
融合注意力机制的QRNN语音增强方法
2022-03-01 04:55:46娄迎曦袁文浩时云龙胡少东
山东理工大学学报(自然科学版) 2022年3期
娄迎曦,袁文浩,时云龙,胡少东
(山东理工大学 计算机科学与技术学院, 山东 淄博 255049)
语音作为生活中传递信息的重要载体之一,倘若受到噪声的干扰会严重影响对目标语音的获取。语音增强作为信号处理中的关键技术,旨在提高语音信号的质量和可懂度、舒适度[1]。传统的语音增强方法有谱减法[2-3]、维纳滤波法[4]等,在假设噪声是平稳的条件下对含噪语音进行增强,对非平稳的噪声抑制能力较差。
随着深度学习技术的不断发展,研究人员开始将深度学习应用到语音增强任务。文献[5]通过深度神经网络(deep neural networks,DNN)学习含噪语音和纯净语音之间的非线性关系,以语音的对数功率谱特征(logarithmic power spectra,LPS)作为网络的输入和训练目标,相比传统的语音增强方法显著提高了语音增强性能。文献[6]使用复数域上的复数理想比率掩码(complex ideal ratio mask,cIRM)作为训练目标,实现了对纯净语音幅度谱和相位谱的同步估计。考虑到语音在时频域中的二维相关性,文献[7]将卷积神经网络(convolutional neural networks,CNN)应用到语音增强领域。文献[8]提出一种全卷积神经网络(fully convolutional networks,FCN),实现含噪语音到纯净语音的直接映射,相比基于DNN的语音增强方法,显著提高了语音增强的可懂度。文献[9]使用Maxout激活函数代替Sigmoid激活函数,解决了基于CNN训练过程中过拟合的问题。考虑到语音序列相邻帧之间的关联性,文献[10]使用循环神经网络(recurrent neural networks,RNN)随着序列时间上的变化进行建模,进一步提高了语音增强的性能。文献[11]使用长短时记忆网络(long short-term memory,LSTM)有效缓解了RNN在处理语音增强问题时梯度消失和梯度爆炸的问题。文献[12]提出了一种基于LSTM-RNN的语音增强方法,使用LPS特征作为输入,分别将纯净语音的LPS和IRM作为训练目标,实验结果表明,该方法可有效提升增强后语音的质量和可懂度。
实际上,无论采用哪种网络结构进行语音增强,都应充分利用语音序列信息上下文之间的相关性,使网络更好地学习含噪语音和纯净语音之间的非线性关系,因此网络模型的输入通常是连续的多帧含噪语音序列。然而含噪语音序列相邻帧所包含的信息并非都是有利信息,也有可能是噪声主导的干扰信息。传统的循环神经网络在处理含噪语音序列时,将不同时间步上的输入编码为固定长度的向量表示,使得网络无法有选择性地学习序列信息,限制了网络模型的性能。因此,本文将Attention机制与准循环神经网络(quasi-recurrent neural network,QRNN)结合,设计出一种融合注意力机制的QRNN(ATT-QRNN)语音增强模型。基于QRNN对含噪语音并行计算的特性保证网络模型的训练速度,通过Attention机制使得QRNN的输入是赋予权重的含噪语音序列,从而提高网络模型对含噪语音序列中目标信息的学习能力,以提高网络的增强性能。
1 网络结构
1.1 QRNN网络
