
多源融合SLAM的现状与挑战
2022-02-28 06:39王金科左星星赵祥瑞吕佳俊刘勇
中国图象图形学报 2022年2期
王金科,左星星,赵祥瑞,吕佳俊,刘勇
浙江大学, 杭州 310027
0 引 言
同时定位与地图构建(simultaneous localization and mapping, SLAM)技术(Smith和Cheeseman,1986)经过几十年的发展,已取得丰硕的研究成果。它所关注的问题是载有传感器的机器人如何在未知环境中定位并构建出环境地图,是机器人估计自身状态和感知外部环境的关键技术。从一些综述文章(Durrant-Whyte和Bailey,2006;Dissanayake等,2011;Cadena等,2016)可知,SLAM的发展经历了3个阶段:第1阶段为早年的“经典”时期(Durrant-Whyte和Bailey,2006),主要完成了SLAM的概率解释,如基于扩展卡尔曼滤波器、粒子滤波器和极大似然估计的方法(Thrun等,2005);第2阶段为“算法分析”时期(Dissanayake等,2011),主要研究SLAM的基本性质,如收敛性、一致性、可观测性和稀疏性;第3阶段为当前的“鲁棒感知”时期(Cadena等,2016),主要解决复杂环境下的适应性问题。面对日趋复杂的应用场景,设计SLAM算法应统筹兼顾,有针对性地对算力、精度和鲁棒性等进行取舍(左星星,2021)。
在SLAM发展过程中,各种传感器承担着至关重要的角色,为定位与建图算法提供全局或局部的测量信息。全球定位系统(global positioning system, GPS)广泛用于户外环境中提供载体在全局坐标系下的位置测量(Burschka和Hager,2004;Chen等,2020a)。然而,在许多环境中,如高楼脚下、室内、隧道和海底等,GPS测量是不可靠或不可用的;惯性测量单元(inertial measurement unit,IMU)可感知机器人自身运动,虽然目前基于微机电系统的高性能、低成本和轻量化的IMU已经推向市场,但IMU测量由于存在零偏不确定性和累计误差(Huang,2019),无法长时间独立使用;相机在SLAM相关领域中的应用已经非常广泛,主要有单目相机(Davison,2003)、双目相机(Engel等,2015)和深度相机(Sturm等,2012)等。龙霄潇等人(2021)对视觉定位与地图构建进行了充分详细的调研。虽然已经有很多解决方案,但仅基于视觉的SLAM系统在动态环境、显著特征过多或过少以及存在部分或全部遮挡的条件下(如图1所示)工作时会失败,且受天气、光照影响较大(Forster等,2017b);基于激光(Hess等,2016)构建场景是传统且可靠的方法,它能够提供机器人本体与周围环境障碍物间的距离信息且比较准确,误差模型简单,对光照不敏感,点云的处理比较容易且理论研究也相对成熟,落地产品更丰富,但其重定位能力较差,激光SLAM在跟踪丢失后很难重新回到工作状态,不擅长在相似的几何环境中工作(Levinson和Thrun,2010),如长直走廊,对动态变化较大的场景适应性也较弱。

图1 具有挑战性的应用场景Fig.1 Challenging application scenarios((a)seasonal environmentl(Olid et al., 2018); (b)occluded scene(Bescos et al., 2018); (c)environment with too few salient features)
基于上述实际SLAM应用中的挑战与难点,现有的技术方法试图从多种传感器、多种特征和多维度信息融合3个层次来进行改善和解决,因此本文中将此3类方法统称为多源融合SLAM方法,具体如下:
1)针对用单传感器构建SLAM系统的局限性,研究者们首先提出将多种传感器组合,利用不同传感器的优势克服其他传感器的缺陷来提高定位建图算法在不同场景中的适用性和对位姿估计的准确性,涌现出视觉惯导(Qin等,2018)、激光惯导(Geneva等,2018)和激光视觉惯导(Shan等,2021)等多传感器融合系统;2)在对图像进行特征提取时,不仅考虑点特征,而且将线特征、平面特征和像素灰度信息等进行处理(Yang等,2019a,b),同时对激光雷达点云信息进行线特征点、面特征点和体素特征点的合理利用(Zhou和Tuzel,2018),从而达到多特征基元的融合;3)语义信息(Cadena等,2016)逐渐应用到SLAM中,它是一种长期稳定的特征信息,不易受环境因素影响,而传统SLAM方法主要使用环境的局部图像几何纹理信息,其容易受到光照、季节和天气等因素影响,故而语义和几何的多维度信息融合成为目前的研究热点之一(Rosinol等,2020)。
本文回顾分析目前多源融合SLAM方法的研究成果,从3个层次(如图2所示)分别进行阐述。
1 多传感器融合
多传感器融合SLAM经过一定时间的发展,已经逐步形成了视觉惯性系统和激光惯性系统和激光视觉惯性系统等多种融合方式,本节基于优化问题定义多传感器融合系统并给出惯性传感器的基本动力学模型,对常用的传感器融合方式进行阐述。
1.1 多传感器融合问题与惯性传感器动力学模型
1.1.1 多传感器融合系统
用于估计机器人状态的多传感器融合系统可分为感知自身运动信息的本体传感器(如编码器、磁力计、轮速计和惯性测量单元等,其中惯性测量单元使用最广泛)和感知外部环境的传感器(如相机、激光雷达和毫米波雷达等)。对于单机器人多传感器状态估计问题,通过使用n个独立的传感器S1,S2,…,Sn估计机器人在m个离散时间的状态X1,X2,…,Xm。将n个传感器的测量输出表示为(van Dinh和Kim,2020)
