
基于随机森林与合成分析法建立脂肪肝合成预测模型
2022-03-02 00:25:26李运明
甘肃科学学报 2022年1期
雷 丽,李运明
(1.西南交通大学数学学院,四川 成都 611756;2.西部战区总医院卫勤部医疗管理科,四川 成都 610083)
近年来,脂肪肝发病率不断升高,发病年龄也日趋年轻化,成为仅次于病毒性肝炎的第二大肝病,严重威胁国人健康。脂肪肝临床表现轻者无明显症状,重者可能会演变成严重肝病(如肝硬化,肝癌)。但脂肪肝属可逆性疾病,所以预测脂肪肝发病风险,提早发现并及时治疗通常可恢复正常。目前已有部分学者尝试将各种预测模型运用到脂肪肝危险因素分析当中,如陈霆等[1]利用随机森林法预测2型糖尿病合并非酒精性脂肪肝;余秋燕等[2]比较了5种常见机器学习算法预测脂肪肝分类的效果,得出决策树模型准确率最高的结论。相关研究进一步比较了随机森林与决策树模型对脂肪肝危险因素的筛选能力,如Samsa等[3]提出根据多个数据源创建多变量风险模型的新方法;Hu等[4]初步尝试将这种方法运用到慢性病预测中,建立了冠心病预测模型;Zhou等[5]在2009年首次提出合成分析法的概念,建立具有连续结果的合成分析回归模型;米生权[6]基于合成分析法建立了糖尿病发病风险预测模型;石福艳[7]利用合成分析法拟合了高血压预测模型。合成分析法是在多个单变量回归模型基础上,根据变量之间的联系,整合建立多变量回归模型的方法。它可以解决因数据不完整而不能得到有效模型的困境。研究从脂肪肝发病率的变化趋势入手,基于决策树模型与合成分析法建立脂肪肝合成预测模型,为脂肪肝易发人群健康管理及风险评估提供了参考依据。
1 资料与方法
1.1 资料来源
数据源自2006—2016年在西部战区总医院(原成都军区总医院)健康体检中心定期健康体检人群的体检数据,并循证医学文献资料检索结果、临床指南等。2006年体检数据记为数据集1,2007—2016年连续10年体检数据记为数据集2。
1.2 变量判断标准与赋值情况
研究共纳入23项体检指标作为研究变量,变量名称、单位及赋值情况[8-10]详情见表1。

表1 变量判断标准与赋值情况
1.3 统计学方法
采用SPSS 18.0与Python 3.8统计软件进行数据分析,用Kolmogorov-Sminov检验连续变量的正态性,符合正态分布或近似正态分布用均数±标准差描述。根据Levene's方差齐性检验结果,组间均数比较采用成组t检验。分类变量采用频率和百分比来描述,组间比较采用χ2检验。数据集1为训练集,数据集2为验证集。
以准确率比较随机森林、Logistic回归、决策树、人工神经网络4种方法筛选脂肪肝危险因素的能力,以ROC曲线下面积(AUC)评价脂肪肝合成预测模型与传统 Logistic回归模型、Cox比例风险模型的预测性能,P<0.05为差异有统计学意义。
2 结果
2.1 调查对象基本情况
