
页岩气储层预测的多标签主动学习算法
2022-03-01 12:35:02冯婷婷唐洪明闫建平廖纪佳
计算机应用 2022年2期
汪 敏,冯婷婷,闵 帆,唐洪明,闫建平,廖纪佳
(1.西南石油大学电气信息学院,成都 610500;2.西南石油大学计算机科学学院,成都 610500;3.西南石油大学地球科学与技术学院,成都 610500)
0 引言
随着人类对能源的需求越来越大,非常规油气资源的开采越来越受到人们的关注。页岩气[1-2]作为非常规油气资源,具有含气面积广泛、资源量大、生产寿命长、产量稳定等特点,吸引了越来越多的研究者投入研究。中国已经成为世界上第三个实现页岩气工业化生产的国家。由于中国页岩气地质条件复杂、页岩气勘探开发关键技术与装备有限,导致页岩气开发成本较高。中国目前的页岩气勘探事业尚处于发展初期,如何快速低成本地判断出页岩气资源“甜点区”,实现经济开采具有重大的意义。
页岩气储层品质[3]受到地质因素、工程因素等多种因素的影响,比如,脆性矿物组成、泊松比、杨氏模量、吸附气含量等参数。众多因素产生的生产数据极其庞大,需要大量的专业知识作为支撑,才可以实现对生产数据的有效处理,因此耗费的人力和物力成本都是巨大的。页岩气储层品质的判断结果会直接影响到试油层位的优选和压裂施工的效果,进而影响页岩气产能的高低。随着人工智能的快速发展,将机器学习运用在页岩气开发领域,已经成为行业关注的热点。
在单标签学习任务中,标签稀少、标签获取难度大、专家标注成本高、获取标签错误率高等问题层出不穷。实际应用中的样本,往往会同时拥有多个标签[4],例如,在文本分类中,每个文档可能同时属于多个主题,如政治和健康。与单标签学习相比,多标签学习中标签的指数级增长更加剧了标签稀缺和标注成本高昂的问题。主动学习[5]通过交互式查询可以有效降低标注成本。将多标签学习与主动学习[6]结合,制定样本选择策略筛选最有价值的样本进行学习,可以有效缓解多标签学习场景中成本高昂的问题。
本文提出一种多标准主动查询的多标签学习(Multistandard Active query Multi-label Learning,MAML)算法,将多标签学习与主动学习相结合,充分考虑了样本属性信息和标签空间内部的信息,有效改善了多标签学习常见的信息挖掘不充分的问题。通过综合考虑样本的信息性、代表性,制定丰富性约束,有效筛选出最有价值的样本,不仅降低了多标签学习的标注成本,而且显著提高了多标签学习算法的性能。
本文提出的MAML 算法思想主要包括以下四个方面:
1)利用基于密度峰值的快速聚类CFDP(Clustering by Fast search and find of Density Peaks)算法[7]选择初始训练样本。将多标签数据集转化为多个单标签二分类数据集,通过Softmax 得到多标签样本在每个单标签下的信息熵。利用最大熵思想,将多个标签下的信息熵进行加权平均得到每个样本的信息性。
2)利用无参数概率密度估计的方法,选择高斯核函数和窗口宽度,利用概率密度函数得到样本的统计概率,从而得到每个样本的代表性。