(1)
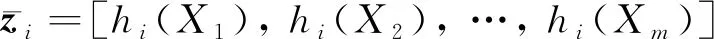
Z=Ψ(X1,X2,…,Xm)∈Rn×m
(2)
式中,矩阵Ψ(·)∈Rn×m为测量模型,机器人的动力学模型为
(3)
式中,Ξ(·)为动力学模型的抽象表示,矩阵X包含机器人在整个运行过程中的状态,矩阵U表示控制输入,矩阵W表示噪声。多传感器融合系统定义为优化问题的最大似然估计,即
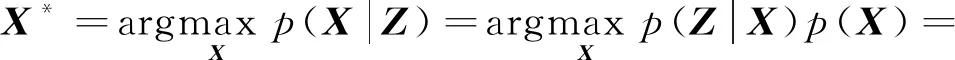
(4)
1.1.2 惯性传感器动力学模型
典型的惯性测量单元提供机体坐标系{I}下的三轴线性加速度am和三轴角速度ωm,测量输出为(Trawny和Roumeliotis,2005)
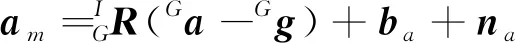
(5)
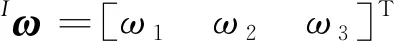
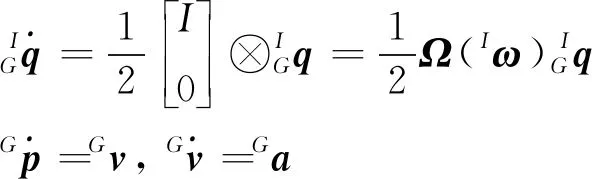
(6)
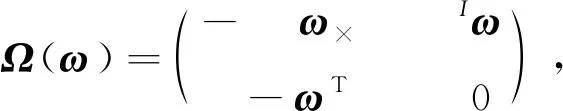
(7)
1.2 视觉惯性系统
Titterton和Weston(2005)指出,视觉惯性系统的核心是如何进行更好的状态估计,如何最佳地将IMU测量值和相机图像信息进行融合,为传感器安装平台提供最优的自身运动信息与环境信息(Huang,2019),典型的视觉惯性系统如图3所示。IMU和相机有两种融合方式:松耦合和紧耦合。松耦合把IMU测量信息和相机图像信息当做两个相对独立的模块分别进行处理,然后再把二者的估计结果一起进行融合或优化,可能会导致精度缺失;而紧耦合直接把相机的图像信息和IMU测量信息提供的约束放在一个估计器或优化器中进行求解,一般来说紧耦合精度更高,但计算量也更大。
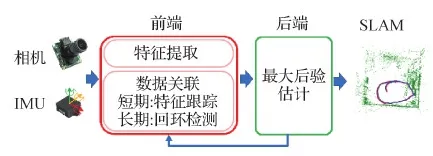
图3 典型视觉惯性SLAM系统框架 (Cadena等,2016; Forster等,2017a)Fig.3 A typical framework of visual-inertial SLAM (Cadena et al., 2016; Forster et al., 2017a)
在扩展卡尔曼滤波器(extended Kalman filter,EKF)的框架下,Konolige等人(2010)实现了相机与IMU的松耦合,状态预测步骤用视觉里程计得到的旋转量来完成,状态更新步骤则用IMU提供的位姿测量来实现。Tardif等人(2010)考虑更多的约束,进一步提高了模型的复杂度,将IMU与视觉里程计历史中多个时刻的状态加入状态向量中进行预测更新,利用了一个延迟的卡尔曼滤波器框架,但该模型复杂度较高。Weiss和Siegwart(2011)引入了一个黑箱模型来表示尺度不确定的视觉里程计,将相机位姿估计的输出作为测量值,与带有尺度信息的IMU位姿估计使用EKF框架进行松耦合。以EKF为滤波框架,Lynen等人(2013)又在EKF滤波框架中提出融合视觉里程计的相对位姿和IMU测量。
多状态约束卡尔曼滤波器(multi-state constraint Kalman filter, MSCKF)(Mourikis和Roumeliotis,2007)是基于EKF提出的一种紧耦合框架,使用IMU进行状态预测,将当前时刻的IMU速度、测量偏差等状态和滑动窗口中的多时刻相机位姿一并放到状态向量中,对视觉惯性里程计进行6自由度的运动估计。并提出了针对视觉特征的零空间操作,视觉特征点不再作为被估计的状态量。Leutenegger等人(2015)提出的OKVIS(open keyframe-based visual-inertial SLAM)虽然也用滑动窗口的方法来构建视觉惯性系统,但用的是因子图优化的方式求解相机与IMU的约束,而且会及时边缘化旧关键帧与特征点来保证Hessian矩阵的稀疏性,从而达到限制问题求解规模的效果。Qin等人(2018)提出的VINS-MONO(monocular visual-inertial system)使用关键帧图像间IMU的预积分约束(Forster等,2017a)和视觉特征点的观测约束构建因子图优化问题,并在后端优化中加入闭环约束,在纠正视觉惯性里程计漂移方面取得较好的效果。Liu等人(2018)使用相关边缘化提出的ICE-BA(incremental, consistent and efficient bundle adjustment),具有更高的全局一致性与计算效率。
此外,基于深度学习的视觉惯性系统也逐步发展起来。Liu等人(2019)提出InertialNet,训练端到端模型来推导图像序列和IMU信息之间的联系,预测相机旋转。Shamwell等人(2020)提出无需IMU内参或传感器外参的无监督深度神经网络方法,通过在线纠错模块解决定位问题,这些模块经过训练可以纠正视觉辅助定位网络的错误。Kim等人(2021)为不确定性建模引入了无监督的损失,在不需要真值协方差作为标签的情况下学习不确定性,通过平衡不同传感器模式之间的不确定性,克服学习单个传感器不确定性的局限性,在视觉和惯性退化的场景中进行了验证。
1.3 激光惯性系统
激光雷达(light deteation and ranging, LiDAR)与IMU也是常用的组合方式,也可分为松耦合与紧耦合两种融合方式。
