
多尺度相似性迭代查找的可靠双目视差估计
2022-02-28 06:39晏敏王军政李静
中国图象图形学报 2022年2期
晏敏,王军政,李静
北京理工大学自动化学院, 北京 100081
0 引 言
深度信息在自主平台避障等任务中属于核心感知信息,激光雷达、双目和深度摄像机作为常用的深度感知传感器,各自都有优缺点。在已知内外参数的双目情况下,深度估计可以等价转化为视差估计或者双目立体匹配的问题。由于双目可以弥补激光雷达数据稀疏和深度摄像机不适合室外场景的缺点,使得研究双目视差估计算法具有重要价值。对比激光雷达和深度摄像机的性能,提升双目视差估计算法的精度和推理速度尤为重要。
针对双目立体匹配,已经发展出一套经典方法,包括4个步骤:匹配代价计算、代价聚合、优化和细化(Lee和Shin,2019)。类似的方法有BM(block matching)、SGM(semi-global matching)(Hirschmuller,2008)等。这些方法往往计算时间长,不能适应重复纹理、低纹理及光照差异大的环境。而随着深度学习的发展及硬件性能的提升,越来越多的视觉问题取得了突破式的成果,如目标检测(赵永强 等,2020)、语义分割(青晨 等,2020)等。双目立体匹配问题也因为深度学习方法的引入,有了极大的突破,如LEAStereo(learning effective architecture stereo)(Cheng等,2020)和GANet-deep(guided aggregation network-deep)(Zhang等,2019),这些方法相对传统的算法在各大数据集上的速度和精度表现出优异的性能。
目前几种典型的基于深度学习的方法有RTSNet(real-time stereo matching network)(Lee和Shin,2019)、GC-Net(geometry and context network)(Kendall等,2017)这种通过构造3维代价体,采用3维卷积来聚合信息,并通过对分类输出加权的方式实现亚像素的视差估计的方法;也有DispNetCorr(disparity network correlation)(Mayer等,2016)、iResNet(iterative residual prediction network)(Liang等,2017)这种采用相关性计算和2维卷积回归得到视差估计的方法等。不论分类或是回归,这些方法都是通过一个复杂的网络尽量集成所有有效信息进行一次推理,往往结构显得笨重,应用不够灵活。
注意到大量基于深度网络的方法性能极度依赖训练数据的分布,且这些方法对不同区域的估计精度有较大差异。为了适应新的场景,设计具有高度泛化能力的网络十分重要,而如何找出估计结果里相对更可靠的部分,去掉网络尚不能很好处理的区域,对于实际应用非常关键。关于前者,一种想法是在网络中集成可在不同数据间推广的操作,如DispNetCorr等方法采用具有明确物理意义的相关性计算来表示像素间的相似性。关于后者,考虑到双目视差估计主要依靠左、右图之间的相似匹配实现,会导致能匹配上的区域和不能匹配上的区域之间估计精度出现明显差异。而去除不能匹配上的区域,如遮挡区域可以提升结果的可靠性。但是目前还没有文献重点处理这个问题。一个可以参考的方向是找到双目的遮挡区域作为不可靠区域进行去除。关于遮挡区域,基于监督学习的方法很少提到相关处理办法,而非监督学习的方法由于要考虑匹配区域的外观一致性,需要排除遮挡区域才能让网络更好地学习和收敛,所以有大量文献会特别处理遮挡区域,如Gordon等人(2019)提出通过比较匹配点估计距离的相对远近来去掉可能的遮挡区域的影响,而Peng等人(2020)通过判断是否有多个点投影到右图的同一像素来去掉距离更远的点,缓解遮挡的影响等。受Gordon等人(2019)和Peng等人(2020)的启发,如果网络推测两个像素点匹配,那么它们的视差应该是接近的,从而可以通过左右视差图匹配点视差值的比较判断视差的可信度,从而去除高度不可靠的估计区域。