3)从样本属性和样本标签两个角度考虑,加入丰富性约束。为了保证选择的训练样本尽可能地丰富,定义样本之间的属性差异性阈值,从而避免选择相似的样本;为了保证选择的样本所具有的标签足够丰富,利用第1)步中Softmax 预测的标签值,获得每次查询过程的样本丰富性,并定义标签丰富性阈值。当同时满足属性差异性和标签丰富性约束时,该样本才会被查询并加入训练集。
4)利用基于实例差异的多标签学习InsDif(multi-label learning by Instance Differentiation)算法[8]对剩余样本的标签集进行预测,从而得到所有样本的标签。
根据文献[9]确定了页岩气水平储层产能的主要影响因素,分别为有机碳含量、孔隙度、脆性指数、总含气量。本文将这四个因素处理为页岩气储层的多个标签,利用综合品质预测精度来判断算法的性能。
本文首先在实际的11 个Yahoo 文本数据集[10]上进行实验,将MAML 算法与流行的多标签学习算法和主动学习算法进行比较,利用常用的四个多标签学习评价指标验证了所提算法的优越性;接着利用Friedman 检验和Nemenyi 假设检验[11]进一步验证了MAML 算法的优越性;然后将实验扩展到真实的四个测井数据集,加入新的评价指标,实验结果表明MAML 算法在实际页岩气测井领域的实用性和优越性。
1 相关工作
页岩气储层[12]具有低孔隙度、低渗透率以及自生自储等特点,其非常规的成藏机制与演化分布加大了页岩气开发的难度。测井数据获取艰难,而对于数据的处理需要专业的知识作为支撑,大大增加了页岩气储层品质评价的成本。利用有效的测井评价方法,可以为后续的开发工作提供可靠的信息。流行的测井评价方法是通过大量的测井资料对页岩气储层进行定量评价。页岩气储层工程品质参数定量评价包括泊松比、杨氏模量、剪切模量、脆性指数、抗压强度等岩石力学参数。从岩石物理性质角度,页岩气储层品质评价包括岩石矿物组成、总有机碳含量、孔隙度、含水饱和度等指标。
传统的页岩气储层评价方法往往根据考虑角度的不同,割裂地对数据进行处理,忽略了生产数据内部之间的关系。比如从可压裂性[13]角度,对脆性指数、泊松比、抗压强度等参数进行定量分析,仅得到页岩气储层在可压裂性方面的评价;从含气量[14]角度,对游离气、吸附气等参数进行定量分析,仅得到页岩气储层在含气量方面的评价。在实际生产生活中,可压裂性评价级别与含气量评价级别是相互关联的。利用机器学习充分挖掘数据内在规律,可以有效提高测井评价效率和精度。本文将有机碳含量、孔隙度、脆性指数、总含气量处理为储层的多个标签,避免了储层评价复杂难懂的难题。由于标注成本有限,且对专家知识要求较高,导致实际页岩气储层的“甜点”标签稀少。为了解决这个问题,本文首次提出将主动学习与多标签学习结合应用在页岩气储层品质的综合评价预测领域。
