
深度学习单目深度估计研究进展
2022-02-28 07:33:30罗会兰周逸风
中国图象图形学报 2022年2期
罗会兰,周逸风
江西理工大学信息工程学院, 赣州 341000
0 引 言
从场景中获取深度信息是计算机视觉的基础问题,在智能汽车(胡云峰 等,2019)和机器人定位(Cadena等,2016)等领域应用广泛。获取深度信息的传统方法是激光雷达。激光雷达通过测量激光的折返时间精确地获取深度信息,但由于价格等原因很难大规模应用。与传统方法相比,基于图像的深度估计没有过高的硬件要求,只需要拍摄图像就能得到深度信息。因此,基于图像的深度估计具有更广泛的应用范围和使用人群。基于图像的深度估计分为基于单目视觉的深度估计方法和以立体视觉技术为代表的多目视觉深度估计方法。测试时,单目视觉从单幅图像中获取场景深度信息,而立体视觉技术类似于人眼的成像原理,需要使用两个摄像头获取同一场景的两幅图像,然后对两幅图像进行匹配,利用匹配信息得到深度信息。在立体视觉技术中,左右两图像的基线距离和相机的焦距已知,已知的相机参数信息有助于精度的提高,但左右匹配问题受到设备的限制,从而使得双目视觉应用范围有较大局限性。相较而言,单目深度估计只需单幅场景图像即可估计深度信息,不需要额外的信息,所以具有更广泛的应用价值和重要的研究意义,逐渐成为当前计算机视觉领域的研究热点之一。
从图像中获得深度信息的本质是构建一个关联图像信息和深度信息的模型(Saxena等,2005),随着深度学习的迅速发展,深度卷积神经网络在单目视觉中的应用成为研究热点。深度学习在解决目标识别、图像分割等问题中性能优异,这些方法也大量迁移应用于深度估计。从Eigen等人(2014)首次将神经网络应用于深度估计至今,随着VGG(Visual Geometry Group)(Simonyan和Zisserman,2015)、ResNet(He等,2016)等网络框架和空洞卷积(Yu和Koltun,2016)等卷积结构相继提出,出现了大量性能优异的深度估计网络。普通相机在拍摄时只记录场景的色彩信息,深度信息的丢失导致在不同场景下拍摄的图像可能是相同的,所以单目深度估计是一个病态问题。由于单目深度估计中图像与深度图的对应关系存在一对多的可能性,引入辅助信息提升深度估计精度是众多科研者的思路。
已经训练好的单目深度估计模型在测试或实际使用时,只需要输入单幅图像就可以得到深度估计结果。但在训练学习时,有些模型只需要使用单幅图像训练(Eigen等,2014;Laina等,2016)。也有许多研究者为了提升模型性能,使用立体图像对(Godard等,2017;孙蕴瀚 等,2020)、图像序列(Yin和Shi,2018;Zhou等,2017;Zou等,2018)和深度范围(Fu等,2018;Lee等,2019)来训练模型。目前,深度估计最常用的数据集是NYU depth v2(Silberman等,2012)数据集和KITTI(Karlsruhe Institute of Technology and Toyota Technological Institute at Chicago)(Geiger等,2012)数据集。NYU depth v2是美国纽约大学Silberman团队使用Kinect深度相机创建的室内深度估计数据集,包含464个室内场景的彩色图像和对应的深度图,有效深度范围为0.5 10 m。KITTI数据集由数据采集车沿途采集的彩色图像、深度图和GPS(global positioning system)位置等信息组成,包括城市街道和乡间小道等道路场景,是常用的室外场景深度估计数据集。单图像训练模型采用特征提取主干网络和上采样网络获取深度图,网络结构简单,易于针对特定任务调整结构,并且对硬件要求低,但是需要像素级的深度真值图进行训练。多图像训练模型分为视差模型和运动结构重建模型。视差模型分别估计输入图像的左右视差图,并通过视差图学习图像的深度图;运动结构重建模型由深度估计模块和相机轨迹估计模块组成。多图像训练单目深度估计模型使用图像间的空间关系或时序关系构造监督信息,在训练时不需要图像的深度真值,训练数据很容易获得,所以在大数据量上训练得到的模型的泛化性能也较好。深度范围也可以用来训练模型,一些单目深度估计模型先将深度范围离散化,然后根据卷积神经网络提取的特征估计每一个像素点的深度范围。