众所周知,基于深度学习的方法,不同任务之间的网络结构千差万别,甚至同一个任务也能有无数种网络结构对应,找到一个有优异性能的网络结构并非易事,而考虑到视差估计和光流估计由于任务之间的相似性,可以在两种任务之间互相借鉴和启迪新算法。RAFT(recurrent all-pairs field transforms)(Teed和Deng,2020)作为一种高效的光流估计算法,采用了相关性操作能保证一定的泛化能力,通过查找多尺度的能表示大范围的相似量,结合上下文等信息回归视差的更新量使得网络具有一定的可解释性,方便融入人类的先验知识和经验进行设计和改进。另外该方法采用迭代多次的方法提升精度,提供在精度和速度之间灵活平衡的可能。
本文提出采用单、双边多尺度相似性迭代查找的方法以实现高精度的双目视差估计。与RAFT不同的是,不失一般性地对特征网络进行增强设计,光流估计涉及上下左右4个方向,而视差只涉及一个方向,考虑迭代更新的是残差,所以实际涉及两个方向,原本对RAFT的4个方向的相似性查找改为双边查找是最直接的,针对视差只能为负,在双边查找的基础上增加单边查找结构可以提升视差估计性能。针对方法在不同区域估计精度和置信度不一致的问题,提出了左右图像视差估计一致性检测提取可靠估计区域的方法。
1 本文算法
1.1 网络结构
本文方法主要包括特征网络、上下文网络、多尺度相似性计算和查找及更新网络,如图1所示。其中特征网络F-Net如图2所示,通过采用跳层连接、残差结构(He等,2016)及关联上下文的金字塔池化模块(pyramid pooling module,PPM)(Zhao等,2017)来增强网络建模能力。特征网络最终输出维度为32、分辨率为原图1/8大小的特征图F用于计算相似性。上下文网络由3个步长为2的卷积、8个残差模块和1个步长为1的卷积计算构成。该设计的目的为:1)保持输出的尺度和特征一致;2)多个残差模块堆叠增加网络的建模能力。上下文模块部分输出用来初始化卷积循环神经网络的隐变量,部分作为辅助信息来源用来提供关于轮廓等额外信息。
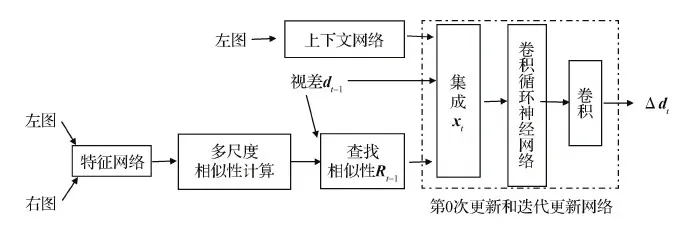
图1 总体计算框图Fig.1 The total calculation block diagram
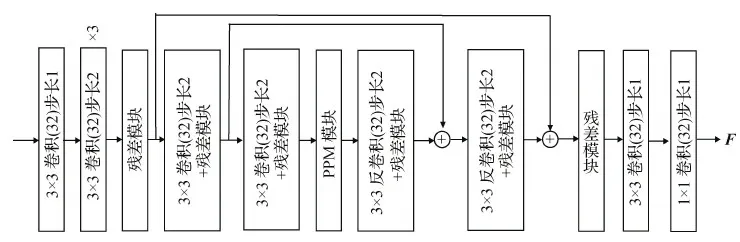
图2 特征网络F-NetFig.2 The feature network F-Net
1.2 多尺度相似性计算和查找
相似性计算和查找过程如图3所示,通过特征网络计算得到左、右图的特征图后,对左、右图的特征FL和FR分别提取出同一行,对取出的行进行矩阵乘法得到尺度S=1的相似性矩阵CS=1(为了实现归一化的效果,对矩阵乘法的结果除以特征维度的平方根),即得到左图中每个像素关于右图中同一行上每个像素的相似性,如图3中相似性矩阵CS=1的第p行第q列元素Cp,q等于左特征图中某一行的第p个元素fipL和右特征图中同一行的第q个元素fiqR的乘积,表示左图某一行中第p个像素和右图中同一行的第q个像素的相似性。而多尺度的相似性通过对前面计算得到的相似性在宽度方向进行平均池化得到,如图3中黄色和蓝色的颜色块所示,平均池化核大小为1×2,步长为2,所以尺度为S=1/2的相似矩阵CS=1/2高度不变,宽度缩小两倍,后续多个尺度类似。
