
基于FPGA的智能垃圾分类识别系统设计
2022-02-28 04:14陈欢纪丽萍秦怀宇
电子元器件与信息技术 2022年12期
陈欢,纪丽萍,秦怀宇
1.无锡科技职业学院,江苏 无锡 214000;2.江苏科技大学,江苏 镇江 212000
0 引言
分类垃圾桶是最为常见的垃圾分类装置。普遍结构单一化,采用敞开式或手动密封式,卫生条件较差。而且,大多数人尤其是老年人对“垃圾分类”知之甚少,使得人们难以长期坚持垃圾分类的实施。因此,设计出一款基于语音识别的智能垃圾分类装置是必要的,该装置加入语音识别,方便人机语音交互,帮助用户进行正确的垃圾投放。同时,FPGA的硬件功能十分强大,运行速度可以和专用芯片相比。使用语音识别模块与FPGA硬件相结合,对系统识别率将有更大的提升[1]。
基于此,本文以现场可编程门阵列Cyclone II EP2C5T144和语音识别为核心,设计选题为基于FPGA的智能垃圾分类装置。装置功能的实现过程如下:当用户在投放垃圾时,通过语音指令唤醒并说出垃圾的名称,语音识别系统会根据该语音信号对垃圾进行分类。显示屏将显示垃圾名称和垃圾类型的拼音、对应种类的LED指示灯闪烁并实时语音播报垃圾种类。操作简单方便,适用于各个年龄段,特别是中老年人,有效地解决了用户因分类意识薄弱而不能正确投放垃圾带来的困扰。
下面回顾语音识别与智能垃圾桶的国内外研究成果。
语音识别是实现人机语音交互等智能应用产品的核心技术。通过接收和执行设备发出的指令,LCD显示屏、LED指示灯和MP3语音广播可以输出相应的视觉或听觉信息。近年来,因为深度神经网络(Deep Neural Network,DNN)的出现、系统大数据的应用与网络云计算的运行,语音识别技术过渡到一个新的阶段,并逐渐在市场上走向实用。
由AT&T Bell实验室开始自动语音识别技术的研究,第一次成功地识别出10个孤立的英文数字。
60年代,随着计算机和数字处理器的出现,语音识别技术的研究得到了进一步的提升。同时期,语音识别通过简单的模板匹配,发展了动态规划(DP)与线性预测(LP)这两项重要技术。70年代,研究人员对60年代的线性预测技术(LP)进行改进,从而推出线性预测的编码技术(LPC)以及动态时间的规整技术(DTW),这两个技术分别解决了信号的特征参数提取和时间长度不相同而不能匹配的难题,使得特定人、孤立词的语音识别成为可能。80年代初期,矢量量化技术(VQ)被提出,用于压缩语音信号信息,以减少识别时间、降低实现复杂度;中期,发展了混合高斯-隐马尔可夫模型(GMMHMM),语音识别方法由60年代的简单模板匹配转变为概率统计模型;后期,人工神经网络(ANN)开始应用,但语音识别的整体效果不如中期提出的GMM-HMM模型。90年代,提出的MFCC在鲁棒性、识别速度和精度上体现了优异的性能,为语音模型的优化和设计做出了巨大的贡献。该时期,发布Via Voice的IBM、Whisper 的微软和Voice Tone的Dragon等公司将语音识别推广到日常生活中。
由于GMM-HMM模型在语音识别中的整体性能与实用化水平相差悬殊,此后将近10年的时间,语音识别技术陷入瓶颈期,发展速度缓慢。直到2006年,由Hinton提议出的深度置信网络(DBN),改进了深度的神经网络(DNN)。2009年,Hinton及Mohamed D在语音识别模型中进行DBN应用的实验,最终可以识别出词汇量较少的连续词。2011年,DNN能够允许识别连续词、大词汇量。同时期,Apple Inc. 推出了具有语音识别功能的iPhone 4S系列,得到了公众的广泛认可。
此后,传统的GMM-HMM模型被基于深度(DNN)、循环(RNN)、卷积(CNN)的神经网络和端到端技术的模型取代[8-10]。与GMM-HMM模型相比较而言,DNN模型提高了连续词语音识别的整体性能;RNN模型通过反馈记忆有效信息,优化了DNN模型;CNN模型又是RNN模型的一个改进版本,它能有效地抑制信号中的各种噪声,具有更强的鲁棒性能。随着语音识别技术的日益兴盛和完备,它已逐渐进入市场并走向实用化。