多标签学习[15]广泛应用在文本分类、生物信息、网络信息挖掘等多个领域。多标签数据集的每个样本都有一个标签集,输出空间会随着标签数量的增加而呈指数级增长。例如,对于具有20 个类标签的标签空间(q=20),可能的标签集数量将超过100 万(即220)。利用标签之间的相关性处理多标签学习问题可以有效应对这一挑战。将多标签学习问题转化为多个独立的二分类问题属于一阶策略,简单高效但是忽略了标签之间的相关性。考虑标签对相关性排名等属于二阶策略,但是实际情况往往不能满足二阶假设。考虑标签集的随机标签子集对样本的影响等属于高阶策略,但是实现难度大。在实际场景中,如何在标签稀缺、样本查询成本有限的情况下尽可能地获得令人满意的分类精度就成为大家关注的问题。
主动学习选择最有价值的样本,利用专家标注组成训练集,可以大幅减少标注成本[16-17]。常用的主动学习方法包括委员会查询、不确定性抽样、优化实验设计等[18]。传统的主动学习[19-21]多从样本的信息性、代表性或二者结合进行考虑,而忽略了样本之间的关系。为了更好地解决多标签学习问题,减少专家标注成本,结合主动学习势在必行。多标签主动学习算法[22]利用关键样本选择策略选择最有价值的样本,加入多标签学习分类器模型进行训练,从而实现对多标签数据标签的高效预测。流行的多标签主动学习常常采用基于信息量的标准来选择关键样本,却无法充分利用样本数据和标签空间的信息,从而导致算法性能不佳,因此综合考虑多个标准设计查询策略就成为需要关注的问题。
2 问题描述
对于实际生活中的学习任务,数据样本往往由多个标签来表示,这些标签互相关联,共同表征该样本的情况。由于数据样本标注成本耗费过大,加剧了数据挖掘的困难。多标签主动学习通过制定一套标准,筛选出最有价值的样本,由专家系统进行标注,然后利用人工智能得到剩余数据的标签信息,不仅降低了成本,而且可以充分利用数据信息。在实际的多标签学习任务中,令N为专家系统所提供的具有完整多标签信息的样本个数,q为标签个数,标签总预算为100 万元,每个标签的标注费用为100 元,N=。那么如何选择最有价值的N个实例,获得最大的标注效益和预测精度就成为需要考虑的关键问题。
D={(x1,Y1),(x2,Y2),…,(xl,Yl),xl+1,xl+2,…,xn}表示含有n个样本的数据集,其中:xi=(xi1,xi2,…,xid)是d维行向量;Yi=(Yi1,Yi2,…,Yiq)是q维行向量,表示第i个样本的标签。若样本xi含有第j个标签,则Yij=1;否则Yij=0。数据集包括训练集Dl和测试集Du,其中:Dl={(x1,Y1),(x2,Y2),…,(xl,Yl)},Du={xl+1,xl+2,…,xn}。在每一轮迭代中,从测试集Du中选出一个样本xs,查询它的标签集,将其加入训练集Dl,直到获取N个训练样本,整个过程结束。
3 本文算法
3.1 信息性
信息性用来衡量模型的不确定性。本文利用softmax 获得样本在每个单标签下的信息熵,其中信息熵[23]表示样本包含信息的不确定性。对于多标签学习场景而言,每个单标签下的信息熵就代表了样本属性与该标签二分类向量之间的关联度。然后利用最大熵思想,将每个标签下的信息熵进行加权平均,得到样本在每个标签下的信息性。