基于松耦合的激光惯性里程计,在LOAM(lidar odometry and mapping)(Zhang和Singh,2014)推出后,追随者越来越多。LOAM定义了逐帧跟踪的边缘与平面3D特征点,使用高频率的IMU测量对两帧激光雷达之间的运动进行插值,该运动作为先验信息用于特征间的精准匹配,从而实现高精度里程计。Shan和Englot(2018)在LOAM的基础上提出LeGO-LOAM(lightweight and ground-optimized lidar odometry and mapping),通过对地平面的优化估计,提高用在地面车辆上的LOAM的实时性能。然而,当面临无结构环境或退化场景(Zhang等,2016),这些算法性能将会大大降低甚至失效,因为在长高速公路、隧道或空旷空间等场景中,激光雷达的作用距离有限,无法找到有效约束。
LIPS(lidar-inertial plane SLAM)(Geneva等,2018)是激光雷达与IMU紧耦合的早期工作之一,它是一种基于图优化的框架,最小化平面特征之间的距离和IMU残差项,提出基于最近点的平面表示方法,优化3D平面因子与IMU预积分。Ye等人(2019)在LOAM的基础上,引入IMU的预积分测量量,提出在快速移动场景中,比LOAM性能更好的LIOM(lidar inertial odometry and mapping)。同样基于LOAM框架,Shan等人(2020)通过引入局部扫描匹配提出的LIO-SAM(lidar inertial odometry via smoothing and mapping),其系统结构如图4所示。使用IMU预积分对激光雷达点云做运动补偿并为激光点云的配准提供初值,此外,该系统还可以加入闭环与GPS信息来消除漂移,从而实现长时间导航。在退化场景中,由于缺乏有效观测,紧耦合的激光惯性系统同样很难适应。
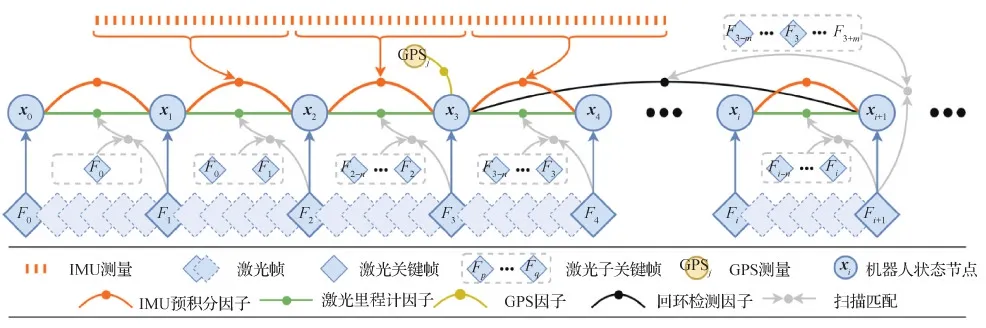
图4 LIO-SAM紧耦合激光惯性系统结构(Shan等,2020)Fig.4 Tightly coupled lidar-inertial system structure of LIO-SAM(Shan et al., 2020)
1.4 激光视觉惯性系统
为了使SLAM算法在光照条件较差或结构退化的场景中都能有效工作,将激光雷达、相机和IMU三者进行融合是个很好的方案。本文也从松耦合与紧耦合两个方面对该系统进行回顾。
近年涌现出将视觉与激光雷达和IMU松耦合的解决方案,几种传感器优势互补,既能够适应退化场景又兼具激光雷达惯性系统的高精度平滑轨迹。Zhang等人(2014)提出DEMO(depth enhanced monocular odometry),使用激光雷达的点云深度值为视觉特征点提供深度信息,可以提供更高精度的位姿估计和更高质量的地图。Zhang和Singh(2015)又基于LOAM算法,集成单目特征跟踪与IMU测量来为激光雷达扫描匹配提供距离先验信息,提出了V-LOAM(visual-lidar odometry and mapping),然而算法执行过程是逐帧进行的,缺乏全局一致性。针对这一问题,Wang等人(2019)通过维护关键帧数据库来进行全局位姿图优化,从而提升全局一致性。为了克服退化问题,Khattak等人(2020)提出另外一种类似LOAM的松耦合方法,它使用视觉惯性先验进行激光雷达扫描匹配,可以在无光照的隧道中运行。Camurri等人(2020)提出用于腿足机器人的Pronto,用视觉惯性里程计为激光雷达里程计提供运动先验信息,并能校正视觉与激光之间的位姿。
为了提高SLAM系统的鲁棒性,研究者们对激光雷达、视觉与IMU的紧耦合方式进行了探索。Graeter等人(2018)提出了一种基于集束调整(bundle adjustment, BA)的视觉里程计系统LIMO(lidar-monocular visual odometry),该算法将激光雷达测量的深度信息重投影到图像空间,并将其与视觉特征相关联,从而保持准确的尺度信息。Shao等人(2019)提出的VIL-SLAM(visual inertial lidar SLAM),直接对3种传感器信息进行联合优化,将视觉惯性里程计与激光里程计相结合作为单独的子系统,用来组合不同的传感器模式。许多学者基于MSCKF对三者执行联合状态优化,Zuo等人(2019a)的LIC(lidar-inertial-camera)-Fusion也用MSCKF框架对激光雷达边缘特征、IMU测量和稀疏视觉特征进行紧耦合操作。在其后续工作LIC-Fusion2.0中(Zuo等,2020),引入了基于滑动窗口的平面特征跟踪方法来处理激光雷达的3D点云。Shan等人(2021)提出的LVI-SAM(lidar-visual-inertial smoothing and mapping),由视觉惯导子系统与激光惯导子系统组成,基于因子图优化,可以实现鲁棒高精度的状态估计与建图。Wisth等人(2021)提出的紧耦合激光视觉惯性系统(VILENS)(框架如图5所示),则用一个因子图优化框架来联合优化3种传感器,直接提取激光雷达点云中的线面特征,达到实时处理激光雷达数据的目的。
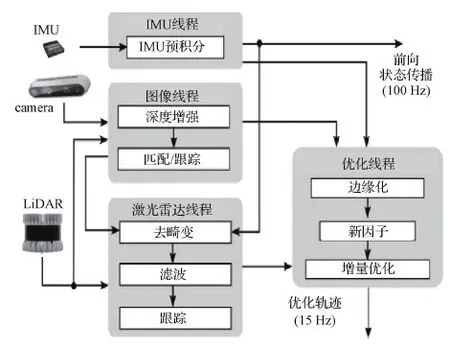
图5 紧耦合激光视觉惯性系统结构(Wisth等,2021)Fig.5 Overview of the VILENS system architecture (Wisth et al., 2021)
1.5 其他传感器融合系统
