
面向集群网络的全序数据传输策略研究
2022-03-01 06:04:06王春辉
智能计算机与应用 2022年1期
王春辉
(启东市第二中等专业学校,江苏 启东 226200)
0 引言
在诸如集群的分布式系统中,当一台主机读取或写入不同远程主机上的多个对象时,无法保证消息同时到达不同的远程主机,通常需要加锁来实现一致性;另外,分布式数据的多个分片生成日志到多个副本,每个副本可能会以不同的顺序从分片接收日志,从而违反数据一致性。由此可知,数据传输的顺序严重影响着分布式系统的性能。对此,本文提出了一种全序数据传输框架,即TOC 框架。在TOC中,消息按组发送并在虚拟管道中序列化,这样一来不同的接收方进程能够以一致的顺序从发送方进程传递消息。TOC 框架由提供尽力而为数据传输服务的TOC-BE 策略和提供可靠传输的TOC-Re 策略组成。
1 尽力而为全序数据传输策略设计
1.1 消息和屏障时间戳机制
尽力而为全序数据传输(TOC-BE)发送方为每条消息分配一个非递减的时间戳,分散传输中的消息具有相同的时间戳。同步主机的单调时间,并使用本地时钟时间作为消息时间戳,消息时间戳确定接收方的交付顺序,接收方按照时间戳的升序发送到达消息。
当接收者传递带有时间戳的消息时,必须确保其已经收到并传递了所有时间戳小于的消息。一种简单的方法是只传输时间戳不减少的消息,并丢弃所有无序消息。然而,由于不同的网络路径具有不同的传播和排队延迟,这种方法会丢弃太多消息。对此,引入了屏障时间戳的概念,屏障时间戳与链路或节点相关联,表示所有未来到达消息的消息时间戳的下限。每个接收者维护自己的屏障时间戳,并传递时间戳小于屏障时间戳的消息。
TOC-BE 利用网络排队结构,使时间戳下限聚合更具可扩展性和效率。TOC-BE 利用可编程交换机来聚合屏障时间戳信息,接收端根据交换机提供的屏障时间戳信息对消息进行重新排序。
在TOC-BE 中,为每个消息包附加了两个时间戳字段:第一个是消息时间戳字段,由发送方设置,不会被修改;第二个字段是屏障时间戳,由发送方初始化,交换机进行修改。交换机或主机从网络链路接收到屏障时间戳为的数据包时,意味着未来来自链路的到达数据包的消息时间戳和屏障时间戳将大于。
为了计算屏障时间戳,发送方使用非递减的消息时间戳,初始化消息中所有数据包的字段。交换机为每个输入链路∈维护一个寄存器R,其中是所有输入链路的集合;再将具有屏障时间戳的数据包从输入链路转发到输出链路后,交换机首先更新寄存器R=B,然后将数据包的屏障时间戳修改为B=minR。
每个交换机以这种方式计算屏障时间戳,屏障时间戳通过交换机进行逐跳的聚合,最终接收方获得网络中所有可达主机和链路的屏障。