2006—2016年各年度参检人数分别为3 049人、2 797人、2 760人、2 804人、1 921人、2 002人、1 732人、1 821人、1 809人、1 757人、1 654人,连续11年总参检人次数24 106人,其中男性21 777人次(90.34%),女性2 329人次(9.66%)。研究人群最小年龄34岁,最大103岁,平均年龄(67.79±12.90)岁。2006—2016年脂肪肝的检出率分别为15.10%、18.40%、20.40%、19.50%、21.10%、23.30%、23.60%、30.10%、27.50%、24.00%、29.30%,呈逐年攀升趋势。数据集1中共3 049人,其中男性2 770人(90.8%),女性279人(9.2%);年龄≥65岁1 824人(59.8%),年龄<65岁1 225人(40.2%)。
2.2 脂肪肝检出率在不同年龄、性别分布情况
数据集1中脂肪肝检出459例(15.1%),其中男性433例(15.6%),女性26例(9.3%)。不同年龄、性别人群中脂肪肝的分布情况见表2。由表2可知,男性脂肪肝检出率大于女性(χ2=7.899,P<0.05)。年龄≥65岁234例(12.8%),年龄<65岁225例(18.4%),年龄≥65岁人群脂肪肝检出率小于年龄<65岁人群(χ2=17.578,P<0.001)。年龄<65岁组内,男性脂肪肝检出率依然高于女性;年龄≥65岁组内,男女之间脂肪肝检出率无显著差异(χ2=0.000 8,P=0.928)。既往研究表明年龄是脂肪肝患病的危险因素[11],而此次研究高龄组脂肪肝检出率却比非高龄组低,这是因为69岁前脂肪肝患病率随年龄升高,70岁以后反而降低[12]。
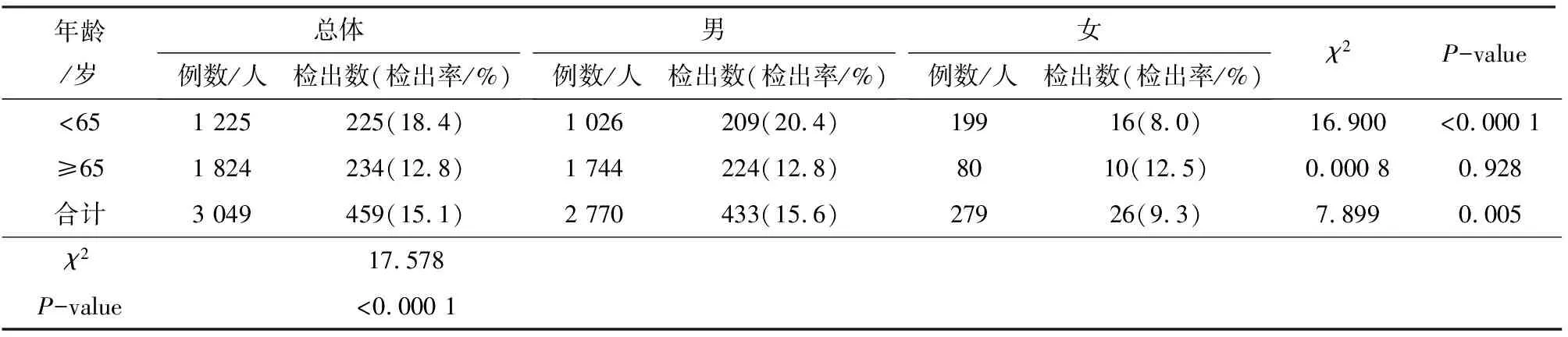
表2 脂肪肝的检出率在性别年龄之间比较结果
2.3 脂肪肝影响因素筛选
以是否检出脂肪肝为因变量,以性别、年龄、高血压、血红蛋白、总胆红素、谷丙转氨酶、空腹血糖、甘油三酯、总胆固醇、高密度脂蛋白、低密度脂蛋白、血尿酸、体重指数、白细胞、白球比、癌胚抗原、甲胎蛋白、血小板、总蛋白、白蛋白、尿素氮、血肌酐是否异常为自变量(见表1)。用随机森林算法、Logistic回归模型、BP人工神经网络、决策树模型4种方法分别基于数据集1进行变量筛选,比较筛选效果。
首先用随机森林算法进行脂肪肝影响因素筛选。随机森林算法属于集成算法的一种,若使用KNN或线性分类器等作为随机森林的基分类器,这些基分类器自身模型比较稳定、方差小,集成采样导致模型不容易收敛,会增大偏差。相比之下,决策树模型的特征分支自带随机性,可以更好地整合样本的权重。此外,其学习能力和泛化能力可以通过调节树的层数结构进行调整,从而减小偏差和方差,解决过拟合和欠拟合的问题。所以研究以CART决策树作为基分类器。将数据集1导入Python软件,用随机森林算法对训练集进行训练,得到的学习曲线如图1所示。

图1 随机森林的学习曲线Fig.1 Learning curve of random forest
学习过程中使用均匀抽样,每个样本权重一致,每个基分类器权重相等。参考学习曲线,再利用网格搜索将随机森林的参数进行调整。最终确定最优参数组合为:基分类器数量为13,基分类器最大分类深度为5,此时准确率达到最高,为84.8%。
