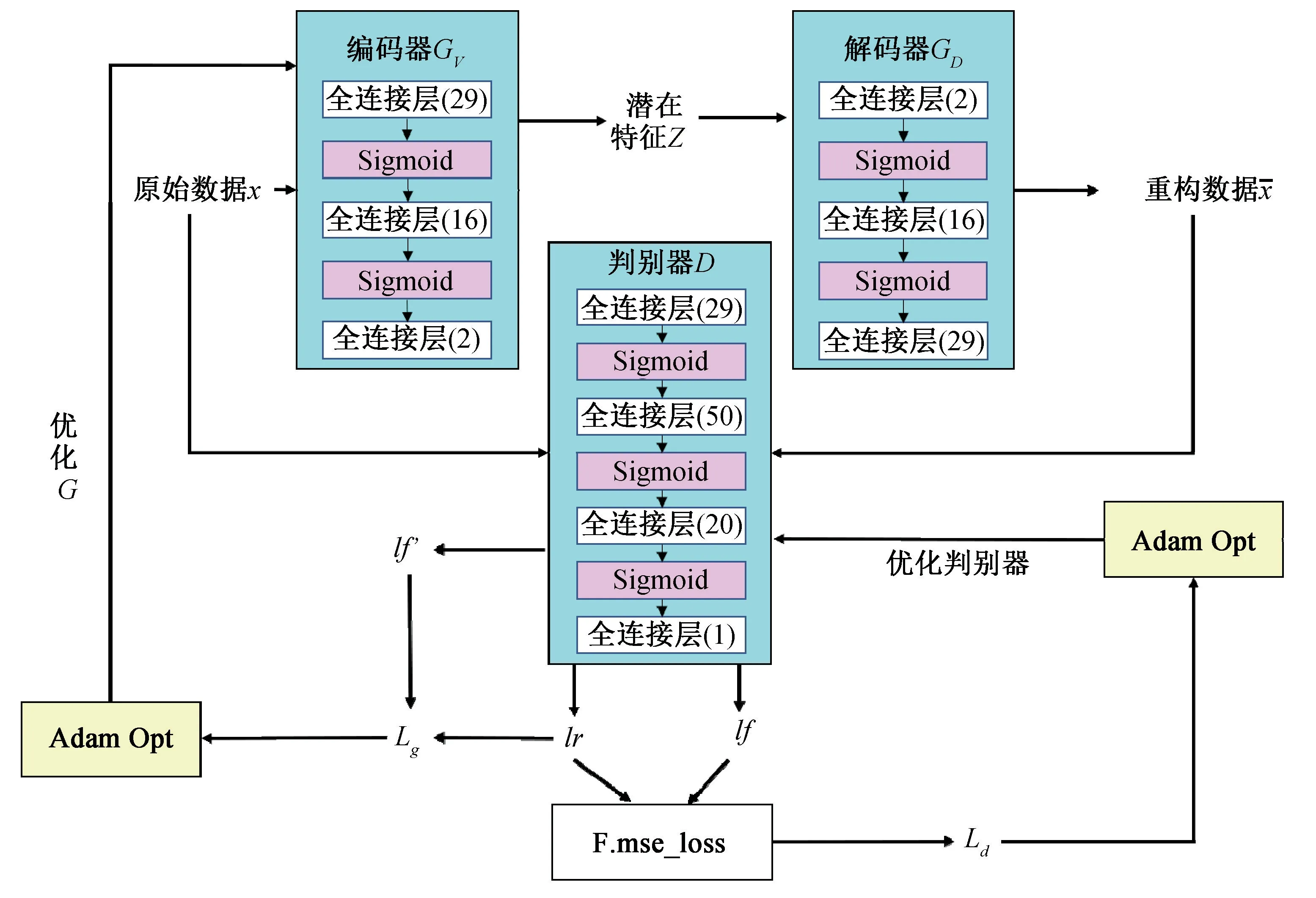
图4 VAE-GAN 算法模型结构
首先对输入样本进行预处理,对获得的原始数据进行PCA 降维,之后对带有标签的数据进行去标签化,作为输入数据。 设置好神经网络的结构之后,将无标签的原始数据送入判别器D中,将原始数据x降维至一个较小的维度,即提取出原始数据的特征表示,标记为逻辑真值lr;同时将无标签的原始数据送入VAE 型的生成器G中,通过编码器GV(x) 提取原始数据x的近似后验分布qφ(z|x),经过重参数化提取出潜在特征z, 再经解码器GD(z) 得到重构数据, 如式(2-1)所示:
模型在参数最优化求解上使用的是Adam优化算法,Adam 能自适应地根据训练数据特点迭代地更新参数权重。 使用均方损失函数计算生成数据与原始数据间的重构误差Lrec,其定义如下所示:
根据损失更新判别器D的各项参数及梯度,让判别器D得到优化,在D的优化过程中,G的权值参数保持不变,只通过反向传播对D的权重进行优化训练;之后将重构数据输入到优化后的判别器D中,得到新的逻辑假值l f′, 这一新的逻辑假值l f′将会和逻辑真值lr一起被用以计算生成器的损失Lg,其定义如下:
同样通过Adam 优化算法,根据损失更新生成器G的各项参数及梯度,让生成器G也得到优化,在G的优化过程中,D的权值参数保持不变,只通过反向传播对G的权重进行优化训练。不断重复上述过程,在不断的相互对抗中迭代寻优。
与常见生成式对抗网络算法不同的是,最终被固定下参数并参与异常值检测的不是判别器D,而是VAE 型的生成器G。 由于原始数据不断被映射到隐变量空间中,信用卡欺诈检测数据集的极不平衡性令正常数据在训练集中的占比远远大于异常数据,因此最终固定生成器G的参数时,得到的是能够最大程度还原正常数据分布的生成器G。
2.4 异常值检测
在模型完成训练之后,此时的VAE 型生成器G已经具有很强的还原数据即集中正常数据分布的能力。 在测试过程中,把测试集中的样本送入训练好的VAE 型生成器G,在检测过程中,生成器G会先将测试样本送入编码器GV(x) 进行编码,然后将编码器所提取的潜在特征进行重新参数化成正态分布,之后经过解码器GD(z) 重构数据生成一个新的样本,通过计算新样本和原始测试样本的均方差,便能通过均方差的大小与阈值的比较判断该数据的标签值。
如果输入的测试数据是欺诈数据,在经过重构后,这一原始的欺诈数据样本和其重构样本之间在空间上的距离将会非常大,即其重构误差值[14]将会非常大,因此二者的均方差也会非常大,以至于均方差大于所设置的阈值,从而被检测出异常。
具体的阈值可以由ROC 曲线中的灵敏度和特异度计算约登指数来确定,小于阈值会被判断为正常,否则被判断为异常[15]。
3 实验结果
