
基于深度学习的驾驶员分心行为识别模型
2022-03-01 06:03:40成福朋赵芸
智能计算机与应用 2022年1期
成福朋,赵芸
(浙江科技学院 信息与电子工程学院,杭州 310023)
0 引言
据统计数据显示,大约25%的车祸是由于驾驶员分心造成的。目前,驾驶员分心检测主要是利用深度学习方法进行识别。王冠等人根据Hough 算法进行车道线检测和识别,然后使用多点透视算法对驾驶员头部姿态进行估计,分心行驶识别率达到了80.8%。陈军等人设计了二级级联网络,训练速度快,结构特征冗余较少,准确率达到93.3%。王加等人采用车辆偏航角以及转向盘转速的标准差作为辨识特征量,准确率达到85 %。Eraqi等人提出了一种基于深度学习的驾驶员分心检测解决方案,该方案由卷积神经网络的遗传加权集成组成,证明了使用遗传算法的加权集成分类器具有更好的分类可信度,实现了90%的准确率。白中浩等人提出一种基于图卷积的多信息融合驾驶员分心行为检测方法,准确率达到93%。刘伟等人提出一种使用驾驶员局部定位信息,帮助卷积神经网络识别驾驶员分心驾驶的方法,准确率达到96.10%。本文基于文献[20]中的PSA模型,提出改进的MCAM(Multi-scale Convolutional Attention Module)分类模块,通过加入改进的注意力机制来提高分类的准确率。
1 MCAM 分类模块
MCAM 分类模块分为MCM模块和MSE模块。设计MCAM 分类模块的目的是解决VGG16 网络中多层卷积造成网络参数量过大的问题,并且MCAM分类模块中加入了改进的通道注意力,能够让通道间进行通信,并且为每个通道分配不同的权重,使其网络能够关注重要的特征,抑制不重要的特征,以此提高分类的准确率。
原始VGG16的网络结构如图1 所示。其中5个卷积模块的卷积核尺寸均为3×3,卷积核使用的数量分别是64、128、256、512、512。这样的卷积模块设置存在的问题:一是全部使用3×3 卷积,没有考虑到其它尺寸的卷积核是否可以提取到更多的特征;二是卷积核数量太多,导致网络参数量增多。因此为了解决这两个问题,提出了MCM模块。

图1 VGG16 网络结构Fig.1 VGG16 network structure
MCAM 分类模块如图2 所示。该分类模块主要操作步骤为:

图2 MCAM 分类模块图Fig.2 MCAM classification module diagram
(1)上一层的特征图进入MCM模块,在通道维度上拆分为4个子特征图;
(2)4个子特征图分别使用3×3、5×5、7×7、9×9进行卷积;
(3)卷积结果进入空间注意力,得到新的4个子特征图;
(4)使用MSE模块提取新的子特征图的注意力向量后,在通道维度上进行拼接。
在VGG16 中插入MCAM模块后的结构变化如图3 所示,并将其命名为MC-VGG16。
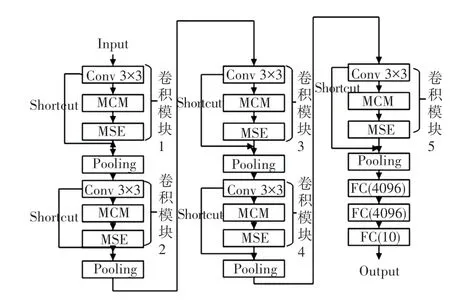
图3 MC-VGG16 网络结构Fig.3 MC-VGG16 network structure
1.1 MCM模块
MCM模块主要是对特征图进行分离并提取不同尺度下的空间信息,解决VGG16 网络中单尺寸卷积核的问题,并且将VGG16 网络中每个卷积模块的卷积核数量减少一倍,使用空间注意力弥补特征的损失。空间注意力的优势是只有一个7×7×1的卷积,可以保证参数量不会增加太多,而且提取每个通道的特征图在(,)位置的特征,增强特征表达。因此,MCM模块对输入特征图进行通道分离,然后进行多尺度下的特征提取。MCM模块架构如图4所示。