1980年之前,是国内少数科研机构对语音识别的探索时期,语音识别技术的发展相对缓慢。但随着1987年863 计划的实施和人工智能体系的应用,我国语音识别技术的研究进入了一个快速发展的轨道。2002年,中国科学院研发的Pattek-ASR成功地识别出汉语语音,具有良好的识别效果。2008年,科大讯飞公司推出了可以应用在多种产品中的多功能识别系统Aitalk2.0,支持多种语音信号的智能控制。2010年,谷歌发布了搜索引擎,首次增加了语音搜索功能;此后,百度、搜狗、科大讯飞等国内企业纷纷推出基于语音识别的智能产品。2013 年之后,国内语音芯片开始快速发展。
虽然我国语音识别技术的发展趋势较好,但由于市场上的语音识别产品对识别速度和精度的要求不断提升,而大量涉及语音识别技术的产品仅通过软件优化的方式不能满足上述的要求。因此,迫切需要设计出适合硬件的更加高效的数据处理算法。
美国的Clean Robotics研发的Trash Bot原型机,具有垃圾分类投放、自动填满垃圾的功能,解决了用户由于缺乏垃圾分类意识而无法正确投放垃圾的问题。芬兰Enevo初创公司设计的首款Enevo One Collect,具有实时监控垃圾桶异常、优化垃圾回收路线的功能,有助于降低环卫机构的运营成本,改善城市的运营效率。法国Uze公司开发的Eugene,具有垃圾分类功能,主要通过扫描仪确定待丢垃圾所属的垃圾种类。波兰Bin-E公司研制的新型人工智能垃圾桶,具有垃圾智能识别、垃圾信息及时更新与反馈的功能,并对用户消费习惯数据进行了一定程度的分析。美国Big Belly Solar公司发明的“大胃王”垃圾桶,具有压缩垃圾、优化回收路线等功能,有效节约一定的人力物力资源,保证了城市环境的卫生。悉尼大学留学生设计的Tetra Bin垃圾桶,通过“游戏”的形式实现了多种功能,不仅给群众提供了一定的帮助还有利于环境的改善。
智能垃圾桶在我国已经逐步发展,并取得了一定的经济和社会成效,但仍然存有大量的实际问题需要解决,如资源紧缺、卫生差劲、空气污染等。因此,本系统实现的低成本、高效能的智能垃圾分类装置具有一定的实用价值与研究价值。
1 系统总体设计
本装置基于语音识别技术和FPGA硬件知识,选用芯片型号为EP2C5T的ALTERA FPGA开发板、LD3320语音识别模块、串口MP3语音播报模块、LM393红外感应模块以及LCD1602显示模块,实现一种基于FPGA的智能垃圾分类装置。这款智能垃圾分类装置适用于各种场合和不同人群,即使不知道垃圾的种类也不会把垃圾扔错。这方便工作人员对垃圾进行分类处理,也解决了垃圾来源的分类问题。总体设计框图如图1所示。
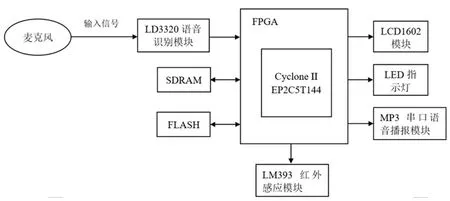
图1 系统总体设计框图
下面介绍语音识别系统的基本理论、基本原理和组成部分,阐述语音信号系统的具体实现过程:数字化与预处理、特征参数提取、声学模型和语音模型的建立、解码。
(1)预处理模块,主要用来滤除各种噪声,从而保留原始语音数据信号中的有效信息。
(2)特征提取模块,若采用最适合系统的特征参数,即可以高效地提取出具备关键特征的语音信号。
(3)声学模型训练,用于匹配原始语音数据信号的特征参数,从而得到匹配度最高的语音特征信号。
(4)语言模型训练,主要用来判断模板匹配中哪些词更容易出现,从而可以排除匹配过程中一些不可能出现的词。其缩小了搜索范围且提高了识别率。
(5)解码模块,通过采用相匹配的搜索算法,从而可以得出识别结果。