除了上述的相机、IMU和激光雷达的传感器组合融合方式,还有许多其他的传感器广泛应用于SLAM中。Khan等人(2018)使用卡尔曼滤波器将超声波距离传感器、IMU和轮速计进行融合,实现定位与栅格地图构建。Zhu等人(2019)针对大视野应用场景,使用全景相机实现高精度的相机位姿估计和3D稀疏特征地图的构建。Jang和Kim(2019)针对未知水下环境,融合单波束声学高度计、多普勒测速仪(Doppler velocity log, DVL)或IMU,实现基于面板的测深SLAM。Almalioglu等人(2021)使用无迹卡尔曼滤波(unscented Kalman filter,UKF)框架融合IMU和毫米波雷达信息,完成室内的低成本位姿估计。Zou等人(2020)使用WiFi、激光雷达和相机等传感器,可以在易于访问的自由空间中同时构建密集WiFi无线电地图和空间地图,支持高斯过程回归条件最小二乘生成对抗网络,实现移动机器人平台在复杂室内的高精度定位。Zhou等人(2021)提出一种UWM(ultra-wideband)坐标匹配方法,通过UWB SLAM和LiDAR SLAM中的采样点对,使用轨迹匹配算法得到两个坐标系之间的变换关系。
多传感器融合系统的简要对比如表1所示,随着新的传感器应用,会出现更多的传感器组合方式,相信未来SLAM的适应性、鲁棒性和性能精度能够进一步得到提升。
2 多特征基元融合
针对复杂环境,基于单特征基元的SLAM在精度和鲁棒性方面都有所欠缺,容易受到光照、运动和纹理等因素的影响,不确定性较高。而对于相机图像,不仅可以从中提取特征点,还可以获得线段特征、平面特征和像素灰度等信息特征;对于激光雷达点云,可以从中提取线特征点、面特征点和有正态分布特性的体素特征(voxel)。将对多特征基元之间的融合进行介绍,多特征基元融合系统的简单对比如表2所示。
2.1 特征点法与直接法
在视觉SLAM系统中,特征点法通过提取和匹配相邻图像(关键)帧的特征点估计对应的帧间相机运动,包括特征检测、匹配、运动估计和优化等步骤(邹雄 等,2020)。最具代表性的工作为牛津大学提出的PTAM(parallel tracking and mapping)(Klein和Murray,2007),它开创性地将相机跟踪和建图分为两个并行的线程。基于关键帧的技术已经成为视觉SLAM和视觉里程计的黄金法则,在同等算力的情况下,它比滤波方法更加精确(Strasdat等,2012)。Strasdat等人(2011)使用双窗口优化和共视图实现了大场景的单目视觉SLAM。基于前人的工作,Mur-Artal等人(2015)提出的ORB-SLAM,Mur-Artal和Tardós(2017)提出的ORB-SLAM2(2017)以及Campos等人(2021)提出的ORB-SLAM3使用ORB(oriented fast and rotated brief)特征,这种描述子可以提供较长时间内的数据关联。ORB-SLAM系列算法使用DBoW2(bags of binary words)(Glvez-López和Tardós,2012)实现回环检测和重定位,ORB-SLAM3甚至可以适配单目、双目、RGB-D、针孔和鱼眼等相机模型。基于特征的方法比较依赖检测和匹配阈值,还需要稳健的技术去处理错误匹配,且计算量较大。
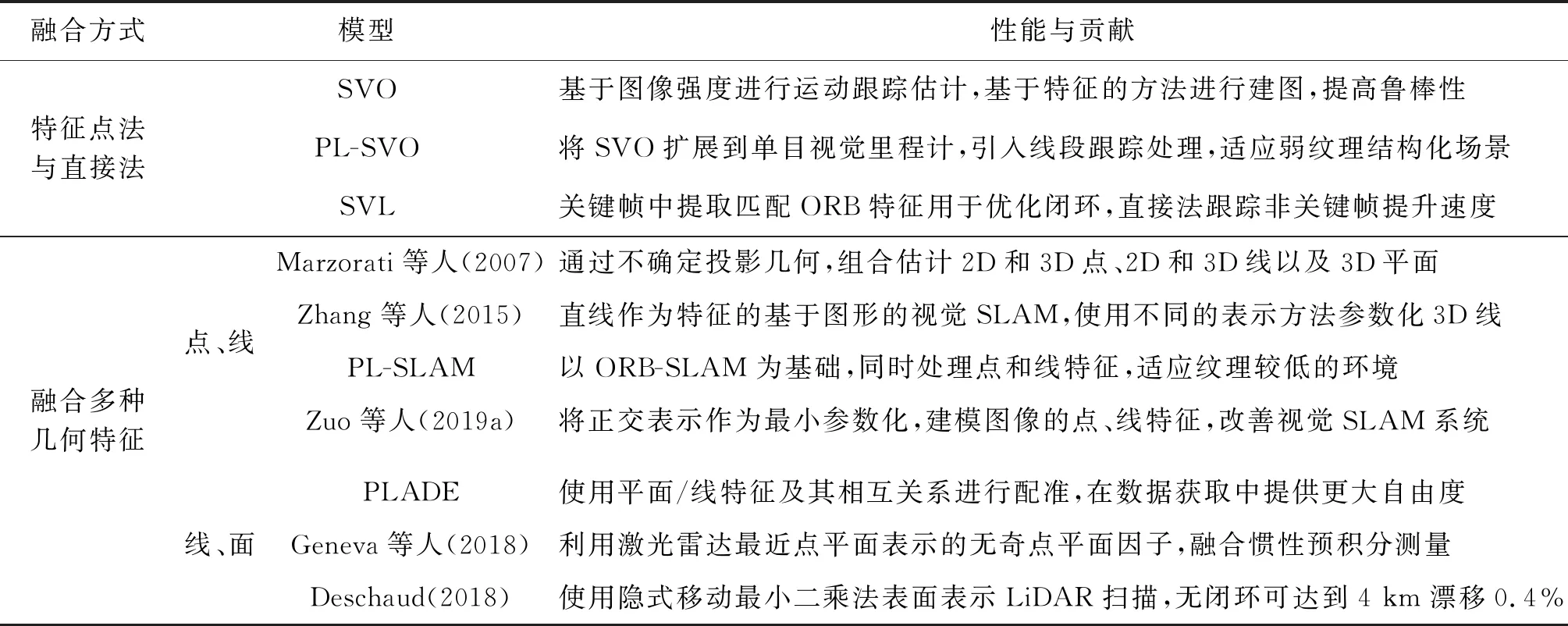
表2 多特征基元融合算法简要对比Table 2 Briof comparison of multi-feature primitive fusion algorithms
与特征点法不同的是,直接法不用提取图像特征,而是直接使用像素强度信息,通过最小化光度误差来实现运动估计。Newcombe等人(2011b)的DTAM(dense tracking and mapping)首先使用直接法实现了单目视觉SLAM,它提取每个像素的逆深度并通过优化的方法构建深度图,进而完成相机位姿估计。LSD-SLAM(large-scale direct SLAM)(Engel等,2014)针对大规模场景,能够使用单目相机获得全局一致的半稠密地图。DSO(direct sparse odometry)(Engel等,2018)对整个图像中的像素进行均匀采样,考虑了光度校准、曝光时间、镜头渐晕(lens vignetting)和非线性响应函数。LDSO(loop-closure DSO)(Gao等,2018)在DSO的基础上增加闭环,保证长时间的跟踪精度。Stereo DSO(Wang等,2017a)则用多视图几何来估计深度值。虽然直接法相较于特征点法省去了特征点和描述子的计算时间,只利用像素梯度就可构建半稠密甚至稠密地图,但是由于图像的非凸性,完全依靠梯度搜索不利于求得最优值,而且灰度不变是一个非常强的假设,单个像素又没有什么区分度(高翔和张涛,2019),所以直接法在选点较少时无法体现出其优势。
利用特征法和直接法的优点,Forster等人(2014)在多旋翼飞行器上实现了半直接单目视觉里程计(semi-direct visual odometry, SVO)。该系统工作流程如图6所示,使用像素间的光度误差,通过基于稀疏模型的图像对齐进行位姿初始化;通过最小化特征快匹配的重投影误差优化位姿和地图点,可以更快更准地得到状态估计结果。他们还将这种组合方式推广到了多相机系统中(Forster等,2017b)。针对SVO对姿态初始值过度依赖的问题,Gomez-Ojeda等人(2016)提出PL-SVO(SVO by combining points and line segments),用点和线段特征对SVO进行改进。Lee和Civera(2019)则将ORB-SLAM与DSO进行松耦合来提升系统的定位精度,该方法的前后端几乎是独立的,限制了性能的进一步提高。Kim等人(2019)提出一种双目测距的半直接方法,其中运动估计用特征法来获得,相机姿态则用直接法来优化。SVL(semi-direct visual with loopclosuer)在关键帧中提取ORB特征,然后用直接法跟踪非关键帧中的这些特征,从而实现一个快速准确的半直接SLAM系统(Li等,2019b)。