与传统的深度获取方法和多目深度估计方法相比,单目深度估计只需一张照片就能获得场景的深度信息,应用范围更广泛,是计算机视觉的研究热点。2014年以来,许多研究者从事单目深度估计的研究,提出了不同的单目深度估计模型。Khan等人(2020)和Zhao等人(2020)以模型使用监督学习、无监督学习或半监督学习为依据,对单目深度估计研究进行了分类综述。与上述综述不同,本文从单目深度估计模型采用训练数据类型的角度,对近年来基于深度学习的单目深度估计研究进行综述,将单目深度估计方法分为单图像训练模型、多图像训练模型、语义及数据集深度范围优化深度估计,旨在为根据获得的训练数据类型和辅助信息选择和设计模型提供参考。
1 单图像输入训练模型
单图像输入的训练模型以单幅彩色图像为输入,参考深度信息为监督信息,训练网络模型实现深度估计。在使用卷积神经网络拟合得到深度图后,还可以通过一些优化方法对深度图进行优化以提高预测精度。
1.1 卷积神经网络拟合深度图
卷积神经网络拟合深度图的方法是使用卷积神经网络提取图像特征后,采用全连接或上采样的方法获取图像的深度图。此类方法性能的提升依赖于深度卷积神经网络的学习能力。随着深度学习技术的发展,出现了AlexNet(Krizhevsky等,2017)、VGG(Simonyan和Zisserman,2015)和ResNet(He等,2016)等网络结构。新型网络结构提高了网络的深度,更深的网络模型可以提取更丰富的特征信息,有利于提高拟合深度图的精度。Eigen等人(2014)将AlexNet应用于深度估计,并提出由粗到细的两步策略。网络中使用粗细两个尺度的神经网络,其中粗尺度网络获取全局深度,细尺度网络在粗尺度网络输出的基础上丰富局部细节。粗尺度网络使用AlexNet网络作为主干网络,输入的彩色图像经过AlexNet网络提取特征,这些特征通过全连接层映射为分辨率是输入图像1/4的粗略深度图。在细尺度网络中,使用卷积提取原图像的局部特征并与全局深度图拼接,经过卷积获得最终的深度图。但Eigen等人(2014)提出的网络缺少上采样层,使得网络输出的深度图分辨率较小,细尺度网络的优化效果也不太理想,深度估计的精度有所欠缺。2014年,牛津大学提出了VGG网络(Simonyan和Zisserman,2015),使用多个小卷积核的叠加替代AlexNet中的大卷积核,加深了网络,从而提高了网络性能。在Eigen等人(2014)的基础上,Eigen和Fergus(2015)采用VGG网络提取图像的特征,并在Eigen等人(2014)提出的网络结构的基础上加入第三尺度网络,进一步优化细节,同时网络中增加上采样层,使输出深度图的尺寸提高,为输入图像的1/2。
Eigen等人(2014)使用全连接层生成深度图,全连接层巨大的参数量限制了深度图分辨率的提高。Shelhamer等人(2015)在为解决语义分割问题提出的全卷积网络(fully convolutional networks,FCN)中使用特征图取代全连接的结果,经过上采样将特征图还原到输入图像的尺寸,在更少参数量的情况下获得了原图像同样分辨率的输出。在此基础上,Laina等人(2016)将ResNet和FCN网络应于单目深度估计。网络在特征提取端使用ResNet50提取彩色图像的深层特征,特征图通过4次上采样输出分辨率为原图像1/2的深度图,并使用reverse Huber(Owen,2007;Zwald和Lambert-Lacroix,2012)函数替代L2范数为损失函数提高深度估计精度。由于ResNet有效缓解了梯度消失问题,相比Eigen等人(2014)提出的模型,Laina等人(2016)的模型的全局误差显著降低,深度估计的精度明显提高。