QRNN相邻时刻的隐层连接方式不再采用全连接的形式,而是将连续时间步上的隐层单元连接改进为仅对上一时刻对应隐层单元连接,表示QRNN网络在多路隐层单元之间可以进行并行计算,从而提高网络的训练速度。QRNN由卷积层和池化层组成,通过卷积对含噪语音序列信息进行跨纬度特征提取作为网络的输入,并构造门控函数和记忆单元使得网络可以保存之前时刻的序列信息。QRNN在t时刻隐层单元结构如图1所示,由遗忘门、输出门和记忆单元组成。

图1 QRNN隐层单元结构
遗忘门ft控制隐层单元对当前时刻输入序列的保留程度;记忆单元ct控制隐层单元对之前时刻序列信息的保留程度;输出门ot决定隐层单元的输出。对给定的含噪语音序列X=[x1,x2,...,xT],经过大小为k的滤波器卷积后得到第t帧为中心连续k帧的含噪语音序列Xt=[xt-(k-1)/2,...,xt,...,xt+(k-1)/2]作为网络的输入,根据k的取值不同可以改变输入到隐层单元的语音序列维度。此时QRNN中序列信息zt、遗忘门ft、输出门ot的计算公式为:
(1)
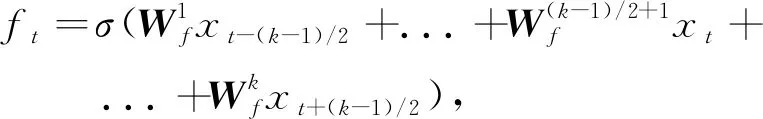
(2)
(3)
式中:Wz、Wf、Wo均为门函数的权重矩阵;elu、σ表示激活函数。最后通过记忆单元ct贯穿不同时刻序列信息的保留程度并决定网络隐层最后的输出ht:
ct=ftοct-1+itοzt,
(4)
ht=otοct。
(5)
1.2 Attention机制
Attention机制是一种资源分配机制,常用于序列任务分配。通过对关键的序列信息赋予更大的权重,提高网络对目标信息的关注程度。在语音增强的任务中,不同时刻输入网络中的序列对语音增强效果的影响是不同的,因此本文在模型中引入Attention机制,使网络以高注意关注目标语音的某一区域,同时以低注意感知噪声干扰信号,且网络可以随着时间的推移改变注意力的焦点。Attention机制的更新方式为
(6)
式中:αij是通过Attention机制的线性层学习得到的权重系数;dj为Attention机制层的输入;vi为Attention机制层的输出。
1.3 融合注意力机制的QRNN语音增强方法
本文将Attention机制与QRNN网络结合,使模型在保证训练速度的基础上更有效地学习语音序列的上下文关系,以达到更好的增强效果。融合Attention机制的QRNN语音增强模型如图2所示,网络由输入层、Attention机制层、QRNN层以及输出层组成,其中卷积层的并列模块表示QRNN对含噪语音序列的并行处理。

图2 基于ATT-QRNN的语音增强模型
本文将Attention机制应用在网络的输入层之后,即网络不再以含噪语音序列直接作为QRNN层的输入,而是直接将含有权重系数的含噪语音序列作为后续QRNN层的输入。则Attention在t时刻的输出vt可表示为
vt=αtXt,
(7)
式中:αt是通过Attention机制对含噪语音序列赋予的权重;Xt为当前时刻网络输入的连续多帧含噪语音序列特征。
基于ATT-QRNN的语音增强方法见表1。

表1 基于ATT-QRNN的语音增强方法
2 实验
2.1 实验配置