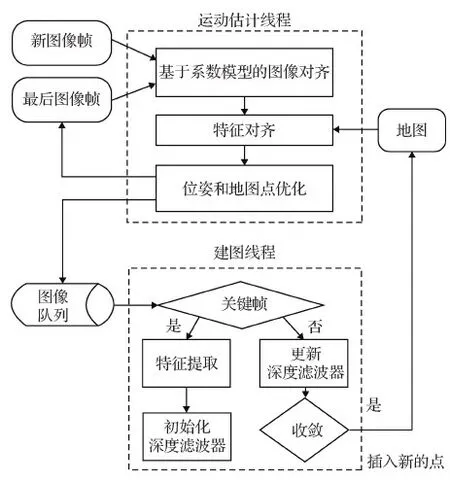
图6 特征点法与直接法结合的跟踪与建图流程 (Forster等,2014,2017b)Fig.6 Tracking and mapping pipeline combining feature-based method and direct method (Forster et al., 2014, 2017b)
2.2 融合多种几何特征
点特征在视觉SLAM和激光SLAM中得到研究者们普遍使用,然而在走廊、礼堂和地下车库等环境中,由于无法有效提取足够的特征点,基于点特征的方法不再适用,但是上述环境中的直线、曲线、平面、曲面和立方体等多维几何特征却十分丰富,这为研究者们解决问题提供了思路。
许多学者尝试使用环境中的点、直线(线段)和面特征来辅助视觉SLAM系统进行状态估计。Marzorati等人(2007)通过不确定投影几何将3D点和线集成到6自由度视觉SLAM中,在构成的框架内,可以描述、组合和估计诸如2D点和3D点、2D和3D线以及3D平面等各种类型的几何元素,以此来提高建图和位姿估计精度。Zhang等人(2015)提出一种基于图像直线特征的视觉SLAM系统,使用双目相机进行运动估计、位姿优化和BA,并用不同的表示方式来参数化3D线,在线特征比较丰富的环境中,性能要优于基于点特征的方法。Gomez-Ojeda和Gonzalez-Jimenez(2016)用基于概率的方法,将点特征与线特征进行组合,通过最小化点和线段特征的投影误差来恢复相机运动,该系统在低纹理场景中也能有效地工作。PL-SLAM(points and lines SLAM)(Pumarola等,2017)则以ORB-SLAM为基础,同时处理点特征和线特征,其系统框架如图7所示,用3幅连续图像帧中的5条线段来估计相机位姿并构建3D地图。同样基于ORB-SLAM,Zuo等人(2017)采用正交表示作为最小参数化,建模视觉SLAM中的点特征和线特征,并推导出重投影误差的关于线特征参数的雅可比矩阵,并在仿真和实际场景中取得了较好的实验效果。Yang等人(2019a)基于图像的线段测量,提出滑动窗口的3D线三角化算法,并揭示了导致三角化失败的3种退化运动,为其提供几何解释。Arndt等人(2020)将平面地标和平面约束添加到基于特征的单目SLAM中,它不依赖深度信息或深度神经网络就可实现更完整更高级别的场景表示。除此之外,共线(Zhou等,2015)、共面(Li等,2020)和平行(Li等,2020a)等关系也可为几何特征提供正则化,进一步提高估计器的精度。甚至更多维的几何特征,如曲线(Meier等,2018)、曲面(Nicholson等,2019)和立方体(Yang和Scherer,2019)都可用来提升SLAM系统的性能。

图7 双目PL-SLAM系统框架(Pumarola等,2017)Fig.7 Scheme of the stereo PL-SLAM system (Pumarola et al., 2017)
激光雷达的激光点测量信息可直接用点云匹配算法进行位姿估计(Konecny等,2016)。近年来激光SLAM也开始利用线特征(Wu等,2018)、面特征(Berger,2013)等多维几何特征提供有效约束,进行更高精度的点云配准和位姿估计。PLADE(plane-based descriptor)(Chen等,2020c)用平面特征和线特征以及二者之间的相互关系来进行配准,并且可以配准重叠较小的点云,使数据获取更加自由。激光雷达数据中,与直接使用点特征相比,线和面特征之间的数据关联有时更为简单,比如仅有3D位置的两个激光点很难进行有效区分和准确的数据关联。现有的激光雷达数据关联通常需要迭代地寻找最近的几何特征(Deschaud,2018),这种数据关联方式效率较低,容易出错,会降低SLAM的精度并导致状态估计不一致。
3 多维度信息融合
传统SLAM系统发展几十年至今,理论方面逐渐趋于成熟。其中的闭环检测通常依赖于从传感器原始数据中提取的几何基元特征,如特征点、线和面等,通过对几何特征编码的场景特征向量进行匹配实现闭环检测。但在恶劣环境下,几何特征提取极不稳定,难以保证准确的闭环检测。而语义信息是一种长期稳定的特征,不易受环境因素的影响,但只用语义信息无法实现精确定位。因此,可以尝试将语义信息融合到传统SLAM系统中,构建长期稳定的定位系统。近年来,基于数据驱动的深度学习的方法逐渐兴起,通过对大量数据的学习可以得到比手工设计更加精确的模型,故而传统方法与学习方法有效融合可以提升定位系统的精度和鲁棒性。此外,物理信息辅助位姿估计也是许多研究者感兴趣的方法之一,通过对特定物理信息分析建模,可为状态估计提供有效约束。表3对当前的多维度信息融合系统进行了对比。
3.1 几何信息与语义信息
几何信息在机器人定位导航领域至关重要,语义信息不仅可以辅助构建稳健的SLAM系统,还可以为机器人提供抽象模型,便于其理解和执行人类的指令。早期的几何重建如运动恢复结构(structure from motion,SfM)(Enqvist等,2011)、多视图立体几何(Schops等,2017)和语义分割(Garcia-Garcia等,2017)的研究基本上是独立开展的。近年来,研究者们对二者交叉的研究和应用兴趣浓厚,并产生了许多优秀的成果(Cadena等,2016)。
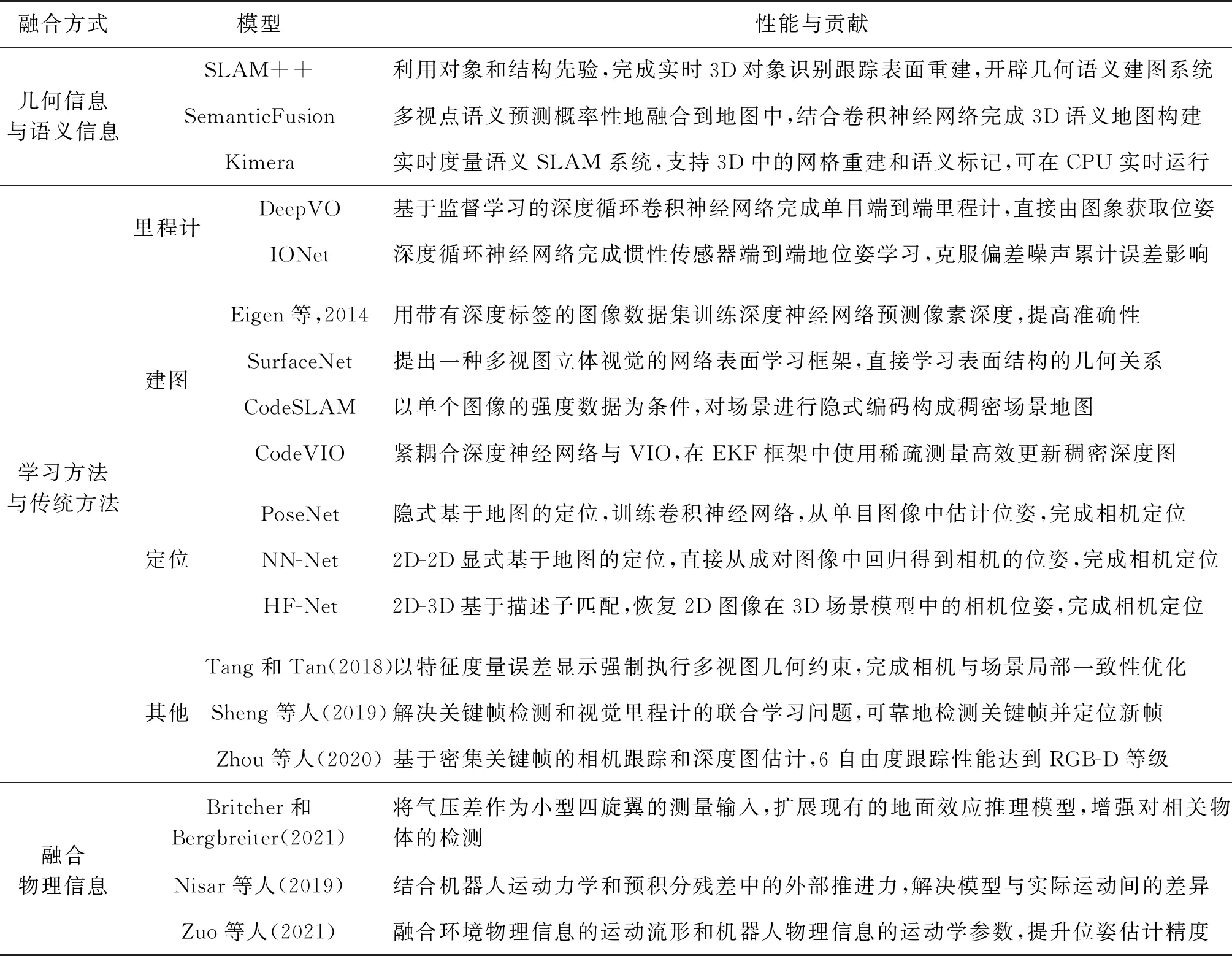
