
密码算法识别技术研究进展与展望
2022-03-02 12:42池亚平岳梓岩
北京电子科技学院学报 2022年4期
池亚平 岳梓岩 赵 伦
1. 北京电子科技学院,北京市 100070
2. 中国科学院信息工程研究所,北京市 100093
3. 西安电子科技大学,西安市 710071
0 引言
随着信息技术的飞速发展,信息安全的重要性日益凸显,通过密码系统对数据进行加密保护是实现信息安全的重要环节之一,对密文进行密码分析也是密码学领域一个重要分支。
在对密码系统进行监管时,密码分析者通常只能获取密文,无法确定是否正确调用了系统指定的密码算法,导致密码分析和密码设备监管工作困难重重[1]。 1998 年密码学家Lars Knudsen按照已获得的秘密信息的不同将分组密码的攻击分为五类,如表1 所示。 从表1 可以看出,在唯密文条件下实现加密算法的识别是进行各类密码攻击的前提,也是之后开展密码分析的必要条件。 信息安全中的攻与防是相辅相成的,一方面密码算法的识别研究是密码分析领域的重要分支,这也是对密码算法进行的一种攻击。 另一方面,从密码算法设计角度来看,对抗现有技术对密码算法的识别,也是一种新挑战。 密码算法识别目前有两个方面的研究,一方面是利用逆向分析工程对加密算法进行代码层面的分析[2][3],另一方面是在唯密文条件下对密码算法进行识别,本文研究仅针对第二方面进行研究。

表1 针对分组密码的攻击类别
为此,本文从密码算法识别现状研究出发,重点研究融合了机器学习与深度学习技术的各种密码算法识别方法,对这些方法的特点、数据集获取及处理方式进行总结分析和实验验证,针对现有方法存在的问题进行了分析,并对密码算法识别技术发展方向进行了展望。 (注:本文所设计实验内容的运行环境如表2 所示。)

表2 实验环境配置
1 密码算法识别技术评价指标
当前,密码算法识别工作大多使用机器学习中准确性相关指标进行评价,包括精确率、召回率、误报率、总体准确率等[4],常用指标变量如表3 所示。 表3 中各参数定义为:设N 为密码算法类型数,即密文样本由N 类密码算法加密而成;nij表示实际密码算法类型为i的密文被识别为密码算法类型j 的样本数。

表3 常用指标变量
精确率定义为式(1):
召回率定义为式(2):
总体准确率定义为式(3):
精确率和召回率体现了识别方法在每个单独算法类别上的识别效果[5]。 特别是当样本类别分布不均匀时,精确率和召回率可以准确获知每个类别的分类情况。 总体准确率体现了识别方法的总体识别性能,好的算法应该同时具有较高的总体准确率、精确率和召回率。
F-Measure 是综合查准率和查全率得到的评价指标,F-Measure 越高表明算法在各个类型的分类性能越好。 F-Measure 定义为式(4):
完整性反映了识别方法的识别覆盖率。 完整性是指被标识为i的样本与实际类型为i的样本的比值,相当于精确率和召回率的比值,取值范围可能超过1。 完整性定义为式(5):
2 密码算法识别研究内容与研究现状
密码算法识别研究内容框架如图1 所示,主要包括识别类型和识别方法。 密码算法识别的首要任务是在唯密文条件下根据需求确定识别类型,之后再选用合适的识别方法。 密码算法识别方法主要可以分为3 类:基于统计检测的方法、基于机器学习的方法、基于深度学习的方法。密码算法识别研究内容框架如图1 所示。
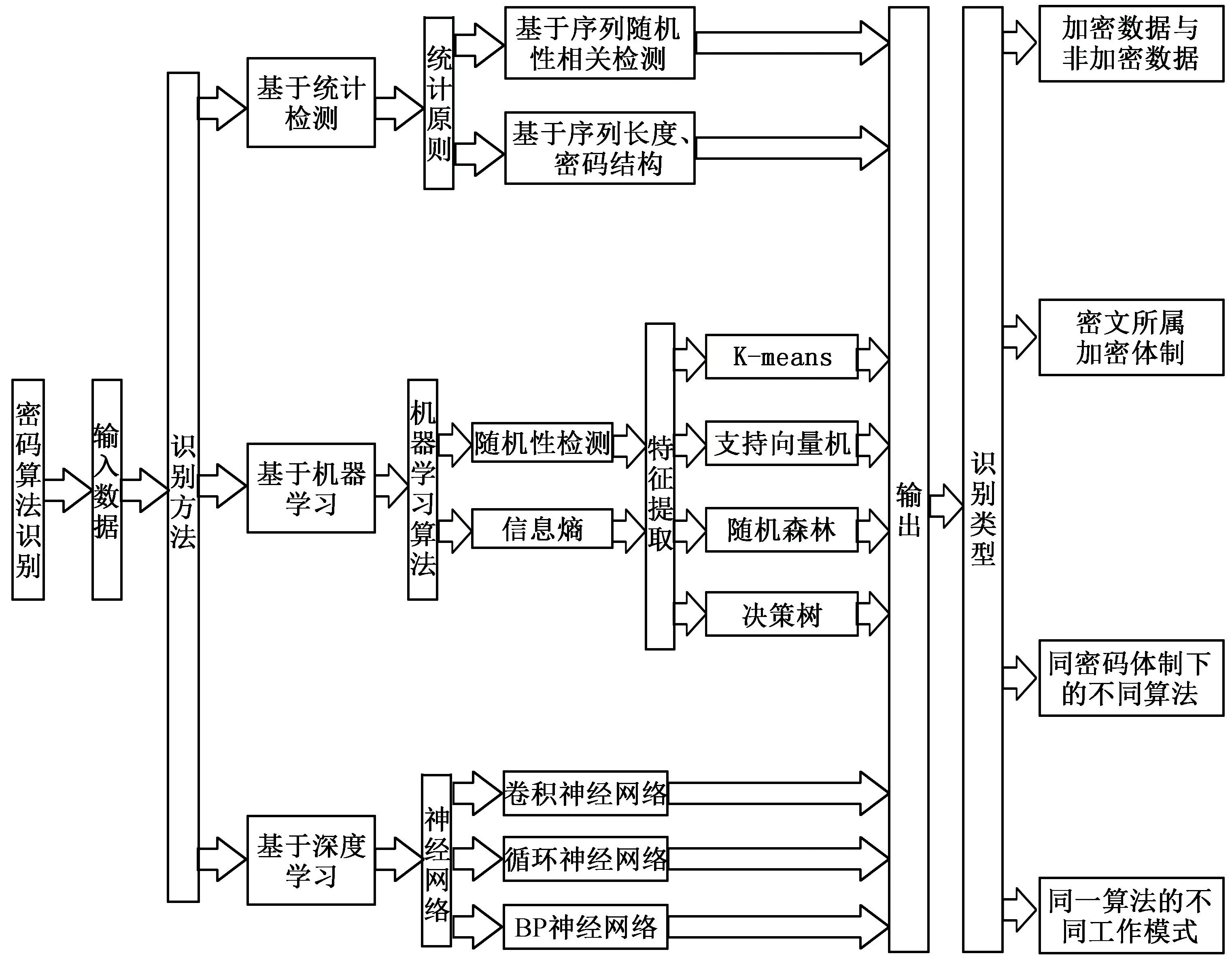
图1 密码算法识别研究内容
2.1 识别类型