Laina等人(2016)提出的网络模型存在物体形状扭曲、小物体缺失和物体边界模糊等问题,一些研究者对此提出新的网络模型。Hu等人(2019)认为不同尺度的特征图包含不同的深度信息,基于这个观点, Hu等人(2019)采用与Laina等人(2016)类似的主干网络,不同尺度的特征图上采样后与主干网络的输出融合生成最终的深度图,尝试使用ResNet、DenseNet(Huang等,2017)和SENet(Hu等,2020)提取特征,其中SENet的深度估计效果最为优异。网络充分融合多尺度特征,有效增强了深度图局部细节,提高了深度估计的精度。与Hu等人(2019)方法不同, Zhao等人(2019)使用Shi等人(2016)提出的亚像素卷积融合多尺度特征,提高模型对细节的深度预测能力。为了提高物体边界处的深度估计精度,谢昭等人(2020)基于编解码结构提出了一种采样汇集网络模型,在上采样和下采样层中加入局部汇集模块,通过采样汇集跨层的上采样网络提高特征图分辨率,局部汇集模块的使用减少了物体边界定位误差对深度估计的影响,提升了估计的精确度。
1.2 利用图像特征优化深度图
在卷积网络模型估计得到深度图后,可以利用输入图像的区域相似性和梯度等图像自身的特征进一步优化深度图,其中利用图像相似性优化深度图的方法主要有条件随机场(conditional random field,CRF)(Lafferty等,2001)。Liu等人(2015)认为图像中相似区域的深度相近,根据图像的区域相似性使用连续条件随机场优化深度图。首先,将图像划分为多个区域块,即超像素,然后通过神经网络估计超像素的深度值,并根据相邻超像素生成相似矩阵优化深度估计。在CRF模型中,超像素作为图模型的节点,每个超像素的深度映射函数用U表示,节点间的连线用二元项V表示,二元项反映节点间的相似度,卷积神经网络通过优化U和V这两个函数,使得相似度高的超像素有相近的深度值。输入图像分为N个超像素,以超像素的质心为中心在原图中截取图像块作为一元项U的训练图像,经过卷积层和全连接操作后输出超像素质心对应的深度值。N个超像素有K组相邻超像素对,K组超像素对的相似度组成相似性矩阵。一元项部分的网络以L2范数为损失函数,二元项以CRF损失进行优化。但网络模型需要计算超像素的深度和超像素间的相似性,计算量大,耗时严重,而且深度估计的结果以超像素为单位降低了深度估计的精度。在此基础上,Liu等人(2016)提出使用掩膜层加快计算,将图像分割成多个超像素作为超像素掩膜层。彩色图像经过卷积和最近邻插值得到与输入图像分辨率相同的深度图,深度图与超像素掩膜层结合,将同一超像素中的深度值平均后作为超像素的深度值,再进行条件随机场优化。由于神经网络不需要重复估计超像素的深度值,网络的运行速度得到提升。
Xu等人(2017)将条件随机场作为独立的网络分支,设计了一个由卷积神经网络和条件随机场组成的深度估计网络,卷积神经网络使用全卷积网络产生深度图,在上采样网络中将不同尺度特征图生成的深度图逐层输入条件随机场,得到精度逐步提高的深度图。与使用条件随机场优化深度图的方法不同, Li等人(2017)利用图像梯度信息优化深度估计,设计了一个独立分支充分提取输入图像的梯度特征,并与深度估计融合,达到优化深度图的目的。Lee等人(2018)提出一种在频域中分析候选深度图以提高深度图精度的深度学习网络,使用裁剪率不同的裁剪图像得到多个深度预选图,在频域中学习各深度预选图的分量,并通过2维傅里叶逆变换产生最后的深度图。由于不同裁剪率生成的深度预选图在全局和局部的表现不同,深度学习模型充分学习了全局分量和局部细节,使得深度估计的精度得到提高。
1.3 小结