当接收方收到一个带有屏障时间戳的数据包时,首先将数据包缓存在一个优先级队列中,该队列根据消息时间戳对数据包进行排序。接收者知道所有未来到达数据包的消息时间戳将大于,因此其将消息时间戳低于的所有缓冲数据包传递给应用程序进行处理。如果应用程序进程收到时间戳大于的消息,则将其丢弃,并向发送方返回一条NAK 消息。由此可知,无序的消息不会违反正确性。
为了在Lamport 逻辑时钟上保持因果顺序,本地时钟时间应该高于传递的时间戳。每个进程都有发送者和接收者的角色,而收到的屏障是从包括在内的所有发送者聚合的。由于本地时钟是单调的,当收到屏障时,的时间戳高于。
1.2 信标机制设计
空闲的链路会影响屏障时间戳的计算,为了避免空闲链路的影响,会定期在每个链路上发送信标。与消息包不同,信标包只携带屏障时间戳字段,没有有效载荷数据。
主机和交换机都可以发送信标数据包,目的地是其一跳邻居。对于主机生成的信标,屏障时间戳是主机时钟时间。交换机使用本地屏障时间戳来初始化信标的屏障时间戳,当主机或交换机输出链路在信标间隔时间T内没有观察到任何消息包时,其会生成一个信标包。
当主机、链路或交换机发生故障时,其邻居的屏障时间戳会停止增加。为了检测故障,每个交换机的每个输入链路都有一个超时计时器,如果在特定的时间内没有接收到信标或数据包,则认为输入链路已失效,并从输入链路列表中删除,移除故障链接后,屏障时间戳恢复增加。
2 可靠全序数据传输策略设计
2.1 丢包处理机制
在可靠全序数据传输(TOC-Re)策略中,当接收者发送带有时间戳的消息时,必须确保已经发送完时间戳少于的所有消息。因此,如果接收方不知道数据包丢失,则无法根据屏障时间戳可靠地传递消息,采用两阶段提交方法来处理数据包丢失。首先发送方将消息放入发送缓冲区,在附加了时间戳字段后发送消息,沿路径的交换机不会聚合数据包的时间戳屏障;接收方将消息存储在接收缓冲区中,并使用ACK 进行回复。发送方使用ACK 来检测和恢复数据包丢失;当发送方收集到时间戳小于或等于的数据包的所有ACK 时,其会发送一个带有提交屏障的提交消息,该提交消息被发送到邻居交换机;每个交换机聚合输入链路上的最小提交屏障,并产生传输到输出链路的提交屏障,当接收者收到提交屏障时,接收者在接收缓冲区中传递小于或等于的消息。
2.2 故障恢复机制
使用网络控制器通过信标超时检测故障。控制器需要确定故障的进程和故障情况,与控制器断开连接的进程被视为故障。例如,如果主机出现故障,则其上的所有进程都被视为故障。当进程故障时,无法可靠地确定进程最后一次提交和最后一次传输的时间戳。从提交时间戳到将时间戳传输给接收者会产生传播延迟,因此有可能找到一个由失败进程P 提交但没有传输到任何接收者的时间戳。这样一来,所有接收者会接收缓冲区中来自P,且在时间戳之前的消息,并丢弃之后的消息。P的故障时间戳是P的所有邻居报告的最大最后提交时间戳。如果多个故障同时发生,将尝试在网络中找到一组无故障的节点,并将故障节点和没有故障的接收器分开。