相似性查找分成第0次查找和其他次查找。其他次查找是在计算得到多尺度的相似性后,对左图像的每一个像素结合前一次更新得到的视差,在不同尺度相似性中查找对应到右图像素位置(左图坐标减去视差)左右各4个像素对应的区域。
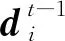
对于每一个尺度,选取的位置包括根据视差计算得到的右图像素位置和左右各4个像素位置,一共9个像素位置,如图3中绿色色块所示,由于视差不一定是整数,这里通过线性插值得到9个位置点的具体相似值。每个尺度9个位置点的相似量级联成一个9×1维的向量,4个尺度的向量进一步级联成一个9×1×4维的向量,也即图1中的Rt-1。于是,每个像素点的单次查找范围可以覆盖左右各2×2×2×4×8个像素宽的原图像范围(3个2表示3个缩小的尺度,4表示查找的邻域区域大小,8表示特征图已经相对原图缩小到了1/8),从而可以在单次更新的时候就得到比较理想的结果。而第0次查找和其他次查找的区别是只查找对应到右图像素位置的左侧部分,因为左图的像素在右图的匹配点只能在左侧,而其他次查找是在第0次更新后进行校正,此时校正量正负都有可能。与只有双向查找的结构相比,增加单边查找可以完全确定初次查找方向是准确的,这是由视差符号同向决定的,从而可以提升初次迭代估计的视差精度以致提升多次迭代估计的精度。
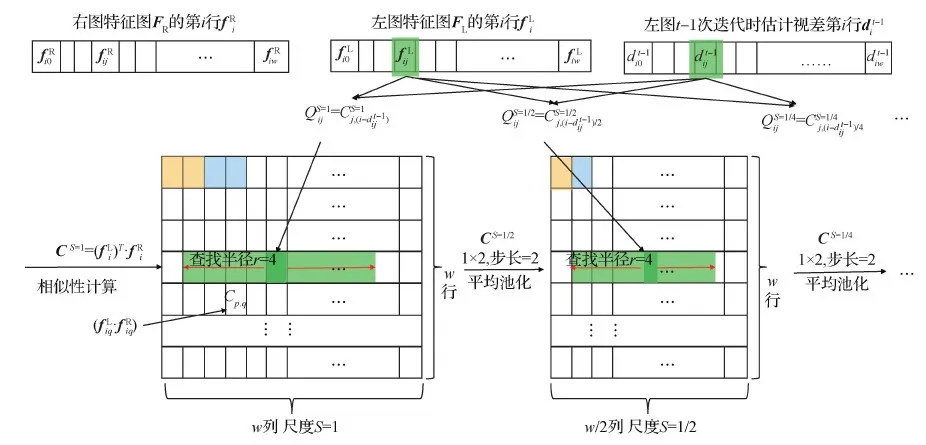
图3 多尺度相似性计算和查找Fig.3 Multi-scale similarity calculation and search
1.3 更新网络
更新网络分成第0次更新和其他次迭代更新网络,两者的结构是类似的,核心是循环迭代的卷积循环神经网络,即图4中的循环迭代模块,由于Teed和Deng(2020)的工作对比证明了采用该结构比直接采用等计算量的3层卷积层更新视差性能更优,这里为了高效地实现视差估计便沿用了该结构。为了迭代输出视差的更新量,提供的有效信息包括当前估计的视差、当前视差周围查找得到的相似性及进一步补充的上下文信息。将综合这些信息的xt输入循环迭代模块,迭代更新隐变量ht,ht经过两次卷积就能输出视差的更新量Δdt。为了减少计算量并且保留视野的大小,核心模块没有采用一个5×5的卷积循环神经网络,而是采用核分别为1×5和5×1的两个卷积循环神经网络级联构成,具体迭代过程(Cho等,2014)为
zt=σ(Conv1×5([ht-1|xt],Wz))
(1)
rt=σ(Conv1×5([ht-1|xt],Wr))
(2)
(3)
(4)
z′t=σ(Conv5×1([h′t|xt],Wz′))
(5)
r′t=σ(Conv5×1([h′t|xt],Wr′))
(6)
(7)
(8)
式(1)—(4)对应第1个卷积循环神经网络,式(5)—(8)对应第2个卷积循环神经网络,“|”表示向量级联,⊙表示矩阵对应元素相乘,σ表示sigmoid激活函数,Conv表示卷积操作,Conv的下标表示卷积核的大小,W表示对应卷积核的参数,下标t表示第t次更新迭代,z表示更新门,确定隐变量的更新比例,且z越大隐变量更新越多,r表示重置门,确定历史隐变量被利用的程度,且r越小,历史记忆就越少,另外上述公式中所有卷积输出的通道数和隐变量一致。上下文网络输出第0次更新和其他次更新的上下文及第0次更新的循环迭代模块隐变量的初始值h0,其他次迭代更新共享同一个网络,该网络的隐变量由第0次更新网络输出的隐变量进行初始化。初始化视差d0为0,则每次迭代估计得到的视差为