典型的单图像输入训练模型的网络结构都比较简单。FCN网络提出前都使用卷积层加全连接层来产生深度值,FCN网络提出后深度估计模型大多采用了编解码结构。与卷积神经网络拟合深度图的方法相比,虽然深度图优化的方法预测深度更精确,但在训练时多采用分步训练,网络需要更多迭代次数,时间复杂度更高。随着性能更好的新型骨干网络框架的提出,单图像训练模型更倾向于采用卷积神经网络拟合的方法。典型单图像训练模型的概要如表1所示。

表1 典型单图像训练模型概要总结Table 1 Summary of typical single image training models
2 多图像输入训练模型
多图像输入训练模型分为使用立体图像对训练的方法和使用图像序列训练的方法。以立体图像对作为训练数据的单目深度估计模型通过视差图来学习场景的深度,而以图像序列为训练数据的单目深度估计模型,需要结合学习深度估计和相机姿态,通过场景重建来优化深度估计。多图像输入单目深度估计与立体视觉有显著不同,在测试时,单目深度估计只需单幅图像,而立体视觉还需要立体图像对。
2.1 立体图像对训练模型
Mayer等人(2016)在FlowNet(Dosovitskiy等,2015)的基础上,提出了用于视差估计的DispNet模型,在FlowNet的解码端增加了卷积层和上采样层,获得了更平滑、分辨率更高的视差图。Godard等人(2017)将视差法应用单目深度估计,网络结构如图1所示。
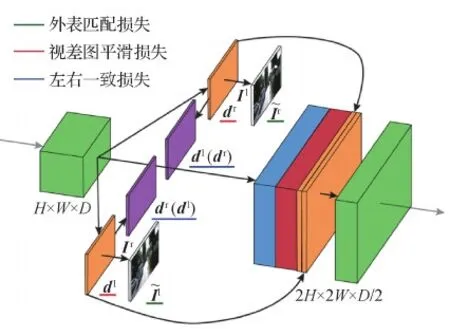
图1 MonoDepth网络结构示意图(Godard等,2017)Fig.1 The framework of MonoDepth(Godard et al.,2017)

基于视差估计深度的网络模型,其效果严重依赖于视差估计结果。所以一些研究者致力于视差估计模型的研究,GA-Net(guided aggregation net)(Zhang等,2019)和Bi3DNet(Badki等,2020)等视差预测模型有效提高了深度估计的效果。基于Godard等人(2017)的网络模型和损失函数,孙蕴瀚等人(2020)通过DenseNet(Huang等,2017)提取特征后使用特征金字塔结构(Lin等,2017)估计多尺度深度图,并在损失函数中使用多尺度损失,深度估计精度有所提高。在Godard等人(2017)的方法中,右视差图dr是左视图Il生成的,造成右视图Ir与右视差图dr不匹配,从而影响了深度图的精度。Repala和Dubey(2019)使用双流网络并行处理左右视图,估计左右视差图,使左右视差图与对应视图匹配,得到了更精确的深度图。
2.2 图像序列训练模型
Kendall等人(2015)提出了PoseNet网络模型,通过分析图像序列获得相机的运动轨迹,实现相机姿态估计。在此基础上,Zhou等人(2017)提出了运动结构重建模型SfMLearner(structure from motion learner),在假定没有运动物体和场景物体是理想反射以及相机参数已知的条件下,将深度估计与相机姿态估计结合,使用运动结构重建来学习图像中的深度信息。网络结构如图2所示,以图像序列作为输入,It为目标图像,It-1和It+1表示目标图像的前后帧图像,将它们输入相机姿态估计网络中,分别估计从It到It-1和从It到It+1的相机运动轨迹。深度估计网络估计输入图像It的深度图,然后图像It的深度图结合相机运动轨迹和相机参数将图像It中所有点的位置映射到It+1和It-1中,最后根据映射关系使用It+1和It-1中像素点的亮度值重建图像It。网络以重建后的图像和原图像间的误差作为损失函数,同时优化深度估计网络和姿态估计网络。训练时,网络以图像序列作为训练数据,预测时只需输入单幅图像估计图像的深度图。

图2 SfMLearner网络结构示意图(Zhou等,2017)Fig.2 The framework of SfMLearner(Zhou et al.,2017)