本文中的训练过程均在华为云服务器AI 加速 型 ai1s. xlarge. 4、 CPU Intel SkyLake 6151 3.0GHz / Intel Cascade Lake 6278 2.6GHz、16 GB RAM 环境下和CentOS 操作系统下进行,并使用Python3.8 及Pytorch 框架进行实验。
3.1 数据集
本文采用Kaggle 中的高维数据集Credit Card Fraud Detection 进行实验,该数据集包含了欧洲信用卡用户在2013 年9 月通过信用卡进行交易的数据,原始数据为两天内所产生的交易信息,其中共有284,807 笔交易,在这之中只有492 笔交易发生了信用卡欺诈,数据集高度不平衡,欺诈数据仅占所有交易的0.172%。 在本套数据集中,数据已经过PCA 主成分分析技术被分为30 个维度,共包含284,807 个对象,其中类标签为“0”的正常样本共284,315 个,类标签为“1”的异常样本共492 个,其分布如图5 所示。带标签数据仅用于验证集验证,而训练集所用数据为去标签数据。

图5 Credit Card Fraud Detection 数据集的数据分布
3.2 评估指标
本文对模型评估所采用的性能指标是AUC(Area Under Curve)、召回率(Recall)、准确率(Accuracy)、F 值(F-score)。
AUC(Area Under Curve)值是接受者操作特征曲线(Receiver Operating Characteristic)下的面积,该值越大则意味着模型的效果越好,在数据不平衡的情况下依旧可以对模型结果进行的合理预测。 召回率(Recall)表示所有正常样本中,被正确预测出的比例。 准确率(Accuracy)表示模型正确判断的样本占数据集总样本数的比例。
F 值(F-score)是精确度(Precision)和召回率(Recall)的值的调和平均,其计算公式为:
其中β值影响精确度(Precision)和召回率(Recall)两者间的权重。 当β< 1,表示分配给精确度(Precision)的权重更高,当β> 1, 表示分配给召回率(Recall)的权重更高。 而在信用卡欺诈检测中,当真实值为正,而未被成功预测为正(FN)时,成本很高,如本身为欺诈数据而被判断为正常数据,因此非常看重正常样本被正确预测的比例,即召回率(Recall)。 因此在本实验中,为β赋值为2 计算F 值[16]。
3.3 实验结果及分析
对于数据集,首先将其随机打乱为三个部分:70%用于训练,20%用于测试,10%用于验证。 为了研究不同超参数对实验效果的影响,验证集中采用K 折方法将数据划分为三份包进行交叉验证,并使用ROC 曲线中的灵敏度和特异度计算约登指数,找出最佳阈值作为不同模型下二分类的标准。 交叉验证后得到不同生成器网络结构下的AUC 值与召回率,取其中召回率超过90%的生成器网络进行AUC 值比较,得到表1,由表可确定生成器结构为[16,2],阈值为2.29 时,模型效果最佳。