2.1.1 加密数据与非加密数据
加密的本质是在传输过程中通过使用特定的加密算法对数据进行加密处理,由此产生的数据是人们无法辨识和篡改的密文。 密码算法识别首要工作是判断数据是否被加密,需分析密文数据区别于明文数据的特征[6],从密码学角度,经过加密得到的密文消除了统计特征,近似为随机数据。 文献[7] 基于NIST 随机性检测标准[8],统计了利用RSA 公钥密码、AES-ECB、IDEA-ECB、DES-ECB 加密后的密文与随机文件(未被加密)的随机性特征值,得出密文文件与未被加密的文件在频率检验、块内频数检验、非重叠模板检验、游程检验、近似熵检验与离散傅里叶变换检验上的特征分布存在着明显区别,即从随机性分布出发,可有效识别与区分加密数据和非加密数据。
2.1.2 密文所属加密体制
文献[9]中提出,针对密文,密码算法识别的第一步是根据密文特点识别密码体制,其中包含古典密码、序列密码、公钥密码、分组密码等,第二步识别具体密码算法。
公钥密码[10]主要有RSA、ECC、IBC 三类[11],针对RSA 我国没有相应的标准算法出台,而针对ECC 和IBC,我国分别发布了相应的SM2、SM9 标准算法, 典型公钥密码包括RSA1024、RSA2048、SM2、SM9;文献[9]提出的密码体制识别方案中包含Substitution、Permutation、 Triviu Sosemanuk、 Grain、 RC4、 AES、Camellia、DES、3DES、SM4、RSA、ECC 在内的13种密码算法,其中涉及古典密码体制、序列密码体制、分组密码体制、公钥密码体制。
根据研究,可以得出经过非对称密码体制和单项函数密码体制加密后的密文具有较明显的长度特征,因此专门针对公钥密码体制和单向函数密码体制识别的研究与对称密码体制识别的研究相比较少,其长度特征总结如表4 和5所示。

表4 公钥密码体制长度特征总结

表5 Hash 密码体制长度特征总结
2.1.3 相同密码体制下的不同算法
现有密码算法识别工作主要针对对称密码体制,该体制下主要包括分组密码与序列密码。针对分组密码,文献[12]选取AES、DES、3DES、IDEA、Blowfish、 Camellia 六种分组密码,基于随机性测试算法的提取方式与参数设置, 提出了一系列分组密码算法识别的新特征,输入随机森林算法中进行分类,得出基于随机性测试密文特征具有更低的维数的优势,在密码算法识别中具有一定的有效性。 文献[13]通过分割变换密文文件提取特征向量,利用支持向量机(SVM)算法作为分类器,实现在短密钥流场景下,对RC4、A5/1 和Trivium 三种序列密码的准确识别。
2.1.4 同一算法的不同工作模式
对于分组密码而言,工作模式是一项增强密码算法安全性或扩展算法应用场景的技术。 多次使用相同的密钥对多个分组加密,会引发许多安全问题。 为了应对不同场合,因而需要开发出不同的工作模式来增强密码算法的安全性。NIST(SP800-38A)定义了5 种“工作模式”。 其中电码本(Electronic CodeBook,ECB)、密文分组链接(Cipher-block Chaining,CBC)、密文反馈(Cipher FeedBack, CFB)、 输 出 反 馈(Output FeedBack,OFB)这4 种模式实际上覆盖了大量使用分组密码的应用[14]。 针对应用广泛的分组密码,密码算法识别研究主要集中于ECB 模式,但是很多密码应用场景更多地采用了CBC 或者与CBC 相关的模式。 因此,对分组密码工作模式的分类与识别也属于密码算法识别领域,文献[15]针对SM4 算法的四种模式,借助统计学方法与信息熵实现密文序列的特征提取。 利用决策树分类算法进行二分类识别与四分类识别,结果表明,该方法在二分类问题中表现稳定,准确率高达90%以上,而在四分类问题中,区分率在25%左右,与随机猜测准确率相近,识别准确率还有提升空间。