样本xi的信息熵公式如下:

其中:zk表示样本在每个单标签下的第k类,k∈{0,1};θ表示softmax 类别预测过程中的参数;表示样本xi在单个标签Yij下的信息熵。
样本xi的信息性f(xi)表示了样本属性与多个标签之间的关联度。利用最大熵的思想,令每个标签出现的概率相同,对所有单标签下的信息熵进行加权平均,得到样本信息性:

其中:j∈{1,2,…,q}。
3.2 代表性
将样本的所有属性值输入到概率密度函数进行计算,结果表示该样本所代表的信息,样本的概率密度越大,越具有代表性[24]。本文采用无参数的方式,样本xi属性向量在区域R的统计概率如下:

令窗函数的宽度为dc,则样本的概率密度函数如下:
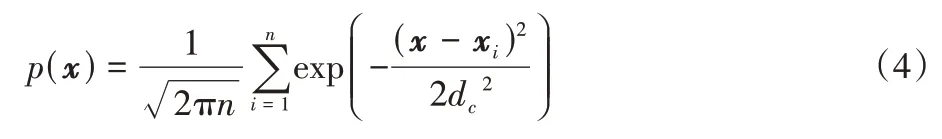
3.3 丰富性
为了提高算法预测标签的精度,本文从样本属性和样本标签两个角度出发,制定属性丰富性约束和标签丰富性约束,保证选择的训练样本所具有的信息尽可能地丰富。
3.3.1 属性丰富性
由K最近邻(K-Nearest Neighbor,KNN)算法的思想可知,距离越近的两个样本相似的可能性就越高。在属性丰富性[25]约束部分利用距离阈值约束,使得备选样本的属性丰富性满足差异性要求。两个样本之间的曼哈顿距离可定义为:

当样本之间的曼哈顿距离足够大时,可保证样本之间的差异性,故将差异性阈值定义为:

其中:u∈{1,2,…,d}。通过大量实验获知,当系数∂取0.5时,算法性能最优。本文以上一轮主动学习选出的训练样本s作为基准,根据样本的信息性和代表性处理后的结果降序排序,遍历剩余样本,当距离dist(x,s) >β时,该样本x选为备选样本。
3.3.2 标签丰富性
标签丰富性约束可以衡量样本的标签是否足够丰富。本文利用信息性部分对样本单标签下的类别预测结果来获取该样本当前的标签。由于本研究针对的是多标签二分类问题,每个样本的标签丰富性就可以定义为:

其中:Yij表示第j个标签;q表示标签的数量;I(·)表示满足括号里条件的次数。样本的标签信息越丰富,查询的价值就越高。
由于标签信息分布不均,通过大量实验得知,当标签丰富性大于当前剩余样本丰富性的均值时,选出的备选样本价值最高,故标签丰富性阈值定义为:

其中:i∈{1,2,…,m},m表示剩余测试样本的数量。当备选样本的丰富性h(xi)≥α时,该备选样本加入训练集。
3.4 算法设计
基于多标签学习的主动学习算法框架如算法1 所示,第2)~4)行用来选择初始训练集,复杂度为O(dn2);第5)~17)行对剩余样本进行处理,利用约束条件选取关键样本,更新训练集和测试集,复杂度为O(Ndqn2);第18)~19)行对剩余样本的标签集进行预测,复杂度为O(dqn)。算法1 的时间复杂度为O(Ndqn2)。
O(dn2)+O(Ndqn2)+O(dqn)=O(Ndqn2)
其中:d、q和n分别表示样本的属性数量、样本标签数量和样本数量。


3.5 算法评价指标