图4 MCM模块Fig.4 MCM module
图4 中,对于输入特征图,将其在通道维度下分离成4个子特征图,每个子特征图尺寸为4。在4个尺寸的卷积核进行卷积时,使用非对称卷积,将参数量进一步减少。图中表示非对称卷积,具体过程如图5 所示。
图5 中,左边为3×3的卷积核,右边1×3和3×1是非对称卷积,中间5×5 为特征图。非对称卷积的做法是将一个3×3的卷积核分解为两步:首先使用1×3 来对特征图进行卷积,然后使用3×1 对1×3的结果卷积。这样得到的结果与一次3×3的卷积结果相同。

图5 非对称卷积过程Fig.5 Asymmetric convolution process
对于非对称卷积第一步得到的3×3 特征图,首先是做填充,将3×3 特征图填充为5×5,最后使用3×1的卷积核去卷积计算,同样参与计算的参数是3个,则两次参与计算的参数是6个。而使用3×3的卷积核对5×5的特征图进行卷积的计算,参与计算的参数是3×3=9,则节约的参数量为:(9-6)/9=0.33。因此,非对称卷积减少了大约33%的参数量。
为了弥补减少卷积核数量时损失的特征,将4个子特征图分别进行空间注意力的提取。对于特征图中的(,)位置,在通道维度上取平均值后得到最后特征图’’1,全局最大池化也是同样的操作,只是取的是最大值。将全局平均池化和全局最大池化的结果在通道维度上进行拼接,得到输出特征图’’2,然后进行77的卷积,输出特征图’’1,最后与输入特征图’’’ 进行元素相乘。通过空间注意力,将原始图像中的空间信息变换到另一个空间中并保留了关键信息。在经过空间注意力后,4个子特征图作为MSE模块的输入。因此,MCM模块中对于输入特征图,首先进行通道维度下的分离,平均分离为4个子特征图,分离如公式(1)所示:

式中,表示输入特征图;表示分离操作;表示将分离为子特征图的个数;表示在通道维度上进行分离;表示分离结果。
分离操作完成后,分别对4个子特征图进行不同尺寸的卷积操作,卷积如公式(2)所示:

式中,Result表示保存在中的第个子特征图;表示输入子特征图的通道数;4表示使用卷积核的数量;表示使用的卷积核的尺寸为;Conv表示第个子特征图的卷积结果。 Result中的变量取值为:{0,1,2,3},的取值为:{3,5,7,9}。
在计算时,相同位置的数字要一一对应,第0个子特征图对应为3,第1个子特征图对应为5,第2个子特征图对应为7,第3个子特征图对应为9。为了进一步降低参数量,使用图5 所示的非对称卷积。
卷积操作完成后,需要对每个子特征图进行空间注意力的计算,计算公式为:

式中,表示输入的特征图4;GMP和GAP 分别表示全局最大池化和全局平均池化;+表示在通道维度上进行特征图拼接;∗表示7 ×7 卷积结果与进行元素相乘得到输出结果’。
将77 卷积后的特征图’’1 标记为F。则对于输入特征图与F进行元素相乘时,由于的通道维度是4,F的通道维度为1。因此分别将的每一通道维度的特征图与F进行对应位置元素相乘,输出的特征图’为’’’’4。
1.2 MSE模块
MSE模块基于SENet的思想,主要作用是提升网络准确率,并在此基础上减少网络参数量。SENet模块中使用全连接层来限制模型复杂度,增加泛化能力。然而,全连接层还是带来了大量的参数。因此,SENet模块虽然使模型性能提升,但是也带来了参数量增加的问题。SENet 如图6 所示。

图6 SENetFig.6 SENet
在SENet 中,全连接层的计算采用全局卷积计算方式。但这样的卷积方式参数量较多,特别是当输入特征图的增加时,全连接层的通道也会增加,参数量就会成倍的增长。因此,MSE模块沿用SENet 中加权的方式,改用一维卷积而不是用全连接层。由于MSE模块中特征图通道之间的通信是在通道K 邻域内,这意味着不需要将输入特征图1×中的个通道完全进行卷积,只在通道的邻域内进行计算即可。MSE模块如图7 所示[10]。