2.2 识别方法
从公开文献来看,总体上关于密码算法识别研究并不多见,现有方案主要针对分组密码开展相关研究,也取得了一些进展。 下面详细介绍现有的密码算法识别方法,并从技术路线、识别效果等方面进行对比分析。
2.2.1 基于统计检测的密码算法识别方法
在该方向研究初期,学者们较多利用统计检测的思想进行探索。 统计检测在分组密码安全性评估的过程中发挥着重要的作用,关于分组密码密文序列的统计检测初衷是通过将分组密码作为一个伪随机数发生器进行检测,以此判定分组密码输出序列是否拥有优秀的随机性能。 在密码算法识别任务中,利用统计检测发现不同分组密码密文的随机程度存在差异,从而判断密文所属的密码算法。 相关文献表明,随机性检测方法多达上百种,其中美国商务部国家标准技术协会(NIST)公布的2010 版SP800-22 标准中的15 种随机性检测算法(以下简称NIST 随机性检测)[8]最为典型。
文献[16]提出除了随机性相关统计检测外,还有一类统计检测方法与分组密码的分组长度、密码结构等有关,因此基于分组长度,将分组密码看作是一个随机的多输出布尔函数,将256个密文分组进行异或操作,统计其结果的汉明重量,进而通过期望值计算判断是否服从二项分布。 将此方法用于Rijndael、Camellia 和SM4 算法,统计结果表明,这3 种算法分别从第4 轮、第5 轮和第7 轮开始呈现出良好的统计性能,体现了3 种算法的在该统计检测方法中表现出的差异性。
2015 年,文献[17]通过统计密文比特流中比特0 与1 的频数、特定序列出现的频数及固定分块长度内比特1 出现频数,对比分析了不同分组密码算法密文统计检测值间的差异性,对AES、Camellia、DES 及3DES 等分组密码算法产生的密文提取其显著特征值,NIST 随机性检测中的“monobit test”、“runs test”这两个测度指标体现了该方法的核心思想。
2.2.2 基于机器学习的密码算法识别方法
在1990 年,从文献[18]中可以看到密码学家们已经开始思索密码学与机器学习两大领域的碰撞,并提出一些相关概念和结论[19]。 文献[20]探讨了机器学习应用于密码学的可行性。不同密码算法所产生的密文在统计特性上存在一定的差异﹐这些差异可以作为识别密码算法的重要依据。
在唯密文的情况下,基于密文特征的密码算法识别任务与机器学习相互结合,通过构建特征工程使密码算法识别的准确率和效率显著提高。基于机器学习算法的密码算法识别方法较多是在NIST 随机性检测的基础上设计实现的。 2006年,文献[21]将密文生成一个文档向量,利用支持向量机算法,对DES、3DES、AES、RC5 和Blowfish 这5 类算法进行识别。 2015 年,文献[22]选取码元频数统计检测值、游程频数统计检测值、块内频数统计检测值进行特征值分布分析,提出一种针对密文随机性的度量值,得出在相同样本量条件下,SM4 密文的随机性度量值取值个数均明显小于AES、Camellia、DES、3DES 密文的随机性度量值取值个数,然后采用K-means 聚类算法,对AES、Camellia、DES、3DES 进行识别,其识别准确率接近90%。 