Logistic回归模型筛选变量时,先进行单因素Logistic回归,再将具有统计学意义的脂肪肝影响因素纳入多因素 Logistic 逐步回归分析(进入α=0.05,移出α=0.1)。模型有统计学意义(χ2=366.059,P<0.001)。利用Logistic回归模型进行变量筛选的结果见表3,表3中OR值为该因素相对于参照水平的优势比。经过Wals检验,当P<0.05时,该因素作为脂肪肝影响因素具有统计学意义。最终筛选出脂肪肝影响因素及其OR(95%CI)值为:年龄0.532(0.404~0.700)、谷丙转氨酶2.183(1.528~3.118)、空腹血糖=1(1.881(1.297~2.728))、空腹血糖=2(2.208(1.518~3.210))、甘油三酯=1(1.461(1.035~2.064))、甘油三脂=2(2.850(2.096~3.875))、血尿酸1.925(1.426~2.597)、体重指数=1(3.529(2.592~4.803))、体重指数=2(9.199(5.923~14.286))、白细胞0.505(0.292~0.875)。

表3 Logistic回归模型变量筛选结果
其次用决策树模型进行脂肪肝影响因素筛选。以是否检出脂肪肝为目标变量,表1中所有自变量为输入变量,采用CRT增长方法筛选脂肪肝影响因素(拆分α=0.05;合并α=0.05)。决策树模型中父节点最少样本个数设置为50,子节点最少样本个数设置为20,建立树模型如图2所示。图2中显示:CRT树形生成11个节点,最大生长深度4层。第1、2层都是体重指数,说明超重、肥胖与脂肪肝患病风险关联性最强;第3层为谷丙转氨酶、年龄;第4层为甘油三酯。决策树模型筛选出脂肪肝影响因素与多因素Logistic回归筛选出的前四位一致,不同的是决策树模型更加强调谷丙转氨酶异常对脂肪肝的影响作用。

图2 脂肪肝CRT树形图Fig.2 CRT tree diagram of fatty liver
最后用人工神经网络筛选脂肪肝影响因素。将表1中所有自变量设为输入变量,是否检出脂肪肝设为输出变量,采用包含1个隐含层的3层BP神经网络筛选脂肪肝影响因素。结果显示脂肪肝影响因素按重要性排列依次为:体重指数、甘油三酯、空腹血糖、谷丙转氨酶、血尿酸、年龄、白细胞、性别等。人工神经网络筛选出被决策树模型忽略掉的性别因素,体现出它筛选全面的独特优势,同时也意味着人工神经网络存在过拟合的风险。
由于人工神经网络无法进行交叉验证,所以从数据集1中随机选择1 163例作为训练集,555例作为测试集,208例作为防止过拟合的验证集(6∶3∶1)。4种方法在训练集上筛选脂肪肝影响因素的准确率分别为84.8%、83.4%、82.2%、84.1%,在测试集上筛选的预测准确率分别为88.0%、83.3%、86.0%、83.9%,检验结果与训练集结果差别不大,随机森林准确率最高。筛选变量的标准是模型中变量重要性大于0.02,经过4种不同模型筛选后,变量重要性排序的前七位见表4。

表4 4种分类方法筛选变量重要性排序
根据4种模型得到了脂肪肝患病的主要危险因素有:体重指数、谷丙转氨酶、甘油三酯、空腹血糖、血尿酸、年龄、高血压等,这为脂肪肝合成预测模型指标的选择提供了重要的线索。
2.4 建立脂肪肝合成预测模型