(9)
为了获得比双线性上采样更高精度原图分辨率的视差图,这里采用RAFT中学习上采样的方法,具体为对图4中的循环迭代模块的输出隐变量ht通过卷积核分别为3×3和1×3的卷积计算得到上采样的权重系数,对估计得到的1/8分辨率视差图每个像素邻近3×3区域的视差值进行64次加权分别得到原图分辨率邻近8×8大小区域的视差值,从而实现8倍上采样。
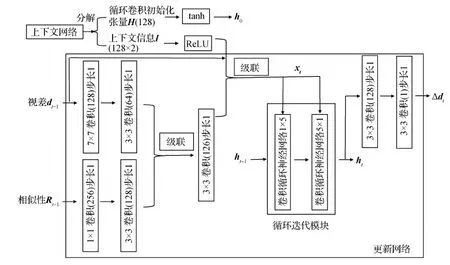
图4 更新网络Fig.4 The updating network
1.4 监督训练
采用有监督的方法对上面提出的网络进行训练,为了使得迭代输出的视差误差随着迭代次数的增加而逐渐减小,给后续迭代的损失设置相对大一些的权重,通过设置为底小于1的指数形式的权重实现,损失函数设计为
(10)
1.5 左右结合推导可靠的视差估计区域
双目成像的特点如图5所示,取物体后面的某一个平面,图中2维展示为一条线,两台摄像机共同可视的区域是绿线表示的部分,也就是左图中在右图的非遮挡区域,而红线部分是左图中视野超出右图的区域,黄色实线是左图中在右图被遮挡的区域,而黄色虚线是左图中不可见部分。这里将左图中超出右图视野和在右图被遮挡的区域统称为遮挡区域,而共同可视的区域称为非遮挡区域。由于本文方法是通过相似性查找得到左图像素的匹配点,理论上本文方法只能估计非遮挡区域的视差,而遮挡区域需要通过上下文等信息进行填充得到,两者的精度和置信度应该会存在明显的差别。对于实际应用而言,能够提取置信度高的估计区域具有重大意义。于是本文提出鲁棒提取可靠估计区域的方法。该方法需要同时估计左右图像的视差,而原本的网络是对左图的每个像素在右图中检索相似性(根据实际得到的匹配只能在右图的相对左侧,网络中加上了单边检索,所以无法通过交换左右图的顺序估计右图的视差),结合左右固定顺序的训练,网络只能估计左图视差,为了能估计右图的视差,本文提出通过左右反序和图像左右翻转的办法来实现对右图的视差估计。
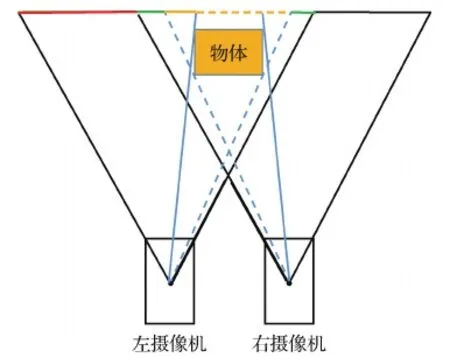
图5 双目成像Fig.5 Binocular imaging
假设左图像一点PL的横坐标为xL,在右图的匹配点PR横坐标为xR,则视差dL=xL-xR,左右图像反序并左右翻转后,原来右图的匹配点横坐标变成xR→L=w-xR,其中w表示图像的宽度,原来左图点横坐标变成xL→R=w-xL,此时新的视差为
dR=xR→L-xL→R=(w-xR)- (w-xL)=xL-xR=dL
(11)
也就是通过左右反序和图像左右翻转实现了视差同符号等大小,使得存在单边检索及左右顺序数据训练的网络也能对右图进行视差估计。
(12)
2 实验分析
2.1 实验数据
为了弥补获取真实场景视差数据或者深度数据代价过大的问题,这里采用模拟器产生的仿真数据集Sceneflow(Mayer等,2016)对网络进行训练和测试,并采用真实场景数据KITTI(Karlsruhe Institute of Technology and Toyota Technological Institute at Chicago)(Geiger等,2012)对本文方法的泛化能力进行验证。
2.2 评估指标
采用4个与误差相关的评估指标:1)末端点误差(end point error,EPE)表示统计区域所有估计像素的视差误差平均值,即
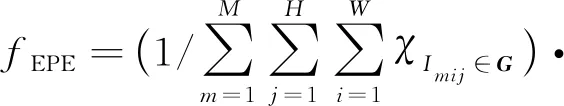
(13)
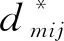