2017 年,文献[9]根据密码学常识,提出了针对密码算法识别任务中的分层思想,其思想是先对密文按照密码体制类别进行分类识别,继而再识别其具体密码体制,根据此思想设计双层密码算法识别方案,选取固定比特熵、固定字节熵以及固定序列出现的频率,作为簇分特征,采用最大熵和随机性测试作为单分特征。 对比传统单层识别方案,准确率提升20%左右。 2018 年,文献[23]结合NIST 随机性检测指标、信息熵、傅里叶变换对AES、DES、Camellia等11 种现代密码算法密文进行特征提取,引入支持向量机识别算法,在二分类问题中,对于区分度较高的密码算法如AES 、Camellia 可以达到接近80%的正确率,平均准确率约为60%。 在多分类问题中,也可以达到30%左右的准确率,高于随机猜测的准确率。 同年,文献[24]将密码分组长度视为分类不同分组密码算法和流密码算法的主要依据,将密文根据不同的分组长度分块,分别求每块的固定比特熵,固定字节熵,固定字节概率,将其作为分类算法的特征,并且引入Fisher 判别算法作为分类器,对分组算法和流密码算法的进行识别。
文献[25]针对CBC 模式下的分组密码算法分类进行研究,通过提取多个密文流中的第一个分组块,将其抽象为密码分组算法的特征,并使用支持向量机作为分类器,当密文文件大于100KB 时,对CBC 模式下AES、DES、3-DES、RC5、Blowfish 五种不同的分组密码算法的识别准确率达到了90%。 2019 年,文献[26]将密文按照字节进行划分,然后分别提取每一字节中的固定比特位组成新的密文,再将构造的密文按照字节划分,统计不同字符出现的频率作为密文识别的特征向量,使用随机森林作为分类器,对ECB 模式下 AES-128、AES-256、DES,3-DES、SM4、CAMELLIA-128、IDEA、Blowfish 八种不同的分组算法进行识别,识别准确率达到了87.9%。 同年,文献[27]在现有密码体制识别问题的定义系统[9]的基础上,通过对识别分类问题中的主要难点进行进一步分析,对特征提取过程的各环节进行形式化定义,并以此定义为基准,探究包含随机性检测、统计学中的熵、最大熵、基尼系数在内的不同特征的属性对识别分类准确率的影响,采用多种分类学习算法作为个体学习器并集成的方式进行分类识别,避免了单一分类算法误选导致模型的泛化性能不足。 实验结果表明,将熵作为特征提取函数的特征表现更稳定,且较文献[9]识别分类准确率提升6%-11%。
文献[28]将密文中的每个字符转码为十进制数,将这些数字构造成一维数组,得到这些一维数组之间的欧几里得距离。 然后我们将这些距离作为特征输入随机森林、逻辑回归和支持向量 机 中 对 DES、 3DES、 AES、 IDEA、 SM4、Blowfish、Camellia 七类分组密码进行识别,在略高于现有方法识别率的前提下,缩短了实验时间,降低了计算成本。 2021 年,文献[29]结合NIST 随机性检测中的组内频率检测、连续块测试和最长1 游程测度作为密文特征提取的方法,设计了主要针对SM4 算法体制识别方案。 通过使用RC4.5 决策树分类算法,SM4 与AES、3DES、Blowfish、Cast 五种算法之间的识别率在90%以上。
2.2.3 基于深度学习的密码算法识别方法