表1 不同生成器网络下的AUC 值
此后通过控制变量法调节其他超参数,直到获得最优模型,其超参数设置见表2。 此时模型在此数据集上获得最佳分类效果。
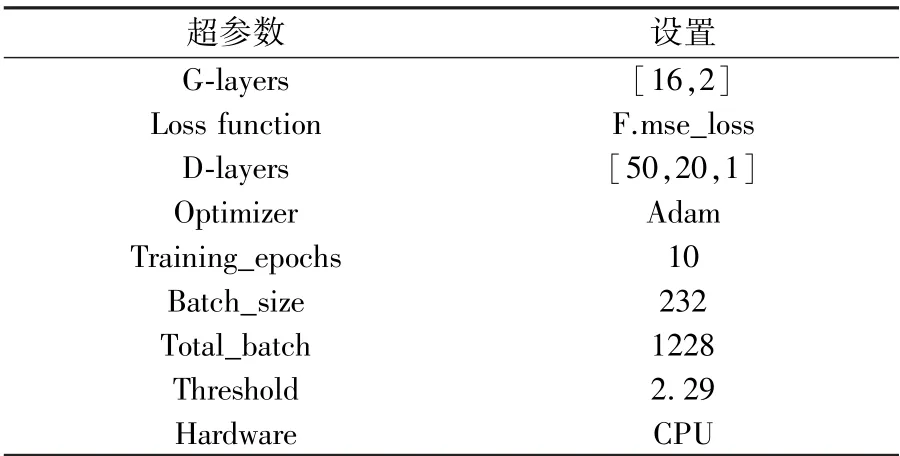
表2 本文中最优模型的超参数设置
该最优模型的混淆矩阵和ROC 曲线如图6所示。 以此最优模型及其相应超参数代表本文所提出的模型,计算出其AUC 值、召回率、准确率以及F 值这四个评估指标,多次实验取得最优值,并与其他模型进行对比实验。
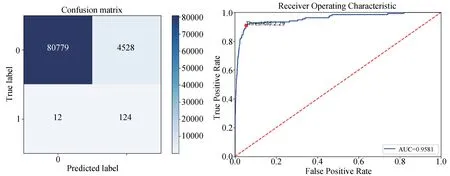
图6 最优模型的混淆矩阵和ROC 曲线
为验证变分自编码器相较于传统自编码器在本文环境中的优越性,以AE 型生成器替换本文模型中的VAE 型生成器,控制无关变量相同,更换不同隐藏层参数在相同实验环境下进行多次实验,分别获得其与本文模型隐藏层参数相同时的分类效果以及在自身最优隐藏层参数下的分类效果,取实验中最优值与本文模型分类效果进行对比实验,结果如表3。 可以看出,VAE 型生成器的各项指标均高于AE 型生成器,其中AUC 值高约1%,说明其有着更好的分类效果;而召回率高约1.6%,因此,认为本文所选用的VAE 型生成器较传统AE 型生成器更适用于信用卡欺诈检测这一领域。

表3 AE 型与VAE 型生成器对比
为验证本文模型在信用卡欺诈检测问题上的有效性,本文在Kaggle 上选取了同样在该问题下进行无监督分类学习且效果为当前算法/模型中表现最优的几类与本文模型进行对比,最终选取的四种算法分别为:Isolation Forest、Kmeans、LOF、One-Class SVM。 其中,不同算法/模型的超参数设置见表4。

表4 不同算法/模型的超参数设置
各算法/模型与本文模型在相同实验环境下的实验结果对比如表5 所示,其中加粗项为该评估指标中最优的一项[17-19]。

表5 不同算法/模型实验结果对比
可以看到,相对于模型效果次优的Isolation Forest 算法,本文所提出的模型在AUC 值上领先其5.77%,具有较为显著的优势,而本文模型的AUC 值(0.9581) 对比K-means(0.5191)、LOF(0.4970)、One-Class SVM(0.5128)更是有着及为显著的优势。 而在召回率上,本文比效果次优的Isolation Forest 算法领先6.91%,并显著领先于其他算法。 同样的,在F-score 上本文模型也以微小的差异领先其他算法。 但由于在极不平衡数据集上识别异常数据时往往代价高昂的特性,本文的准确率稍逊于最优的两项,有着约千分之二的差距。