2)超过阈值的像素百分比(percentage of pixels over threshold,PPT)表示误差超过3个像素并且误差相对视差超过5%的像素占总统计像素数的百分比,即
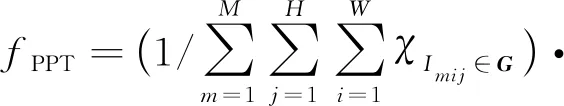
(14)
3)可靠估计区域百分比表示提取的可靠区域占所有图像区域的面积百分比,简写为EST(estimated),即
(15)
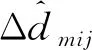
4)KITTI2012数据用到的超过阈值的像素百分比(PPT2),表示误差超过给定个数的像素占总统计像素数的百分比,即
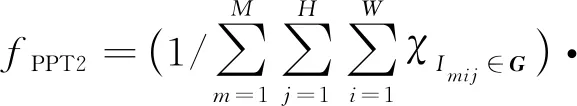
(16)
式中,eh表示给定的视差误差阈值。
2.3 Sceneflow实验结果分析
2.3.1 消融实验
考虑视差估计可以等价为特殊情况下的光流估计,所以RAFT方法(Teed和Deng,2020)的消融实验在这里也适用,本文和RAFT最大的区别是考虑视差估计的特性增加了第0次迭代的单边查找更新,所以这里对这一结构的提出进行消融实验,也就是比较有单边查找和无单边查找情况下的网络性能。
通过对Sceneflow的Flyingthings3D的21 818对540×960像素大小的训练图像随机裁剪得到256×512像素大小的图像输入网络训练44万次,批大小为4,训练过程中采用分段降低学习率的方法,使用RMSProp优化算法(Tieleman和Hinton,2012)进行学习。本文代码采用TensorFlow框架(Abadi等,2016)实现。各次迭代的EPE和PPT及迭代不同次数在NVIDIA GTX 1080Ti显卡下平均推理时间(100次推理取平均,推理图像大小为576×960像素),如表1所示,统计像素集合G包括所有的测试数据。从表1可以看到,随着迭代次数的增加,推理时间变长,但平均误差和超过阈值的像素百分比逐渐减小。带单边查找的时候,第0次更新平均误差达到了1.50像素,第4次更新达到了0.84亚像素的精度,超过阈值的像素百分比也减小到3.19%。表1中,带单边查找的网络比不带的网络各项指标都有一定的提升,尤其是第0次迭代的结果改善更加明显(注意推理时间与机器运行状态有关,可以认为两者的推理时间非常接近,不存在明显的差异),所以增加单边查找是合理和有利的,说明前面基于人的先验知识和经验对RAFT方法的改进是有效的。后面实验都是采用带单边查找的网络。
2.3.2 方法对比
本文方法SRS(similarity recursive search)与GC-Net(Kendall等,2017)、PSMNet(pyramid stereo matching network)(Chang和Chen,2018)、Edgestereo (Song等,2020)和AANet*(adaptive aggregation network)(Xu和Zhang,2020)方法的对比如表2所示,统计像素集合G包括所有的测试数据,考虑推理时间和硬件及图像大小强相关,给出了推理时间涉及的硬件和图像大小,为了便于对比,本文方法给出了两种图像大小对应的推理时间。可以看出本文方法获得了与先进方法相近的精度,结合表1,本文方法还可以通过选择不同的迭代次数实现在精度和推理时间上的灵活平衡,综合体现了本文方法的优越性能。
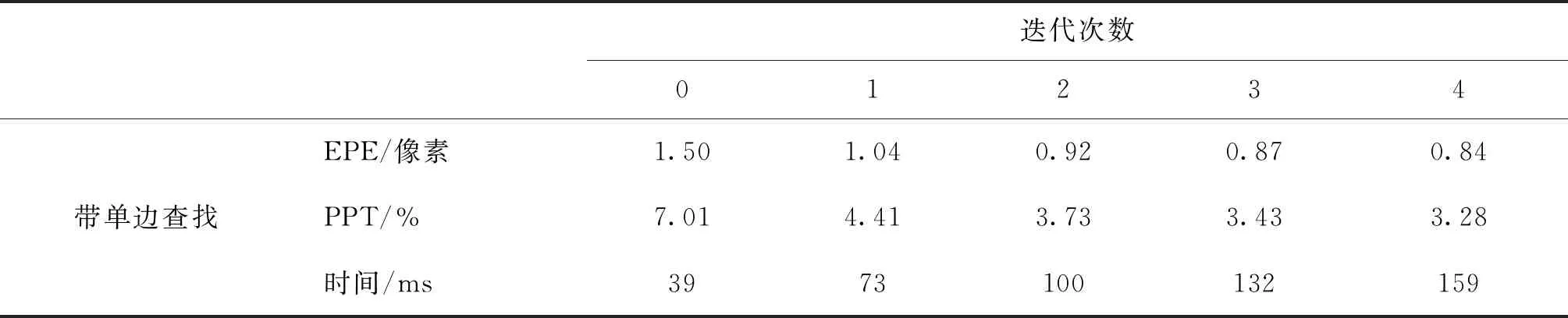