表3 多维度信息融合算法简要对比Table 3 Brief comparison of multi-dimensional information fusion algorithms
早期的几何语义理解由于计算量问题无法达到实时,只能离线运行(Bao和Savarese,2011;Brostow等,2008)。SLAM++(Salas-Moreno,2013)是一个实时增量的SLAM系统,可以高效地对场景进行语义描述,非常适合由重复相同的结构和特定领域的物体组成的公共建筑内部环境,能够完成3D对象的实时识别跟踪,并提供6自由度相机对象约束。得益于这项开创性工作,涌现出了大批实时几何语义建图系统。SemanticFusion(McCormac等,2017)将卷积神经网络和ElasticFusion(Whelan等,2015)相结合,用RGB-D相机帧间的像素级匹配把每帧的2D分割融合为一个连贯的3D语义地图,可以在25 Hz帧率下进行实时交互。Zheng等人(2019)基于语义分割的在线RGBD重建,提出一种未知环境下的机器人主动场景理解方法,使用在线估计的视角分数场(viewing score field,VSF)和截断符号距离函数(truncated signed distance function)联合优化路径和相机位姿。Tateno等人(2015)和Li等人(2016)使用概率推理的方法,结合对象位姿估计和SLAM场景理解与语义分割,构建了一种在线增量场景建模框架,提高了语义分割和6自由度对象位姿估计性能。其他诸如Fusion++(McCormac等,2018)、Mask-Fusion(Runz等,2018)、Co-Fusion(Rünz和Agapito,2017)和MID-Fusion(multi-instance dynamic fusion)(Xu等,2019a)等工作用的传感器大部分是RGB-D相机,基于体素、面元或物体表示,并使用GPU加速来实现跟踪或建图。其他基于CPU的解决方案,如在室内场景中可实时运行在移动设备上的方法(Wald等,2018),Voxblox(Grinvald等,2019),PanopticFusion(Narita等,2019),传感器用的也是RGB-D相机。也有其他的一些解决方案使用激光雷达,如SemanticKitti(Behley等,2019)和SegMap(Dubé等,2018);单目相机,如CNN-SLAM(Tateno等,2017),VSO(visual semantic odometry)(Lianos等,2018),XIVO(Dong等,2017)等。Kimera(Rosinol等,2020,系统结构如图8所示)将视觉惯性SLAM系统、网格重建和语义理解相结合,提供一个快速、轻量级并且可以扩展的基于CPU的解决方案,可以在室内室外等场景中良好运行。
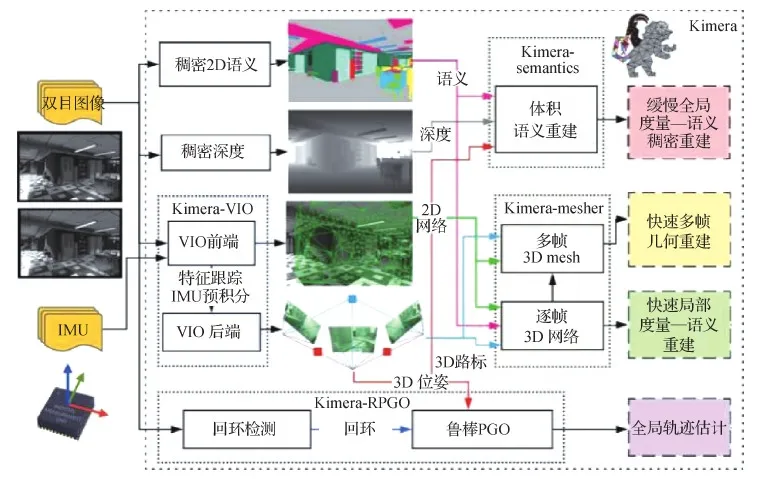
图8 Kimera结构示意图(Rosinol等,2020)Fig.8 Kimera’s schematic(Rosinol et al., 2020)
3.2 学习方法与传统方法
传统SLAM方法发展至今,理论已趋于成熟,并在各种数据集上达到了不错的效果。但实际应用场景复杂度一般要高于数据集,某些基于物理模型或几何理论的假设与实际情况不相符。近年来基于深度学习的方法逐渐兴起,可以通过数据驱动的方式学习得到比手工设计更加精确的模型,从而提升SLAM系统的性能。从里程计估计、建图和全局定位到同时定位与建图(Chen等,2020b),深度学习方法已经在SLAM系统的方方面面得到应用。
里程计用两帧或多帧传感器数据来估计载体的相对位姿变化,以初始状态为基础推算出全局姿态,其核心问题是如何从各种传感器测量中准确地估计出平移和旋转变换。当前的深度学习方法在视觉里程计、惯性里程计、视觉惯性里程计和激光里程计等应用中已经实现端到端的方案。典型的基于学习的视觉里程计结构如图9所示。基于监督学习的DeepVO(Wang等,2017b)使用卷积神经网络和递归神经网络的组合方式实现视觉里程计的端到端学习,卷积神经网络完成成对图像的视觉特征提取,递归神经网络则用来传递特征并对其时间相关性建模。基于无监督学习的SfmLearner(Zhou等,2017)由一个深度网络和一个位姿网络构成,深度网络用来预测图像的深度图,位姿网络用来学习图像之间的运动变换。单目视觉里程计D3VO(deep depth, deep pose and deep uncertainty visual odometry)(Yang等,2020)在深度、位姿和不确定性估计3个层次上使用深度网络,在仅使用一个相机的情况下与当时性能最好的视觉惯性里程计不相上下。Chen等人(2018)提出IONet(inertial odometry networks)用于从惯性测量序列中端到端学习相对位姿,这种纯惯性方案可以应用在视觉信息缺失的极端环境中。DeepVIO(deep learning visual inertial odometry)(Han等,2019)将双目图像和惯性数据集成到一个无监督学习框架中,用特有损失进行训练,可以在全局范围内重建运动轨迹。CodeVIO(code visual-inertial odometry)(Zuo等,2020)提出一个轻量级紧耦合的深度网络和视觉惯性里程计系统,可以提供准确的状态估计和周围环境的稠密深度图。对于激光雷达里程计,LO-Net(lidar odometry networks)(Li等,2019a)用深度卷积网络端到端地训练激光雷达点云的特征选择、特征匹配和位姿估计,甚至可以用几何信息和语义信息提高系统精度,与LOAM算法的准确度相当。Kim等人(2021)在对不确定性进行建模时,引入无监督学习,不需要真值协方差等标签,并提出一种方法可以平衡不同传感器模型之间的不确定性,在某些数据集上的效果已优于传统方法。