本文采用 AveragePrecision、Coverage、OneError、RankingLoss 这四种在多标签学习中常见的评价指标[26]来衡量算法的性能。其中,AveragePrecision 的值越大,表示算法性能越好,其余指标则相反。
4 实验与结果分析
实验分为两个部分:第一部分在实际的Yahoo 数据集上进行实验,实验结果验证了MAML 算法的优越性;第二部分在实际的页岩气测井数据集上进行实验,经过专业处理之后,对比最终的页岩气储层综合品质类别,验证了MAML 算法在页岩气储层预测领域的优越性和可行性。对比算法包括多标签学习算法,即基于K最近邻多标签(Multi-LabelKNearest Neighbor,ML-KNN)学习算法[26]、多标签学习的反向传播(BackPropagation for Multi-Label Learning,BP-MLL)算法[27]、具有全局和局部标签相关性的多标签学习GLOCAL(multi-label learning with GLObal and loCAL label correlation)算法[28],以及通过查询信息性和代表性样本的主动学习QUIRE(active learning by QUerying Informative and Representative Examples)算法[29]。每次实验运行10 次来获得各算法四种评价指标的均值和方差,然后利用Friedman 检验和Nemenyi 假设检验获取多标签学习算法的性能平均排名。
4.1 Yahoo数据集实验
表1 列出了Yahoo 数据集的详细信息。Yahoo 数据集是从yahoo.com 网址上获取的网页信息,通过处理划分为11 个领域的文本数据,包括艺术、经济、计算机、教育、表演、健康、娱乐、参考书、科学、社交、社会。每个数据集包含5 000 个样本,数据集属性数量最高可达到1 047,标签数量最高可达到40 个标签,满足实验要求。本文选择每个数据集数量的5%,即250 个样本组成训练集。

表1 Yahoo数据集Tab.1 Yahoo datasets
针对11 个Yahoo 数据集进行实验,选择样本数量的5%作为训练集。和多标签学习算法做对比,在四个多标签学习评价指标上的平均排名如表2 所示。从表格中可以看到,MAML 算法在AveragePrecision 上的排名均值为1.090 9,在OneError 上的排名均值为1.636 4,均位于所有算法的第一位。表3 是MAML 算法分别与多标签学习算法ML-KNN、BP-MLL、GLOCAL 以及主动学习算法QUIRE 进行对比的具体实验结果。MAML 算法与多标签学习算法相比,有10 个数据集在指标AveragePrecision 上的性能优于其他算法,5 个数据集在指标OneError 上性能优于其他算法。MAML 算法与主动学习算法相比,MAML 在四个评价指标上的性能表现明显优于QUIRE,只有在Arts、Business、Recreation 这三个数据集上,QUIRE 表现更好一些。通过11 个Yahoo 数据集的实验,充分证明了MAML 算法的优越性。