表1 Sceneflow测试数据集上各次迭代平均误差和超过阈值的像素百分比及推理时间Table 1 Average error, pixel percentage without a given threshold and inference time of each iteration on Sceneflow test set (with unilateral search)
2.3.3 可靠提取区域视差估计评估
本文方法在非遮挡区域、遮挡区域和可靠提取区域的评估指标如表3所示,注意这里的统计像素集合G分别对应非遮挡区域、遮挡区域和可靠提取区域。可以看出,本文方法在遮挡和非遮挡区域指标存在明显的差别,其中非遮挡区域第4次迭代平均误差达到了0.55像素,超过阈值的像素百分比只有1.61%,而遮挡区域平均误差为2.87像素,超过阈值的像素百分比甚至达到了13.95%。通过可靠区域提取后,平均误差减小到0.21像素,超过阈值的像素百分比甚至减小到0.29%,极大地提升了估计性能,而此时的提取区域大小也达到75.85%。图6展示了本文方法在Sceneflow测试集某对图像上的测试结果,可以看到,第0次迭代输出就已经得到比较完整的结构信息,随着迭代的增加,误差逐渐减小,边缘更加清晰。对比图6(g)-(i)可以发现,可靠区域提取基本去掉了遮挡区域,并且去掉了一些误差比较大的非遮挡区域(如最右上角的区域),保留了64.72%的区域。从图6(j)像素随误差分布图可以看出,可靠区域提取后,大误差的像素基本被去除,小误差的像素百分比明显增加。综合以上,说明本文可靠区域提取方法的有效性。

表2 Sceneflow测试集上其他方法和本文方法第4次迭代评估指标Table 2 Evaluation results of our method’s the 4th iteration and other methods on Sceneflow test set

表3 本文方法在Sceneflow测试集上3种区域的评估指标Table 3 Evaluation results of our method in three kinds of areas on Sceneflow test set
2.4 KITTI实验结果分析
为了进一步验证本文方法在实际场景数据上的性能,将Sceneflow数据集上训练好的模型分别在KITTI2015和KITTI2012两个数据集的训练集上进行微调(训练5 500次),然后交叉在KITTI2012和KITTI2015数据集的训练集上进行测试。另外,为了方便与其他方法进行公平比较,将Sceneflow数据集上训练好的模型在KITTI2012和KITTI2015 两个训练数据合集上训练1.1万次,然后分别在KITTI2012和KITTI2015 测试集上进行测试。
2.4.1 KITTI训练集交叉测试
KITTI2012和KITTI2015分别测试一对图像的交叉测试结果如图7所示,图中泛化表示在仿真数据集Sceneflow上训练好的模型直接在实际场景数据集KITTI上测试。从图7(c)可见,仅仅泛化就能得到不错的结果,而图7(d)-(i)说明微调及可靠区域提取后,模型在实际场景的指标能进一步提升。从图7(l)可见微调相对泛化能明显提升小误差的像素百分比且减小大误差的像素百分比,而可靠区域提取后不仅明显增加了小误差的像素百分比,且几乎去除了大误差的像素。对比图7的点云图,可以看到提取可靠区域前,点云中存在大量被遮挡区域的填充点云,这些填充点云分布在前景和背景之间,往往都是噪点,而可靠区域提取后这些噪点基本去除,使得前景和背景能比较好地分离,但是提取后的点云相对提取前密度减小,出现了一些明显的孔洞区域,这个问题可以后续考虑改进方法提升遮挡区域的深度估计,或者结合位姿估计叠加时间序列上的多帧深度估计信息。
