
融合全局结构信息的拓扑优化图卷积网络
2022-03-01 12:33:46高金辉赵晓梦李佳宁
计算机应用 2022年2期
富 坤,高金辉,赵晓梦,李佳宁
(河北工业大学人工智能与数据科学学院,天津 300401)
0 引言
在许多领域中,越来越多的数据以图的方式呈现,如通信网络中的信息传播、生物网络中的蛋白质交互、社交用户的偏好和交际关系[1-2]等,因此,通过对图数据进行网络表示学习并对其深入挖掘有较高的研究价值和现实意义。在相关研究中,网络信息的表示是一个重要的问题。本文主要针对基于拓扑优化的图卷积网络(Topology Optimization based Graph Convolutional Network,TOGCN)无法表达全局结构信息的问题进行研究。
图卷积神经网络(Graph Convolutional Neural Network,GCNN)是卷积神经网络(Convolutional Neural Network,CNN)[3]在图数据上的一种推广,是近期进行网络表示学习的一类重要模型[4-6]。Bruna 等[7]提出将GCNN 根据定义卷积的方式分为两种:
1)基于谱域的GCNN 以卷积定理和图谱理论作为理论基础,利用拉普拉斯矩阵定义图中的傅里叶变换,并使用不同的滤波器进行图数据的特征提取。Spectral CNN 模型将滤波器定义为一组可学习参数,使用了多通道滤波器对图数据进行特征提取。ChebNet(Network with Chebyshev polynomials)模型[8]使用切比雪夫多项式来近似图卷积滤波,用多项式的阶数K控制卷积核的参数数量,减少了图卷积的参数,降低了计算复杂度。Kipf 等[9]提出了图卷积网络(Graph Convolutional Network,GCN)模型对ChebNet 进行简化,使用的卷积滤波近似于一阶切比雪夫滤波,该模型同时属于基于谱域和基于空域的GCNN 模型。Levie 等[10]提出了CayleyNet(Network with Cayley polynomials)模型使用一个定义于复空间的函数Cayley 多项式近似卷积滤波来捕获窄频带。谱域GCNN 优势在于具有扎实的理论基础,便于研究人员对其运行机制进行挖掘,但该类模型只能应用于无向图中,且在图发生变化时模型的适用性较差。
2)基于空域的GCNN 主要考虑节点的空间关系,节点更新是对其邻域节点特征进行聚合的过程。Micheli[11]提出了NN4G(Neural Network For Graphs)模型累加邻域节点信息进行特征聚合,并使用剩余链接和跳跃链接的方式记忆每一层的节点信息。Atwood 等[12]提出DCNN(Diffusion-CNN)模型把图卷积看作是节点信息扩散的过程,假设每个节点的信息以一定的概率转移到相邻节点。相较于谱域GCNN,空域GCNN 的卷积过程更加灵活。