对原始语音数据信号进行数字化和预处理操作,可以使得系统识别效果更加高效。数字化过程包括预滤波、采样、模数变换;预处理过程包括中值滤波与归一化、预加重、加窗与分帧、端点检测。由于采集的原始语音数据信号通常是模拟信号,采用数字化和预处理操作可以将模拟信号转换成更适合计算的数字信号。同时,抑制各种干扰噪声对语音信号的影响,便于信号的后续处理,提高语音识别系统整体性能。
(1)预滤波。在一般的原始语音信号处理时,由采样定理,选取8~16KHz的采样频率。原始语音信号在进行采样之前,应先进行预滤波操作,预滤波相当于带通滤波器。
(2)采样。在进行预滤波操作后,选取适当的采样频率进行采样。由奈奎斯特采样定理可知,若模拟语音信号的频谱带宽是低于fm的带宽,则取样选择等于或高于2fm的带宽,从而能够从等距离的离散时间中恢复出原始语音信号。
(3)模数转换。经过采样后的语音数据信号,再通过模数转换器将模拟语音信号变换成数字语音信号,即完成模拟信号到数字信号的过渡,从而使得处理后的语音信号在时间和幅度上都离散。
2 系统硬件设计
2.1 语音识别模块
LD3320语音识别模块集成了语音数据信号识别的处理器以及一些外围电路,主要包含了模数/数模转换器、麦克风语音输入接口以及语音输出接口等。首先,该语音模块不需要任何外部的辅助模块,即能够直接嵌入到产品中使用,从而实现语音识别、语音控制、人机对话等功能;其次,LD3320模块的使用相对简单,用户不需要深入了解语音识别的原理,通过I^2C通信,即可以完成语音信号识别。最后,在LD3320语音识别模块中,内部含有高精度、高速度的识别性能和完整的识别数据库[2-4]。
用户使用I^2C通信,将关键词编码成字符串,传输给LD3320语音识别芯片,下次识别时则立即生效。该模块有三种主要的使用模式。用户可以使用编码定义三种不同的工作模式,如下所示。
(1)按键检测模式:系统主控MCU接收到外部触发信号后,在芯片上启动时序识别过程。这时,用户需要说出在一定时间段内要识别的关键词。此过程完成后,用户需要再次触发以重新启动标识过程。
(2)循环检测模式:系统主控MCU循环启动自动语音识别过程。若没有发出声音,则没有识别结果。每个进程的识别时间是固定的,超过识别的时间,则开始新的识别过程;如果得到识别结果,那么再根据识别的结果进行处理。
(3)口令检测模式:口令模式需要一个关键词来唤醒,唤醒后可以识别。默认的唤醒关键字是第一句话。识别出来后,如果想再次识别,仍需把装置唤醒,类似小洁。
LD3320语音识别模块的主要特点有如下三个。
(1)LD3320模块识别精度高,语音识别效果实用化。该模块无需录音即可完成与说话人无关的语音识别命令,用户只需使用同一种语言进行识别,识别效率大大提高,最高可达95%。
(2)LD3320模块可动态识别关键词,自由编辑50个关键词。在该模块的设计中,用户可以根据实际情况选择多种可能,比如定义50个识别语句作为语音数据命令的候选语音信号,以此提升系统的整体识别性能。
(3)LD3320模块具备高精度A/D和D/A通道;不仅能够支持串行和并行接口,还可以设置为休眠状态,以便于后续激活。
LD3320语音识别模块除了方便与主控芯片通信外,内部还集成了优化后的孤立词语音识别算法。用户可以方便地将LD3320模块嵌入到产品中,达到语音交互的目的。其原理图如图2所示。

图2 LD3320模块原理图
2.2 语音显示模块
语音显示包括LCD1602显示屏和LED指示灯显示。LCD1602模块可以提供各种控制命令,例如清除屏幕、字符闪烁、光标闪烁、显示移位等其他功能。具有画质高、画面效果清晰、功率低等优点,应用范围广泛。
2.3 语音播报与检测模块
MP3-FLASH-16P串口语音模块,采用SPI通信方式。其通过简单的串口指令,无需繁琐的底层操作,即能够播放指定的语音。MP3_FLASH_16P可以作为播放器使用。首先,当用户说出垃圾的名称时,LD3320模块能够识别到语音信号指令。其次,通过串口向MP3模块发送一系列指令,MP3模块接收到相应指令后,即可播放相应的垃圾类型。该模块无需繁琐的底层操作、使用方便且稳定可靠。
