
注入注意力机制的深度特征融合新闻推荐模型
2022-03-01 12:34刘羽茜刘玉奇张宗霖卫志华
计算机应用 2022年2期
刘羽茜,刘玉奇,张宗霖,卫志华,苗 冉
(同济大学电子与信息工程学院,上海 201804)
0 引言
目前互联网信息数据呈指数级增长,从海量数据中发掘价值信息,对用户作出个性化的新闻推荐变得困难。随着深度学习的繁荣发展,许多基于内容的新闻推荐方法被提出:2017 年Okura 等[1]提出了利用自编码器为文章编码并使用循环神经网络为用户编码的方法;2018 年Wang 等[2]提出了通过知识感知卷积神经网络(Convolutional Neural Network,CNN)来提取新闻特征;等等。对这些模型进行对比分析,得到在当前新闻推荐系统中经常存在以下的问题:
1)如何从新闻内容中高效地提取新闻信息是新闻推荐的重要内容,尤其是对长新闻的处理,这需要捕捉文本中的重点词汇,减少无关词汇对语义的影响。例如图1 中的“扶贫”“致富”“人民”,较其他词汇更能代表新闻特征,若能得到重点关注可以有效提高长新闻的特征提取准确率[3]。
2)如何有效建模用户偏好。在图1 中,第一条新闻在建模用户兴趣方面比第五条新闻信息更丰富,因为后者通常被大量不同特征的用户浏览。同时,目前的推荐系统往往在建立用户画像时忽略了将与用户相关的项目特征纳入表征[4],同样在图1 中,前两篇新闻文章是相关的,因为它们都是脱贫致富类的新闻。本文需要解决如何将用户所关注的新闻特征之间的关系进行处理提取。

图1 用户新闻浏览记录示意图Fig.1 Schematic diagram of news browsing history of a user
针对以上问题,本文提出注入注意力机制的深度特征融合新闻推荐模型,具体包括新闻编码模块(news encoder)和用户偏好编码模块(user encoder)。本文主要工作如下:
1)在新闻编码中,为了提取更有效的新闻特征,本文基于加法注意力机制的卷积神经网络(additive attention CNN)学习关键文本,融合新闻文本的上下文特征。
2)基于新闻编码得到的新闻表征,进行用户偏好建模。为了同时建模用户浏览记录的序列特性和浏览内容的特征,本文首先通过门控循环单元(Gate Recurrent Unit,GRU)网络对历史新闻记录进行建模,提取序列特征;而为了进一步建模用户浏览历史的特点,本文还使用新闻级别多头自注意力机制(multi-head self-attention)来捕捉新闻之间的关系;最后基于注意力机制从历史新闻特征中学习用户偏好表征。
1 相关工作
新闻推荐系统已经有了较为成熟的发展,传统的算法可分为基于内容的推荐、基于协同过滤的推荐、混合推荐算法[5]。
基于协同过滤的推荐是将阅读同一新闻的相似用户已浏览新闻作为推荐新闻,考虑相邻用户(或新闻)之间的关联性;但协调过滤缺少用户点击历史的顺序信息利用,无法建模兴趣的动态变化[6]。
基于内容的推荐是对新闻特征和用户兴趣特征显式建模,具有可解释性强的特点,并基于深度学习有了积极繁荣的发展。例如,Okura 等[1]在2017 年提出使用去噪自动编码器学习新闻表征,并使用GRU 网络从用户浏览的新闻中学习用户表征。Wu 等[3]在2019 年提出了多种基于多头自注意力的神经网络新闻推荐(Neural news Recommendation with Multi-head Self-attention,NRMS)模型在单词和新闻层面使用多头注意力机制,挖掘上下文关系与新闻间关系;TANR(neural news recommendation with Topic-Aware News Representation)模型基于卷积神经网络提取新闻特征并附加新闻的主题分类,在新闻特性的提取上有很好的效果[7];LSTUR(neural news recommendation with Long-and Short-Term User Representations)模型使用循环神经网络和id 嵌入方式提取用户长短期兴趣特征[8];NAML(Neural news recommendation with Attentive Multi-view Learning)模型基于卷积神经网络推出了多视角的思想[9]。但基于内容的推荐同样也面临着短板,绝大多数方法采用文章级匹配方式,可能会丢失隐藏在更细粒度新闻片段中的语义特征与兴趣特征[6],忽视了历史新闻之间的联系,在用户画像构建上有所缺失。
本文的工作基于对内容推荐的研究,希望解决上述的基于内容推荐的短板。本文构建了注入注意力机制的深度特征融合新闻推荐模型,希望能够提取更细粒度的语义特征,并将用户浏览行为(时序)考虑到模型中,以获得用户兴趣趋势,以使得基于内容推荐的建模角度更加全面。
2 模型实现方法
如图2 所示,本文基于深度学习构造了一个自主学习用户特征的新闻推荐系统,由基于加法注意力机制的卷积神经网络文本特征提取模型来提取用户浏览新闻的特征与候选新闻特征;对于浏览新闻列表添加由门控制循环单元实现的时序特征提取机制,由加法注意力机制与多头自注意力机制结合的用户特征模型获得用户特征;最后实现一个候选新闻预测排序模型,结合用户特征与浏览历史,对候选新闻进行打分。