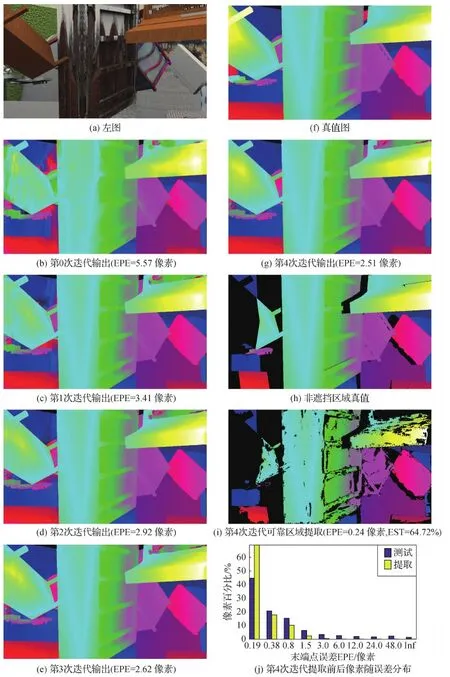
图6 Sceneflow测试集测试结果图示Fig.6 Illustration of test results on Sceneflow test set((a) left image; (b) the 0th iteration output; (c) the 1st iteration output; (d) the 2nd iteration output; (e) the 3rd iteration output; (f) ground truth; (g) the 4th iteration output; (h) ground truth in non-occluded areas; (i) the 4th iteration reliable region extraction; (j) pixel distribution with EPE before and after reliable region extraction of the 4th iteration)

图7 KITTI训练集测试结果图示Fig.7 KITTI training set test results((a) left images; (b) ground truths; (c) generalization results of the 4th iteration; (d) the 0th iteration output after fine tuning; (e) the 1st iteration output after fine tuning; (f) the 2nd iteration output after fine tuning; (g) the 3rd iteration output after fine tuning; (h) the 4th iteration output after fine tuning; (i) the 4th iteration reliable region extraction after fine tuning;(j) point cloud within 50 meters of the 4th iteration after fine tuning; (k) point cloud within 50 meters of the 4th iteration reliable region extraction result after fine tuning; (l) pixel distribution with EPE before and after reliable region extraction of the 4th iteration after fine tuning)
2.4.2 KITTI测试集测试
同时在两个KITTI训练集上训练后的模型分别在KITTI两个测试集上的测试结果及对比方法的结果如表4和表5所示(表中其他方法的数据来源于KITTI网站http://www.cvlibs.net/datasets/kitti/index.php),其中LEAStereo(Cheng等,2020)和GANet-deep(Zhang等,2019)是KITTI排行榜上指标最佳、已经发表文献并且在KITTI2012和KITTI2015两个数据集上进行了测试的方法。