实验阶段采用的数据集由爱丁堡大学信息学院语音技术研究中心(CSTR)[13]提供。该数据集包括纯净语音数据集Voice Bank集[14]和噪声数据集Demand集[15]。在训练阶段将Voice Bank集中的28位说话人录音和Demand集中的8类噪声、2类人工合成噪声按照15、10、5和0 dB的全局信噪比合成11 572段含噪语音文件。在测试集将Voice Bank集中的2位说话人录音和Demand集中的另外5类噪声按照17.5、12.5、7.5和2.5 dB的全局信噪比合成824段含噪语音文件。
在数据处理阶段所有语音文件均采用16 kHz进行重采样,实验STFT的语音窗长设为512点(32 ms),帧移设置为256点(16 ms)。网络采用连续7帧的含噪语音LPS特征作为输入,采用纯净语音的幅度谱掩蔽特征作为网络的训练目标,损失函数采用MAE。网络迭代epoch设为50,batchsize设为512,优化器选用Adamax。为验证ATT-QRNN模型的合理性和有效性,实验阶段使用QRNN模型作为基准模型,旨在验证ATT-QRNN能够利用QRNN模型提升训练速度的前提下,提高网络模型的性能。此外还将LSTM和GRU网络以及融合相同注意力机制的ATT-LSTM、ATT-GRU进行语音增强,以对比ATT-QRNN在增强后语音的性能以及网络训练时间上的优势。
2.2 评价指标
本文采用的语音增强性能的评价指标主要包括主观语音质量评估(perceptual evaluation of speech quality,PESQ)[16]、短时客观可懂度(short-time objective intelligibility,STOI)[17]、语音信号失真指数(CSIG)[18]、背景噪声失真指数(CBAK)[18]、整体质量(COVL)[18]。其中,PESQ是国际上公认的客观MOS评估指标,其取值范围介于[-0.5,4.5]之间,取值越高表示增强后语音的质量越高。STOI是衡量增强后语音可懂度的重要指标,尤其是在低信噪比的情况下,STOI的得分情况具有重要意义,其取值范围介于[0,1]之间,取值越高表示增强后语音的可懂度越高。CSIG、CBAK、COVL是通过多种指标线性回归分析得到的,取值范围均介于[0,5]之间,取值越高表示增强后语音的质量越高。
2.3 实验结果与分析
2.3.1 网络训练时间和参数量对比
本文旨在保障网络训练速度的基础上提高语音增强的性能,因此本文首先对比了ATT-QRNN网络和其他模型的参数量和每个epoch上的训练时间,对比结果见表2。

表2 不同网络训练时间和参数量对比
结果表明,ATT-QRNN的参数量与QRNN近似,明显少于LSTM、GRU、ATT-LSTM、ATT-GRU的,
虽然ATT-QRNN与QRNN相比在每个epoch的平均训练时间上存在延时,但与其他模型相比仍有大幅度提升。即基于ATT-QRNN的语音增强模型综合上具有较少的训练参数和较快的训练速度。
2.3.2 语音增强性能对比
在语音增强性能的对比上,首先采用PESQ和STOI两种指标对比增强后语音的质量和可懂度。图3给出了不同网络增强后的PESQ与STOI得分情况。在相同的信噪比下,ATT-QRNN以及其他模型的PESQ和STOI得分相比含噪语音均有不同程度提升,且基于ATT-QRNN的语音增强方法的两种评估指标得分提升幅度最大,表明注意力机制能有效地改善含噪语音的质量和可懂度。
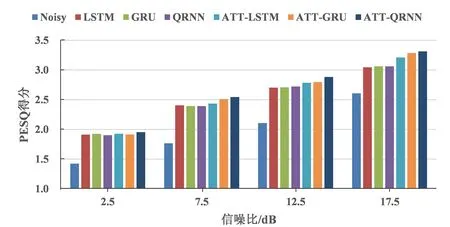