图7 MSE模块Fig.7 MSE module
完整的MSE 流程如图8 所示。

图8 MSE 完整流程Fig.8 MSE full process
其中,一维卷积过程如图9 所示。

图9 一维卷积过程Fig.9 One dimensional convolution process
图9 中,(3,5,1)表示一维卷积核3×1,(1,5,6,3,7,0)表示重组后的一维特征图1。一维卷积核的尺寸为31,其尺寸的确定是由于在MSE模块中,特征图通道之间的通信是在通道邻域内,因此这里选取3 进行示例说明。卷积核中的数据分别是3、5、1。其中,5 为锚点。在卷积时,锚点依次移动到特征图的每一个位置处,对应位置相乘再求和,得到卷积后的特征图尺寸也为1。
MSE模块中,由于卷积时很容易做,邻域一般取奇数,并且只有是奇数时,一维卷积核才有锚点。
2 实验结果与分析
2.1 实验环境与参数
实验中,集成开发环境为JetBrains PyCharm 2018.1.4 x64,操作系统为win10,内存32 G,8 核CPU,显卡为NVIDIA GeForce RTX 2080 Ti,开源框架为Keras。训练网络时,_设置为16,设置为120,优化器为,学习率为110。
2.2 评价指标
对于MC-VGG16 网络,使用准确率()、精确率()、召回率()进行模型性能评价,其公式如公式(4)公式(6)所示。

式中,表示模型预测为正例,实际也为正例;表示模型预测为正例,实际为负例;表示模型预测为负例,实际上为正例;表示模型预测为负例,实际上为负例。
数据集中有十类驾驶员分心行为,当前类别识别时标记为正例,其他类别则为负例。例如对当前c0 类来说,其是正例,其他9 类均是负例。
2.3 数据集
实验中使用State Farm Distracted Driver 数据集。数据集由驾驶员10 种行为的训练集图像17 462个,测试集图像4 961个组成,图片是RGB 图像,分辨率为320×240。10 种行为分别是:安全驾驶、右手编辑手机、右手打电话、左手编辑手机、左手打电话、操作收音机、喝东西、向后找东西、整理发型或化妆、与乘客交谈。训练集有驾驶员行为的真实标签,测试集不含有驾驶员行为的真实标签。将测试集中的10 种驾驶员图像手动分类,并将训练集和测试集中的每一类别分别编号为c0、c1、c2、c3、c4、c5、c6、c7、c8、c9。训练集和测试集每个类别的数量见表1、表2。
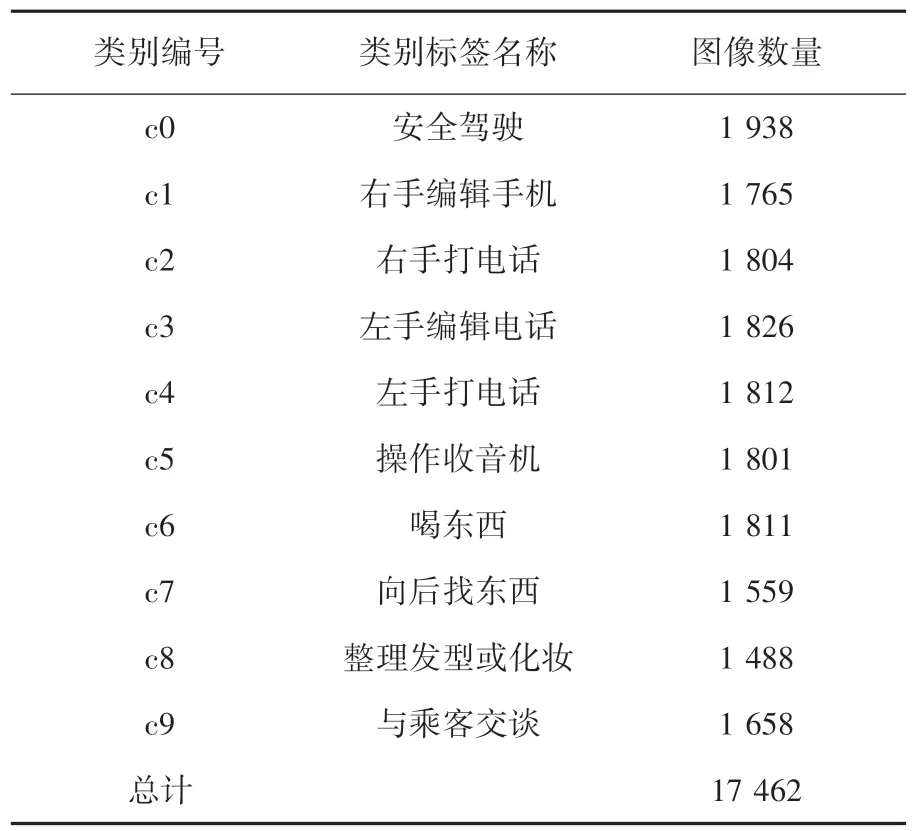
表1 训练集细节Tab.1 Training Set details