本文方法(提取可靠区域后)在KITTI2012数据集上估计了79.42%的像素点,在KITTI2015数据集上估计了77.80%的像素点,其他方法估计了100%的区域。表4和表5中仅展示了本文方法最后一次迭代的评估指标。其中Noc表示非遮挡区域,All表示包含所有的区域,分别对应各自的统计像素集合G。表4是误差大于给定像素(式(16)中eh分别为2、3、4、5像素时)的像素百分比PPT2。表5是误差大于3像素并且误差占真实视差的百分比(即相对误差)大于5%的像素百分比PPT。组合表示统计像素集合G。由于本文方法在KITTI数据上没有做过多的参数调优,所以在做可靠区域提取前本文方法的指标与对比方法还存在一定差距。但如果只考虑被算法估计了有效视差值的像素点,本文方法的指标在两个数据集上都具有绝对优势(KITTI官网提供根据全部带真值的像素进行评估和根据带真值的像素与提交数据提供有效值的像素的交集进行评估的排行榜,截至2021年12月1日时该方法在第2种评估指标上居于榜首),充分说明本文提取可靠区域方法的有效性。

表4 KITTI2012测试集上其他方法和本文方法第4次迭代评估指标PPT2Table 4 Evaluation results of our method’s the 4th iteration and other methods on KITTI2012 test set

表5 KITTI2015测试集上其他方法和本文方法第4次迭代评估指标PPTTable 5 Evaluation results of our method’s the 4th iteration and other methods on KITTI2015 test set
3 结 论
本文利用视差估计和光流估计之间的相似性,将光流估计的优势方法RAFT迁移到了视差估计,利用多尺度的相似性迭代查找实现高精度的视差估计,并且能在精度和推理时间之间通过选取不同的迭代次数实现灵活平衡。针对视差估计左图匹配点只能出现在右图的相对左边,增加单边相似性查找,进一步提升了视差估计精度,在Sceneflow数据集上得到了与先进方法可以相提并论的精度。针对遮挡区域误差较大,提出了左、右图反序和翻转同时估计左、右图视差,并对比左、右图匹配点视差估计值的差值绝对值与给定阈值的大小获取可靠估计区域的方法,保证了提取区域的高精度视差估计,去掉了大量的遮挡区域和其他误差较大的区域,评估指标得到了明显提升。通过泛化实验验证了模型在仿真数据和真实场景数据之间的迁移能力,但是微调可以进一步提升真实场景的估计性能,在只考虑被估计部分的情况下,本文方法(结合可靠区域提取)在KITTI双目测试数据集上指标高居榜首。
下一步,考虑本文方法采用1/8分辨率的特征图通过相似性查找进行视差估计,极大地限制了估计精度,后续可以考虑采用高分辨率的特征图进行视差估计,但是同时需要提升推理速度;另外本文方法基本只能保证非遮挡区域较高精度的估计,遮挡区域需要针对性地提出改进策略;最后本文采用监督学习对网络进行训练,需要代价极高的标注数据,后续可以考虑研究非监督的方法对网络进行训练。
猜你喜欢
计算机应用与软件(2022年5期)2022-07-07
雪莲(2017年2期)2017-05-12
环球市场信息导报(2017年1期)2017-04-08
小天使·二年级语数英综合(2015年8期)2015-07-06
小雪花·成长指南(2014年8期)2014-08-26
新课程学习·中(2013年3期)2013-06-14
数理化学习·高一二版(2009年2期)2009-03-30
中学数学研究(2008年3期)2008-12-09