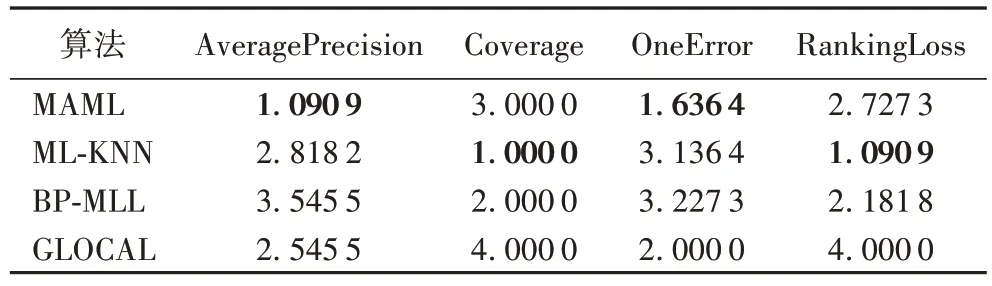
表2 Yahoo数据集上不同多标签学习算法性能的平均排名Tab.2 Average performance ranking of different multi-label learning algorithms on Yahoo datasets

表3 MAML与对比算法在Yahoo数据集上4个评价指标比较Tab.3 Comparison of four evaluation indicators between MAML and comparison algorithms on Yahoo datasets
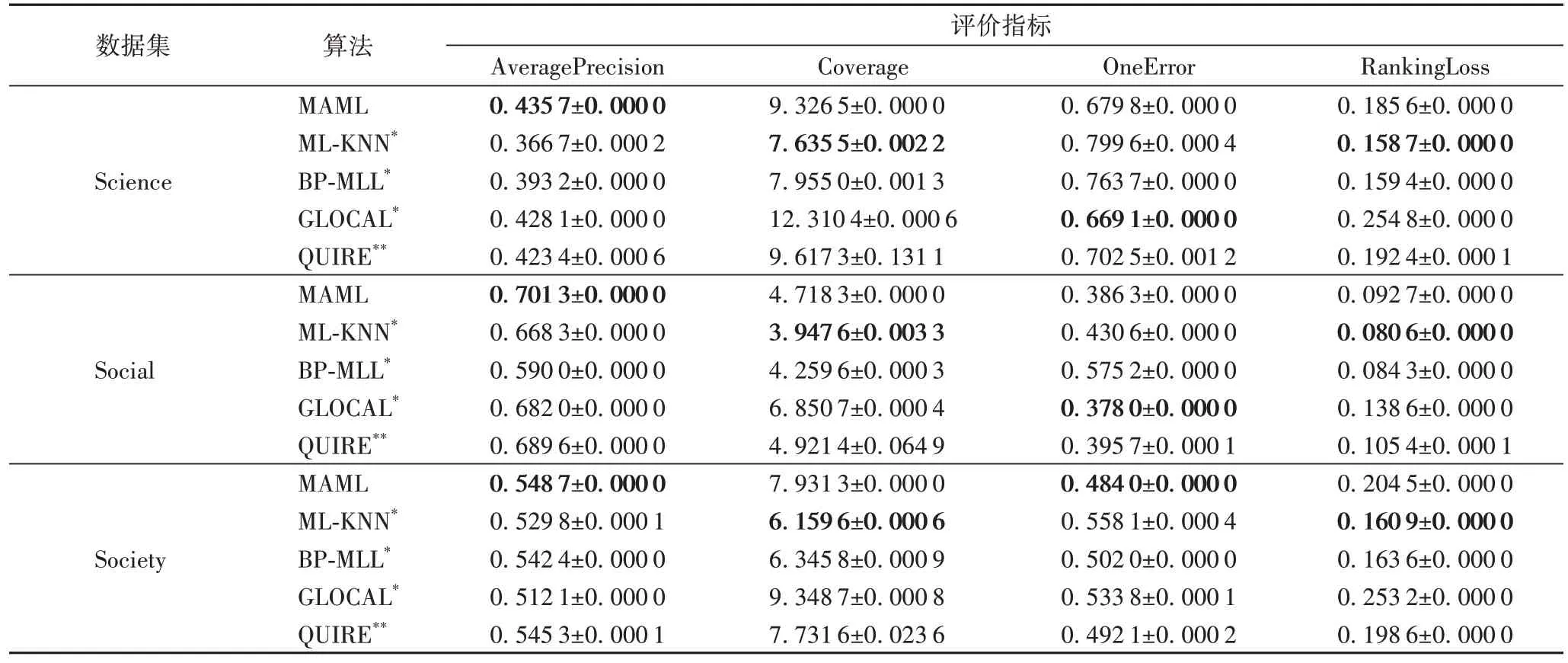
续表
AveragePrecision 和OneError 评价指标的关注点在于样本真实标签与实际标签是否一致。MAML 算法综合考虑样本的信息性和代表性,利用样本属性差异性和标签丰富性约束选出的训练样本所包含的信息更丰富,基于此训练集训练的多标签学习分类模型性能更优越。AveragePrecision、OneError 指标的算法平均排名和具体实验数据都验证了MAML 算法在提高预测标签准确性方面具有明显优势。
Coverage 用来衡量预测标签的相关性,RankingLoss 用来衡量预测标签的不相关性。ML-KNN 算法假定标签之间相互独立,并在Yahoo 等多个数据集上得到了验证,从而在Coverage 和RankingLoss 指标上的实验效果可以排在第一位。
4.2 某页岩气测井数据集实验
实验采用的四个真实页岩气测井储层数据集来自某油气田公司滇黔川地区天然气井数据,具体信息如表4 所示。
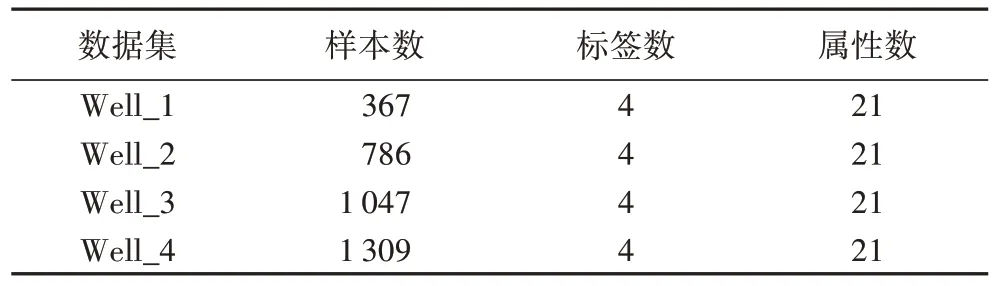
表4 测井数据集Tab.4 Well logging datasets
本研究将有机碳含量、孔隙度、脆性指数、总含气量处理为页岩气储层的4 个标签,故每个数据集的标签个数均为4,属性个数为均为21。然后将预测的多个标签进一步处理得到每个样本的综合品质类别。为了更好地评价算法在测井场景下的性能,本文引入评价指标Accuracy,即预测精度。
预测精度表示分类准确的样本数占该样本总数的比例,可以评估页岩气储层综合品质预测类别是否正确。

其中:a表示分类错误的样本;b表示样本总数。
对于实际的测井数据,由于每种算法的运行结果中,评价指标OneError 的值都为零,故不再赘述。对四个测井数据集进行实验,选择样本数量的50%作为训练集,将MAML 算法与多标签学习算法ML-KNN、BP-MLL 和GLOCAL 进行对比,然后将MAML 算法与主动学习算法QUIRE 进行对比。运行10 次来获得算法在四种评价指标的均值和方差,然后利用Friedman 检验和Nemenyi 假设检验获取多标签学习算法的性能平均排名。