2021 年,文献[30]分别对文本、语音、图片形式的明文文件进行加密,后对密文按8bit 分块,并采用累计求和的方法将分块后的密文映射为二维的向量矩阵。 随后将得到二维向量通过固定卷积核的卷积网络,提取密文的卷积特征向量。 最终将该特征向量输入随机森林模型中,对AES、3DES、Blowfish 的识别准确率达到83%。同年,文献[7]同样基于NIST 随机性测试来构造密文的特征向量,首先对密文按固定大小分块,随后对每一分块进行包括频率检验、块内频数检验、非重叠模板检验、游程检验与近似熵检验在内的五种随机性测试,得到每块密文对应的测试结果。 将每一密文分块的随机性测试结果作为密文的二维的特征向量。 采用了CNN 和RNN 模型对密文特征进行训练,得到了较高的识别准确率。
2.3 密码算法识别方法总结
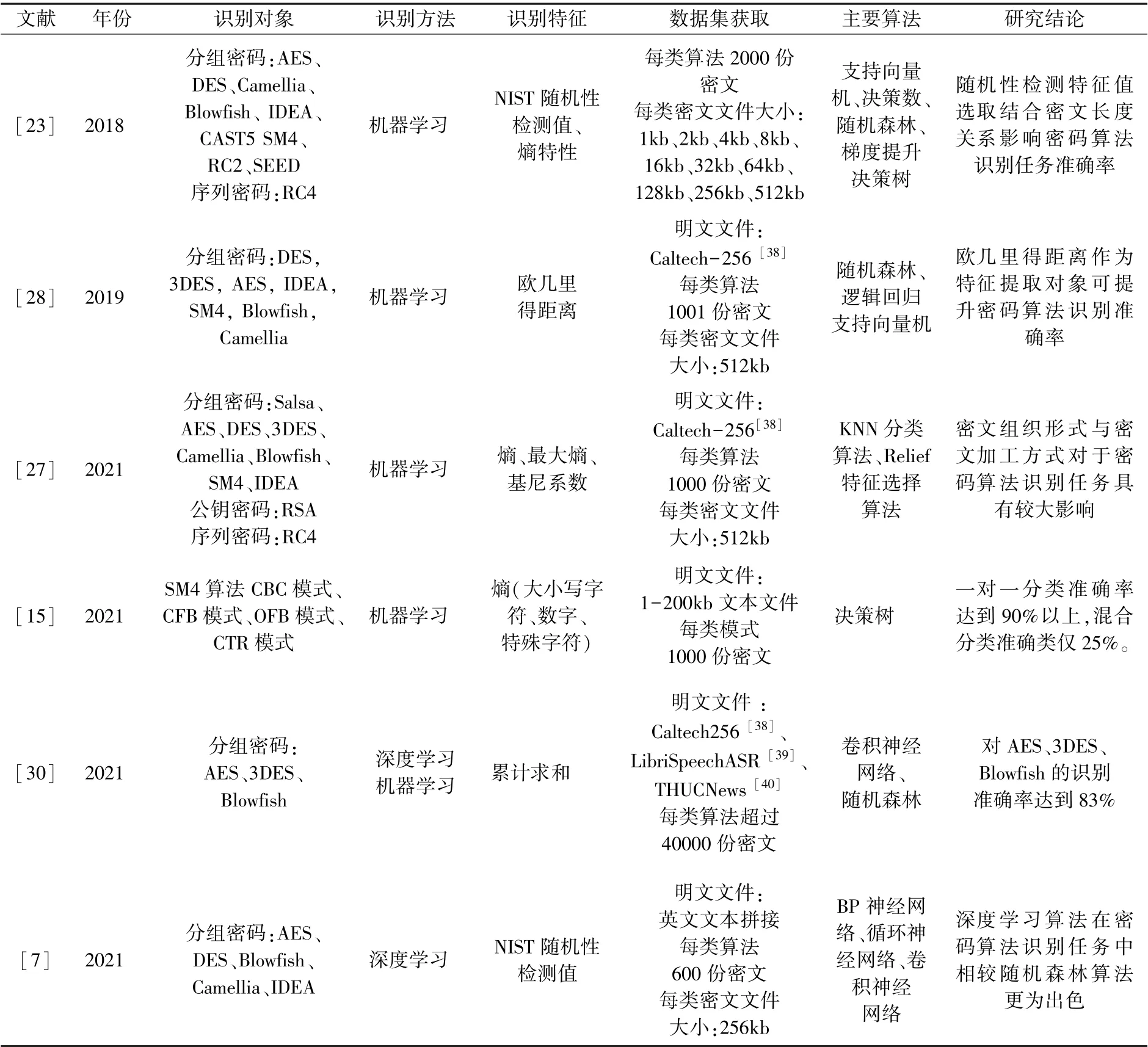
本文将上述密码算法识别方法从多个角度进行了对比分析,如表6 所示。

表6 研究方法概述
文献 年份 识别对象 识别方法 识别特征 数据集获取 主要算法 研究结论[23] 2018分组密码:AES、DES、Camellia、Blowfish、 IDEA、CAST5 SM4、RC2、SEED序列密码:RC4机器学习NIST 随机性检测值、熵特性每类算法2000 份密文每类密文文件大小:1kb、2kb、4kb、8kb、16kb、32kb、64kb、128kb、256kb、512kb支持向量机、决策数、随机森林、梯度提升决策树随机性检测特征值选取结合密文长度关系影响密码算法识别任务准确率[28] 2019[27] 2021分组密码:DES,3DES, AES, IDEA,SM4, Blowfish,Camellia分组密码:Salsa、AES、DES、3DES、Camellia、Blowfish、SM4、IDEA公钥密码:RSA序列密码:RC4机器学习 欧几里得距离机器学习 熵、最大熵、基尼系数明文文件:Caltech-256 [38]每类算法1001 份密文每类密文文件大小:512kb明文文件:Caltech-256[38]每类算法1000 份密文每类密文文件大小:512kb随机森林、逻辑回归支持向量机KNN 分类算法、Relief特征选择算法欧几里得距离作为特征提取对象可提升密码算法识别准确率密文组织形式与密文加工方式对于密码算法识别任务具有较大影响[15] 2021 SM4 算法CBC 模式、CFB 模式、OFB 模式、CTR 模式机器学习熵(大小写字符、数字、特殊字符)明文文件:1-200kb 文本文件每类模式1000 份密文决策树一对一分类准确率达到90%以上,混合分类准确类仅25%。[30] 2021分组密码:AES、3DES、Blowfish深度学习机器学习 累计求和明文文件:Caltech256 [38]、LibriSpeechASR [39]、THUCNews [40]每类算法超过40000 份密文卷积神经网络、随机森林对AES、3DES、Blowfish 的识别准确率达到83%[7] 2021分组密码:AES、DES、Blowfish、Camellia、IDEA深度学习 NIST 随机性检测值明文文件:英文文本拼接每类算法600 份密文每类密文文件大小:256kb BP 神经网络、循环神经网络、卷积神经网络深度学习算法在密码算法识别任务中相较随机森林算法更为出色
3 密码算法识别研究趋势与挑战分析
3.1 主要问题
通过上述对密码算法识别现状的研究与分析,当前密码算法识别通过机器学习等方法取得了一些研究成果,但仍存在一些问题尚未解决。