考虑到图像序列间的亮度差异会影响深度估计的精确度,Yang等人(2020)在Zhou等人(2017)的基础上,使用亮度转换函数和亮度不确定参数来减少匹配图像序列间的亮度误差,提高了深度估计的整体精度。一些研究者在SfMLearner基础上,通过优化姿态估计网络和深度估计网络提高深度估计模型的性能。梁欣凯等人(2019)在姿态估计网络中加入长短期记忆网络,并在深度估计网络中使用空洞特征金字塔网络(Chen等,2018)提取特征,提升了深度估计的精度。同样的,Johnston和Carneiro(2020)使用自注意力(Wang等,2018)和离散差异体积卷积(Kendall等,2017)增强深度估计模块的性能。SfMLearner模型隐含地假定了目标图像帧与其相邻帧间不存在遮挡或分离现象,为了克服此局限性,Godard等人(2019)采用U-Net(Ronneberger等,2015)网络作为特征提取主干网络来估计图像的深度,重建损失项中使用最小重投影损失取代平均重投影损失降低遮挡物对深度估计的影响,从而提高了深度图的精确性。
为了处理存在运动物体的场景,Yin和Shi(2018)结合FlowNet(Dosovitskiy等,2015)提出了GeoNet模型,采用分治策略,根据场景中物体是否存在相对移动,将场景中的物体分为静态和动态物体,深度估计和姿态估计网络处理静态物体,光流网络计算场景中运动物体的光流。首先使用运动结构重建的思想实现场景重建,然后将重建后的场景图输入后续的光流网络中,通过前后向光流一致性优化深度估计网络、相机姿态估计网络和光流网络,很好地解决了运动结构重建无法处理运动物体的问题。同样地,为了解决运动物体问题,Zou等人(2018)提出DF-Net模型,使用光流网络,通过前后向一致性生成掩膜层来明确静态与动态物体的区域。而Ranjan等人(2019)使用运动分割的方法明确静态与动态区域。这两种方法使得动态物体的区域更为明确,进一步提升了网络应对运动物体的能力。
相机将3维场景映射为2维图像时,2维图像丢失了图像中物体尺寸与实际物体尺寸的比例关系,因此无法准确估计单幅图像中物体的长度。立体图像对中,由于两视图间的基线距离已知,根据基线距离能够准确计算图像与实际物体尺寸的比例,所以使用立体图像训练的深度模型能够准确估计图像的深度值。与立体图像对不同,图像序列间缺少相机移动的实际度量尺度,度量尺度的缺失引起的尺度模糊问题会影响深度估计的效果。Zhan等人(2018)考虑到图像序列中存在的尺度模糊问题,提出使用立体图像序列训练单目深度估计的网络模型。在立体图像序列中,左视图到右视图的相机运动轨迹已知,网络分别估计左视图序列和右视图序列中的相机运动轨迹,然后结合相机运动轨迹与深度图重建视图。考虑到重建图与原图间存在亮度差,而这种亮度差会影响深度估计的效果,因此重建图像的同时还重建了图像的特征,在图像重建损失的基础上增加了原图与重建图的特征匹配损失项,降低了原图与重建图像间亮度不同对网络性能的影响。使用立体图像序列降低了图像序列中尺度模糊的影响,同时立体图像序列在图像序列中增加了左右视图间的空间约束,提升了深度估计的精确性。
2.3 小结
视差法深度估计模型和运动结构重建模型作为多图像训练的典型模型,与单图像训练模型相比,网络结构复杂度明显提高。但是多图像训练模型在训练时不需要深度真值作为监督,极大降低了训练数据的获取难度,增加的训练数据提高了网络的泛化性能。相对于视差法深度估计模型,运动结构重建模型的结构更为复杂,网络包括深度估计和相机轨迹估计两个前端模块和光流网络等后端处理模块,训练过程更复杂,收敛速度更慢。典型多图像训练模型的概要如表2所示。

表2 典型多图像训练模型概要总结Table 2 Summary of typical multi-image training models
3 结合语义及数据集深度范围优化深度估计