(a)PESQ得分
表3对比了ATT-QRNN与其他模型在不同信噪比下CSIG、CBAK、COVL的得分情况。通过对表3观察发现,语音增强网络各项评估指标的取值相比于含噪语音的评估指标均有所提升。其中基于ATT-QRNN的语音增强方法在CSIG指标的12.5 dB和17.5 dB上得分略低于ATT-GRU;在COVL指标的7.5 dB上得分略低于ATT-LSTM、ATT-GRU;在其他不同信噪比和指标下,ATT-QRNN均取得了最优得分。综合表3的得分情况,尽管ATT-QRNN在某些信噪比下的得分略低于其他网络模型,但在同一指标不同信噪比的平均得分水平上,ATT-QRNN均取得了最优得分。
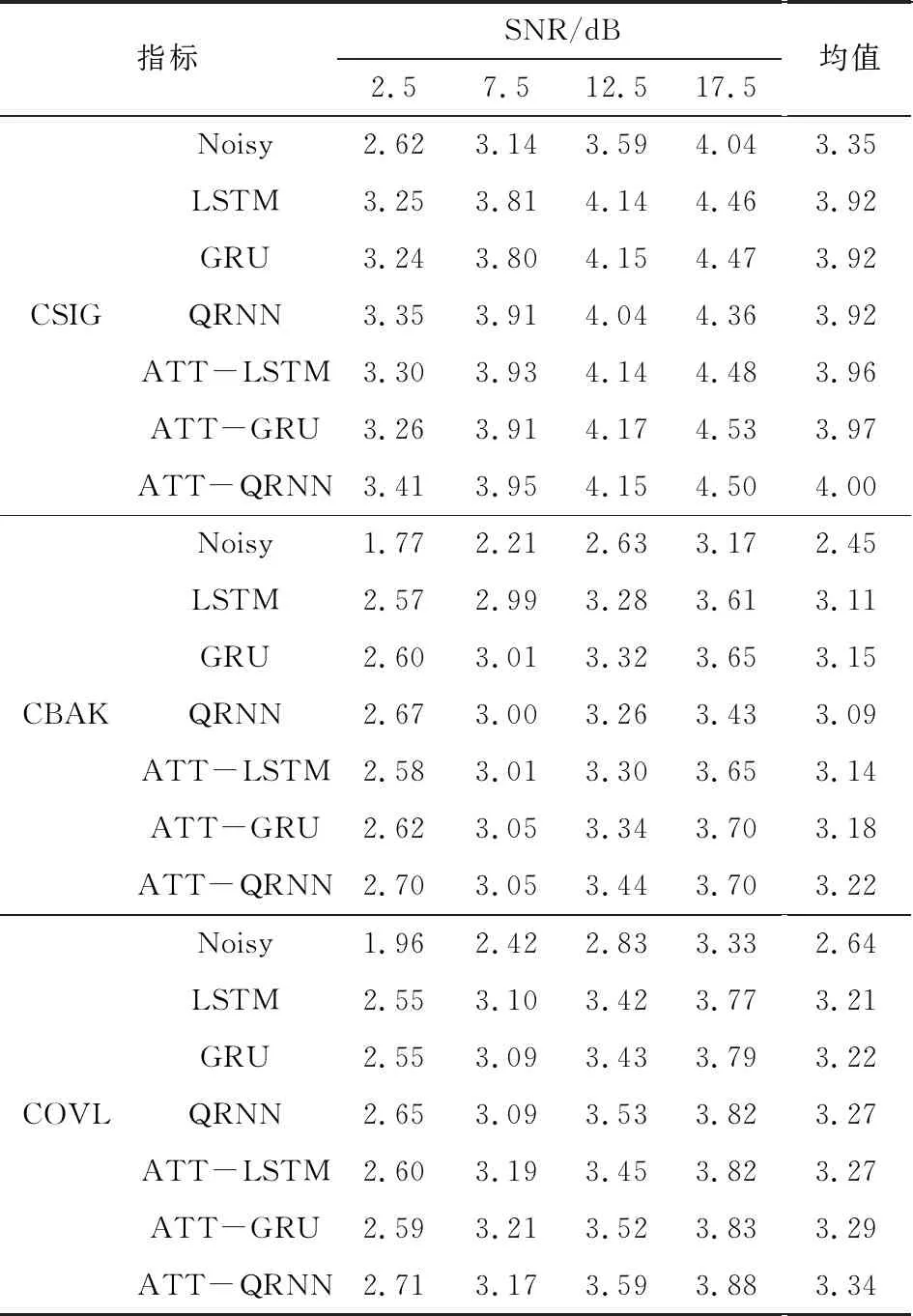
表3 不同网络的语音增强性能比较
为了更加直观地对比不同网络的语音增强效果,本文以信噪比为2.5 dB的一段含噪语音为例,对比了该含噪语音以及对应的纯净语音、不同网络增强后的语音语谱图。图4(a)—图4(h)分别表示纯净语音、含噪语音以及基于LSTM、GRU、QRNN、ATT-LSTM、ATT-GRU、ATT-QRNN增强后的语音语谱图。

(a)纯净语音 (b)含噪语音 (c)LSTM增强的语音
通过语谱图的对比发现,各网络增强后的语音语谱图明显比含噪语音的降低了更多的能量噪点,使增强后的语音语谱图更趋近于纯净语音的。其中基于ATT-QRNN增强后的语音语谱图能量噪点减少的最明显,保留了更多的目标语音细节,表明ATT-QRNN网络对噪声具有更好的抑制能力,对噪声干扰起到了缓解作用。
综合分析以上实验结果,相比除QRNN以外的其他模型,融合注意力机制的QRNN语音增强方法具有更快的训练速度,且在增强后的语音质量和可懂度的客观评价,以及增强后语音的语谱图的客观分析上都取得了更好的结果,表明融合注意力机制的QRNN在保证训练速度的基础上,通过注意力机制能提高语音增强性能。
3 结论
1)通过QRNN网络实现对含噪语音序列信息并行计算,保证网络的训练速度。
2)在QRNN网络层前融入Attention机制对含噪语音的处理,通过权重分配提高网络模型学习更多有利信息的能力。
3)相比除QRNN以外的其他模型,融合注意力机制的QRNN语音增强方法具有更快的训练速度。
4)通过对语谱图观察表明本文提出的方法对干扰噪声具有更好的抑制能力。
综合表明融合注意力机制的QRNN在保证训练速度的基础上,通过注意力机制能提高语音增强性能。
猜你喜欢
北京航空航天大学学报(2019年9期)2019-10-26 02:30:12
阅读(快乐英语高年级)(2019年5期)2019-09-10 07:22:44
电子制作(2019年14期)2019-08-20 05:43:38
电子制作(2019年9期)2019-05-30 09:42:10
人民珠江(2019年4期)2019-04-20 02:32:00
小说界(2018年5期)2018-11-26 12:43:42
电子测试(2018年11期)2018-06-26 05:56:02
雷达学报(2017年3期)2018-01-19 02:01:27
西南石油大学学报(自然科学版)(2015年5期)2015-04-16 05:12:24
计算机工程(2014年9期)2014-06-06 10:46:47