邻居检测到故障后会将最后提交时间戳通知控制器,控制器确定故障的进程及其故障时间戳,将故障的进程P 及其故障时间戳广播给所有正确的进程。每个正确的进程都会丢弃接收缓冲区中时间戳高于,由P 发送的消息。每个正确的进程丢弃发送缓冲区中发送到P的消息。如果丢弃的消息处于分散传输状态,需要中止分散传输的过程,即召回分散传输到其他接收者的消息;发送方向这些接收方发送召回消息,每个接收方丢弃接收缓冲区中的消息,并向发送方响应ACK;控制器从所有正确的进程中收集完成信息,通知网络组件,从失败的组件中删除输入链路。
如果网络故障影响和之间的连通性,那么会要求控制器将消息转发给,并等待来自控制器的ACK;如果控制器也无法传递消息,则将被认为是故障,并记录无法传递的召回消息;如果控制器收到召回消息的ACK 但无法将其转发给,则将被认为故障。总而言之,如果一个进程在特定的时间内没有响应控制器,则可以认为该进程发生故障。
当进程从故障中恢复,则该进程需要传递或丢弃接收缓冲区中的消息。控制器会通知进程其故障,进程联系控制器以获取主机故障通知,传递缓冲消息后,恢复的进程需要作为新进程加入TOC-Re。
3 全序数据传输实现
3.1 主机端实现
在终端主机上实现一个TOC 库,该库建立在RDMA 协议上。TOC 从处理器周期计数器中获取时间戳,并将其分配给软件中的消息,由于RDMA 在不同队列中缓存消息,无法确保网卡到交换机链路上时间戳的单调性。因此,使用RDMA的不可靠服务(UD),将每条TOC 消息分割成一个或多个UD 数据包。
TOC 在软件中实现端到端的流量和拥塞控制。当目标进程第一次被访问时,其会与源进程建立连接,并为其提供一个接收缓冲区,其大小为接收窗口。数据包序列号(PSN)用于丢失检测和碎片整理。拥塞控制采用DCTCP,其中显示拥塞控制标记位于UD数据包部。当应用程序进行发送传输时,其存储在发送缓冲区中。每个目的地都维护一个发送窗口,是接收窗口和拥塞窗口中的最小值。当发送缓冲区中某个分散的所有消息都在相应目的地的发送窗口内时,其会附加当前时间戳并发送出去,即当分散传输的某些目的地或网络路径拥塞时,其会被阻止在发送缓冲区中,而不是减慢整个网络的速度。为了避免活锁,散射从发送窗口获取信用。如果目的地的发送窗口不足,则分散传输将保持在等待队列中,而不释放信用,确保最终可以发送大量分散,但代价是浪费可用于无序发送其他分散的信用。