单幅图像单目深度估计方法根据神经网络提取的图像特征拟合深度图,多图像单目深度估计通过视差图和运动结构重建计算图像的深度。为了进一步提高深度估计的精度,许多研究者结合语义标签和数据集深度范围等信息来获得更好的深度估计效果。
3.1 结合语义分割与深度估计
语义分割与深度估计是计算机视觉中的两项基本任务,都是对图像场景的理解,语义分割中物体边缘普遍存在深度跳跃而分割物体内部的深度大多连续,两项任务具有非常高的相关性,结合进行训练可以学习到额外的信息,从而提高深度估计的性能。而且两项任务可以共享一个主干网络,减少训练两项任务的参数量。因此,许多研究者通过结合语义分割与深度估计来提高深度估计效果。
Wang等人(2015)首次提出在网络框架中联合利用语义和深度信息,旨在提升深度估计和语义分割的效果。网络结构如图3所示,全局卷积神经网络以整个图像作为输入,同时估计整幅图像的深度图和语义概率图。而区域卷积神经网络以over-segmentation(Liu等,2011)算法分割的图像块为输入,估计归一化相对深度模板和语义标签。然后利用像素点的深度与语义标签、图像块的深度与语义标签以及图像块与像素间的包含关系组成分层条件随机场。最后联合利用像素级深度信息和区域级深度信息,使用循环置信传播(loopy belief propagation, LBP)算法估计每个图像块的语义标签,再使用最大后验概率算法估计图像块中每个像素点的语义标签。在获得语义标签后,通过LBP算法估计图像块中心深度和深度变化尺度,结合区域卷积网络估计的归一化模板,获得图像块的绝对深度。模型通过最小化双层CRF联合估计语义标签和深度图,充分利用了图像中语义与深度信息的关联性,精度得到了一定提升。
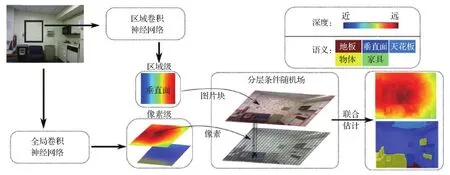
图3 分层条件随机场网络结构示意图(Wang等,2015)Fig.3 The framework of hierarchical conditional random field(Wang et al.,2015)
Jiao等人(2018)通过分析数据集中深度值的分布,提出使用语义信息和注意力驱动损失来优化深度图。图像在提取特征后分别输入深度估计和语义分割两个分支网络,两个分支网络间采用横向共享单元将同尺度下的特征相互拼接实现特征共享,同时每个分支中使用跳跃连接将各上采样层融合,得到最后的深度图和语义分割图。网络同时进行深度估计和语义分割,横向共享单元使两项任务的效果协同提高,有效提高了深度估计的精度。
Chen等人(2019)提出采用立体视图同时预测图像的深度信息和语义分割,将左视图生成的语义分割图通过视差图转化为右视图的语义分割图,右视图生成的语义分割图通过同样的操作获得左视图的语义分割图,然后使用相对应语义分割图差值之和优化网络,相比Godard等人(2017)单纯使用立体图像对进行深度估计,精度获得了显著提升。
有些研究者将实例分割和全景分割等新型的图像分割任务与深度估计结合。Wang等人(2020)将深度估计、语义分割和实例分割三者结合,提出了SDC-DepthNet(semantic divide-and-conquer network)模型,采用分治策略先对图像进行语义分割和实例分割,再结合分割结果估计图像深度。语义分割图促使图像中相同语义类别的物体有相近的深度值;实例分割图明确界定了同种物体中不同个体的边界,使图像中同类物体的不同个体在深度图中存在明显的深度差。SDC-DepthNet模型利用语义分割和实例分割的特点,提升了深度估计的精确度。
3.2 深度范围作为辅助信息
常用的深度估计数据集有NYU depth和KITTI数据集,NYU depth数据集的深度范围是0 10 m,KITTI数据集的最大深度是120 m。在数据集的有效深度范围已知条件下,一些研究者采用像素级分类的方法实现深度估计。