a) 相较于其他领域的识别任务,评价指标尚需完善。 本文在章节1“密码算法识别技术评价指标”中介绍的密码算法识别技术评价指标,与图像分类、文本分类等成熟分类领域相比,仍需继续完善。 未识别率是计算不属于已知类型的样本占总样本数目的比率,以此反映识别方法对未知类型样本的识别能力。 现有密码算法识别方法都是对某几种特定密码算法进行识别,缺少未知算法的加入,因此无法统计未识别率。
另外,识别任务的显著特点之一就是需要具有高时效性,密码算法识别尚处于起步阶段,在引入机器学习或深度学习后,构建复杂的密文特征工程需要耗费大量的存储空间和计算能力,例如对于诸多文献中采用的NIST 随机性检测,本文利用该工具包对不同大小的密文文件进行检测,检测所耗费的时间如图2 所示。 在图2 中,检测64kb 以内文件所需的检测时间在1 分钟之内,但文件超过64kb 之后的检测时间急剧上升,仅检测一个大小为500kb 的文本文件就耗时接近10 分钟,对于上万条加密数据,所需时间倍增。 从长远来看,通过牺牲时间复杂度来提升识别准确率是不现实的,因此时间复杂度指标也是密码算法识别任务中的关键衡量指标。

图2 密文随机性检测时间统计
b)数据集不公开。 根据文献查阅,还没有发现通过密文识别加密算法的公开研究,现有文献都是在自己制作的数据集明文(图片、语音、文本)上研究实现,使用的加密工具主要有OpenSSL、GmSSL 与Crypto++ 密码算法库。 算法或方案的评估需要当前最新的数据集,任何一种密码算法识别方案的比较又需要相同的数据集,相同的数据集则需要使用同样的加密工具,但目前没有公开的密文数据集和统一的数据标记方法。
c)模型泛化性差。 泛化性指模型适应新数据的能力,即模型在从未见过的数据面前,仍然保持一定适用性的能力。 当前方法识别的对象都是主流密码算法,在文献[31]中也对Grain-128 算法识别进行了专门的研究然而随着各领域个性化需求的变化,小众的密码算法[32][33]层出不穷,因此针对这些未知类型的密码算法,现有模型还无法对此进行识别。
3.2 识别准确率影响因素
a)是否固定密钥及盐值因素。 现有的密码算法识别方案中,例如文献[34]中当训练和测试密文样本的密钥相同时,识别准确率相对较高,但在实际环境下,训练样本的密钥与测试样本的密钥会有所不同。 此外,在密码学中,通过在密码任意固定位置插入特定的字符串,让散列后的结果和使用原始密码的散列结果不相符,这种过程称之为“加盐”[35]。 例如在使用OpenSSL对文件进行加密时,若不表明“-nosalt”,密钥会产生变化,因此影响识别准确率。 在现有方案中尚未对是否“加盐”进行分析和论述。
b)密文长度。 文献[15]中设置不同长度的密文作为实验样本,证明了密文长度对密码算法识别具有一定影响,但到达一定临界值后,准确率不再随密文长度增加而提高,这一临界值取决于密码算法本身。
c)分组密码工作模式。 在密码算法识别研究初期,针对分组密码的研究较为宽泛,没有对工作模式进行特别说明,大多文献都默认使用分组密码ECB 模式进行加密获得密文样本。 引入机器学习技术后,则以密文字节序列的分布随机性作为基础构建差异特征模型,但大多仅对DES、 3DES 等老旧密码算法、ECB 及CBC 等简单加密工作模式进行分类[36]。 然而以SM4 算法为例,本文通过比较其随机性特征值分布,可以明显发现,CBC 模式随机性明显优于ECB 模式,说明ECB 模式下的密文相较于CBC 模式下的密文更容易被识别。 除了CBC 模式,分组密码CFB 模式、OFB 模式同样具有优秀的随机性,因此对密码算法识别准确率带来较大影响。 本文对现有文献中涉及分组密码工作模式进行总结见表7。