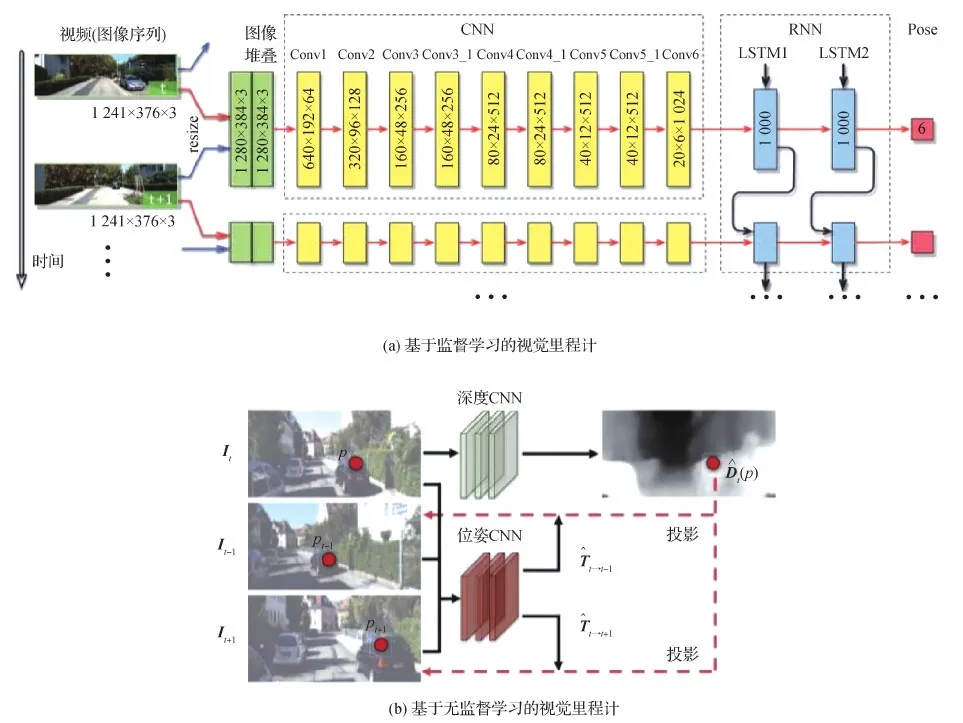
图9 基于监督学习的视觉里程计(Wang等,2017b)和基于无监督学习的视觉里程计(Zhou等,2017)典型结构Fig.9 The typical structure of supervised learning of visual odometry (Wang et al., 2017b) and unsupervised learning of visual odometry(Zhou et al., 2017)((a)supervised learning;(b)unsupervised learning)
在建图领域,深度学习已经完成了场景感知理解的体系构建。从几何地图到语义地图再到一般地图,深度学习都有所涉猎。在几何地图的深度表示中,基于监督的学习方法(Eigen等,2014;Ummenhofer等,2017;Liu等,2016)用带有深度标签的图像数据集训练深度神经网络来预测图像中每个像素的深度,相对传统基于结构的方法,虽然可以提高深度预测的准确性,但这种方法过于依赖模型训练,在新的场景中很难有效工作。基于无监督的学习方法(Godard等,2017;Zhou等,2017)分别将空间一致性和时间一致性作为自监督信号,进行深度和自身运动估计,在双目和单目深度预测中取得了较好的效果,若能加入更多的附加约束,应该可以更好地回复网络参数,提升深度预测性能。对于体素这一几何特征,SurfaceNet(Ji等,2017)提出一种多视图立体视觉的网络表面学习框架,可以直接学习表面结构的照片一致性和几何关系,通过学习预测体素的置信度,进一步确定它是否在表面上来重建场景的3D表面,虽然可以将其准确重建,但缺乏更进一步的后处理方法来进一步提高精度。开创性工作PointNet(Charles等,2017)致力于直接处理点特征,通过最大池化单个对称函数处理无序的点数据,用于目标分类、部分分割和场景语义理解。对于语义地图,DA-RNN(data associated recurrent neural networks)(Xiang和Fox,2017)提出数据关联递归神经网络,将递归模型引入语义分割框架中,从而学习多个视图框架上的时间连接,网络的输出与 KinectFusion(Newcombe等,2011a)等建图技术结合,以便将语义信息注入到重建的3维场景中。但该结构主要关注对象类标记,对广泛的语义标记问题还需进一步验证。CodeSLAM(Bloesch等,2018)以单个图像的强度数据为条件,将场景进行隐式编码来构成通用详细的场景地图,这种基于关键帧的方法,可以通过引入运动估计先验来完成鲁棒跟踪。Roddick和Cipolla(2020)使用语义贝叶斯占用网络框架,提出简单统一的端到端深度学习框架,直接从单目图像中估计语义地图,可以为车道检测预测提供思路。SLOAM(semantic lidar odometry and mapping)(Chen等,2020d)利用自定义的虚拟现实工具来标记用于训练语义分割网络的激光雷达3D扫描,实现基于语义特征的位姿优化,可在手持设备或飞行器上稳定运行。
全局定位通过2D或3D场景模型提供的先验知识确定载体的绝对位姿,深度学习可用于解决此过程中的数据关联问题。2D-2D显式基于地图的定位NN-Net(N ranked references and N relative poses networks)(Laskar等,2017)直接从成对图像中回归相对位姿,隐式基于地图的定位PoseNet(Kendall等,2015)通过训练卷积神经网络,从单目图像中估计相机位姿,从而端到端地解决相机重定位问题。2D-3D基于描述子匹配的HF-Net(hierarchical features networks)(Sarlin等,2019)和基于场景坐标回归的定位(Bui等,2018),用深度学习的方法恢复2D图像在3D场景模型中的相机位姿。激光雷达3D-3D的定位L3-Net(Lu等,2019)使用PointNet(Charles等,2017)处理点云数据以提取编码某些有用属性的特征描述子,并通过递归神经网络建模动力学模型,用最小化点云输入和 3D 地图之间的匹配距离来优化预测位姿和真实值之间的损失,进而完成基于学习激光雷达定位框架。
SLAM系统中的其他模块:确保相机运动和场景几何的局部一致性的局部优化(Clark等,2018;Tang和Tan,2018);在全局范围内限制轨迹漂移的全局优化(Zhou等,2020;Czarnowski等,2020);减轻系统漂移误差的关键帧(Sheng等,2019)和回环检测(Süenderhauf等,2015;Gao和Zhang,2017);以及对SLAM系统提供置信度度量的不确定估计(Wang等,2018),都有相应的深度学习方案提出。
3.3 融合物理信息
SLAM算法一般部署在特定环境中的特定机器人平台上,来自于环境和机器人平台自身的物理约束可以为状态估计提供有效信息。利用物理信息辅助SLAM任务中位姿估计主要有两类方法(左星星,2021):一类方法直接使用传感器测量相应的物理量,如气压(Britcher和Bergbreiter,2021)、高度(Jang和Kim,2019)和物理接触(Hartley等,2020)等;另一类方法在没有直接的传感器测量情况下,从背景知识出发间接制定约束条件,如地形(Sawa等,2018;Xu等,2019b)和推进力(Nisar等,2019)等。