同时,为了验证本模型在极度不平衡数据集中相较其他方法更具优势,我们选取召回率这一最重要指标作为参考标准,首先采用SMOTE 算法,对原始数据集中的欺诈数据进行了合成少数类过采样,对比各算法的召回率在数据平衡度较高时的效果;随后欠采样欺诈数据,对比各算法的召回率在数据极端不平衡时的效果。 最终各项结果汇总为表6。

表6 不同数据平衡度下各算法/模型召回率结果对比
由上述实验结果可知,当数据集越不平衡,本文方法优势越明显:当数据平衡度为10%时,本文方法较效果次优的Isolation Forest 算法领先5.87%,而这一值在数据偏向极度不平衡时被迅速拉大,在数据平衡度为0.143%时该值为8.02%,在数据平衡度为0.127 时该值为9.30%。 作为目前Kaggle 上信用卡欺诈检测问题下无监督学习领域的最优模型之一,本文模型在数据异常值检测上的AUC 值、召回率以及Fscore 相较于传统数据异常检测方法具有很大的优势,这意味着在数据集极不平衡的情况下,本模型依旧可以对数据进行合理的预测,其召回率高的特性很好的契合了数据异常检测领域中“宁可错杀一千也不可放过一个”的特性,但同时其对正常数据的误判率也有着优秀的水准。就其表现来说,本文所提供的模型在数据异常检测下的无监督领域可以作为一种新思路,具有一定的研究价值。
4 结论
本文针对信用卡欺诈检测问题,利用VAEGAN 算法优化了目前基于神经网络的计算模型的训练过程。 使用Kaggle 中的高维数据集Credit Card Fraud Detection 进行训练。 模型采用无监督学习的方式,能够更好地预防从未出现过的新型信用卡欺诈数据,更符合实际情况。 本文中所讨论的VAE-GAN 算法,在训练过程中相较于传统的变分自编码器和生成对抗网络有较大的不同,主要体现在利用训练后的VAE 型生成器G 能够有效还原出所输入的正常数据分布这一特点,有效识别出经过重构映射后分布位置离正常数据较远的异常数据,改善了由于异常数据过少而导致的过拟合的现象。 同时,本文在信用卡欺诈检测中采用VAE-GAN 算法所取得的测试效果优于Kaggle 中现存的算法。
猜你喜欢
眼科新进展(2022年12期)2022-12-29
网络安全与数据管理(2022年1期)2022-08-29
汽车维修与保养(2019年7期)2020-01-06
中国外汇(2019年16期)2019-11-16
中国外汇(2019年10期)2019-08-27
制造技术与机床(2017年7期)2018-01-19
瞭望东方周刊(2017年35期)2017-09-22
西安工程大学学报(2016年6期)2017-01-15
中国防伪报道(2016年10期)2016-11-21
探测与控制学报(2015年4期)2015-12-15