传统的GCNN 一般通过原始的拓扑图进行节点向量的学习。虽然使用原始的拓扑图进行学习有益于模型的可解释性,便于分析图数据的特性,但由于图数据关系的稀疏性,原始的拓扑图中会带有噪声,不利于学习节点表示向量。为了解决这个问题,研究人员们提出了TOGCN,该类模型根据节点属性等特征优化拓扑图。Veličković 等[13]提出的GAT(Graph Attention Network)模型利用注意力机制确定每个邻居节点对中心节点的重要性,将其作为新的网络拓扑图中的边权重。Li 等[14]提出的AGCN(Adaptive Graph Convolutional Network)模型使用广义马氏距离替代欧氏距离来计算节点之间的距离,更新拓扑矩阵的残差矩阵。Vashishth 等[15]提出的Conf-GCN(Confidence-based GCN)模型对每个节点都设置一个关于其标签分布的置信度向量,根据两相邻节点的置信度差异对拓扑图进行更新,Jiang 等[16]提出的图学习卷积网络(Graph Learning-Convolutional Network,GLCN)模型则利用相邻节点属性相似度来约束其链接权重,并对图拓扑优化训练与图卷积训练进行集成,提高了模型的优化效率。
虽然TOGCN 很好地衡量了相邻节点间的关联程度,但仍存在以下问题:1)忽略了全局信息对节点表征的影响;2)不能很好地处理由于信息缺失带来的模型性能下降的问题。
本文针对以上两个问题,对TOGCN 中的一个经典模型GLCN 进行改进,提出融合全局结构信息的TOGCN(Global structural information Enhanced-TOGCN,GE-TOGCN)模型,该模型通过运用GLCN 的图学习方法保留了拓扑优化在学习节点邻域信息方面的优势;同时以类中心向量作为网络的全局向量,将其与类标签同时作为节点的类辅助信息进行训练。先利用标记节点计算类中心向量,而后利用部分未标记节点更新类中心向量,再使用新的类中心向量更新节点表示向量,使模型能够同时学习到丰富的局部信息和全局信息。
1 相关工作
在这部分,本文主要介绍网络表示学习与全局结构信息的概念,介绍用于网络表示学习的经典模型GCN 的谱域图卷积原理。
1.1 网络表示学习
网络表示学习[17]目的是学习节点低维稠密的特征信息,得到的低维节点特征不仅能在最大化保留原有网络信息的情况下减小节点特征的存储空间,而且降低了图中冗余噪声信息的影响,再将这些节点特征用于后续的网络数据分析任务。
1.2 全局结构信息
全局结构信息[18]可表示为非相邻节点间存在的结构关系或网络本身存在的某种特征信息,如子图、路径等。本文中使用类信息作为全局结构信息,来捕获节点的类特征。
1.3 谱域图卷积原理
CNN 在不需过多先验知识的情况下仍保持着强大的特征提取能力,被广泛应用于图像处理、计算机视觉等领域中。但CNN 只能处理网格数据,即每个节点的邻域节点数量要保持一致,而图数据中每个节点的邻居数量并不固定,不符合CNN 卷积的前提条件,因此,GCNN 设计了适于处理图数据的非欧氏卷积核。
CNN 中的卷积过程可以表示为输入信号与卷积核经傅里叶变换后乘积的逆变换,傅里叶变换的目的是通过一组正交基将输入信号由空域投影到频域中,本质上是时域信号与正交基的内积运算。正交基为拉普拉斯算子的特征函数,推广到图上时,由于拉普拉斯矩阵是拉普拉斯算子的离散形式,因此拉普拉斯矩阵的特征向量集合就可看作是GCNN 的一组正交基。下面以图输入信号为例,简要叙述图中的傅里叶变换过程。
首先定义图的拉普拉斯矩阵:

其中:D代表度矩阵;A代表图的拓扑矩阵。
假设图为无向图,则矩阵L为对称矩阵,因此可分解为:

其中:Λ为矩阵L的特征值矩阵;U为对应于Λ的特征向量组成的矩阵。
那么在图中的傅里叶变换过程可表示为:

其中:N代表图中节点个数;f*(λl)代表图信号在第l个特征值λl对应的特征向量上的投影;f(i)代表图信号第i个节点的信号值;ul(i)表示第l个特征值对应的特征向量在节点i上的分量。则在全图中的图信号傅里叶变换可表示为:

类似地,定义傅里叶逆变换为:

定义卷积核为g,则图的卷积过程可表示为:

2 GE-TOGCN模型设计
本文提出的GE-TOGCN 模型整体结构如图1 所示。通过一个含有5 个节点,且节点分为2 类的图来表示模型中节点表示向量的计算过程,其中:x1,x2,…,x5表示5 个节点的高维向量;z1,z2,…,z5表示经训练后各节点的低维表示向量;μ1和μ2表示两类的类中心向量。

图1 GE-TOGCN模型整体结构Fig.1 Overall structure of GE-TOGCN model
本文模型主要包括以下部分。
1)图拓扑优化层:沿用GLCN 的拓扑优化方式,学习一个最优的拓扑图来表示节点间更准确的相互关系。
在图拓扑优化层中引入类中心向量作为图中的全局结构信息,通过维持准则将类中心向量与节点表示向量关联起来,使得节点可以更准确地学习到类内节点与类之间的结构关系。依据以下步骤进行类中心向量计算与基于全局正则化的节点表示更新:首先利用标记节点向量定义初始类中心向量;然后利用未标记节点更新类中心向量,从而使计算出的类中心向量可以更好地代表类内节点的整体情况;最后根据全局正则化规则使用更新后的类中心向量更新节点表示向量。
2)图拓扑优化损失LGTO:该损失函数通过计算两个相邻节点属性向量的距离来修正优化后的拓扑图中两个节点之间的连接权重。
3)图卷积层:将学习好的拓扑图进行卷积操作得到节点的低维表示向量。
4)半监督损失Lsemi:该损失函数利用交叉熵损失来降低每一个给定标签节点的表示向量与真实类标签之间的差异。
2.1 图拓扑优化层
在本层中,给定图的属性矩阵,目的是学习一个可优化的相似矩阵S。图拓扑优化层具体计算步骤如下:
给定一个输入X=(x1,x2,…,xN)∈RN×p,先通过一个全连接神经网络层学习一个节点的低维属性表示向量H,而后使用一个添加注意力机制的神经网络层拟合一个映射函数Sij=m(hi,hj),Sij代表由第i个节点的低维表示向量hi与第j个节点的属性hj由函数m映射后得到的节点i与节点j之间的相似程度,如式(7)~(8)所示:

其中:WL为神经网络层的权重矩阵;b为偏置向量;ReLU(·)=max(0,·)代表激活函数,保证拓扑图矩阵S中每一个元素非负;a为注意力向量,用于学习每一个邻居节点j对节点i的重要程度。先通过使用注意力向量与连接节点之间的距离来计算两节点之间的连接相似性,再使用softmax 操作对相似权重进行归一化,目的是满足矩阵S每一行元素相加为1,有利于简化模型在图卷积层中的计算过程。在拓扑优化层中使用式(9)所示损失函数优化图拓扑矩阵S:

式(9)表示:若节点i和节点j属性向量之间的差距较大,则两节点之间的相似度会较小,第二项对相似度矩阵做了正则化来控制该矩阵的稀疏性。该损失函数通过计算两个相邻节点属性向量的距离来修正优化后的拓扑图中两个节点之间的连接权重。
2.2 图卷积层
在学习到优化后的拓扑图后,将其作为新的图卷积核进行卷积操作,共同提升图拓扑优化和图卷积的表现。在一个完整的图拓扑优化神经网络结构中包含多个图卷积层,每层的传播规则如式(10)所示:
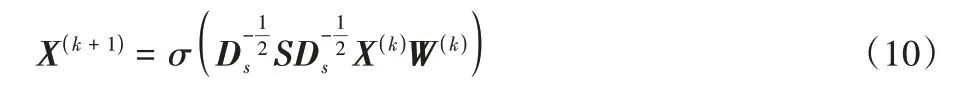
其中:k代表卷积的层数;DS=diag(d1,d2,…,dn)是关于S的一个对角矩阵,di=为节点i在优化图S中的“度”,使用DS对矩阵S进行归一化可以消除梯度消失和梯度爆炸对模型的影响;W(k)代表第k层卷积层中的权重矩阵;σ(·)代表激活函数,在中间层设置为ReLU(·)=max(0,·)函数保证向量非负;X(k+1)代表经过第k层卷积得到的节点特征向量。由于优化后的图S本身满足行相加为1 的条件,不需要使用DS对S进行归一化,因此可简化为式(11):

对于半监督学习任务,最后一层的输出如式(12)所示:

其中:C代表类的个数;Z为模型最终输出的节点表示向量;zi表示第i个节点的表示向量。
由于TOGCN 是基于半监督学习的图模型,因此该模型引入部分节点的标签向量,通过交叉熵函数减小标签向量与对应节点表示向量之间的距离,损失函数如式(13)所示:

其中:Y为部分给定的|Nlabel|个标签向量;Z为对应的节点向量。
TOGCN 模型的总损失函数如式(14)所示:

损失函数的第一部分利用交叉熵损失来降低每一个给定标签节点的表示向量与真实类标签之间的差异;第二部分为图拓扑优化层的损失函数,使用参数θ表示图拓扑优化层损失函数所占比重。
2.3 维持全局结构信息的正则化准则
在TOGCN 中,虽然使用注意力机制和相邻节点的属性信息来获取节点间实际的链接权重,但并没有考虑到全局结构信息对节点的影响。Li 等[19]提出的LGAE(Local-Global AutoEncoder)模型定义了全局信息维持准则,并将类中心向量作为全局信息加入模型中,实验结果表明加入该信息后分类任务的准确率有一定的提升。受该模型的启发,为了更好地量化全局结构信息与节点属性信息之间的关系,本文使用类中心向量更新节点表示向量,并利用部分节点的真实标签优化类中心向量。具体来说,在图中每个类都设置一个软类标签,即类分布中心向量,使节点的表示向量接近于该向量。
LGAE 模型使用一个虚拟二部图G来对节点与类之间的关系进行描述并定义全局信息维持准则:定义二部图G=((V,Vˉ),E)为节点集合V与Vˉ之间、边权重为E的无向图。对于一个被分为C个类的图,顶点集分别为图数据样本V和数据类分布中心Vˉ,E代表数据样本和类分布中心之间的连接权重矩阵,可看作是样本与类向量之间的相似程度。将第c(c∈C)个类的类中心分布向量定义为μc(x(Vc)),Vc代表第c个类的节点集合,x(Vc)代表第c个类节点集合中节点的高维向量,则Vˉ可表示为类中心分布向量的集合,即Vˉ=[μ1(x(V1)),μ2(x(V2)),…,μC(x(VC))]。全局嵌入的目的是建立一个映射g*:V→g*(x(V)),该映射要满足:若数据样本高维向量xi接近于第c类的分布中心μc(x(Vc)),那么作为样本节点的低维表示向量,g*(xi)也应当接近于低维的类分布中心μc(g*(x(Vc))),因此,维持全局结构信息的准则如式(15)所示:

其中:μc(g*(x(Vc)))表示与第c类相对应的类分布中心向量(以下简称为μc);B是一个关于映射矩阵G*的约束矩阵。全局图嵌入寻求一种低维表示,来保持数据样本和对应类分布中心之间的邻近性。全局信息嵌入可以将同一类的表示数据映射到对应类分布中心附近,因此,它可以降低类内差异。
下面介绍维持全局结构信息的准则中相似度e的选取方式。现有图卷积网络模型中通常用两种方式设定相邻节点间的连接权重:
1)高斯核权重。该方法使用高斯核函数来度量两个向量之间的相似程度,函数如式(16)所示:

其中:xi与xj代表节点i与j的属性向量。高斯核函数可以将低维的向量投影到无穷维来度量两个向量的相似度,并使用参数σ控制函数的径向作用范围。即若σ减小,则在两向量距离减小时,两个向量的相似度会更明显地增大。
2)相同权重。即节点与所有相连节点之间的相似度e相同,如式(17)所示:

若节点i是节点j的邻居节点,则节点i对于节点j的相似度为1;若节点i与节点j无连接关系,则i对于j的相似度为0。
在正则化损失中,若选用第一种方式定义权重会削弱距离类中心向量较远的节点对损失函数的影响,因此本文选用第二种方法来设定节点与类节点之间的相似度e。
2.4 类中心向量计算与基于全局正则化的节点表示更新
本文同时使用标记节点与未标记节点计算类中心向量,将节点根据2.3 节中的全局正则化准则,使用更新后的类中心向量更新节点的表示向量,并利用标记节点的真实标签对类中心向量与节点表示向量进行优化。
本文先使用标记节点的表示向量计算初始类中心向量,具体来说,每类的初始类中心向量为该类中全部标记节点的表示向量的平均值,如式(18)所示。
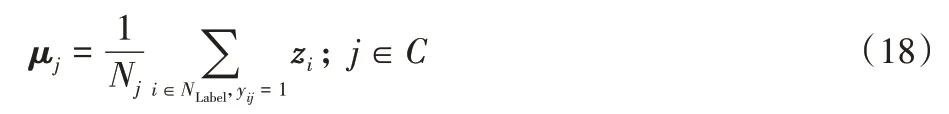
使用标签向量计算类中心之后,需要使计算出的类中心更接近类内全部节点的中心,因此,在计算过程中不仅要考虑标记节点,也需要考虑未标记节点的情况。Shoestring 模型[20]根据未标记节点表示向量与当前的类中心向量之间的相似度将部分未标记节点分配至对应的类,综合考虑当前类的中心向量和这些未标记节点的情况,重新计算类中心向量,从而使计算出的类中心向量可以更好地代表类内节点的整体情况,经实验表明由该向量优化后的节点表征在标签较少时具有良好的性能。
受该模型启发,本文增加了类中心向量的更新过程,并使用类中心向量进行节点表示的更新工作。在每一次迭代过程中,根据未标记节点的表示向量与当前计算出的类中心向量的相似度,利用部分相似度排名高的未标记节点更新对应的类中心向量,而后根据更新后的类中心向量将节点分配到其最接近的类中,并利用半监督损失函数来保持标记节点的表示向量与更新后的对应类中心向量之间的邻近性(节点的表示向量代表该节点从属于每类的概率)。
具体来说,计算未标记节点向量对更新后类中心向量的贡献权重与对应的贡献向量,根据权重将更新前类中心向量与未标记节点的贡献向量相加,更新后的类中心向量用于节点表示向量的更新。具体计算步骤如下所示:
1)设定未标记节点的分配比例k∈[0,1],将每类中100k%个未标记节点分配到每类中。而后,使用softmax 函数计算未标记节点分配到各个类别的概率,计算公式如式(19)所示:

其中:i表示未标记节点;c∈C为类别;zi为当前模型中节点i最后一层的输出向量;j为节点i所属的类别;μj为第j类的类分布中心向量;eij代表节点i与类j之间的边权重。
2)对于每一个类别,将所有未标记节点根据从属于该类别的概率p(i∈c)进行排序,并根据设定的节点抽取比例k将从属概率排名前100k%的节点抽取出来,后续将根据这些节点的表示向量计算新的类中心向量。
3)计算每个分配到各类的未标记节点向量对于对应类中心向量的贡献权重。①对于每个类,将该类中所有分配的未标记节点的分配概率相加作为未标记节点的初始贡献权重基数。②为了根据给定标签节点的情况自适应调控分配的未标记节点对更新后类中心向量的贡献权重,统计该类中标记节点的总数,将该总数与未标记节点的初始贡献权重基数相加得到该类中所有未标记节点的最终贡献权重基数。这样计算后,若每类给定的标记节点较少,那么未标记节点的总贡献权重相对较高。因为若给定标签节点较少,那么由给定标签节点表示向量计算出的类中心向量个例性太强,相对不可靠,就需要增加未标记节点的贡献权重调整类中心向量。③节点自身分配概率p计算出的贡献权重基数的比值即为该节点向量对其所分配类的类中心向量的贡献权重,计算方法如式(20)所示:

4)计算各类中未标记节点向量与更新前类中心向量的差异向量,计算公式如式(21)所示:

5)对于分配到某个类的未标记节点,它的贡献向量为该节点的贡献权重与差异向量的乘积。对于类别c,将更新前第c类的类中心向量与被分配到该类的所有节点的贡献向量相加就可以得到更新后的类中心向量,计算过程如式(22)所示:

6)参考全局正则化准则与Shoestring 模型中节点的重分配过程,通过节点与类中心向量的欧氏距离计算节点属于每类的概率,将其作为更新后的节点表示向量。通过进行softmax 操作,可以增大类内节点的相似性与不同类节点间的差异性,计算方法如式(23)所示:

经过上述步骤,完成了对类中心向量与节点表示向量的更新工作。由于融合了未标记节点的类信息,因此在更新之后,每类的中心向量可以更好地表示该类节点的整体聚合趋势。
得到更新后的节点表示向量后,通过交叉熵损失函数减小节点预测类向量与对应节点真实标签向量之间的距离(标签向量矩阵定义为Y,yij表示第i个节点标签向量在第j类上的分量),计算方法如式(24)所示:

GE-TOGCN 模型总损失函数LGE-TOGCN由LGTO和Lsemi两部分构成,计算方式如式(25)所示:

其中:λ1,λ2∈[0,1]是LGTO和Lsemi的权重控制参数。
2.5 GE-TOGCN模型伪码
GE-TOGCN 模型伪码如下所示:

3 基于GE-TOGCN的实验与结果分析
为评估模型GE-TOGCN 的性能,使用Cora、Citeseer 两个真实数据集在完成模型训练后进行节点分类和可视化任务实验,选用的对比模型为原模型GLCN[16]、谱域图卷积网络模型ChebNet[8]、图卷积网络模型GCN[9]与同样基于拓扑优化策略的信任图卷积网络模型Conf-GCN[15]。
3.1 实验设置
本文实验环境是基于Windows 10 系统,内存为8 GB 的CPU 环境,编程语言为Python3.6,实验框架为Tensorflow。
实验数据集Cora 是一个包含多个领域的机器学习论文的引文数据集,论文根据类型分为基于事例、基于遗传模型、基于神经网络模型、基于概率模型、基于强化学习、基于规则学习和基于理论共7 类,共2 708 篇文章。在预处理过程中,将每篇文章中所有频数大于10 且有实际意义的词语(无意义词语如“的”“有”等)提取出来构建一个词汇表,词汇表中单词的个数即为论文属性的个数。经提取后Cora 数据集属性个数为1 433。
实验数据集Citeseer 是由论文数据库Citeseer 上提取的部分论文组成的引文数据集,分为代理技术、人工智能、数据库、信息检索、机器学习和人机交互共6 类。共选取3 327 篇论文,词汇表中单词个数为3 703。
两个数据集的详细信息如表1 所示。

表1 数据集详细信息Tab.1 Details of datasets
在两个数据集中,每一类分别从原训练集随机抽取1、2、5、10 个节点作为训练集来模拟标签信息缺失的情况(每类抽取部分标签即代表缺失训练集中其他节点的标签信息),选择500 个节点作为验证集,1 000 个测试节点作为测试集,进行节点分类任务。模型由一个图拓扑优化层与两个图卷积层构成,图拓扑优化层隐藏单元数为70,图卷积层中第一层隐藏单元数为30,第二层需根据数据集类的个数具体设定。设置最大训练迭代次数为10 000,使用Adam 优化器[21]进行参数优化,学习率设置为0.05。如果验证损失在100 次内没有下降,则提前停止训练。
3.2 基于GE-TOGCN的实验结果与分析
完成模型训练后,分别使用测试集进行节点分类和可视化任务。
1)GE-TOGCN 在节点分类任务中的实验结果与分析。
将模型训练后得到的节点表示向量与真实标签向量进行比较,使用Micro-F1 指标[22]计算节点分类的准确率。由于抽取标记节点时具有随机性,因此将模型重复运行10 次,计算平均分类准确率作为最后的分类结果。节点分类准确率如表2~3 所示。

表2 Cora数据集上的节点分类准确率 单位:%Tab.2 Node classification accuracy on Cora dataset unit:%