对于直接使用传感器测量值,Britcher和Bergbreiter(2021)评估了气压差测量作为小型四旋翼地面、天花板和墙壁感应手段的可行性,扩展现有的地面效应推理模型,推导模型来预测由于悬停和倾斜地面效应引起的压力变化,从而增强对相关物体的检测。Jang和Kim(2019)针对未知水下环境,融合单波束声学高度计、多普勒测速仪或IMU,提出具有双线性面板模型的测深SLAM在构建地图时需要的存储空间更小,计算量更低。Hartley等人(2020)使用不变扩展卡尔曼滤波器(invariant extended Kalman filter,InEKF)融合IMU和接触传感器的测量进行腿足机器人的状态估计, 实现接触—惯性动力学与前向运动相结合。
对于传感器不能直接测量的物理量,可以建立相应的物理模型来提供额外的约束以正则化状态估计(左星星,2021)。VIMO(visual inertial model-based odometry)(Nisar等,2019)提出一种相对运动约束,结合机器人动力学和预积分残差中的外力,以减小模型预测运动与实际运动之间的差异。Zhang等人(2021)提出融合环境物理信息的运动流形,Zuo等人(2019b)融合机器人物理信息的运动学参数进行位姿估计,这两种解决方案提升了机器人在复杂大规模真实环境中的位姿估计精度。
4 问题与挑战
回顾本文分析的SLAM解决方案,可概括出一种多源融合SLAM框架(如图10所示),并将其分为3个层面。第1层面的多传感器融合,结合应用场景以及每种传感器的优缺点选择不同的传感器组合方式;第2层面的多特征基元融合,对图像的点、线、面特征及像素灰度信息进行提取处理,对于激光雷达点云还可得到3维的线、面和体素特征等,将不同的特征基元进行有效融合来满足应用需求;第3层面的多维度信息融合,将图像和点云通过学习方法得到的语义信息与传统的几何信息以及通过其他传感器获取的环境及平台自身的物理信息进行融合,以适应具有挑战性的复杂环境。
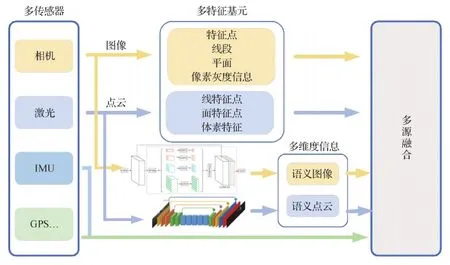
图10 一种多源融合SLAM框架Fig.10 A frame of multi-source fusion SLAM
同时满足上述3个层面的多源融合SLAM,一般基于多传感器融合,针对不同传感器的特征,使用不同的方法进行处理融合。Lvio-Fusion(Jia等,2021)基于图优化融合双目相机、激光雷达、IMU和GPS,使用轻量级深度强化学习方法调整每个因子的权重,实现了高精度、高鲁棒的城市SLAM框架。Du等人(2020)根据沙漠蚂蚁导航原理,观察光线偏振,设计仿生偏振天窗传感器,结合激光雷达和里程计实现位置、方向和地图的估计,并提高定向精度。Kimera(Rosinol等,2020)基于相机与IMU,融合学习方法的3D几何与语义重建,为视觉惯性里程计、SLAM、3D重建和分割等领域的研究人员提供了很好的学习案例。
通过对多源融合SLAM的梳理,可知尽管它在过去几十年中取得了重大进展,但仍有许多挑战需要应对,受篇幅限制本文仅列出部分开放性挑战和问题供大家讨论:
1)合理融合多传感器的测量往往能提升系统性能,但在融合之前需要标定不同传感器之间的相对位姿变换与时间戳,一般会选择离线标定,然而在使用过程中,传感器间的外参由于机械变形及外界物理环境的变化,很有可能发生改变。虽然有在估计器中进行在线外参标定的解决方案,但其容易受到退化运动的影响而失效(左星星,2021)。故而需要开发鲁棒适应性强的实时在线多传感器外参标定、时间同步方法。
2)在具有挑战性的动态复杂环境条件下,如变化的光照、剧烈运动、开阔场地和缺乏纹理的场景等,需要长期稳健安全的算法来支撑,其应该具备有效表示和实时检测跟踪运动物体的能力,以及将低维几何特征与多维几何特征相结合的能力。在此过程中,通用鲁棒的几何特征提取、参数化、数据关联、耦合方法以及可信度估计等显得尤为重要。
3)在融合几何信息和语义信息、传统方法与学习方法、外界与自身物理信息等多维度信息时,大量的数据处理将非常耗时,而且对计算性能有一定要求,如何构建轻量级、紧凑部署和快速响应的SLAM系统仍是一个挑战。此外,能否构建出统一的、适应性极强的SLAM框架来应对不断出现的新传感器、新表示方法和新学习方法,是一个值得探究的问题。
5 结 语
本文从多传感器融合、多特征基元融合和多维度信息融合3个融合层面对近年来的多源融合SLAM进行系统性分析与回顾,提出的多源融合框架便于研究者宏观掌握SLAM的发展脉络及未来方向。重点介绍了常用的传感器之间的组合方式、低维几何特征与多维几何特征的结合、几何信息与语义信息的融合、学习方法与传统方法的融合等多源融合SLAM系统,并对各方法的优缺点进行简要阐述。最后概括了当前多源融合SLAM仍然存在的问题与面临的挑战,在多传感器在线标定、适应高动态复杂环境、高层次语义信息理解和资源有效合理分配等方面仍然需要进一步研究。未来的多学科交叉技术将对解决多源融合SLAM问题有所帮助。
猜你喜欢
小学科学(2022年8期)2022-09-07
农业工程学报(2022年4期)2022-04-24
汽车观察(2021年8期)2021-09-01
科技研究·理论版(2021年20期)2021-04-20
舰船科学技术(2021年12期)2021-03-29
计算机与网络(2020年19期)2020-12-04
时代英语·高一(2019年1期)2019-03-13
新高考·高一物理(2015年5期)2015-08-18
中学生数理化·八年级物理人教版(2014年1期)2015-01-09
中学生数理化·八年级物理人教版(2014年1期)2015-01-09