4.2.1 实验结果与分析
MAML 算法与多标签学习算法做对比,算法在四个评价指标上的平均排名如表5 所示。MAML 算法在评价指标AveragePrecision 和Accuracy 的排名均值分别为1.500 0 和1.000 0,均位于所有算法的第一位。表6 是MAML 算法分别与多标签学习算法ML-KNN、BP-MLL、GLOCAL 以及与主动学习算法QUIRE 进行对比的具体实验结果。MAML 算法与多标签学习算法相比,MAML 算法在指标AveragePrecision 和Accuracy 上比其他三种多标签学习算法的性能都要好。尤其是评价指标Accuracy,在四个测井数据集上的测试结果均值分别为0.666 7、0.679 4、0.741 9、0.723 2,效果明显优于其他算法。MAML 算法与主动学习算法相比,MAML 算法的评价指标表现效果不如QUIRE,但对于指标Accuracy,四个测井数据集的测试结果均明显优于对比算法。

表5 测井数据集上不同多标签学习算法性能的平均排名Tab.5 Average performance ranking of different multi-label learning algorithms on well logging datasets
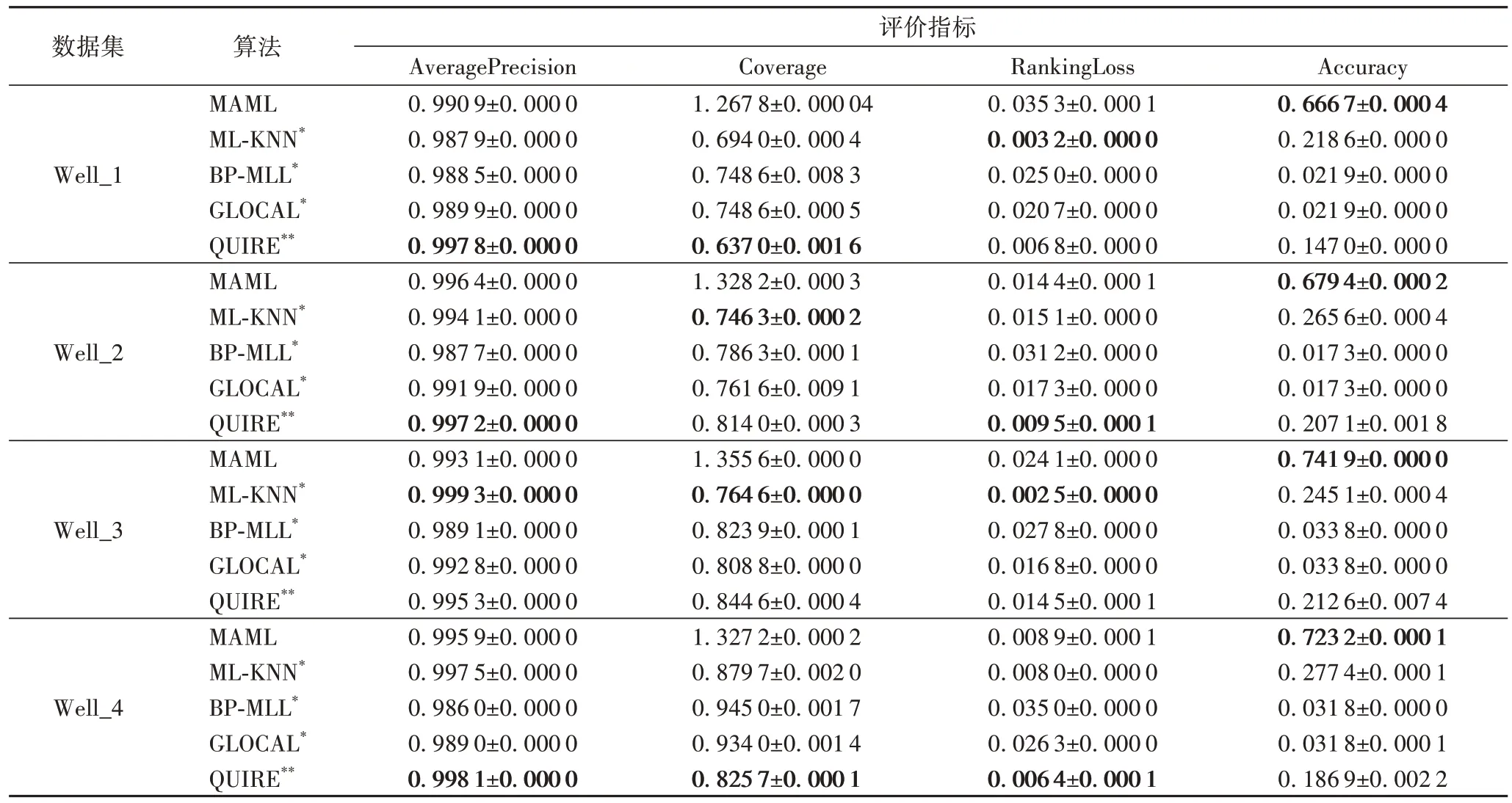
表6 MAML与对比算法在测井数据集上4个评价指标比较Tab.6 Comparison of four evaluation indicators between MAML and comparison algorithms on well logging datasets
对于真实的4 个测井数据集,由于数据集本身并不是传统的多标签数据集,无法充分体现MAML 算法在多标签学习方面的优势。Coverage 和RankingLoss 的关注点都在于评价预测标签的相关性。对于真实的测井数据集,在数据处理时,将有机碳含量、孔隙度、脆性指数、总含气量处理为4 个相互独立的标签,导致MAML 算法在Coverage 和RankingLoss上的效果较差;而ML-KNN 算法处理标签不相关的数据集时极具优势,故可以在Coverage 和RankingLoss 上的性能排名第一。
MAML 算法综合考虑样本的信息性、代表性、属性差异性和标签丰富性选出训练集,基于此学习得到的分类模型在预测标签准确率(指标AveragePrecision)上优势明显。对于实际的页岩气测井储层预测场景来说,储层综合品质的预测评级准确度Accuracy 与预测标签准确率息息相关。MAML算法在Accuracy 上的实验结果远远优于对比算法,充分证明了该算法在实际页岩气测井场景中,尤其是本文关心的测井综合品质预测方面,具有优越性和实用性,有助于研究者利用人工智能识别页岩气储层甜点区。
4.2.2 测井实验数据具体分析