图2 本文模型示意图Fig.2 Schematic diagram of the proposed model
为了描述建模过程,本文定义了如表1 所示的变量。

表1 符号的定义Tab.1 Definition of symbols
2.1 基于additive attention CNN 的新闻特征建模
首先要提取本文的特征。为了高效提取文本的上下文关系、局部特征与全局特征,并且通过对重点词汇加权来高效处理长新闻,本文使用卷积神经网络和单词层面的注意力机制建模。
1)将新闻文本从词序列转换为向量序列。将新闻文本表示为(word1,word2,…,wordl),其中l为标题长度;然后将其通过词嵌入矩阵E转换为由词向量构成的矩阵[w1,w2,…,wm],记为Wwords,计算式为:

2)使用CNN 捕捉上下文信息[10]。CNN 层将词向量作为输入,并输出上下文关联的词向量顺序构成的矩阵:

其中:k是卷积核数。
3)加法注意力层。当新闻文本过长时,语义向量可能无法完全表示整个序列的信息,先输入的内容携带的信息容易被后输入的信息稀释。本文为新闻文本注入注意力机制,能够高效地提取关键性信息,降低次要信息的干扰[10]。例如,“深圳龙岗1 份进口的冻鸡翅表面样品新冠病毒检测呈阳性”在未注入注意力机制时,每一个词的含义(词向量值)对整个句子的特征分析结果影响是相等的,即权重相同;但“新冠病毒”是判断本条新闻特征的重点词汇,注入注意力机制,使“新冠病毒”的权重增加,调整其余词汇的权重,能够使神经网络更加高效准确地提取到本新闻具有“医疗”的特征。第i个单词权重为[11]:

其中:Vw和vw是训练的权重矩阵;qw是查询矩阵。

最终输出每一条新闻的特征向量vnews。特征向量达到了高细粒度特征的提取的要求。
2.2 基于时序预测的多头注意力机制用户特征提取模型
为了处理用户浏览时间远近带来的时序特征[12],提取历史新闻之间的关联以及影响用户的重点新闻,本文构建了用户特征提取模型。它包含三层:
1)基于GRU 的神经网络实现的时序预测模块,通过浏览记录列表输出特征矩阵,使得浏览时间的远近能够被纳入考虑。对于编码表征后的历史新闻矩阵Vnews=[vnews1,vnews2,…,vnewsm],用户表征计算[13]为:

其中:t代表时刻;σ是sigmoid 函数;Wr、Wz、是GRU 网络的参数;rt是重置门,代表t时刻之前的信息是否需要重置;zt是更新门,代表t时刻之前的信息是否需要更新;是时刻t的候选隐藏状态;ht是时刻t的隐藏状态;将由远及近的m条新闻记作m个时刻的用户浏览事件。添加时序的用户表征是GRU 网络的最后一个隐藏状态,由它可以得到神经网络预测的未来一个时刻用户将会点击的新闻的特征,记作R=hm。

图3 基于门控循环单元的神经网络结构Fig.3 Structure of neural network based on gated recurrent unit
2)新闻级别的多头自注意力(multi-head self-attention)机制层,能够通过捕捉同一用户阅读各条新闻的之间的关联性,得到用户更加深层的特征,这也是本文要做到千人千面的一个关键步骤。
多头注意力机制由多个缩放点击注意力模块(scaled dot-product attention)基础单元经过堆叠而成[11]。输入是查询矩阵Q、关键词K、关键词的特征值V三个元素。对于输入的新闻组,里面的每条新闻都要和其他所有新闻进行注意力计算,目的是学习同一用户所浏览的新闻之间的关系。
在本文模型中,输入的新闻特征矩阵R=[rnews1,rnews2,…,rnewsdim],其中dim是一个用户的特征向量表征维度,rnewsi是一条新闻的特征向量。取:

其中:Wq、Wk、Wv是可训练权重矩阵。
缩放点注意力机制的计算式为:

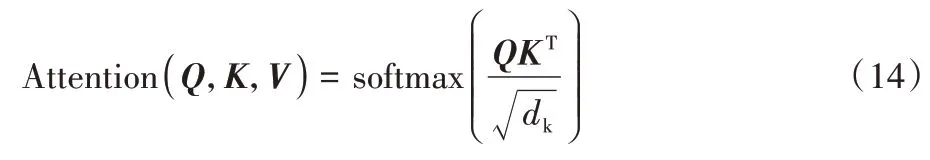
在Multi-head attention 中,Q、K、V首先进行一次线性变换,输入到scaled dot-product attention,这里要做h次,即多头,且每次Q、K、V进行线性变换的参数W是不一样的;然后将h次的scaled dot-product attention 结果进行拼接,再进行一次线性变换得到的值作为Multi-head self-attention 的结果。

将结果记为:

3)附加新闻注意力层,与新闻特征模型中的附加注意力机制原理相同,由于是新闻层面的注意力,所以将词向量修改为新闻特征向量:

其中:Vn和vn是和训练的权重矩阵;qn是查询矩阵。

不同的新闻在代表用户时可能具有不同的信息量。本文应用附加注意机制来选择重要的新闻,以学习更具信息性的用户表示。
综上,通过时序预测与两层注意力机制,输出用户特征向量u。
2.3 推荐预测
损失函数:m条新闻作为正样本,随机选取同类但非已浏览的n条新闻作为负样本。对于某个样本的打分(即点积预测器预测的概率)越高,表明该用户点击这条新闻的概率越大。本文取正样本新闻权重的负数和作为损失:

其中pi表示第i条是否是正例,如果是则取1,否则取0。
3 实验与结果分析
3.1 数据集与实验背景
使用了财新网2014 年3 月的用户浏览行为中文数据集与英文数据集MIND(Microsoft News Dataset)[14]对模型进行测试实验。数据集情况如表2 所示。

表2 数据集情况统计Tab.2 Statistics of datasets
中文数据集包含用户、新闻标题、新闻内容、浏览时间戳。
英文数据集MIND 包含用户、新闻标题、新闻摘要、新闻内容、新闻类别、新闻实体,本文主要用到了前五项。
数据集中训练集、验证集、测试集的划分比例为10∶1∶1。
3.2 实验方法与评估指标
对于任意用户,随机选取已浏览过的m条新闻作为正样本,随机选取同类但非已浏览的n条新闻作为负样本,共m+n条新闻作为候选新闻。用户其余已浏览新闻作为历史新闻,模型使用历史新闻来提取该用户特征。
评估指标如下:
对于候选新闻排序事件s,取S为s的集合,候选新闻共有m+n条。
平均值倒数秩(Mean Reciprocal Rank,MRR):对于一次候选新闻排序事件s,若第一个新闻正样本排在第rank位,则MRR 得分为。

归一化折现累积收益(normalized Discounted Cumulative Gain,nDCG):

其中:ci表示是否是正样本,是则取1,不是则取0。
3.3 参数设置说明
本文基于Tensorflow 实现模型,具体的模型参数如表3所示,优化器使用Adam[15]。

表3 超参数取值Tab.3 Hyperparameter value
3.4 实验结果与分析
将本文方法与近年来的先进新闻推荐算法进行对比:如NRMS[3]、TANR[7]、LSTUR[8]、NAML[9]模型,以及基于知识卷积神经网络的DKN(Deep Knowledge-aware Network for news recommendation)模型[2],这些方法都是基于内容和基于神经网络的新闻推荐模型,与本文模型相近,这使得对比实验更具有意义。
模型每批次64 个用户新闻推荐排序事件,每100 批次为一个epoch,以20 个epoch 的nDCG 与MRR 都未提升作为收敛标志,记录了收敛时间。对于每个模型均进行了10 次重复实验,并取各指标的平均值。
如表4 所示,在中文数据集中,本文模型具有收敛快、正样例能获得权重最高的优势。相较于对比模型,对nDCG 平均提升率为2.59%,提升区间为-0.22%~4.91%;对MRR 的平均提升率为2.08%,提升区间为-0.82%~3.48%,与唯一为负的比较模型LSTUR 相比,收敛时间缩短了7.63%。这意味着本文模型对新闻的特征区分更有优势,是因为本文使用了卷积神经网络结合注意力机制,可以获得新闻更细粒度的特征。而nDCG 与MRR 与LSTUR 的值相当,本文模型与LSTUR 同样使用了CNN 进行新闻表征和GRU 提取新闻关联性和时间性,这一方面再次验证了CNN 在文本表征上的高效性,同时也推测用户所浏览的新闻的时序能够较好地体现用户的特征。同时,本文模型在收敛时间上也最具优势,尤其是与同样使用了多头自注意力机制的NRMS 模型相比,由于NRMS 在词汇级上也使用了多头注意力机制来提取上下文关系,效率上远低于本文使用的卷积神经网络。