由于纵向数据队列比横断面数据多包含时间信息,目前已有很多医学领域研究[13-14]基于纵向数据开展(在实际情况中,纵向数据往往需要数年随访,数据来之不易)。当缺少纵向数据时,采用合成分析法将不同数据集的数据纳入同一模型,既减少之前研究资料的浪费,又获得更多数据信息。合成分析法可以解决变量间共线性问题[3],同时估计参数的方差[5]。Elisa等[15]在已有的合成分析模型基础上,提出了将合成分析法用于建立Logistic回归预测模型的新思想。研究采用这种新方法建立了脂肪肝合成预测模型。
除了从数据集1中筛选出的影响因素外,大量饮酒[16]、荤食[17]等也是导致脂肪肝患病的重要影响因素,补充变量的赋值情况为:饮酒(否=0,是=1);谷草转氨酶(AST)(正常=0,异常=1);糖尿病(否=0,是=1);过度荤食(否=0,是=1);谷氨酰转肽酶(GGT)(正常=0,异常=1);胆结石(否=0,是=1)。
将数据研究结果(见表3)结合文献资料,最终确定纳入脂肪肝风险合成预测模型的变量见表5。
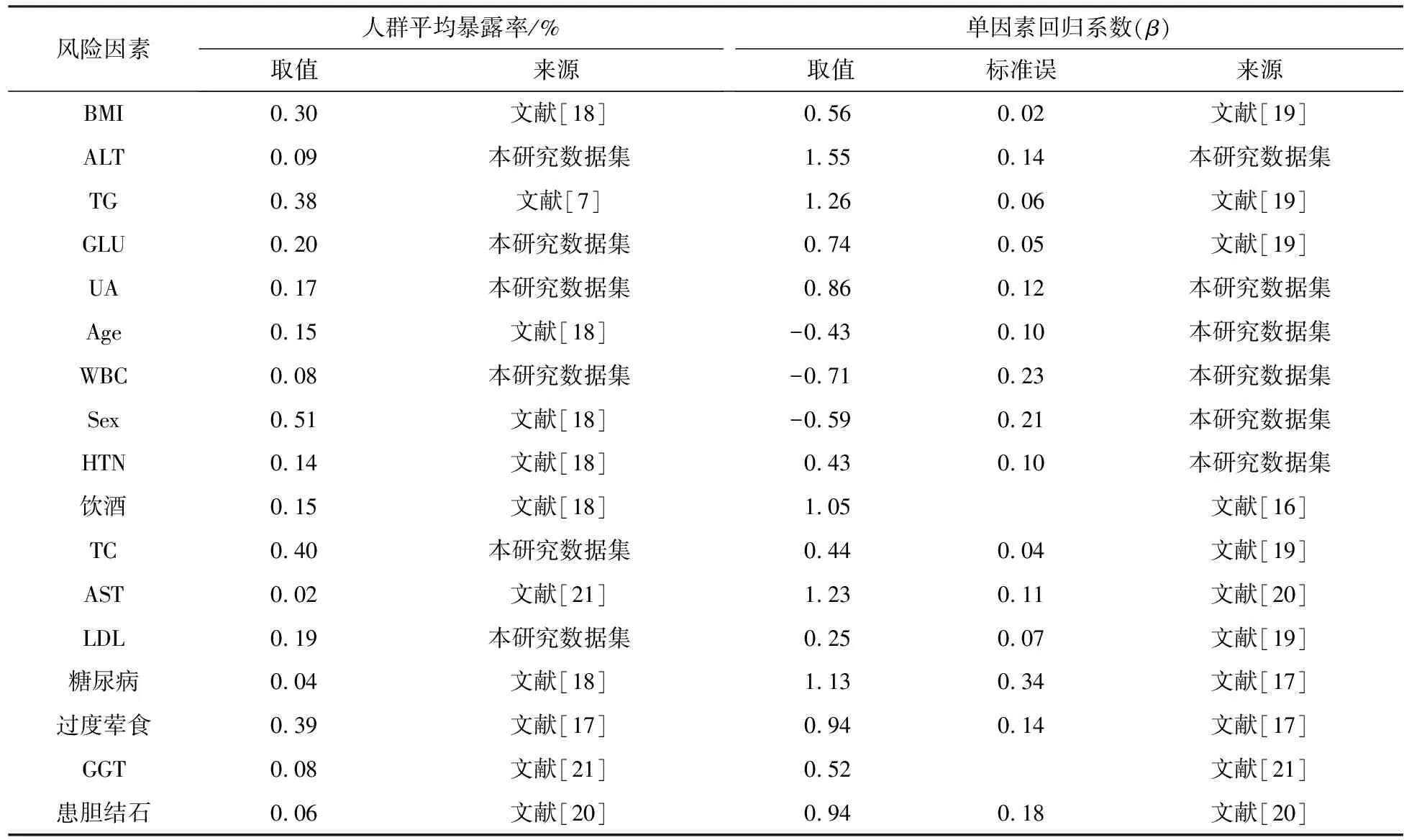
表5 纳入脂肪肝合成预测模型的变量回归系数取值及来源情况
首先根据年龄与疾病的关系,构建出基础方程D1:
D1=LogitP=-1.492-0.425×Age,
其中:P为脂肪肝患病的概率;Age是表1中的年龄变量(岁)。在D1的基础上逐步纳入其他变量,脂肪肝合成预测模型的构建过程见表6。

表6 脂肪肝合成预测模型构建过程
2.5 脂肪肝合成预测模型评价结果
以数据集2为测试集,绘制了Cox比例风险模型、Logistic回归模型和脂肪肝合成预测模型的ROC曲线对比图,如图3所示。

图3 3种模型的ROC 曲线对比Fig.3 ROC curve comparison of the three models
3种模型的ROC曲线下面积和约登指数对比情况见表7。表7分析了3种模型处理纵向数据的预测性能。Logistic回归模型ROC曲线下面积为0.732,约登指数0.340,灵敏度0.589;Cox比例风险模型ROC曲线下面积0.681,约登指数0.269,灵敏度0.503;脂肪肝合成预测模型ROC曲线下面积0.710和约登指数0.330,介于前二者之间,灵敏度0.639,是3个模型中最高的。

表7 3种模型ROC曲线下面积和约登指数对比情况
作为脂肪肝预测模型,为了更大概率判断出脂肪肝患者,可以适当牺牲准确率而提高灵敏度。脂肪肝合成预测模型不但具有优于传统纵向数据分析模型的预测能力,而且在缺少纵向数据时,它还可以提供有效的脂肪肝预测方法。
3 讨论
研究对决策树模型与合成分析法在脂肪肝预测模型构建中的应用过程进行探讨。随机森林、Logistic回归模型、人工神经网络、决策树模型4种方法筛选脂肪肝影响因素的准确率分别为88.0%、83.3%、86.0%、83.9%,随机森林的准确率最高,决策树模型准确率排在第2位。决策树能处理变量间的复杂联系,当需要引入自变量的高次项或交互项时优势明显,这与余秋燕等[2]研究结果一致。研究筛选出的因素结合文献资料,最终以超重或肥胖(BMI)、谷丙转氨酶(ALT)、甘油三酯(TG)、空腹血糖(GLU)、血尿酸(UA)、年龄(Age)、白细胞(WBC)、高血压(HTN)、饮酒、总胆固醇(TC)、谷草