根据MAML 算法的样本选择策略,测井数据集每经过一轮数据筛选,就选出一个备选样本加入训练集。表7 列举了10 个备选样本在被选择时的信息性、代表性、丰富性量化结果。根据MAML 算法的样本选择策略选出信息性、代表性充足,标签丰富的样本加入训练集,保证训练集包含的信息足够丰富,有利于分类器模型的训练优化。
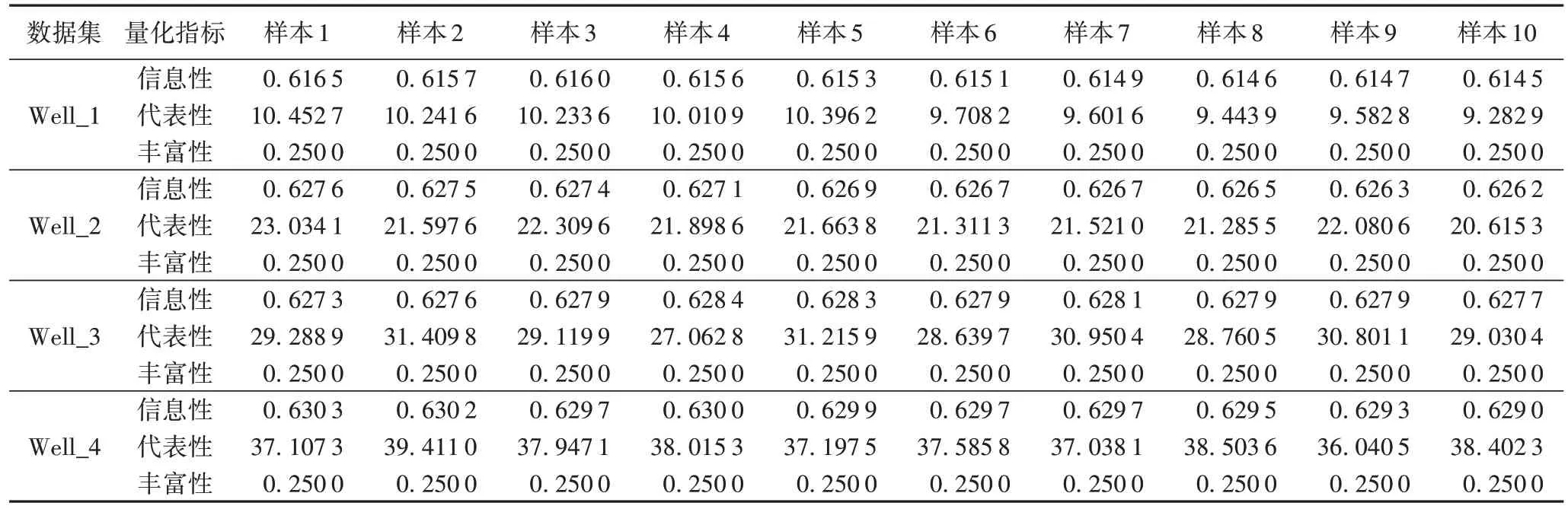
表7 MAML算法对10个测井备选样本的信息性、代表性、丰富性量化结果Tab.7 Informativity,representativeness,and richness quantitative results of MAML algorithm to 10 candidate well logging samples
表8 以数据集Well_1 为例,列举了从信息性、代表性、丰富性三个角度处理过后的排序前10 的样本量化结果。其中,对于测井数据集而言,由于本文将页岩气数据集处理为多标签数据集,将储层品质影响的主要参数,总有机碳含量、孔隙度、游离和吸附气量、脆性指数处理为4 个标签,故根据式(6)排名靠前的样本丰富性量化结果都为0.250 0。
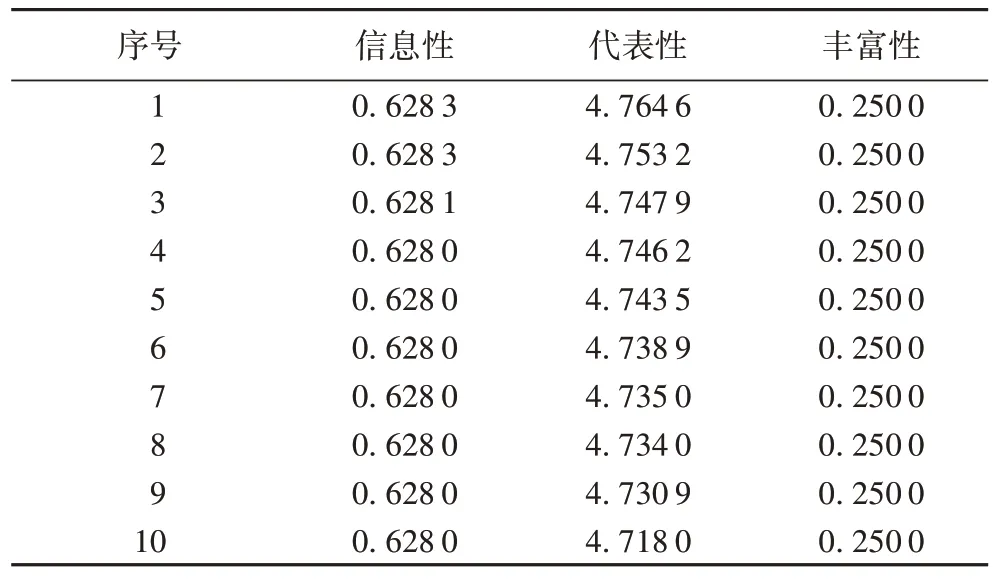
表8 Well_1数据集最后一轮筛选后top-10样本Tab.8 Top-10 samples after last round of screening of Well_1 dataset
5 结语
将机器学习与实际场景结合并加以应用已经成为行业的流行趋势。本文将多标签学习与主动学习相结合,对数据进行充分的挖掘,综合考虑样本的信息性、代表性、属性差异性以及标签丰富性,从而选出最具价值的样本进行训练,大幅降低了专家标注成本。实际Yahoo 数据集上的实验充分证明了该算法在多标签数据领域的可行性,在真实测井数据的实验充分证明了MAML 算法在测井数据处理领域,尤其是页岩气储层甜点区的判断方面的可行性和优越性。未来研究工作主要包括以下三个方面:1)尝试更多选择初始训练样本的算法以尽可能提高训练集的价值;2)优化主动学习多标准约束算法以简化筛选过程;3)优化场景结合形式,从而获得更高的预测准确度。
猜你喜欢
疯狂英语·爱英语(2024年1期)2024-03-13 04:08:19
测井技术(2022年3期)2022-11-25 21:41:51
中国煤层气(2021年5期)2021-03-02 05:53:12
记者摇篮(2016年11期)2017-01-12 14:00:35
科技传播(2016年17期)2016-10-09 21:28:06
中国煤层气(2015年4期)2015-08-22 03:28:01
中国质量与标准导报(2015年2期)2015-02-28 22:27:15
学周刊·下旬刊(2014年3期)2014-04-01 05:28:54
语文教学与研究(2014年7期)2014-02-28 21:54:33
西江月·中旬(2013年9期)2013-04-29 02:16:32