Cao等人(2018)将数据集深度范围离散化后对每个像素点进行深度分类,实现深度估计。网络通过ResNet152提取图像特征,并控制输出特征图的通道数与深度范围离散个数相同。然后,特征经过softmax层后生成概率图,获得像素点的深度范围,以深度范围的中值作为像素点的深度值。最后,将每个像素点深度值的对数损失作为一元项,使用高斯核函数衡量输入图像中像素点对间的颜色和位置相似度,高斯核函数与对应像素点对的深度绝对差之积作为二元项来构造条件随机场,分类器估计深度范围后使用条件随机场优化深度图,最终得到的精确度比Laina等人(2016)的方法更高。
Fu等人(2018)在数据集深度范围已知的条件下,将深度估计看做是一个分类问题,采用顺序回归的方法实现单目深度估计。网络以整幅图像作为输入,输入图像经过密集特征提取后输入场景理解模块,最后通过有序回归实现深度估计。场景理解模块由空洞特征金字塔网络(Chen等,2018)和全图编码器组成,空洞特征金字塔网络充分融合多尺度特征,特征经过编码进行有序回归。有序回归时需要多个间隔递增离散化标签,考虑到深度估计误差随着图像深度的增大而增大,在对数域中将数据集深度范围平均离散化作为有序回归的类别。网络通过有序回归获得每个像素点的深度区间后,将深度区间的中点作为像素点的深度值,取得了2018年KITTI深度估计的最优效果。
Su和Zhang(2020)同样将深度估计作为分类任务,提出了SSE-Net(scale-sernantic exchange network)模型,使用与Fu等人(2018)相同的方法对数据集深度范围离散化。SSE-Net网络以ResNet101为主干网络提取多尺度特征,多尺度特征输入信息交换网络充分融合,然后经过卷积产生类别概率图,最后使用软回归网络获得深度图。在软回归网络中,考虑到数据集深度范围严格离散化会对深度的连续性和模型处理歧义的性能产生影响,引入了尺度项和偏移项对生成的类别概率图进行修正。信息交换网络和软回归的使用有效提升了深度估计的效果。
与上述像素级分类方法不同,Lee等人(2019)利用数据集深度范围提出新型的场景重建网络,以数据集深度范围作为辅助信息,提出使用局部平面指导层解决下采样过程中的信息丢失问题。输入图像通过DenseNet(Huang等,2017)提取特征,接着使用空洞特征金字塔网络(Chen等,2018)充分融合特征图的上下文信息,然后通过局部平面指导层重建场景,最后结合多尺度的场景重建图生成深度图。局部平面指导层进行场景重建时,数据集深度范围与特征图结合,将特征图上每个位置的特征值转换为包含方位信息的特征向量。然后,根据射线平面交叉的原理得到场景重建图。通过数据集深度范围,将每个尺度下的特征图映射为反映场景信息的场景重建图,充分利用了各尺度的特征信息,深度估计的精度有很大提升。
3.3 小结
辅助信息的加入提高了深度估计的精确度,但是使用辅助信息会使网络更复杂,训练需要的时间更长。语义信息不仅使网络更复杂,而且增加了训练难度,一些结合语义分割的深度估计模型不得不采用分步训练的方法。与语义信息相比,在深度估计网络中加入深度范围更灵活,深度范围不仅应用于像素级分类深度估计模型,还可以加强网络对输入图片场景的理解能力,并且使用深度范围作为辅助信息的深度估计模型采用统一训练的方法,训练简单。典型辅助信息训练模型的概要如表3所示。
4 评价指标及代表性方法对比
单目深度估计模型常用的性能评价指标有绝对值相对误差(AR)、平方相对误差(SQ)、对数平均误差(ML)、均方根误差(RMS)、对数均方根误差(LRMS)以及阈值准确率(fcorrect)(Zhuo等,2015),计算方法为
(1)
(2)
(3)
(4)
(5)
(6)
(7)

表4、表5和表6分别比较了单图像输入单目深度估计模型、多图像输入单目深度估计模型和利用辅助信息优化深度模型在NYU数据集和KITTI数据集上的测试性能。表中数据取自各方法的测试结果,KITTI数据集的深度范围采用0 80 m,表5中训练网络使用的数据类型M和S分别表示图像序列和立体图像对。