表3 Citeseer数据集上的节点分类准确率 单位:%Tab.3 Node classification accuracy on Citeseer dataset unit:%
可以看出,在缺失标签信息的情况下,GE-TOGCN 的分类精度优于基准模型及GLCN 模型。根据分类结果,改进后的模型与次优的模型相比,在Cora 数据集上的分类准确率提高了1.2~12.0 个百分点,在Citeseer 数据集上分类准确率提高了0.9~9.9 个百分点。实验结果分析如下:
ChebNet 利用切比雪夫高阶展开式近似图的卷积过程,简化了原始图卷积过程的计算,同时加强高频信号的作用,但高频信号对节点分类效果产生了一定的负面作用。GCN简化了ChebNet,使用重归一化加强了低频信号的作用,所以优于ChebNet 中节点的分类效果。Conf-GCN 对每个节点都设置了类分布向量作为节点的信任向量,根据邻接节点的分布向量与分布方差计算两者之间的相似度来优化拓扑矩阵。GLCN 与Conf-GCN 分别利用相邻节点的属性相似度与节点的信任向量优化拓扑矩阵,为模型提供了额外的弱监督信息。在标记节点较少时,这些弱监督信息会帮助节点学习到更准确的表示向量,因此性能优于GCN;但这两种方法只能使相邻节点信息更准确地进行传播,而对于非相邻节点的类相似度考虑不足。GE-TOGCN 在GLCN 的基础上融合了全局结构信息,量化了非相邻节点的表示信息与全局类信息之间的关系,因此在训练节点较少的情况下,通过标记节点与非标记节点的双重作用,模型可以更充分地利用标记节点的标签信息,并利用全局类信息更好地表示该类节点的整体聚合趋势,分类效果优于TOGCN。
2)GE-TOGCN 在节点可视化任务中的实验结果与分析。
在节点可视化任务中,本文使用t-SNE(t-distributed Stochastic Neighbor Embedding)模型[23],通过非线性降维的方式将学习到的最终节点表示向量投影到二维空间。图2 中的点表示测试集中各节点表示向量经投影后的二维向量,点的颜色表示类别。由于模型分类结果会随着选取标签的质量上下浮动,因此运行结果会存在偏差,本文选择10 次结果中分类准确率最接近平均值的一次完成可视化任务。从图2 中可以看出,GE-TOGCN 模型比基准模型类内节点的聚合程度更高,不同类簇之间边界划分更清晰。实验结果说明加入类中心向量后,每类类内节点具有更强的聚合性,不同类节点间具有更明显的差异性。

图2 Cora数据集上每类标签节点个数为5时的可视化结果Fig.2 Visualization results with 5 label nodes per class on Cora dataset
4 结语
本文针对TOGCN 仅对邻接节点之间的连接关系进行优化,却忽略全局结构信息的问题进行了改进,将类向量作为全局结构信息融入到节点信息中,使得节点可以在学习局部信息的同时在低维空间中保持高维空间中节点与对应类之间的几何结构。在Cora 与Citeseer 上进行了模型训练和下游任务实验,节点分类任务实验结果表明,引入类信息作为全局结构信息可以提高在标签信息缺失的情况下节点分类的准确率;节点可视化任务实验结果显示,改进后的模型可以增强同类节点之间的内聚性,同时增强不同类节点间的差异性。实验结果表明,加入类全局信息有助于提高原模型在标签信息缺失时的鲁棒性,同时节点能够表现出更明显的类特征。
致谢:感谢天津大学金弟老师为本文研究提出的建设性意见。
猜你喜欢
数学物理学报(2022年4期)2022-08-22 04:07:12
数学物理学报(2022年2期)2022-04-26 14:08:04
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
电子制作(2019年11期)2019-07-04 00:34:38
金桥(2018年4期)2018-09-26 02:24:54
车迷(2018年11期)2018-08-30 03:20:32
海峡姐妹(2018年3期)2018-05-09 08:21:02
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
公民与法治(2016年10期)2016-05-17 04:12:58
计算机工程(2015年8期)2015-07-03 12:20:27