TOC 中的UD 数据包添加了24个字节的头部:消息时间戳、屏障时间戳、提交屏障时间戳、数据包序列号、一个操作码和一个标记消息结束的标志。
3.2 网络内处理
使用P4 实现网络内处理,并将其编译到Tofino。一个Tofino 交换机有4个管道、4个输入端口和4个输出端口,每个端口都独立地计算屏障时间戳。TOC的每个输入链路需要2个状态寄存器,分别存储两个屏障,以实现TOC-BE和TOC-Re 策略。对于每个数据包,输入链路的屏障寄存器在交换机的第一个状态流水线阶段更新。由于每个阶段只能计算两个屏障中的最小值,因此交换机使用带有(log)流水线阶段的寄存器二叉树来计算最小链路屏障B。在最后的流水线阶段,数据包中的屏障时间戳字段更新为B,控制平面软件会例行检查链路屏障,并在链路屏障明显滞后时报告故障。
对于没有可编程交换芯片的交换机,在交换机的处理器上实现网络内处理。商用交换机不能处理数据平面的数据包,但其处理器可以处理控制平面的数据包。与服务器处理器和网卡相比,交换机处理器通常具有较低的计算能力,较低的带宽。由于交换机处理器无法处理每一个数据包,数据包直接由交换芯片转发,处理器会定期在每个输出链路上发送信标。信标的屏障时间戳存储在每个输入链路的寄存器中,处理器上的线程会定期计算链路屏障的最小值并向所有输出链路广播新的信标。
如果交换机供应商不提供交换机处理器的公开访问接口,可以将信标处理任务卸载到主机,为每个网络交换机指定一个主机代表。信标包使用单侧RDMA 写入来更新主机代表上的屏障,定期计算最小屏障时间戳,并将其广播给下游主机代表。
4 实验评估
实验评估平台由10 台Arista 交换机和32 台服务器组成,每台服务器都配置有2个至强E5-2650 处理器和一个运行RoCEv2的迈络思ConnectX-5 网卡。指定一个处理器作为每个交换机和网卡的主机代表来处理信标,主机代表直接连接到交换机,信标包不需要绕道。在小规模实验(2~32个进程)中,每个进程都运行在不同的服务器上,每个进程使用一对线程分别进行发送和接收。对于大规模的实验(64~512个进程),每个服务器托管相同数量的进程。
TOC的可扩展性能如图1 所示。其中图1(a)展示了TOC 与其他全序广播策略的吞吐量对比。每个进程向所有进程广播消息,随着进程数量的增加,TOC 仍然可以实现较高的吞吐量。TOC的吞吐量受处理器处理和RDMA 消息传递速率的限制,由于需要确保传输的可靠性,TOC-Re的吞吐量要稍低于TOC-BE,Seq 策略会引入额外的网络延迟,当Seq的吞吐量饱和并出现拥塞时,延迟会急剧增加,如图1(b)所示。由于仅使用一个进程进行传输,信令策略的吞吐量很低。
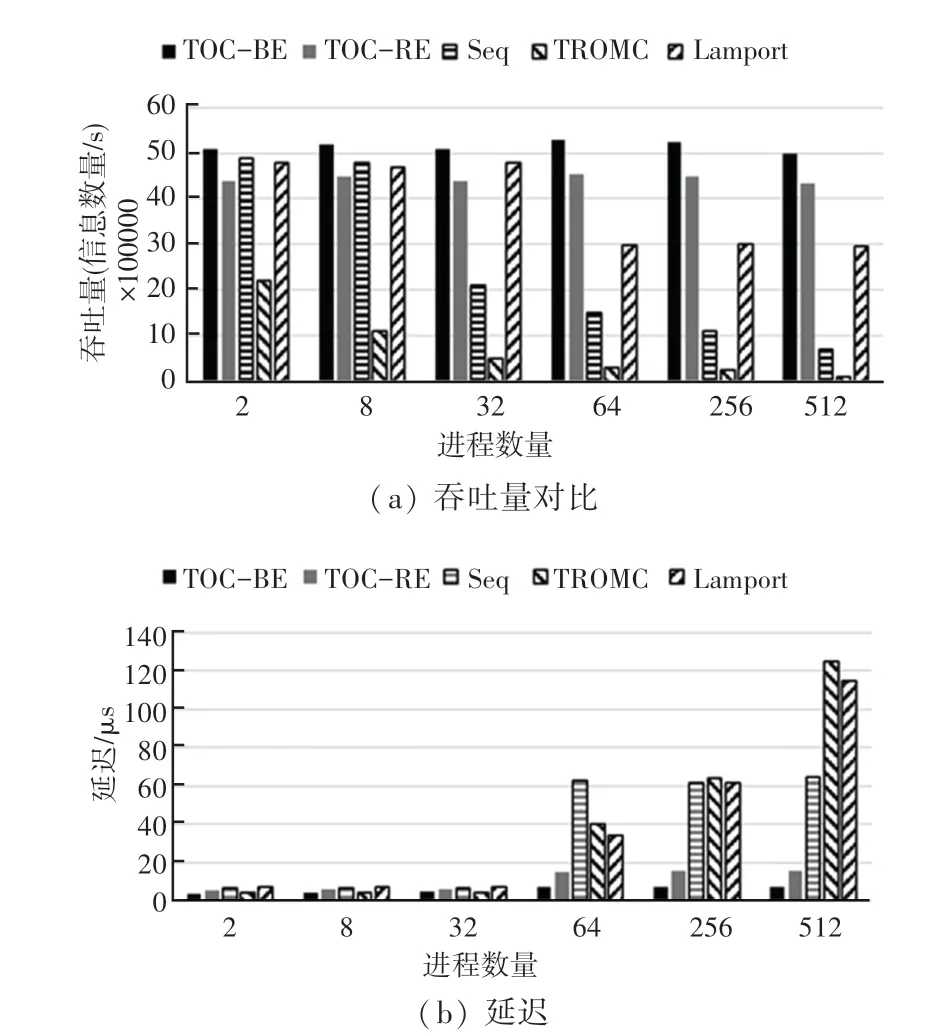