表2 测试集细节Tab.2 Testing Set details
最后对数据集的处理是数据增强,这是为了在进行模型识别时丰富图像的多样性,数据增强的目标是减少网络的过拟合,增加模型的泛化性。实验中图形增强主要是将图像进行水平翻转和竖直翻转,如图10 所示。

图10 数据增强Fig.10 Data Augmentation
数据集中有10 类驾驶员分心行为,当前类别识别时标记为正例,其它类别则为负例。例如,对当前c0 类来说,其是正例,其他9 类均是负例。
2.4 消融实验
MC-VGG16 网络是基于VGG16 网络而来,因此在实验时需将两种网络进行对比。又由于MSE模块中特征图的通道通信是在邻域内,为了找出效果更好的,将取值为{3,5,7,9},依次实验。实验结果见表3。

表3 不同模型准确率和参数减少量对比Tab.3 Comparison of accuracy and parameter reduction of different models
由表中数据可见,与原始VGG16 网络相比,MC-VGG16网络中3、5、7、9 时,都比原始网络VGG16的准确率高,且统计出的参数量也比VGG16网络的参数量要少。当3 时,比原始VGG16的网络降低了13,356,008个参数。其中,当9 时,分类效果比3 时稍低,但也降低了VGG16 网络13,355,888个参数。能够降低参数量的原因:一是所用模型中的卷积核数量较少,二是非对称卷积的使用。实验结果证明,MC-VGG16不仅可以提高分类准确率,更能明显的降低原始VGG16模型的参数量。
为了证明MCM模块中多尺寸卷积以及空间注意力的有效性,仅在VGG16模型中添加MCM模块后,与原始VGG16 网络进行了对比。从表3 中看出,VGG16+MCM模型的准确率达到了95.53%,比原始VGG16 网络的准确率高了1.65%,并且参数量减少了13,356,088个。因此,MCM模块的加入不仅降低了VGG16的参数量,并且提高了准确率。
由于MSE模块基于SENet模块进行改进,因此需要将MSE模块和SENet模块进行对比。由表3中可以看出,MC-VGG16+SENet模型虽然减少了原始VGG16模型13,345,724个参数,但是却不如当3 时的MC-VGG16模型减少的参数量多,且MSE模块比SENet模块具有更高的准确率。结论是:当3 时,模型准确率较高,且参数量最少。
2.5 损失和准确率结果
当3 时,MC-VGG16模型的测试准确率达到了97.50%,其主要原因是MCM模块和MSE模块改进了原始VGG16 网络中的卷积层,解决了使用卷积层带来大量参数的问题;对子特征图进行加权,保留重要特征,删除不重要特征,不仅提升了准确率,而且辅助使用非对称卷积进一步来减少参数量,实现了更高的准确率和更低的参数量。3 时模型的训练准确率、测试准确率、训练损失、测试损失如图11 所示。

图11 准确率和损失曲线Fig.11 Accuracy and loss curve
图中横轴代表迭代次数Epoch,纵轴代表准确率和损失。整体而言,模型没有出现过拟合的现象,证明当3 时模型分类效果理想。
2.6 不同方法对比
为了证明MC-VGG16模型的有效性,将其与其它分类模型进行对比。不同模型的准确率见表4。对比结果证明:MC-VGG16模型具有更高的分类准确率,并且使用MCAM模块可以降低网络的参数量。