表7 针对分组密码工作模式总结
3.3 未来工作展望
3.3.1 深度学习技术的应用
现有密码算法识别方法大部分采用经典的机器学习算法,较高的识别准确率依赖于人工提取并构建的特征工程,耗时费力且十分复杂。 相比之下,基于神经网络的深度学习不再依赖于人为的特征提取,而是通过卷积层等模块自动提取训练集中的数据特征。 作为机器学习的一个重要分支,深度学习已经在数字图像处理[41]、情景分析[42]、机器翻译[43]、语音识别[44]等领域显示出优越的性能,也证明其在提取特征方面[45]具有独一无二的优势。 利用深度学习技术对大量未知数据进行细粒度层次提取特征并高效分类是当下各领域的热点研究内容。
本文选择CNN 模型对SM4 算法四种工作模式下的密文进行识别分类,该模型由输入层、卷积层、池化层、全连接层以及输出层这5 部分组成。 识别流程如图3 所示,训练集与样本集分布见表8,实验结果见表9。
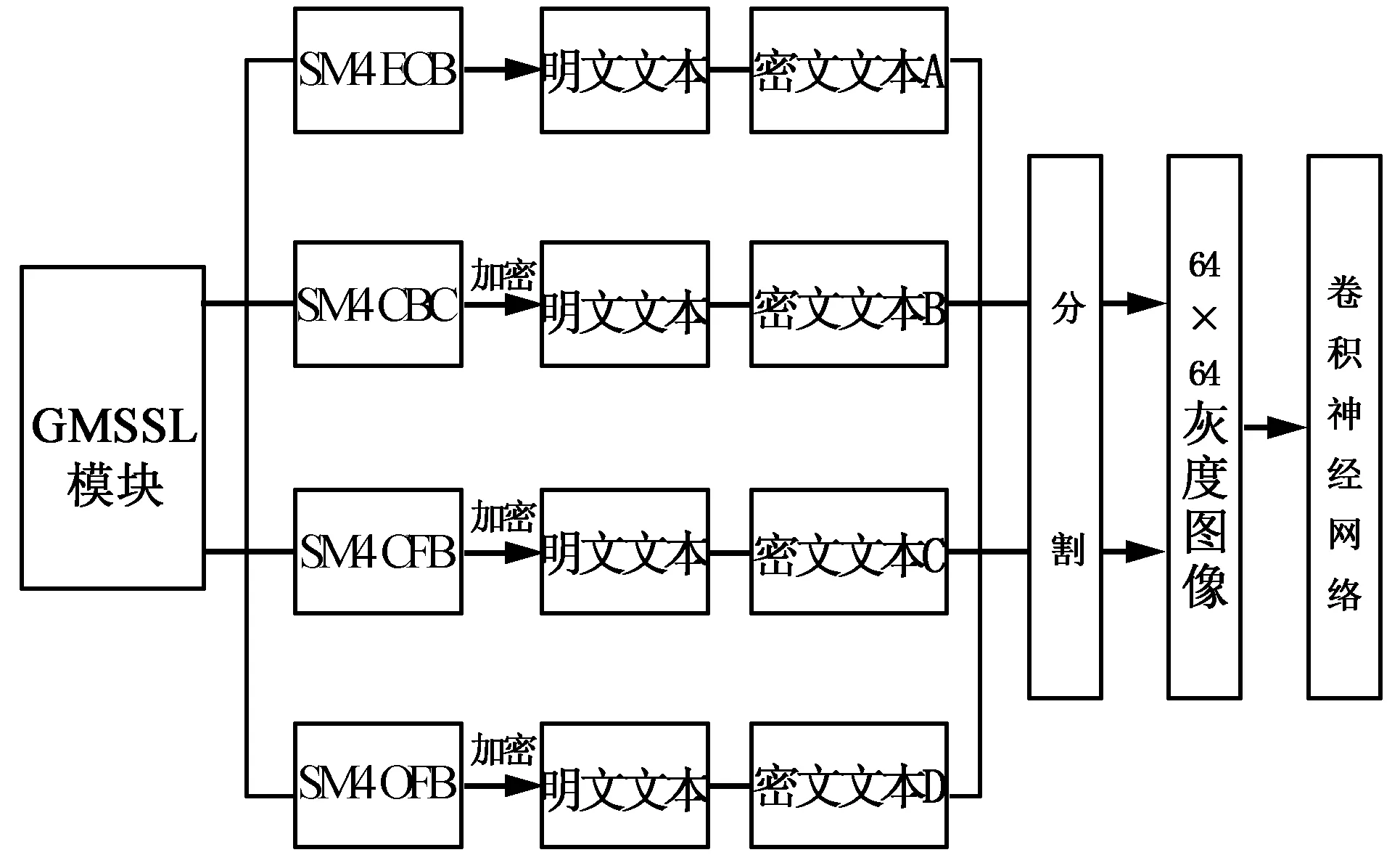
图3 识别流程图
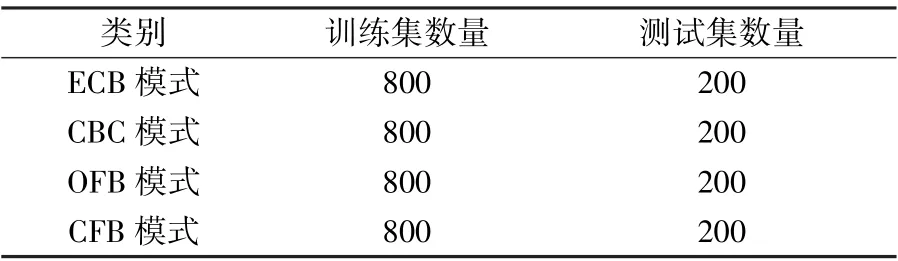
表8 训练集与测试集分布
如表9 所示,通过改变训练迭代次数,该卷积神经网络模型在训练迭代120 轮过程中出现最高准确率53.6%,显著优于随机猜测值25%,从总体结果可以看出,将密文转换为灰度图后,采用深度学习的方法,可以更好的提升在SM4四种工作模式下的密文四分类问题中的准确率。文献[7]与上述利用二维卷积神经网络对SM4算法四种工作模式下的密文分类实验为深度学习在密码算法识别中的应用提供了理论基础与应用价值。 此外,文献[46]通过构建神经网络,实现MARS、RC6、Rijndael、Serpent 和Twofish 这五类密码算法在ECB 模式下的正确分类,得出在密码生成的底层数学运输中存在固有的特性,这些特性在密文中留下了痕迹,通过神经网络提取深层次特征,实现分类,体现了将深度学习应用于密文特征提取和密码算法识别的研究中的可行性。 2021 年,彭波等人[47,48]通过深度学习技术,采用LeNet5 神经网络[49]对密文文件提取特征并形成密文特征映射矩阵,后分别利用随机森林算法和支持向量机算法进行分类识别。 未来可使用不同模型应用于该类问题之中,将深度学习与机器学习相结合,选择合适的神经网络提取密文样本更深层、 更有效的识别特征,提升识别的精度与效率,这也是下一步研究的趋势。

表9 实验结果
3.3.2 规范数据处理
通过对现有密码算法识别方法数据获取及处理的部分进行对比,首先未对加密前的文件类型进行规定,存在图片、文本、语音等各种形式的明文,在处理时,总体来看有两种方法,第一种是将切割后的大量明文文件批量加密获得等量的密文文件作为数据集,第二种则是将较大的明文加密后根据所需密文的大小进行切割从而获得数据集。 第二种方式在切割时仅考虑文件大小,而未考虑密文包含的语义信息,上下文信息缺失导致语义损失[50],分割结果类内一致性较差,影响下一步的特征提取。 本文以文件信息熵为例,从THUCNews、LibriSpeechAS、Caltech256 三类数据集中分别选取1000 条文本、语音、图片文件,对所选文件进行SM4-CBC 加密,得到3 组明密文件,对这6000 份文件统计16 进制下的信息熵,部分结果如表10 所示。 