表4 不同模型在中文数据集的实验结果Tab.4 Experimental results of different models on Chinese dataset
如表5 所示,首先,在英文数据集中,本模型的各项指标均是最佳的,相较于对比模型,对nDCG 平均提升率为0.71%,提升区间为0.07%~1.75%;对MRR 的平均提升率为0.72%,提升区间为0.03%~1.30%。收敛时间略低于TANR和NAML,这可能是因为本文模型考虑的角度更加全面带来的计算量的增加。其次,LSTUR 模型与本文模型的评估指标依旧相近,再次验证了上文的结论。同时,与DKN 模型相比,因为DKN 模型使用了大量的实体导致计算时间大量延长,且DKN 模型没有使用注意力机制和时序模块,各项指标也弱于本文模型。最后,模型较LSTUR 增加了注意力机制,能够使候选新闻中正例的被点击概率评分更高,体现了本文模型更加具有敏锐性。

表5 不同模型在英文数据集的实验结果Tab.5 Experimental results of different models on English dataset
关于注意力机制在本文模型的有效性验证,本文控制了单一变量,进行了无注意力机制(no attention)、只有单词层面注意力机制(words attention)、只有新闻层面注意力机制(news attent)和两个层面的注意力机制皆有(both attention)四组实验,在中文数据集中的实验结果如表6 所示。词汇层次和新闻层次的注意力机制同时存在时较无注意力机制时nDCG 有最大提升率10.33%,MRR 有最大提升率17.97%。由于中文词义的丰富性以及划词的特殊性,实验结果更具说服力。首先,注意力机制在词语层面的注意显著提高了模型的效果,这是因为对单词之间的相互关系进行建模和选择重要的单词可以帮助学习信息丰富的新闻表示;此外,新闻层面的注意力机制也是非常有效的,而且,将词汇和新闻层面的注意力机制结合起来可以进一步提高本文模型的性能。
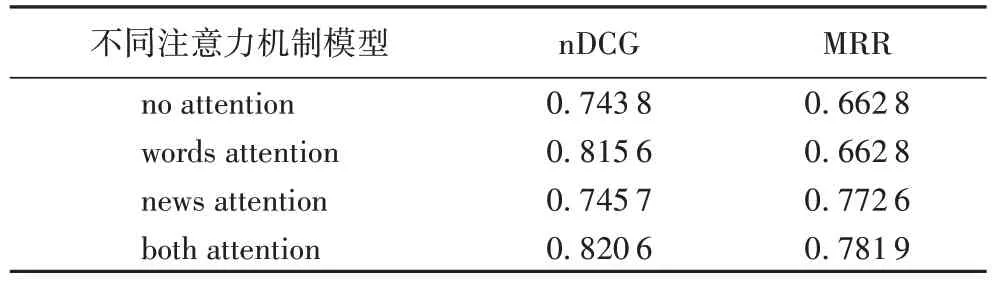
表6 不同的注意力机制性能对比Tab.6 Performance comparison of different attention mechanisms
关于使用GRU 来捕捉用户关注新闻的时序特征来提取兴趣变化趋势,对本文模型做了有无时序预测模块的对比实验,并计算出模块对模型各项指标的提升率,结果如表7所示。

表7 本文模型有无时序预测模块时的对比实验结果Tab.7 Comparison experimental results of the proposed model with and without time series prediction module
可以看到,时序预测模块对模型效果有明显的提升作用。这可能是因为用户近期的浏览内容更加能表达用户的特征和偏好,通过时序模块也能刻画用户偏好变化趋势,起到对未来偏好的预测效果。
综上,通过中英文数据集的各项对比实验结果表明,本文模型具有优良的性能和良好的适应性,高效简捷;同时,本文方法在计算点击概率得分时不需要记住用户的新闻浏览历史,可以通过并行计算注意力机制,使得它也能够在大规模场景上也有良好的表现。
4 结语
本文通过附加注意力机制与卷积神经网络提取新闻文本的特征,继而构建添加时序预测的加法注意力机制与多头自注意力机制结合的用户特征模型,做到了文本层面对重点词汇的关注、上下文关联的提取、用户层面对浏览记录的重点新闻关注和新闻相互关联的深度提取,最后实现了一个候选新闻预测排序模型。
在未来的工作中,希望加入新闻位置信息与词汇位置信息参数,提高网络的精准性与时效性;同时将考虑结合图神经网络,挖掘用户与用户之间、用户与新闻之间、新闻与新闻之间的深层关系。
猜你喜欢
导航定位学报(2022年5期)2022-10-13
农业工程学报(2022年12期)2022-09-09
舰船科学技术(2022年11期)2022-07-15
中国教育信息化·高教职教(2022年4期)2022-05-13
计算技术与自动化(2022年1期)2022-04-15
小猕猴智力画刊(2022年3期)2022-03-28
农业工程学报(2022年1期)2022-03-25
煤气与热力(2022年2期)2022-03-09
意林·作文素材(2021年23期)2021-01-22
上海师范大学学报·自然科学版(2019年5期)2019-12-13