表4 不同方法的准确率比较Tab.4 Comparison of accuracy of different methods
几种模型对每一类别的准确率的对比结果见表5。
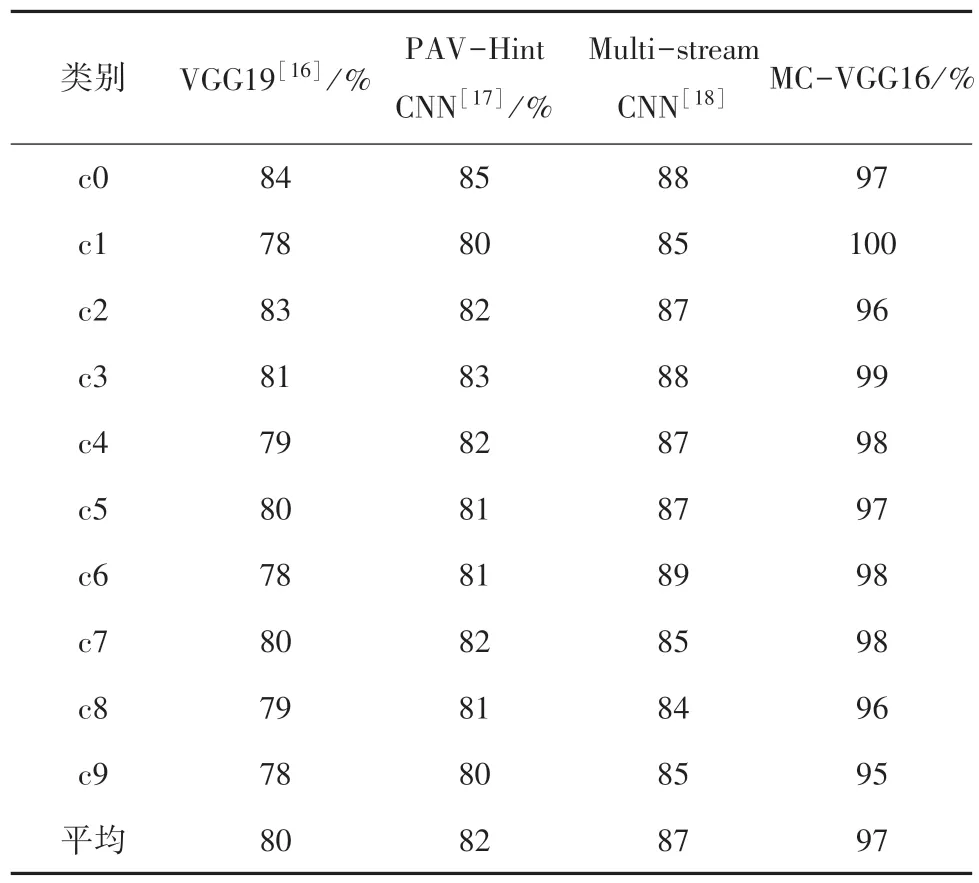
表5 不同方法对每一类别的准确率比较Tab.5 Comparison of accuracy of different methods for each category
表5 中通过对比VGG19、PAV-Hint CNN、Multi-stream CNN 3 种方法每一类别的准确率,证明了MC-VGG16模型的分类效果更好。
2.7 可视化结果
从数据集选取十类分心图像进行识别,如图12所示。图像下方的文字表示该图像的实际行为类别,在每个图像上显示的文字为模型预测的图像类别结果。由此可见,模型可以正确预测将每个图像所属的类别,证明MC-VGG16模型具有良好的识别效果。

图12 可视化结果Fig.12 Visualization results
3 结束语
本文的MCAM模型的主要目的是降低VGG16网络中的参数量,并且加入注意力机制来提高分类准确率,实验表明该模块是有效的。在实验过程中使用非对称卷积来进一步减少网络的参数量,并且分析了通道间通信的邻域的取值不同也会导致最后网络识别的效果不同。尽管模型取得了不错的识别效果,但是当两种分心行为相似时会出现识别错误,后期研究会结合更多的特征进行研究。此外,数据集中的图像都是清晰可见的,因此下一步的研究方向可以是如何对低分辨的图像进行分类识别,以此保证驾驶员的生命安全。
猜你喜欢
汽车实用技术(2022年14期)2022-07-30 06:13:42
汽车实用技术(2022年4期)2022-03-07 06:07:20
健康之家(2021年19期)2021-05-23 11:17:39
医学食疗与健康(2021年27期)2021-05-13 18:46:23
农业科技与信息(2021年2期)2021-03-27 07:27:38
数学年刊A辑(中文版)(2018年2期)2019-01-08 01:59:50
中国交通信息化(2018年5期)2018-08-21 03:37:40
数学理论与应用(2016年4期)2016-05-17 04:50:23
公民与法治(2016年4期)2016-05-17 04:09:26
电测与仪表(2015年4期)2015-04-12 00:43:04