图1 可扩展性评估Fig.1 Evalutation of the scalability
模拟了接收者随机丢弃消息的场景,以评估数据包丢失对延迟的影响,如图2 所示。该场景中,进程的数量为512个,当丢包率高于0.001%时,TOCBE和TOC-Re的延迟均开始增长。在TOC-BE和TOC-Re 中,链路上丢失的信标数据包都会延迟屏障的传输。在TOC-Re 中,丢失的消息将触发重传,因此TOC-Re 对丢包更为敏感。
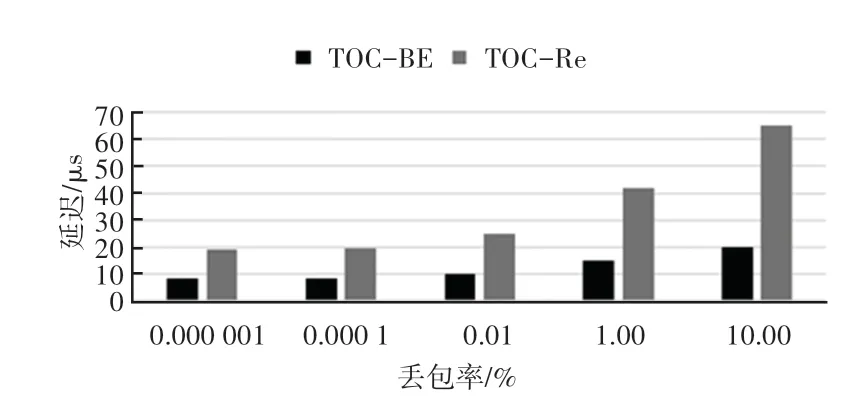
图2 丢包与延迟的关系Fig.2 Relationship between packet loss and delay
由于TOC的信标间隔非常小,因此TOC的故障检测通常比心跳超时机制更快,如图3 所示。如果在10个信标间隔(即30 μs)内未收到信标,则检测到故障。核心链路和核心交换机的故障在大多数的情况下并不影响网络连通性,而主机和机柜交换机故障会导致进程与系统断开连接,因此恢复需要更长的时间。TOC的处理器开销有两部分:接收器的重新排序和交换机的信标处理,如图4 所示,消息传递吞吐量会随着重新排序消息的增多而略有下降。虽然最大发送和接收缓冲区大小随延迟线性增加,但在缓冲区最多仅占用不超过3.5 MB。
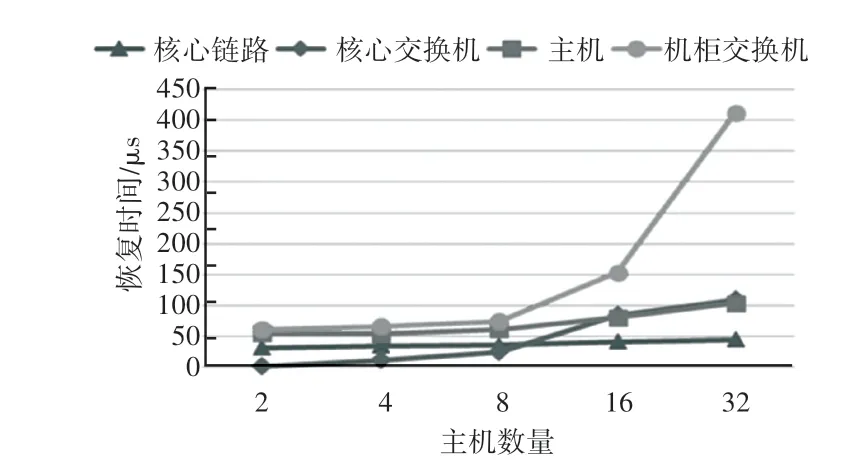
图3 恢复时间Fig.3 Recovery time

图4 处理器开销Fig.4 CPU overhead
5 结束语
本文提出了用于网络集群的全序通信策略TOC,该策略以发送方的时钟时间顺序进行消息传输,通过利用可编程的集群网络将聚合顺序信息与转发数据包分开,来实现可扩展性和效率。实验评估表明,TOC 能够提高全序数据传输的效率,还具有较低的故障恢复时间和开销。
猜你喜欢
江苏安全生产(2022年8期)2022-11-01 09:14:32
小资CHIC!ELEGANCE(2021年36期)2021-10-15 14:36:34
艺术评鉴(2020年5期)2020-04-30 06:47:57
人大建设(2018年10期)2018-12-07 01:13:46
四川师范大学学报(自然科学版)(2018年4期)2018-07-04 11:51:58
铁道通信信号(2018年3期)2018-04-19 02:32:56
长春理工大学学报(自然科学版)(2015年4期)2015-12-07 06:57:06
水道港口(2015年1期)2015-02-06 01:25:45
合作经济与科技(2013年21期)2013-01-18 05:44:06
通信学报(2012年3期)2012-08-10 01:53:24