信息熵反映的是信息的混乱程度,从明文角度来看,文本类文件信息熵明显偏小,图片类文件信息熵接近临界值,语音类文件信息熵较文本类文件偏高,但有较大起伏,无明显规律。 从整体来看,所有类型文件经过加密过程,信息熵均增大,变得更“混乱”了,印证了前文所述经加密得到的密文消除了统计特征,近似为随机数据。 从表中数据看出,不同文件类型经过加密后,信息熵增加的幅度不同,因此探究明文文件类型和数据集切割方式对识别准确率的影响也是一个研究重点。
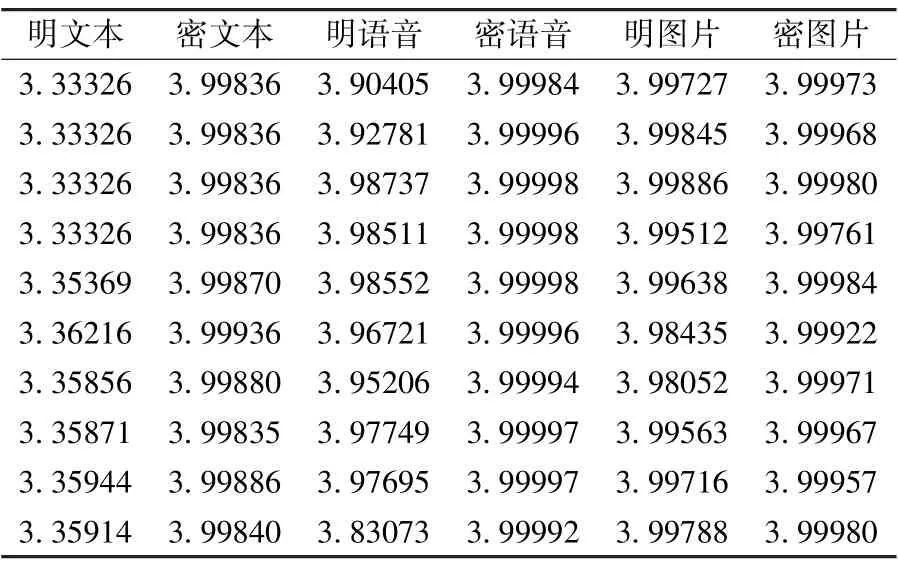
表10 文件信息熵
3.3.3 探索新的密文组织形式和特征提取方法
首先,现有密文特征提取研究主要集中在随机性检测和熵相关特征,这些特征在研究中显然已经遇到了瓶颈。 虽然现有文献可以以较高的识别率(90%以上)识别某些密码算法,在复杂的混合密文情境下,平均识别率大都不高,仅稍高于随机猜测的准确率。 此外,NIST 随机性检测中个别检测值对文件大小有要求,因此针对较短的密文序列识别必须探索新的特征提取方案。例如,文献[51]和[52]提出随机性测试新方案,这也可作为密文特征提取方法进行深入研究。其次,特征提取的关键就是密文数据得到高效的预处理,现有密文组织形式包括2 进制、10 进制序列与ASCII[53]码,因此未来尝试将密文转换为图片、语音等不同组织形式和引入先进的人工特征选择算法[54-57],可以为特征提取提供新的思路。
3.3.4 分层识别方案与算法结构的深入研究
文献[9]证明在密码算法识别任务中采用分层方案[57]与集成学习技术可以有效提高准确率。 下一步通过多种方法集成[58]的多层分级框架逐步实现密码算法精细化识别,增加方案的适用性、稳健性和普遍性同样是值得研究的重点。针对分组密码密文特征提取,可以尝试从密码学的角度出发,利用其算法本身不同的结构,分析密文特征,文献[59]证明了不同算法结构之间存在密文特征分布上的差异性,七类常见分组密码结构如表11 所示,未来可针对特定结构算法展开进一步识别与研究。

表11 分组密码算法结构
4 结束语
随着信息技术和密码技术的飞速发展与融合,使得密码算法识别研究难度日益加剧,但密码算法识别的研究对于密码系统进行分类和检测以及评估密码系统的安全性具有重要的意义。 密码算法识别一方面是为了验证密码算法抗攻击能力,另一方面也是为了对密码设备进行监管,现有方案的样本均为各类密文文件,而在现实生活中,密文包裹在各类网络协议数据包进行传输,较密文文件长度更短,并且要求实时高效,因此需要结合加密流量分析领域相关内容进行研究。 本文基于现有密码算法识别经典方案方法,聚焦特征提取、特征选择等方面,分析并阐明现有方法的特点及未来发展方向,希望能为进一步开展密码算法识别研究的同仁提供参考。
猜你喜欢
保健医苑(2022年4期)2022-05-05
黑龙江大学自然科学学报(2022年1期)2022-03-29
计算机仿真(2021年10期)2021-11-19
学与玩(2018年5期)2019-01-21
中国科技纵横(2016年20期)2016-12-28
通信技术(2016年10期)2016-11-12
信息安全与通信保密(2016年10期)2016-11-11
语文世界(小学版)(2016年9期)2016-09-14
通信电源技术(2016年5期)2016-03-22
微型小说选刊(2015年5期)2015-06-05