从表4可以看出,Eigen等人(2014)方法与Hu等人(2019)方法的结果相比,单图像单目深度估计模型的性能在5年时间内提升了近一倍。多图像单目深度估计模型是2017年出现的,虽然模型出现较晚,但发展势头强劲。从表5可以看出,Johnston和Carneiro(2020)方法与Zhou等人(2017)方法的结果相比,预测误差明显降低。从表6的数据可以发现,通过利用辅助信息优化深度估计后,性能相比表4和表5中模型有较大提升。表6中Chen等人(2019)的RMS与表5中Repala和Dubey(2019)模型相比,降低了2.198。Wang等人(2015)模型与表4中Eigen等人(2014)模型相比,RMS降低了0.162。

表4 部分单图像训练模型的评估函数值Table 4 Quantitative evaluation of some single image training models

表5 部分多图像训练模型的评估函数值Table 5 Quantitative evaluation of some multi-image training models

表6 部分辅助信息优化深度模型的评估函数值Table 6 Quantitative evaluation of some auxiliary information training models
5 结 语
深度估计的应用领域对单目深度估计的精确度、估计速度和泛化性等方面有很高的要求。本文根据网络输入数据的类型对单目深度估计模型进行了分类综述,分别介绍了单图像输入、多图像输入和结合辅助信息3类方法中的典型网络结构。以单幅图像作为训练数据的模型具有网络结构简单的特点,但泛化性能较差。采用多图像训练的深度估计网络有更强的泛化性,但网络的参数量大、网络收敛速度慢、训练耗时长。引入辅助信息的深度估计网络的深度估计精度得到了进一步提升,但辅助信息的引入会造成网络结构复杂、收敛速度慢等问题。单目深度估计研究还存在许多的难题和挑战,未来的研究趋势包含如下两个方面:
1)多图像训练模型成为研究热点。虽然采用单幅图像作为训练数据的网络模型具有模型简单的特点,但是训练所需的精确密集深度信息难于获得,训练数据的场景种类和样本数量非常有限,导致单图像训练单目深度估计模型的泛化性较差。而多图像训练单目深度估计网络模型在训练时不需要精确的深度信息,训练数据的成本更低,所以可以获得更大量的训练数据,从而使得模型的泛化性能得到提高,所以多图像输入单目深度估计逐渐成为单目深度估计的研究热点。
2)单目深度估计中加入约束信息。由于单目深度估计的病态性,仅从彩色图像中获取的场景信息很难提高深度估计的精确度。在这种情况下,在单目深度估计网络中加入辅助信息是提升单目深度估计的有效方法。语义标签与深度估计联系紧密,常用来提升深度估计的效果。特定领域约束信息的加入在解决特定问题中也能取得不错效果,如Chen等人(2016)在野外深度估计任务中加入相对深度信息提高深度估计的精度。
猜你喜欢
开放教育研究(2020年2期)2020-03-31 01:54:14
计算机应用(2019年3期)2019-07-31 12:14:01
中国惯性技术学报(2019年1期)2019-05-21 00:58:30
北京航空航天大学学报(2017年4期)2017-11-23 05:48:16
软件导刊(2016年9期)2016-11-07 22:22:57
光学精密工程(2016年4期)2016-11-07 09:05:11
现代语文(2016年21期)2016-05-25 13:13:44
科技视界(2016年2期)2016-03-30 11:17:03
大连民族大学学报(2015年2期)2015-02-27 08:28:11
机械工程师(2015年10期)2015-02-02 01:13:47