红外感应模块是基于红外技术的自动控制模块。当遇到障碍物时,红外信号被接收管反射接收,接收管通过传感器接口返回FPGA,智能垃圾分类装置可以利用返回信号判断垃圾是否满了。在正常情况下,人体可以发出约10nm的波长。当用户进入感应范围时,智能垃圾分类装置将电平变化信号发送给FPGA,然后通过语音模块广播垃圾已满。其具有干扰小、使用方便、灵敏度高、功耗低等优点。本文使用LM393红外感应模块,其输出可以直接连接FPGA的IO口,电路简单、信号处理速度快且抗干扰能力强。当接通电源后,发射管发出一定频率的红外线。用户触碰红外管时,接收管接收到红外反射信号,MP3模块则实时播报“垃圾已满”。
3 系统软件设计
本系统装置通电后,各模块初始化,具体实现工作如下。
(1)LCD显示屏初始化,装置显示“la ji fen lei ti xing xi tong”的主界面。
(2)串口MP3模块实时播报“欢迎使用垃圾分类提醒系统,请呼唤小洁后,说出你要放置的垃圾名称”。
(3)呼唤小洁后,用户说出垃圾名称,垃圾分类装置开始识别,识别结果以三方面提醒用户:LCD1602显示垃圾名称和类型的汉语拼音或中文字符、识别垃圾种类对应的LED灯亮、MP3_FLASH_16P语音模块实时播报垃圾名称对应的垃圾种类。
(4)未识别或识别时间超过15s时,自动返回垃圾分类装置主界面。
(5)当垃圾处于异常模式时,触碰红外极管,串口MP3模块语音播报“垃圾已满”,装置显示在主界面。开串口即可自动解析返回数据。
系统软件流程图如图3所示。

图3 系统软件流程图
4 系统实现
系统设计与系统测试两者是相辅相成的,在完成系统软硬件的设计后,本节主要对预期实现的功能逐一进行测试。
写入语音模型的具体流程如下。
(1)在PC机上预先训练预识别词汇模型。本系统针对现有的四大垃圾类别:可回收垃圾、厨余垃圾、有害垃圾和其他垃圾,对其分别选取6个词进行训练,即共设置24个识别词。识别词以各种垃圾名称的汉语拼音或中文显示,如yi la guan(易拉罐)、su liao ping(塑料瓶)等。
(2)对训练好的模型进行编号,生成C语言的头文件进行程序调用。在程序中,用汉语拼音串或中文字符写入每个词汇和垃圾类别。
(3)系统将识别出的垃圾和所属垃圾种类的汉语拼音或中文字符显示在液晶屏上。
装置上电后,各个模块开始初始化。LCD1602显示屏显示主界面“la ji fen lei ti xing xi tong”,串口MP3语音播报模块实时播报“欢迎使用垃圾分类提醒系统,请呼唤小洁后,说出你要放置的垃圾名称”。装置主界面显示如图4所示。

图4 装置主界面
本系统识别四大种类垃圾,每种垃圾识别6个对应的垃圾名称,统计24个垃圾名称。这里显示每种垃圾对应的1个垃圾名称。垃圾名称识别时,LCD1602显示屏显示垃圾名称和垃圾种类的汉语拼音或中文字符;垃圾名称对应垃圾种类的LED指示灯会亮起;串口MP3语音播报模块实时播报所丢垃圾的垃圾种类。垃圾分类装置的中文字符识别界面如图5所示。

图5 装置中文字符识别显示图
5 结语
设计了基于FPGA的智能垃圾分类识别系统,可满足测试及显示要求,人机交互友好,整体识别率高、识别速度快。
猜你喜欢
科普童话·学霸日记(2021年2期)2021-09-05
装备制造技术(2020年11期)2021-01-26
当代陕西(2019年24期)2020-01-18
阅读(快乐英语高年级)(2019年5期)2019-09-10
电子制作(2019年14期)2019-08-20
电子制作(2019年9期)2019-05-30
小说界(2018年5期)2018-11-26
小太阳画报(2018年10期)2018-05-14
通信电源技术(2016年4期)2016-04-04
通信电源技术(2016年5期)2016-03-22