转氨酶(AST)、低密度脂蛋白(LDL)、糖尿病、过度荤食、谷氨酰转肽酶(GGT)、患胆结石,共16个变量纳入脂肪肝合成预测模型,得到脂肪肝合成预测模型表达式为
LogitP=-1.492-0.425×Age-0.735×(Sex-
0.09)+0.511×(BMI-0.5)+1.358×
(ALT-0.09)+1.069×(TG-0.33)+
0.427×(GLU-0.2)+0.524×(UA-
0.17)-0.464×(WBC-0.08)+0.251×
(HTN-0.29)+1.048×(饮酒-0.147)+
0.212×(TC-0.4)+1.234×(AST-
0.02)+1.134×(糖尿病-0.035)+0.935×
(荤食-0.39)+0.516×(GGT-0.0836)+
0.936×(胆结石-0.065)+0.247×
(LDL-0.188),
其中:P是脂肪肝患病的概率,各原始变量的单位及赋值情况见表1,补充变量赋值情况为:饮酒(否=0,是=1);谷草转氨酶(AST)(正常=0,异常=1);糖尿病(否=0,是=1);过度荤食(否=0,是=1);谷氨酰转肽酶(GGT)(正常=0,异常=1);胆结石(否=0,是=1)。
既往学者基于合成分析法拟合的冠心病风险评估模型[4]、高血压预测模型[7]与传统 Logistic 回归模型的 ROC 曲线下面积相比差别都很小(约为0.001)。研究中,数据集2测试结果显示,脂肪肝风险等级指数ROC曲线下面积0.710,优于Cox比例风险模型(0.681),与Logistic回归模型ROC曲线下面积0.732仅相差0.022,与既往研究结果基本一致。此外,脂肪肝合成预测模型灵敏度0.639,是3个模型中最高的。综上可知,合成分析法基于横断面数据,充分利用既往学者的研究成果,建立简洁有效的脂肪合成预测模型,为其他慢性病风险评估研究提供了新思路。
合成分析法的优点是变量可来自不同数据集,并且一定程度上解决变量之间共线性问题,但在确定减数中心和系数来源选择时,存在人为主观成分,可能会产生选择偏倚。所以应秉承尽量可靠的原则,降低选择偏倚。不同统计学建模方法各有其利弊,应根据实际情况,将多种建模方法结合使用。
猜你喜欢
中老年保健(2022年5期)2022-11-25 14:16:14
中老年保健(2022年1期)2022-08-17 06:14:08
防爆电机(2022年4期)2022-08-17 05:59:06
保健医苑(2021年7期)2021-08-13 08:47:54
家庭医学(下半月)(2020年7期)2020-08-24 07:47:04
成都信息工程大学学报(2019年3期)2019-09-25 08:31:20
电子制作(2018年16期)2018-09-26 03:27:06
中国交通信息化(2017年9期)2017-06-06 07:14:54
中央民族大学学报(自然科学版)(2016年4期)2016-06-27 08:06:04
项目管理技术(2016年8期)2016-05-17 05:39:14
